Download as PDF, PPTX













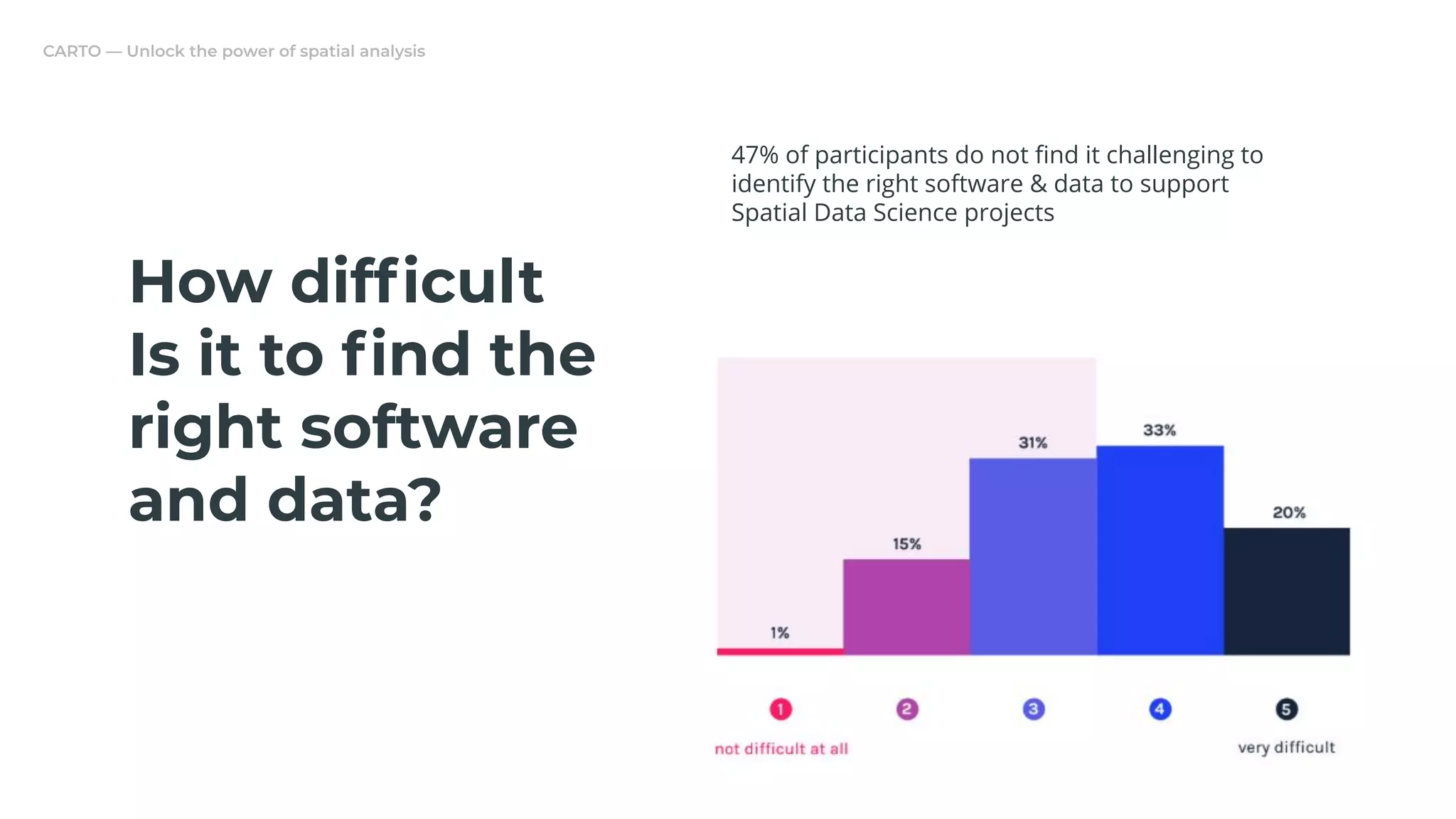
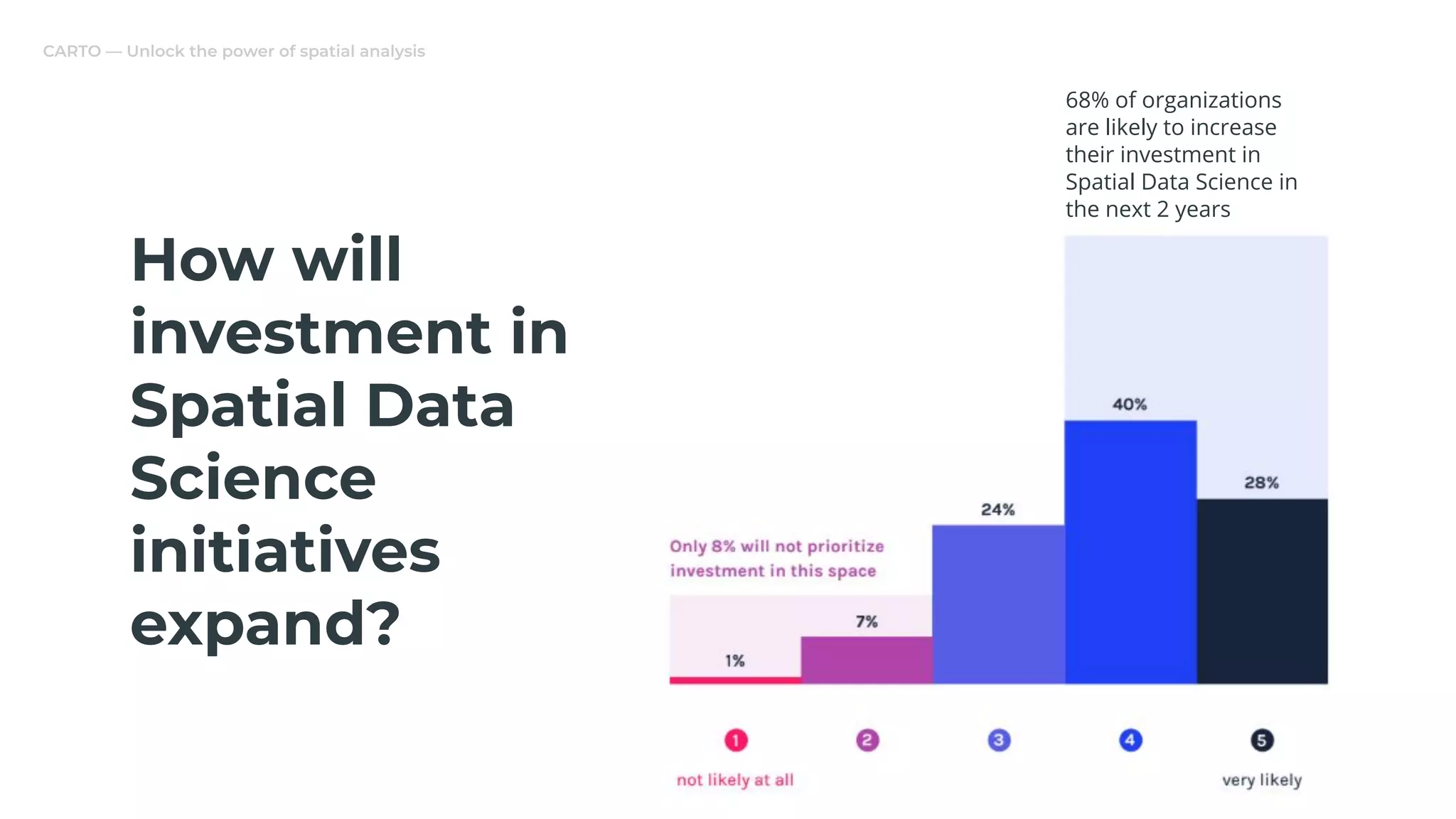


















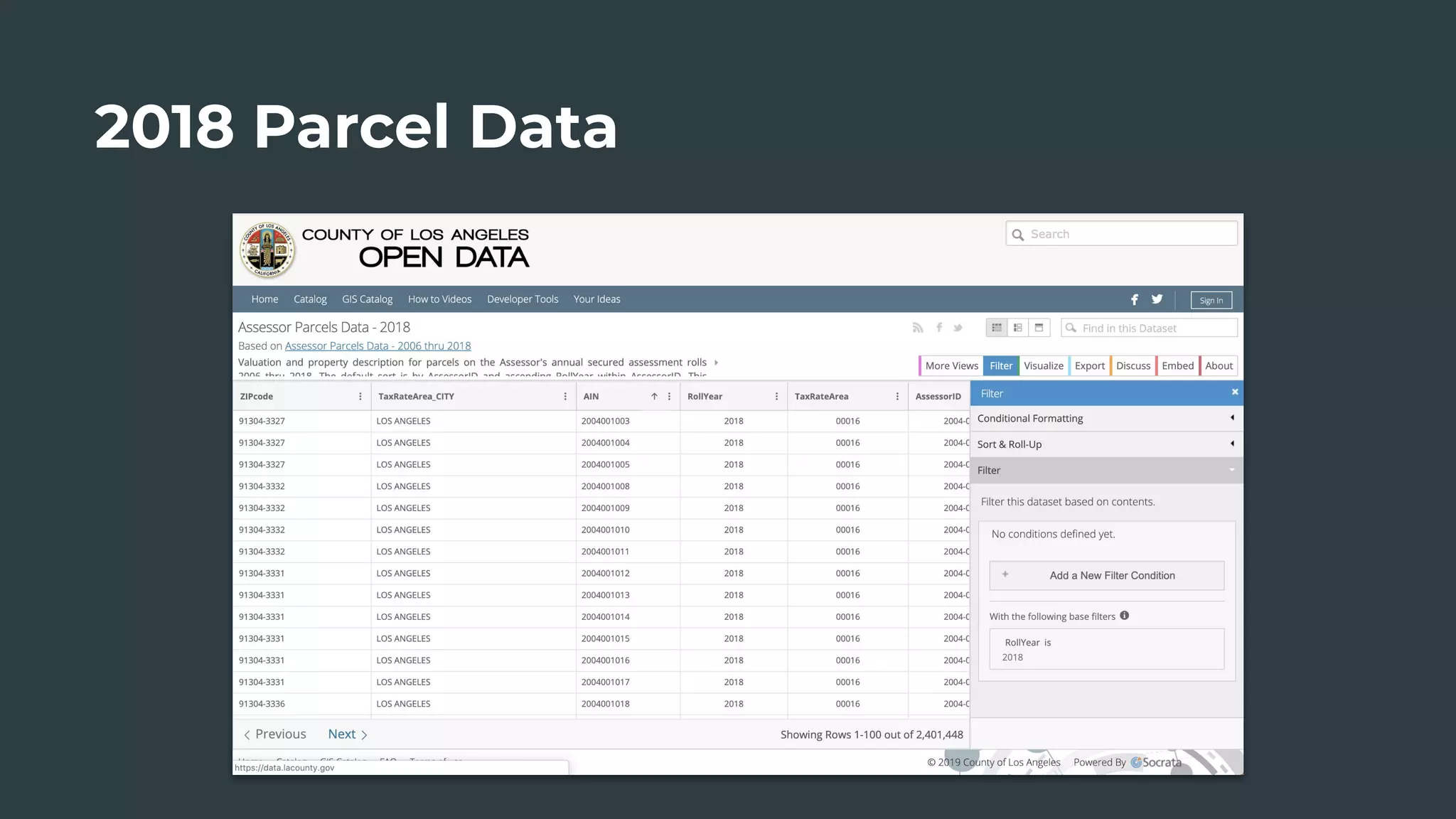
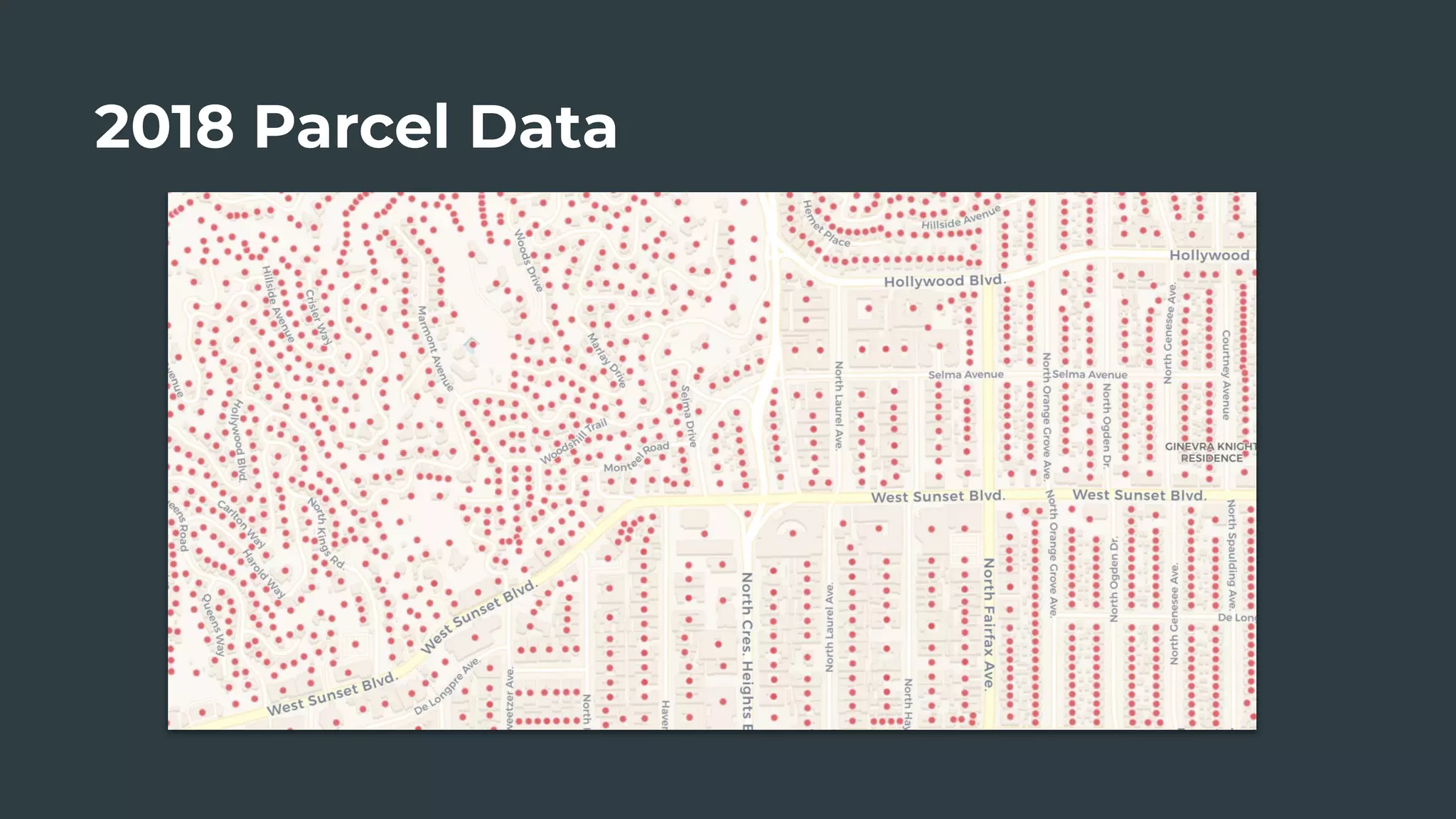






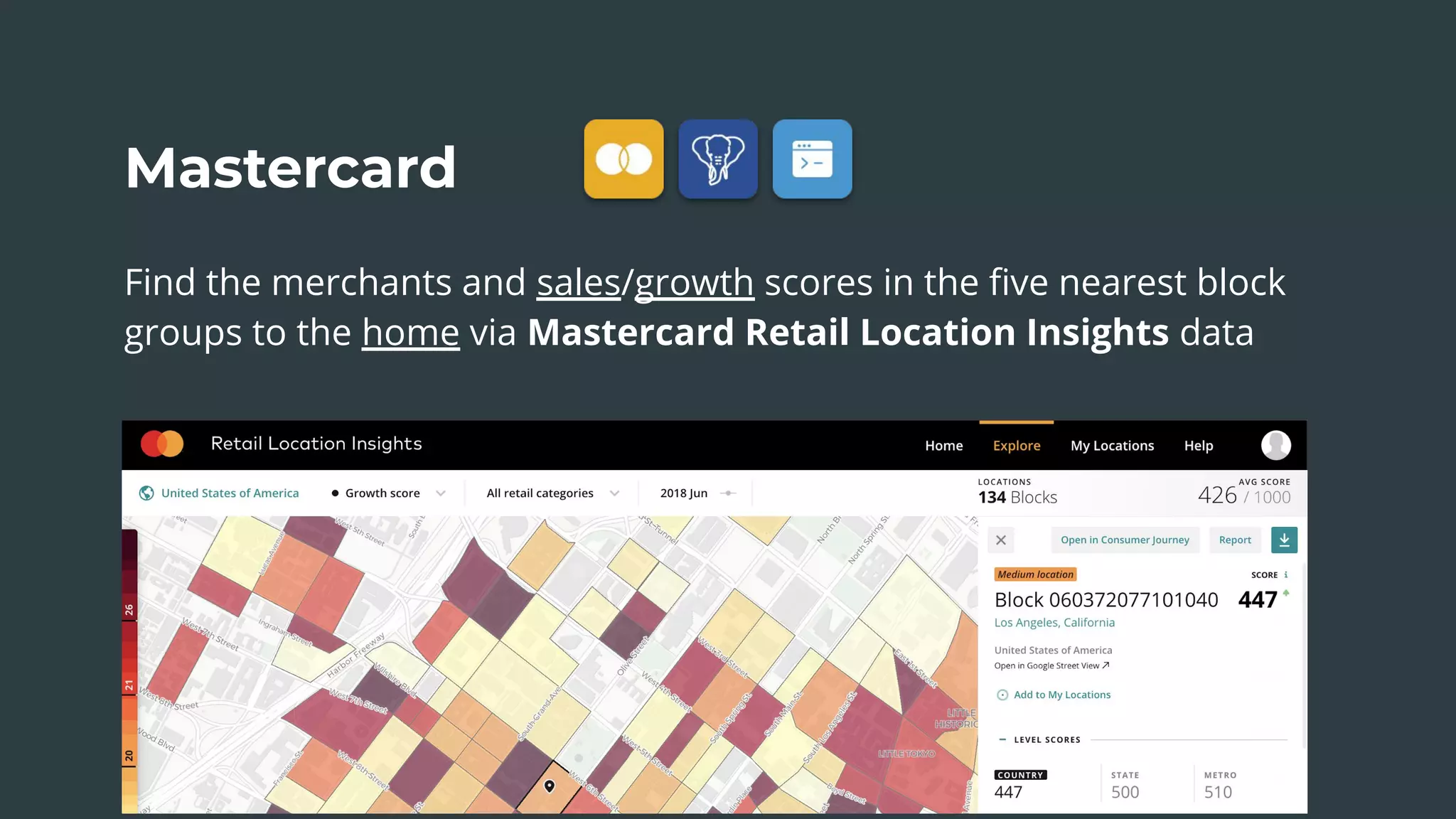


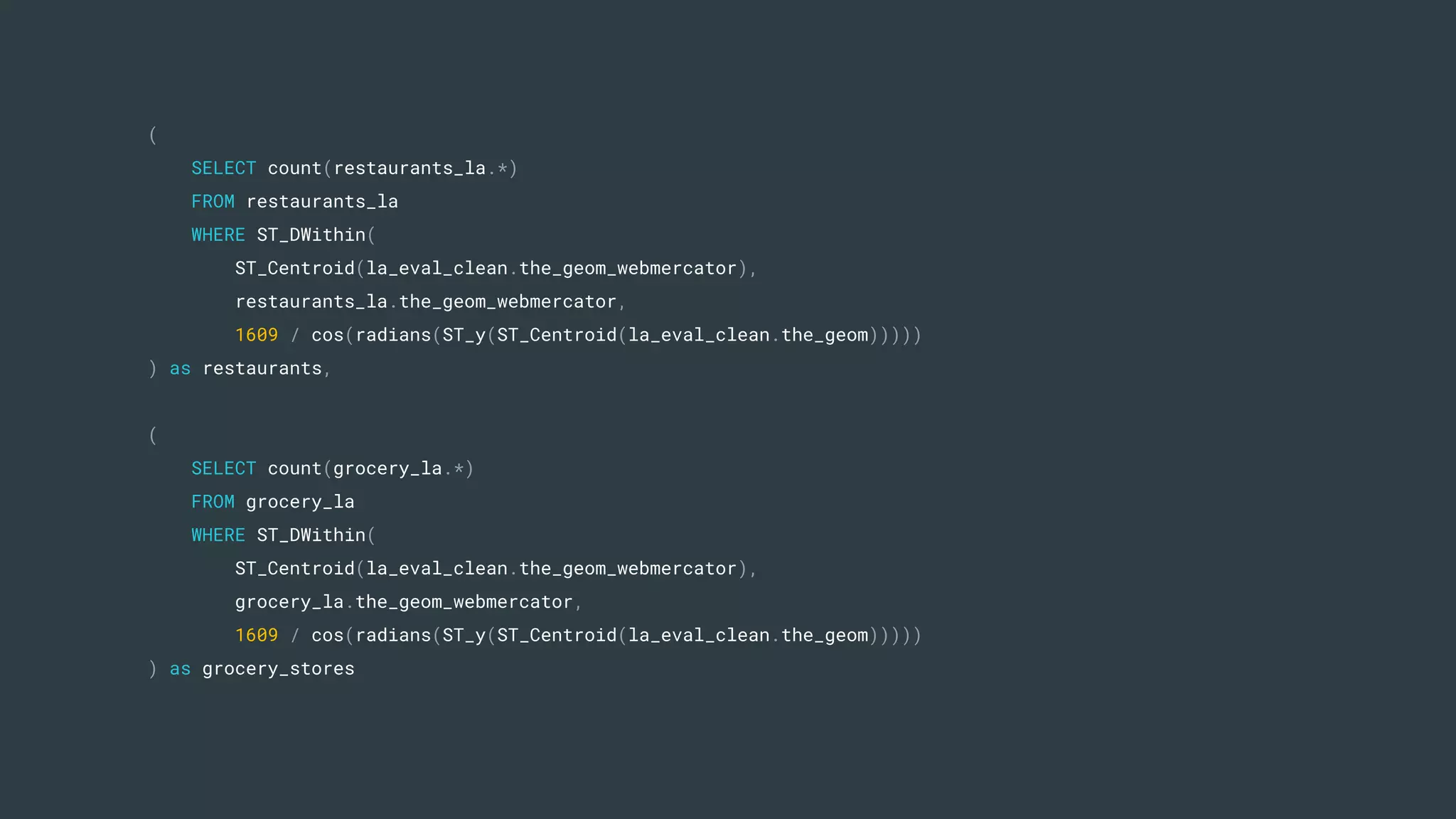






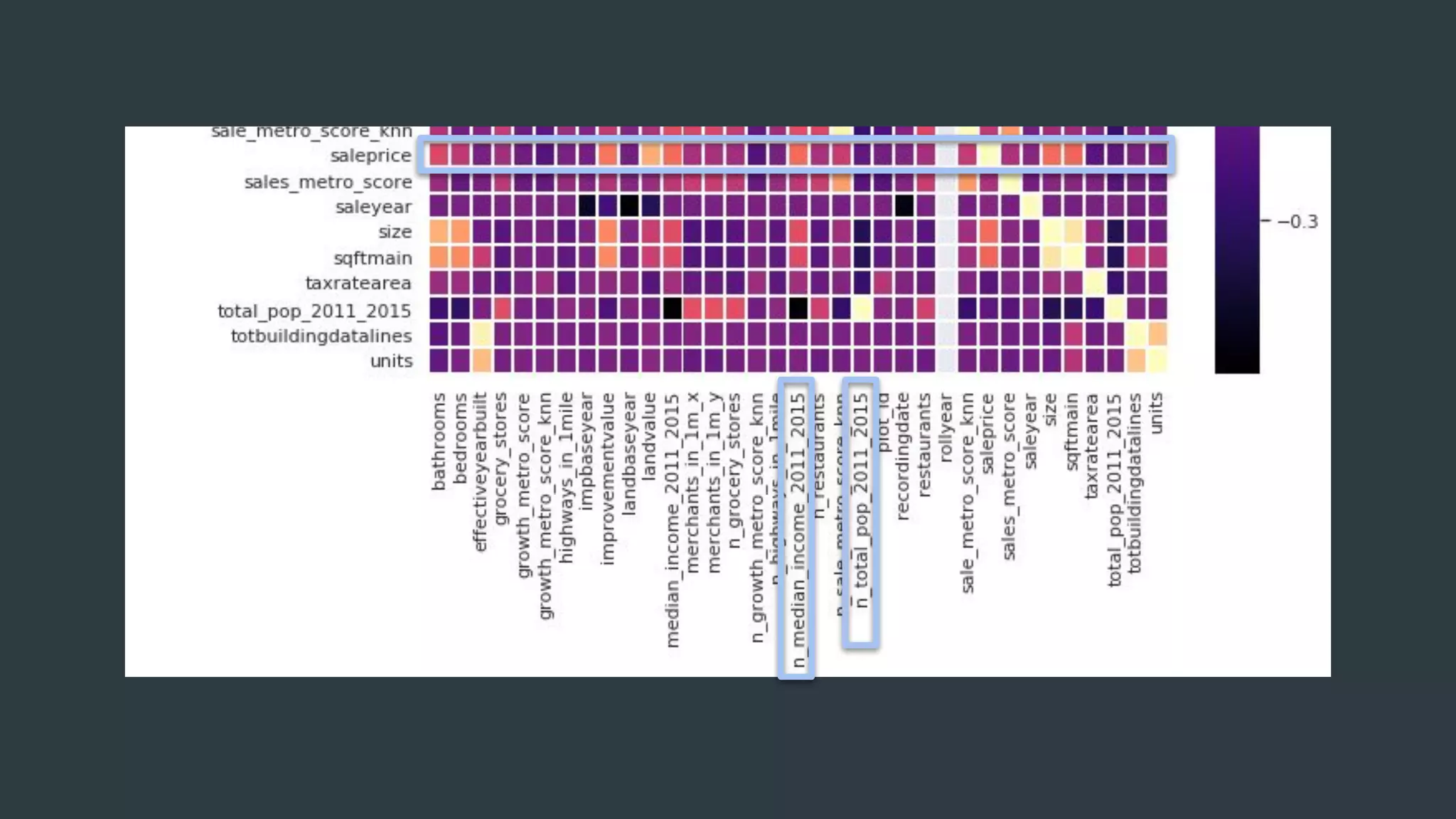

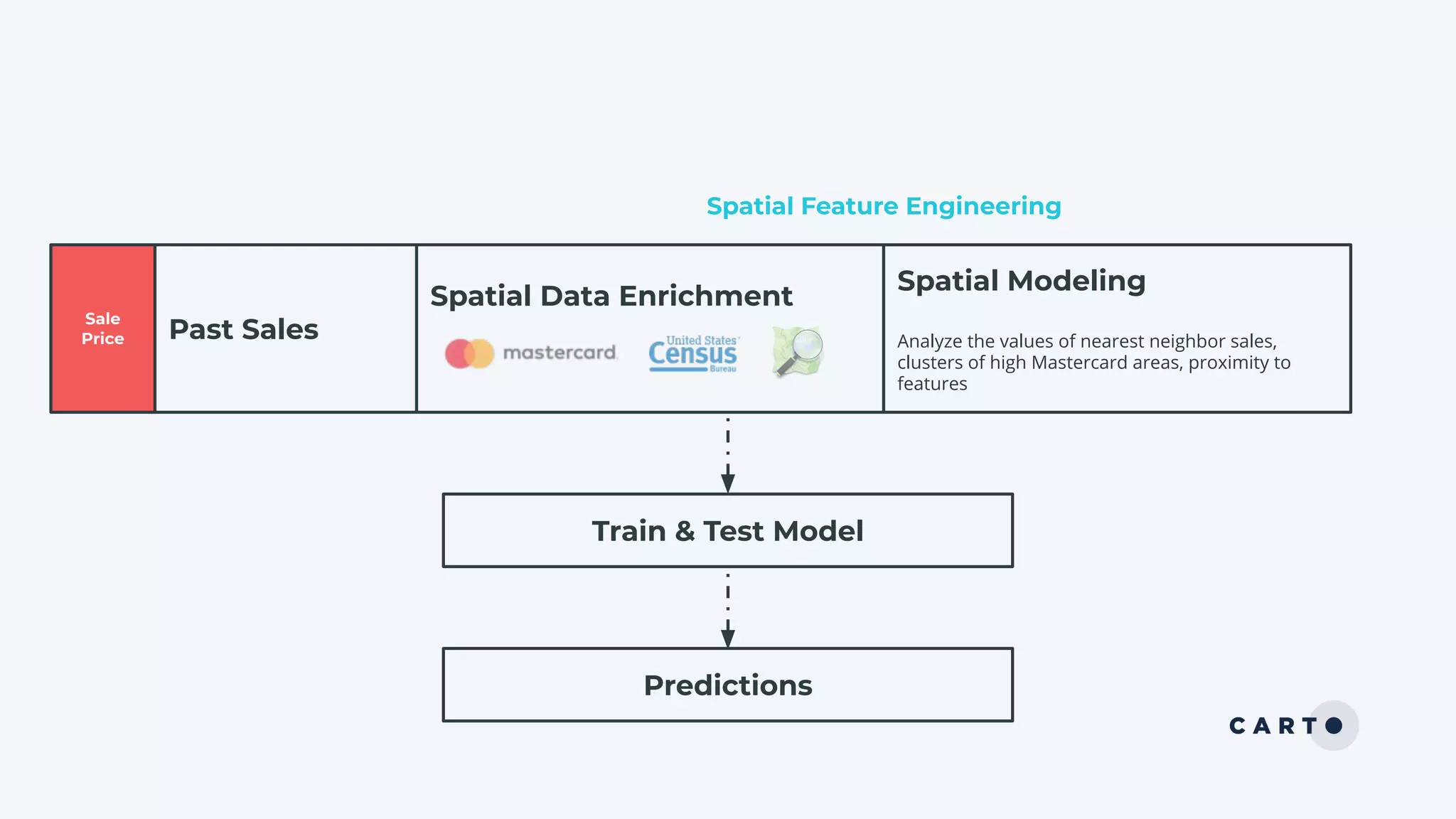

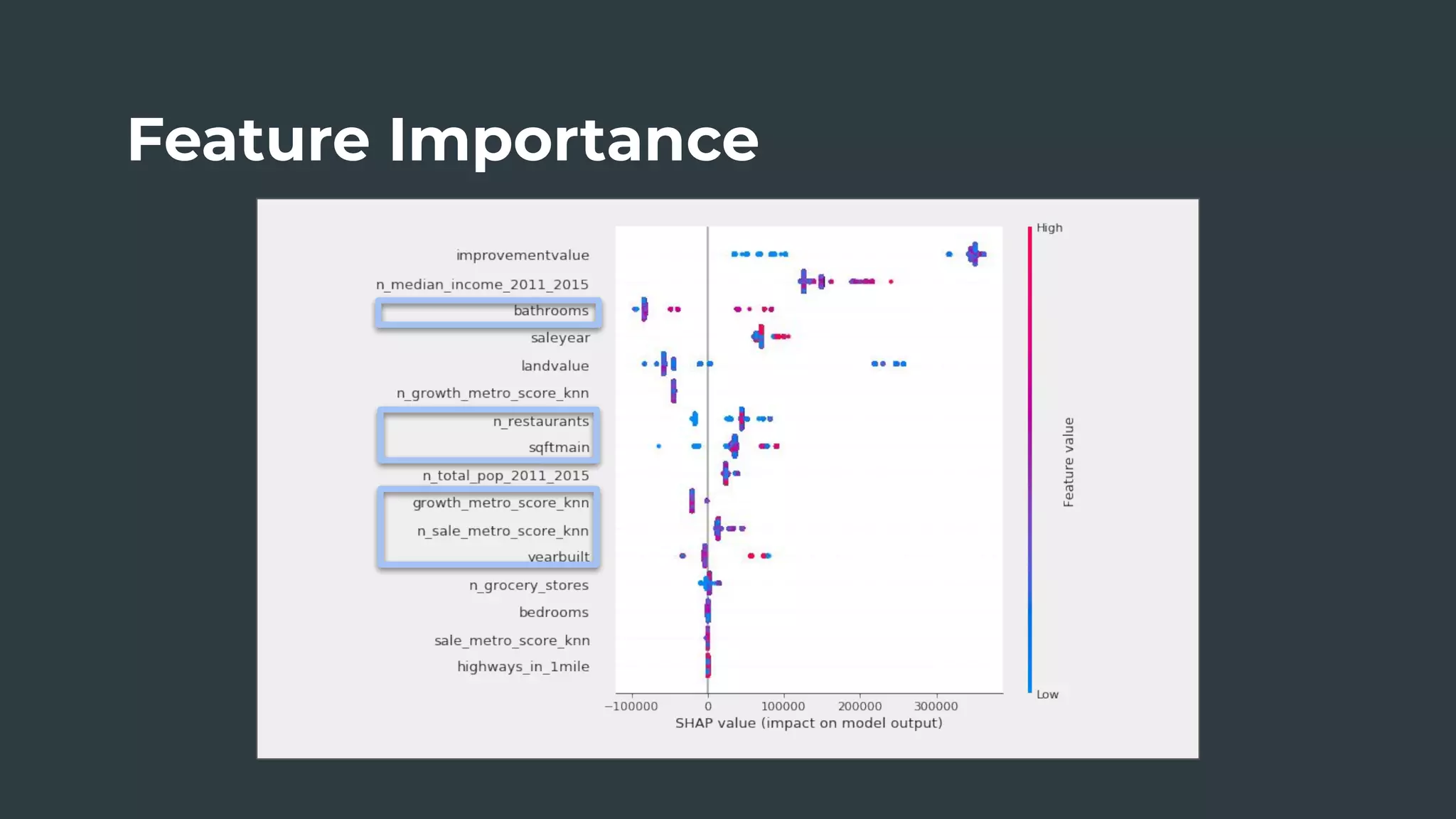


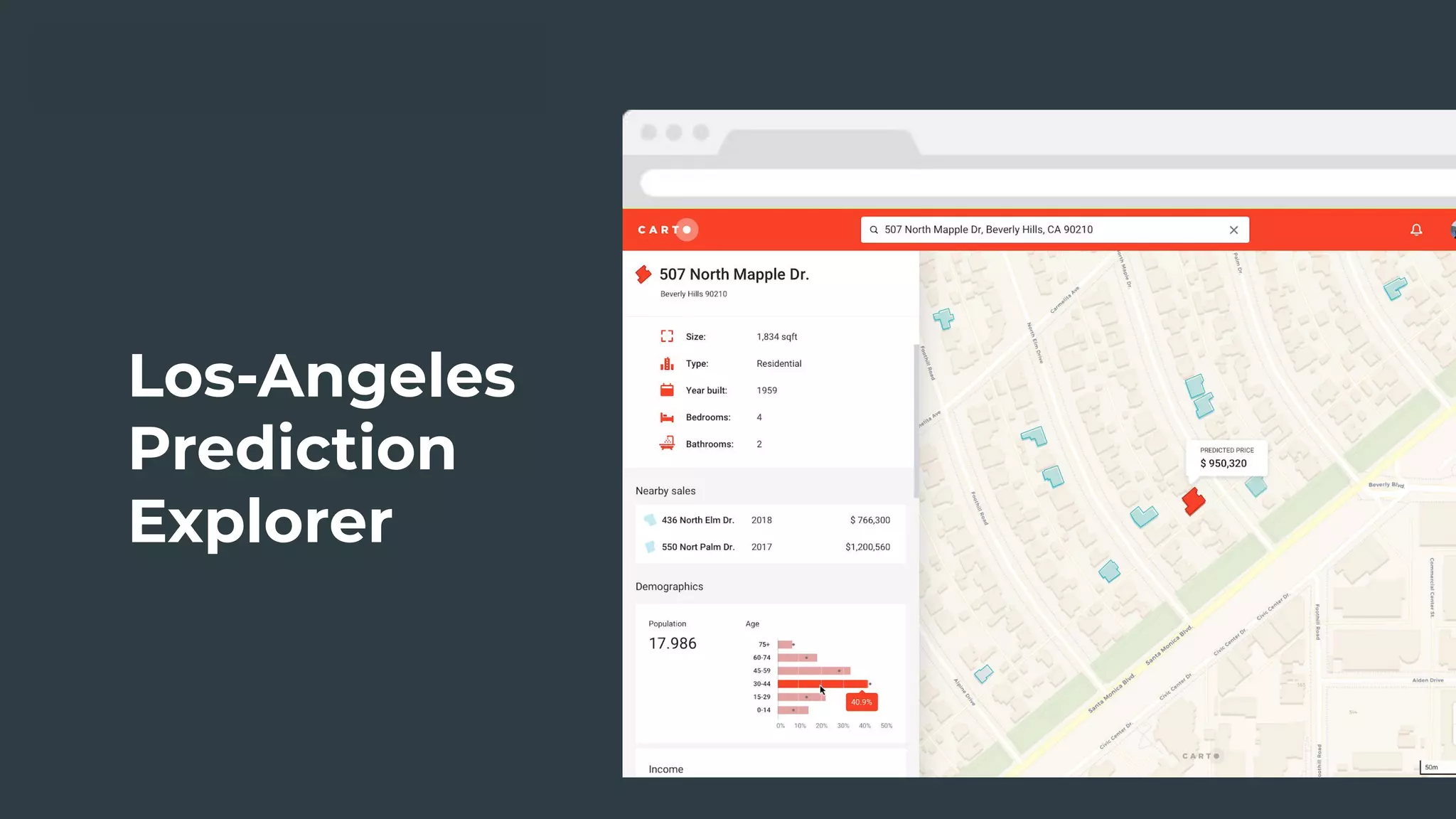





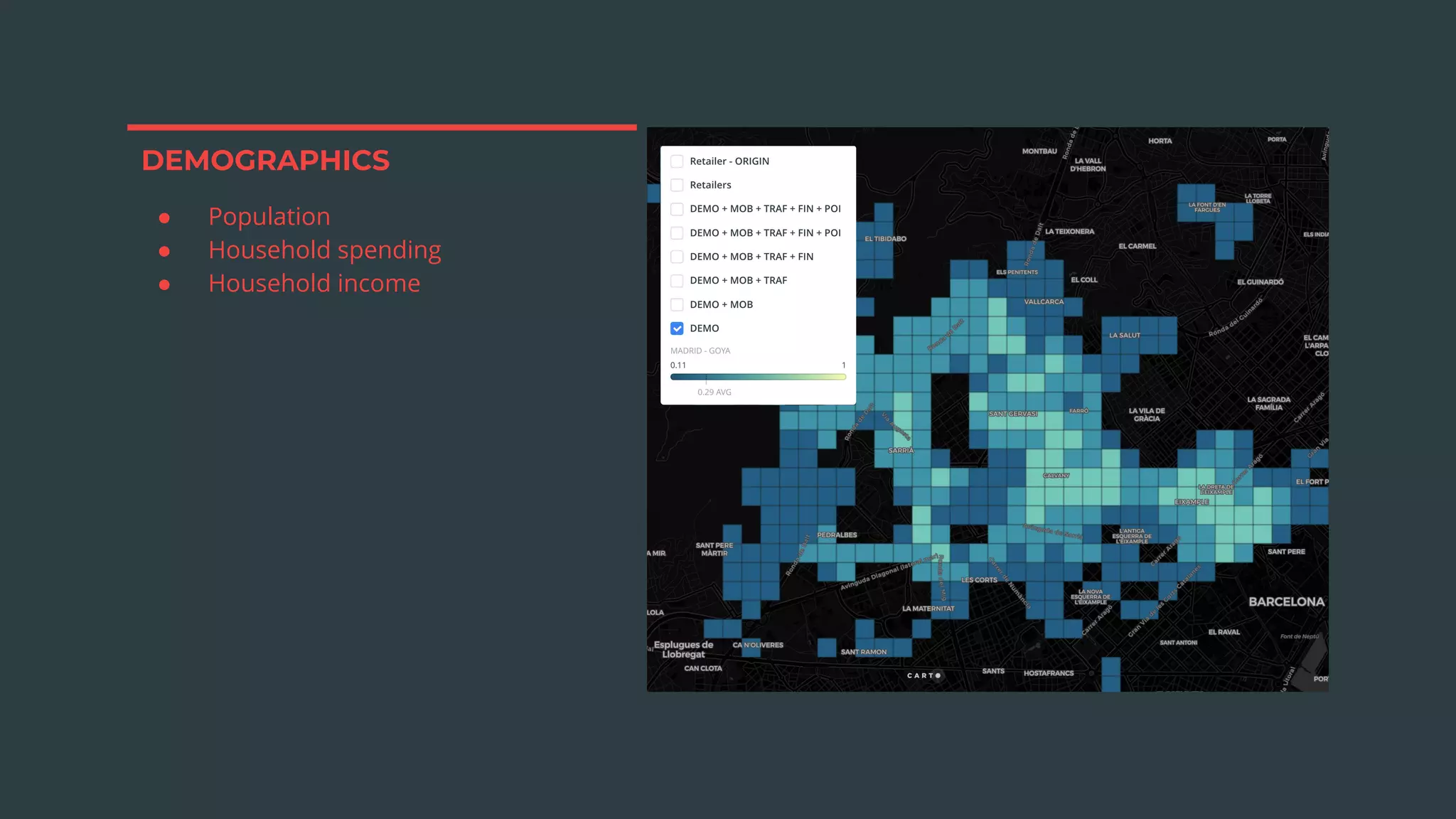
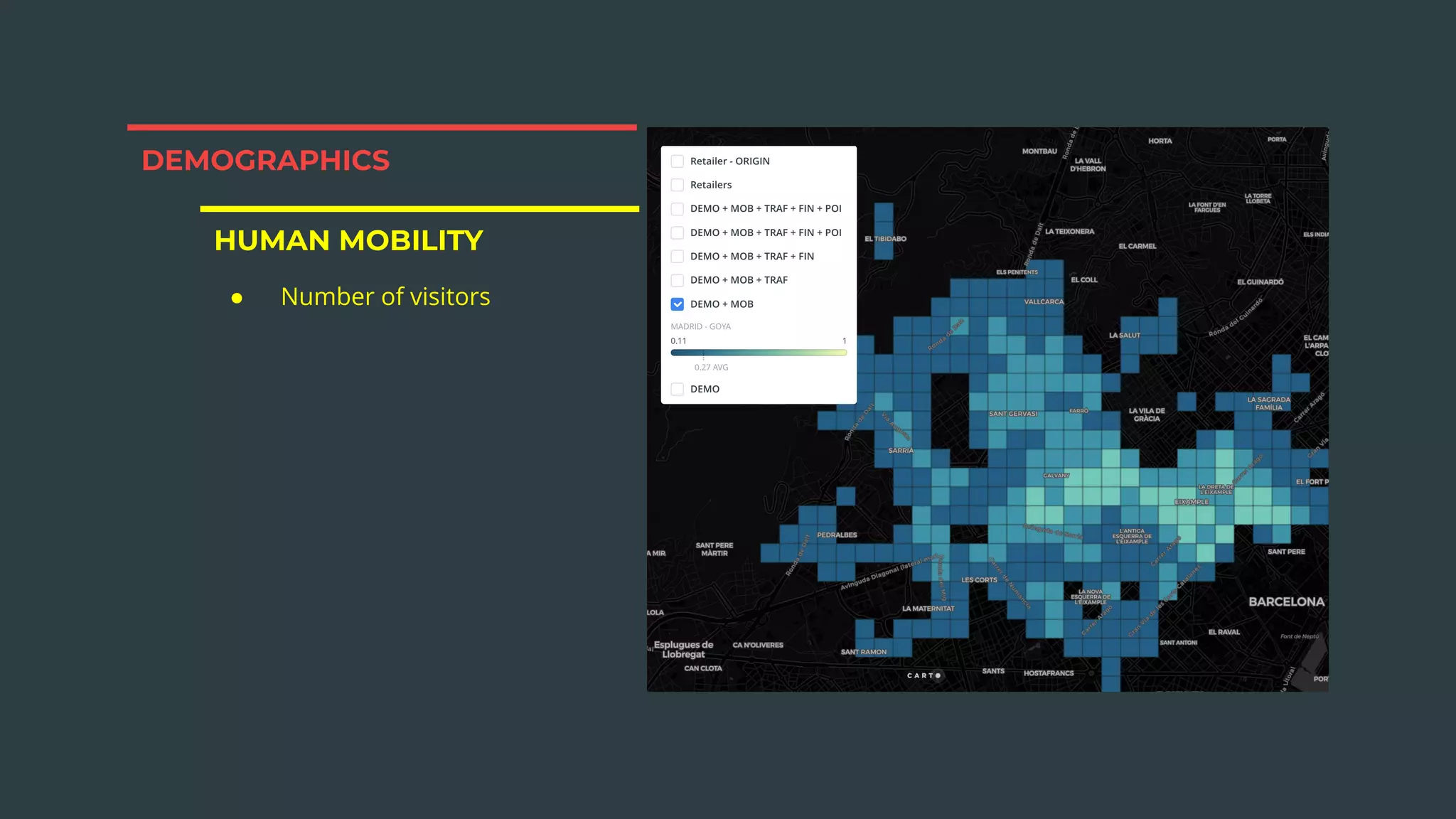
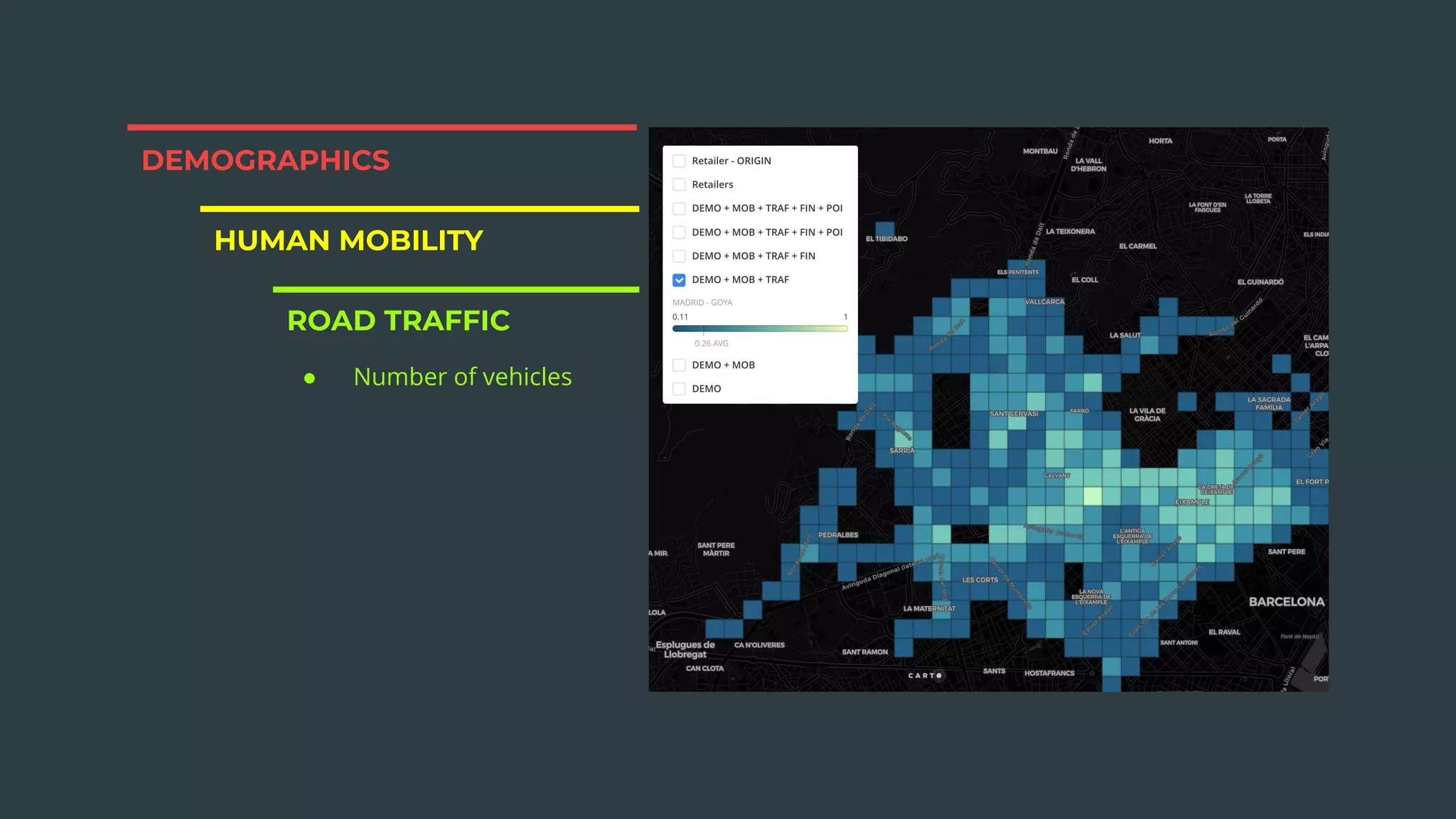
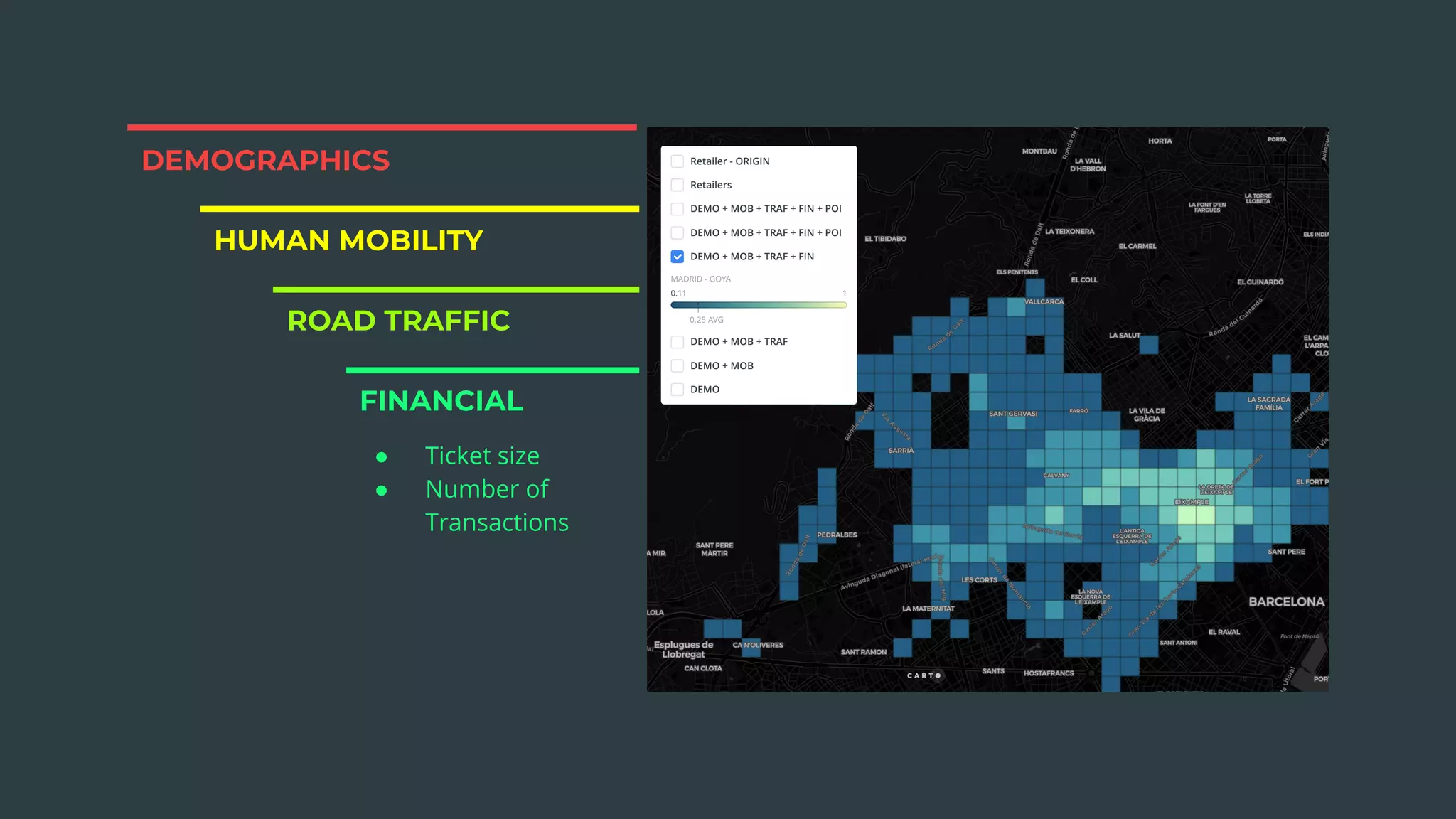
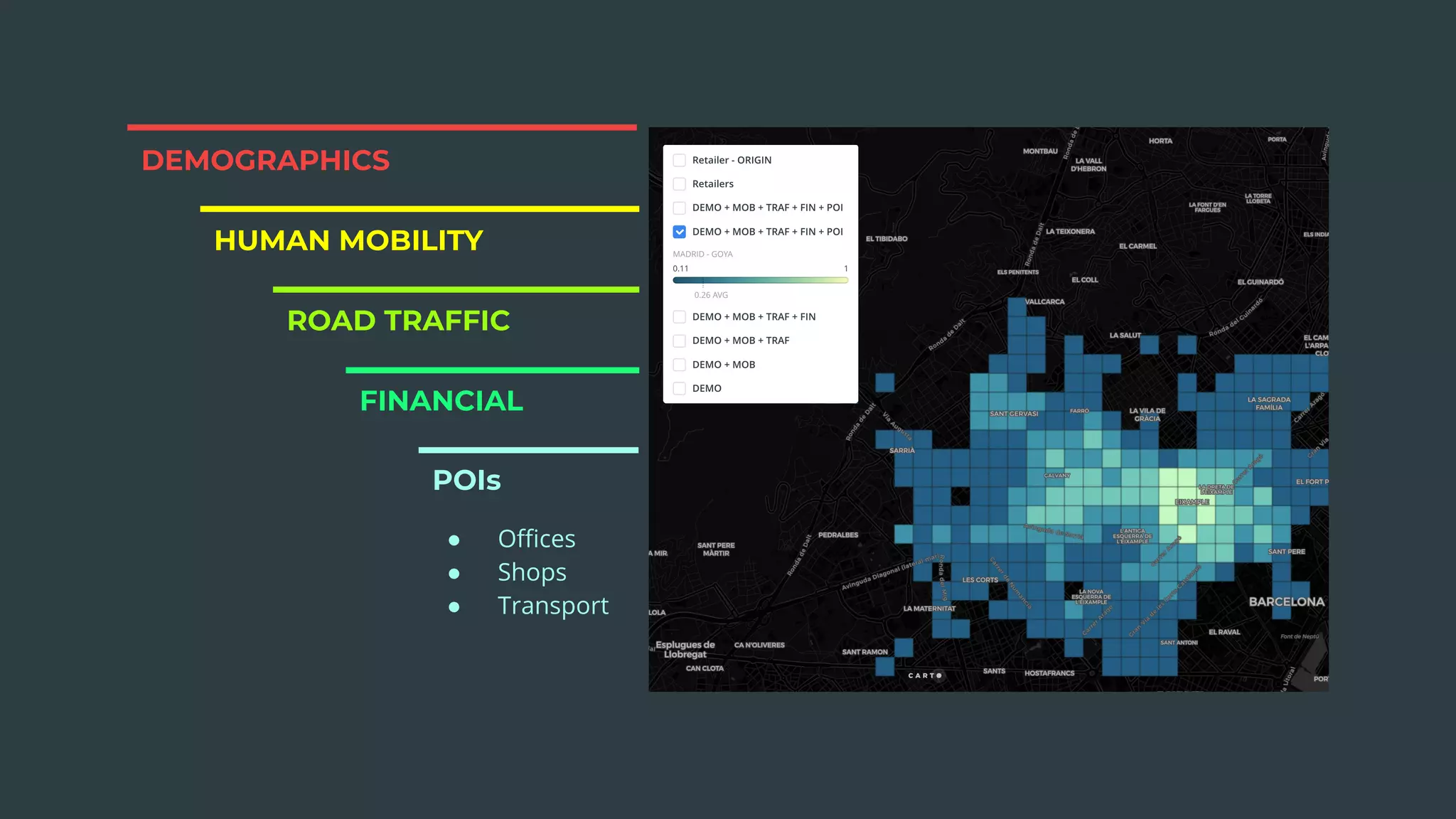




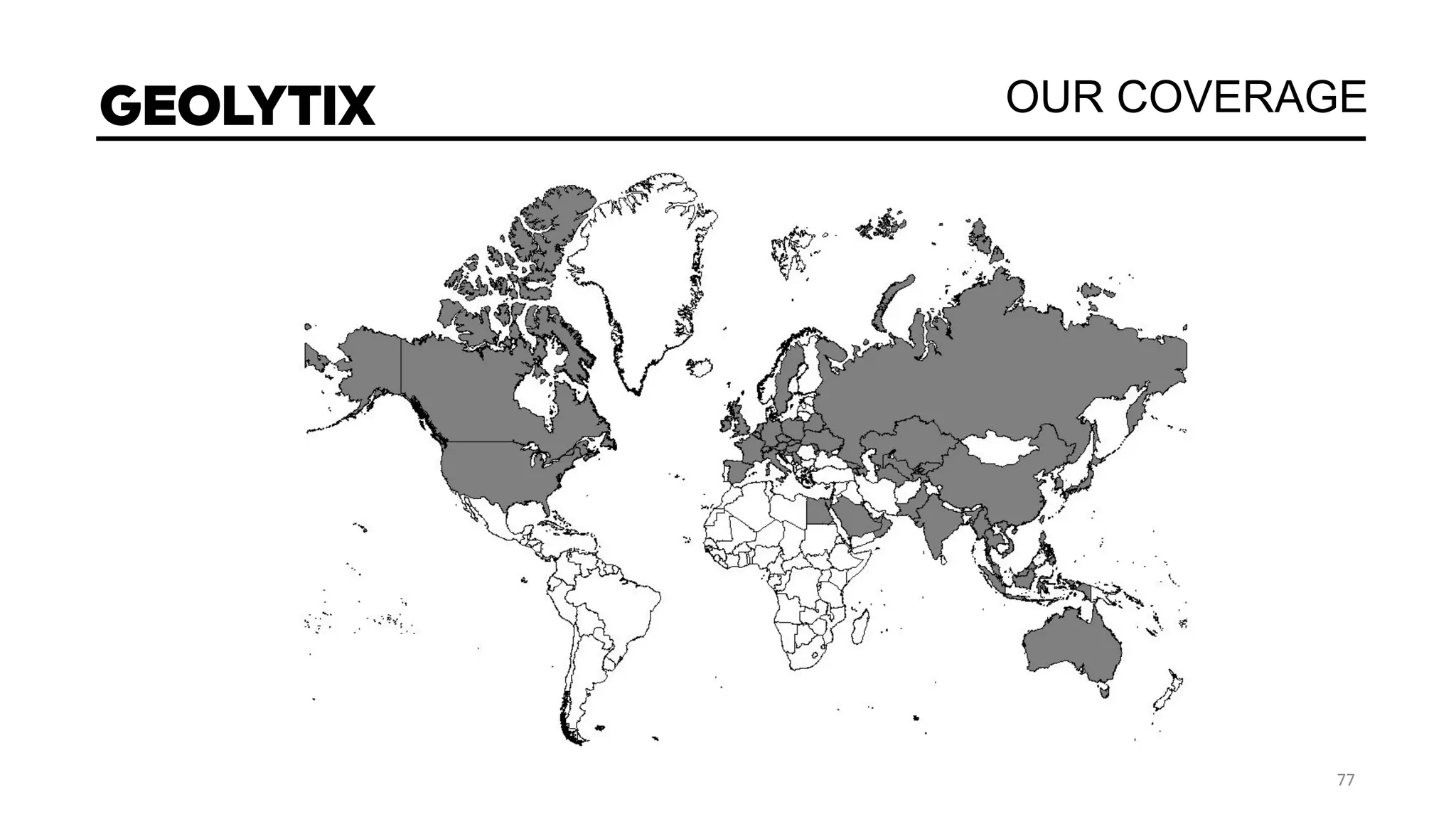


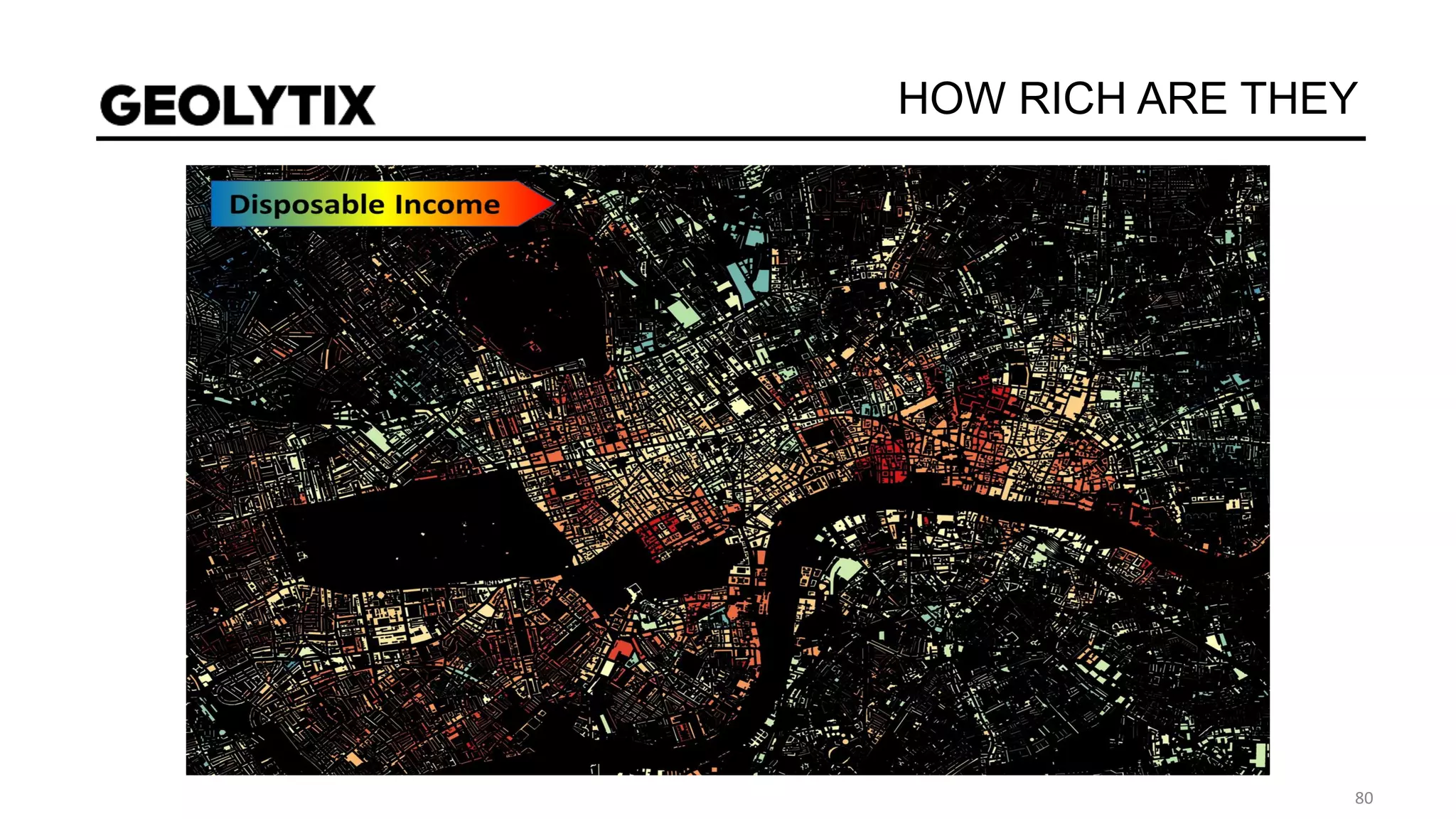












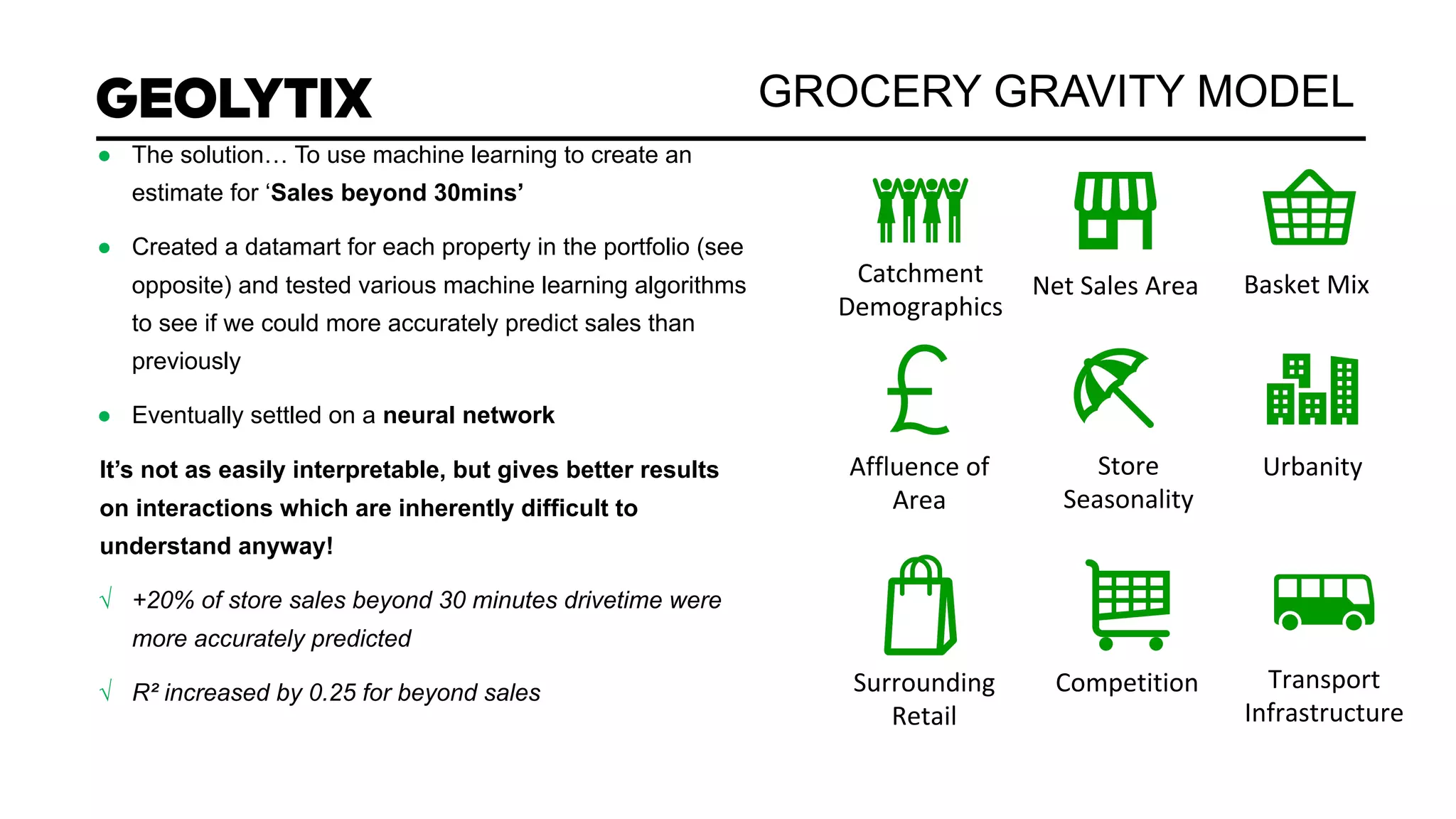









The document discusses a real estate meetup focused on spatial data science, highlighting its importance in various sectors such as investment analysis, site planning, and market analysis. It outlines the challenges in hiring data scientists with expertise in spatial analysis, preferred technologies, and the integration of spatial data into business workflows. Additionally, it provides a detailed case study on analyzing real estate sales in Los Angeles, demonstrating a comprehensive approach for data enrichment, predictive modeling, and the application of location intelligence.































![The Sum of our Parts: the Complete CARTO Journey [CARTO]](https://cdn.slidesharecdn.com/ss_thumbnails/recordedwebinarthesumofourpartsthecompletecartojourneydeck-190424092526-thumbnail.jpg?width=640&height=640&fit=bounds)


![CARTO en 5 Pasos: del Dato a la Toma de Decisiones [CARTO]](https://cdn.slidesharecdn.com/ss_thumbnails/cartoen5pasosdeldatoalatomadedecisionesrecordedwebinar-190508103941-thumbnail.jpg?width=640&height=640&fit=bounds)
![Unlock the power of spatial analysis using CARTO and python [CARTOframes]](https://cdn.slidesharecdn.com/ss_thumbnails/unlockthepowerofspatialanalysisusingcartoandpython-190927095046-thumbnail.jpg?width=640&height=640&fit=bounds)



![How to Use Spatial Data Science in your Site Planning Process? [CARTOframes]](https://cdn.slidesharecdn.com/ss_thumbnails/webinardeckhowtousespatialdatascienceinyoursiteplanning-190828105208-thumbnail.jpg?width=640&height=640&fit=bounds)















































