Downloaded 106 times





















![References
[1]D. Jurafsky and J. Martin, Speech and
language processing. Upper Saddle River,
N.J.: Pearson Prentice Hall, 2009.
[2]https://developers.google.com/machi
ne-learning/
[3]bunch of stackoverflow /
stackexchange / Kaggle threads
[4]bunch of Medium posts](https://image.slidesharecdn.com/textclassificationpresentation-190314064339/75/Text-Classification-27-2048.jpg)

The document outlines a research overview on text classification for Rax Studio, emphasizing natural language processing applications such as sentiment analysis and intent classification. It details the data preprocessing steps, feature extraction methods like one-hot encoding and word2vec, and various machine learning models including Naive Bayes and multilayer perceptron. Additionally, it suggests an implementation plan focused on email management and cleaning, with a framework for model updating and retraining.
Introduction to text classification by Russ M. Delos Santos, focusing on RAX Studio with a use case in account management through email.
Explains natural language processing (NLP) applications including sentiment analysis, intent classification, and topic labeling, used for processing human language.
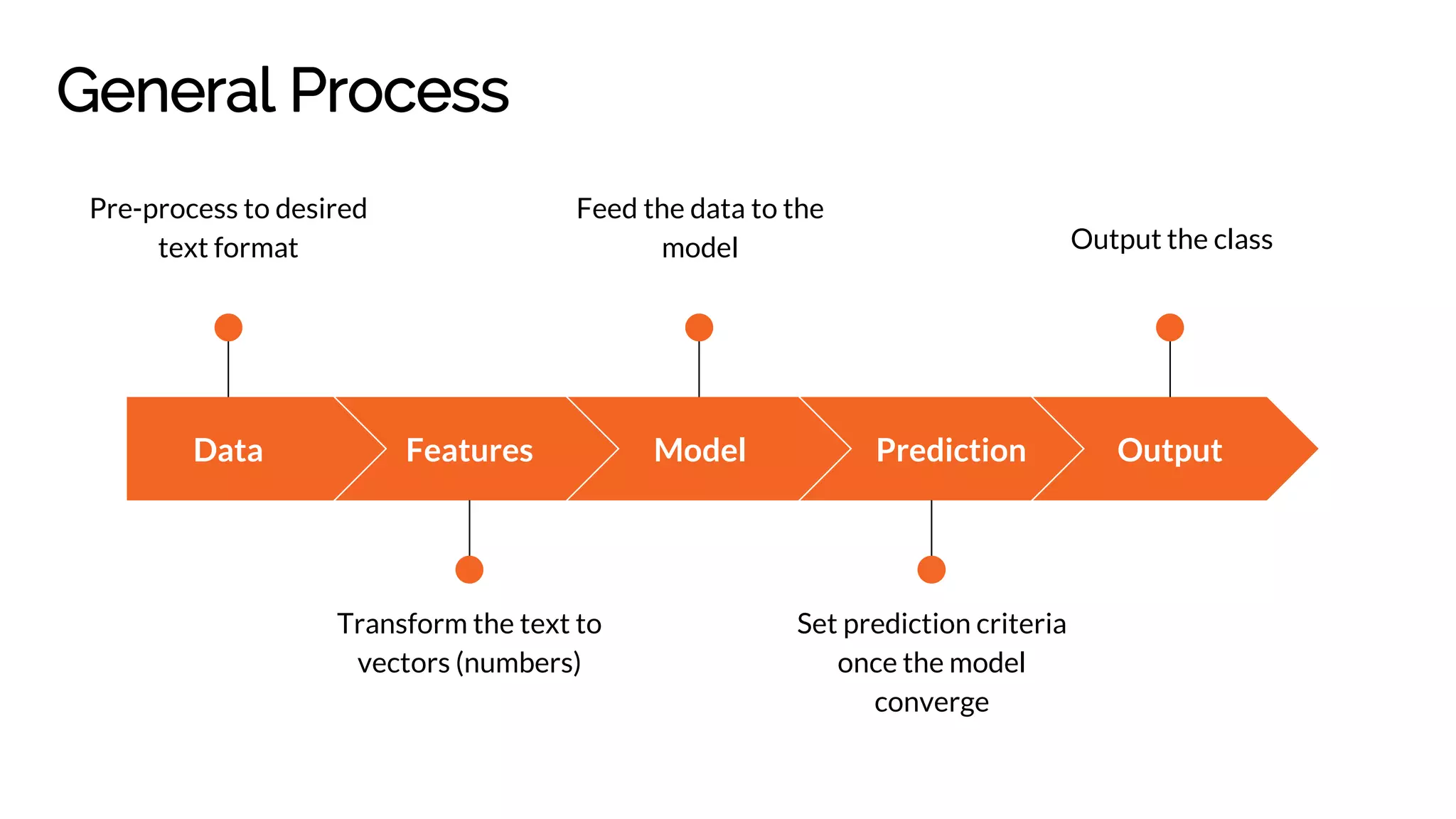
Describes steps in text classification: data preprocessing, feature transformation, model training, and prediction criteria setting.
Discusses datasets for model training, including open-source examples like Amazon Reviews and Enron Email Dataset; emphasizes preprocessing requirements.
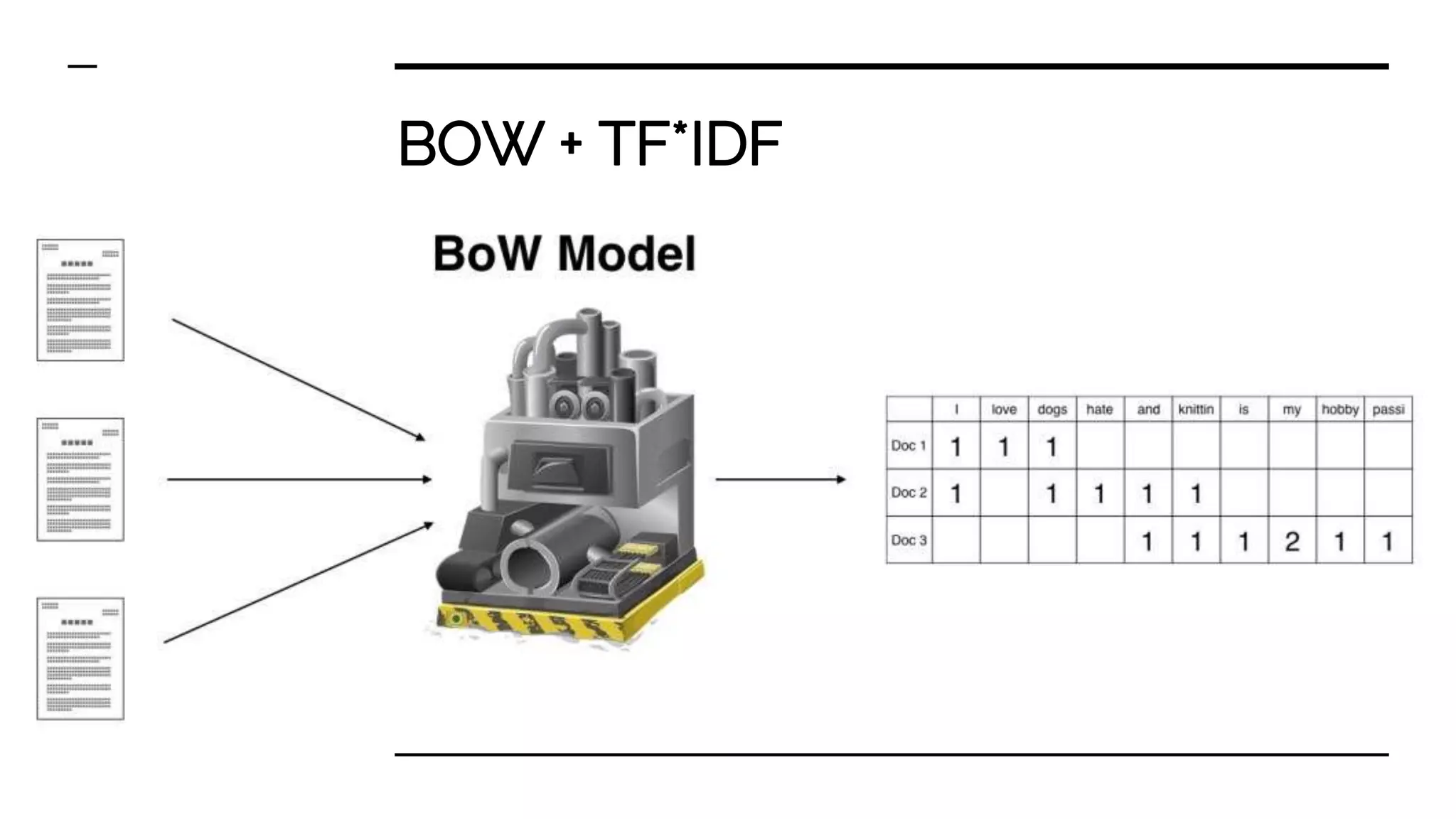
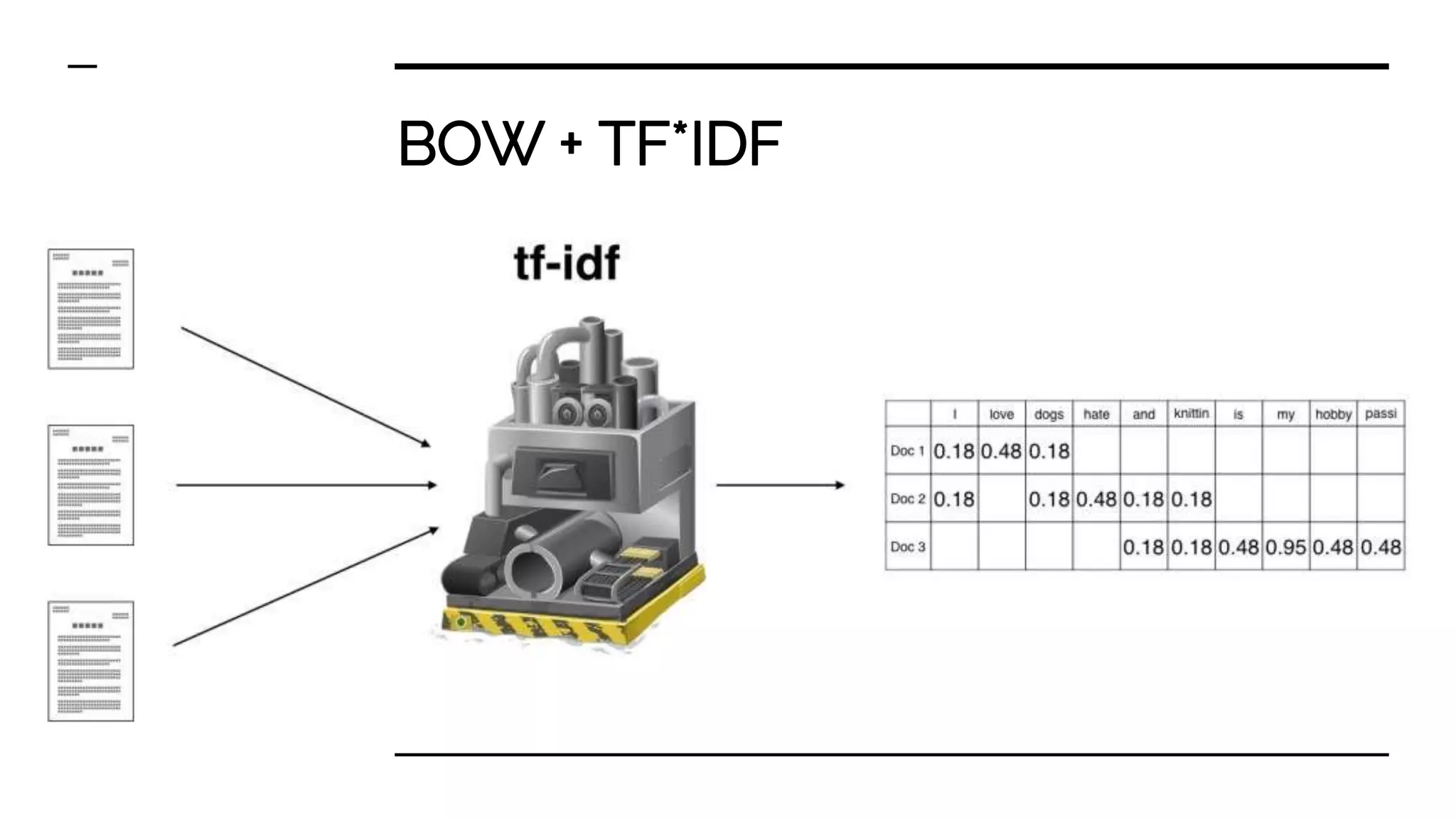
Various feature extraction methods transforming text to vector formats include One-hot encoding, Bag-of-words + TF*IDF, and word2vec.
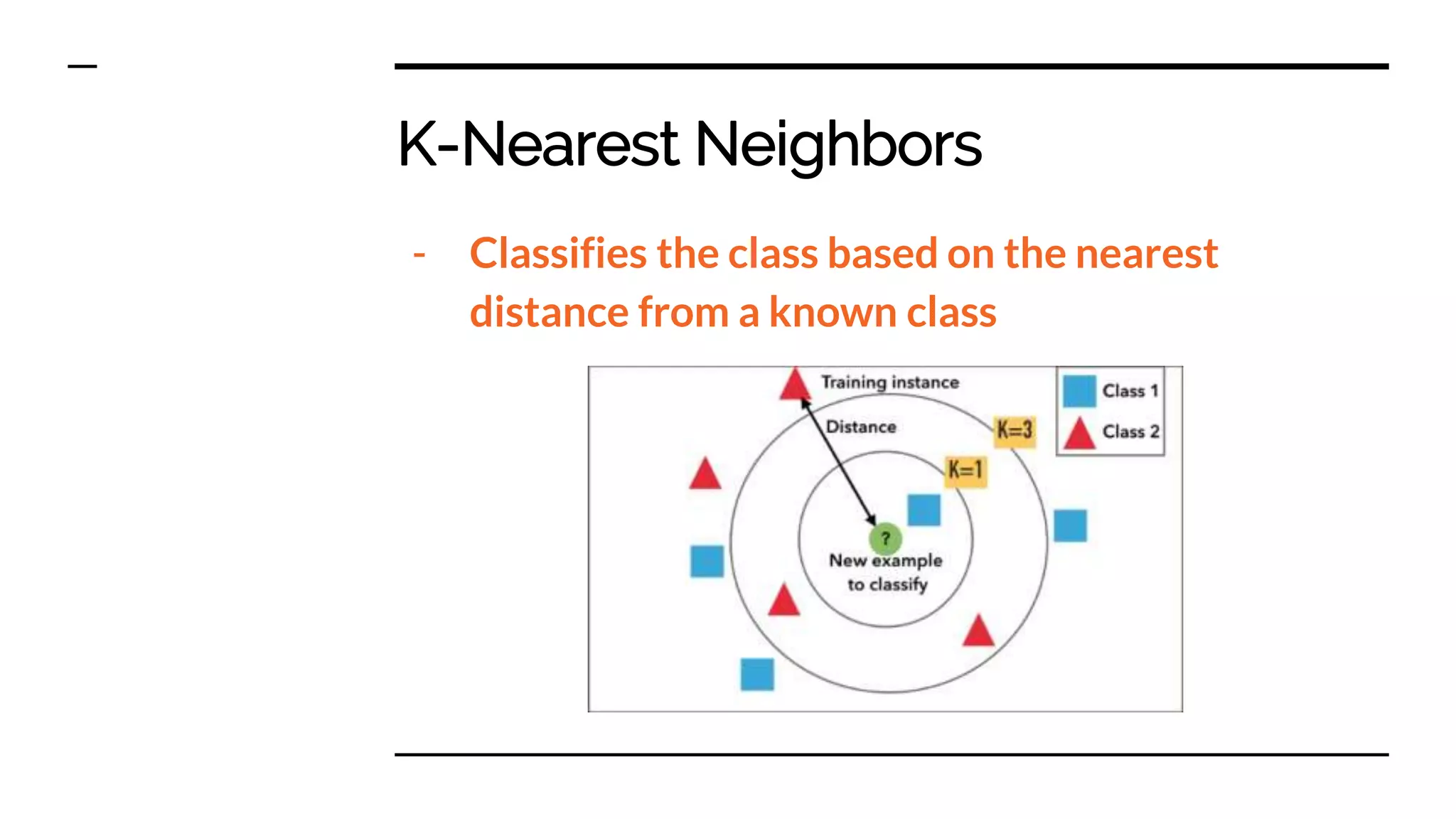
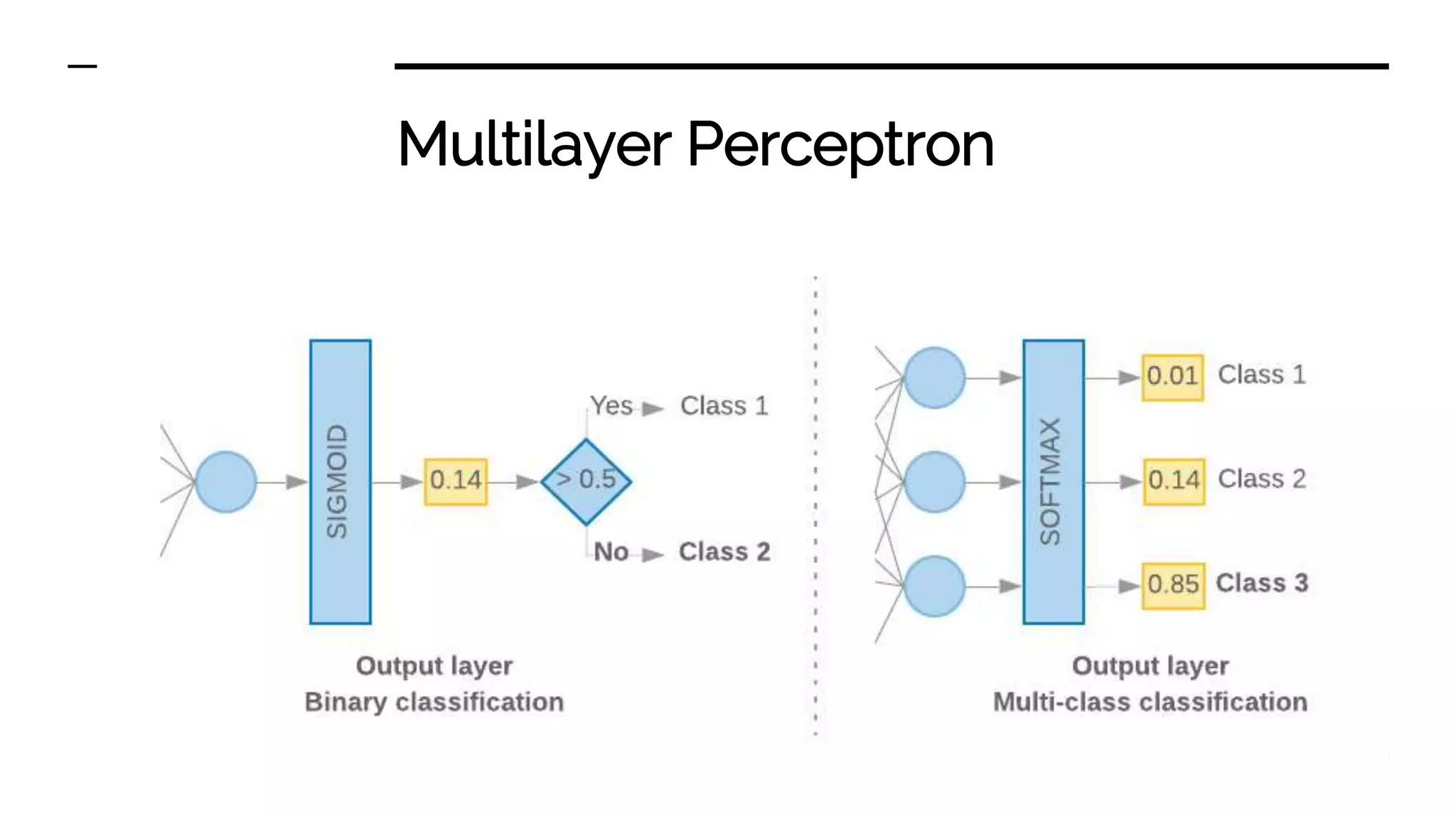
Overview of classifiers such as Naive Bayes, K-nearest neighbors, and Multilayer Perceptron, outlining their functions and applications.
Compares two assessment options for implementing text classification with pros and cons, focusing on different feature extraction methods and ML algorithms.
Highlights challenges like ML.NET Learning Curve, need for large labeled datasets, and impracticality of retraining models for every new word.
Outlines implementation for an email classifier, including data cleaning, standardization, feature extraction, and neural network setup.
Lists references for further reading on speech and language processing, Google machine learning resources, and various online discussions.


















































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

