Download to read offline

![International Journal of Computer Engineering and Technology (IJCET), ISSN 0976-6367(Print),
ISSN 0976 - 6375(Online), Volume 5, Issue 10, October (2014), pp. 51-56 © IAEME
Client applications update their local database copy by executing transactions against the database.
Each transaction consists of a series of one or more operations (insert, update, and delete).
52
Mobile Computing
Many modern mobile database systems operate while disconnected from the server. In such
systems, clients must explicitly synchronize their states. One way to do this is by asynchronously
exchanging updates in update files. Clients occasionally put together gathered updates into update
files, which are transmitted to a file server when a network connection is established. The server
regularly checks the file server for update files, and installs their contents into the database. The
server subsequently prepares more update files containing these changes for clients to download [2].
Figure 1 provides an overview of the occasionally connected database architecture. The
server maintains a database which contains the union of all client data. Let D be a data shared by
clients 1 and N. If Client 1 changes D, it applies the change to its local database and records the
change in its delta file. When Client 1 connects to the network, it sends its modified file which
records all changes at Client 1 since the last connection, including the change to D. The server
processes these changes against its own database and, since Client N also shares D, the server
records the change in a modified file destined for Client N. When Client N connects, it downloads
the modified file from the server, applying the changes to its database.
Figure 1: Occasional connected Database Architecture
Mobile database offers way in toward a huge amount of data in the course of mobile
communication. Mobile database capture data as well as access data anywhere you are.
Instantaneously gather, retrieve and evaluate significant data in spite of physical location.
Data-centric Database Sharing
With the occasionally connected database, the server maintains a database which contains the
union of all client data. The transactions constituting the updates made to a client's local database are
logged and propagated to the server database when the client connects. The data shared between the
server and some client X may also be shared with another client Y; therefore, changes to that data at
Client X should be reflected at Client Y. Since the clients are only occasionally connected and
cannot directly send changes to other clients, the server acts as a medium by forwarding updates to
data shared among multiple clients.
The major problem with the client centric approach is as the client population increases the
memory required is also increases, instead of client centric approach go for data centric[4] approach,
Instead of client centric approach go for data centric approach, in which the datagroup is generated
according to the data. The clients will subscribe to the datagroup according to their requirement as
shown in below figure 2. The advantage of data-centric approach includes server processing cost,
disk storage cost and transmission cost [4].](https://image.slidesharecdn.com/synchronizationandreplicationthroughocmdbs-141116233546-conversion-gate02/75/Synchronization-and-replication-through-ocmdbs-2-2048.jpg)
![International Journal of Computer Engineering and Technology (IJCET), ISSN 0976-6367(Print),
ISSN 0976 - 6375(Online), Volume 5, Issue 10, October (2014), pp. 51-56 © IAEME
The precise combination in use by the server very much effects the overall effectiveness of
the system. So to establish the preferred grouping, we have to know the information applicable to all
clients. We wish to design groups that increase the performance of the system. The creation of a
grouping speaks about to breakup design.
53
Grouping Estimate Approach
Without needing to ask, in circumstances with adequate data sharing, our data-centric
approach shows enhanced server performance above the client-centric approach; nevertheless, we do
not thus far know the extent of the performance enhancement. Clearly, the amount of server
enhancement depends on a large range of issues including the amount of shared data and the design
of database groups. The specific grouping employed by the server profoundly affects the overall
performance of the system. To determine the desired grouping, we need to know the data relevant to
each client.
Estimation algorithm, discussed in our previous work [3] deals with groups that reduce the
scalability-limiting redundancy created by the overlap between client data interests in the client-centric
approach. The creation of a grouping relates to breakup design and allocation in traditional
distributed databases. The groups should form a partition of the server database fragments. That is,
each segment should appear exactly once in the set of groups. This disjointness constraint may be
relaxed in further reorganization of groups. Formation of the groups should proceed by selection of
the larger sets of shared fragments, removing the fragments from the subscription of each client, and
repeating the process. These heuristics have profound effects. Grouping Estimate Algorithm is
accountable for identifying the set of shared clusters derived through increasing on both sides of tree
until sharing falls less than entry level.
Synchronization and Replication
Managing data in a mobile computing environment invariably involves replication. In many
cases, a mobile device has access only to data that is stored locally. Given portable devices with
limited resources, weak or intermittent connectivity, and security vulnerabilities, data replication
serves to increase availability, reduce communication costs, foster sharing, and enhance survivability
of critical information [1]. Let C1, C2, C3, C4 be primary copies of a group Cmain and C11 be a
secondary copy Csecond. Cmain represents the primary copy of data item Di and Csecond the secondary
copy data item Di. The most recently updated copy of two copies obtained is considered as Csecond.
The secondary copy is always the most recent copy.
Figure 2 shows the idea of Primary and Secondary copies. The groups hold the primary
copies of a given data item and the group maintain a temporary replica of this data item if the
replication plan determines that it is beneficial to store a copy.
Fig. 2: Primary and seccondary copies](https://image.slidesharecdn.com/synchronizationandreplicationthroughocmdbs-141116233546-conversion-gate02/75/Synchronization-and-replication-through-ocmdbs-3-2048.jpg)
![International Journal of Computer Engineering and Technology (IJCET), ISSN 0976-6367(Print),
ISSN 0976 - 6375(Online), Volume 5, Issue 10, October (2014), pp. 51-56 © IAEME
As shown in following figure 3, the replication process is divided into two components. The
first one illustrates the replication among mobile clients, which disconnect after getting the data. In
the second component mobile units forever stay online. The resulting replica set is then copied to the
mobile unit. After that, the change of the data is likely on the database server as well as on the
mobile client. In particular among off-line operational mobile clients, updating causes inconsistent
data. This means that different version of data may occur. Hence, mobile clients and database servers
must synchronize with each other.
Figure 3: Replication process in mobile environment
In client-oriented replication we have two situations, online and offline. The replication
schema is firstly generated through the administrator and describes the subdivision of the source
database schema, which is noticeable to whole mobile clients for future replica definition. Definition
of replication and synchronization of bring up-to-date information are online events. The transactions
on the mobile client are processed offline and have to be reapplied to the server database at the time
of synchronization.
As synchronizing among a device and a database server, there are quite a few problems so as
to make this a different problem from replicating between client or server [5]. One of the main issues
is, because of the storage constraints on the device, the data that is synchronized tends to be a subset,
or working set of the full database. We focus on mobile database synchronization performance.
Mobile database clients carry a subset of the centralized enterprise database, and can manipulate
their Synchronization is the method of building uniformity. Our aim is to connect occasionally the
applications that synchronize with the back-end database.
Step1. Initialize the locks obtained on the number of groups = 0 (zero);
Step2. Identify and find the number of groups (NGi) belonging to the Di
Step3. Repeat from step3 through step5 FOR each group
Step4. Request a lock on Di at the group
Step5. Increment by 1 locks obtained on the number of groups
Step6. IF locks obtained on the number of groups = ((NGi/2) + 1) then go to next step otherwise
54
go to step9
Step7. Update/Write to the ((NGi/2) + 1) groups
Step8. Commit T
Step9. If majority locks are not obtained then
Step10. Abandon T
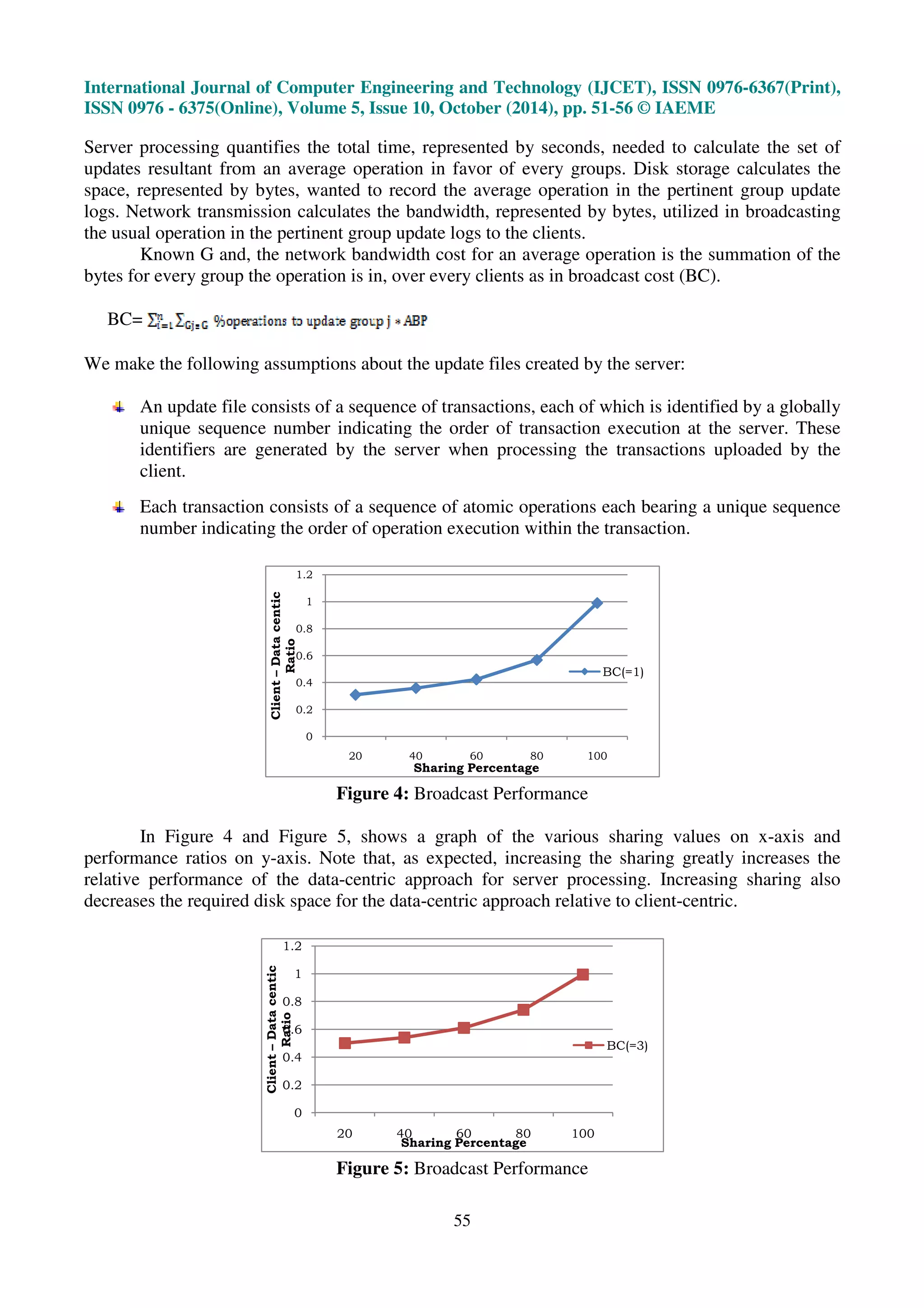
Background and Experimental Work
Consider the cost issues in assessing the performance of a specific grouping: server
processing, broadcast cost, and server storage. Calculate these costs on an average per-operation.](https://image.slidesharecdn.com/synchronizationandreplicationthroughocmdbs-141116233546-conversion-gate02/75/Synchronization-and-replication-through-ocmdbs-4-2048.jpg)
![International Journal of Computer Engineering and Technology (IJCET), ISSN 0976-6367(Print),
ISSN 0976 - 6375(Online), Volume 5, Issue 10, October (2014), pp. 51-56 © IAEME
56
CONCLUSIONS
Our experiments are designed to show the relative performance in terms of transmission costs
with respect to the data-centric groupings with necessary replication. Optimistic replication is
particularly appropriate on the way to surroundings where mobile devices are often disconnected.
Mobile storage schemes employ optimistic replication, OSMDB systems permits clients to replicate
a database on a mobile device, change it though being detached, and afterward combine the changes
among any other device that the user manages to communicate with. We propose in this paper, and
the client- centric grouping that is performed in commercial OSDBs with respect to increasing
degrees of interclient data sharing. Intuitively, we know that the data-centric approach performs best
when all clients share the same data and not that worst though there is no sharing. It is also
interesting to note that even with an overall sharing of data is almost zero; data-centric still performs
better than client centric for processing. This is because of the grouping, which saves significantly on
server processing. Our data-centric approach improves server resources difficulty by rearranging
client subscriptions into data-groups rather than make available to individual clients.
ACKNOWLEDGEMENTS
The first author articulates his gratefulness to Management of CBIT, and Dr. B. Chenna
Kesava. Rao, Principal, CBIT for their support and assistance and also takes the occasion to express
gratitude to Dr. Y Rama Devi, Professor and Head, Dept. of CSE, CBIT for her support.
REFERENCES
[1] China Ramu, S and Premchand, P, 2014: Dealing Synchronization with Occasionally
Connected Mobile Databases- International Journal of Recent Scientific Research, Vol. 5,
Issue, 2, pp.513-517.
[2] Grenoble, France, 2005: Data Replication and Consistency in Mobile Environments 2nd
International Doctoral Symposium on Middleware ’05 ACM.
[3] Liu, P. and Hsieh, Y, 2005: A study based on the value system for the interaction of the multi-tiered
supply chain under the trend of e-business. In Proceedings of the 7th international
Conference on Electronic Commerce, ICEC '05, vol. 113. ACM Press, New York, NY,
385-392.
[4] Christoph Gollmick, 2003: Replication in Mobile Database Environments: A Client-Oriented
Approach, International Workshop on Database and Expert Systems Applications, IEEE.
[5] China Ramu S. and Dr. Premchand P., 2014: Synchronization with Occasionally Connected
Mobile Databases- International Journal of Current Research, Vol. 6, Issue, 01,
pp. 4754-4756.
[6] M. Pushpalatha, T. Ramarao, Revathi Venkataraman and Sorna Lakshmi, “Mobility Aware
Data Replication using Minimum Dominating Set in Mobile Ad Hoc Networks”, International
Journal of Computer Engineering Technology (IJCET), Volume 3, Issue 2, 2012,
pp. 645 - 658, ISSN Print: 0976 – 6367, ISSN Online: 0976 – 6375.](https://image.slidesharecdn.com/synchronizationandreplicationthroughocmdbs-141116233546-conversion-gate02/75/Synchronization-and-replication-through-ocmdbs-6-2048.jpg)

This document discusses synchronization and replication in occasionally connected mobile database systems. It begins by describing the architecture of such systems, where mobile clients maintain local copies of shared data and synchronize with a central server when reconnected. It then discusses using a data-centric approach where data is grouped and clients subscribe to relevant groups. The document proposes a grouping estimation algorithm to determine optimal data groupings. Finally, it describes how primary and secondary copies are used for replication among clients and servers, and the need for synchronization when clients operate offline.
![[IJET V2I5P18] Authors:Pooja Mangla, Dr. Sandip Kumar Goyal](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i5p18-161107144130-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[KB캠퍼스스타] 팔방미인_일념통암](https://cdn.slidesharecdn.com/ss_thumbnails/finalno320141118-141117201455-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)



