









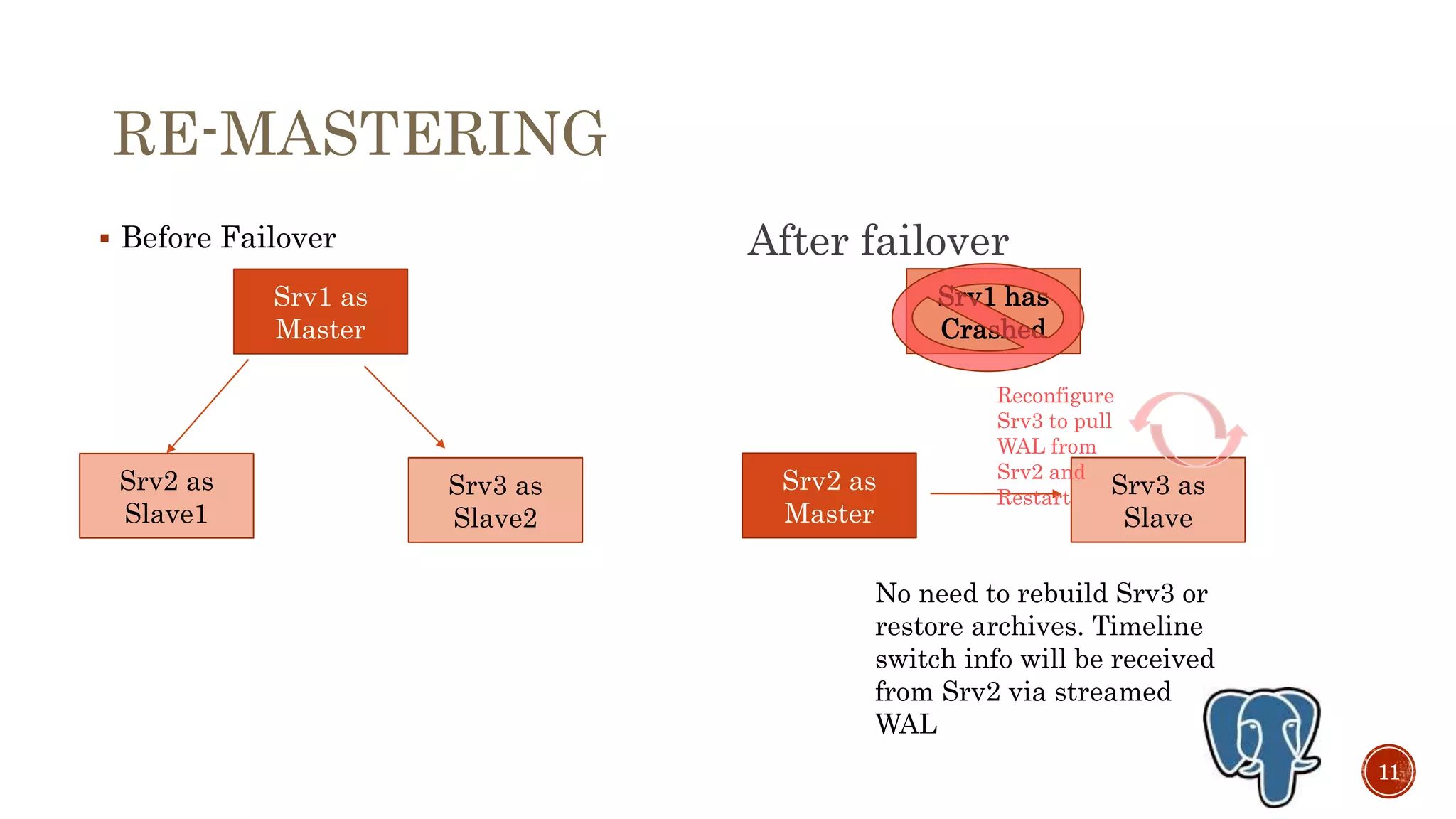




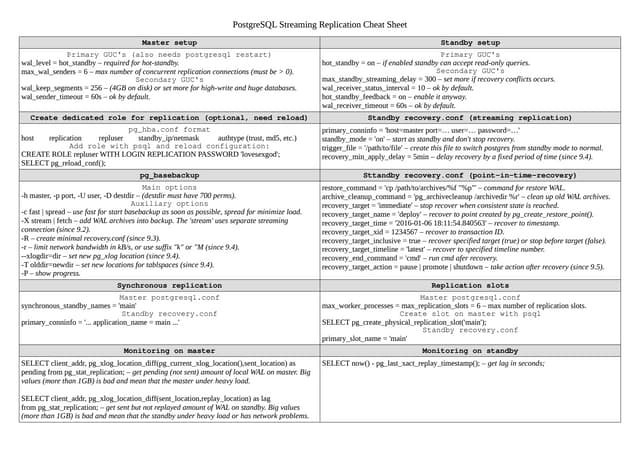
This document discusses setting up streaming replication in PostgreSQL v9.3 to enable high availability. It covers preparing primary and standby servers, configuring wal_level and max_wal_senders on the primary, taking a backup and restoring on the standby, creating a recovery.conf file, starting the servers to test replication, triggering failover by promoting the standby, handling multiple replicas without rebuilding, and rebuilding the original primary as a new standby. Monitoring replication status is also addressed using views like pg_stat_replication.
























































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
