Download as PDF, PPTX












![Case 1. Predicting the d-band centers
!18
Guest
Host
Ruban, Hammer, Stoltze, Skriver, Nørskov, J Mol Catal A, 115:421-429 (1997)
J. K. Nørskov, et al., Advances in Catalysis, 2000
Host
Guest
Two types of models
• 1% doped
• overlayer
[1% doped]
The d-bands of
transition metals
play central roles.](https://image.slidesharecdn.com/icredd-jst20190918-190926143856/75/2019-9-19-2048.jpg)
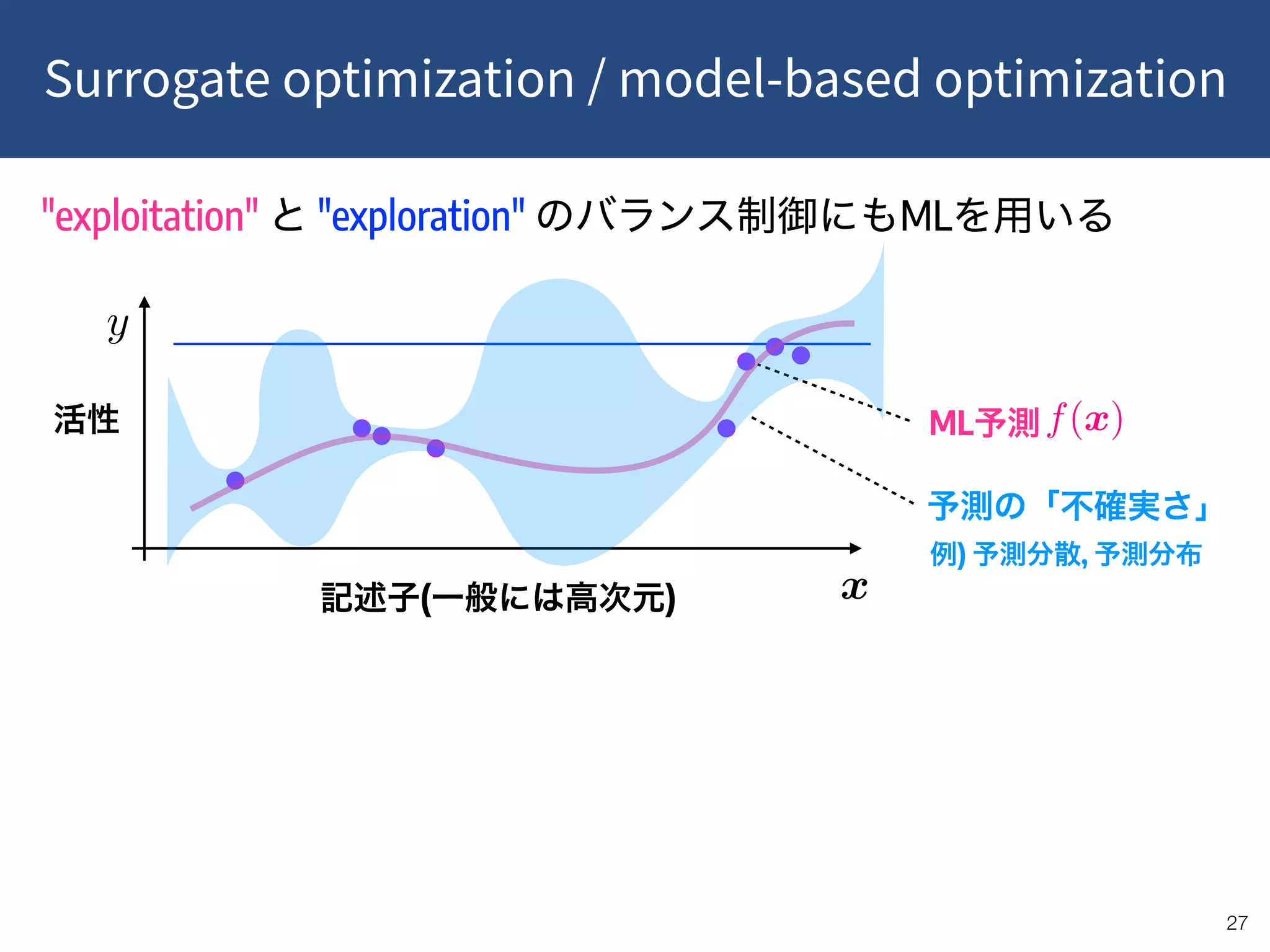
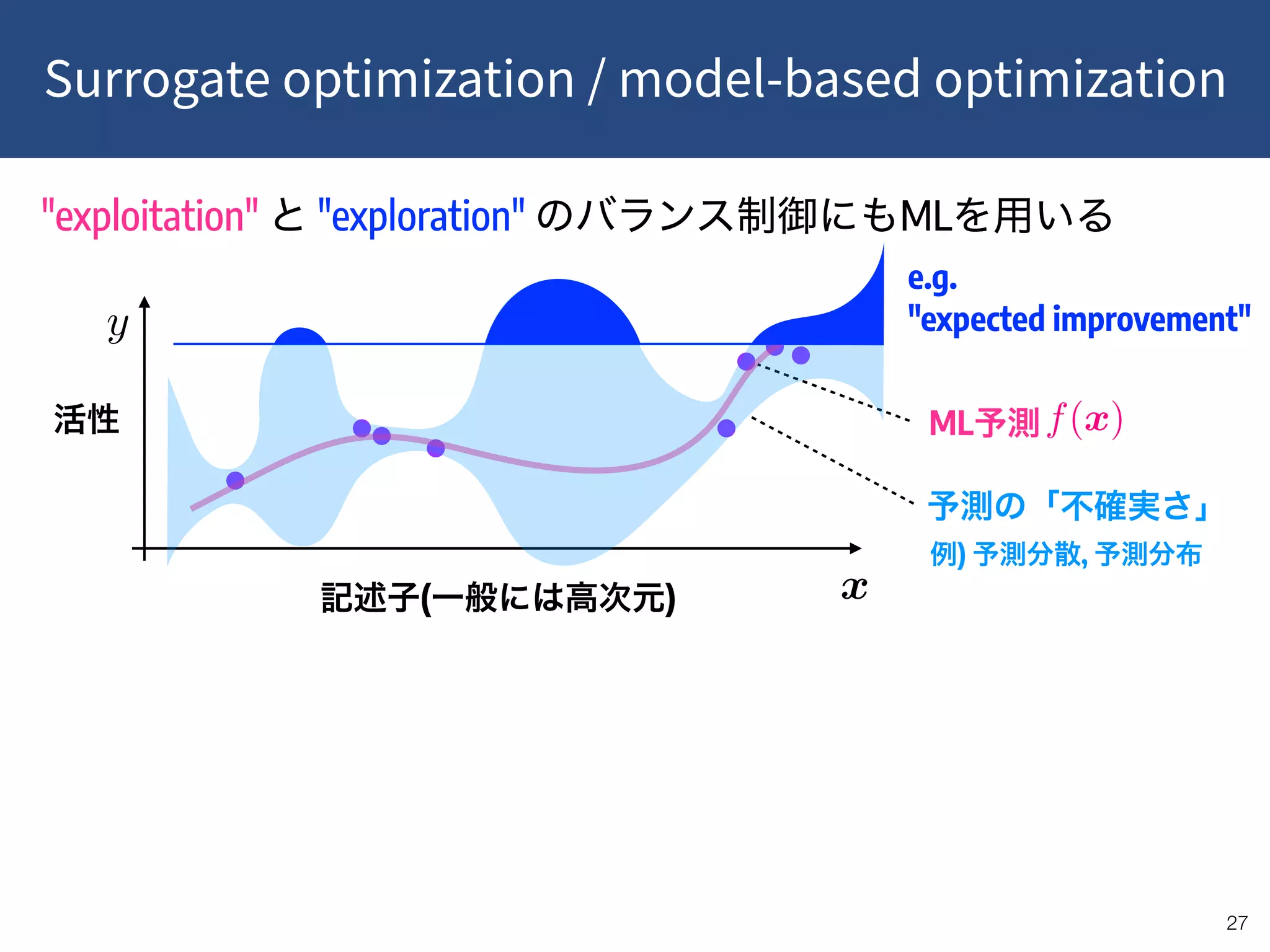
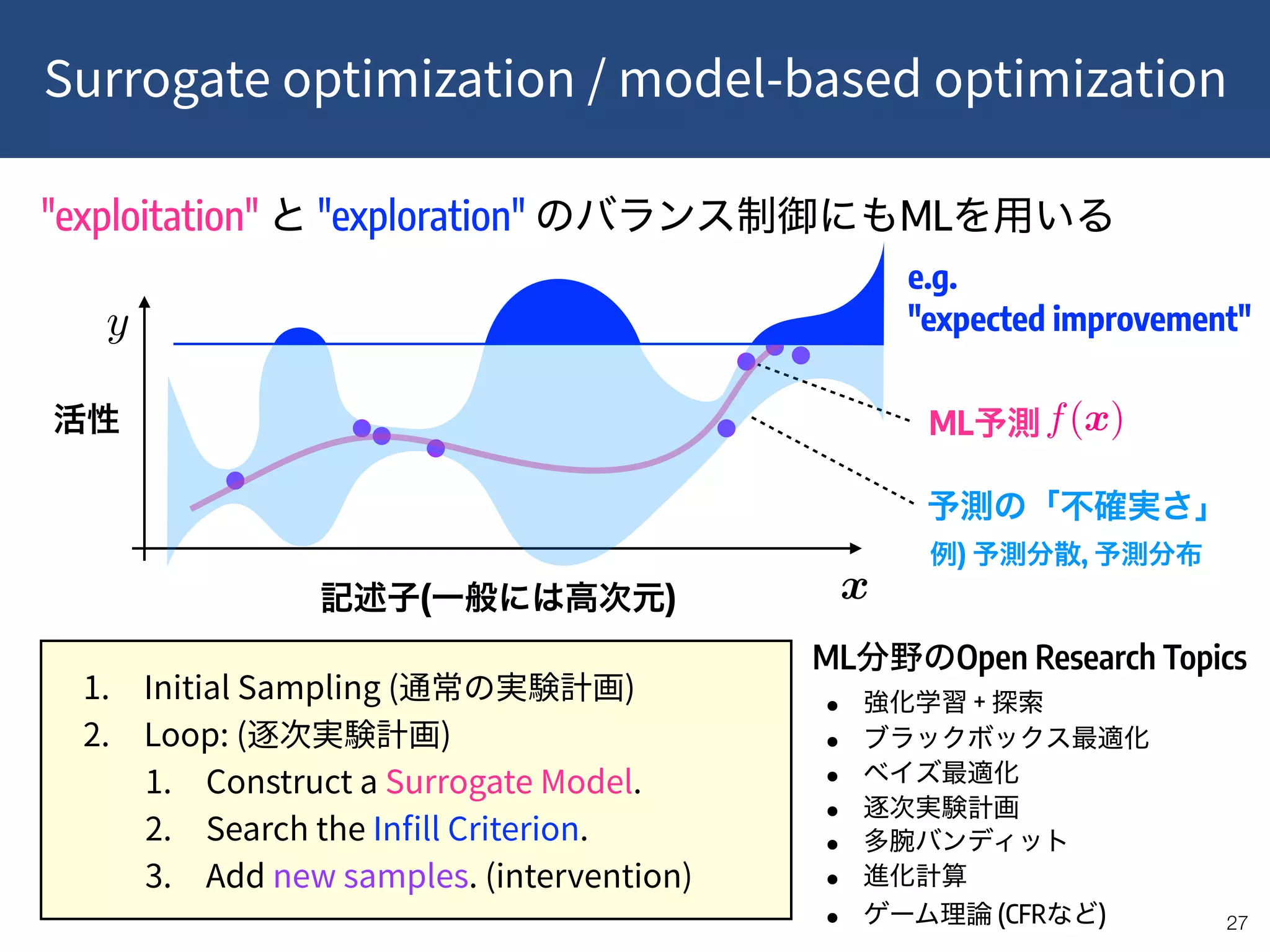



![!32
• 1833 catalysts
Oxidative coupling of methane (OCM)
[Zavyalova+ 2011]
• 4185 catalysts
Water gas shift reaction (WGS)
[Odabaşi+ 2014]
• 5567 catalysts
CO oxidation [Günay+ 2013]
Our model
GPR-based BO
Random
(OCM )](https://image.slidesharecdn.com/icredd-jst20190918-190926143856/75/2019-9-37-2048.jpg)

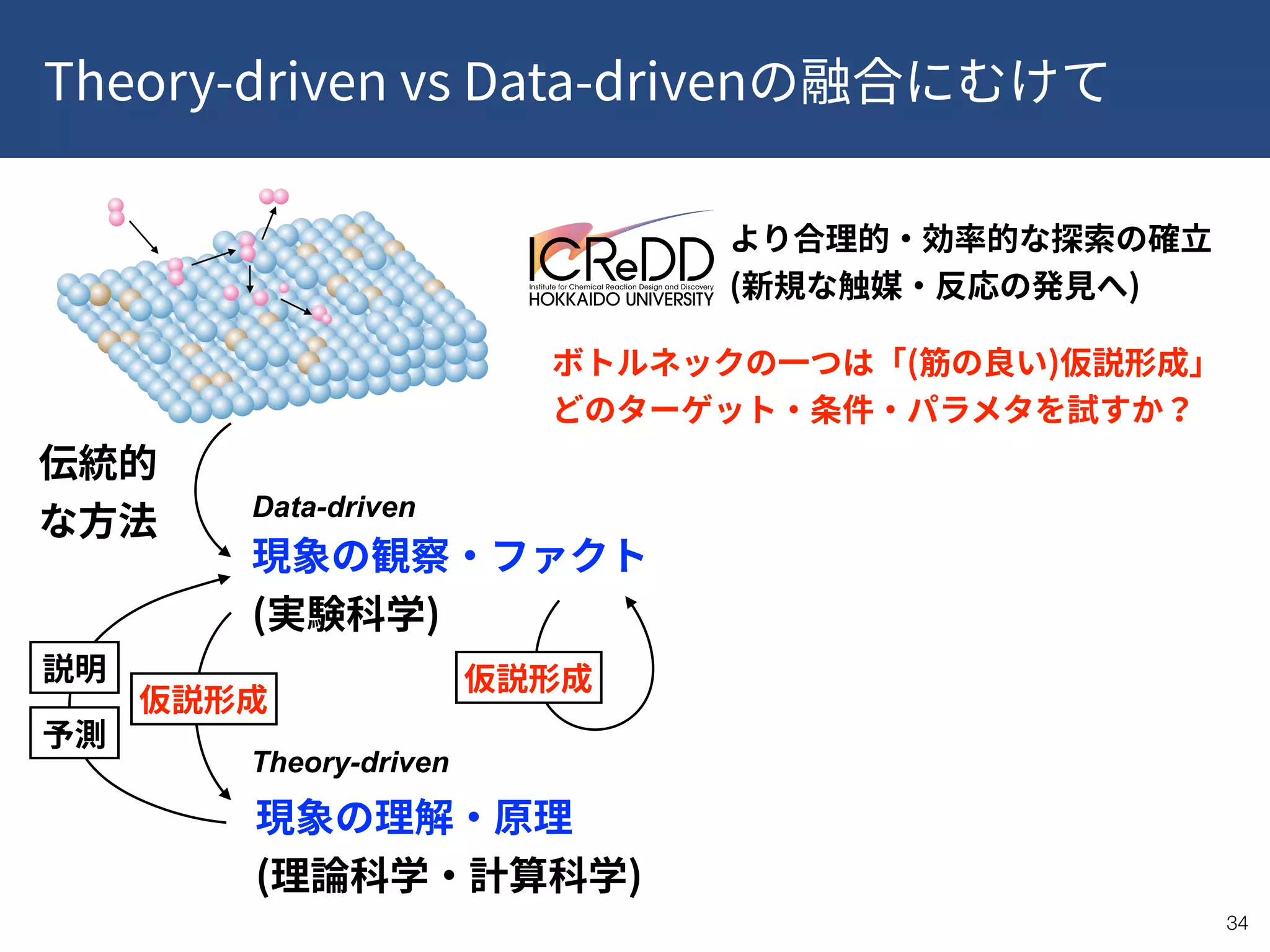
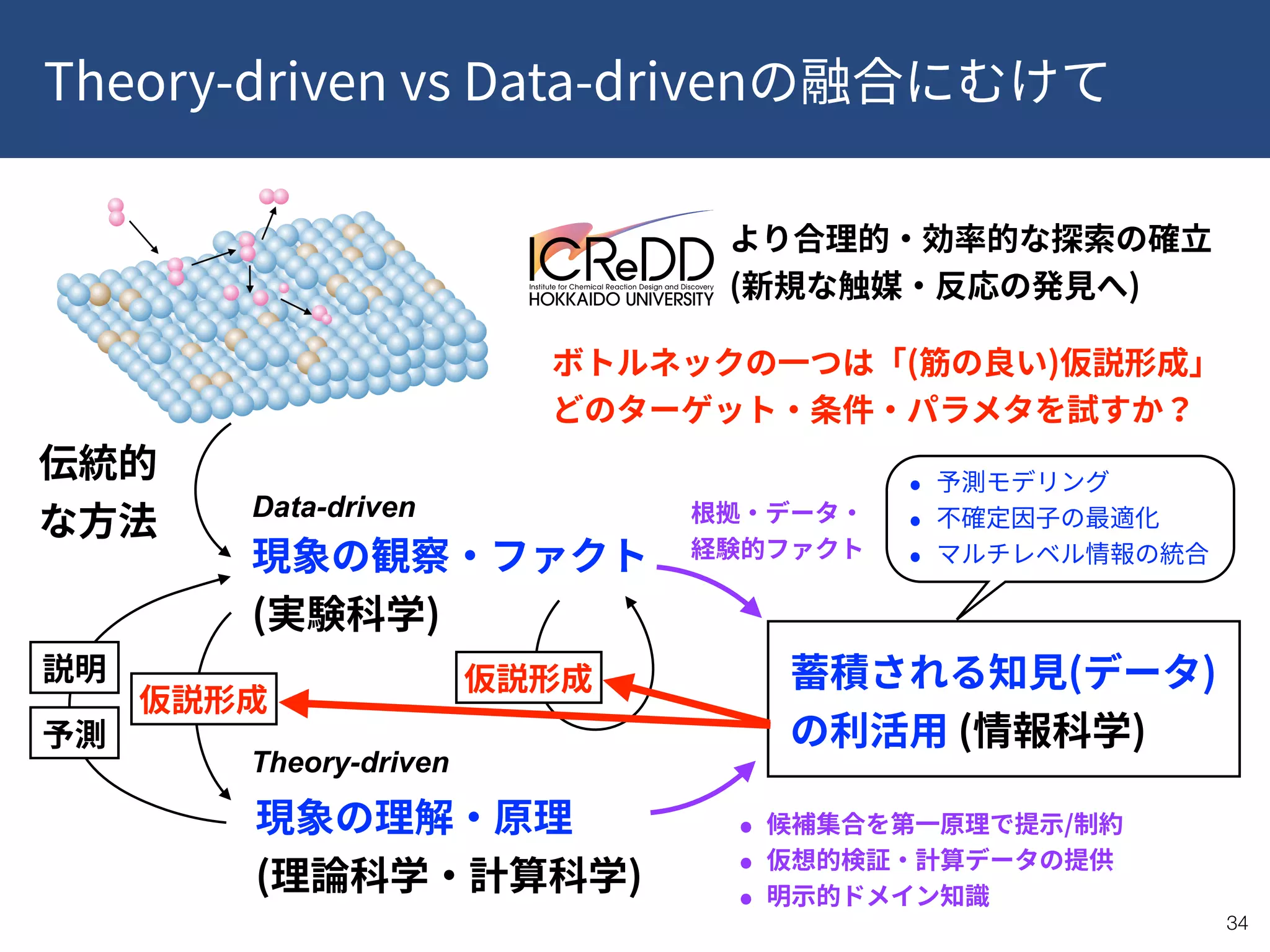


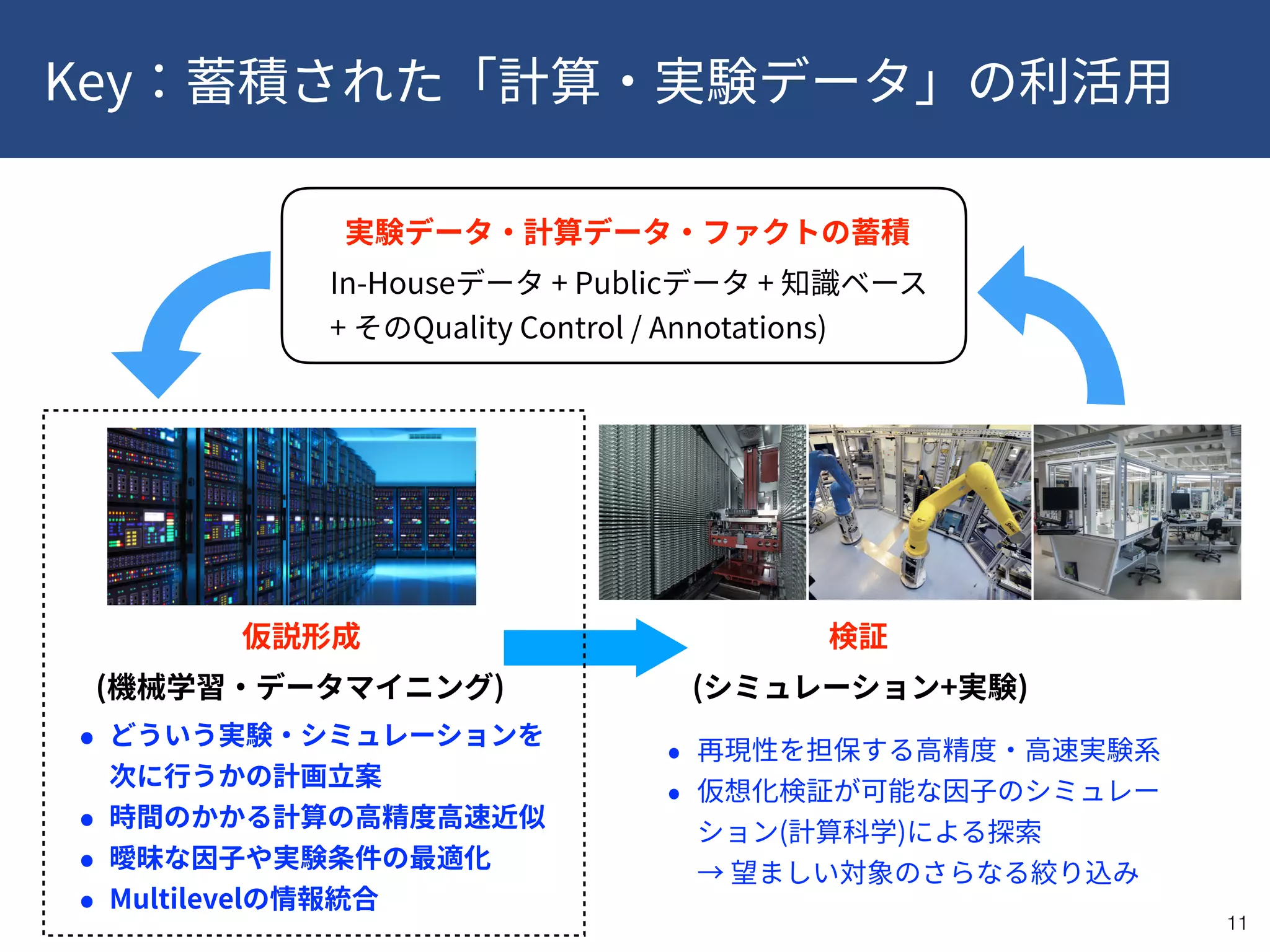
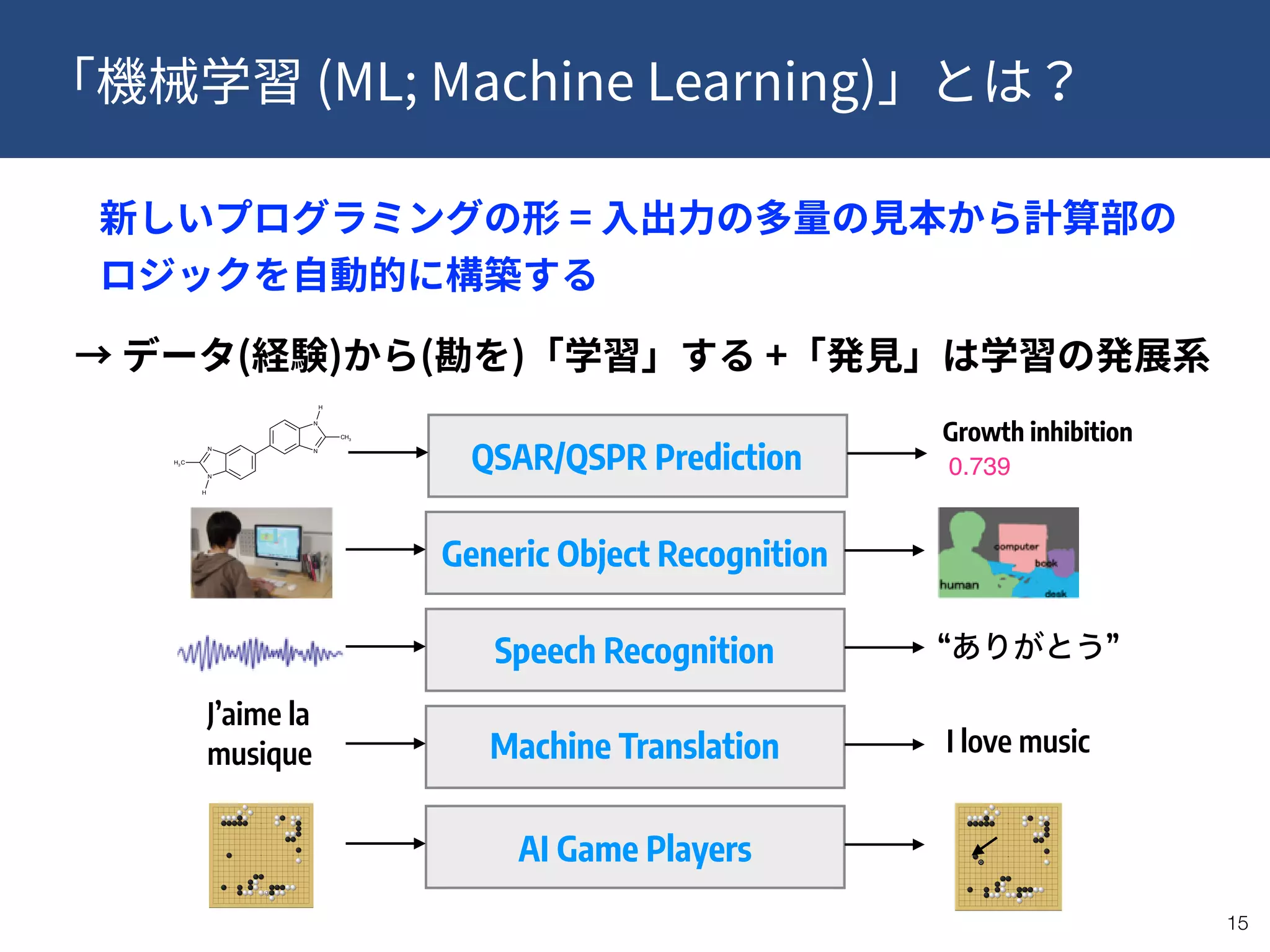
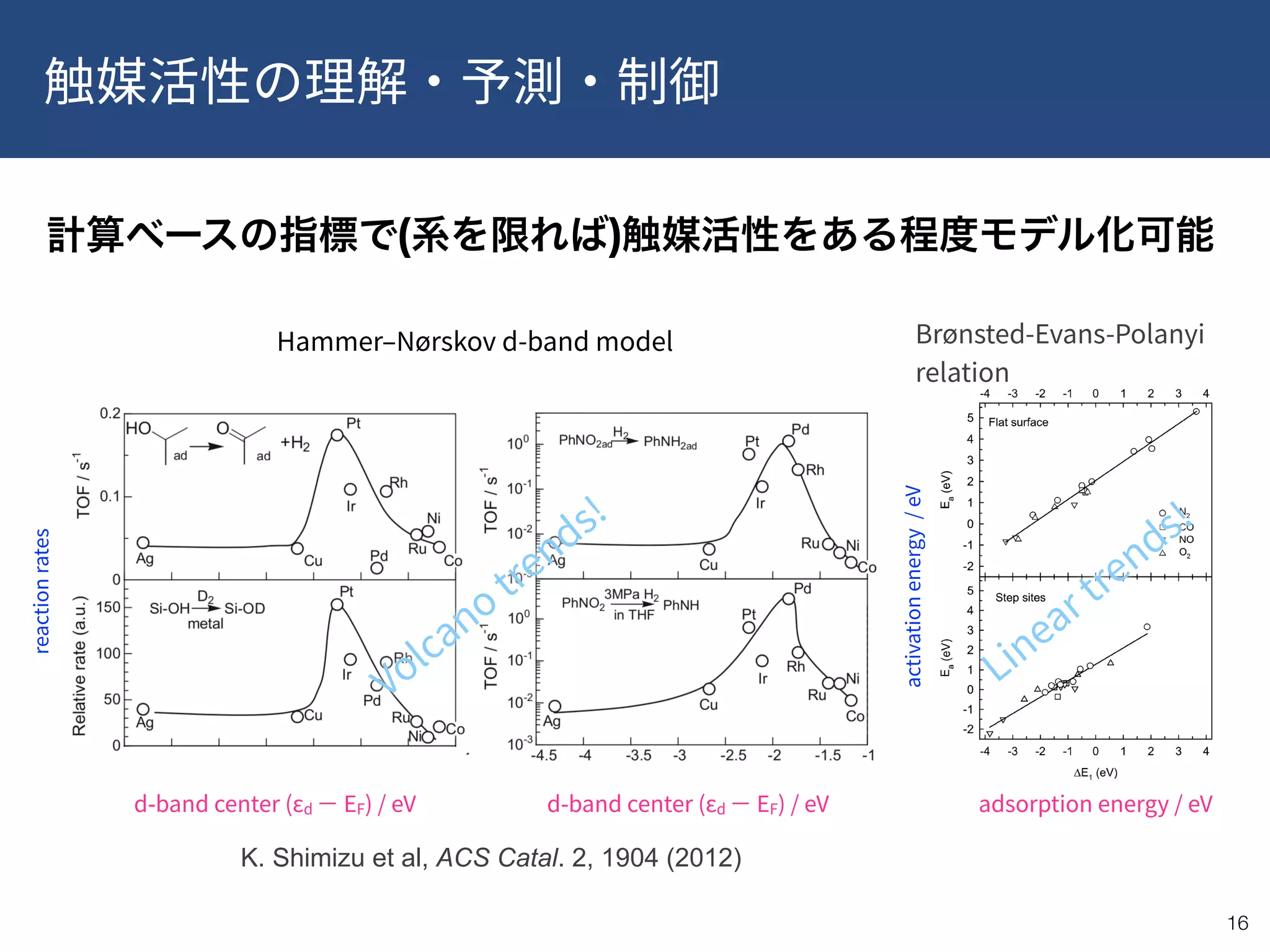
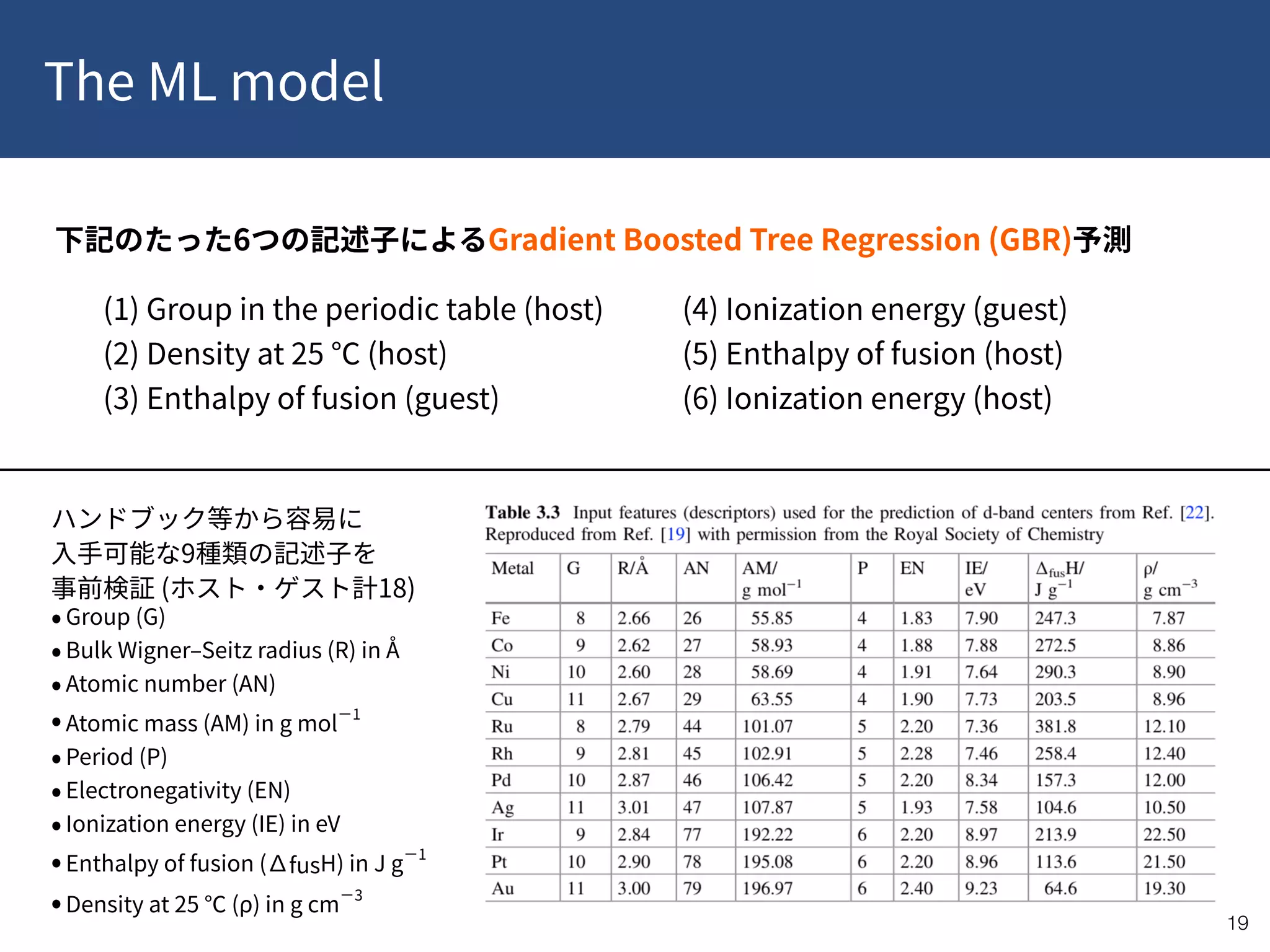
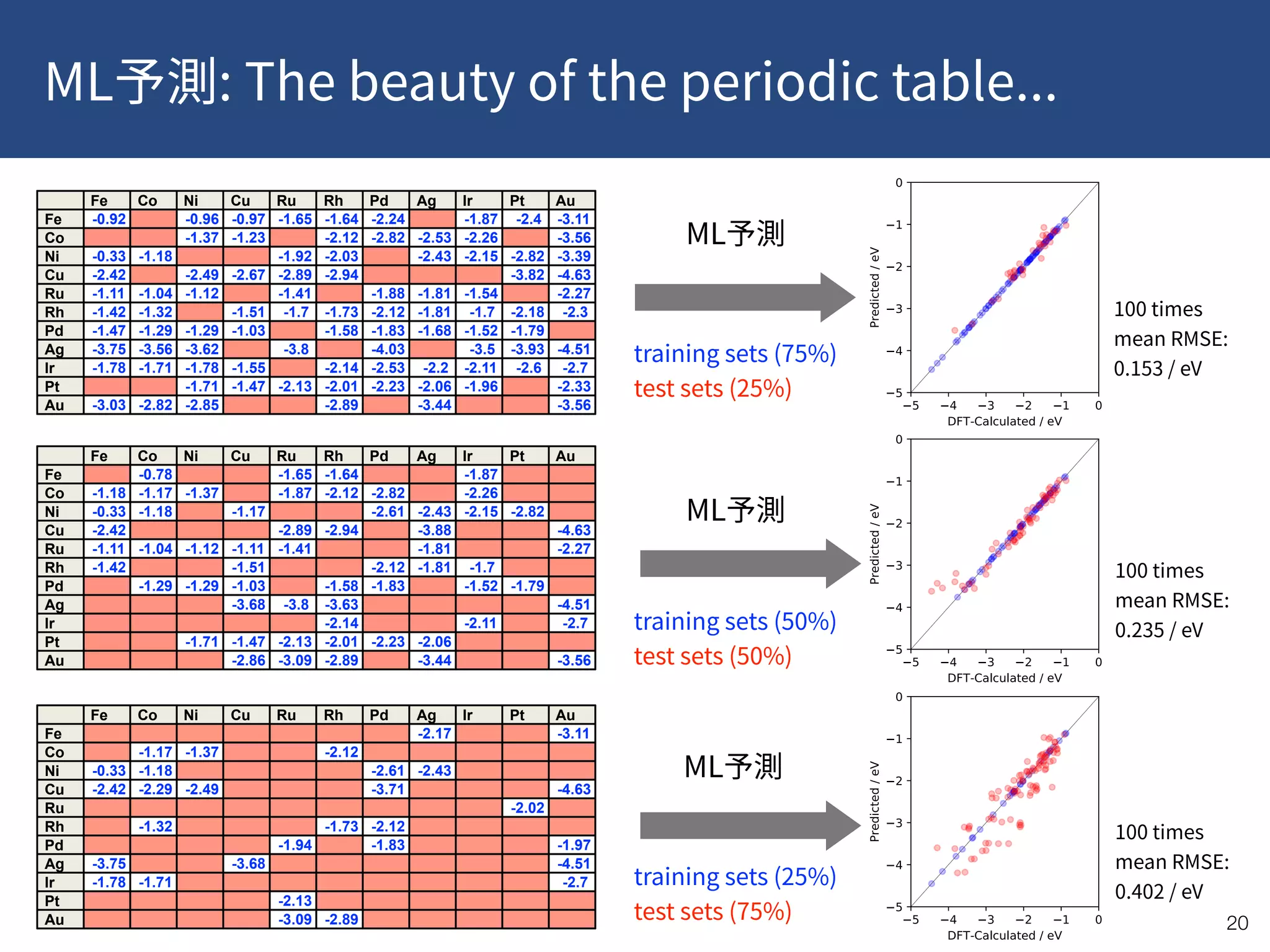
This document provides a summary of recent publications related to research conducted at the WPI-ICReDD. It lists five publications from 2018-2019 related to catalysis and materials science. It then discusses the research projects and personnel involved in the JST CREST program that is funding this work. The document outlines the goals of using data-driven approaches and machine learning to optimize materials discovery and design. It proposes a multilevel framework that combines in-house and public data along with quality control and annotations to advance the field.























































































