Download as PDF, PPTX


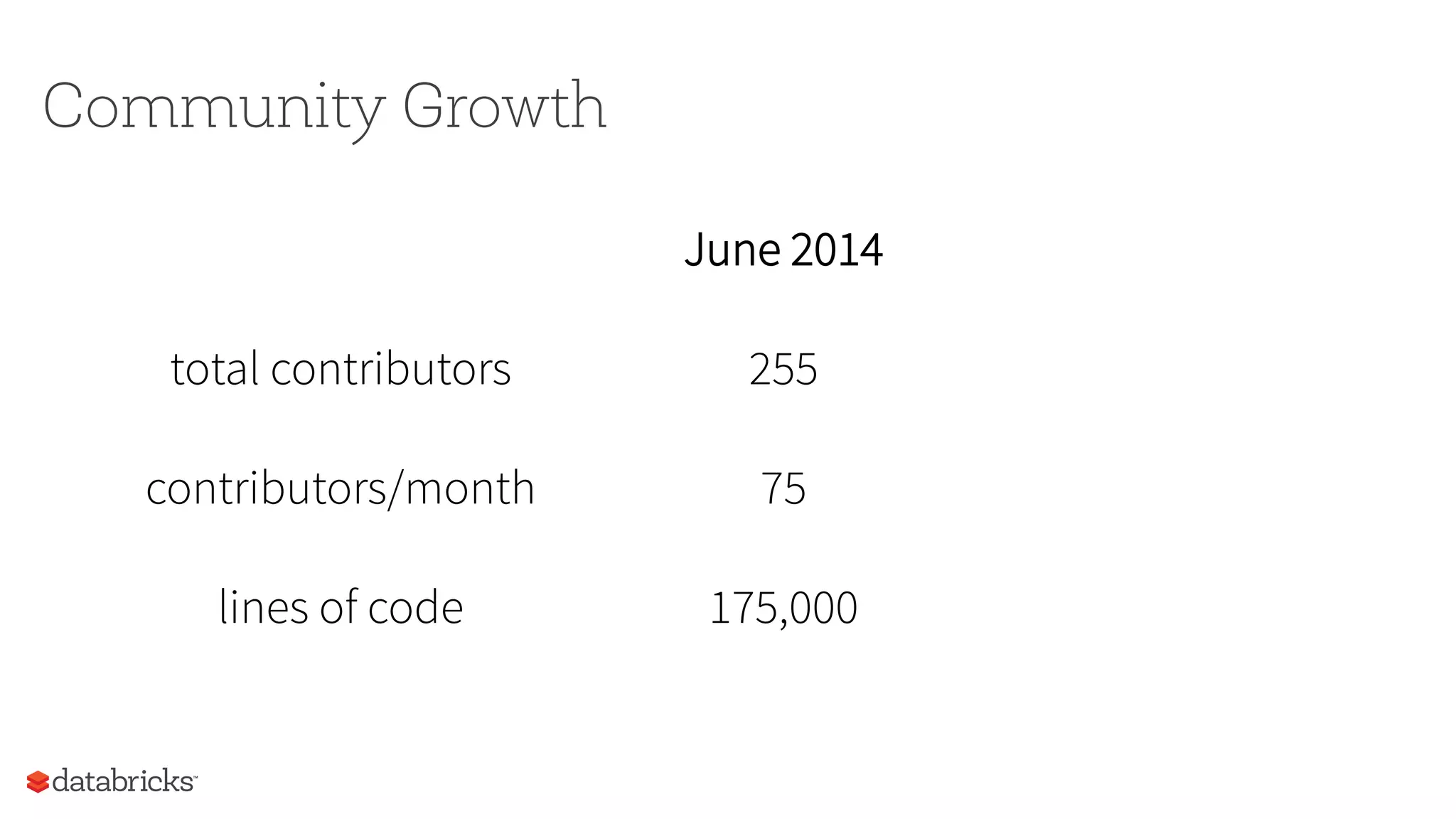
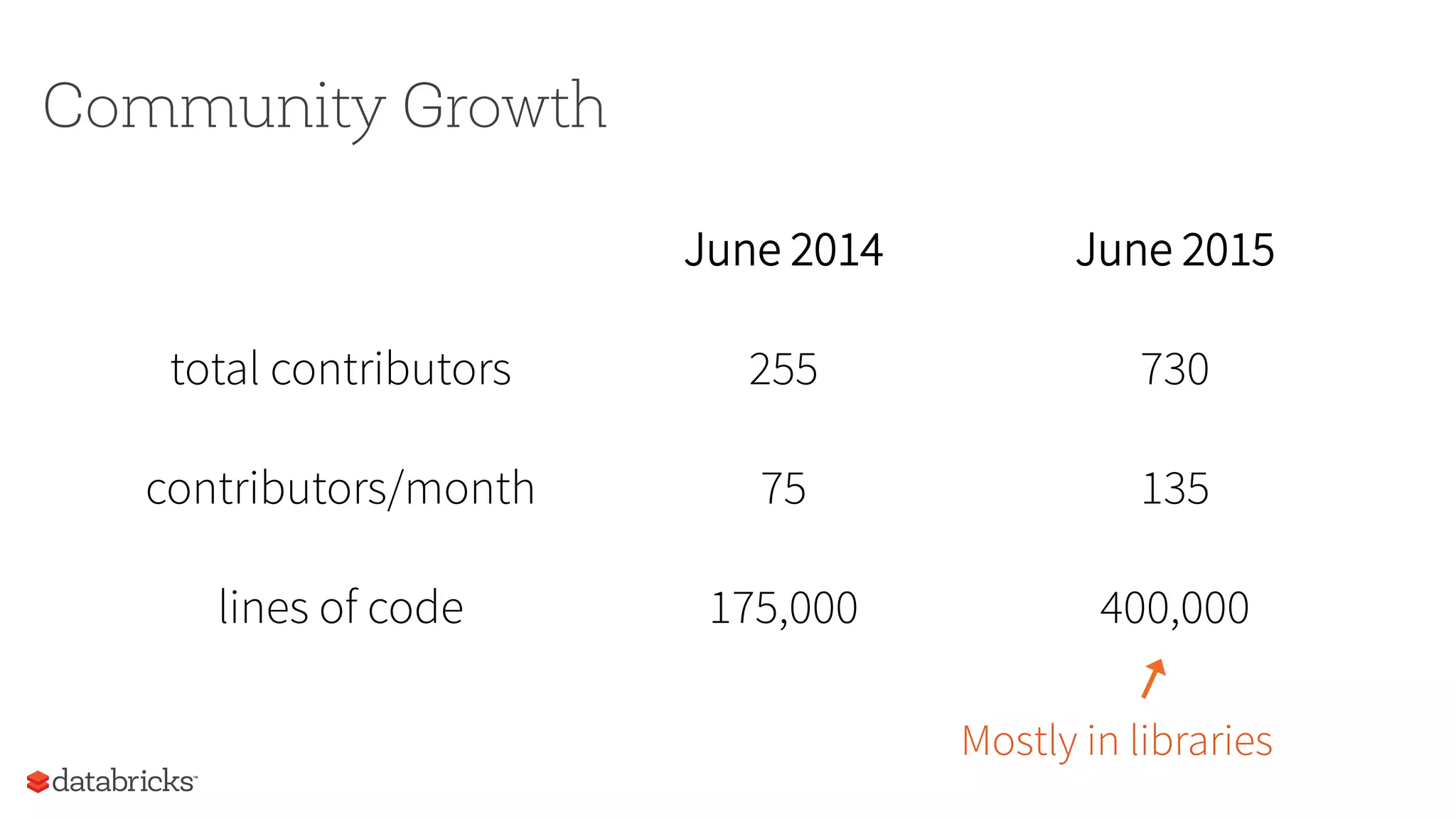










![ML Pipelines
17
Data
Frame
tokenizer hashingTF lr
Pipeline Model
//
create
pipeline
tok
=
Tokenizer(in="text",
out="words”)
tf
=
HashingTF(in=“words”,
out="features”)
lr
=
LogisticRegression(maxIter=10,
regParam=0.01)
pipeline
=
Pipeline(stages=[tok,
tf,
lr])
Data
Frame
//
train
pipeline
df
=
sqlCtx.table(”training”)
model
=
pipeline.fit(df)
//
make
predictions
df
=
sqlCtx.read.json("/path/to/test”)
model.transform(df)
.select(“id”,
“text”,
“prediction”)](https://image.slidesharecdn.com/matei-patrick-spark-summit-2015-150617070827-lva1-app6891/75/Spark-Community-Update-Spark-Summit-San-Francisco-2015-17-2048.jpg)

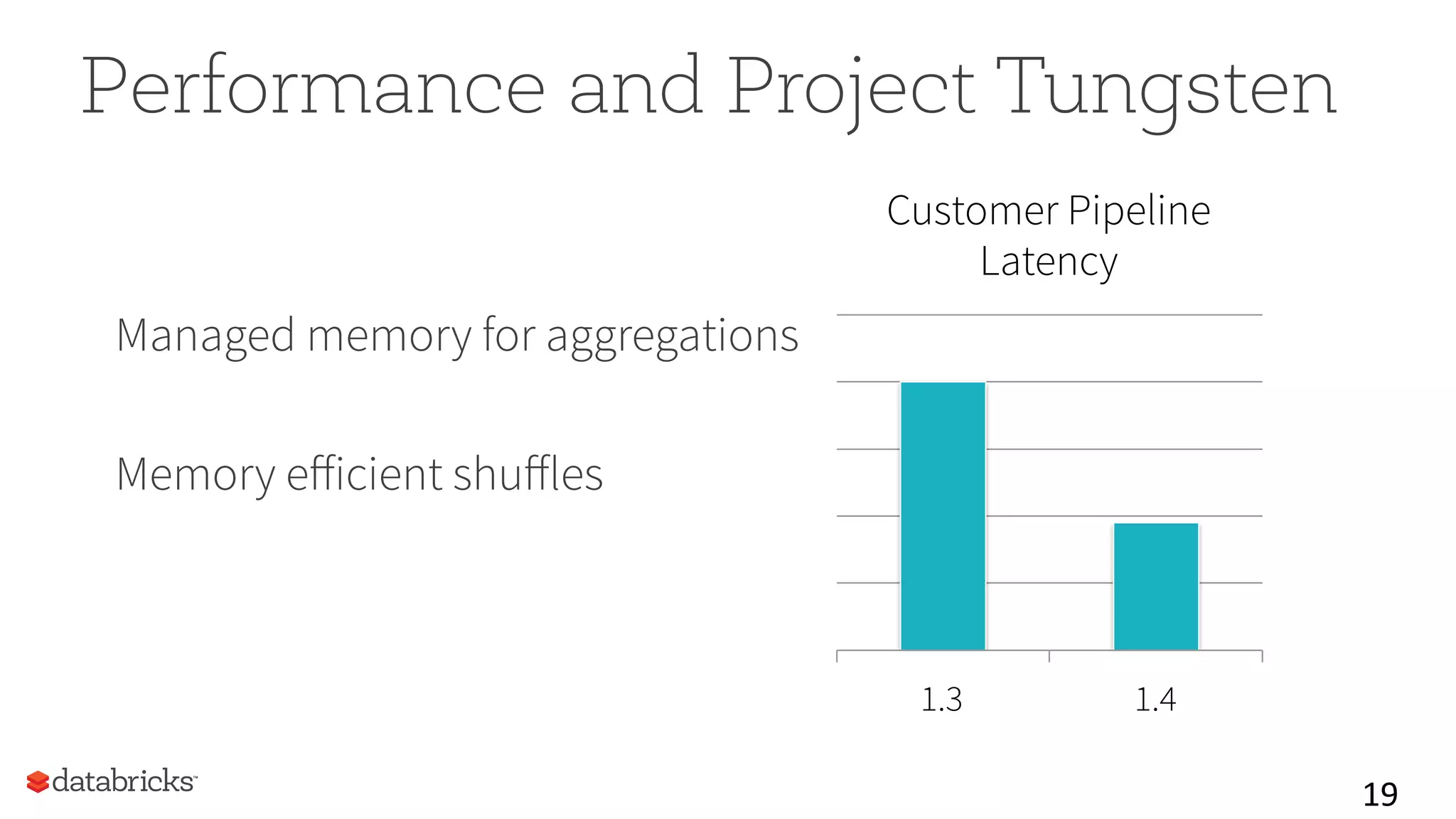

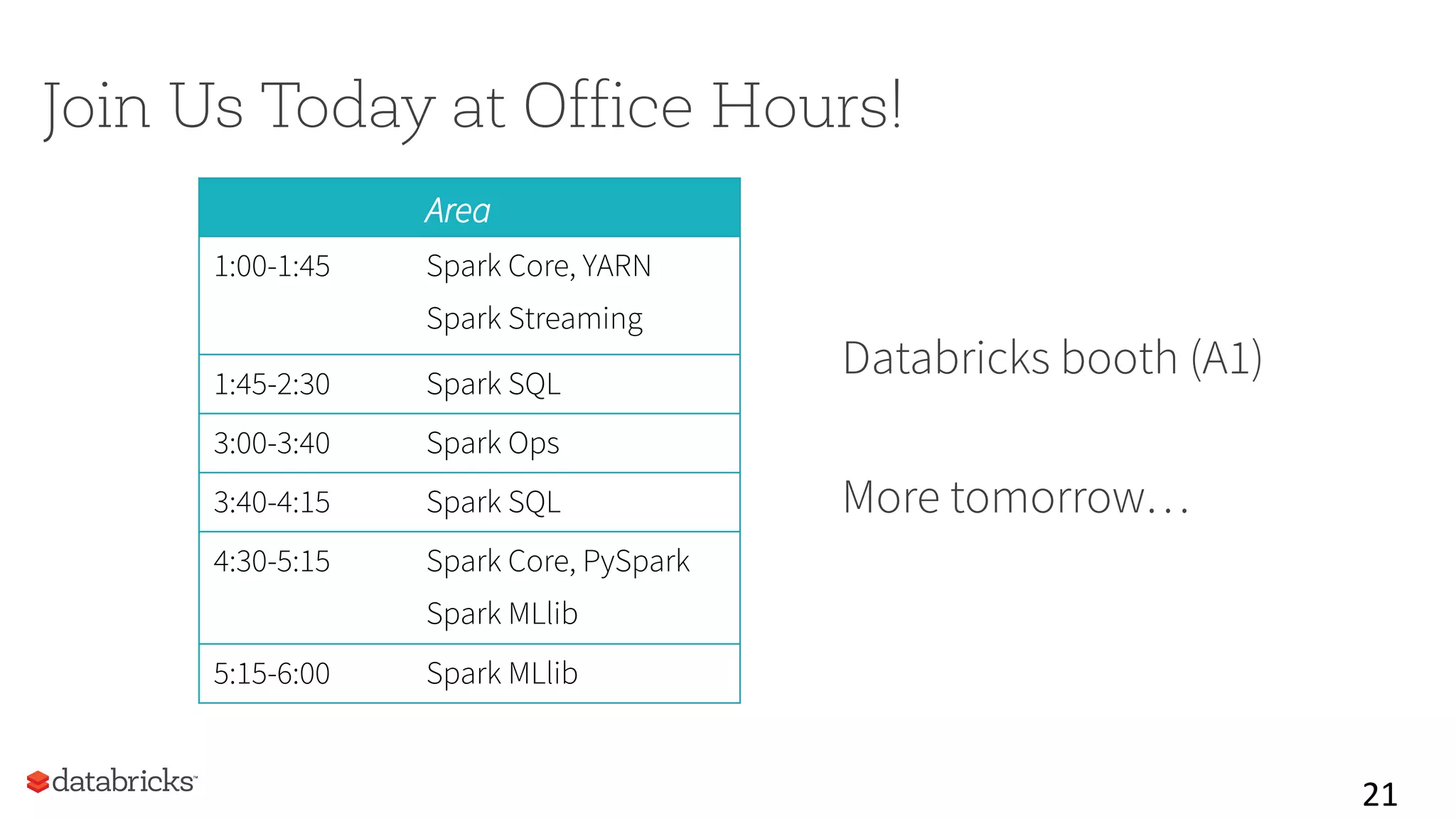


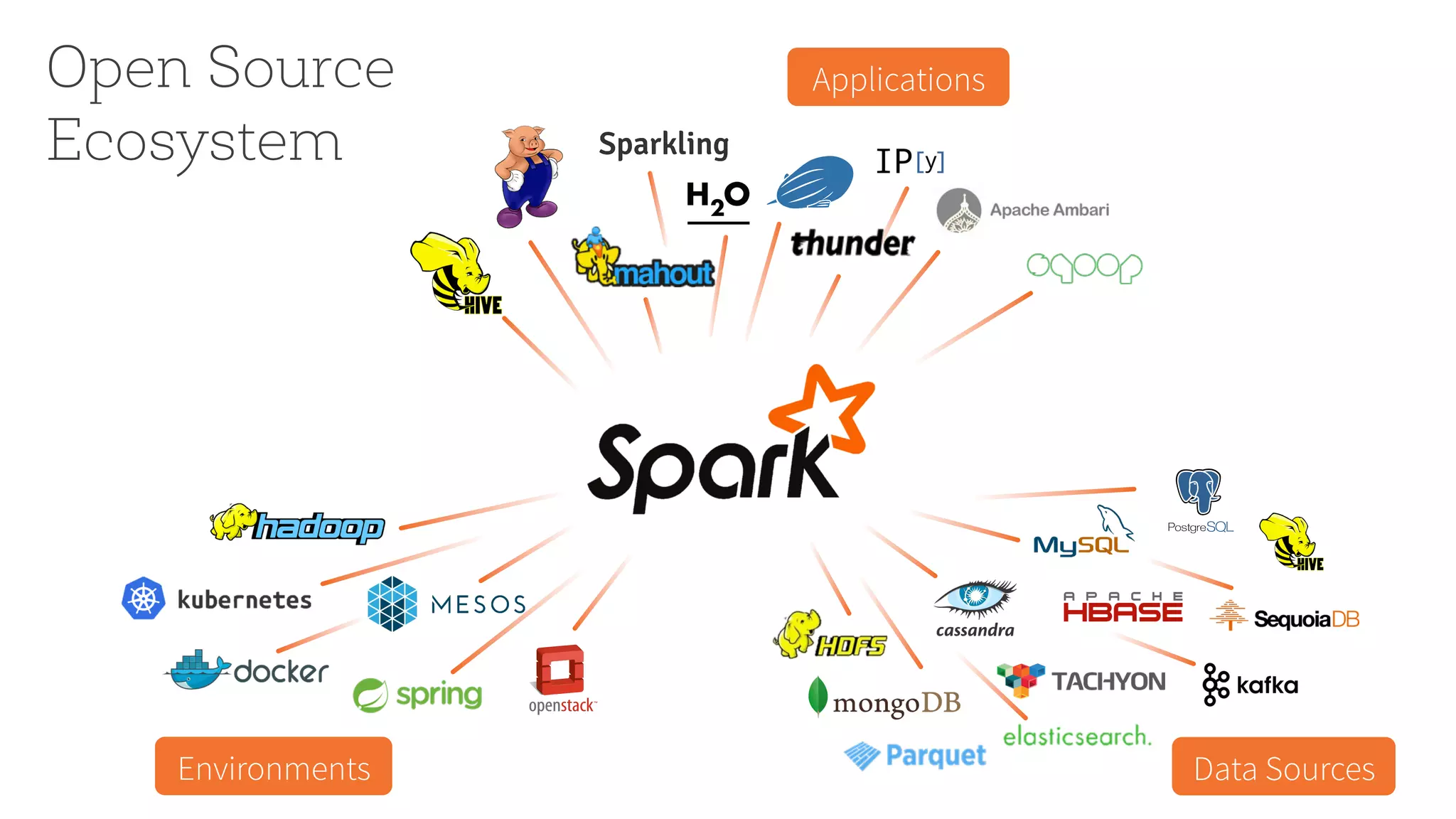
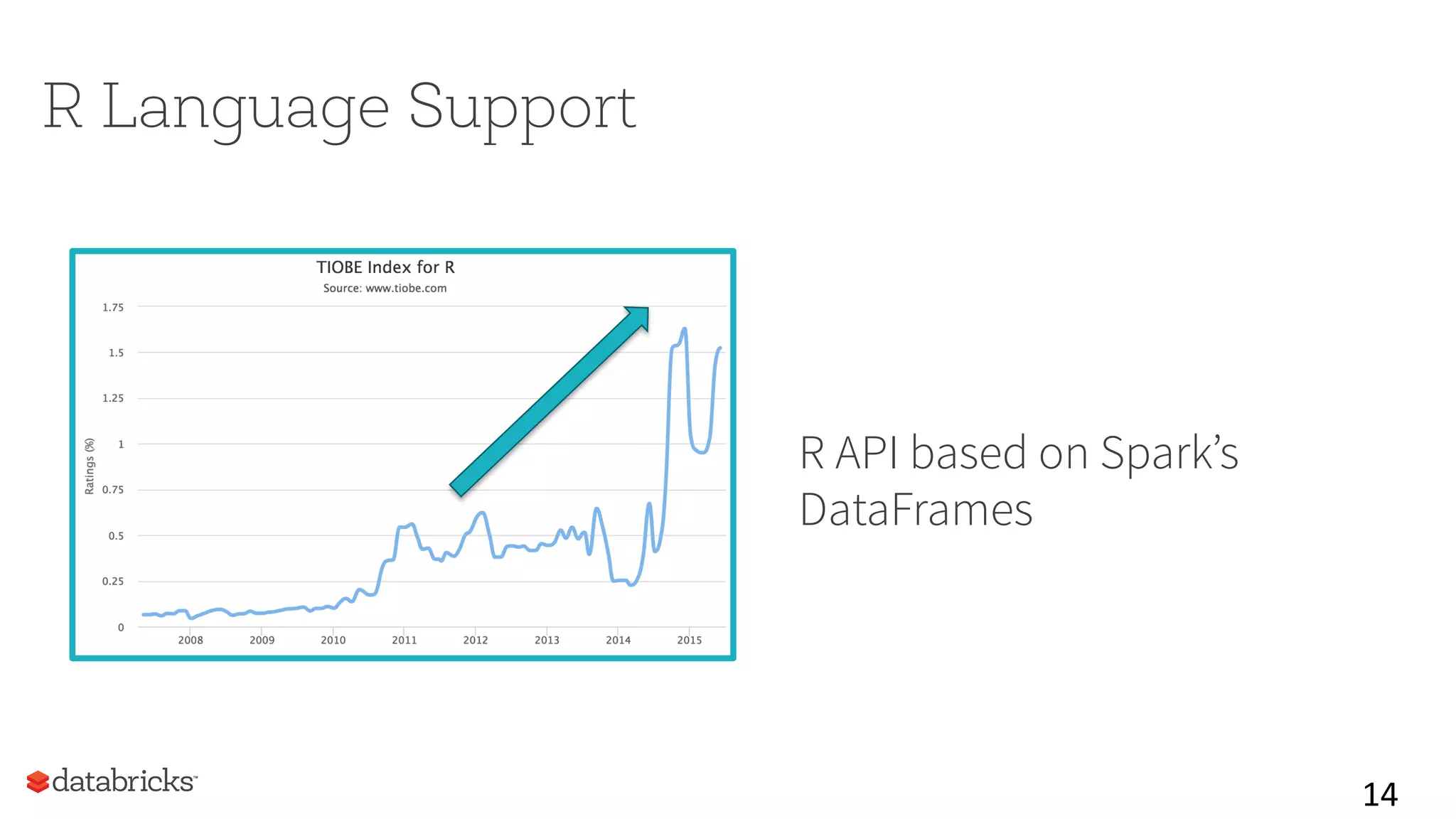
This document summarizes Spark community updates from June 2014 to June 2015. It notes that Spark has become the most active open source project for data processing, with the number of contributors and lines of code doubling over the past year. New features in Spark include support for the R programming language and machine learning pipelines inspired by scikit-learn. The document outlines ongoing work to improve the Spark engine and platform APIs, as well as previews upcoming developments through Spark 1.5.























































































