Downloaded 17 times

























































![Test Case Design Implications of OO Concepts
OO class is the target for test case design. Because attributes and operations are
encapsulated, testing operations outside of the class is generally unproductive.
Although encapsulation is an essential design concept for OO, it can create a
minor obstacle when testing. As Binder notes, “Testing requires reporting on the
concrete and abstract state of an object.” Yet, encapsulation can make this
information somewhat difficult to obtain. Unless built-in operations are provided
to report the values for class attributes, a snapshot of the state of an object may
be difficult to acquire.
Inheritance also leads to additional challenges for the test case designer. We
have already noted that each new context of usage requires retesting, even
though reuse has been achieved. In addition, multiple inheritance complicates
testing further by increasing the number of contexts for which testing is required
[BIN94a].](https://image.slidesharecdn.com/softwaretesting-160912100946/75/Software-testing-66-2048.jpg)







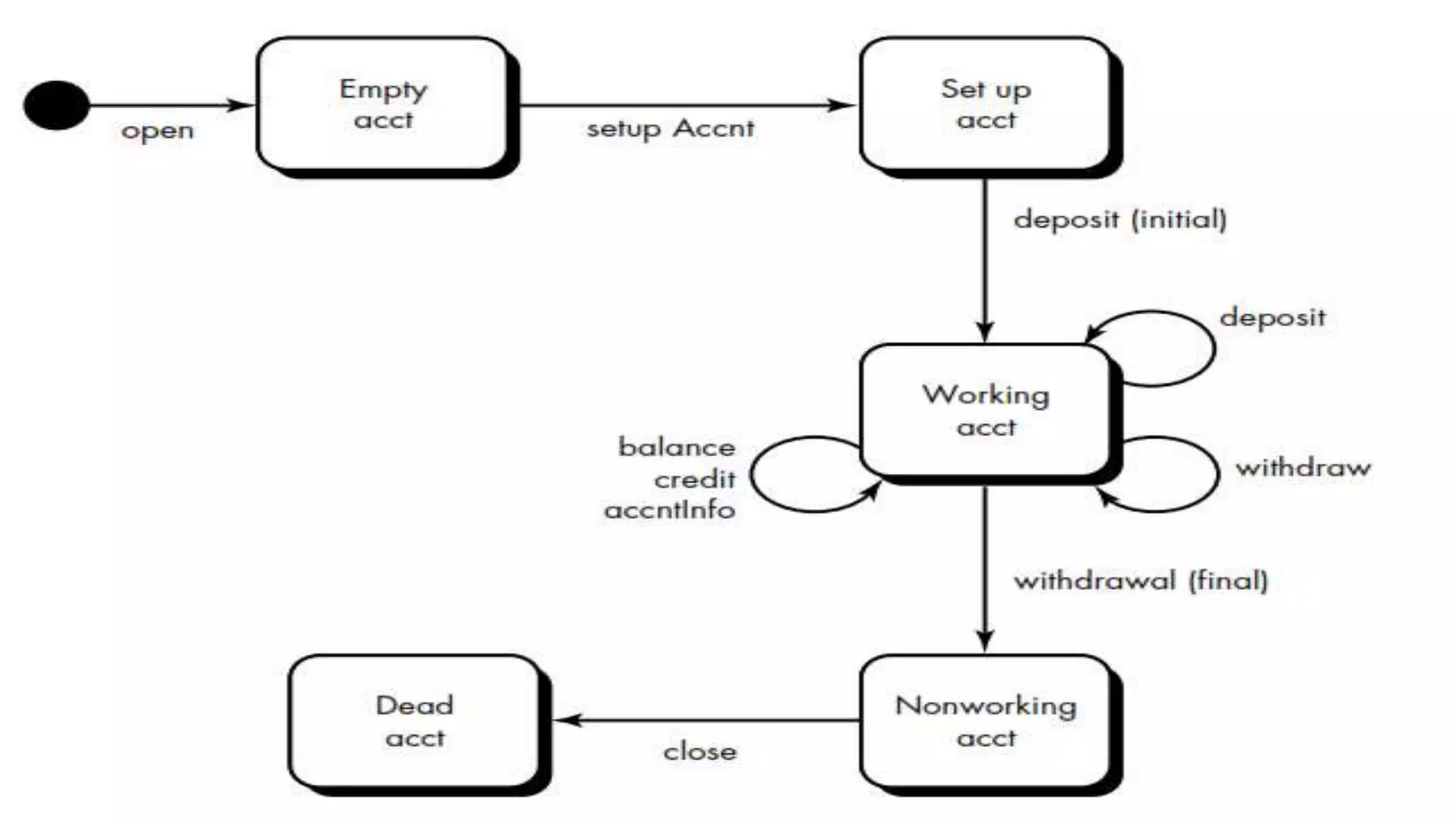
![Random Testing for OO Classes
Consider a banking application in which an account class has the following
operations: open, setup, deposit, withdraw, balance, summarize, credit Limit, and
close. Each of these operations may be applied for account, but certain constraints
are implied by the nature of the problem.
Open*Setup*Deposit*Withdraw*Close
This represents the minimum test sequence for account. However, a wide variety of
other behaviors may occur within this sequence:
Open*Setup*Deposit*[deposit|withdraw|balance|summarize|creditLimit]*Withdraw*Close
A variety of different operation sequences can be generated randomly. For example:
Test case 1: open*setup*deposit*deposit*balance*summarize*withdraw*close
Test Case 2: open*setup*deposit*withdraw*deposit*balance*creditLimit*withdraw*close](https://image.slidesharecdn.com/softwaretesting-160912100946/75/Software-testing-74-2048.jpg)




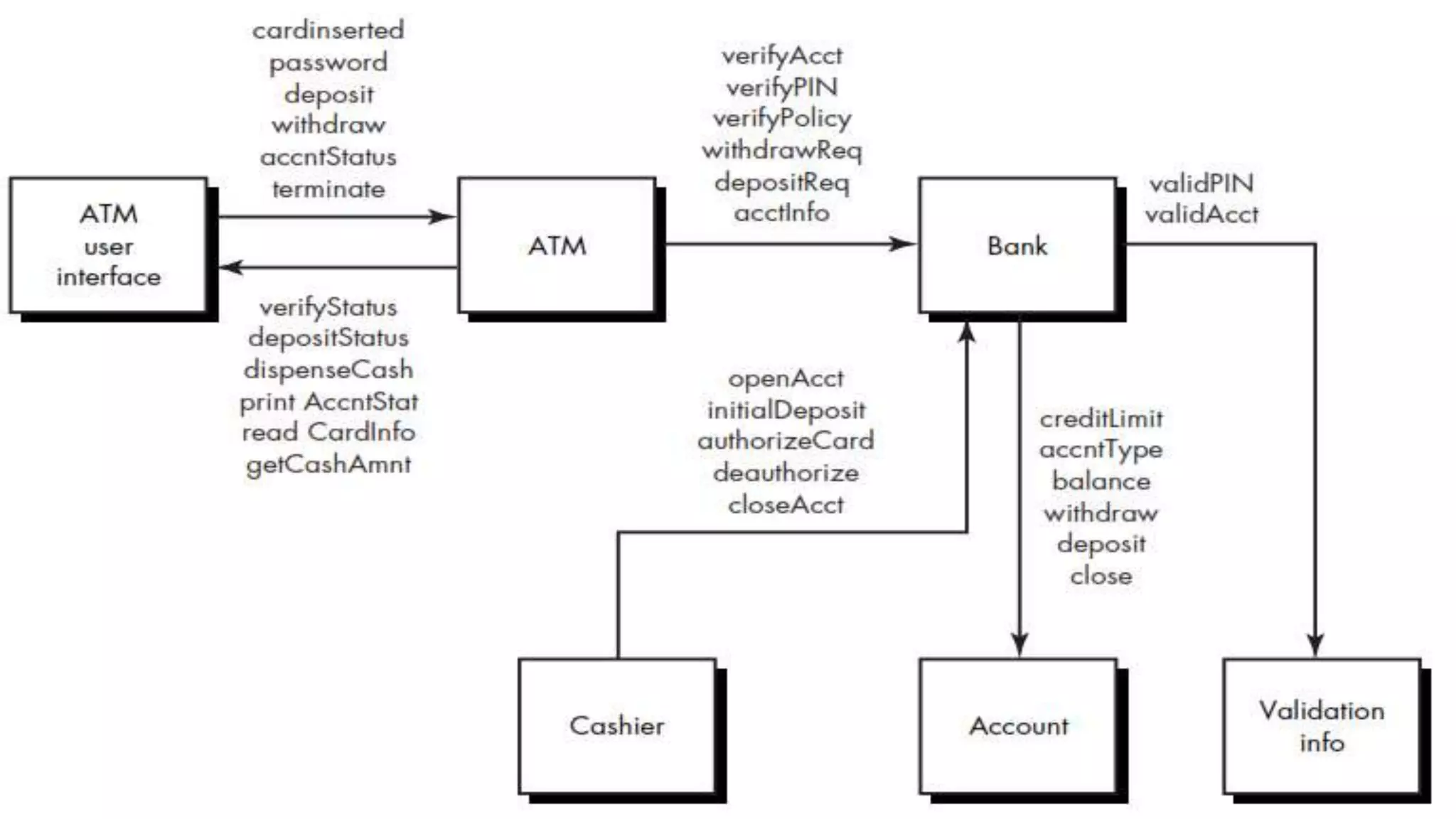



Testing software is important to uncover errors before delivery to customers. There are various techniques for systematically designing test cases, including white box and black box testing. White box testing involves examining the internal logic and paths of a program, while black box testing focuses on inputs and outputs without viewing internal logic. The goal of testing is to find the maximum number of errors with minimum effort.
Introduction to Software Testing as a critical component in software development.
Objectives of testing: error detection and optimization of test case design through systemic techniques.
Clarification of testing objectives including error discovery and probability of test cases.
Key principles guiding effective testing include traceability to requirements and pre-planning.
Defining testability, including operability, observability, controllability, simplicity, stability, and understandability of systems.
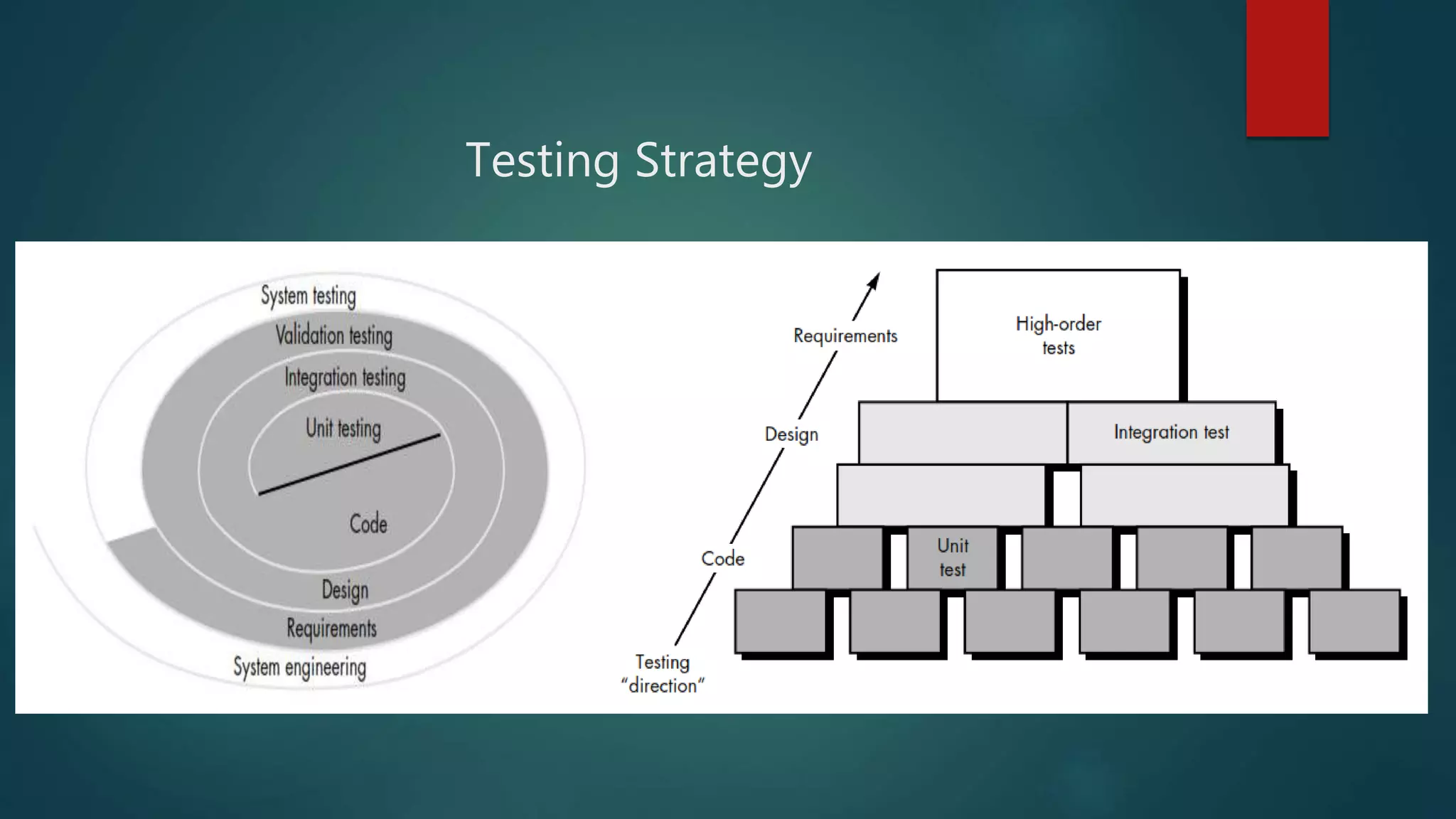
A strategic framework for software testing, emphasizing a systematic progression from component to full system testing.
Distinction between verification (building correctly) and validation (building the right product) in software development.
Introduction to various testing strategies and their implications.
Key strategic considerations for defining product requirements and testing objectives.
Focuses on verifying individual software components through white-box testing techniques.
Highlights common errors encountered during unit testing, such as arithmetic and initialization mistakes.
An overview of integration testing, outlining systematic approaches to error detection in component interfacing.
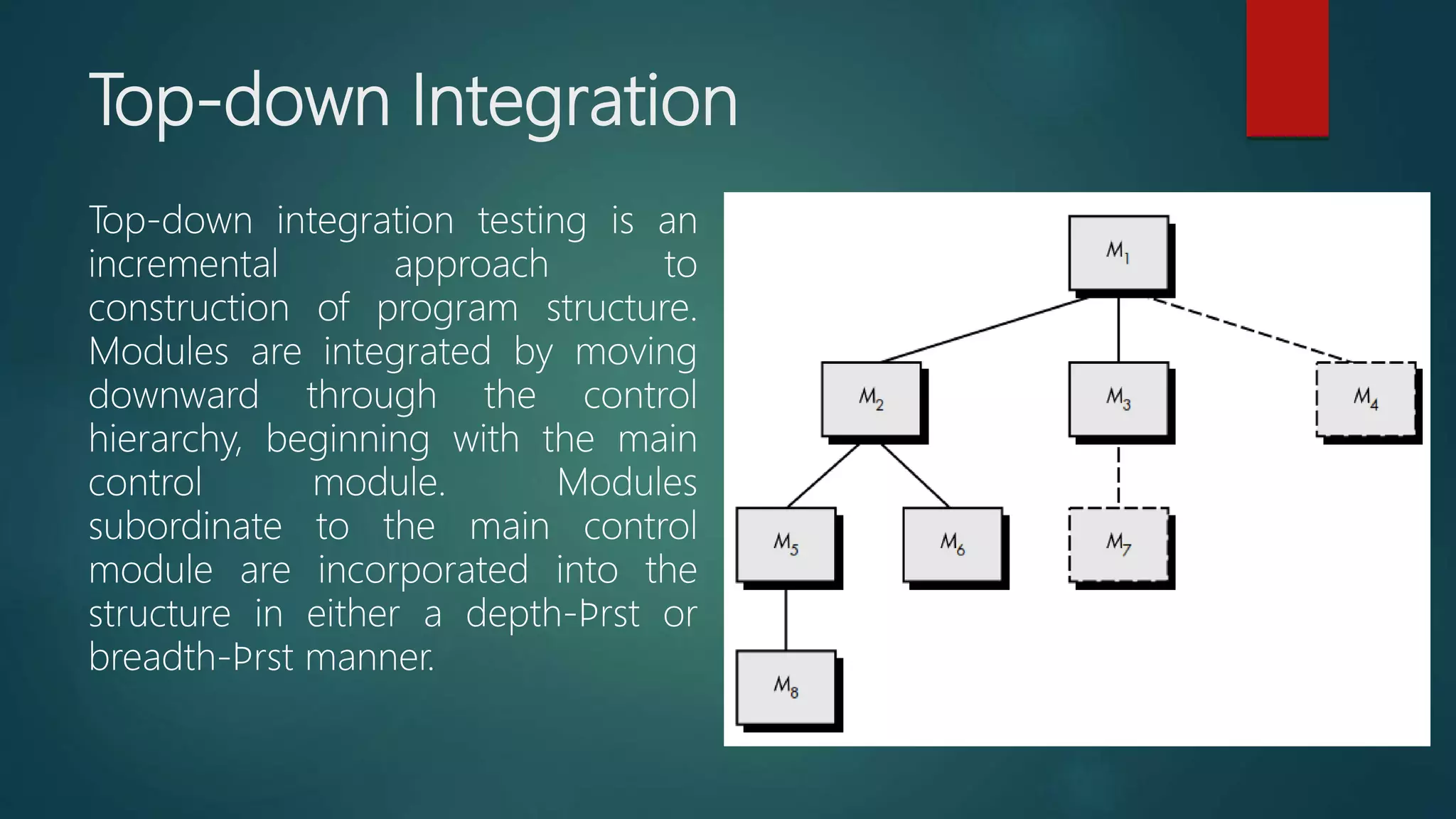
Details of top-down integration, illustrating incremental testing techniques using stubs.
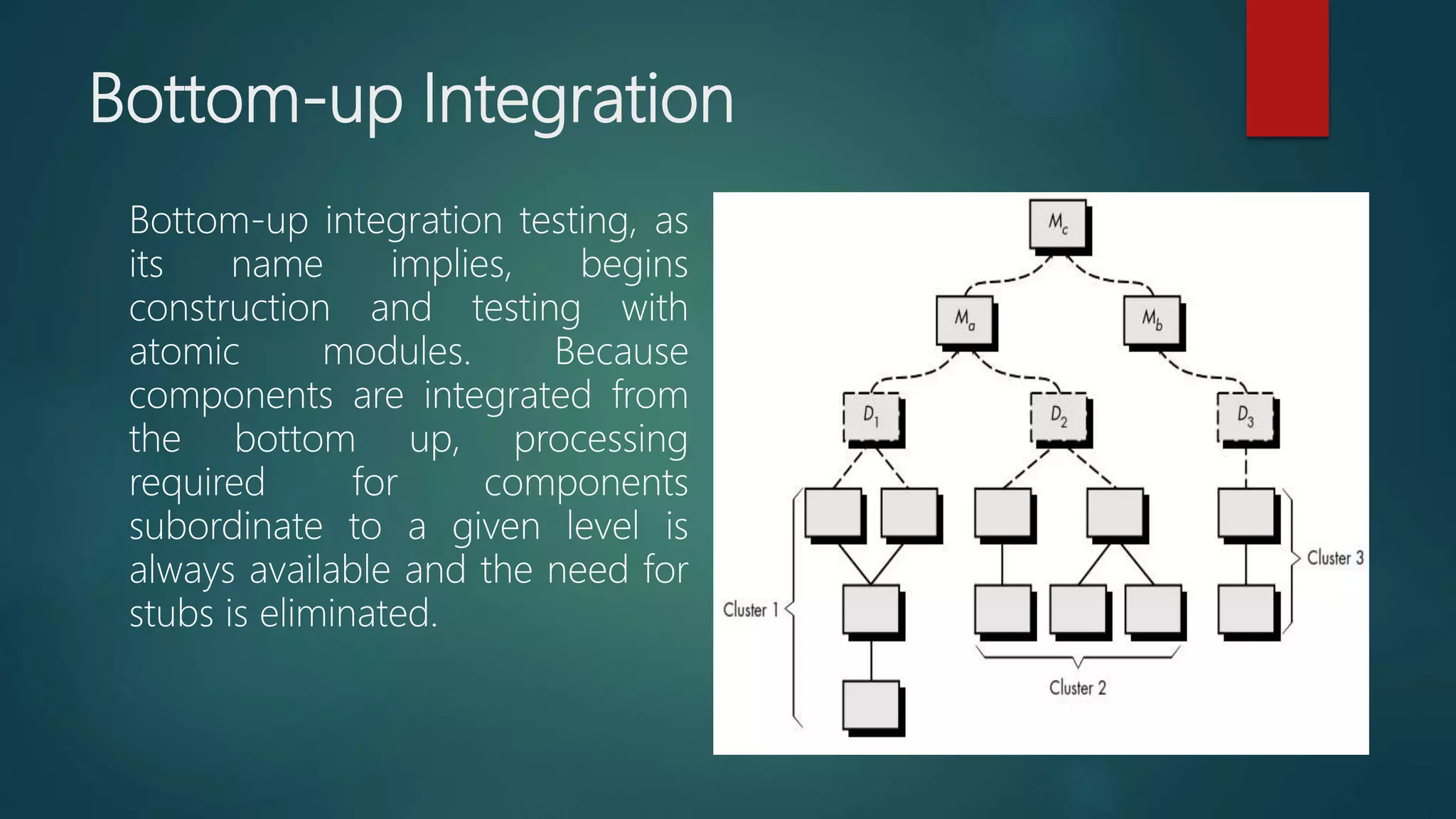
Introduction to bottom-up integration testing that begins with atomic modules for effective testing.
Concept of regression testing to ensure prior functionalities remain unaffected by new changes.
Validation testing ascertains software meets user expectations as per designated requirements.
Outlines validation testing plans and criteria for ensuring compliance with functions and performance requirements.
Importance of configuration reviews in the validation process for maintaining software integrity.
Different phases of testing wherein alpha is informal and beta uncovers errors in user environments.
Covers various system testing categories, verifying integration and allocated functions.
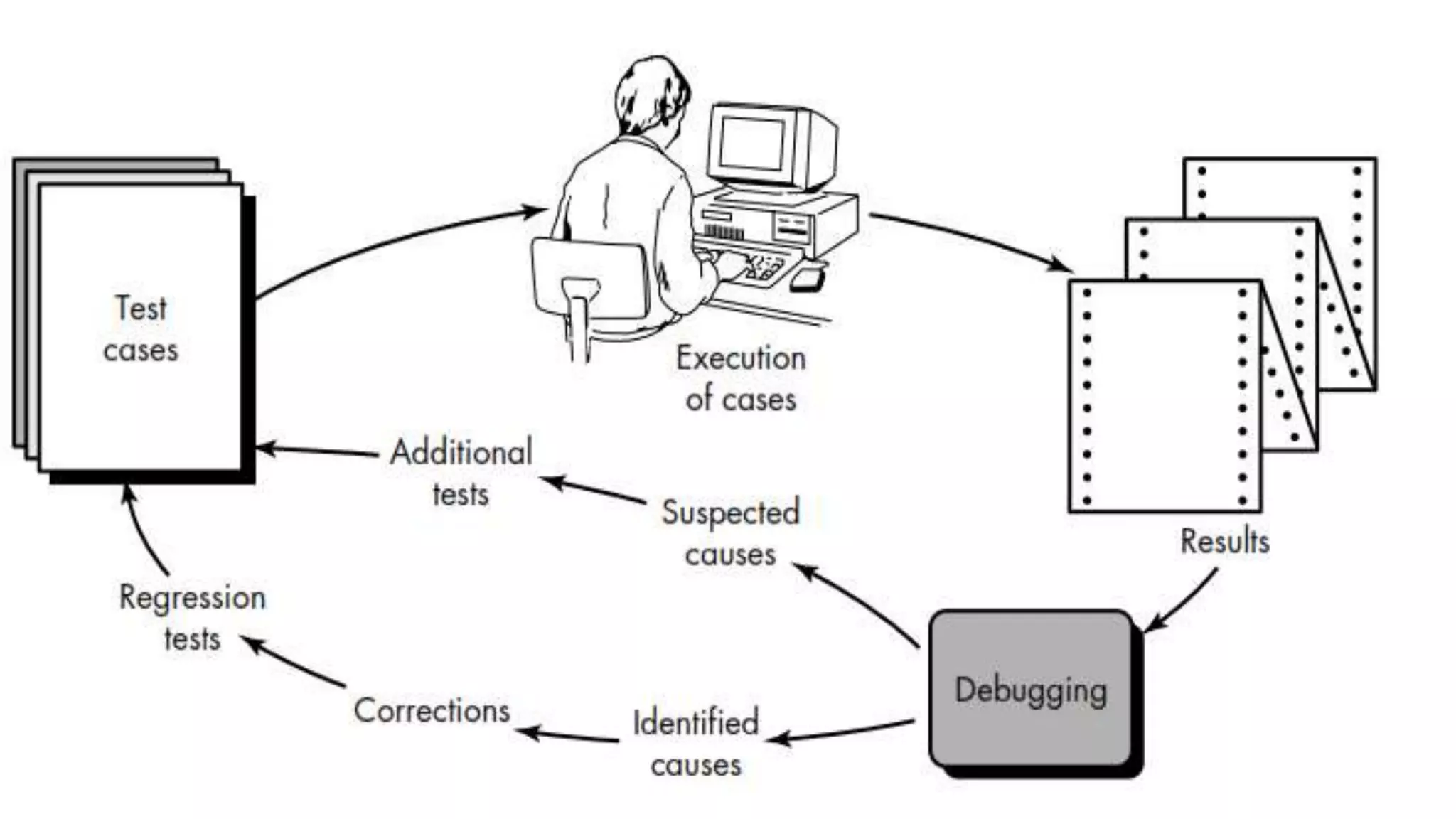
Debugging following successful testing, unraveling the relationship between symptoms and underlying causes.
Step-by-step debugging outcomes on cause satisfaction or identification.
Describes complex nature of bugs and issues related to accurate reproduction of symptoms.
Methodology of white-box testing focusing on internal logic and decision paths within software.
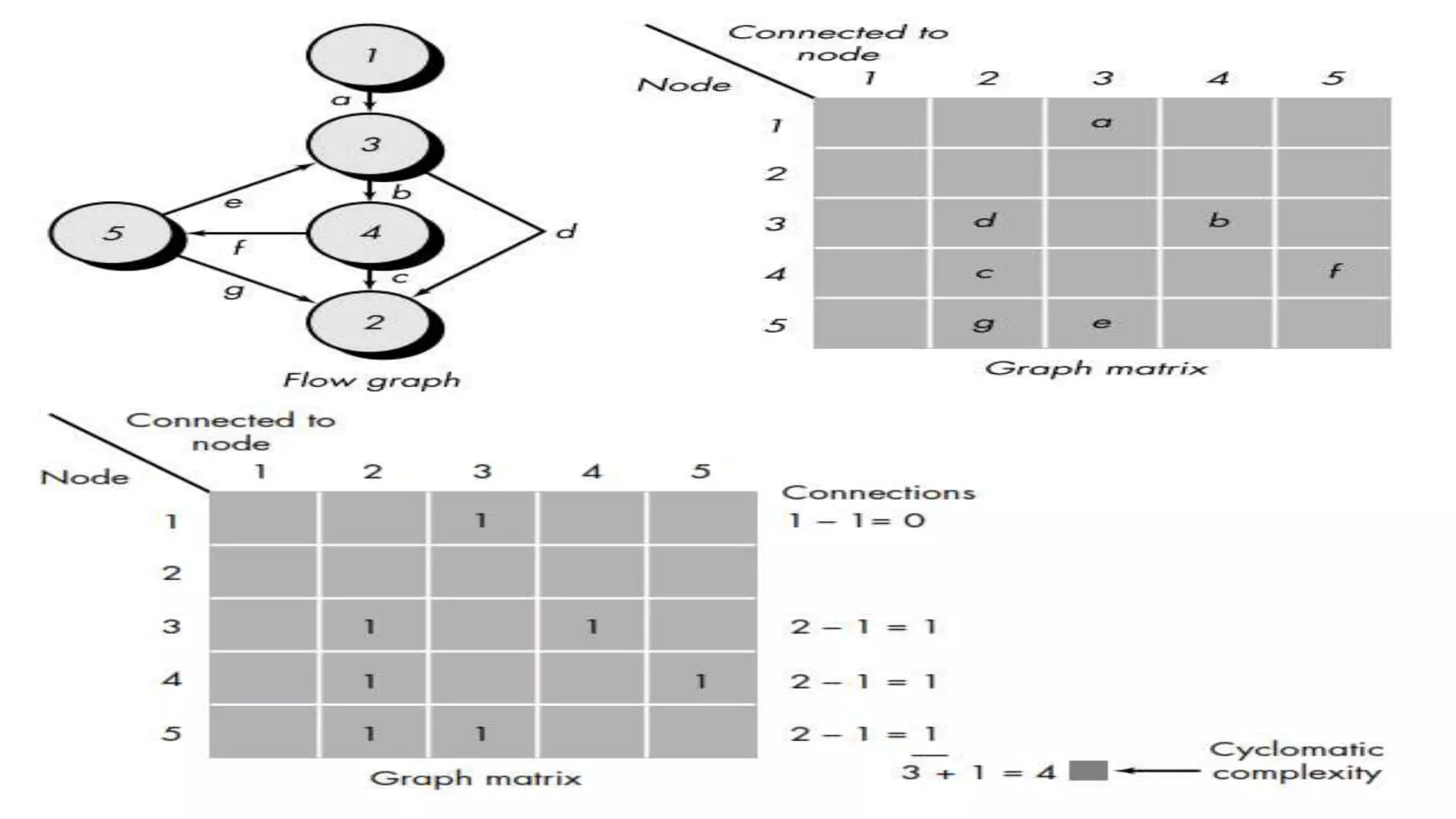
Basis path method design to systematically cover program execution through normalized paths.
Utilization of graph matrices for enhancing program control structure evaluation in testing.
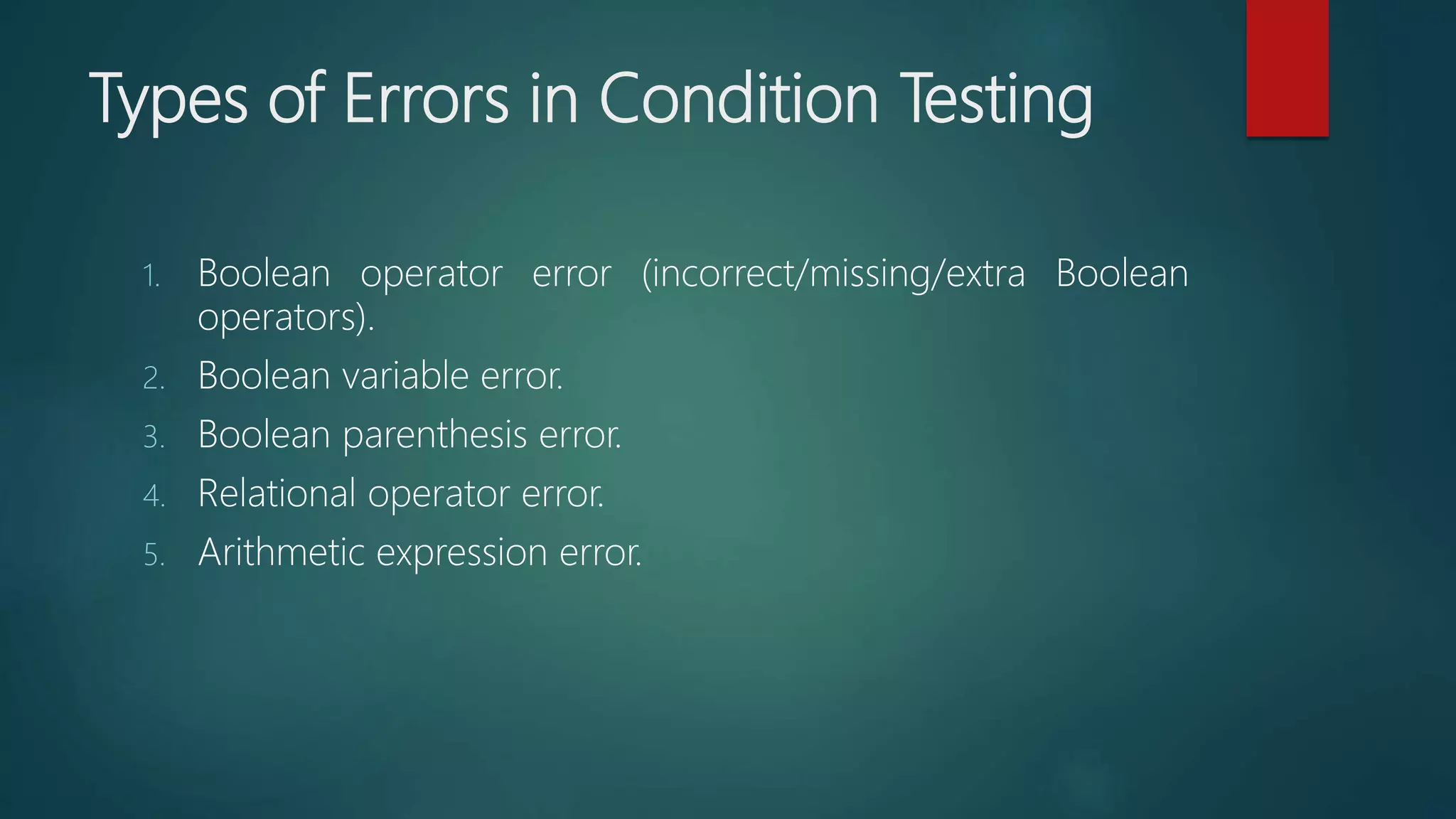
Different variations available in control structure testing enhancing the quality of white-box testing.Explains testing logical conditions contained in program modules, identifying various error types.
Selecting test paths based on variable definitions and usages to optimize error discovery.
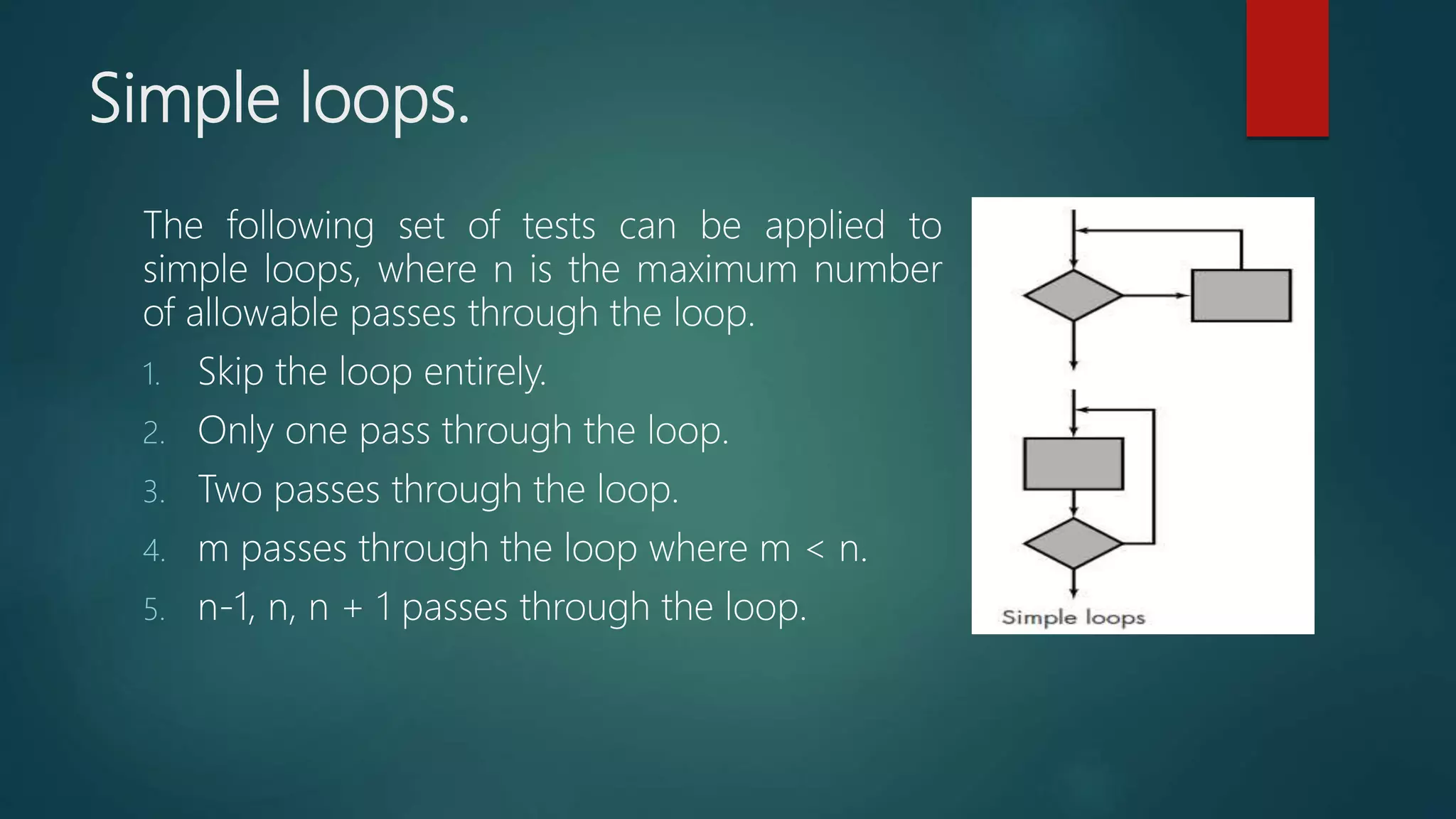
Focusing on loop constructs, detailing classifications and specific testing approaches.
Introduction to black-box testing focusing on functional requirements and error types.
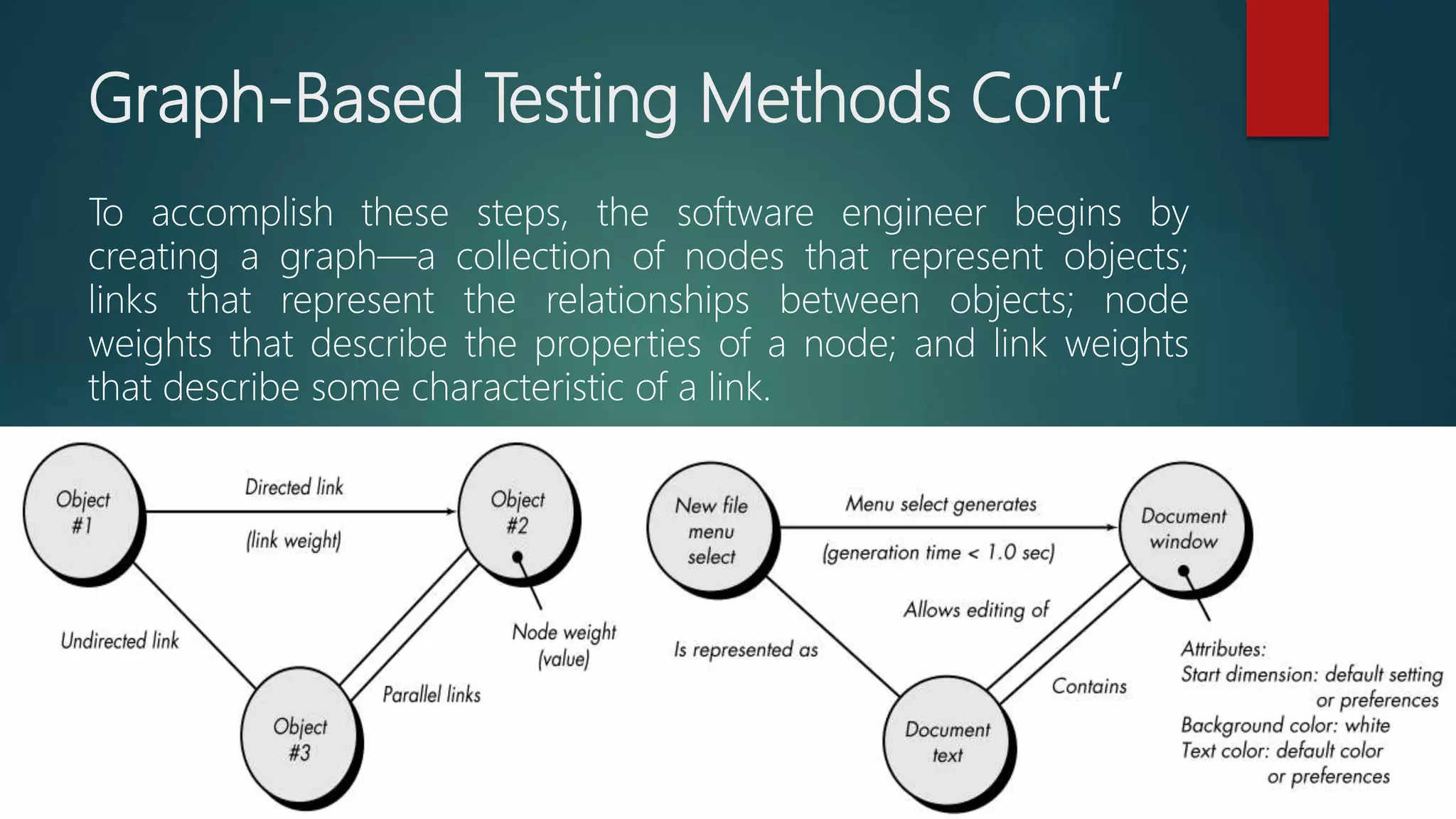
Graph-based testing methods to evaluate relationships and object properties within testing.
A method for deriving test cases reducing total case counts by dividing inputs into equivalent classes.
Identifies focusing on boundary conditions in input domains to conduct effective testing.
Challenges of testing analysis and design models with emphasis on technical reviews.
Testing strategies adapted for OO systems focusing on classes and encapsulations.
Explains unit testing fundamentals within the context of object-oriented programming.
Strategies for integration testing focusing on thread-based and use-based testing approaches.
Validation process in OO software concentrating on user interactions and use-case-driven tests.
Guidelines for creating effective test cases aimed at OO systems, balancing details with clarity.
Discusses how OO concepts impact the test case design and different methods employed.
Approaches to creating tests that explore plausible faults in OO systems and their existence.
Exploration of how OO programming changes fault prevalence and testing complexity.
Focuses on scenarios for uncovering specification errors through a user's interaction.
Testing methods aimed specifically at single classes, including random and partitioning tests.
Techniques for categorizing input/output in class operations to streamline test case development.
Challenges of testing interactions among class collaborations in OO systems.
Focused approach for generating test sequences for client-server class interactions.
Utilizing state transition diagrams for dynamic behavior testing in object-oriented contexts.























































































