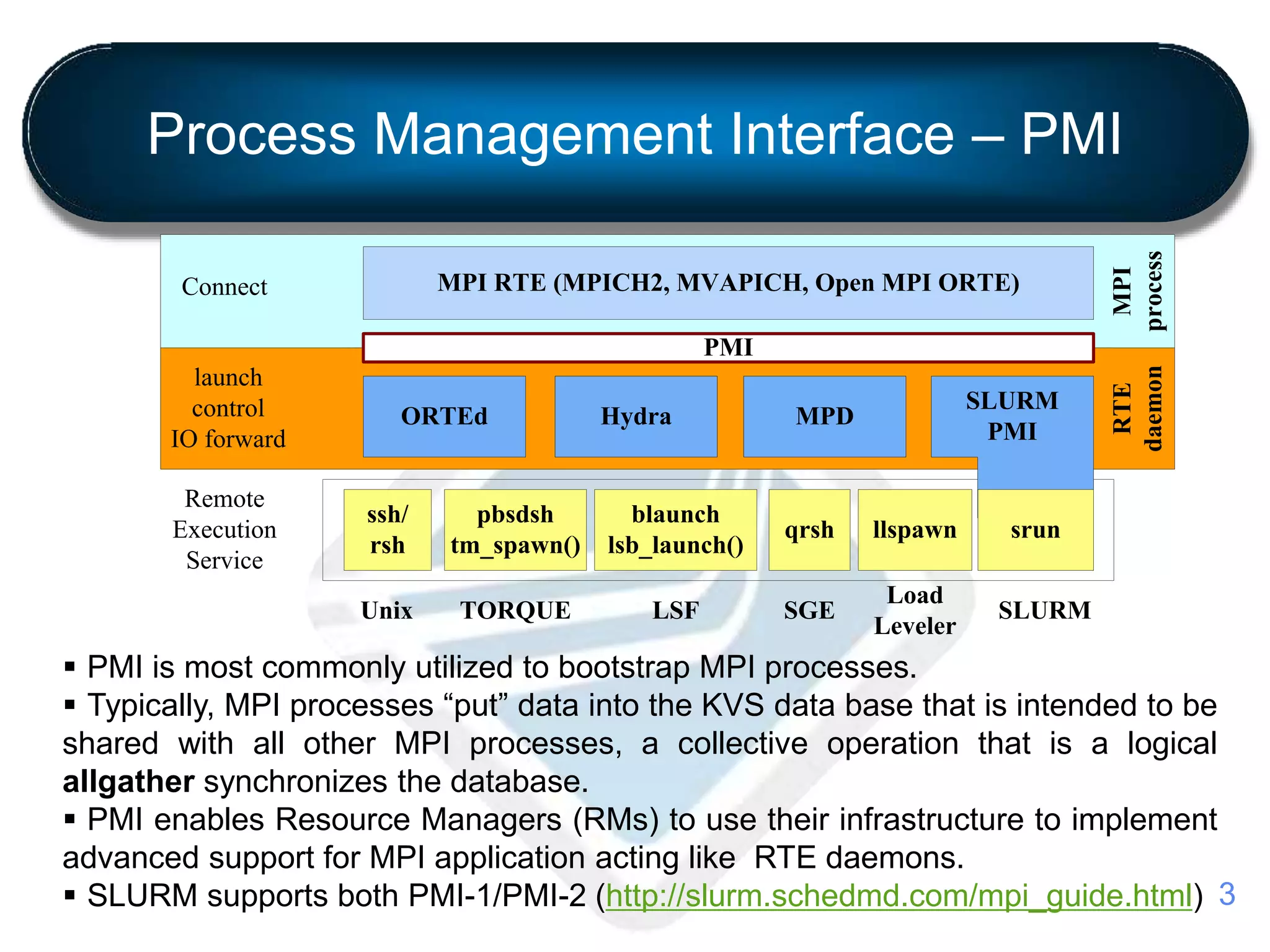
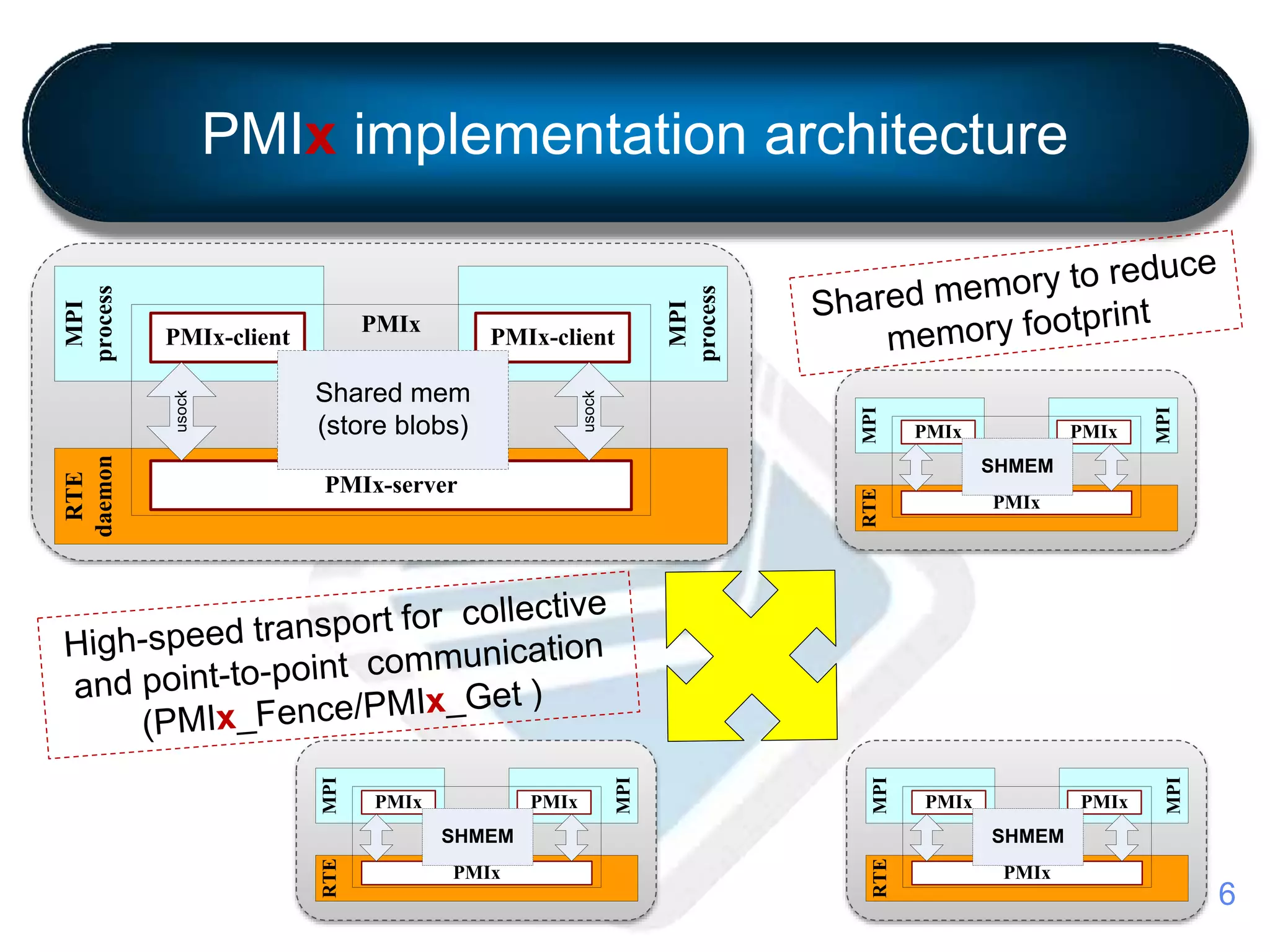
This document introduces PMIx, an extended Process Management Interface for exascale systems. PMIx is a collaborative open source effort led by Intel, Mellanox Technologies, and Adaptive Computing to address limitations of current PMI standards at extreme scale. Version 1.0 focuses on reducing memory footprint and communication overhead. Version 2.0 adds performance optimizations like distributed databases and collective operations. A SLURM plugin implements PMIx support and will be included in the next major SLURM release. The project timeline outlines ongoing development and integration with resource managers and runtimes through 2017.