This document discusses Aardvark, a large-scale social search engine. It begins with an abstract that introduces social search engines and notes how Aardvark differs from traditional hypertextual search engines by using a user's social network as an information source rather than documents. The document then covers Aardvark's architecture, how it works by socially crawling profiles, indexing people, analyzing questions, ranking results, and its user interface. Examples are provided to illustrate how Aardvark routes questions to experts in a user's network to provide answers, unlike traditional search engines that return documents.






![Aardvark : Large - Scale Social Search Engine
1.2 What is Aardvark?
Actually the aardvark is a medium - sized, burrowing, nocturnal mammal (Figure
:4.1a) native to Africa. It is a nocturnal feeder, it subsists on ants and termites,
which it will dig out of their hills using its sharp claws and powerful legs. It also
will utilize its digging ability to create burrows in which to live and rear its young.
It receives a ”least concern” rating from the IUCN, although its numbers seem to
be decreasing.
(a) Aardvark Animal (b) Search Engine Logo
Figure 1.2: Aardvark Search Engine and Animal
Aardvark is a social search engine (Figure:4.1b) based on the village paradigm.
Detailed description is also provided based on the architecture, ranking algorithms,
and user interfaces in Aardvark, and the design considerations that was being moti-
vated . Aardvark is believed to be useful to the research community for two reasons.
First, the argument made in the original Anatomy paper[1] still holds true since
most search engine development is done in industry rather than academia, the re-
search literature describing end-to-end search engine architecture is limited to their
own company as a result knowledge is not flourishing out. Second, the shift in
paradigm opens up a number of interesting research questions in information re-
trieval, for example around expertise classification, implicit network construction,
and conversation design.
Following the architecture description, a statistical analysis of usage patterns in
Aardvark is also presented. It was found that, as compared to traditional search,
Aardvark queries tend to be long, highly contextualized and subjective. In simple
terms the Aardvark queries tend to be the types of queries that are not well-serviced
by traditional search engines. It was also found out that the vast majority of ques-
tions got answered promptly and satisfactorily, and the users were surprisingly ac-
tive, both in asking and answering. Aardvark performs very well on queries that deal
with opinion, advice, experience, or recommendations, while traditional text-based
search engines remain a good choice for queries that are factual or navigational.
Dept. of Computer Science & Engg. 3 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-7-2048.jpg)



![Aardvark : Large - Scale Social Search Engine
(a) Google (b) Aardvark App in iPhone
Figure 4.1: Aardvark Search Engine versus Google’s Search Engine
It is clear in the Figure that when the Query ”Where can i find a great half day
hike within a short drive of San Francisco? I just moved out here looking for some-
thing great views and varied terrain(I am a strong hiker). Any Tips appreciated.”
was provided as input to the Google’s Search engine its best result was a set of
web links which pointed out to famous hiking organization providing hiking stuffs.
While on the contrary the Aardvark gave the result of the perfect reply as expected
by the user. So this results points that the Hyper textual search engine looks for
the keywords in the query and generate the related documents. So it is nearly as a
static reply and this search engine doesn’t goes for the meaning for the query. The
meaning for a query can only be understood by a human as a result Aardvark gave
the optimal result as it is not static and its not form a library.
The main intention to launch Aardvark was Resource Enlargement. If there was
provision provided in this system that keep tracks of the ongoing queries being pro-
cessed and then store the optimal result for all kind of questions then the Search
Engine will be more and more smarted and will be more like a Non Living Friend
with whom a user can clarify the queries. Aardvark is used for asking subjective
questions for which human judgment or recommendation was desired. It was also
used extensively for technical support questions. Users could also review question
and answer history and other settings on the Aardvark website. Google acquired
Aardvark for 50 million dollars on February 11, 2010.[3][4]. In September 2011,
Google announced it would discontinue a number of its products, including Aard-
vark.
Dept. of Computer Science & Engg. 7 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-11-2048.jpg)
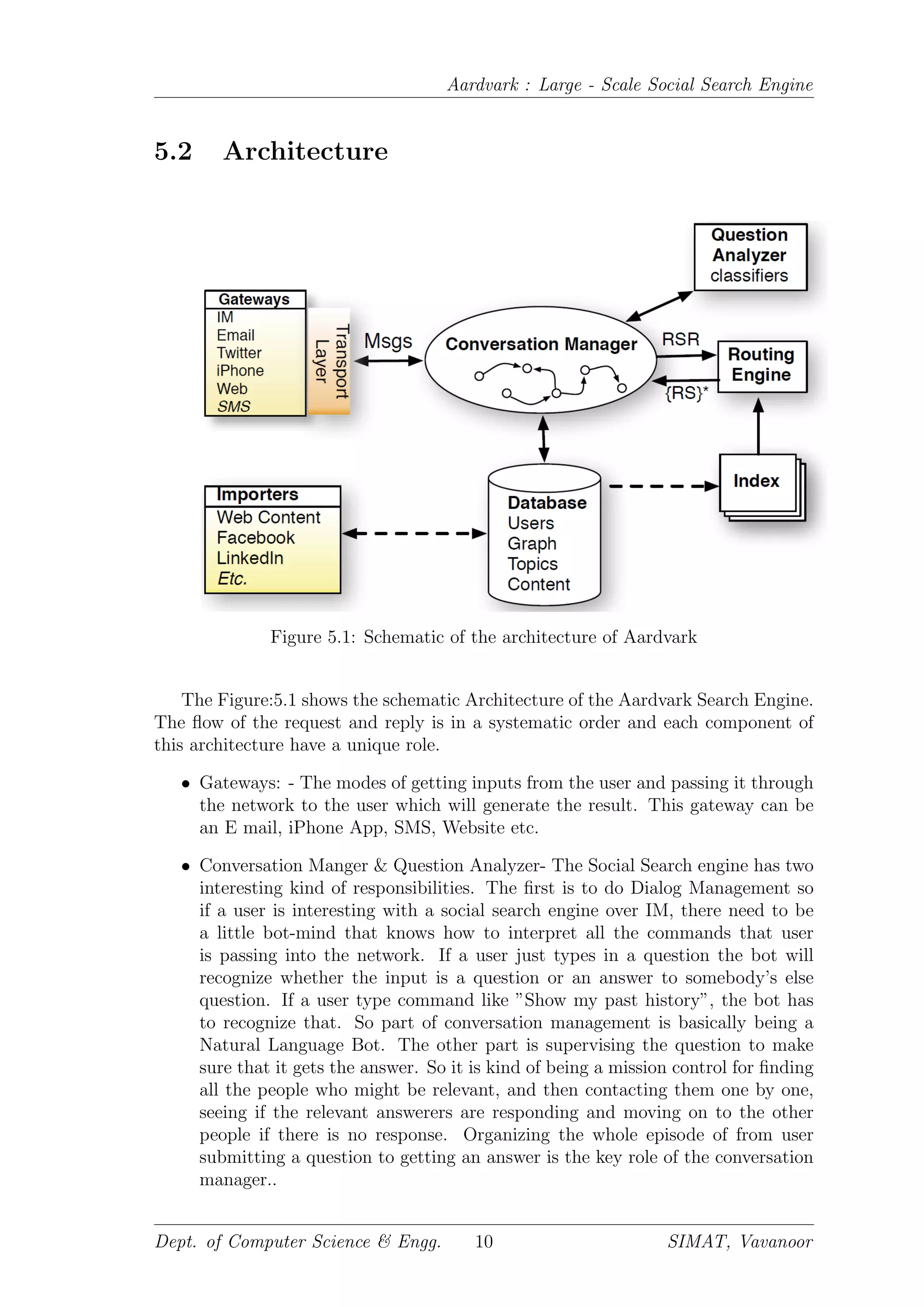
![Chapter 5
Aardvark Architecture
The main components of Aardvark are:
1. Crawler and Indexer - These two parameters are used to find and label re-
sources that contains the correct information about the query being asked
here the resources are in the sense of the human beings not documents.
2. Query Analyzer - As mentioned earlier the Query which is provided as an
input is a highly complex query. From this query the meaning or the purpose
has to be extracted not the important keywords.
3. Ranking Function - As per the Hypertextual Search engine where the resource
pages are ranked, here some what a similar process i carried out where the
answerer is ranked based on the result the answerer generated for a query.
4. User Interface - To present the information to the user in an accessible and
interactive form. The main forms of user interface is by mobile phone apps, e
mails, Web pages, Instant Messaging.
Most document - based search engines have similar key components with similar
aims[1], but the means of achieving those aims are quite different. Before discussing
in detail about Aardvark , it is useful to describe what happens behind the scenes
when a new user joins Aardvark and when a user asks a question to Aardvark.
5.1 Sign Up Process of a User
The strength of the Aardvark lies in the number of users in the Aardvark network,
because more the number of user ,more is the information resources in the network.
Every individual may possess information of same or different or new things, but
the level of information varies from user to user. Some user may have high knowl-
edge about a particular topic while some possess less knowledge. Based on these
factors individuals are separated form each other. So the prime goal here is to know
the information possessed by the user and this process has to be done in a simple
format. When a new user first joins Aardvark, the Aardvark system performs a
number of indexing steps in order to be able to direct the appropriate questions to
her for answering.
8](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-12-2048.jpg)
![Aardvark : Large - Scale Social Search Engine
The questions in Aardvark are routed to the user’s extended network, the first step
involves indexing friendship and affiliation information. For this process of affiliating
information, the data structure responsible for is the Social Graph [16]. The Social
Graph in the Internet context is a graph that depicts personal relations of Internet
users. In short, it is a social network, where the word graph has been taken from
graph theory to emphasize that rigorous mathematical analysis will be applied as
opposed to the relational representation in a social network. The social graph has
been referred to as ”the global mapping of everybody and how they’re related”.
Aardvark is not to aiming to build a social network, but rather to allow people
to make use of their existing social networks like facebook, twitter, hangouts, gmail
contacts etc. . So in the sign-up process, a new user has the option of connecting to
a/many social network such as Facebook or LinkedIn, importing their contact lists
from a web mail program, or manually inviting friends to join. Additionally, any-
body whom the user invites to join Aardvark is appended to their Social Graph and
such invitations are a major source of new users. Finally, Aardvark users are con-
nected through common groups which reflect real-world affiliations they have, such
as the schools they have attended and the companies they have worked at; these
groups can be imported automatically from social networks, or manually created by
users. Aardvark indexes this information and stores it in the Social Graph, which
is a fixed width ISAM index sorted by userId. ISAM stands for Indexed Sequential
Access Method, a method for indexing data for fast retrieval. In an ISAM system,
data is organized into records which are composed of fixed length fields. Records are
stored sequentially, originally to speed access on a tape system. A secondary set of
hash tables known as indexes contain ”pointers” into the tables, allowing individual
records to be retrieved without having to search the entire data set.
Simultaneously, Aardvark indexes the topics about which the new user has some
level of knowledge or experience. This topical expertise can be gathered from sev-
eral sources by using several methods: a user can indicate topics in which he believes
himself to have expertise; a user’s friends can indicate which topics they trust the
user’s opinions about; a user can specify an existing structured profile page from
which the Topic Parser parses additional topics; a user can specify an account on
which they regularly post status updates (e.g. Twitter or Facebook), from which the
Topic Extractor extracts topics (from unstructured text) in an ongoing basis and
finally, the Aardvark also observes the user’s behavior on Aardvark, in answering
a type of questions,or electing not to answer to which kind of questions or about
particular topics.
The set of topics associated with a user is recorded in the Forward Index, which
stores each userId, a scored list of topics, and a series of further scores about a
user’s behavior (e.g., responsiveness or answer quality). From the Forward Index,
Aardvark constructs an Inverted Index. The Inverted Index stores each topicId and
a scored list of userIds that have expertise in that topic. In addition to topics, the
Inverted Index stores scored lists of userIds for features like answer quality and re-
sponse time. Once the Inverted Index and Social Graph for a user are created, the
user is now active on the system and ready to ask her first question.
Dept. of Computer Science & Engg. 9 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-13-2048.jpg)

![Chapter 6
How Aardvark Works?
6.1 Work Model
The core functionality of Aardvark is a statistical model which does the job of routing
questions to potential answerers, because the answer and the question generator both
are a fine end users. Aardvark uses a network variant of what has been called an
aspect model[5], that has two primary features. First, it associates an unobserved
class(i.e the question and topic being asked) variable t ∈ T with each observation
(i.e., the successful answer of question q by user ui). This probability is to find the
relevance of the user ui in answering the topic t. In other words it can be stated
that the probability p(ui|q) that user i will successfully answer question q depends on
whether q is about the topics t in which ui has expertise and it is query dependent:
p(ui, q) =
t∈T
p(ui|t)p(t|q) (6.1)
The second main feature of the model is that it defines a query-independent prob-
ability of success for each potential asker/answerer pair (ui, uj), based upon their
degree of social connectedness, the intimacy and profile similarity between the asker
and the answerer. This is indirectly referencing to the bondage between two friends
for solving each others problem though the answerer may not be expertise in an-
swering the topic. In other words, we define a probability p(ui|uj) that user ui will
deliver a satisfying answer, i.e the quality of the answer to the topic, to user uj ,
regardless of the question. We then define the scoring function s(ui, uj, q) as the
composition of the two probabilities.
s(ui, uj, q) = p(ui, uj).p(ui, q) = p(ui, uj).
t∈T
p(ui|t)p(t|q) (6.2)
The main goal in the ranking problem is: given a question q from user uj, return a
ranked list of users ui ∈ U that maximizes s(ui, uj, q).
It is very interesting to note that the scoring function is composed of a query depen-
dent relevance score p(ui|q) and a query-independent quality score p(ui|uj). This
bears similarity to the ranking functions of traditional text-based search engines
such as Google[1]. The difference is that unlike quality scores like Page Rank[6],
Aardvark’s quality score aims to measure intimacy between the askers and the an-
swerers rather than authority, of a document. And unlike the relevance scores in
12](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-16-2048.jpg)
![Aardvark : Large - Scale Social Search Engine
hypertext-based search engines, Aardvark’s relevance score aims to measure a user’s
potential to answer a query, rather than a document’s existing capability to answer
a query. Computationally, this scoring function has a number of advantages. It al-
lows real-time routing because it pushes much of the computation off line. The only
component probability that needs to be computed at query time is p(t|q). Comput-
ing p(t|q) is equivalent to assigning topics to a question - in Aardvark it is done by
running a probabilistic classifier on the question at query time. The distribution
p(ui|t) assigns users to topics, and the distribution p(ui|uj) defines the Aardvark
Social Graph. Both of these are computed by the Indexer at sign up time, and then
updated continuously in the background as users answer questions and get feedback.
The component multiplications and sorting are also done at query time, but these
are easily parallelize able, as the index is shared by user.
6.2 Social Crawling
The primary goal of any search engine is to intake the query, study the query to
understand the user’s need and then based on the query generate the solution or
solutions to the user. A Knowledge Base (KB)[11] is a technology used to store
complex structured and unstructured information used by a computer system. A
comprehensive Knowledge Base is important for search engines as query distribu-
tions tend to have a long tail [7]. Long tail in the sense the string length of the
query is longer. A Web crawler is an Internet bot that systematically browses the
World Wide Web, typically for the purpose of Web indexing. Web search engines
and some other sites use Web crawling software to update their web content or in-
dexes of others sites’ web content. Web crawlers can copy all the pages they visit for
later processing by a search engine that indexes the downloaded pages so that users
can search them much more quickly. In text-based search engines, the crawling pro-
cess is achieved by large scale crawlers and thoughtful crawl policies. In Aardvark,
the knowledge base consists of people rather than documents, so the methods for
acquiring and expanding a comprehensive knowledge base are quite different.
With Aardvark, the more active users there are in network, the more potential
answerers there are, and therefore the more comprehensive the coverage. More im-
portantly, because Aardvark looks for answerers primarily within a user’s extended
social network, the denser the network, the larger the effective knowledge base. This
suggests that the strategy for increasing the knowledge base of Aardvark crucially
involves creating a good experience for users so that they remain active and are
inclined to invite their friends.
Given a set of active users on Aardvark, the effective breadth of the Aardvark
knowledge base depends upon designing interfaces and algorithms that can collect
and learn.
Dept. of Computer Science & Engg. 13 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-17-2048.jpg)
![Aardvark : Large - Scale Social Search Engine
6.3 Indexing People
Indexing is the process of allocating the actual or the most suitable resource to the
request. The central technical challenge in Aardvark is selecting the right user to
answer a given question originated from another user. In order to do this, the two
main things Aardvark needs to learn about each user ui are:
1. The topics t that the user ui might be able to answer questions about
psmoothed(t|ui)
2. The users uj to whom which user ui is connected p(ui|uj).
Now moving to the first part which is used to describe about the concept of ”topics”
known to a user ui. Aardvark computes the distribution p(t|ui) of topics known by
user ui from the following sources of information:
• Users are prompted to provide at least three topics which they believe they
have expertise about.
• Friends of a user (and the person who invited a user) are encouraged to provide
a few topics that they trust the user’s opinion about.
• Aardvark parses out topics from users existing on line profiles (e.g., Facebook
profile pages, if provided). For such pages with a known structure, a simple
Topic Parsing algorithm uses regular expressions which were manually devised
for specific fields in the pages, based upon their performance on test data. Like
for example if a user takes too many photographs and has joined various groups
of photography then the Aardvark can understand that user is an expertise in
the topics related to photography.
• Aardvark automatically extracts topics from unstructured text on users ex-
isting on line homepage or blogs if provided. For unstructured text, a linear
SVM, Support Vector Machine[17], is a supervised learning models with as-
sociated learning algorithms that analyze data and recognize patterns, used
for classification and regression analysis. SVM identifies the general subject
area of the text, while an ad-hoc named entity extractor is run to extract
more specific topics, scaled by a variant tf-idf score.tf-idf[18] is a numerical
statistic that is intended to reflect how important a word is to a document in
a collection or corpus.
• Aardvark automatically extracts topics from users status message updates
(e.g., Twitter messages, Facebook news feed items, IM status messages, etc.)
and from the messages they send to other users on Aardvark.
The motivation for using these latter sources of profile topic information is a simple
one: if you want to be able to predict what kind of content a user will generate (i.e.,
p(t|ui)), first examine the content they have generated in the past. In this spirit,
Aardvark uses web content not as a source of existing answers about a topic, but
rather, as an indicator of the topics about which a user is likely able to give new
answers on demand.
Dept. of Computer Science & Engg. 14 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-18-2048.jpg)
![Aardvark : Large - Scale Social Search Engine
In simple terms this process involves modeling a user as a content generator, with
probabilities indicating the likelihood he/she will likely respond to questions about
given topics. Each topic in a user profile has an associated score, depending upon
the confidence appropriate to the source of the topic. In addition, Aardvark learns
over time which topics not to send a user questions about by keeping track of cases
when the user:
1. Explicitly ”mutes” a topic
2. Declines to answer questions about a topic when given the opportunity
3. Receives negative feedback on his answer about the topic from another user.
Periodically, Aardvark will run a topic strengthening algorithm. The essential idea
or purpose of this algorithm is that ” if a user has expertise in a topic and most of
his friends also have some expertise in that topic, we have more confidence in that
user’s level of expertise than if he were alone in his group with knowledge in that
area”. Mathematically, for some user ui, has a group of friends U, and user knows
some topic t, if p(t|ui) = 0, then s(t|ui) = p(t|ui)+γ u∈U p(t|u), where γ is a small
constant. The s values are then renormalized to form probabilities.
Aardvark then runs two smoothing algorithms over the list of the topics known
to the user. The purpose of these two algorithms are to record the possibility that
the user may be able to answer questions about additional topics which are not ex-
plicitly recorded in her profile. The first algorithm uses basic collaborative filtering
techniques on topics i.e., based on users with similar topics of the user. For example
if a person knows about photography then he also might knows about the cameras
too. The second algorithm uses semantic similarity. Semantic similarity [19] or se-
mantic relatedness is a metric defined over a set of documents or terms, where the
idea of distance between them is based on the likeness of their meaning or semantic
content as opposed to similarity which can be estimated regarding their syntactical
representation
Once all of these bootstrap, extraction, and smoothing methods are applied, we
have a list of topics and scores for a given user. Normalizing these topic scores so
that t∈T p(t|ui) = 1, we have a probability distribution for topics known by user
ui. Using Bayes Law, we compute for each topic and user:
p(ui|t) =
p(t|ui)p(ui)
p(t)
(6.3)
using a uniform distribution for p(ui) and observed topic frequencies for p(t). Aard-
vark collects these probabilities p(ui|t) indexed by topic into the Inverted Index,
which allows for easy lookup when a question comes in.
Aardvark computes the connectedness between users p(ui|uj) in a number of ways.
While social proximity is very important here, we also take into account similarities
in demographics and behavior. The factors considered here include:
Dept. of Computer Science & Engg. 15 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-19-2048.jpg)

![Aardvark : Large - Scale Social Search Engine
The questions inputed into Aardvark can be classified for better understanding by
following ways[2]:
• NonQuestionClassifier
• InappropriateQuestionClassifier
• TrivialQuestionClassifier
• LocationSensitiveClassifier
A NonQuestionClassifier determines if the input is not actually a question (e.g., is
it a misdirected message, a sequence of keywords, etc.); if so, the user is asked to
submit a new question.
An InappropriateQuestionClassifier determines if the input is obscene, commercial
spam, or otherwise inappropriate content for a public question-answering commu-
nity; if so, the user is warned and asked to submit a new question.
A TrivialQuestionClassifier determines if the input is a simple factual question which
can be easily answered by existing common services (e.g., What time is it now?,
What is the weather?, etc.); if so, the user is offered an automatically generated
answer resulting from traditional web search.
A LocationSensitiveClassifier determines if the input is a question which requires
knowledge of a particular location, usually in addition to specific topical knowledge
(e.g., Whats a great sushi restaurant in Austin, TX?); if so, the relevant location is
determined and passed along to the Routing Engine with the question.
After analyzing and screening a question the next process is to map this question to
relevant topics and from there to the users with knowledge of the topic. The list of
topics relevant to a question is produced by merging the output of several distinct
TopicMapper algorithms[2]:
• KeywordMatchTopicMapper
• TaxonomyTopicMapper
• SalientTermTopicMapper
• UserTagTopicMapper
A KeywordMatchTopicMapper passes any terms in the question which are string
matches with user profile topics through a classifier which is trained to determine
whether a given match is likely to be semantically significant or misleading.
A TaxonomyTopicMapper classifies the question text into a taxonomy of roughly
3000 popular question topics, using an SVM trained on an annotated text of several
millions questions.
A SalientTermTopicMapper extracts salient phrases from the question using a noun-
phrase chunker and a tf-idf based measurer of importance in a document and finds
semantically similar user topics.
A UserTagTopicMapper takes any user tags provided by the asker (or by any would-
be answerers), and maps these to semantically-similar user topics.
Dept. of Computer Science & Engg. 17 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-21-2048.jpg)
![Aardvark : Large - Scale Social Search Engine
At present, the output distributions of these classifiers are combined by weighted
linear combination[8]. The Aardvark TopicMapper algorithms are continuously eval-
uated by manual scoring on random samples of 1000 questions. The topics used for
selecting candidate answerers, as well as a much larger list of possibly relevant topics,
are assigned scores by two human judges, with a third judge adjudicating disagree-
ments. For the current algorithms on the current sample of questions, this process
yields overall scores of 89% precision and 84% recall of relevant topics. In other
words, 9 out of 10 times, Aardvark will be able to route a question to someone with
relevant topics in his her profile; and Aardvark will identify 5 out of every 6 possibly
relevant answerers for each question based upon their topics.
6.5 Ranking Algorithm
Ranking in Aardvark is done by the Routing Engine, which determines an ordered
list of users (or candidate answerers) who should be contacted to answer a question.
To this algorithm the inputs are the details of the asker of the question and the
information about the question derived by the Question Analyzer. The core ranking
function is described by equation 6.2; essentially, the Routing Engine can be seen
as computing equation 6.2 for all candidate answerers, sorting, and doing some
post processing. The main factors that determine this ranking of users are Topic
Expertise p(ui|q), Connectedness p(ui|uj), and Availability.
• Topic Expertise: First, the Routing Engine finds the subset of users who are
semantic matches to the question being asked here. Those users whose profile
topics indicate expertise relevant to the topics which the question is about.
Those users whose profile topics are closer match to the question’s topics are
given higher rank. For the questions which are location-sensitive (as defined
above), then only those users with matching locations in their profiles are
considered for answering.
• Connectedness: Second, the Routing Engine scores each user according to
the degree to which he/she herself - as a person, independently of her topical
expertise - is a good match for the asker for this information query. This part
is more like giving score value to those users who gave the correct and the
most relevant answer to the question being asked. The goal of this scoring is
to optimize the degree to which the asker and the answerer feel more friendship
and trust, arising from their sense of connection and similarity, and meet each
other’s expectations for conversational behavior in the interaction.
• Availability: Third, the Routing Engine prioritizes candidate answerers in
such a way so as to optimize the chances that the present question will be
answered, while also preserving the available set of answerers (i.e., the quantity
of answering resource in the system) as much as possible by spreading out the
answering load across the user base. This involves factors such as prioritizing
users who are currently online (e.g., via IM presence data, iPhone usage, etc.),
who are historically active at the present time-of-day, and who have not been
contacted recently with a request to answer a question.
Dept. of Computer Science & Engg. 18 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-22-2048.jpg)
![Aardvark : Large - Scale Social Search Engine
Given this ordered list of candidate answerers, the Routing Engine then filters out
users who should not be contacted, according to Aardvarks guidelines for preserving
a high-quality user experience. These filters operate largely as a set of rules:
• Do not contact users who prefer to not be contacted at the present time of
day
• Do not contact users who have recently been contacted as many times as their
contact frequency settings permit etc. Since this is all done at query time,
and the set of candidate answerers can potentially be very large, it is useful
to note that this process is parallelize able.
Each Shard[20] in the Index computes its own ranking for the users in that shard,
and sends the top users to the Routing Engine. Shard is a horizontal partition of
data in a database or search engine. Each individual partition is referred to as a
shard or database shard. Each shard is held on a separate database server instance,
to spread load. This is scalable as the user knowledge base grows, since as more
users are added, more shards can be added.
The list of candidate answerers who survive this filtering process are returned to
the Conversation Manager. The Conversation Manager then proceeds with opening
channels to each of them, serially, inquiring whether they would like to answer the
present question; and iterating until an answer is provided and returned to the asker.
6.6 User Interface
Since social search is modeled after the real-world process of asking questions to
friends, the various user interfaces for Aardvark are built on top of the existing com-
munication channels that people use to ask questions to their friends: IM, email,
SMS, iPhone, Twitter, and Web-based messaging. Experiments were also done us-
ing actual voice input from phones, but this is not live in the current Aardvark
production system.
In its simplest form, the user interface for asking a question on Aardvark is any
kind of text input mechanism, along with a mechanism for displaying textual mes-
sages returned from Aardvark. This kind of very lightweight interface is important
for making the search service available anywhere, especially now that mobile device
usage has increased across in the globe.
However, Aardvark is most powerful when used through a chat-like interface that
enables ongoing conversational interaction. A private 1-to-1 conversation creates
an intimacy which encourages both honesty and freedom within the constraints of
real-world social norms. An answering forums where there is a public audience can
both inhibit potential answerers [14] or motivate public performance rather than
authentic answering behavior[15] is a key criteria when the user interface is being
designed. Further, in a real time conversation, it is possible for an answerer to re-
quest clarifying information from the asker about her question, or for the asker to
follow-up with further reactions or inquiries to the answerer.
Dept. of Computer Science & Engg. 19 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-23-2048.jpg)

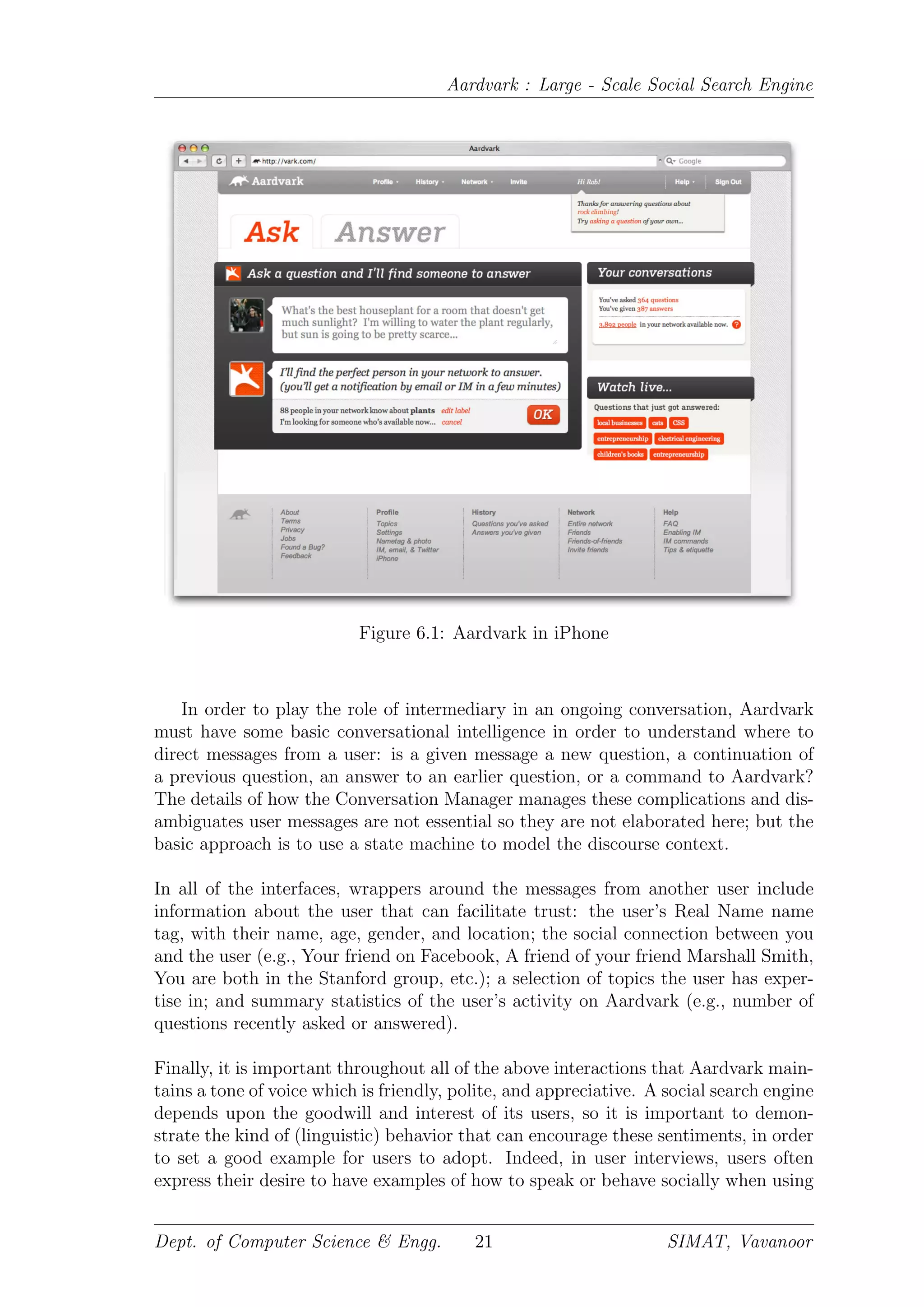
![Aardvark : Large - Scale Social Search Engine
Figure 6.2: Aardvark’s working using a pictorial description
Aardvark; since it is a novel paradigm, users do not immediately realize that they
can behave in the same ways they would in a comparable real world situation of
asking for help and offering assistance. All of the language that Aardvark uses is
intended both to be a communication mechanism between Aardvark and the user
and an example of how to interact with Aardvark. Overall, a large body of research
[9][10][12][13] shows that when you provide a 1-1 communication channel, use real
identities rather than pseudonyms, facilitate interactions between existing real-world
relationships, and consistently provide examples of how to behave, users in an on-
line community will behave in a manner that is far more authentic and helpful than
pseudonymous multi casting environments with no moderators. The design of the
Aardvarks UI has been carefully crafted around these principles.
Dept. of Computer Science & Engg. 22 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-26-2048.jpg)
![Aardvark : Large - Scale Social Search Engine
6.7 Example
The better performance and evaluation of any algorithm can only be understood
using an example. This section is illustrating a working model of the Aardvark
network. Before preceding further moving to a recap of what said early it is very
clear that the Aardvark is not an ordinary search engine. Its more complex and
more natural language based search engine which generates real time results for a
query. The figure 6.4 shows a random sample of questions asked on Aardvark when
the Aardvark was officially launched in the world’s computer network. From the
figure itself it is very clear that not even a single query from this set of query can be
answered by the traditional text based search engine. The main reason is that these
are subjective questions and can only be answered by a human not a machine or a
document. The below Figure 6.3[2] shows the mostly asked topics on Aardvark.
Figure 6.3: Frequent Questions asked in Aardvark
Figure 6.4: A random set of queries from Aardvark
Dept. of Computer Science & Engg. 23 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-27-2048.jpg)


![Chapter 7
Future Works
From the previous chapters it will be very clear how this Search Engine work, what
are the main criteria and various examples to about how query is being processed
by this search engine. Aardvark was originally developed by The Mechanical Zoo, a
San Francisco-based startup founded in 2007 by Max Ventilla, Nathan Stoll (both
former Google employees), Damon Horowitz and Rob Spiro[21].A prototype ver-
sion of Aardvark was launched in early 2008[with an alpha launch in October 2008.
Aardvark was released to the public in March 2009, although initially new users had
to be invited by existing users. The company did not release usage statistics.
Later Google acquired Aardvark for $50 million on February 11, 2010. The Aard-
vark sucessfully completed two years of development in Google. As shown in the
graph Figure 7.1 the number of Aardvark users were increasing which shows a clear
result of the success of Aardvark. But in September 2011, Google announced
it would discontinue a number of its products, including Aardvark.
Figure 7.1: Increasing number of users in Aardvark.
26](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-30-2048.jpg)


![Bibliography
[1] S. Brin and L. Page. The anatomy of a large-scale hypertextual Web search
engine. In WWW Conference, 1998.
[2] D. Horowitz and Sepandar D. Kamvar, The Anatomy of a Large-Scale Social
Search EngineDamon Horowitz. In WWW Coference, 2010
[3] ”Google Acquires Aardvark For 50 million (Confirmed)”. TechCrunch.
techcrunch.com. Archived from the original on February 13, 2010. Retrieved
February 12, 2010.
[4] ”Google Acquires Aardvark”. Official Google Blog. Google. Archived from the
original on February 14, 2010. Retrieved February 12, 2010.
[5] T. Hofmann. ”Probabilistic latent semantic indexing”. In SIGIR, 1999.
[6] L. Page, S. Brin, R. Motwani, and T. Winograd. ”The PageRank citation rank-
ing: Bringing order to the Web”. Stanford University Technical Report, 1998.
[7] B. J. Jansen, A. Spink, and T. Sarcevic. ”Real life, real users, and real needs:
a study and analysis of user queries on the web”. Information Processing and
Management, 2000.
[8] D. Klein, K. Toutanova, H. T. Ilhan, S. D. Kamvar, and C. D. Man-
ning.”Combining heterogeneous classifiers for word-sense disambiguation”. In
SENSEVAL, 2002.
[9] H. Bechar-Israeli. From <Bonehead> to <cLoNehEAd>: Nicknames, Play, and
Identity on Internet Relay Chat. Journal of Computer-Mediated Communica-
tion, 1995.
[10] A. R. Dennis and S. T. Kinney. ”Testing media richness theory in the new me-
dia: The effects of cues, feedback, and task equivocality”. Information Systems
Research, 1998.
[11] Green, Cordell, D. Luckham, R. Balzer, T. Cheatham, C. Rich (1986). ”Report
on a knowledge-based software assistant”. Readings in artificial intelligence and
software engineering (M. Kaufmann): Page Number: 377 - 428.
[12] J. Donath. ”Identity and deception in the virtual community”. Communities in
Cyberspace Conference, 1998.
[13] L. Sproull and S. Kiesler. ”Computers, networks, and work. In Global Net-
works”, Computers and International Communication. MIT Press, 1993.
29](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-33-2048.jpg)
![Aardvark : Large - Scale Social Search Engine
[14] M. R. Morris, J. Teevan, and K. Panovich. ”What do people ask their social
networks, and why? A Survey study of status message Q&A behavior”. In CHI,
2010.
[15] M. Wesch. ”An anthropological introduction to YouTube”. Library of Congress
Summit, 2008.
[16] C. McCarthy. ”Facebook: One Social Graph to Rule Them All?”. CBS News.
Web July 11, 2010.
[17] R. Cuingnet, C. Rosso, M. Chupin, S. Lehricy, D. Dormont, H. Benali, Y.
Samson and O. Colliot, ”Spatial regularization of SVM for the detection of
diffusion alterations associated with stroke outcome”, Medical Image Analysis
Conference, 2011.
[18] Rajaraman, A. Ullman; ”Data Mining Mining of Massive Datasets”, WWW
Conference, 2011
[19] Harispe S., Ranwez S. Janaqi S., Montmain J. ”Semantic Measures for the Com-
parison of Units of Language, Concepts or Entities from Text and Knowledge
Base Analysis”, Arxiv Corporation, August 2013.
[20] R. Roy. ”Shard - A Database Design”, International Conference on Database
Study, Geneva, July 28, 2008.
[21] D. Horowitz.”Mechanical Zoo Gets $6 Million To Build Aardvark Social Search
Product”. TechCrunch. techcrunch.com.Web. March 14, 2009.
Dept. of Computer Science & Engg. 30 SIMAT, Vavanoor](https://image.slidesharecdn.com/slideshare-150122113107-conversion-gate02/75/Aardvark-Social-Search-Engine-34-2048.jpg)







![[100621]제안발표](https://cdn.slidesharecdn.com/ss_thumbnails/100621-100621200046-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













































