Assignment
Design anN-tap transposed linear-phase FIR filter as a sequential
application specific processor. Use only one multiplier and show how
processing time can be decreased twice.
Hint: design a transposed FIR filter structure as in the previous slide
but allow for generating the sums in reversed order PSN-1, PSN-2, …,
PS1, y(n).
1
Copied from [Wanhammer99]
Sequential application
specific processor
A processor tuned only for a particular application
Can be used for low-power implementations
Word lengths can be adjusted to the current problem.
Example: FIR filter
4
5.
Outline
FIR filters
Structures
Polyphase FIR filters
Parallel polyphase FIR
Decimated FIR
Implementations of FIR filters
5
6.
General purpose processor
architecture
FIR example
We will study RISC architectures
Single-cycle processor
Implementation of add and load instructions
Pipelined implementation
Why do all instructions have the same number of cycles
6
7.
Example: Digital Filtering
The basic FIR Filter equation is
Where h[k] is an array of constants
7
]
[
].
[
]
[ k
n
x
k
h
n
y
In C language
y[n]=0;
For (n=0; n<N;n++)
{
For (k = 0;k<N;k++)
//inner loop
y[n] = y[n] + h[k]*x[n-k];}
Only Multiply
and Accumulate
(MAC) is needed!
Copied from Rony Ferzli: http://www.fulton.asu.edu/~karam/eee498/
8.
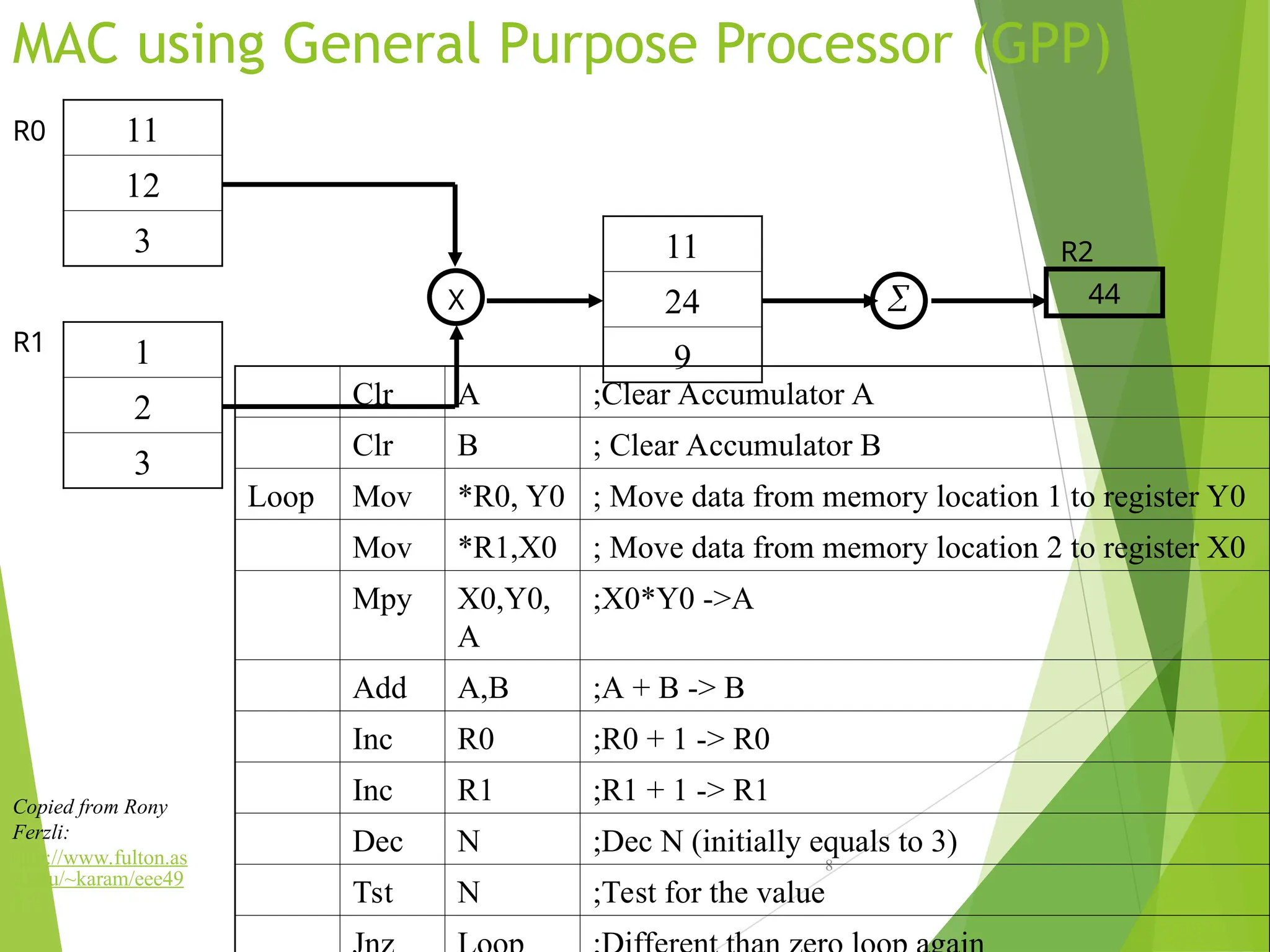
MAC using GeneralPurpose Processor (GPP)
8
1
2
3
11
12
3
X
11
24
9
44
R0
R1
R2
Clr A ;Clear Accumulator A
Clr B ; Clear Accumulator B
Loop Mov *R0, Y0 ; Move data from memory location 1 to register Y0
Mov *R1,X0 ; Move data from memory location 2 to register X0
Mpy X0,Y0,
A
;X0*Y0 ->A
Add A,B ;A + B -> B
Inc R0 ;R0 + 1 -> R0
Inc R1 ;R1 + 1 -> R1
Dec N ;Dec N (initially equals to 3)
Tst N ;Test for the value
Copied from Rony
Ferzli:
http://www.fulton.as
u.edu/~karam/eee49
8/
9.
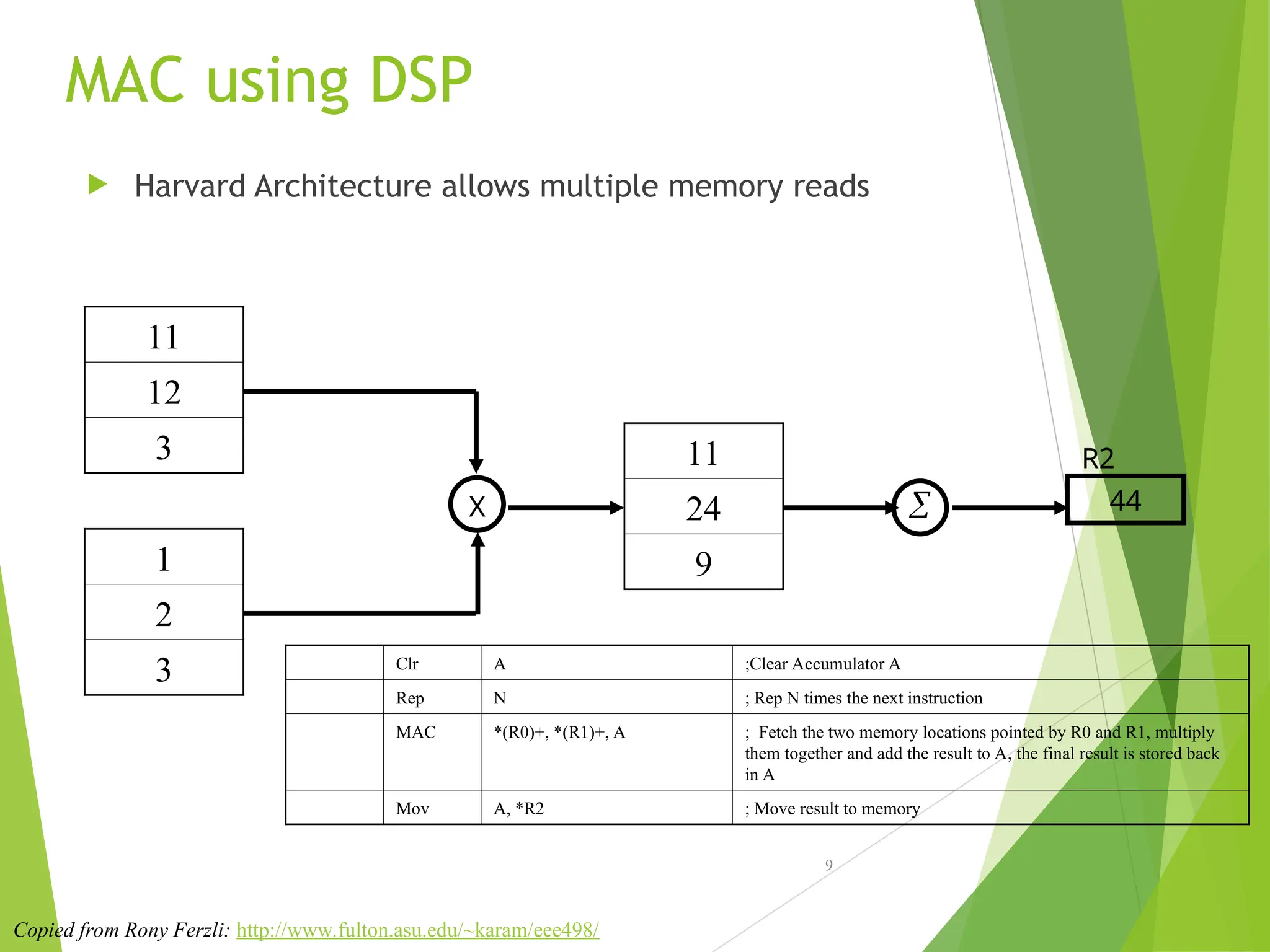
MAC using DSP
Harvard Architecture allows multiple memory reads
9
Clr A ;Clear Accumulator A
Rep N ; Rep N times the next instruction
MAC *(R0)+, *(R1)+, A ; Fetch the two memory locations pointed by R0 and R1, multiply
them together and add the result to A, the final result is stored back
in A
Mov A, *R2 ; Move result to memory
1
2
3
11
12
3
X
11
24
9
44
R2
Copied from Rony Ferzli: http://www.fulton.asu.edu/~karam/eee498/
![Assignment
Design an N-tap transposed linear-phase FIR filter as a sequential
application specific processor. Use only one multiplier and show how
processing time can be decreased twice.
Hint: design a transposed FIR filter structure as in the previous slide
but allow for generating the sums in reversed order PSN-1, PSN-2, …,
PS1, y(n).
1
Copied from [Wanhammer99]](https://image.slidesharecdn.com/test2-250428151859-b780f793/75/Signal-processing-paper-presentation-for-1-2048.jpg)
![Direct form FIR filter
2
Copied from [Wanhammer99]](https://image.slidesharecdn.com/test2-250428151859-b780f793/75/Signal-processing-paper-presentation-for-2-2048.jpg)
![Transposed FIR
3
Copied from [Wanhammer99]](https://image.slidesharecdn.com/test2-250428151859-b780f793/75/Signal-processing-paper-presentation-for-3-2048.jpg)



![Example: Digital Filtering
The basic FIR Filter equation is
Where h[k] is an array of constants
7
]
[
].
[
]
[ k
n
x
k
h
n
y
In C language
y[n]=0;
For (n=0; n<N;n++)
{
For (k = 0;k<N;k++)
//inner loop
y[n] = y[n] + h[k]*x[n-k];}
Only Multiply
and Accumulate
(MAC) is needed!
Copied from Rony Ferzli: http://www.fulton.asu.edu/~karam/eee498/](https://image.slidesharecdn.com/test2-250428151859-b780f793/75/Signal-processing-paper-presentation-for-7-2048.jpg)
![10
Copied from [DSPPrimer-Slides]](https://image.slidesharecdn.com/test2-250428151859-b780f793/75/Signal-processing-paper-presentation-for-10-2048.jpg)























































