Download to read offline


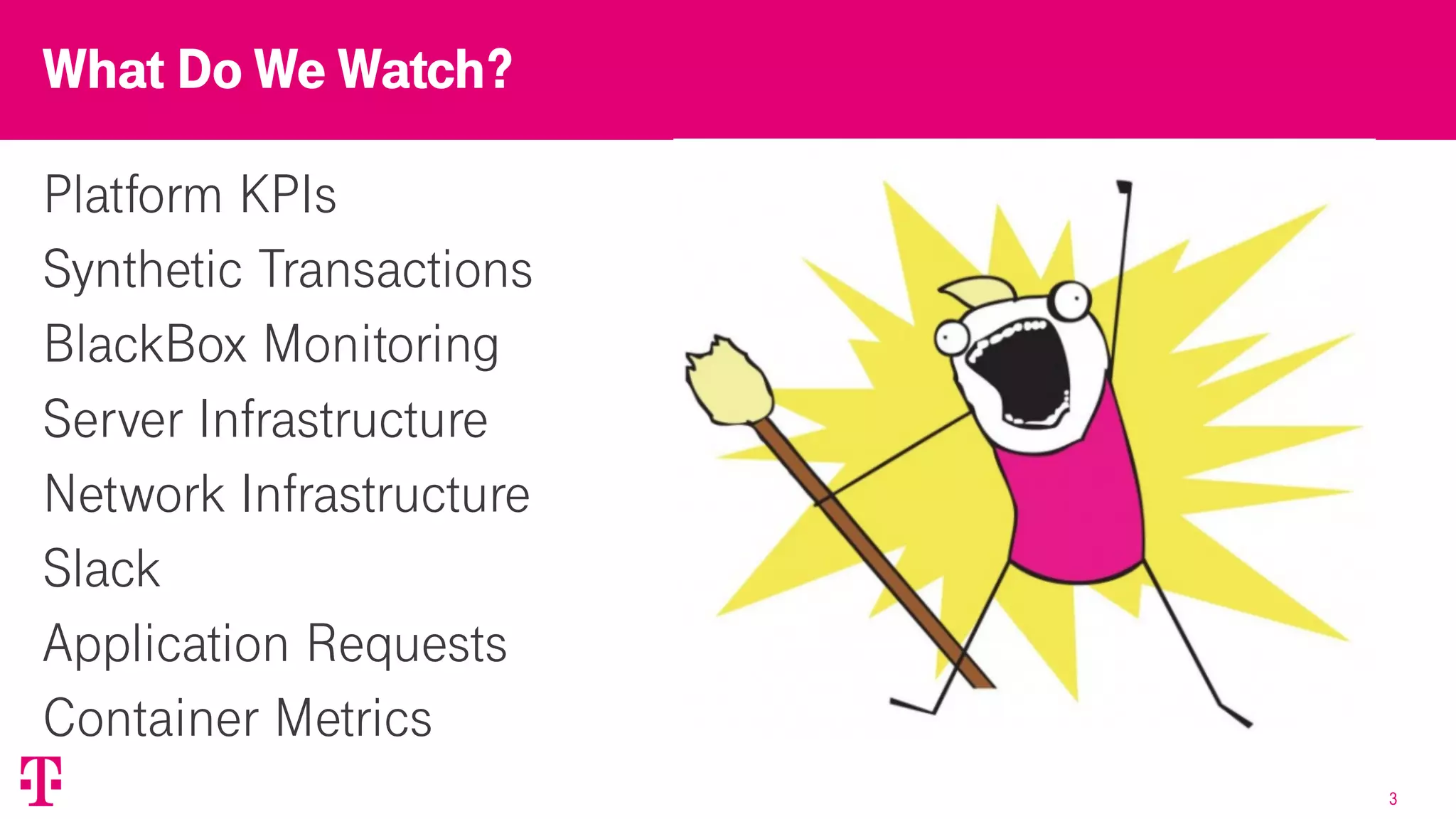
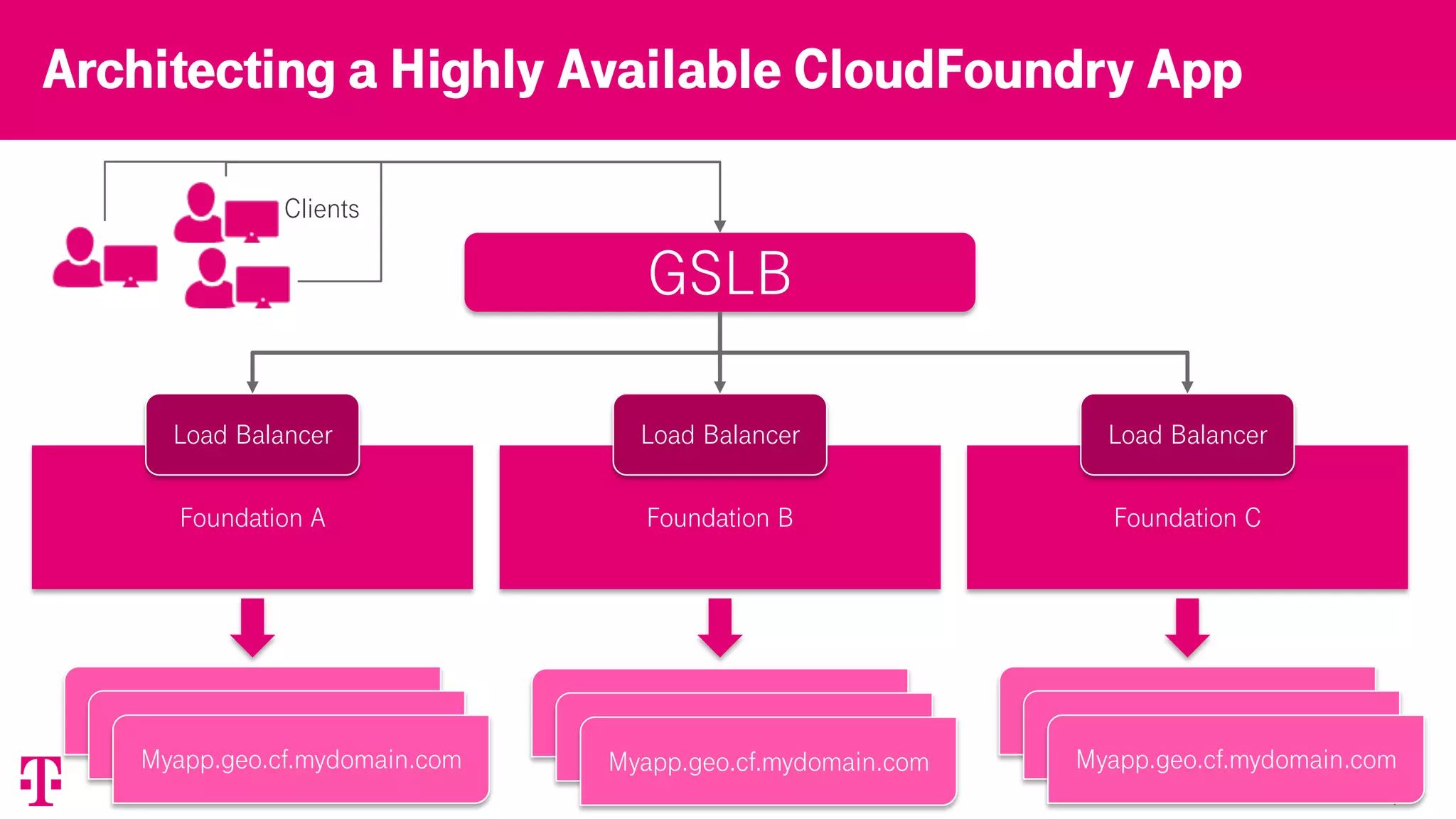










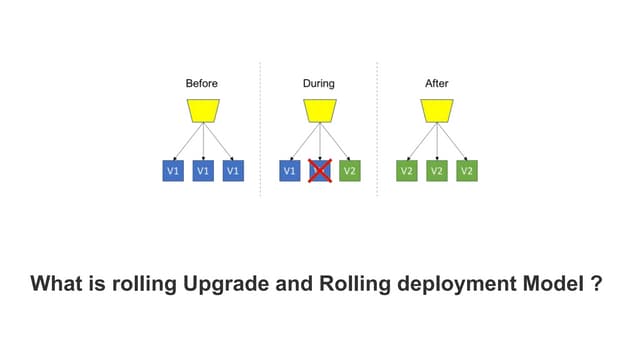
The document discusses T-Mobile's platform architecture and infrastructure, highlighting key performance indicators, load balancing strategies, and incident management. It examines the experiences and lessons learned from technical failures in application deployment on Kubernetes, emphasizing the importance of documentation and customer transparency. The document concludes with recommendations for improving future practices to prevent incidents and enhance collaboration with clients.