SDTpresentaion on testingand sofware all required materials
1.
Most of theSlides are based on:
Roger S Pressman, “Software Engineering: A practitioner’s approach”, 7th Edition, McGraw Hill
Education, 2010.
Rajib Mall, Fundamentals of Software Engineering, PHI Publication, 2009
Software Engineering by Aggrawal
2.
Brief reviewof previous lectures
Introduction to software design
Goodness of a design
Functional Independence
Cohesion and Coupling
Function-oriented design vs. Object-
oriented design
Summary
3.
Introduction tosoftware
engineering
Life cycle models
Requirements Analysis and
Specification:
Requirements gathering and
analysis
Requirements specification
4.
once softwarerequirements have
been analyzed and specified,
software design is the first of three
technical activities
—design, code generation, and
test—that are required to build and
verify the software.
Each activity transforms information
in a manner that ultimately results in
validated computer software.
5.
Design focuseson four major areas of
concern:
◦ data,
◦ architecture,
◦ interfaces, and
◦ components.
At each stage, software design work
products are reviewed for clarity,
correctness, completeness, and
consistency with the requirements and
with one another.
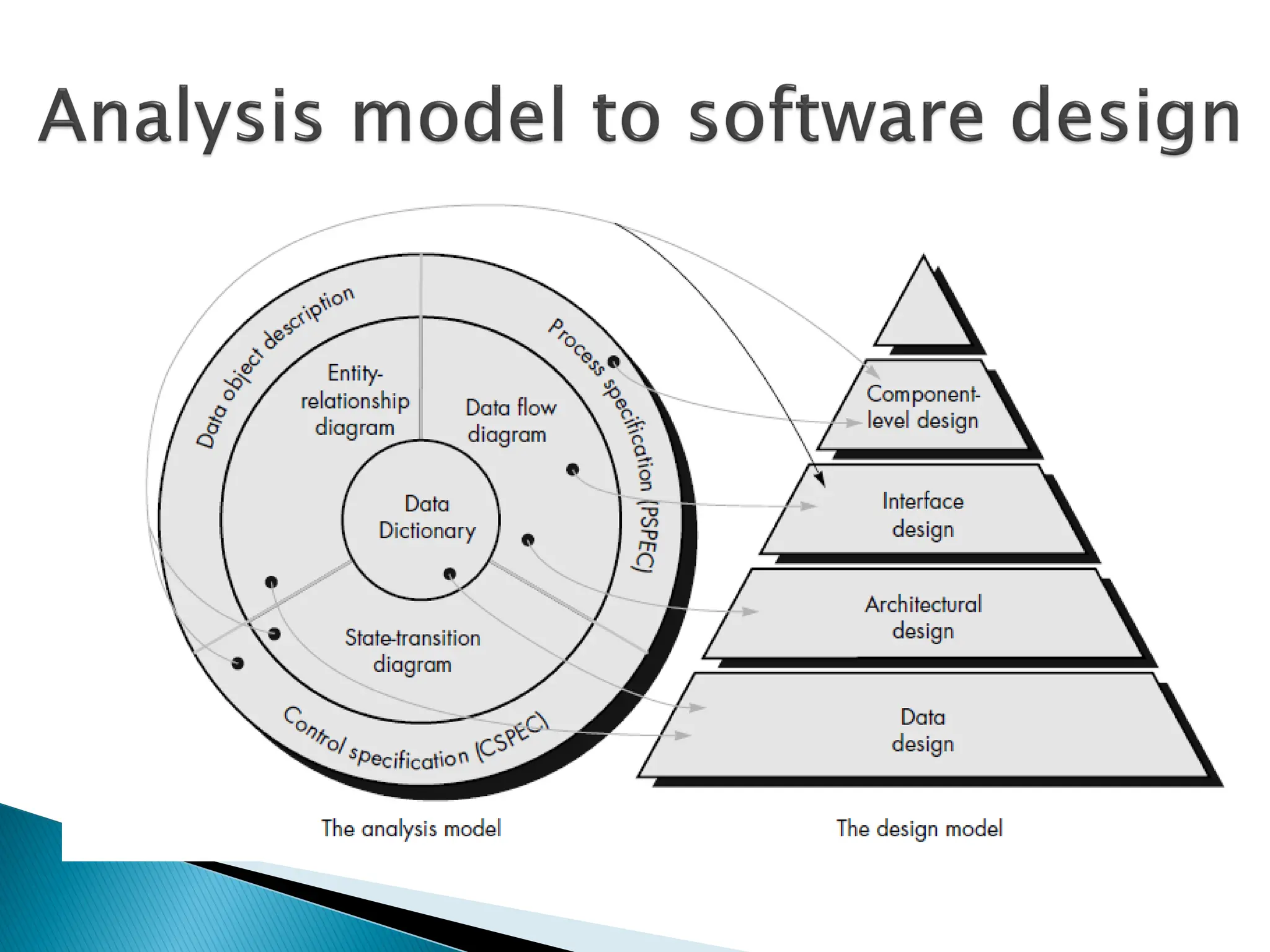
7.
data designtransforms the information domain
model created during analysis into the data
structures that will be required to implement the
software
data objects and relationships defined in the ER
diagram and the detailed data content depicted in
the DD provide the basis for the data design
activity
Part of data design may occur in conjunction with
the design of software architecture
More detailed data design occurs as each
software component is designed
8.
architectural designdefines the relationship
between major structural elements of the
software, the “design patterns” that can be used
to achieve the requirements that have been
defined for the system, and the constraints that
affect the way in which architectural design
patterns can be applied
architectural design representation— the
framework of a computer-based system—can be
derived from the system specification, the
analysis model, and the interaction of subsystems
defined within the analysis model
9.
interface designdescribes how the
software communicates within itself, with
systems that interoperate with it, and
with humans who use it
An interface implies a flow of information
(e.g., data and/or control) and a specific
type of behavior
Therefore, data and control flow diagrams
provide much of the information required
for interface design
10.
component-level designtransforms
structural elements of the software
architecture into a procedural description
of software components
Information obtained from the PSPEC
(Process Specification), CSPEC (Control
Specification) serve as the basis for
component design
During design we make decisions that will
ultimately affect the success of software
construction and, as important, the ease
with which software can be maintained
11.
importance ofsoftware design can be stated with a
single word—quality
Design is the only way that we can accurately
translate a customer's requirements into a finished
software product or system
Software design serves as the foundation for all the
software engineering and software support steps
that follow
Without design, we risk building an unstable
system — one that will fail when small changes are
made; one that may be difficult to test; one whose
quality cannot be assessed until late in software
process
12.
More creativethan analysis
Problem solving activity
Design phase transforms SRS
document:
into a form easily implementable in
some programming language
SRS Document
Design Activities
Design Documents
13.
module structure,
control relationship among the modules
call relationship or invocation relationship
interface among different modules,
data items exchanged among different
modules,
data structures of individual modules,
algorithms for individual modules.
18.
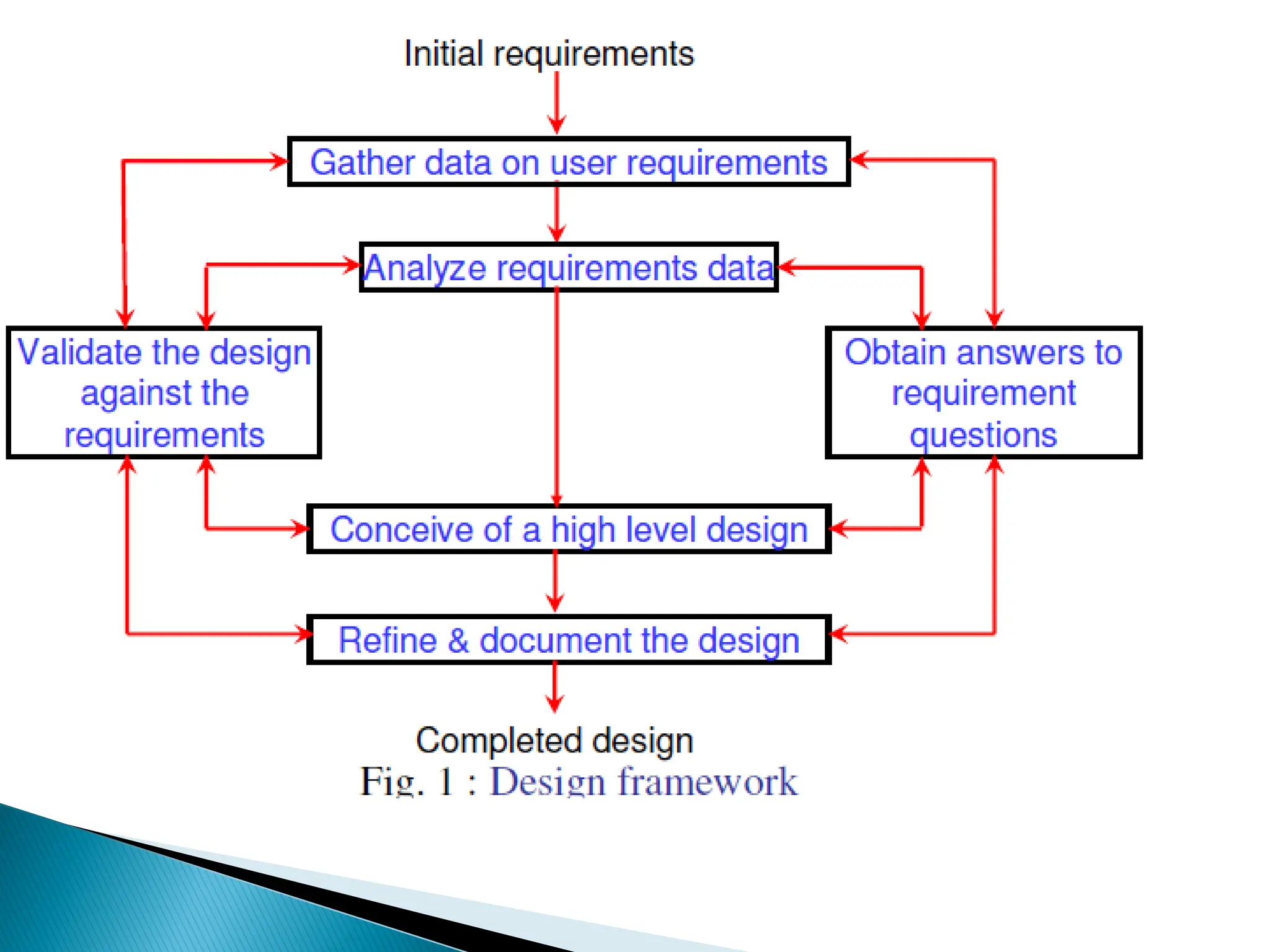
Good softwaredesigns:
seldom arrived through a single
step procedure:
but through a series of steps
and iterations.
19.
Design activitiesare usually classified into
two stages:
preliminary (or high-level) design
detailed design.
Meaning and scope of the two stages:
vary considerably from one methodology to
another.
20.
Through high-leveldesign, a problem
is decomposed into a set of modules.
The control relationships among the
modules are identified, and also the
interfaces among various modules are
identified.
The outcome of high-level design:
program structure (or software
architecture).
21.
Several notationsare available to
represent high-level design:
Usually a tree-like diagram
called structure chart is used.
Other notations:
Jackson diagram or Warnier-
Orr diagram can also be used.
22.
During detaileddesign each module
is examined carefully to design its
data structures and the algorithms.
For each module, design:
data structure
algorithms
Outcome of detailed design:
module specification.
23.
How todistinguish between
good and bad designs?
◦Unless we know what a good
software design is:
we can not possibly design
one.
24.
There isno unique way to
design a system.
Even using the same design
methodology:
◦different engineers can arrive at
very different design solutions.
We need to distinguish between
good and bad designs.
25.
design mustimplement all of the
explicit requirements contained in the
analysis model, and it must
accommodate all of the implicit
requirements desired by the customer -
Should implement all functionalities of
the system correctly.
design must be a readable,
understandable guide for those who
generate code and for those who test
and subsequently support the software -
understandable
26.
design shouldprovide a complete
picture of the software, addressing the
data, functional, and behavioral domains
from an implementation perspective.
Should be easily amenable to change,
◦ i.e. easily maintainable.
Understandability of a design is a
major issue: determines goodness of
design:
◦ a design that is easy to understand:
also easy to maintain and change.
27.
Unless adesign is easy to
understand,
◦ tremendous effort needed to maintain it
◦ We already know that about 60% effort
is spent in maintenance.
If the software is not easy to
understand:
◦ maintenance effort would increase many
times.
good design solution should adequately address
resource, time, and cost optimisation issues.
28.
A designshould exhibit an architectural
structure that
(1) has been created using recognizable design
patterns,
(2) is composed of components that exhibit
good design characteristics
and (3) can be implemented in an evolutionary
fashion, thereby facilitating implementation and
testing.
29.
A designshould be modular; that is, the
software should be logically partitioned
into elements that perform specific
functions and subfunctions.
A design should contain distinct
representations of data, architecture,
interfaces, and components (modules).
A design should lead to data structures
that are appropriate for the objects to
be implemented and are drawn from
recognizable data patterns.
30.
A designshould lead to components
that exhibit independent functional
characteristics.
A design should lead to interfaces that
reduce the complexity of connections
between modules and with the external
environment.
A design should be derived using a
repeatable method that is driven by
information obtained during software
requirements analysis
31.
The designprocess should not suffer from “tunnel
vision.”
◦ A good designer should consider alternative approaches,
judging each based on the requirements of the problem,
the resources available to do the job, and the design
concepts
The design should be traceable to the analysis
model.
◦ Because a single element of the design model often traces
to multiple requirements, it is necessary to have a means
for tracking how requirements have been satisfied by
design model.
32.
The designshould not reinvent the wheel.
◦ Systems are constructed using a set of design patterns,
many of which have likely been encountered before.
These patterns should always be chosen as an
alternative to reinvention. Time is short and resources
are limited! Design time should be invested in
representing truly new ideas and integrating those
patterns that already exist.
The design should “minimize the intellectual
distance” between the software and the problem
as it exists in the real world.
◦ structure of the software design should (whenever
possible) mimic the structure of the problem domain.
33.
The designshould exhibit uniformity and
integration.
◦ A design is uniform if it appears that one person
developed the entire thing. Rules of style and format
should be defined for a design team before design work
begins. A design is integrated if care is taken in defining
interfaces between design components.
The design should be structured to accommodate
change.
34.
The designshould be structured to degrade gently,
even when aberrant data, events, or operating
conditions are encountered.
◦ Well designed software should never “bomb.” It should be
designed to accommodate unusual circumstances, and if it
must terminate processing, do so in a graceful manner
Design is not coding, coding is not design.
◦ Even when detailed procedural designs are created for
program components, the level of abstraction of the design
model is higher than source code. The only design
decisions made at the coding level address the small
implementation details that enable the procedural design
to be coded.
35.
Use consistentand meaningful names
◦ for various design components,
Design solution should consist of:
◦ a cleanly decomposed set of modules
(modularity),
Different modules should be neatly
arranged in a hierarchy:
◦ in a neat tree-like diagram.
36.
Abstraction isone of the fundamental ways that
we as humans cope with complexity.” Grady
Booch
abstraction" permits one to concentrate on a
problem at some level of generalization without
regard to irrelevant low level details;
use of abstraction also permits one to work with
concepts and terms that are familiar in the
problem environment without having to transform
them to an unfamiliar structure
37.
Each stepin the software process is a refinement
in the level of abstraction of the software solution.
During system engineering, software is allocated
as an element of a computer-based system.
During software requirements analysis, the
software solution is stated in terms "that are
familiar in the problem environment."
As we move through the design process, the level
of abstraction is reduced.
Finally, the lowest level of abstraction is reached
when source code is generated.
38.
Procedural abstraction
data abstractions
Control abstraction
A procedural abstraction is a named sequence of
instructions that has a specific and limited
function.
example of a procedural abstraction would be the
word open for a door. Open implies a long
sequence of procedural steps (e.g., walk to the
door, reach out and grasp knob, turn knob and
pull door, step away from moving door, etc.).
39.
A dataabstraction is a named collection of data
that describes a data object
In the context of the procedural abstraction open,
we can define a data abstraction called door.
Like any data object, the data abstraction for door
would encompass a set of attributes that describe
the door (e.g., door type, swing direction, opening
mechanism, weight, dimensions).
It follows that the procedural abstraction open
would make use of information contained in the
attributes of the data abstraction door
40.
Control abstractionis the third form of
abstraction used in software design.
Like procedural and data abstraction, control
abstraction implies a program control mechanism
without specifying internal details.
An example of a control abstraction is the
synchronization semaphore used to coordinate
activities in an operating system.
41.
Modularity isa fundamental
attributes of any good design.
◦ Decomposition of a problem
cleanly into modules:
◦ Modules are almost independent of
each other
◦ divide and conquer principle.
42.
If modulesare independent:
◦ modules can be understood
separately,
reduces the complexity greatly.
◦ To understand why this is so,
remember that it is very difficult to
break a bunch of sticks but very easy
to break the sticks individually.
43.
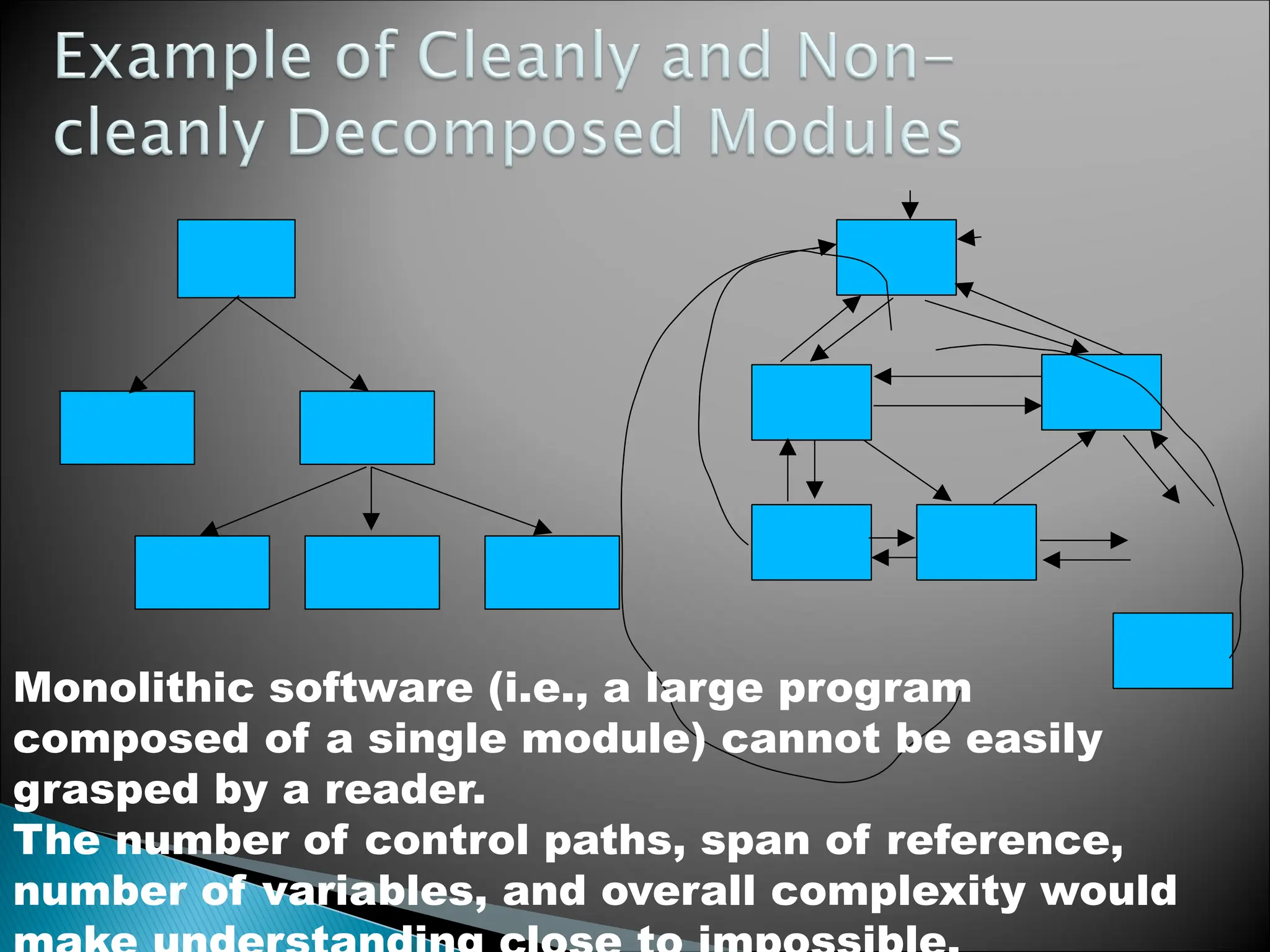
Monolithic software (i.e.,a large program
composed of a single module) cannot be easily
grasped by a reader.
The number of control paths, span of reference,
number of variables, and overall complexity would
44.
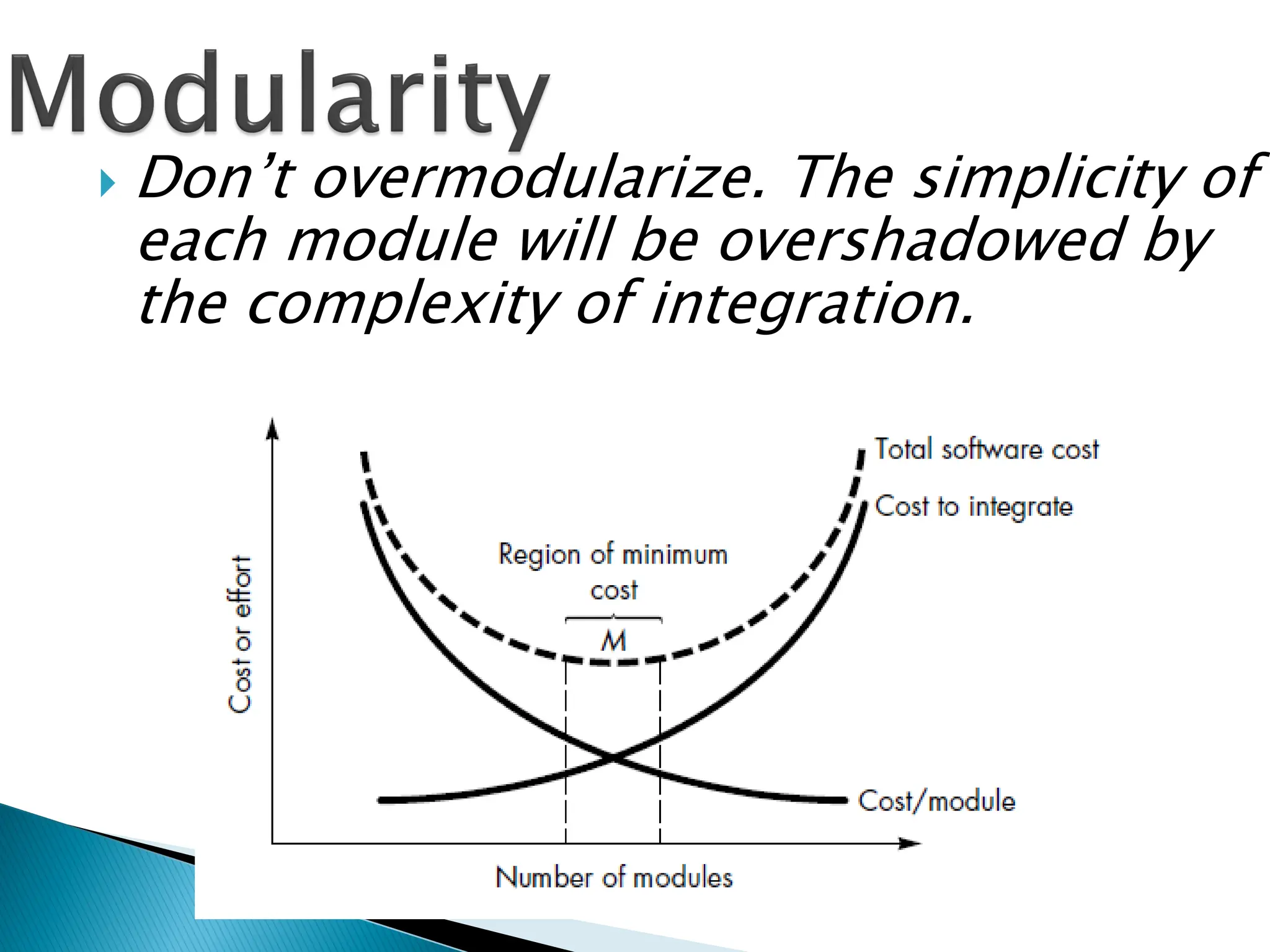
Don’t overmodularize.The simplicity of
each module will be overshadowed by
the complexity of integration.
45.
Unfortunately, thereare no quantitative
metrics available yet to directly measure
the modularity of a design. However, we
can quantitatively characterise the
modularity of a design solution based
on the cohesion and coupling existing
in the design.
A design solution is said to be highly
modular, if the different modules in the
solution have high cohesion and their
inter-module couplings are low.
46.
A modulethat is highly cohesive and also has
low coupling with other modules is said to be
functionally independent of the other modules.
The concept of functional independence is a
direct outgrowth of modularity and the concepts
of abstraction and information hiding
Functional independence is achieved by
developing modules with "single-minded“
function and an "aversion" to excessive
interaction with other modules
47.
Error isolation:
◦Whenever an error exists in a module, functional
independence reduces the chances of the error
propagating to the other modules. The reason
behind this is that if a module is functionally
independent, its interaction with other modules is
low. Therefore, an error existing in the module is
very unlikely to affect the functioning of other
modules.Functional independence reduces error
propagation.
48.
Further, oncea failure is detected,
error isolation makes it very easy to
locate the error.
On the other hand, when a module is
not functionally independent, once a
failure is detected in a functionality
provided by the module, the error
can be potentially in any of the large
number of modules and propagated
to the functioning of the module.
49.
Scope ofreuse:
◦ Reuse of a module for the development of other
applications becomes easier. A functionally independent
module performs some well-defined and precise task and
the interfaces of the module with other modules are very
few and simple. A functionally independent module can
therefore be easily taken out and reused in a different
program.
◦ On the other hand, if a module interacts with several
other modules or the functions of a module perform very
different tasks, then it would be difficult to reuse it. This
is especially so, if the module accesses the data (or code)
internal to other modules.
50.
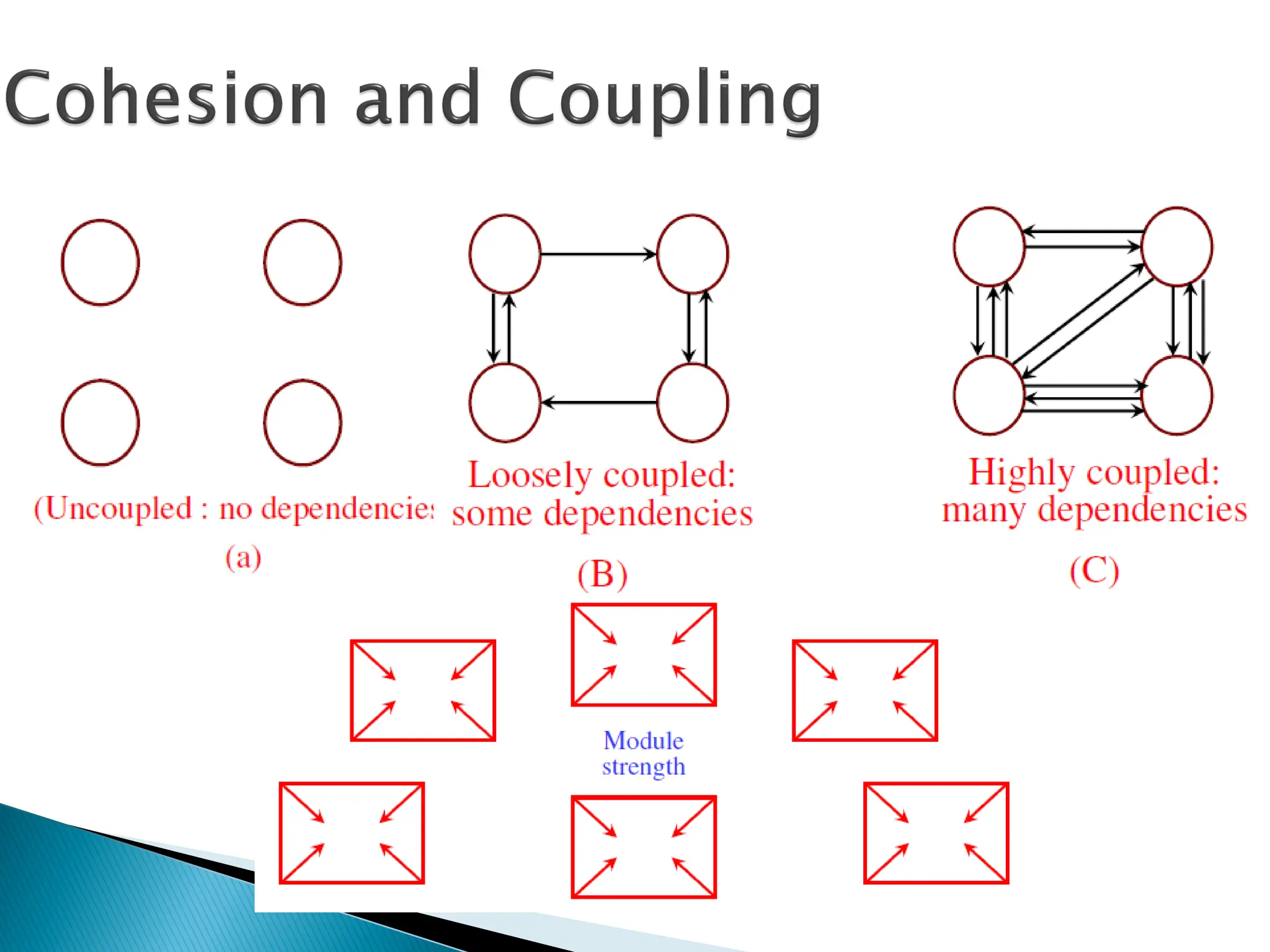
Functional Independenceis
measured using two qualitative
criteria: cohesion and coupling.
Cohesion is a measure of the relative
functional strength of a module.
Coupling is a measure of the relative
interdependence among modules.
51.
Cohesion isa measure of:
◦ functional strength of a module.
◦ A cohesive module performs a
single task or function.
Coupling between two modules:
◦ a measure of the degree of
interdependence or interaction
between the two modules.
53.
class Calculator:
"""Class withlow cohesion - does unrelated tasks."""
def calculate(self, a, b, operation):
"""Handles multiple operations and mixes responsibilities."""
if operation == "add":
return a + b
elif operation == "subtract":
return a - b
else:
return "Invalid operation"
# Main function to run the program
if __name__ == "__main__":
calculator = Calculator()
print(f"Addition: {calculator.calculate(10, 5, 'add')}")
print(f"Subtraction: {calculator.calculate(10, 5, 'subtract')}")
54.
class Calculator: """Classwith high cohesion - each method focuses on a single task."""
def add(self, a, b):
return a + b
def subtract(self, a, b):
return a - b
class CalculatorUser: """Class that depends on Calculator but has low coupling."""
def __init__(self):
self.calculator = Calculator() # Dependency injection
def perform_operations(self, a, b):
"""Perform addition and subtraction using the Calculator class."""
addition_result = self.calculator.add(a, b)
subtraction_result = self.calculator.subtract(a, b)
print(f"Addition: {addition_result}")
print(f"Subtraction: {subtraction_result}")
# Main function to run the program
if __name__ == "__main__":
user = CalculatorUser()
user.perform_operations(10, 5)
55.
Cohesion isa natural extension of the
information hiding concept
A cohesive module performs a single task within
a procedure, requiring little interaction with
procedures being performed in other parts of a
program.
Stated simply, a cohesive module should (ideally)
do just one thing.
Cohesiveness of a module is the degree to which
the different functions of the module co-operate
to work towards a single objective
Cohesion may be represented as a "spectrum."
We always strive for high cohesion, although the
mid-range of the spectrum is often acceptable
56.
Classification isoften subjective:
◦ yet gives us some idea about
cohesiveness of a module.
By examining the type of cohesion
exhibited by a module:
◦ we can roughly tell whether it displays
high cohesion or low cohesion.
At the low(undesirable) end
of the spectrum, we
encounter a module that
performs a set of tasks that
relate to each other loosely, if
at all. Such modules are
termed coincidentally
cohesive.
59.
The module performsa set of
tasks:
◦which relate to each other very
loosely, if at all.
the module contains a random
collection of functions.
functions have been put in the
module out of pure coincidence
without any thought or design.
61.
def print_greeting():
print("Hello, World!")
defadd_numbers(a, b):
return a + b
def get_current_time():
from datetime import datetime
return datetime.now()
These functions are unrelated, grouped together
without a specific purpose, resulting in low cohesion.
62.
A modulethat performs tasks that
are related logically (e.g., a module
that produces all output regardless
of type) is logically cohesive.
All elements of the module perform
similar operations:
◦ e.g. error handling, data input, data
output, etc.
An example of logical cohesion:
◦ a set of print functions to generate an
output report arranged into a single
module.
63.
The functionsare grouped because they are
related to logging, but the specific task is chosen
at runtime.
def log_message(level, message):
if level == "info":
log_info(message)
elif level == "error":
log_error(message)
elif level == "debug":
log_debug(message)
64.
The modulecontains tasks that are related by
the fact:
◦ all the tasks must be executed in the same time
span.
Example:
◦ The set of functions responsible for
initialization,
start-up, shut-down of some process,
etc.
65.
• These functionsare all related to the application's
startup process.
def initialize_application():
load_configuration()
setup_logging()
initialize_database_connection()
66.
When processingelements of a
module are related and must be
executed in a specific order,
procedural cohesion exists.
Though these may work
towards entirely different
purposes and operate on very
different data.
67.
The setof functions of the
module:
◦ all part of a procedure (algorithm)
◦ certain sequence of steps have to be
carried out in a certain order for
achieving an objective,
e.g. the algorithm for decoding a message.
The functions login(), place-order(), check-order(),
printbill(), place-order-on-vendor(), update-
inventory(), and logout() all do different thing and
operate on different data.
68.
The tasksmust occur in a specific order for
the login process to work.
def login_user(username, password):
get_user_input()
authenticate_user(username, password)
redirect_to_dashboard()
69.
When allprocessing elements concentrate on one area
of a data structure,
All functions of the module:
◦ reference or update the same data structure,
Examples:
◦ the set of functions defined on an
array/stack
◦ consider a module named student in which
the different functions in the module such
as admitStudent, enterMarks,
printGradeSheet, etc. access and manipulate
data stored in an array named
studentRecords defined within the module.
70.
def validate_user_input(user_data):
is_valid =validate_data(user_data)
log_validation(user_data, is_valid)
return is_valid
Both validate_data and log_validation operate on the
same user_data.
71.
A moduleis said to possess
sequential cohesion, if the different
functions of the module execute in a
sequence, and the output from one
function is input to the next in the
sequence sort
search
display
72.
In anon-line store consider that after
a customer requests for some item, it
is first determined if the item is in
stock.
In this case, if the functions create-
order(), check-item-availability(),
placeorder- on-vendor() are placed in
a single module, then the module
would exhibit sequential cohesion.
73.
A functionthat processes a string by cleaning it,
converting it to lowercase, and reversing it:
The result of each step is passed to the next,
forming a sequence of dependent tasks.
def process_string(s):
cleaned = clean_string(s)
lowercased = cleaned.lower()
reversed_string = lowercased[::-1]
return reversed_string
74.
Different elementsof a module
cooperate:
◦to achieve a single function,
◦e.g. managing an employee's pay-
roll.
When a module displays
functional cohesion,
◦we can describe the function
using a single sentence.
75.
The module'ssole purpose is to calculate the
factorial, and every line contributes directly to that
goal.
def calculate_factorial(n):
if n == 0:
return 1
return n * calculate_factorial(n - 1)
76.
class FileProcessor:
# FunctionalCohesion: Performs one specific task
def calculate_file_size(file_path):
return os.path.getsize(file_path)
# Sequential Cohesion: Output of one step feeds the
next
def process_file(file_path):
content = read_file(file_path)
cleaned = clean_content(content)
save_processed_file(file_path, cleaned)
# Communicational Cohesion: Works on shared data
def validate_and_log(file_data):
is_valid = validate_file(file_data)
log_file_status(file_data, is_valid)
return is_valid
77.
# Temporal Cohesion:Executes at application startup
def initialize_application():
load_configuration()
setup_logging()
check_dependencies()
# Logical Cohesion: Handles similar operations based on input
def handle_file_operation(operation, file_path):
if operation == "read":
return read_file(file_path)
elif operation == "write":
return write_file(file_path, "Sample Data")
elif operation == "delete":
return delete_file(file_path)
# Coincidental Cohesion: Unrelated tasks (should be avoided)
def unrelated_operations():
print("Task 1: Display greeting")
result = 5 + 10
current_time = datetime.now()
return result, current_time
78.
Write downa sentence to describe
the function of the module
◦If the sentence is compound,
it has a sequential or communicational
cohesion.
◦If it has words like “first”, “next”,
“after”, “then”, etc.
it has sequential or temporal cohesion.
◦If it has words like initialize,
it probably has temporal cohesion.
79.
We cannow make the following
observation. A cohesive module is
one in which the functions interact
among themselves heavily to achieve
a single goal.
As a result, if any of these functions
is removed to a different module,
the coupling would increase as the
functions would now interact across
two different modules.
80.
Coupling isa qualitative indication
of the degree to which a module is
connected to other modules and
to the outside world
Coupling indicates:
◦how closely two modules interact or
how interdependent they are.
◦The degree of coupling between two
modules depends on their interface
complexity.
81.
Two modulesare said to be
highly coupled, if either of the
following two situations arise:
If the function calls between
two modules involve passing
large chunks of shared data,
If the interactions occur through
some shared data,
82.
There areno ways to precisely determine
coupling between two modules:
◦ classification of different types of coupling will
help us to approximately estimate the degree
of coupling between two modules.
The degree of coupling between two modules
depends on their interface complexity.
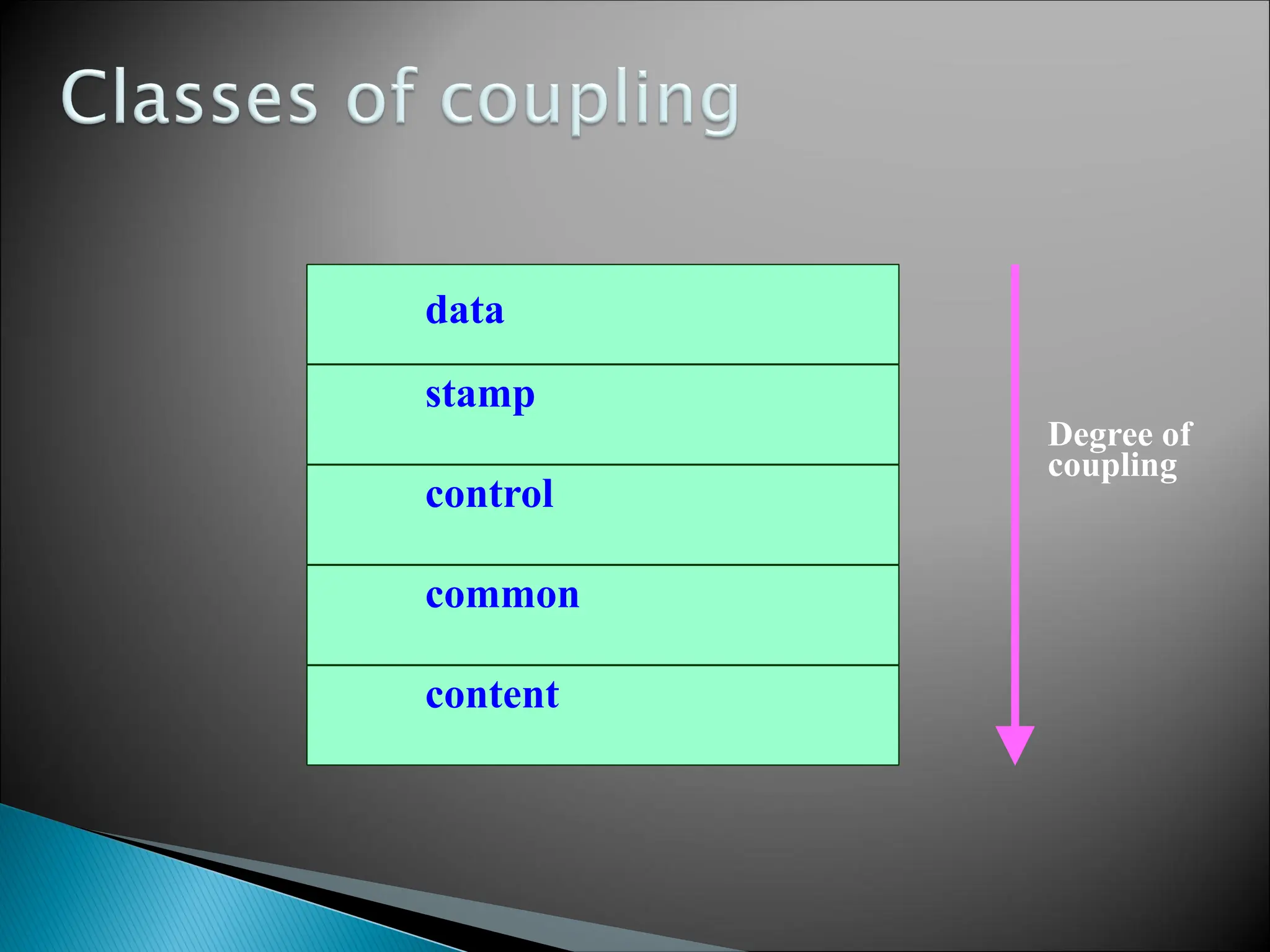
Five types of coupling can exist between
any two modules.
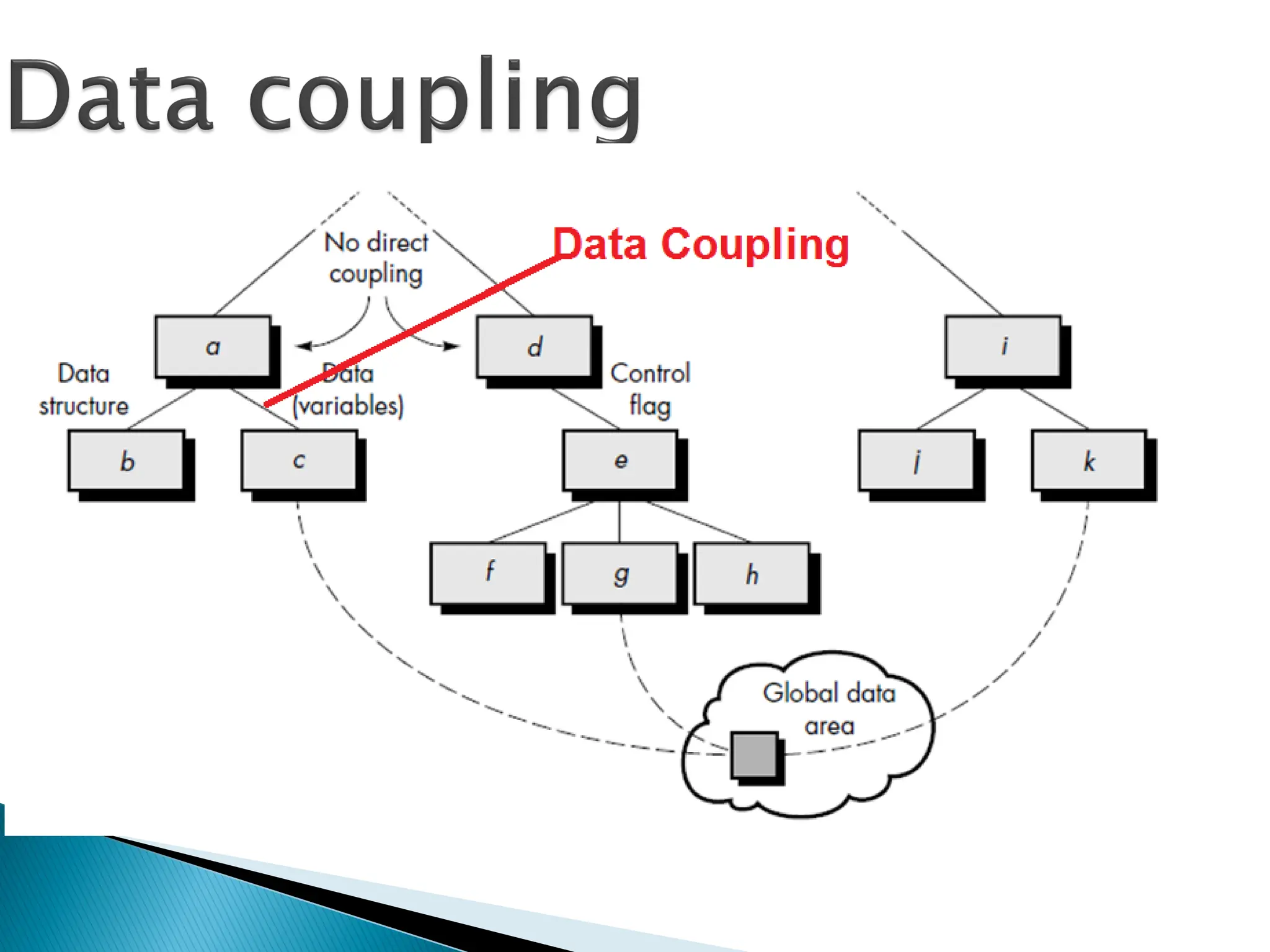
Two modules aredata
coupled,
◦if they communicate via a
parameter:
an elementary data item,
e.g an integer, a float, a
character, etc.
◦The data item should be problem
related:
not used for control purpose.
85.
As long asa simple argument
list is present (i.e., simple data
are passed; a one-to-one
correspondence of items
exists), low coupling (called
data coupling) exists
87.
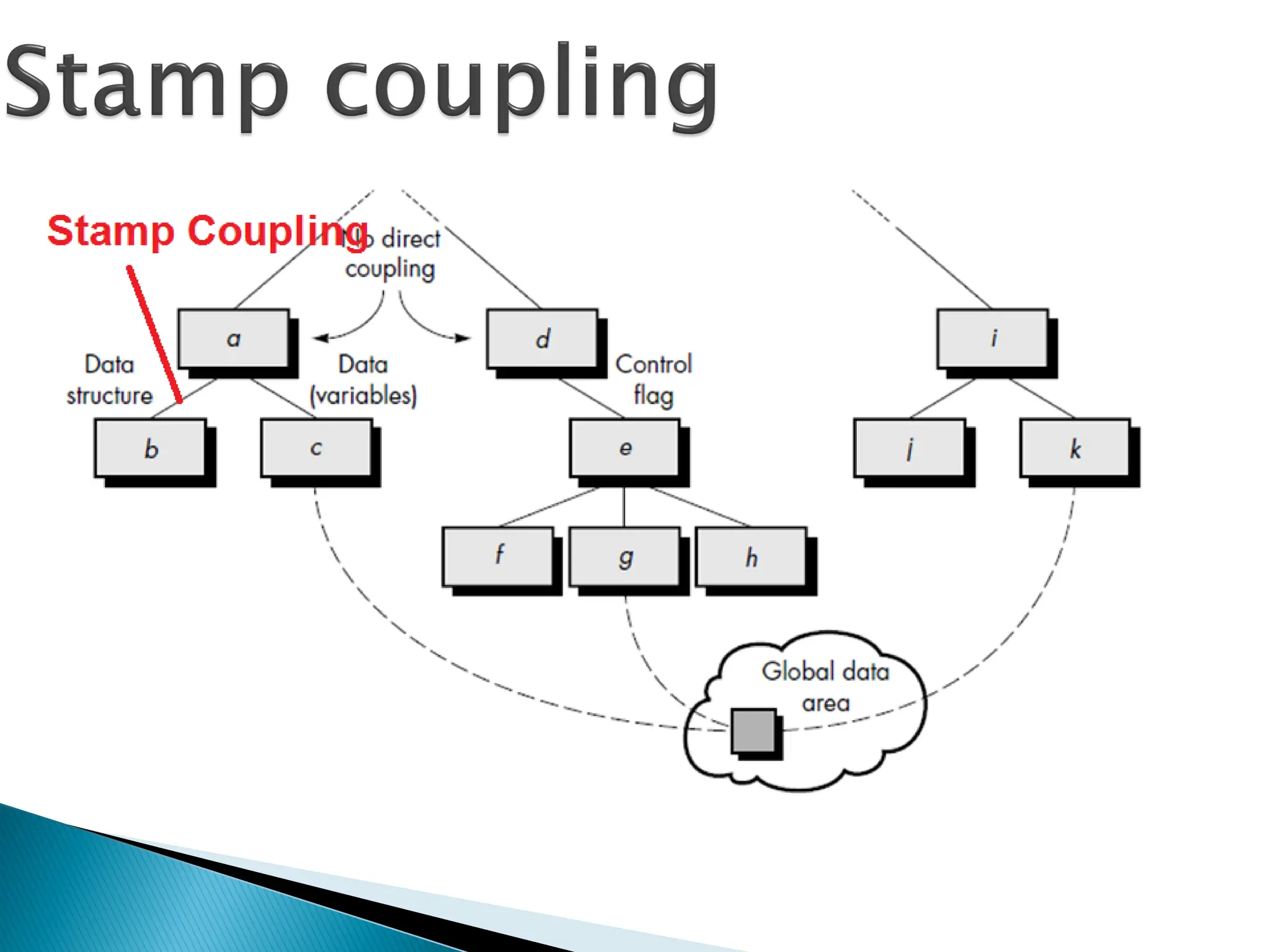
Two modules arestamp
coupled,
◦if they communicate via a
composite data item (rather
than simple arguments)
such as a record in PASCAL
or a structure in C.
89.
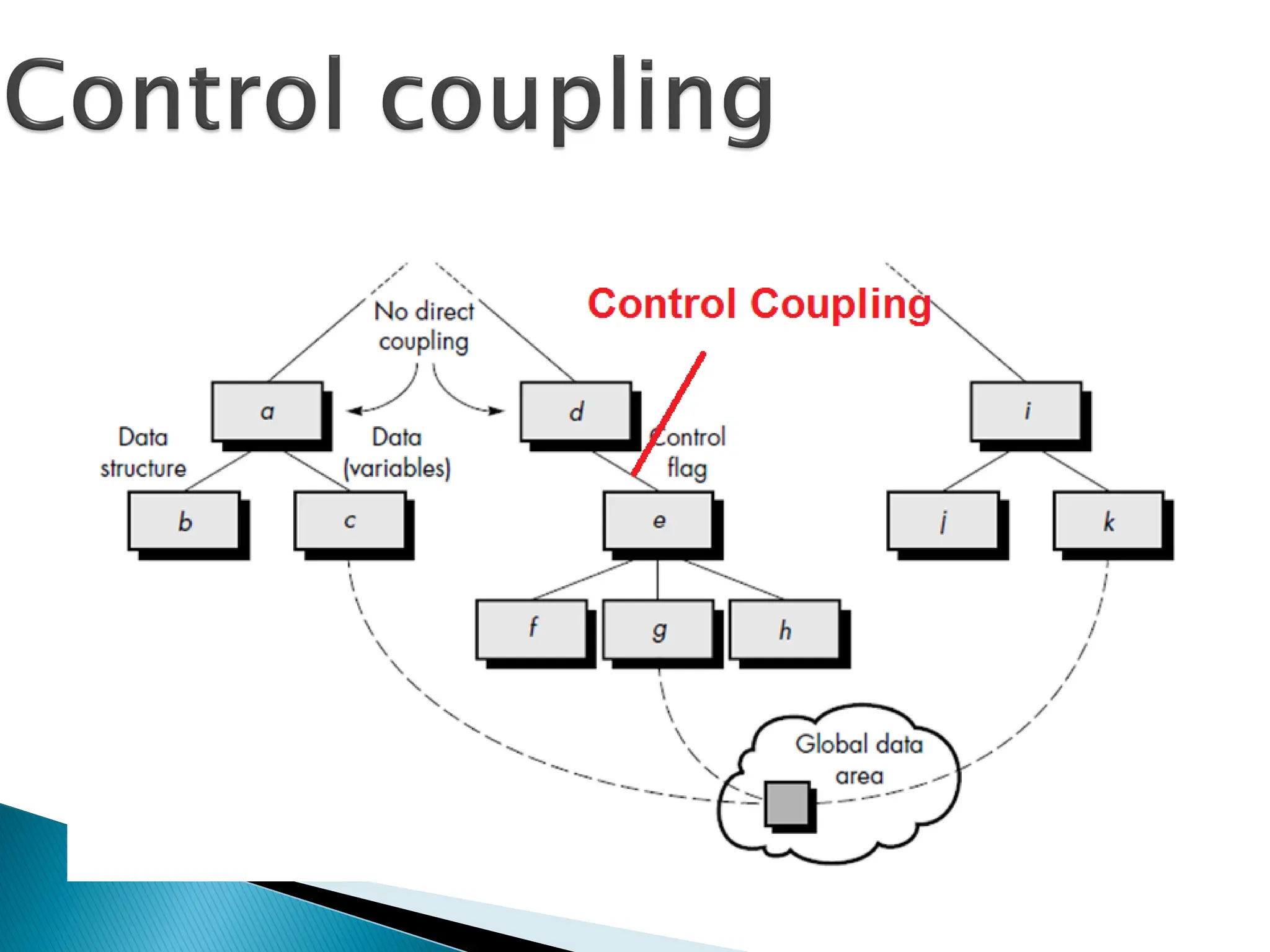
Data from onemodule is
used to direct
◦order of instruction execution
in another.
Presence of Control variable
that controls decisions in a
subordinate or superordinate
module
Example of control coupling:
◦a flag set in one module and
tested in another module.
91.
Relatively high levelsof
coupling occur when modules
are tied to an environment
external to software.
For example, I/O couples a
module to specific devices,
formats, and communication
protocols
92.
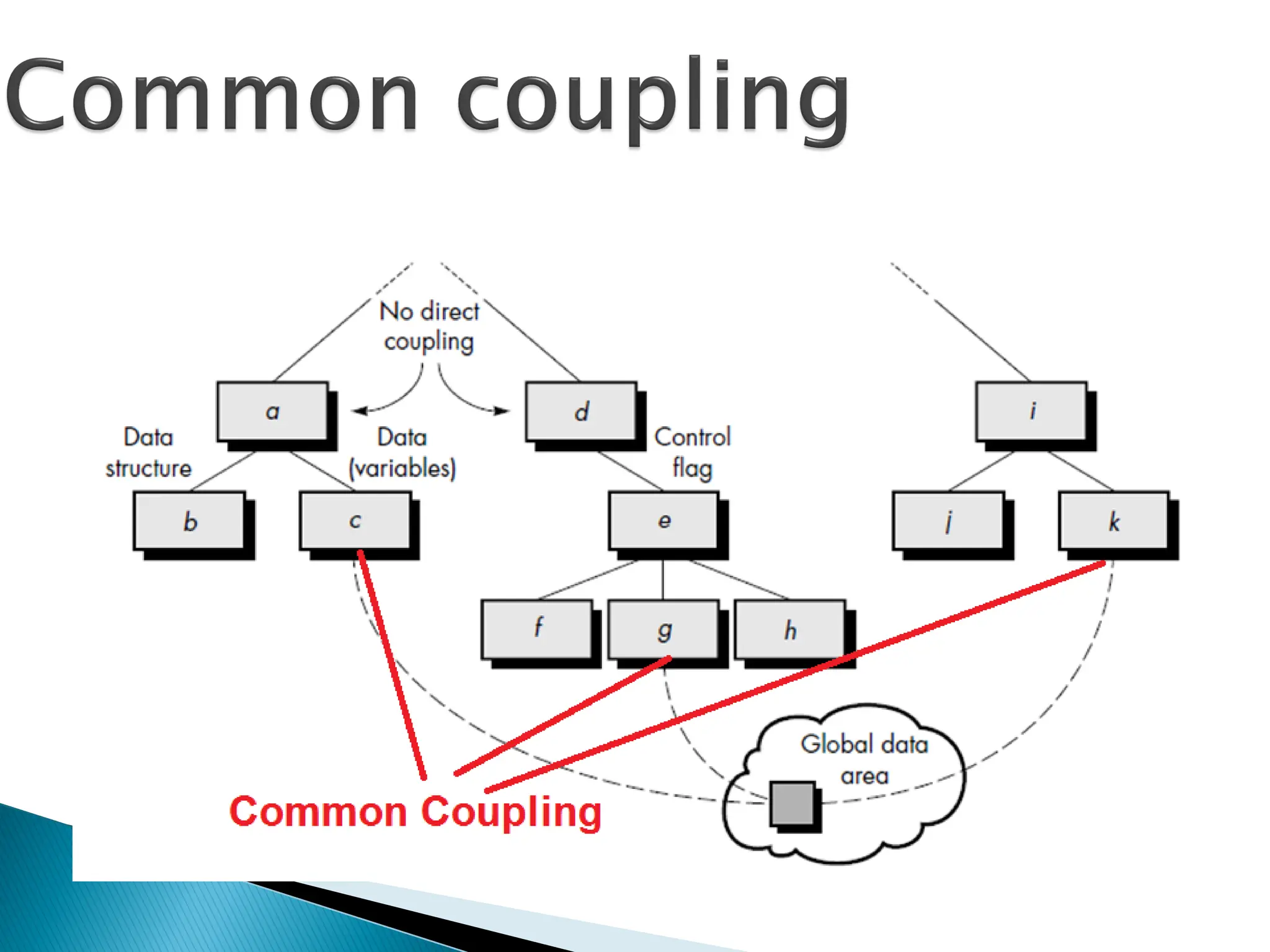
Two modulesare common
coupled,
◦if they share some global data
(e.g., a disk file or a globally
accessible memory area).
use of global data is not necessarily "bad." It does
mean that a software designer must be aware of
potential consequences of common coupling and
take special care to guard against them
94.
The highestdegree of coupling,
content coupling, occurs when one
module makes use of data or control
information maintained within the
boundary of another module.
Secondarily, content coupling occurs
when branches are made into the
middle of a module. This mode of
coupling can and should be avoided.
95.
Content couplingexists between
two modules:
◦ if they share code,
◦ e.g, branching from one module
into another module.
The degree of coupling increases
◦ from data coupling to content
coupling.
96.
#include <iostream>
using namespacestd;
class ClassB {
public:
int data; // Public data (BAD practice)
};
class ClassA {
public:
void modifyB(ClassB &b) {
b.data = 10; // Directly modifying another class's data
}
};
int main() {
ClassB b; ClassA a;
a.modifyB(b);
cout << "ClassB data: " << b.data << endl; // Direct access
return 0;
}
97.
#include <iostream>
using namespacestd;
int globalData = 5; // Global variable (BAD practice)
class ClassA {
public:
void modifyData() {
globalData = 10; // Modifies shared data
} };
class ClassB {
public:
void printData() {
cout << "Global Data: " << globalData << endl;
}};
int main() {
ClassA a; ClassB b;
a.modifyData();
b.printData(); // Uses modified global variable
return 0;}
98.
#include <iostream>
using namespacestd;
class ClassB {
public:
void operation(int flag) {
if (flag == 1)
cout << "Performing Task A" << endl;
else
cout << "Performing Task B" << endl;
}};
class ClassA {
public:
void execute(ClassB &b) {
b.operation(1); // Passing control variable
}};
int main() {
ClassB b; ClassA a;
a.execute(b);
99.
#include <iostream>
using namespacestd;
struct Data {
int x;
int y;
};
class ClassB {
public:
void process(Data d) {
cout << "Processing only x: " << d.x << endl;
}};
class ClassA {
public:
void sendData(ClassB &b) {
Data d = {10, 20};
b.process(d); // Passing full struct, but using only part of it
}};
int main() {
100.
#include <iostream>
using namespacestd;
class ClassB {
public:
void process(int x) { // Only required data is passed
cout << "Processing value: " << x << endl;
}};
class ClassA {
public:
void sendData(ClassB &b) {
b.process(10); // Sending only the required data
}};
int main() {
ClassA a;
ClassB b;
a.sendData(b);
return 0;
}
101.
Coupling Description Example
ContentCoupling (Worst)
One module modifies
another module’s private
data.
Directly changing another
class’s variables.
Common Coupling
Multiple modules share
global variables.
Using global variables
between classes.
Control Coupling
One module controls
another’s flow via control
flags.
Passing a flag to
determine logic in
another module.
Stamp Coupling
Passing a complex data
structure but using only
part of it.
Passing a struct but using
only one field.
Data Coupling (Best)
Only necessary data is
passed between modules.
Passing just the needed
value (e.g., int).
• Low coupling is desirable because it improves modularity, maintainability,
and flexibility.
• High coupling makes software difficult to modify and test.
• The best approach is Data Coupling, where classes interact using only
necessary information.
102.
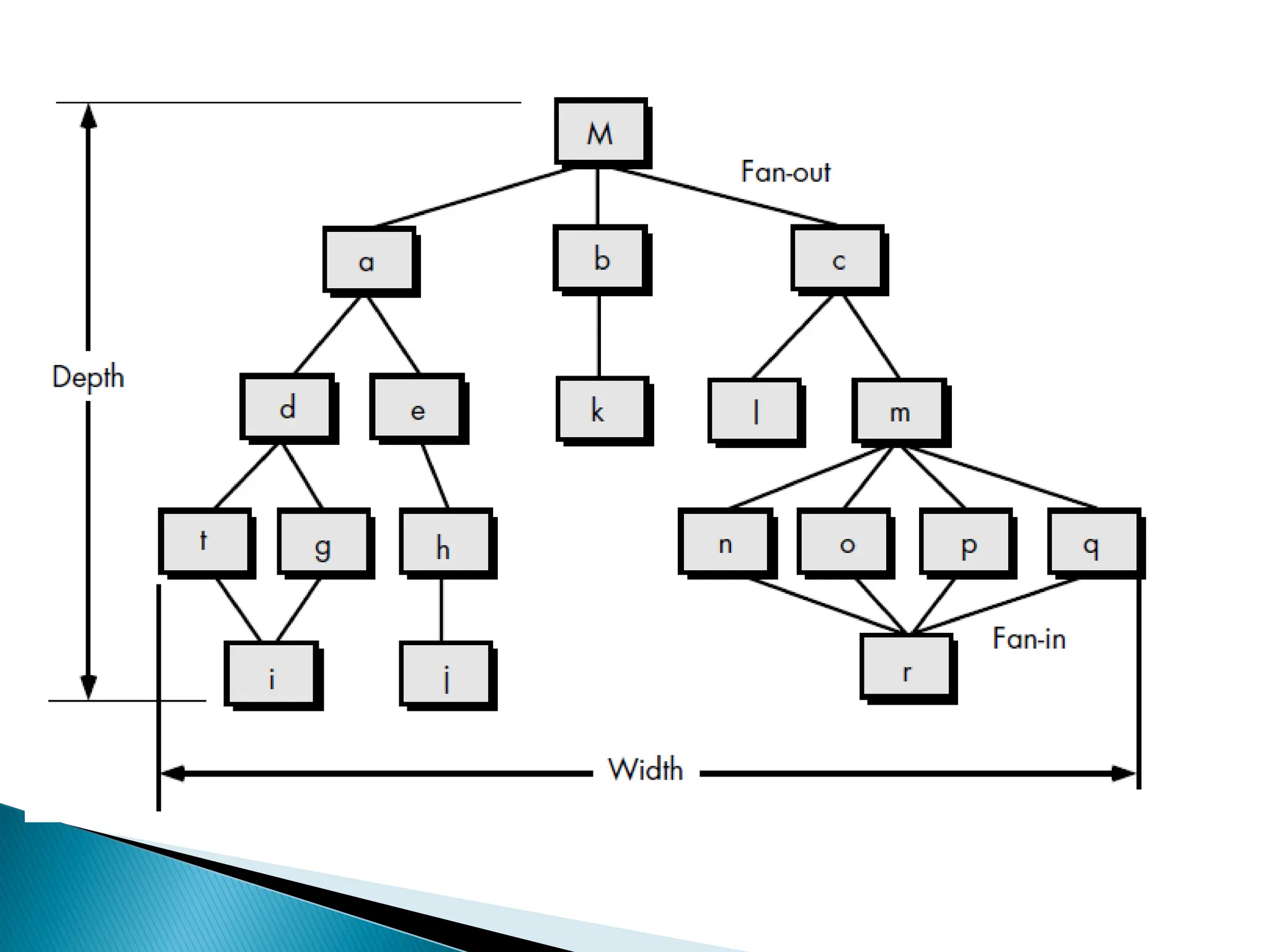
Control hierarchyrepresents:
◦ organization of modules.
◦ control hierarchy is also called
program structure.
Most common notation:
◦ a tree-like diagram called structure
chart.
103.
Essentially means:
◦low fan-out
◦Abstraction
Fan-out:
◦ a measure of the number of modules
directly controlled by given module.
◦ The fan-out of a module is the number
of its immediately subordinate modules.
105.
Fan-in:
◦ indicateshow many modules directly invoke a given
module.
◦ High fan-in represents code reuse and is in general
encouraged.
◦ The fan-in of a module is the number of its
immediately superordinate (i.e., parent or boss)
modules.
◦ The designer should strive for high fan-in at the lower
levels of the hierarchy.
◦ This simply means that normally there are common
low-level functions that exist that should be identified
and made into common modules to reduce redundant
code and increase maintainability.
106.
A designhaving modules:
◦with high fan-out numbers is not
a good design:
◦a module having high fan-out
lacks cohesion.
107.
A modulethat invokes a large
number of other modules:
◦ likely to implement several
different functions:
◦ not likely to perform a single
cohesive function.
108.
The principleof abstraction
requires:
◦lower-level modules do not
invoke functions of higher level
modules.
◦Also known as layered design.
109.
High-level designmaps
functions into modules such
that:
◦ Each module has high cohesion
◦ Coupling among modules is as low
as possible
◦ Modules are organized in a neat
hierarchy
110.
Evaluate the"first iteration" of the program
structure to reduce coupling and improve
cohesion.
Attempt to minimize structures with high fan-
out; strive for fan-in as depth increases
Keep the scope of effect of a module within the
scope of control of that module
Evaluate module interfaces to reduce complexity
and redundancy and improve consistency
Define modules whose function is predictable,
but avoid modules that are overly restrictive.
Strive for “controlled entry” modules by avoiding
"pathological connections
111.
Two fundamentallydifferent
software design approaches:
◦Function-oriented design
◦Object-oriented design
112.
These twodesign approaches
are radically different.
◦However, are complementary
rather than competing techniques.
◦Each technique is applicable at
different stages of the design
process.
113.
A systemis looked upon as
something
◦ that performs a set of functions.
Starting at this high-level view of
the system:
◦ each function is successively refined
into more detailed functions.
◦ Functions are mapped to a module
structure.
114.
The functioncreate-new-
library- member:
◦creates the record for a new
member,
◦assigns a unique membership
number
◦prints a bill towards the
membership
Several function-orienteddesign
approaches have been developed:
◦ Structured design (Constantine and
Yourdon, 1979)
◦ Jackson's structured design (Jackson,
1975)
◦ Warnier-Orr methodology
◦ Wirth's step-wise refinement
◦ Hatley and Pirbhai's Methodology
118.
System isviewed as a
collection of objects (i.e.
entities).
System state is decentralized
among the objects:
◦each object manages its own
state information.
119.
Library Automation
Software:
◦each librarymember is a
separate object
with its own data and
functions.
◦Functions defined for one
object:
cannot directly refer to or
change data of other
objects.
120.
Objects havetheir own
internal data:
◦defines their state.
Similar objects constitute a
class.
◦each object is a member of
some class.
Classes may inherit features
◦from a super class.
Conceptually, objects
communicate by message
passing.
121.
Unlike function-oriented
design,
◦in OOD the basic abstraction is
not functions such as “sort”,
“display”, “track”, etc.,
◦ but real-world entities such as
“employee”, “picture”, “machine”,
“radar system”, etc.
122.
In OOD:
◦softwareis not developed by
designing functions such as:
update-employee-record,
get-employee-address, etc.
◦but by designing objects such
as:
employees,
departments, etc.
123.
Grady Booch sumsup this
fundamental difference
saying:
◦“Identify verbs if you are
after procedural design and
nouns if you are after
object-oriented design.”
124.
In OOD:
◦state informationis not
shared in a centralized data.
◦but is distributed among the
objects of the system.
125.
In anemployee pay-roll
system, the following can be
global data:
◦names of the employees,
◦their code numbers,
◦basic salaries, etc.
Whereas, in object oriented
systems:
◦data is distributed among
different employee objects of
the system.
126.
Objects communicateby
message passing.
◦one object may discover the
state information of another
object by interrogating it.
127.
Of course,somewhere or other
the functions must be
implemented:
◦ the functions are usually associated
with specific real-world entities
(objects)
◦ directly access only part of the
system state information.
128.
Function-oriented techniques
groupfunctions together if:
◦as a group, they constitute a
higher level function.
On the other hand, object-
oriented techniques group
functions together:
◦on the basis of the data they
operate on.
129.
To illustratethe differences
between object-oriented and
function-oriented design
approaches,
◦let us consider an example ---
◦An automated fire-alarm system
for a large building.
130.
We needto develop a
computerized fire alarm
system for a large multi-
storied building:
◦There are 80 floors and 1000
rooms in the building.
131.
Different roomsof the
building:
◦fitted with smoke detectors and
fire alarms.
The fire alarm system would
monitor:
◦status of the smoke detectors.
132.
Whenever afire condition is
reported by any smoke
detector:
◦the fire alarm system should:
determine the location from which
the fire condition was reported
sound the alarms in the
neighboring locations.
133.
The fire alarmsystem
should:
◦flash an alarm message on
the computer console:
fire fighting personnel man
the console round the clock.
134.
After afire condition has been
successfully handled,
◦the fire alarm system should let
fire fighting personnel reset the
alarms.
135.
/* Globaldata (system state) accessible by
various functions */
BOOL detector_status[1000];
int detector_locs[1000];
BOOL alarm-status[1000]; /* alarm activated when status
set */
int alarm_locs[1000]; /* room number where alarm is
located */
int neighbor-alarms[1000][10];/*each detector has at
most*/
/* 10 neighboring alarm
locations */
The functions which operate on the system
state:
interrogate_detectors();
get_detector_location();
determine_neighbor();
ring_alarm();
reset_alarm();
report_fire_location();
136.
class detector
attributes: status, location, neighbors
operations: create, sense-status, get-
location,
find-neighbors
class alarm
attributes: location, status
operations: create, ring-alarm,
get_location,
reset-alarm
In the object oriented program,
◦ appropriate number of instances of the class
detector and alarm should be created.
137.
In the function-oriented
program:
◦the system state is centralized
◦several functions accessing
these data are defined.
In the object oriented
program,
◦the state information is
distributed among various
sensor and alarm objects.
138.
Use OODto design the classes:
◦then applies top-down function
oriented techniques
to design the internal methods of
classes.
139.
Though outwardlya system may
appear to have been developed in
an object oriented fashion,
◦ but inside each class there is a small
hierarchy of functions designed in a
top-down manner.
140.
We startedwith an overview
of:
◦activities undertaken during
the software design phase.
We identified:
◦the information need to be
produced at the end of the
design phase:
so that the design can be easily
implemented using a
programming language.
141.
We characterizedthe features
of a good software design by
introducing the concepts of:
◦fan-in, fan-out,
◦cohesion, coupling,
◦abstraction, etc.
142.
We classified differenttypes
of cohesion and coupling:
◦enables us to approximately
determine the cohesion and
coupling existing in a design.
143.
Two fundamentallydifferent
approaches to software design:
◦function-oriented approach
◦object-oriented approach
144.
We lookedat the essential
philosophy behind these two
approaches
◦these two approaches are not
competing but complementary
approaches.


































































![ A function that processes a string by cleaning it,
converting it to lowercase, and reversing it:
The result of each step is passed to the next,
forming a sequence of dependent tasks.
def process_string(s):
cleaned = clean_string(s)
lowercased = cleaned.lower()
reversed_string = lowercased[::-1]
return reversed_string](https://image.slidesharecdn.com/sdtlecture1feb2025s-250618015755-373feec2/75/SDTpresentaion-on-testingand-sofware-all-required-materials-73-2048.jpg)























































![ /* Global data (system state) accessible by
various functions */
BOOL detector_status[1000];
int detector_locs[1000];
BOOL alarm-status[1000]; /* alarm activated when status
set */
int alarm_locs[1000]; /* room number where alarm is
located */
int neighbor-alarms[1000][10];/*each detector has at
most*/
/* 10 neighboring alarm
locations */
The functions which operate on the system
state:
interrogate_detectors();
get_detector_location();
determine_neighbor();
ring_alarm();
reset_alarm();
report_fire_location();](https://image.slidesharecdn.com/sdtlecture1feb2025s-250618015755-373feec2/75/SDTpresentaion-on-testingand-sofware-all-required-materials-135-2048.jpg)
























































