






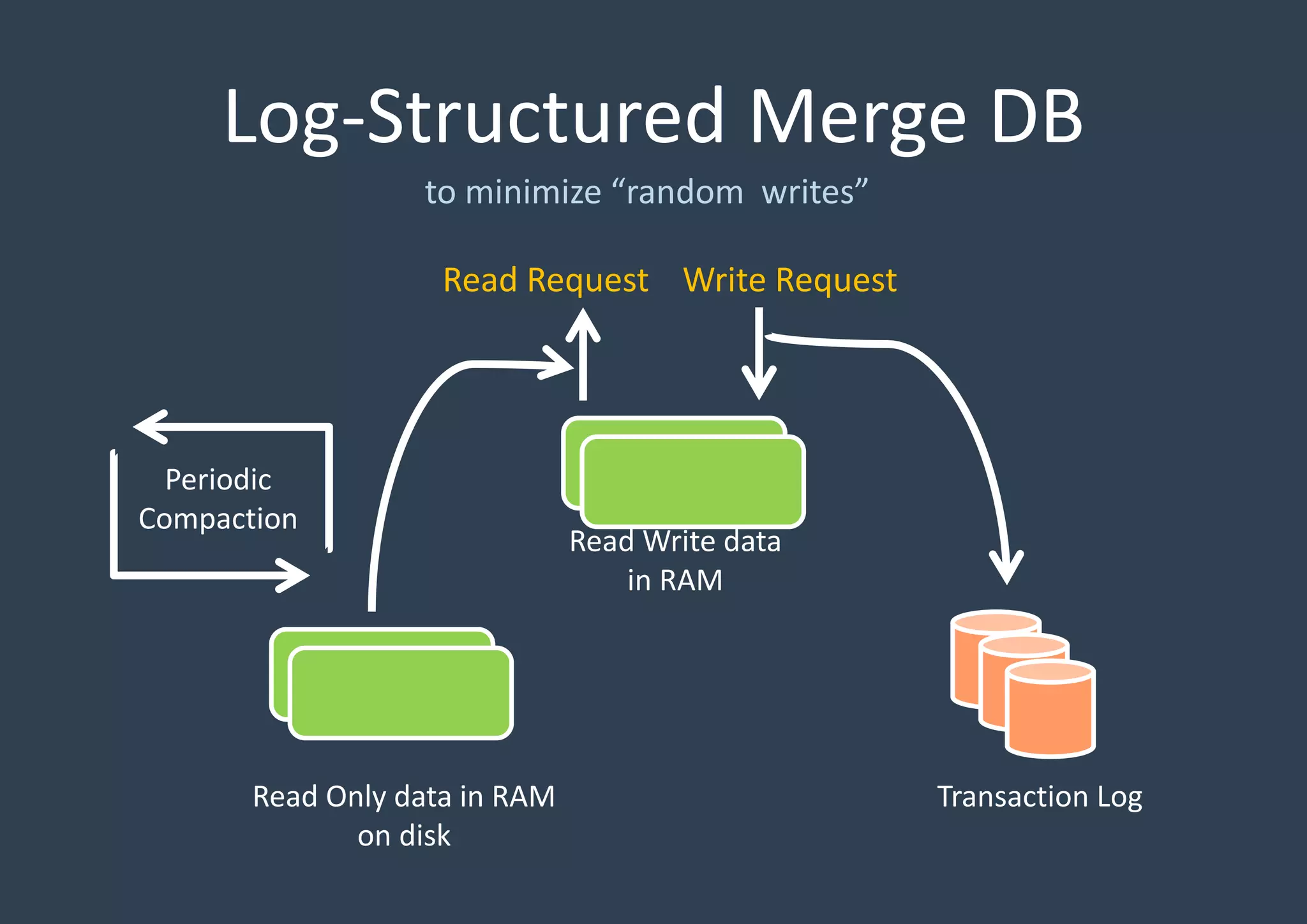


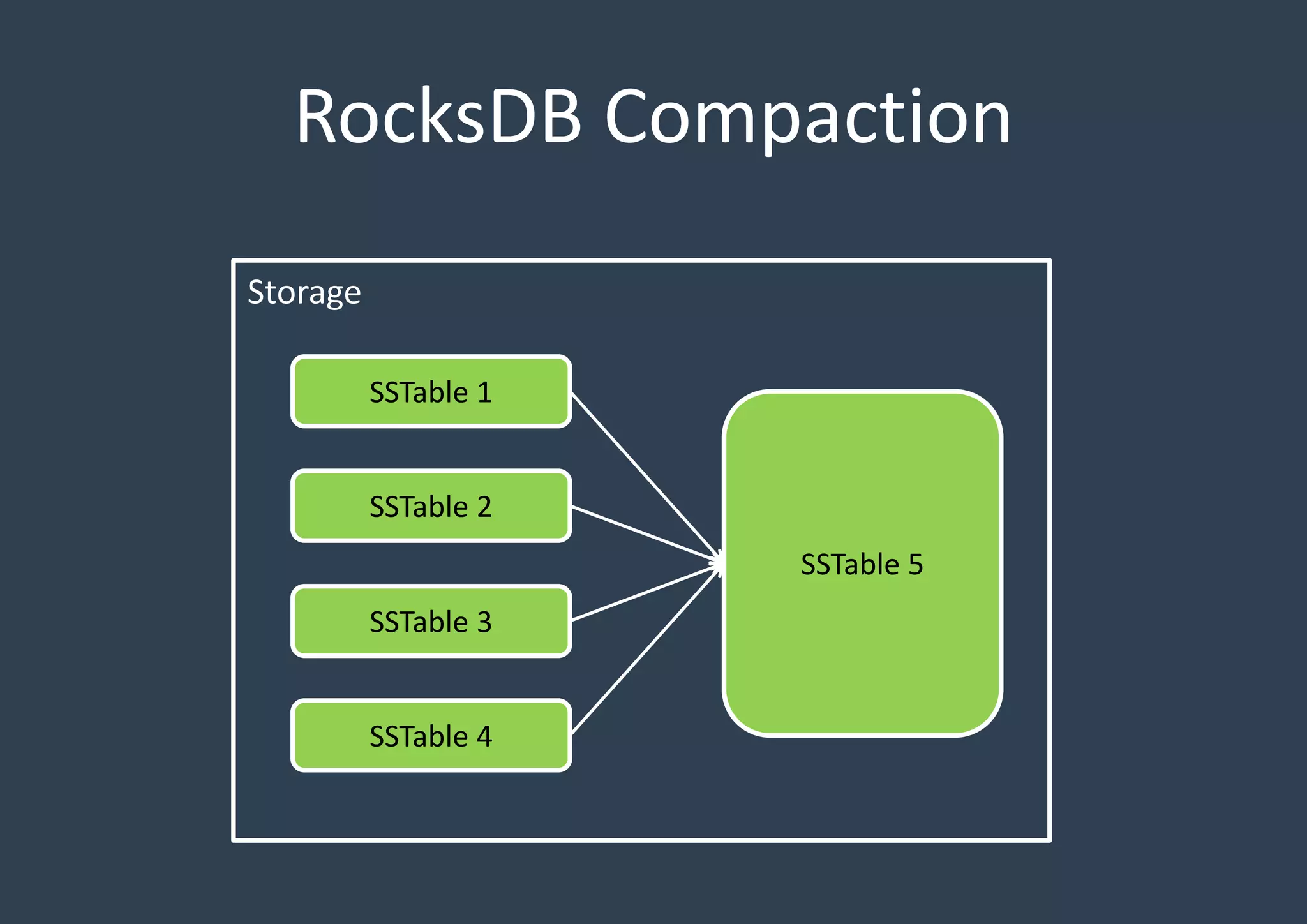


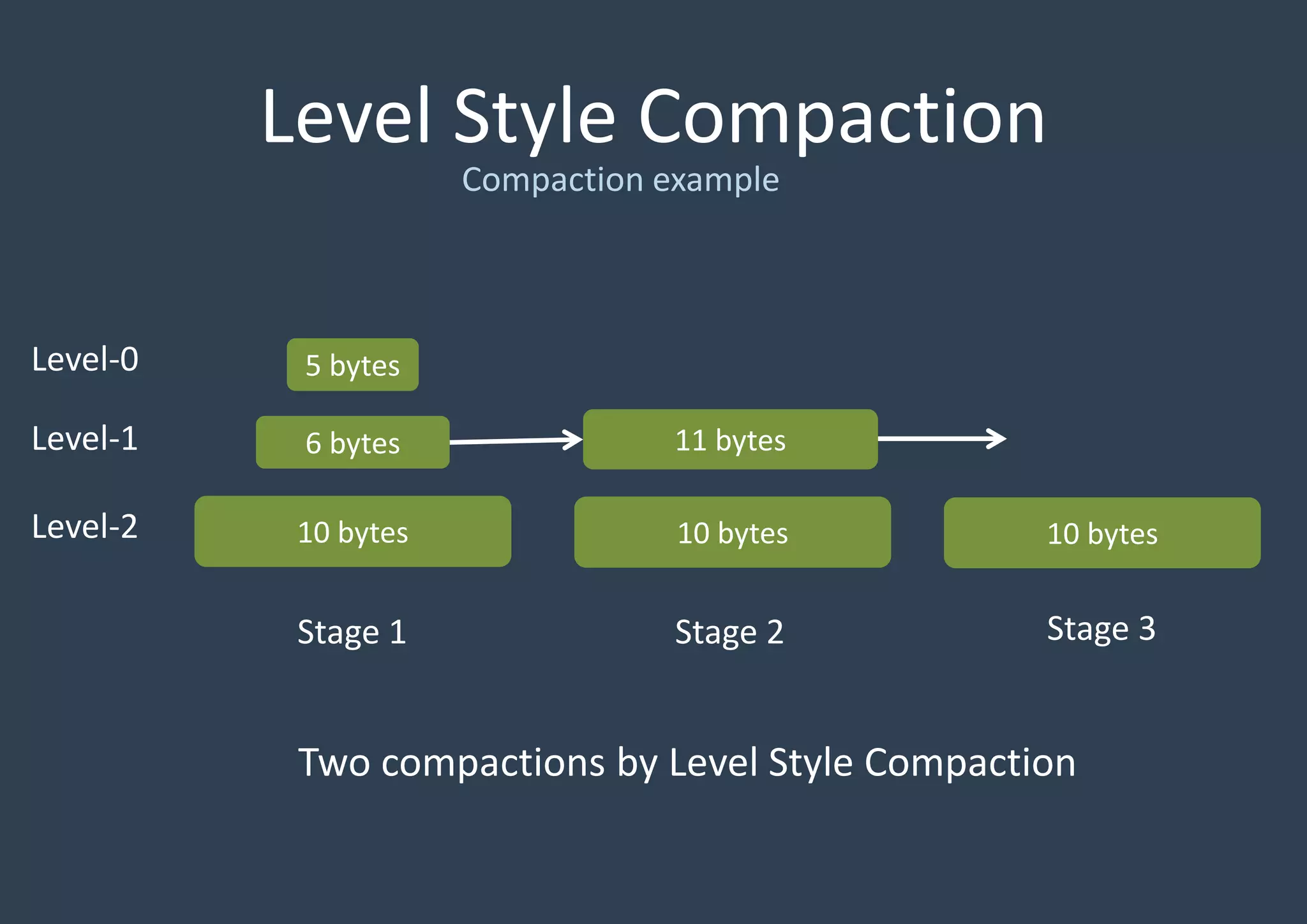




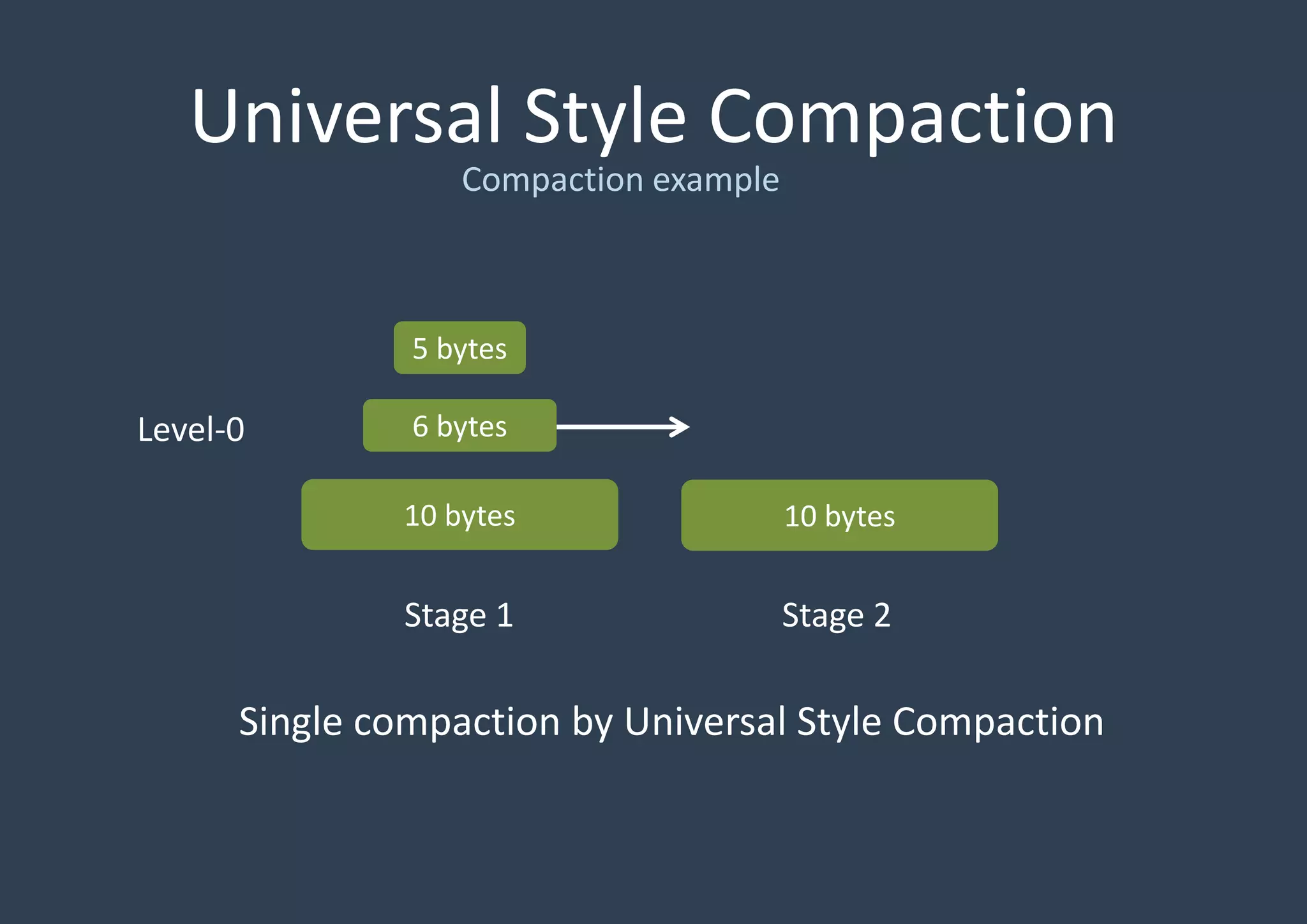

RocksDB is an embedded key-value store written in C++ and optimized for fast storage environments like flash or RAM. It uses a log-structured merge tree to store data by writing new data sequentially to an in-memory log and memtable, periodically flushing the memtable to disk in sorted SSTables. It reads from the memtable and SSTables, and performs background compaction to merge SSTables and remove overwritten data. RocksDB supports two compaction styles - level style, which stores SSTables in multiple levels sorted by age, and universal style, which stores all SSTables in level 0 sorted by time.
Overview of RocksDB as an embedded key-value store optimized for fast storage solutions.
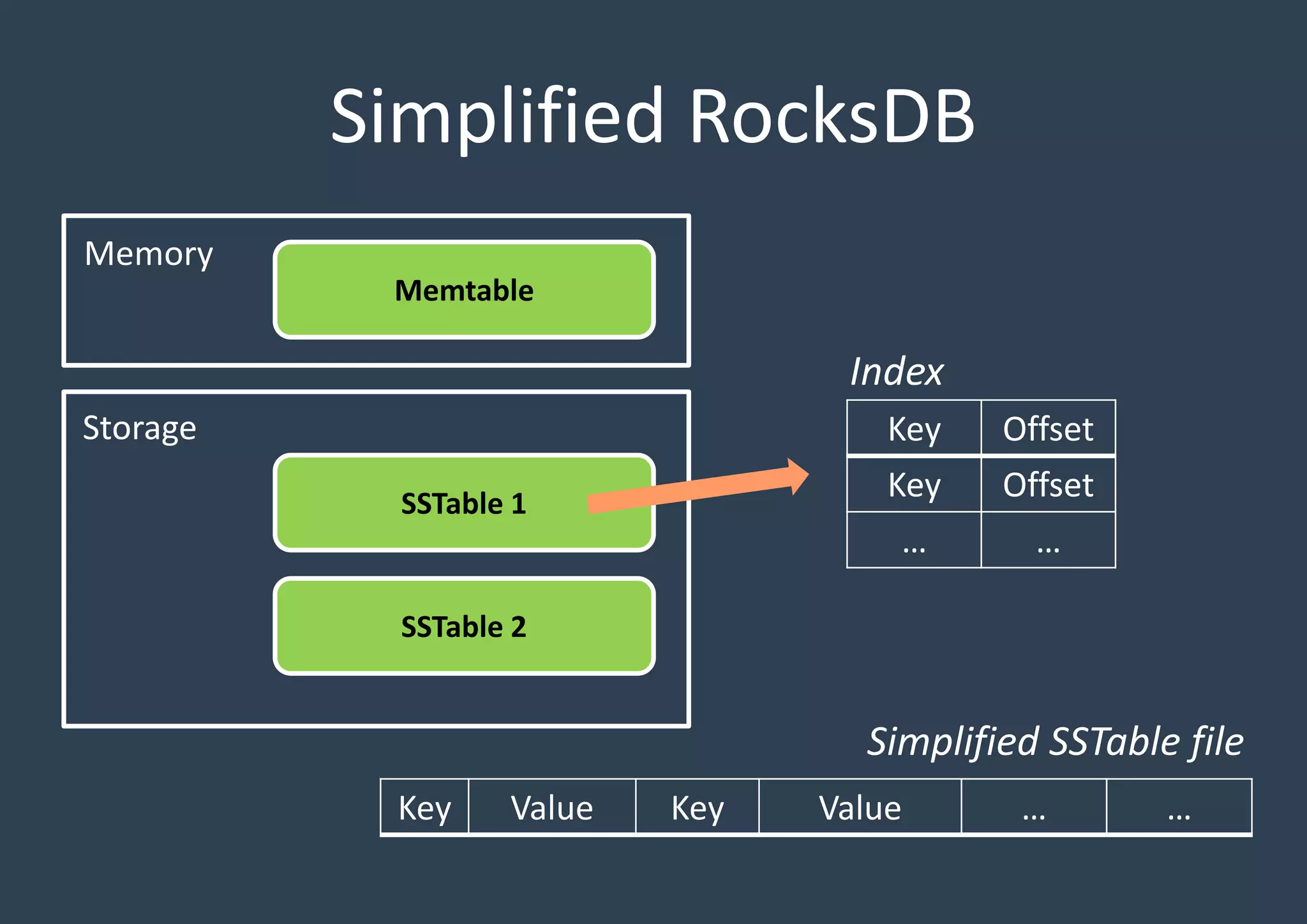
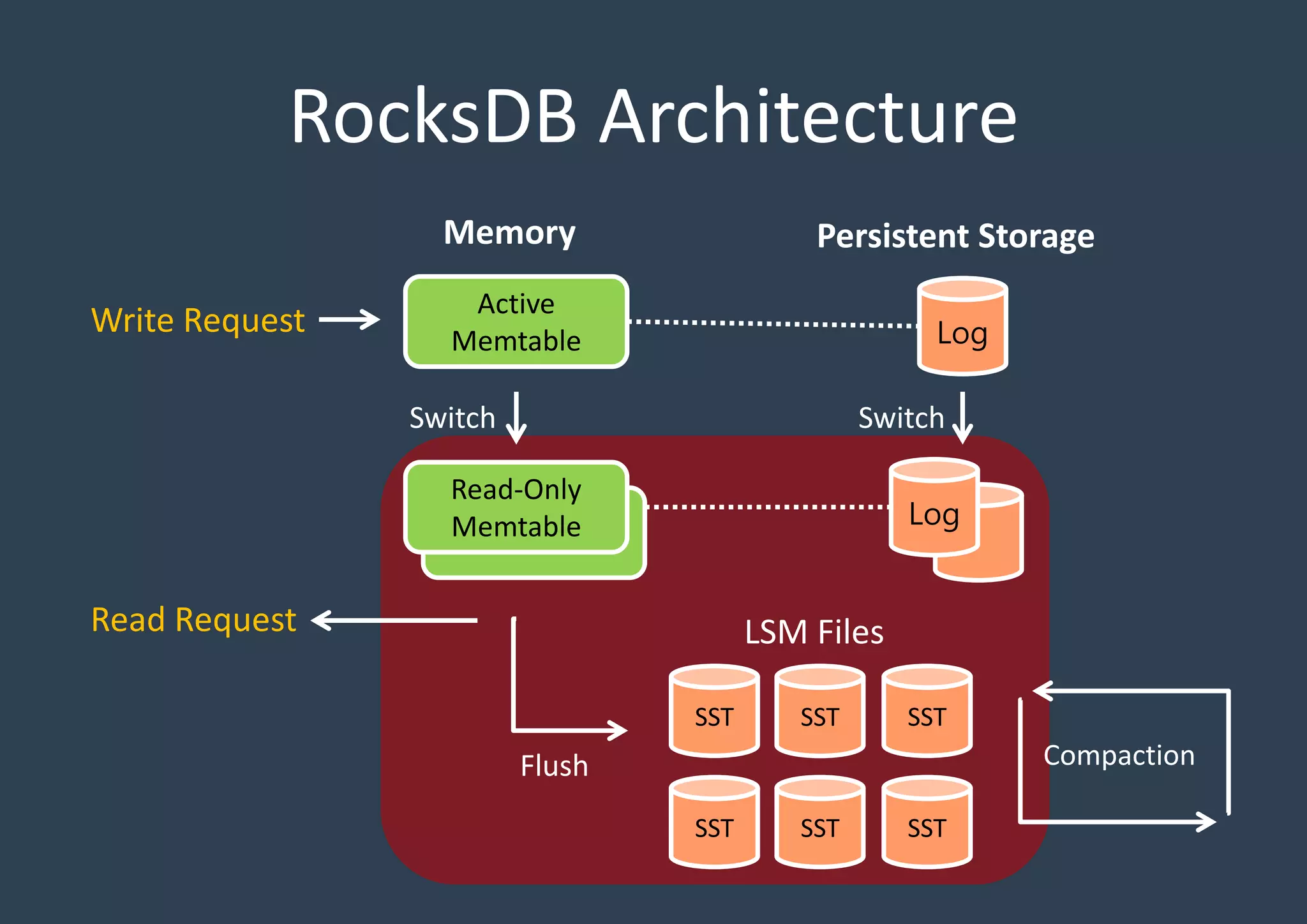
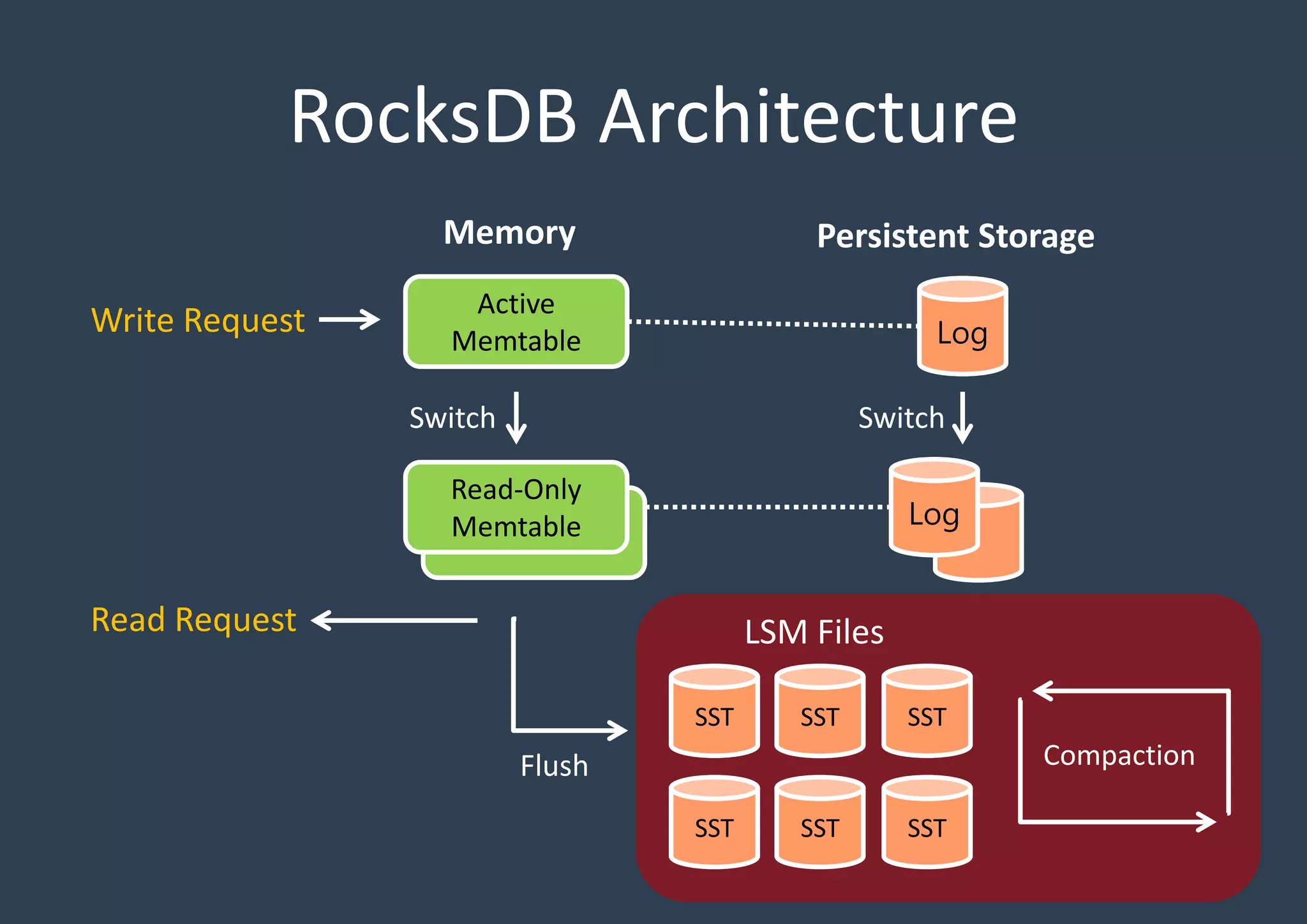
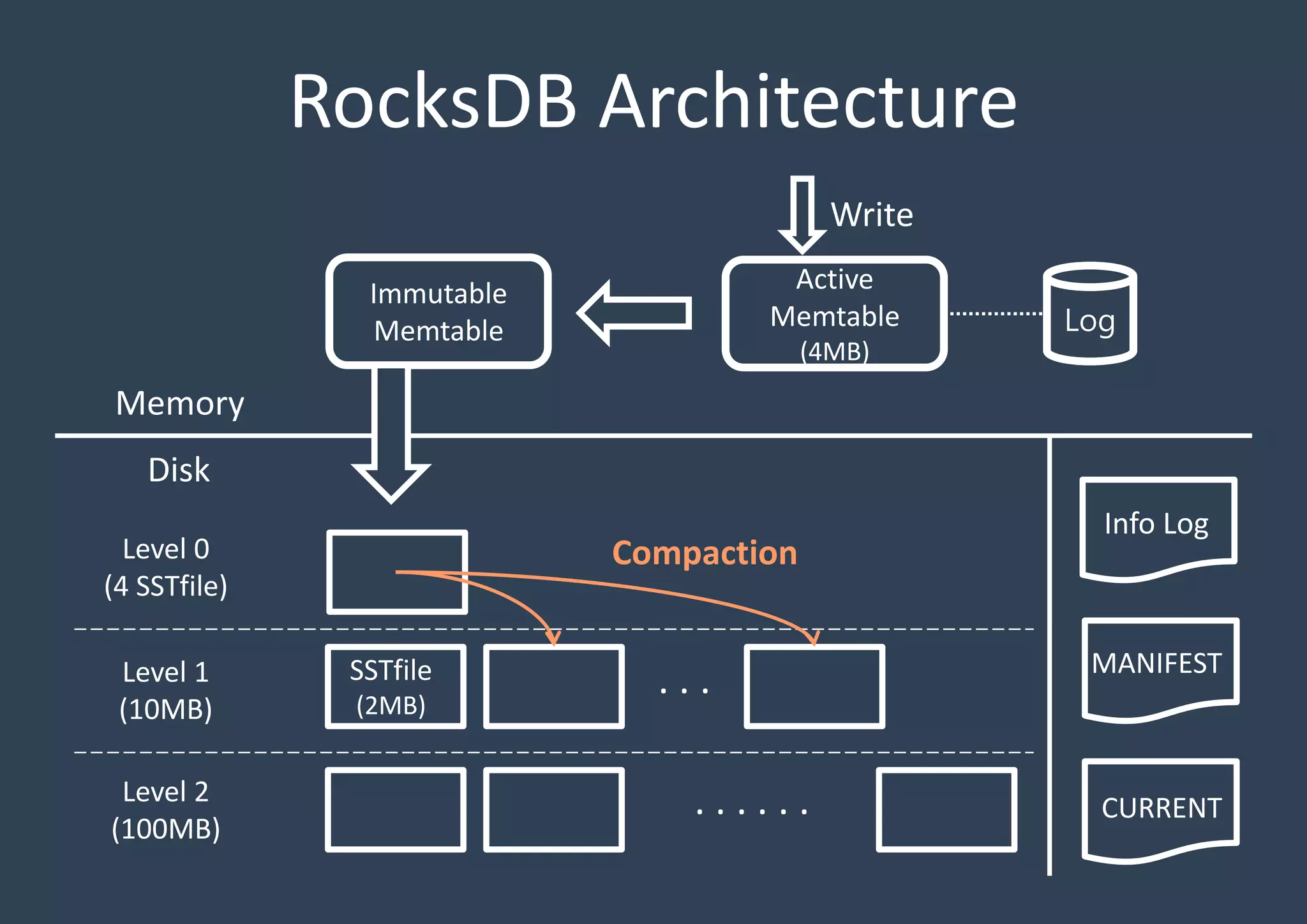
Key constructs of RocksDB include Memtable (in-memory), Logfile (sequential), and SSTable (storage). Each structure aids efficiency and data organization.
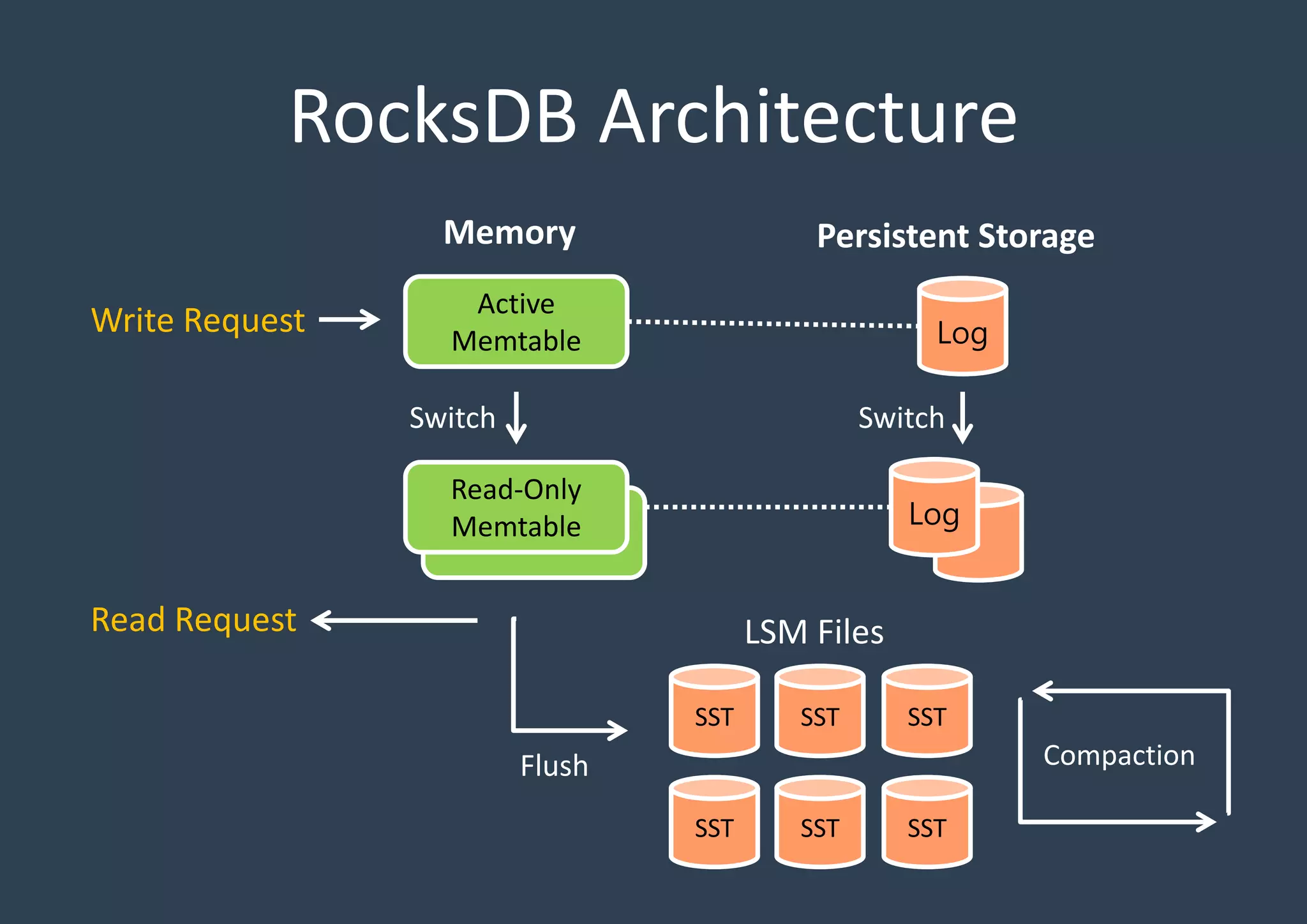
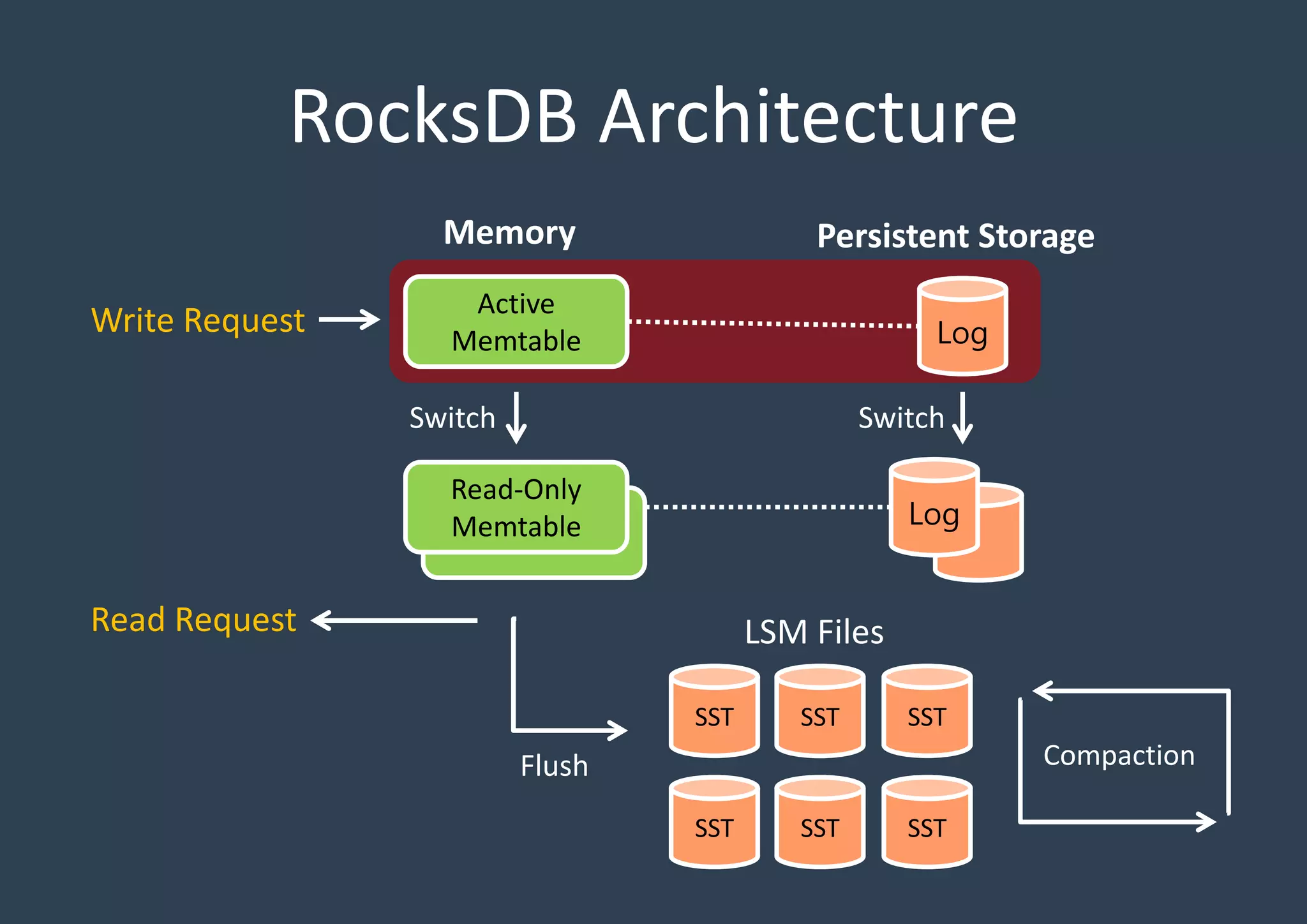
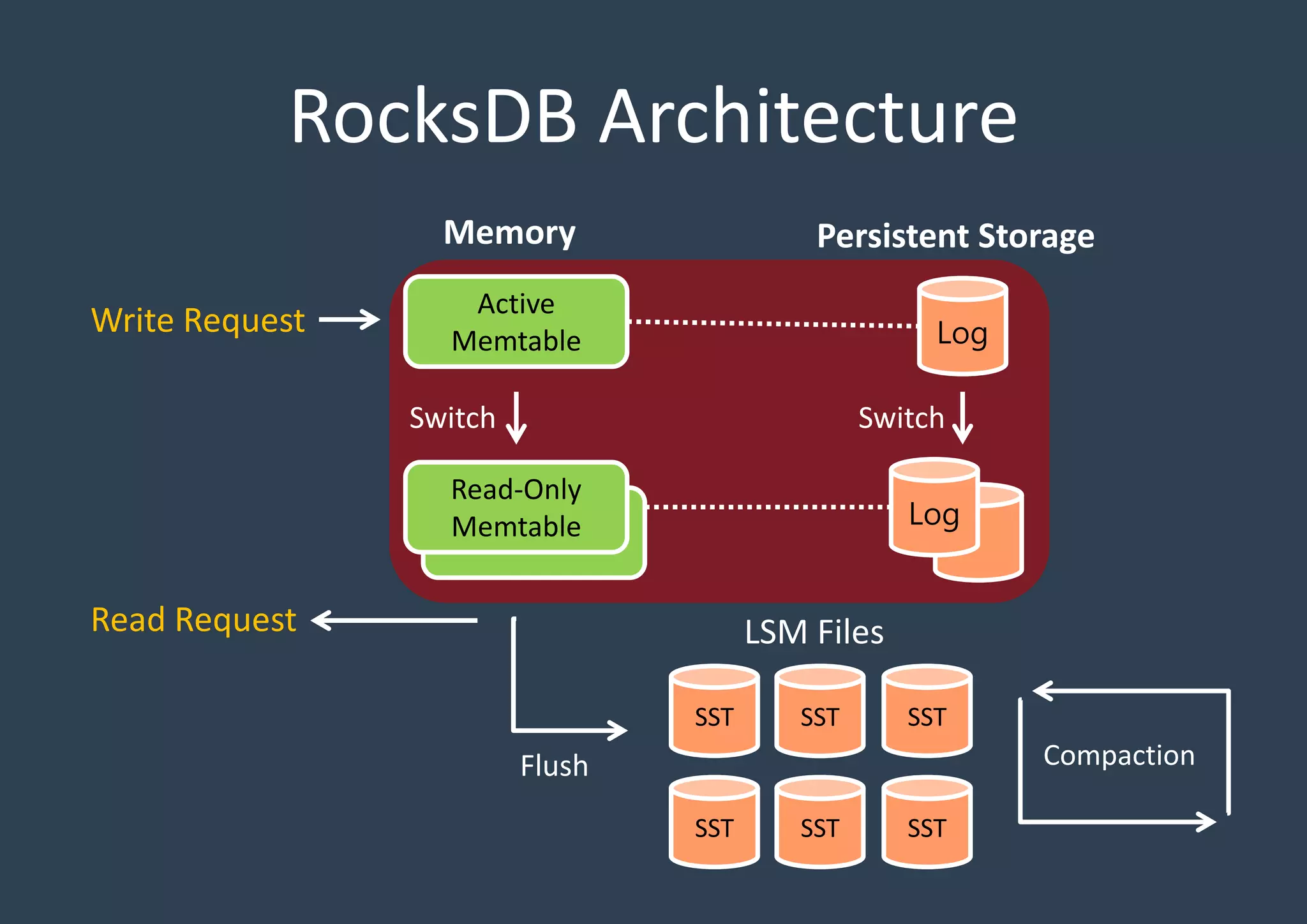
Explains the architecture layout of RocksDB with active and read-only Memtables, logs, and SSTables, emphasizing persistent storage.
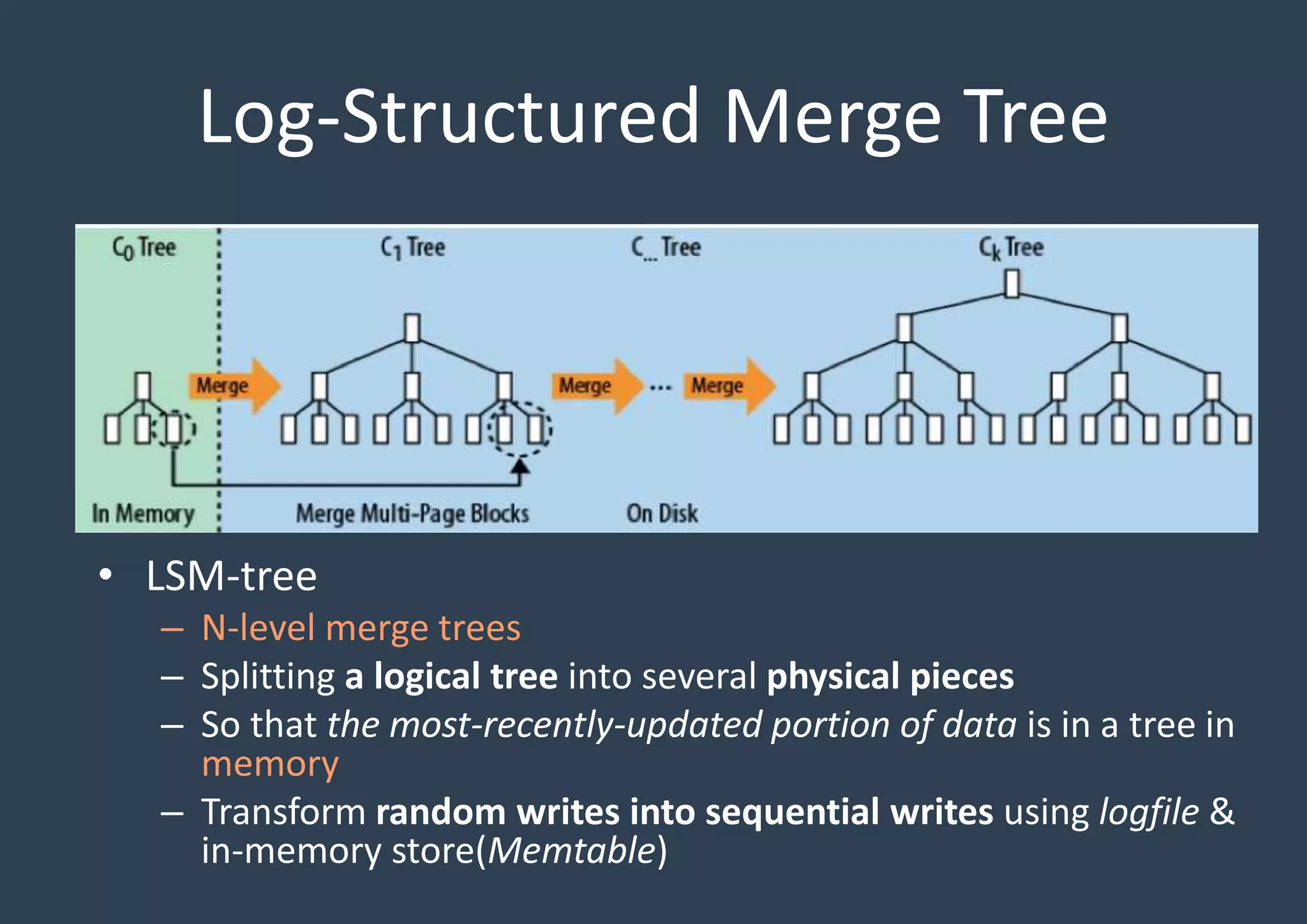
Detailed discussion on the Log-Structured Merge Tree (LSM-tree) which optimizes write operations by minimizing random writes through periodic compactions. Multi-threaded compaction strategies including Level Style and Universal Style compactions, highlighting their roles in managing SSTables and optimizing database performance.

































![[243]kaleido 노현걸](https://cdn.slidesharecdn.com/ss_thumbnails/243kaleido-161025011559-thumbnail.jpg?width=640&height=640&fit=bounds)






![[@IndeedEng] Imhotep Workshop](https://cdn.slidesharecdn.com/ss_thumbnails/imhotepworkshopslides-141117223504-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)















![[db tech showcase Tokyo 2017] C23: Lessons from SQLite4 by SQLite.org - Richa...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-sqlite4-20170906-170911071410-thumbnail.jpg?width=640&height=640&fit=bounds)






























