Download as PDF, PPTX


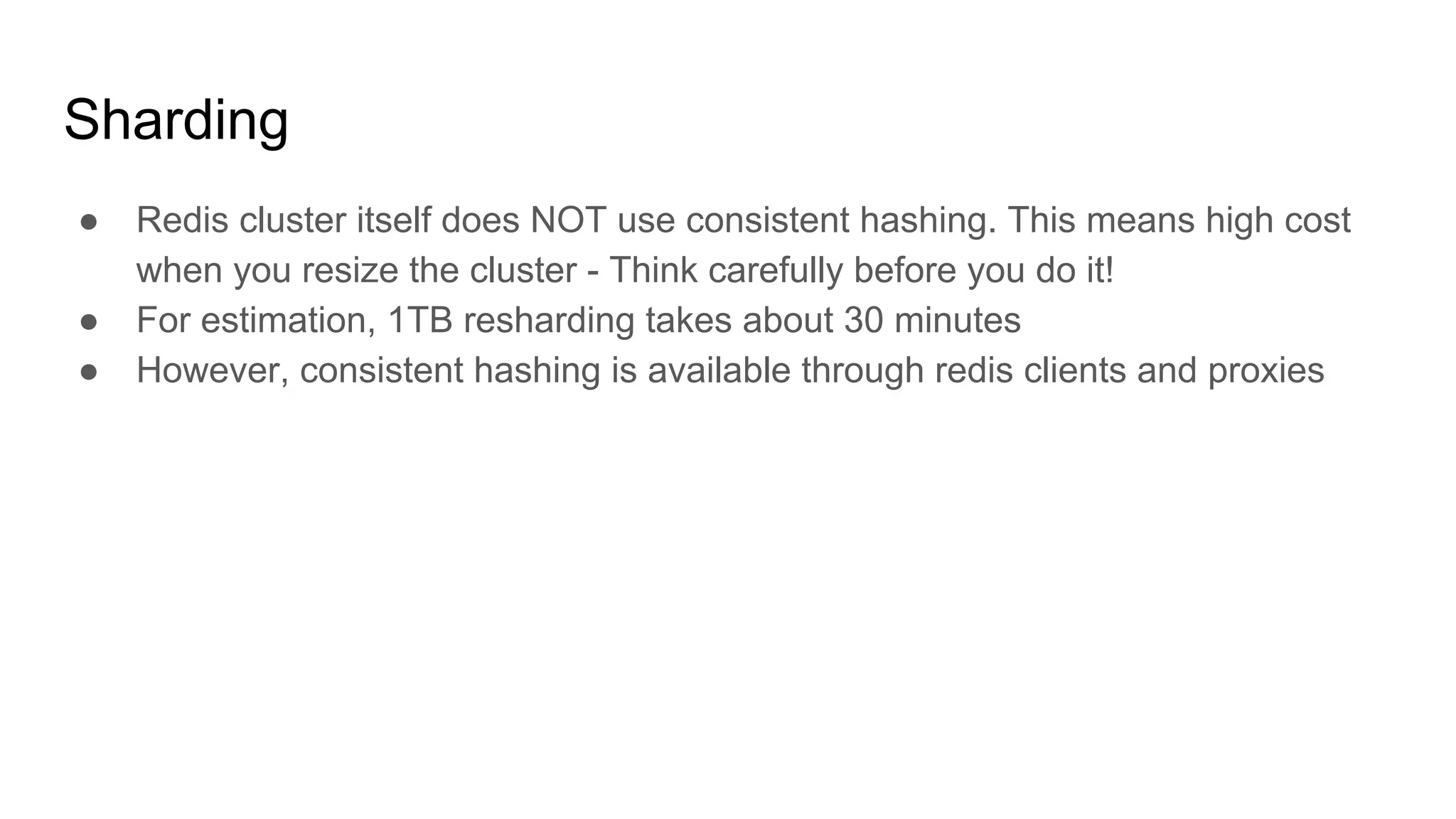


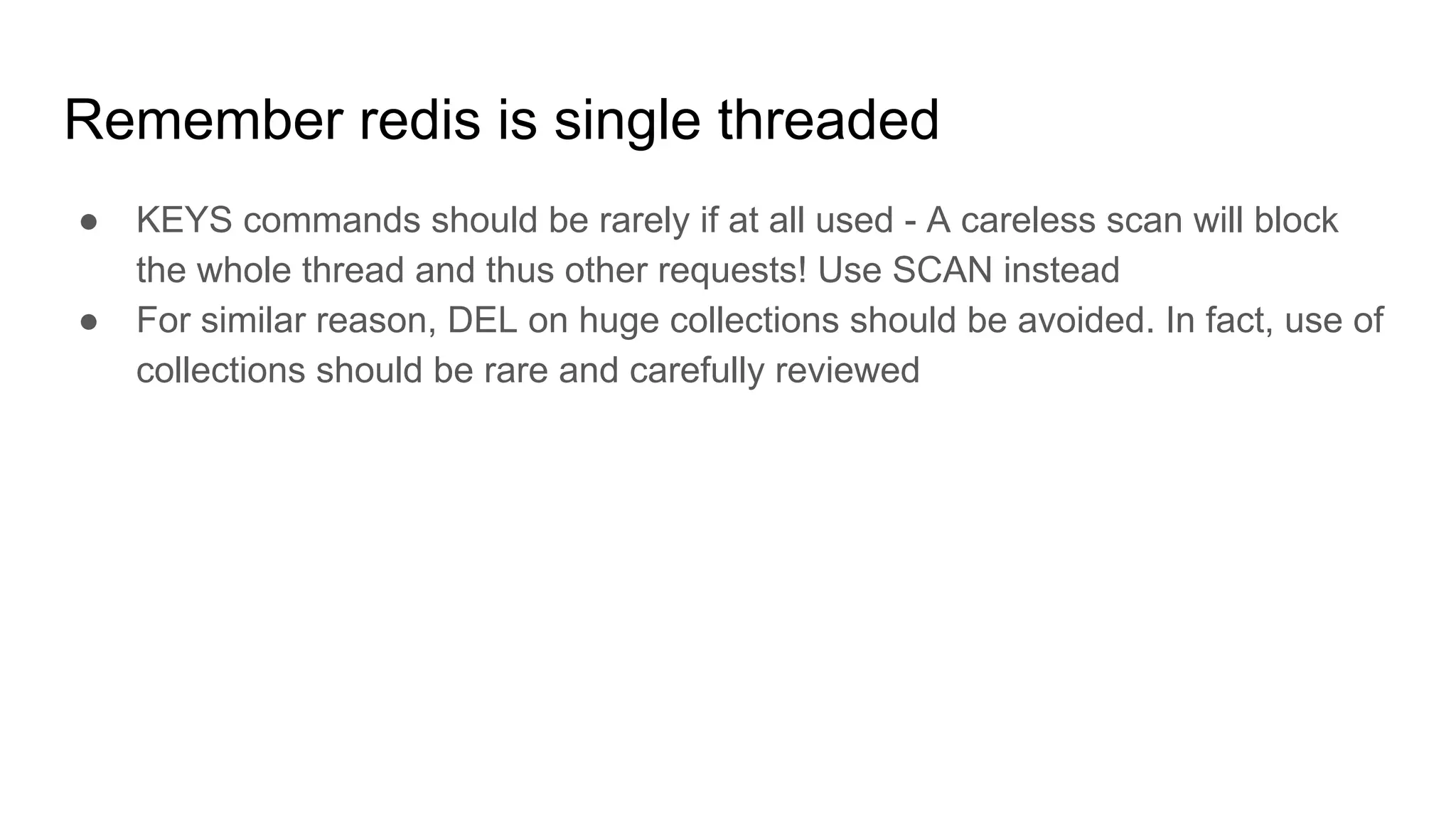



This document provides guidance on improving the stability and performance of ElasticCache/Redis clusters. It discusses sharding, eviction and memory usage, best practices, and anti-patterns to avoid such as using KEYS commands. It also covers strategies for cache-aside patterns and updating hot keys to avoid stampeding the database.



































































