Downloaded 13 times
![Realizing Service-Finder Web Service Discovery at Web Scale http://www.service-finder.eu Lecturer: Emanuele Della Valle [email_address] http://emanueledellavalle.org Authors: Emanuele Della Valle, Dario Cerizza, Irene Celino, Andrea Turati, Holger Lausen, Nathalie Steinmetz, Michael Erdmann, Wolfgang Schoch and Adam Funk](https://image.slidesharecdn.com/estc2008realizingsf-1222270575486773-9/75/Realizing-Service-Finder-at-ESTC-2008-1-2048.jpg)

![SOA onto the Web Service Oriented Architectures ( SOA s) along with Web Services technologies are widely seen as the most promising fundament for realizing service interchange in business to business settings. However , it is envisioned that SOA s and Web Services will increasingly move out of these settings and out onto the Web . 0 10.000 20.000 30.000 2008 [source http://seekda.com/about/web_services (September, 2008)] 2009 2007 [ http://aws.amazon.com/ ] [ http://developer.ebay.com/ ] number of accessible WSDL found by seekda](https://image.slidesharecdn.com/estc2008realizingsf-1222270575486773-9/75/Realizing-Service-Finder-at-ESTC-2008-3-2048.jpg)
![One of the essential building blocks for creating applications that utilize the vast quantities of services, which are available on the Web is making it easier to discovery and select the right services. UDDI was initially proposed as a component of Web Services usage process enabling registering and discovering services, but finally UDDI did not reach its expected potential. The critical problem in this new Web oriented environment is one of scale because services appear, disappear and change at a rate much higher than in business to business settings. UDDI Business Registry Shutdown . " With the approval of UDDI v3.02 as an OASIS Standard in 2005, and the momentum UDDI has achieved in market adoption, IBM, Microsoft and SAP have evaluated the status of the UDDI Business Registry and determined that the goals for the project have been achieved. Given this, the UDDI Business Registry will be discontinued as of 12 January 2006. " [from “Registering for UDDI” 2005-12-17 ] [see http://xml.coverpages.org/uddi.html ] The rise and fall of public UDDI registries](https://image.slidesharecdn.com/estc2008realizingsf-1222270575486773-9/75/Realizing-Service-Finder-at-ESTC-2008-4-2048.jpg)
















![Realizing Service-Finder Web Service Discovery at Web Scale http://www.service-finder.eu Lecturer: Emanuele Della Valle [email_address] http://emanueledellavalle.org Authors: Emanuele Della Valle, Dario Cerizza, Irene Celino, Andrea Turati, Holger Lausen, Nathalie Steinmetz, Michael Erdmann, Wolfgang Schoch and Adam Funk](https://image.slidesharecdn.com/estc2008realizingsf-1222270575486773-9/75/Realizing-Service-Finder-at-ESTC-2008-25-2048.jpg)

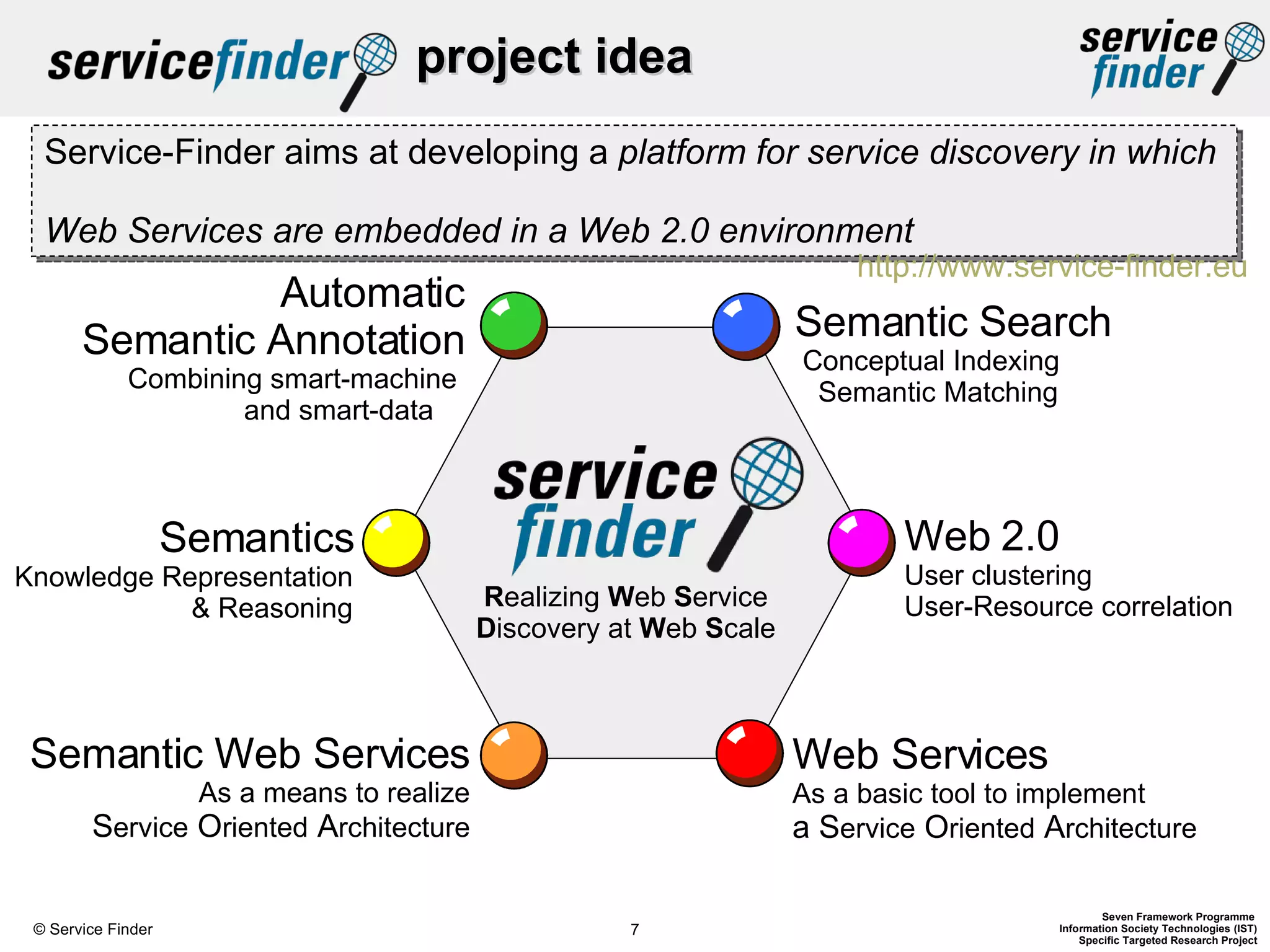
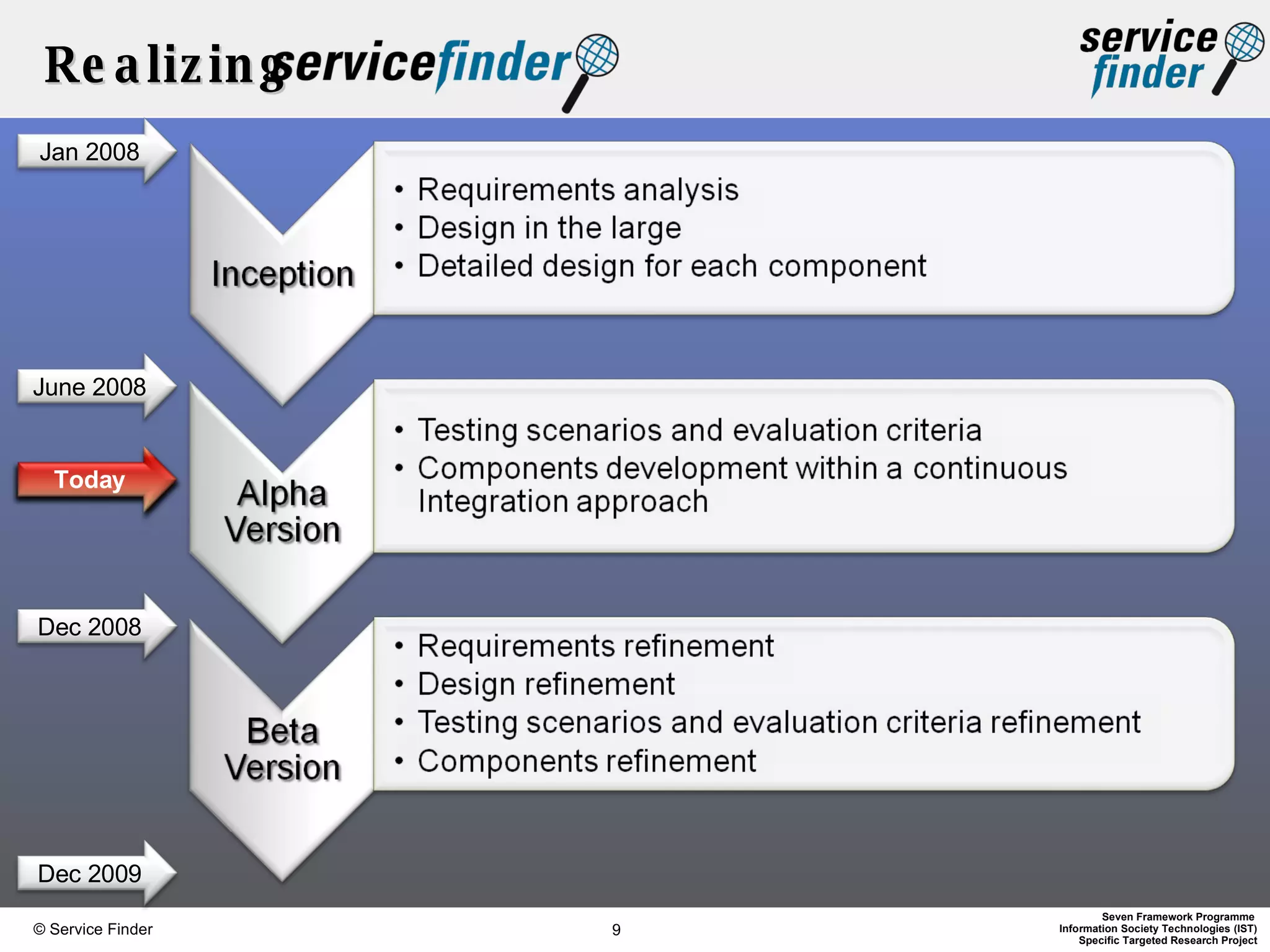
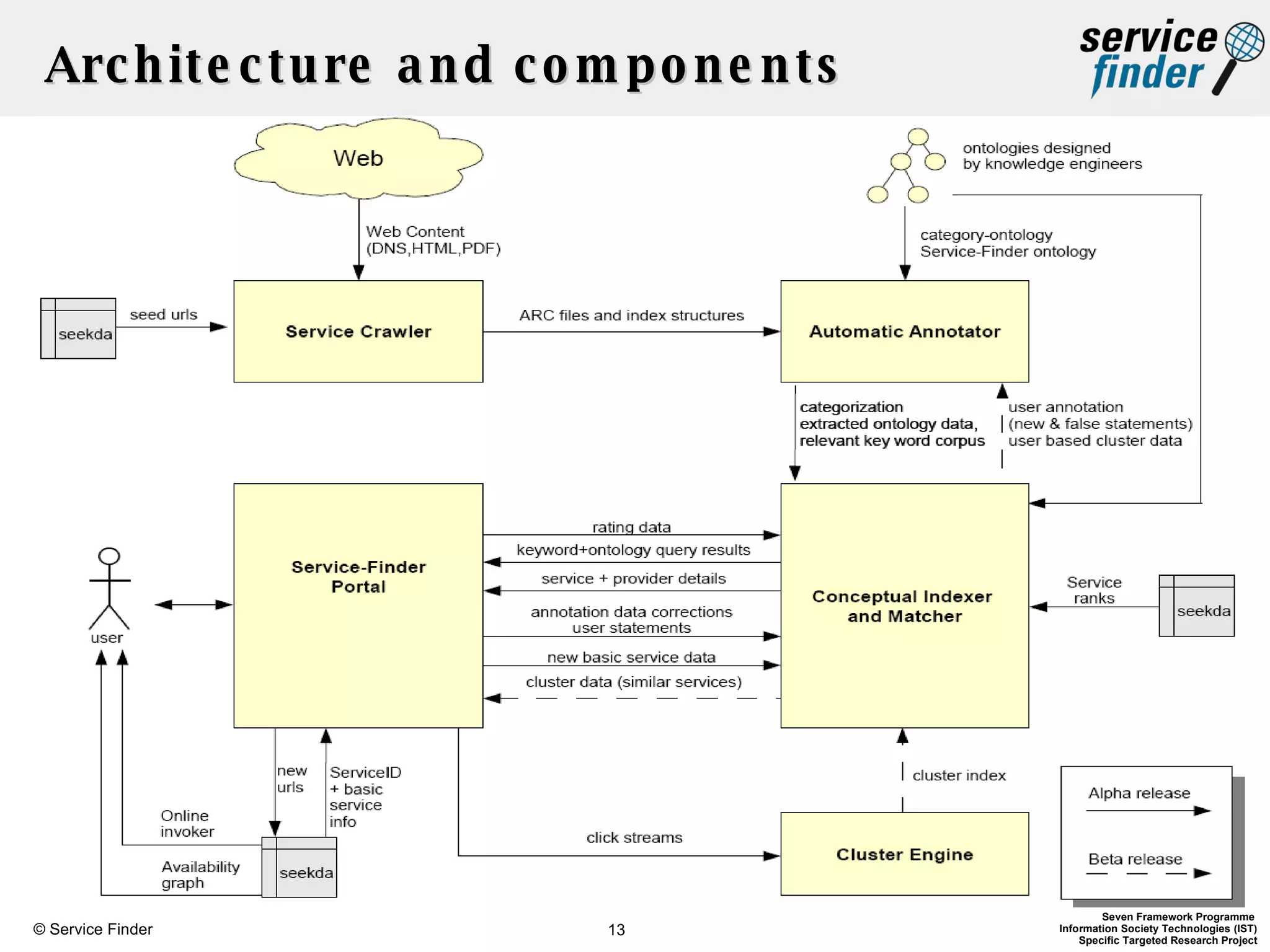
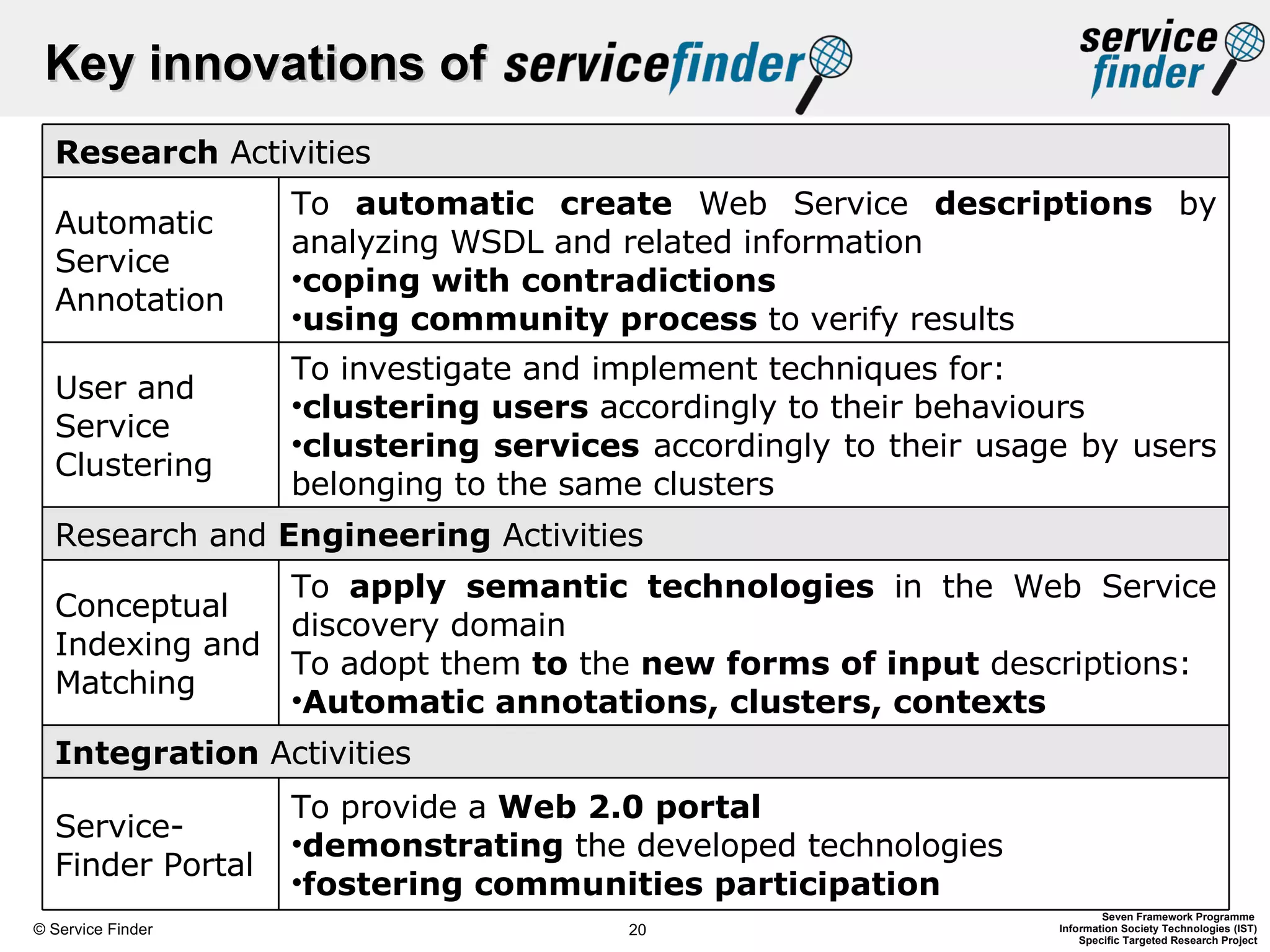
The document discusses the Service-Finder project, which aims to enhance web service discovery by addressing the limitations of public UDDI registries through a semantic search engine and web 2.0 functionalities. Key objectives include creating a service crawler, generating semantic service descriptions, and providing a user-friendly platform for searching and browsing services. The document emphasizes innovations in automatic service annotation and user-service clustering to improve the search experience and adjust to the rapidly changing web service landscape.




























































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




