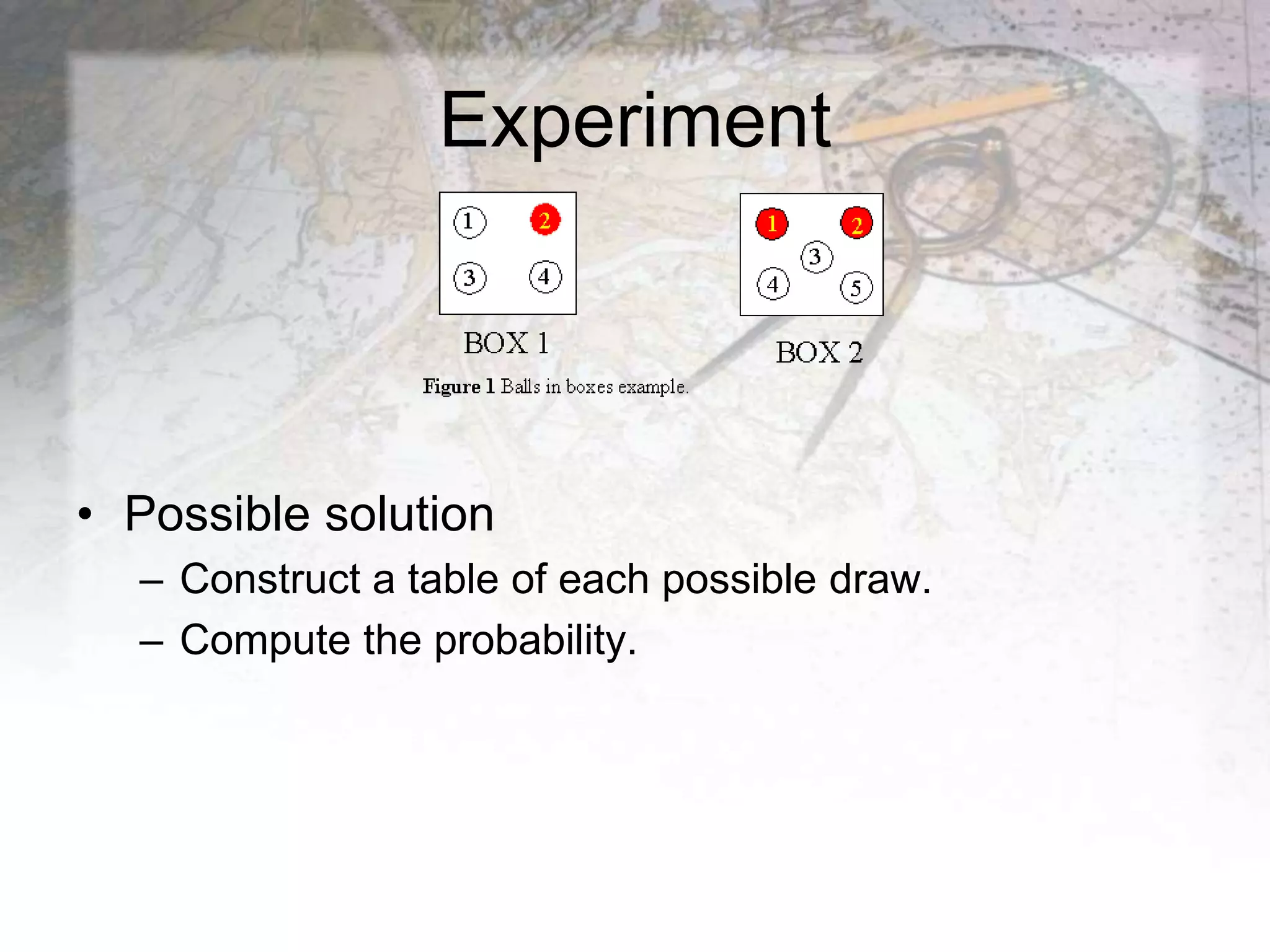
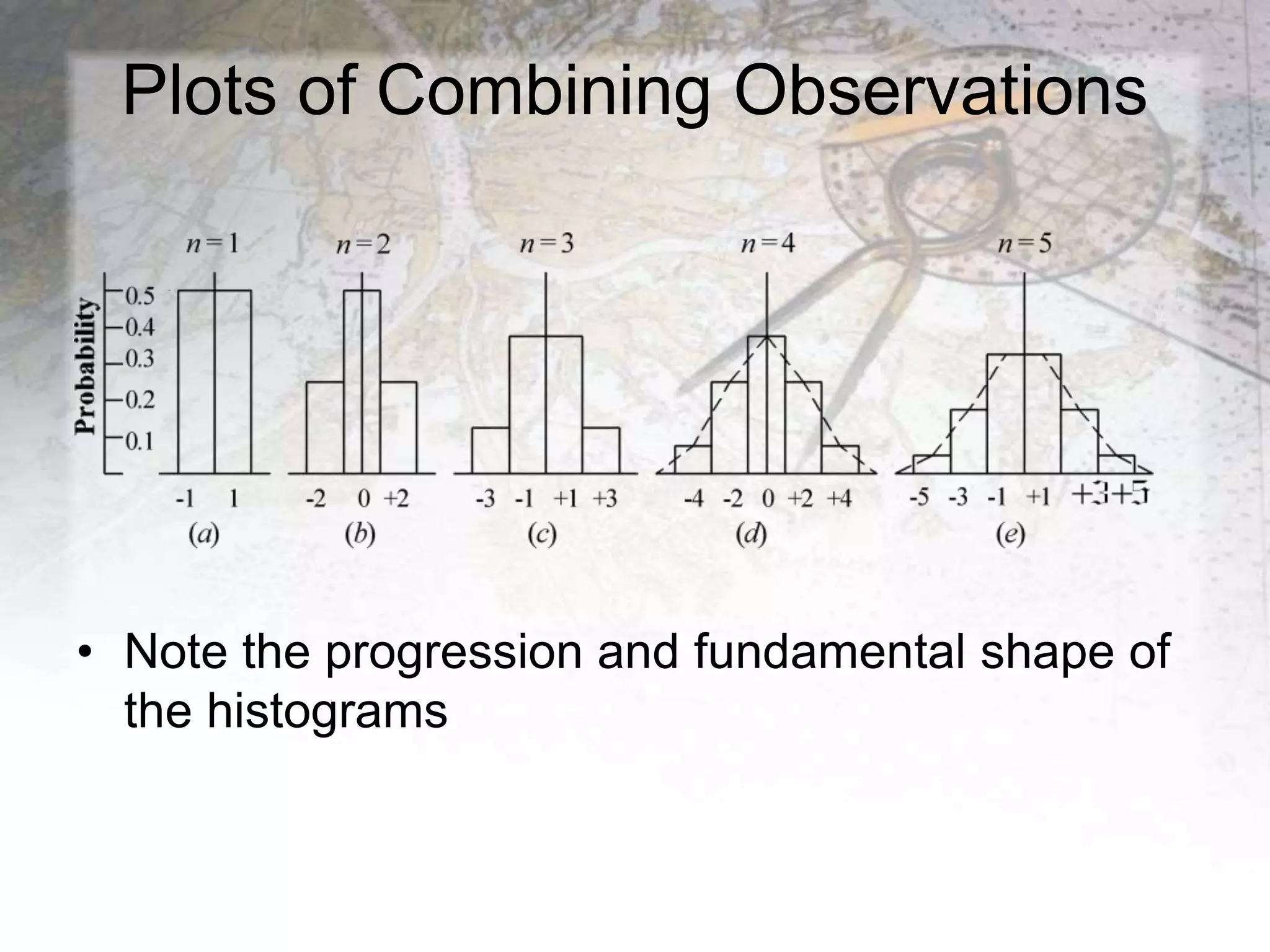
Chapter 3 of the random error theory discusses the concepts of probability and its applications in experiments, highlighting how to calculate individual and compound event probabilities. It also covers the normal distribution curve, properties of distribution, and the significance of standard deviation in determining data precision. Furthermore, it addresses common confidence levels used in statistical analysis, such as 50%, 95%, and 99.7% probable errors.



























![Properties of Distribution
• P(−t < z < t) = P(|z| < t)
= Nz(t) − Nz(−t)
– From the symmetry of the normal distribution, P(z > t)
= P(z < −t)
– Thus the 1 − Nz(t) = Nz(−t)
– So, P(|z| < t) = Nz(t) − [1 − Nz(t)]
= 2Nz(t) − 1
-z +z
-t +t](https://image.slidesharecdn.com/3-randomerrortheory-230622223918-74c54997/75/Random-Error-Theory-30-2048.jpg)


































![Week7 Quiz Help 2009[1]](https://cdn.slidesharecdn.com/ss_thumbnails/week7quizhelp20091-091012152329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
































