Download to read offline

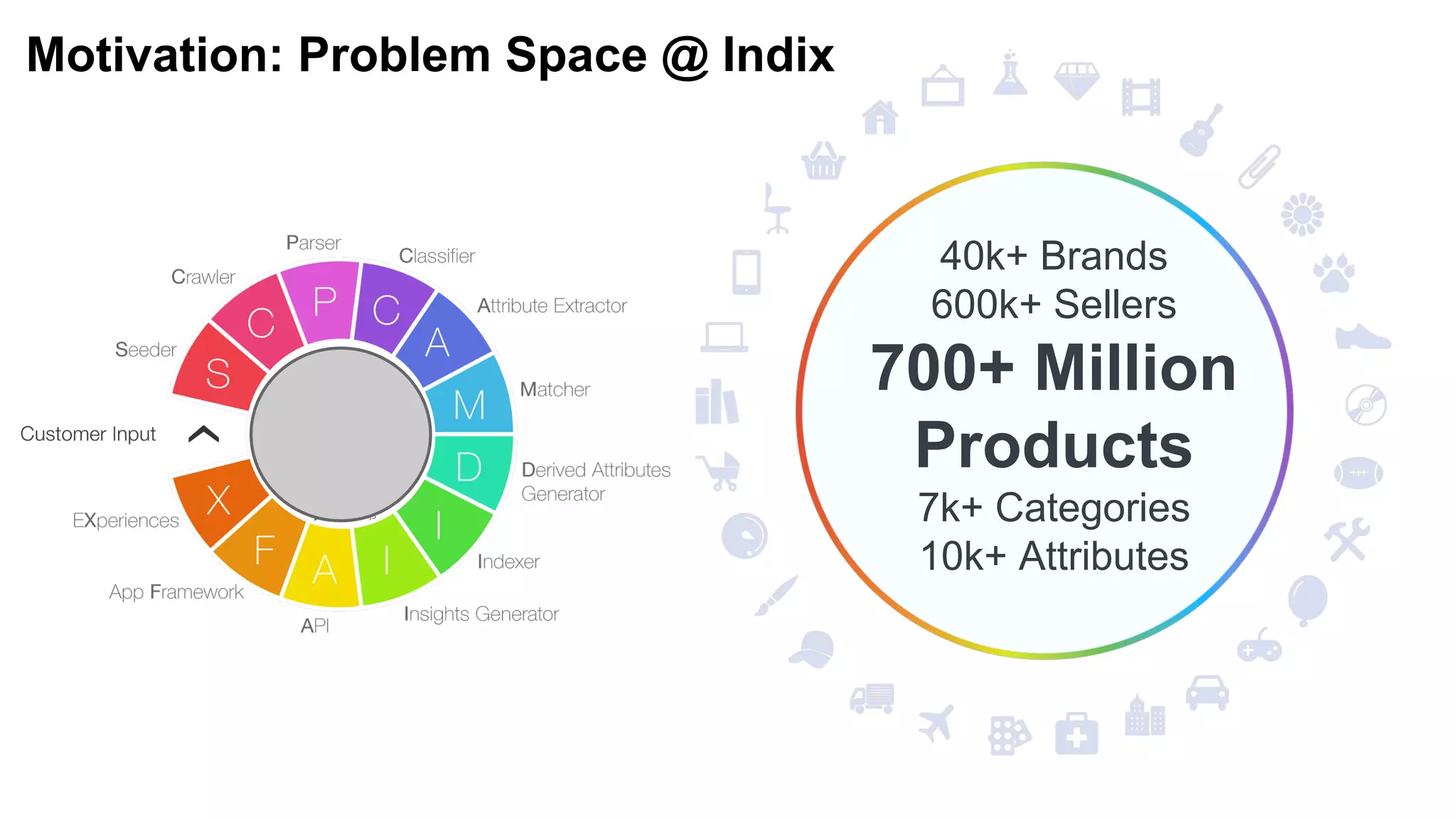
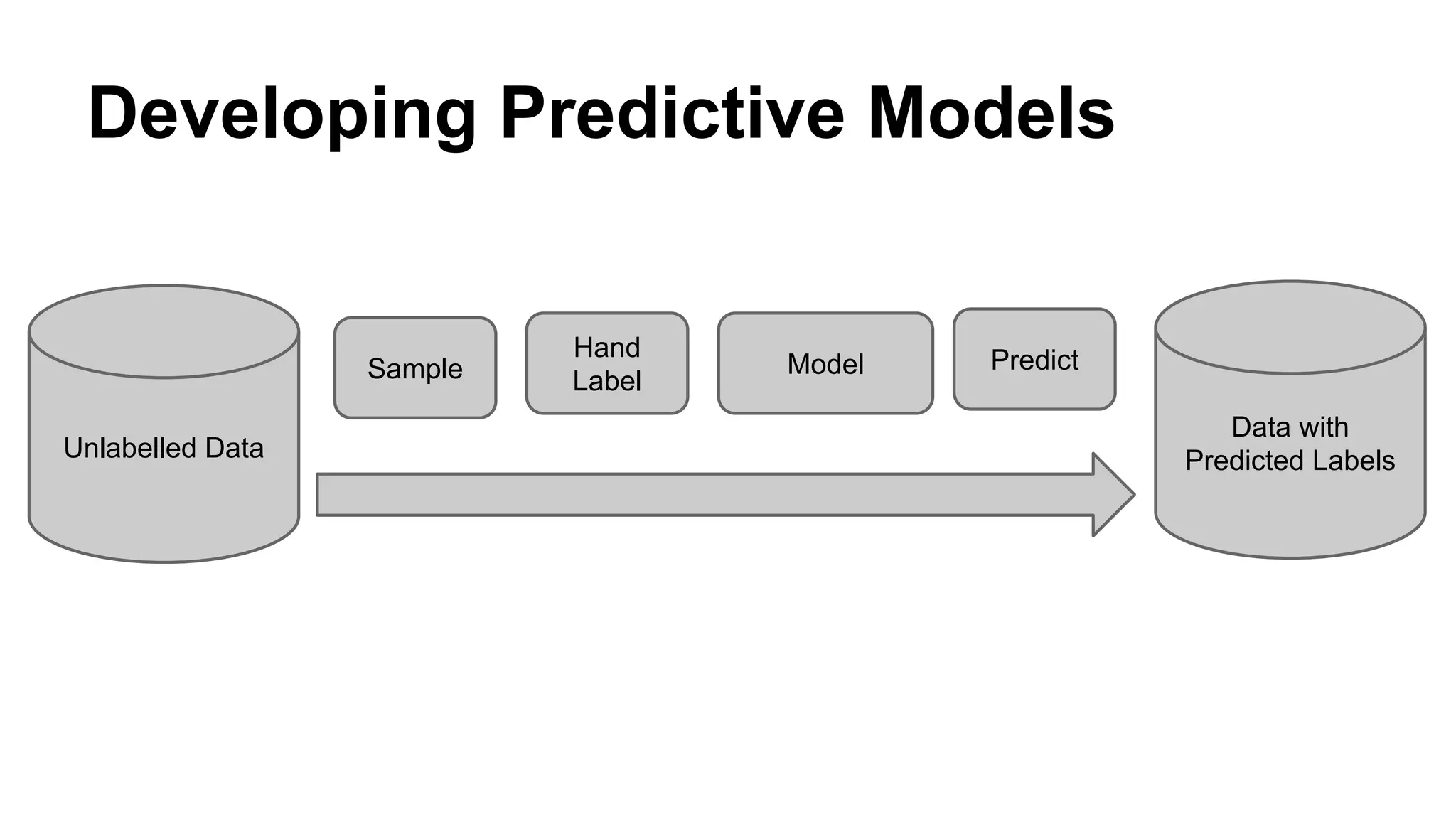
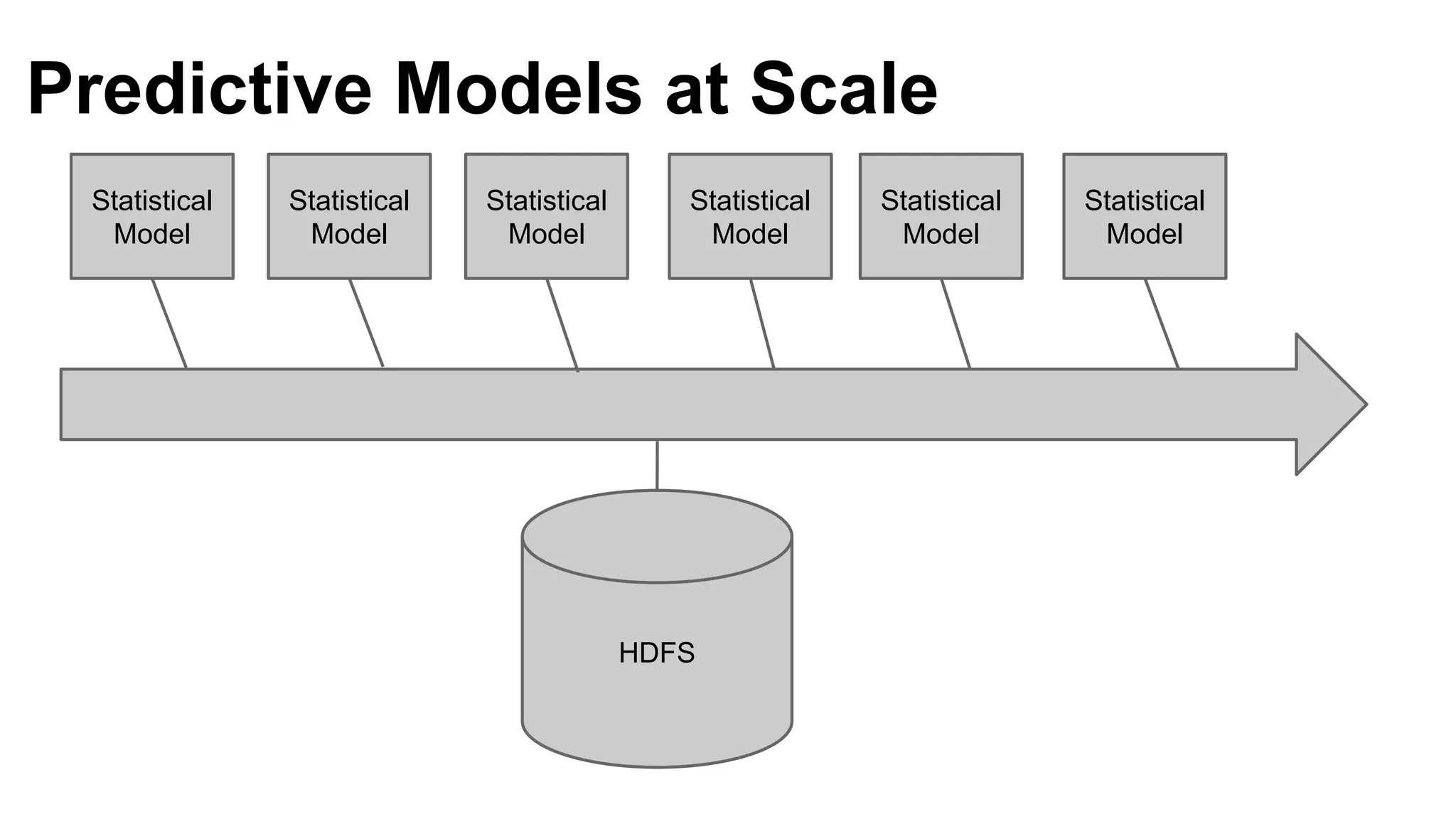
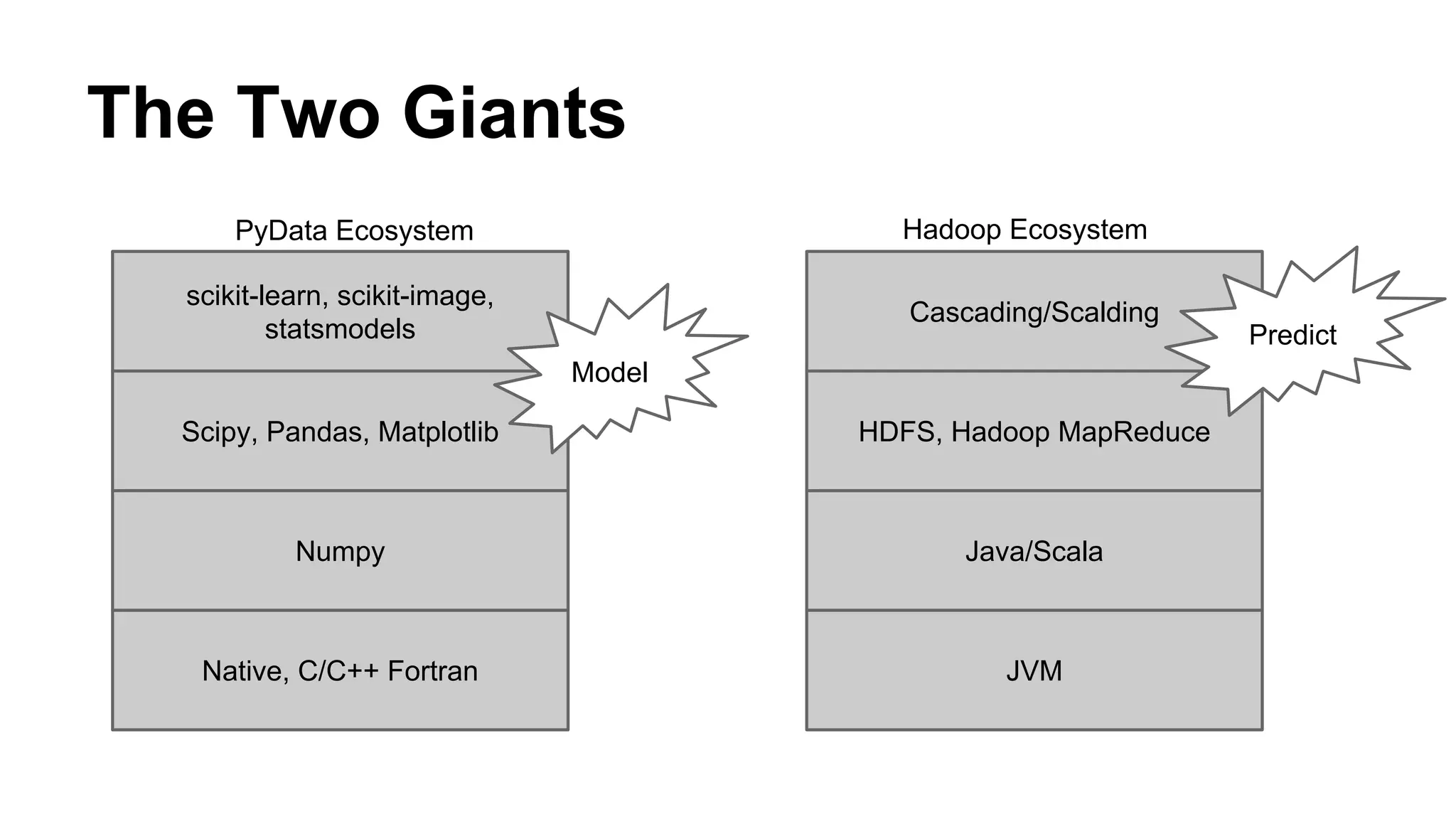





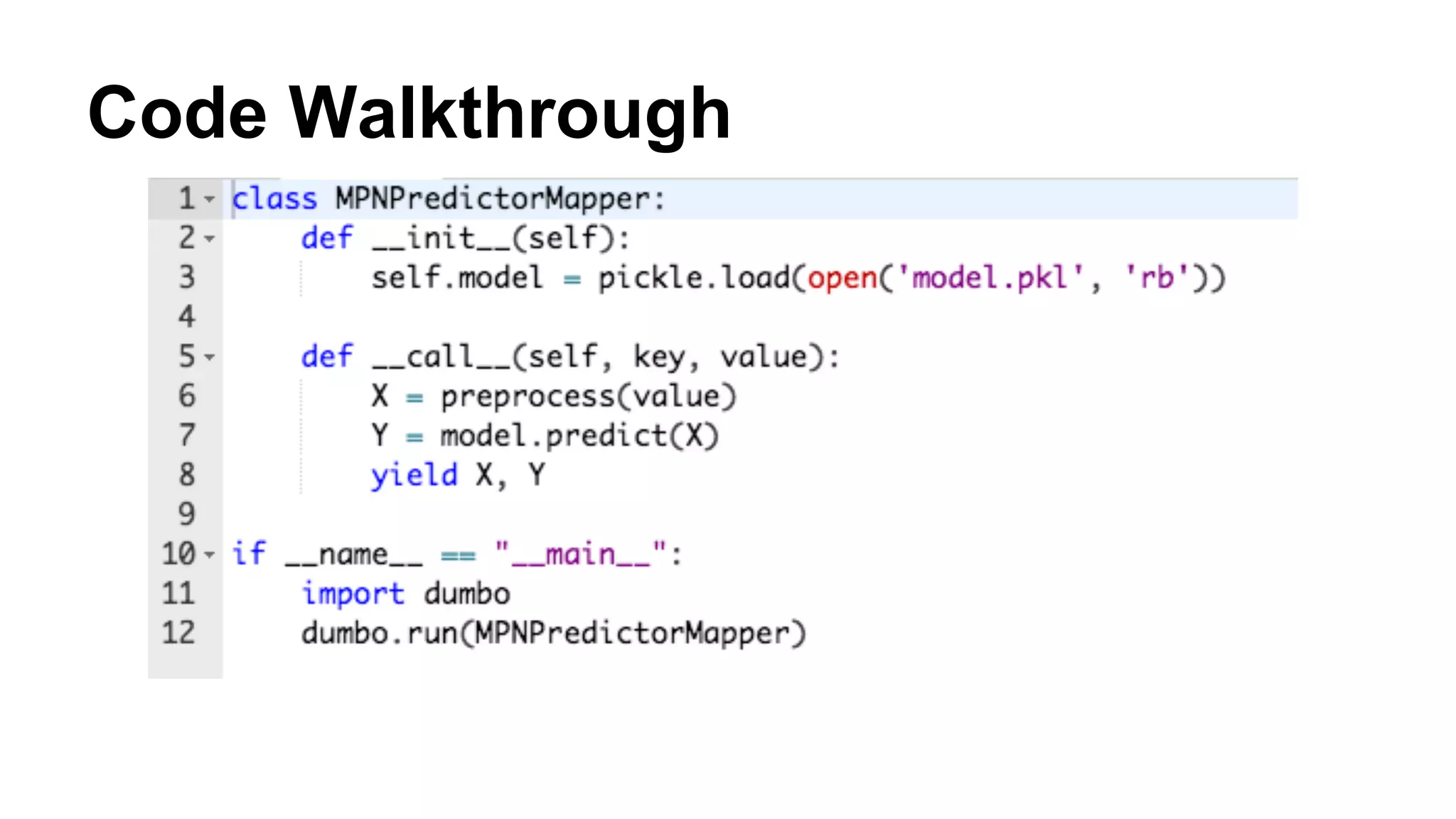


Dumbo is a Python framework that allows Python code to run on Hadoop for predictive modeling at scale. It bridges the gap between the Python data science ecosystem and the Hadoop ecosystem by enabling Python code to run as MapReduce jobs. This allows leveraging Python libraries for machine learning and data analysis while taking advantage of Hadoop's distributed processing. The presentation discusses challenges with existing approaches, introduces Dumbo, and walks through an example of using it to extract model part numbers from product titles at scale.















































