The document provides an overview of the Play Framework, which is a full-stack web framework based on Netty, detailing its components, features, and structure. It also covers key concepts such as routing, controller actions, views, JPA/Hibernate for data persistence, database evolution tracking, and logging best practices. Additionally, it discusses dependency injection with Guice and the usage of filters for cross-cutting concerns in web applications.






























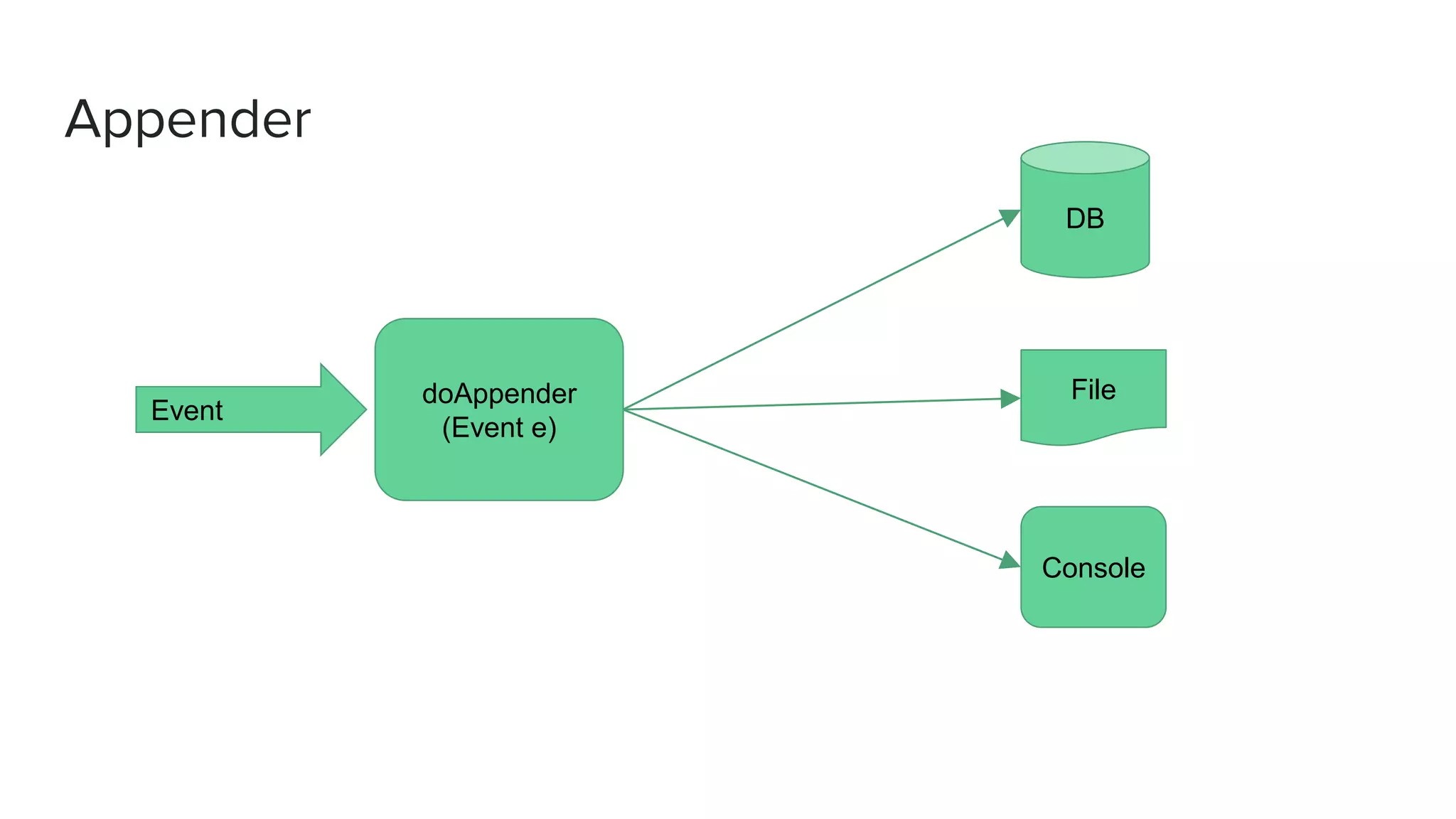

![Sample appender logback.xml
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>${application.home:-.}/logs/application.log</file>
<encoder>
<pattern>%date [%level] from %logger in %thread - %message%n%xException</pattern>
</encoder>
</appender>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%coloredLevel %logger{15} - %message%n%xException{10}</pattern>
</encoder>
</appender>
<appender name="ASYNCFILE" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="FILE" />
</appender>
<appender name="ASYNCSTDOUT" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="STDOUT" />
</appender>](https://image.slidesharecdn.com/yourbigidea1-170714121755/75/Play-framework-A-Walkthrough-40-2048.jpg)























![Java 6 [Mustang] - Features and Enchantments](https://cdn.slidesharecdn.com/ss_thumbnails/java6ee-110917082211-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[Start] Playing](https://cdn.slidesharecdn.com/ss_thumbnails/start-playing-121117211541-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














![Automating ISP Networks Using Ansible and IPAM as a Source of Truth [SoT]](https://cdn.slidesharecdn.com/ss_thumbnails/automatingispnetworksusingansibleandipamasasourceoftruthsot-v25-1-251124105117-d7d4ca24-thumbnail.jpg?width=640&height=640&fit=bounds)













