On-Device or Remote? On the Energy Efficiency of Fetching LLM-Generated Content (CAIN 2025)
Slides of the presentation by Vincenzo Stoico at the main track of the 4th International Conference on AI Engineering (CAIN 2025).
The paper is available here: http://www.ivanomalavolta.com/files/papers/CAIN_2025.pdf
On-Device or Remote? On the Energy Efficiency of Fetching LLM-Generated Content (CAIN 2025)
1.
On-Device or Remote?On the Energy Efficiency of
Fetching LLM-Generated Content
1
Vince Nguyen, 1
Vidya Dhopate, 1
Hieu Huynh, 1
Hiba Bouhlal, 1
Anusha Annengala,
2
Gian Luca Scoccia, 3
Matias Martinez, 1
Vincenzo Stoico, 1
Ivano Malavolta
1
Vrije Universiteit Amsterdam, The Netherlands, 2
Gran Sasso Science Institute, Italy,
3
Universitat Politècnica de Catalunya, Spain
{x.nguyenthanhvinh | v.dhopate | x.huynhthaihieu | h.bouhlal | a.annengala}@student.vu.nl,
gianluca.scoccia@gssi.it, matias.martinez@upc.edu, v.stoico@vu.nl, i.malavolta@vu.nl
2.
Introduction
2
Advantages of fetchingcontent locally
✓ Enhanced privacy: No HTTP requests to remote servers →
reduced data exposure
✓ Offline functionality: Continuous access without
connectivity
✓ Latency reduction: Local processing enables real-time
responses
curl https://api.openai.com/v1/responses
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{
"model": "gpt-4.1",
"input": "Write a one-sentence bedtime
story about a unicorn."
}'
Fetching Remote Data
OpenAI developer platform, https://platform.openai.com/docs/overview?lang=curl
Martine Paris, Forbes, https://shorturl.at/BkAKH
3.
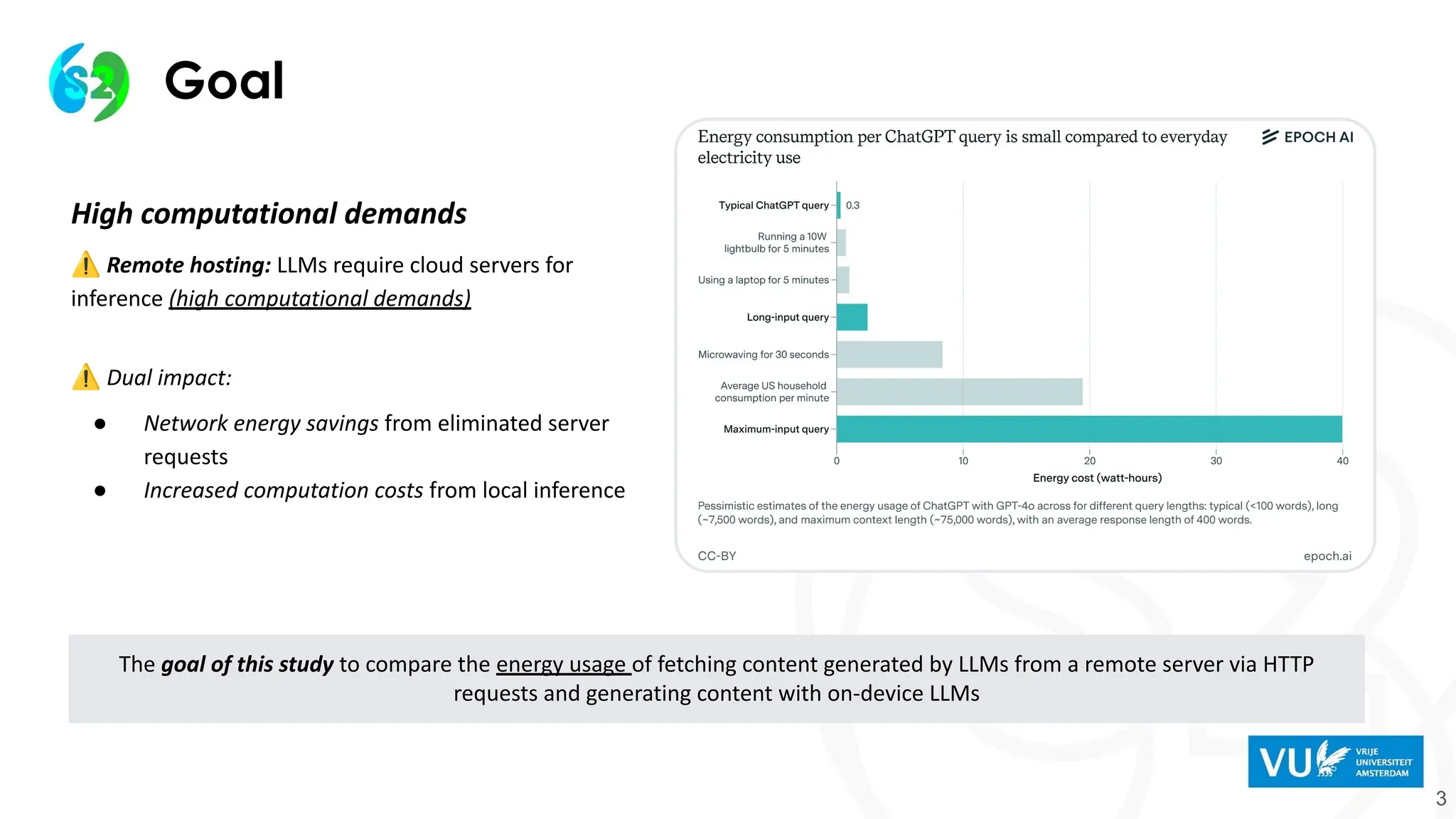
Goal
3
High computational demands
⚠Remote hosting: LLMs require cloud servers for
inference (high computational demands)
⚠ Dual impact:
● Network energy savings from eliminated server
requests
● Increased computation costs from local inference
The goal of this study to compare the energy usage of fetching content generated by LLMs from a remote server via HTTP
requests and generating content with on-device LLMs
4.
Study Design
4
RQ1: Howdoes the energy usage of the client machine
differ when fetching LLMs-generated content on-device
versus remotely?
RQ2: What is the correlation between performance
metrics and the energy usage of the client machine
when fetching LLMs-generated content on-device versus
remotely?
- RQ2.1: Execution Time
- RQ2.2: CPU Usage
- RQ2.3: GPU Usage
- RQ2.4: Memory Usage
(2 Fetching Methods x 7 LLMs x 3 Output Lengths) x 30 Repetitions = 1260 Runs
Blocking Factor - Output Length:
Short (100 words), Medium (500 words), and Long (1000 words)
Yuan, Y. et al. The Impact of Knowledge Distillation on the
Energy Consumption and Runtime Efficiency of NLP Models, CAIN
2024, https://shorturl.at/1Uqvb
5.
Subjects Selection
5
7 QuantizedLLMs via Ollama
● 10 to 30 seconds to generate content
● More than 3 million downloads as of October
2024
Llama 3.1 8B
Gemma1.1 2B and 7B
Qwen2 1.5B and 7B
Phi3 3B
Mistral 0.3 7B
Prompt Topics
● Most-viewed Wikipedia pages from Dec. 1, 2007 to Jan. 1, 2023
● Extracted 101 topics
“Please give me information about [topic]”
6.
Experiment Execution
6
HTTP Requests:
-On-device: the Python code makes on-device HTTP GET requests to
http://localhost/api/generate
- Remote: we expose the server’s IP address publicly so it can be called by
our test on-device machine http://[server_IP_address]/api/generate
Experiment Runner: Python-based framework to define and execute the steps
of an experiment on any platform
Steps to mitigate confounding factors:
- Randomize the order of all individual runs
- Cooldown period of 90 seconds
- Control fan speed (6000 rotations per minutes)
S2 Group, Experiment Runner, https://github.com/S2-group/experiment-runner
7.
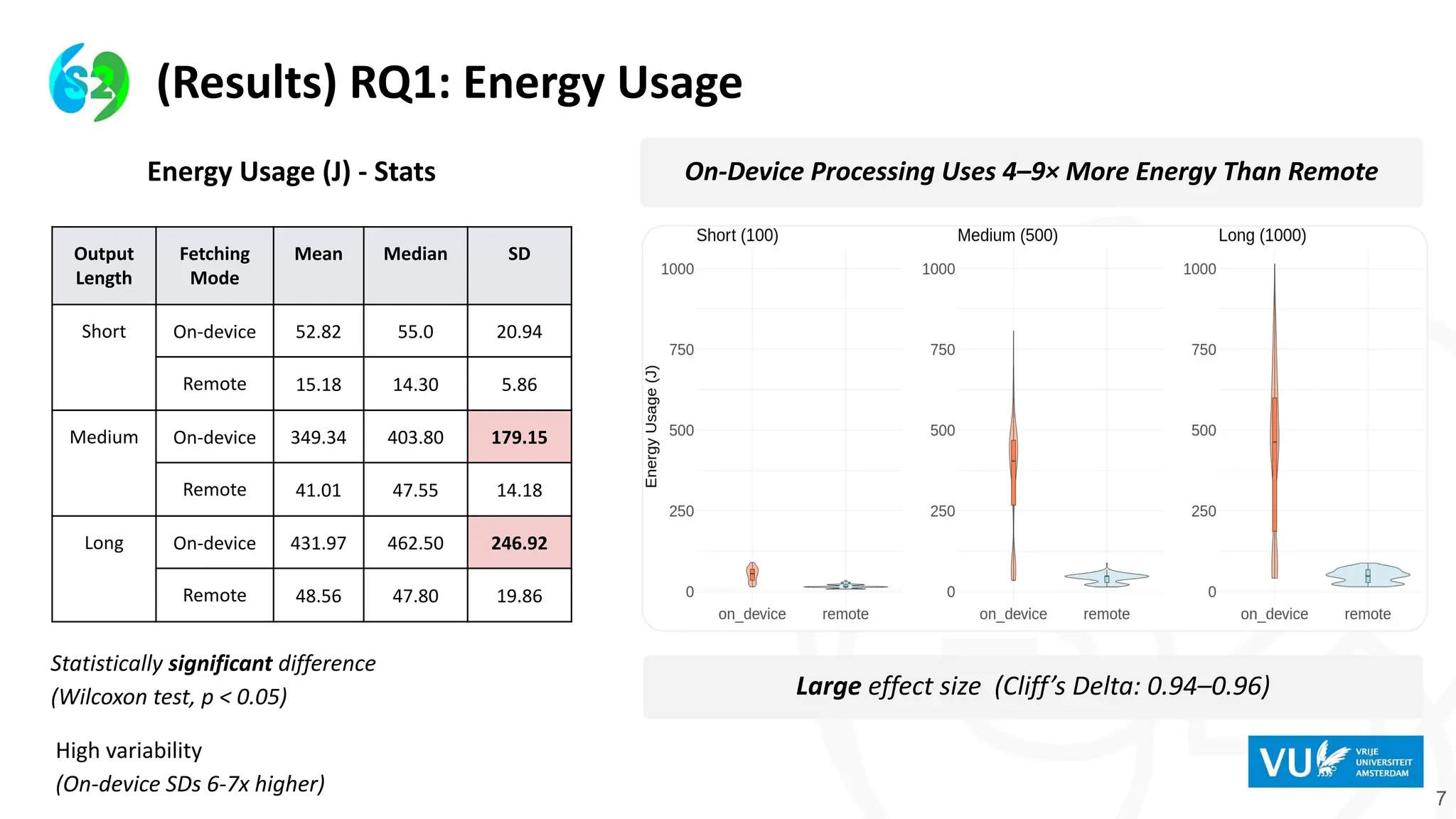
7
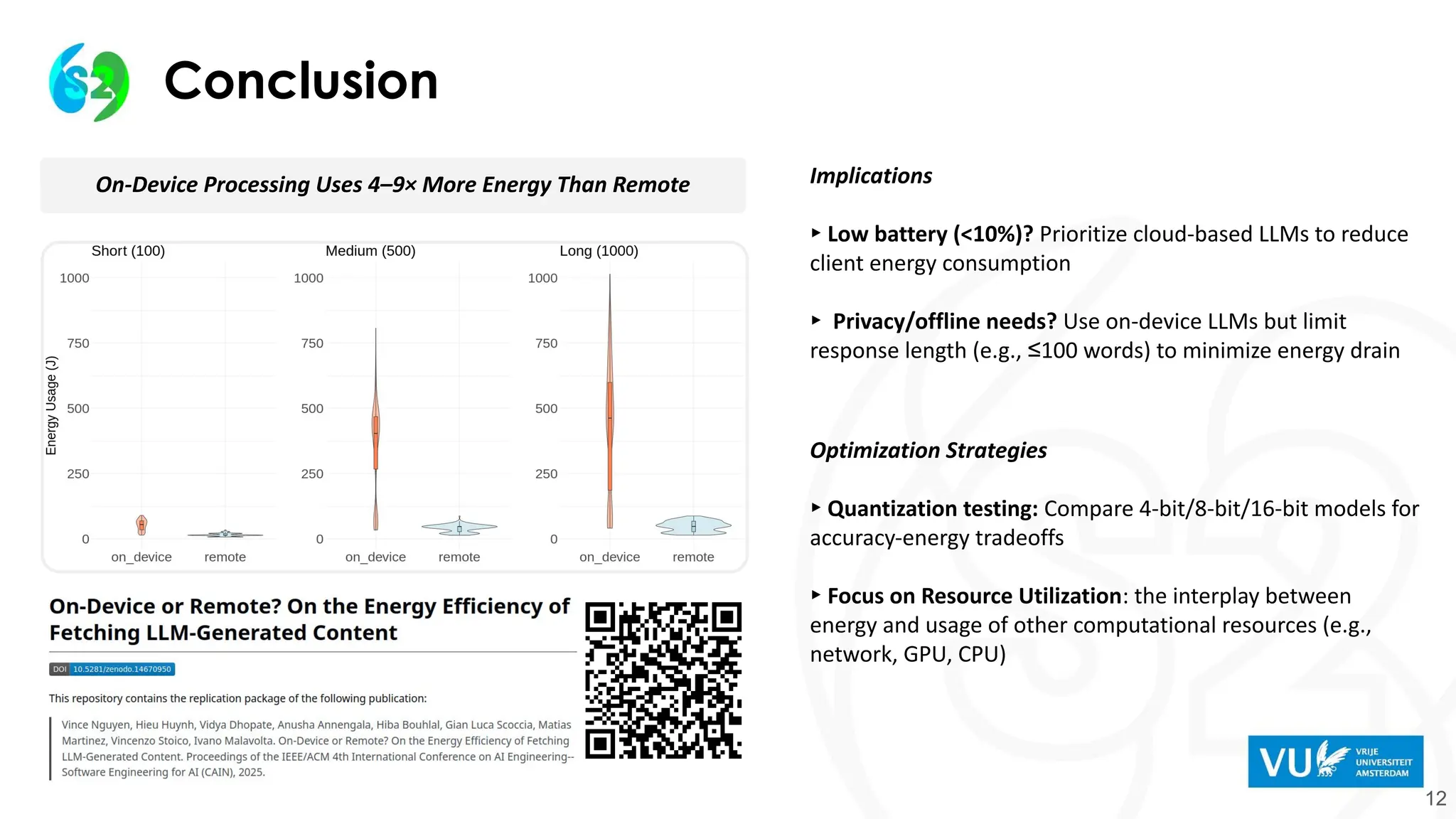
On-Device Processing Uses4–9× More Energy Than Remote
(Results) RQ1: Energy Usage
Output
Length
Fetching
Mode
Mean Median SD
Short On-device 52.82 55.0 20.94
Remote 15.18 14.30 5.86
Medium On-device 349.34 403.80 179.15
Remote 41.01 47.55 14.18
Long On-device 431.97 462.50 246.92
Remote 48.56 47.80 19.86
Energy Usage (J) - Stats
Statistically significant difference
(Wilcoxon test, p < 0.05)
High variability
(On-device SDs 6-7x higher)
Large effect size (Cliff’s Delta: 0.94–0.96)
8.
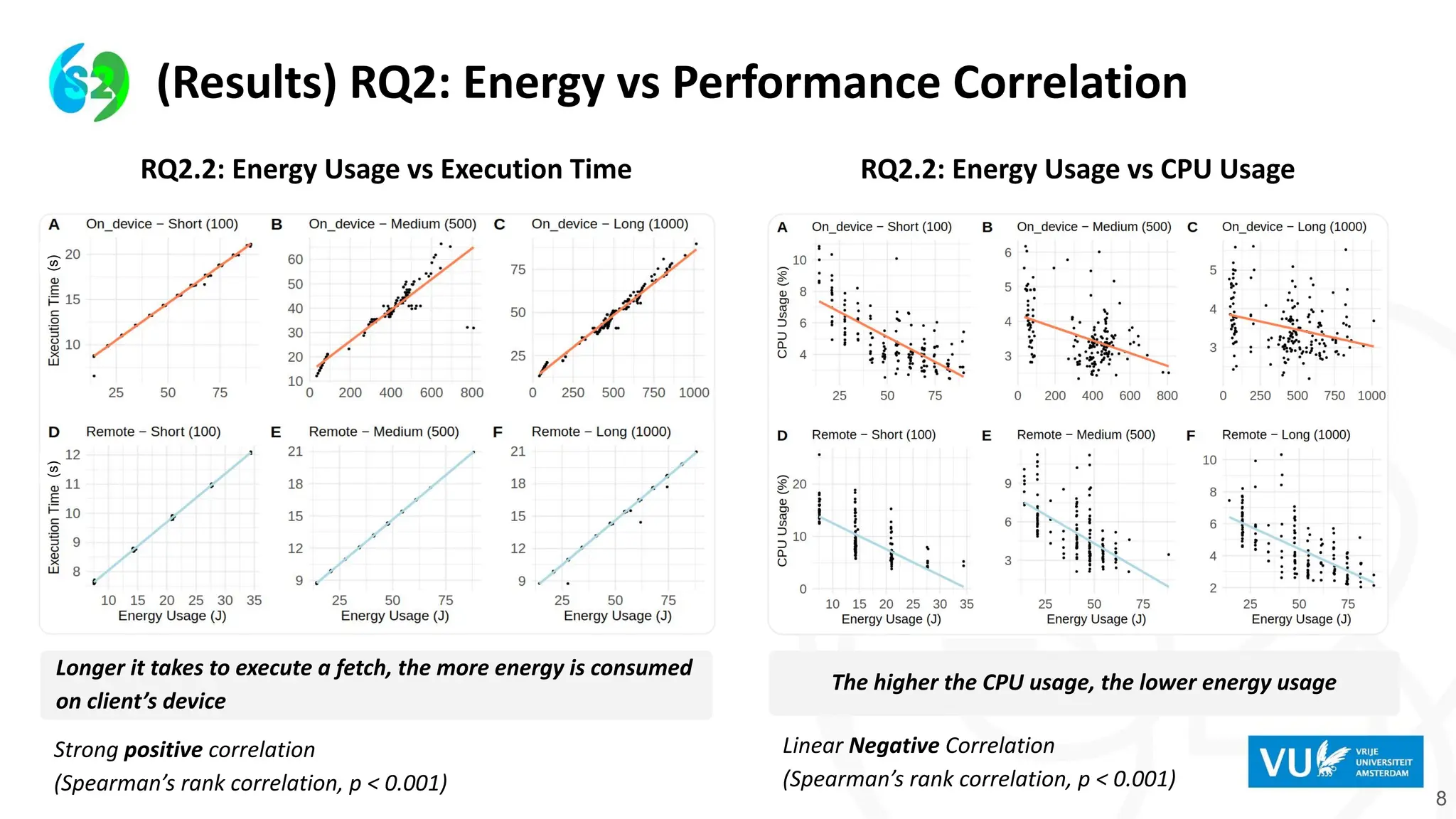
8
(Results) RQ2: Energyvs Performance Correlation
Longer it takes to execute a fetch, the more energy is consumed
on client’s device
The higher the CPU usage, the lower energy usage
RQ2.2: Energy Usage vs CPU Usage
RQ2.2: Energy Usage vs Execution Time
Strong positive correlation
(Spearman’s rank correlation, p < 0.001)
Linear Negative Correlation
(Spearman’s rank correlation, p < 0.001)
(s)
(s)
9.
9
(Results) RQ2: Energyvs Performance Correlation
RQ2.2: Energy Usage vs Memory Usage
RQ2.2: Energy Usage vs GPU Usage
GPU usage has greater impact on longer, more complex
generated content
No evident pattern between energy and memory usage
Small positive difference in On-Device
Statistically significant negative correlation in Remote (p < 0.001)
No significant correlation in Remote (p in [0.57 - 0.89])
Significant positive correlation in On-Device (p < 0.001)
10.
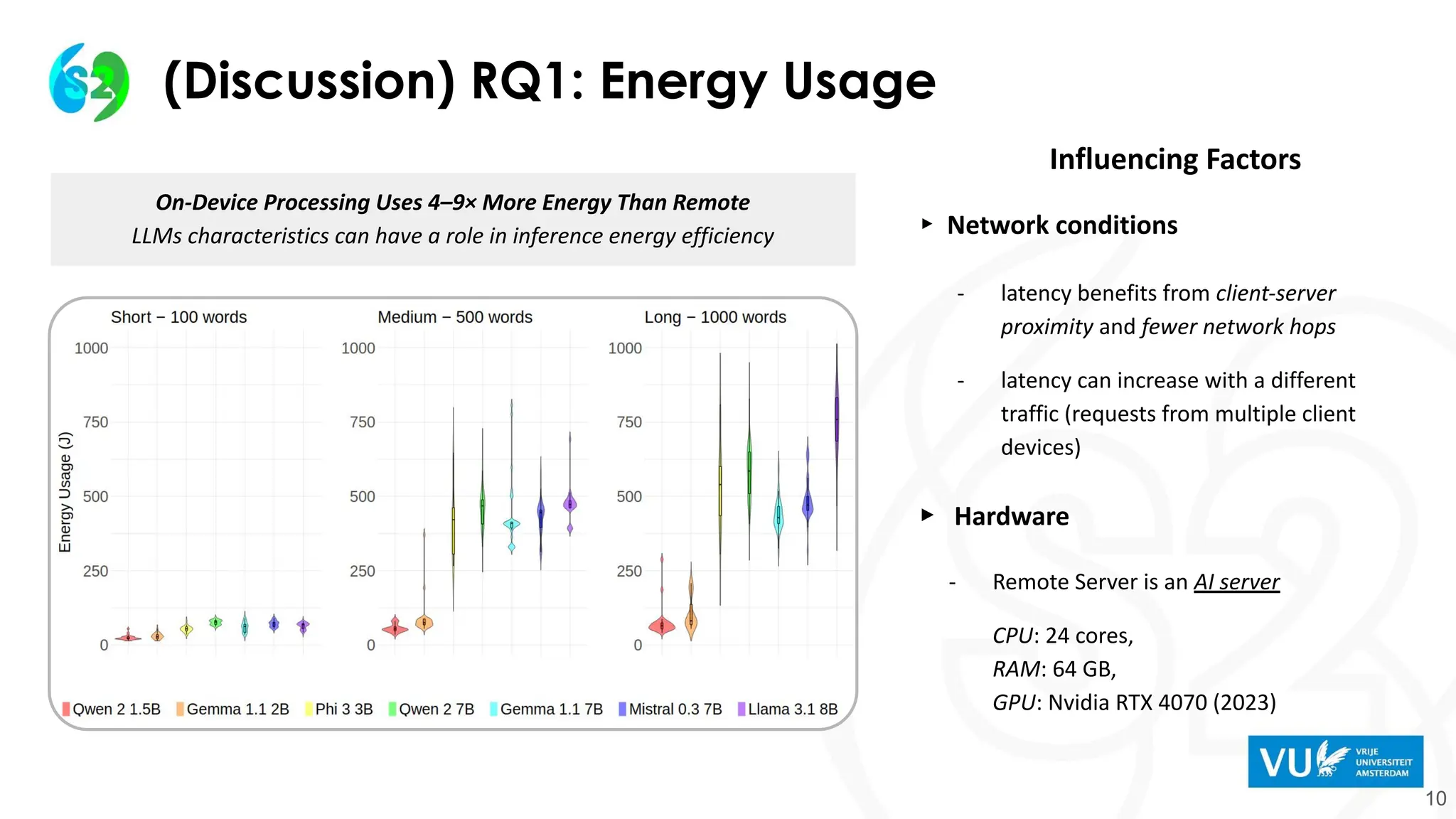
(Discussion) RQ1: EnergyUsage
10
On-Device Processing Uses 4–9× More Energy Than Remote
LLMs characteristics can have a role in inference energy efficiency
Influencing Factors
▸ Network conditions
- latency benefits from client-server
proximity and fewer network hops
- latency can increase with a different
traffic (requests from multiple client
devices)
▸ Hardware
- Remote Server is an AI server
CPU: 24 cores,
RAM: 64 GB,
GPU: Nvidia RTX 4070 (2023)
11.
11
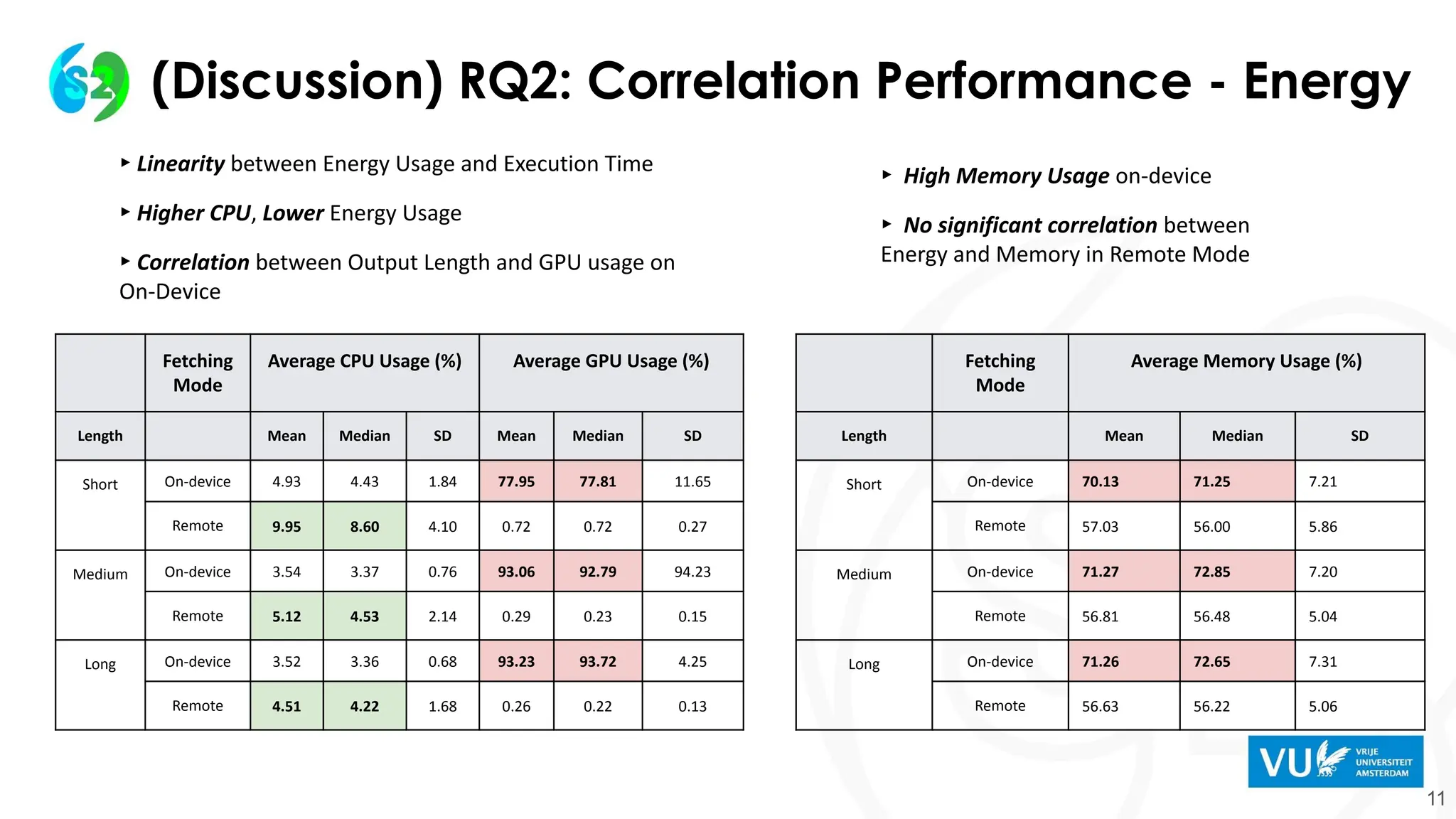
(Discussion) RQ2: CorrelationPerformance - Energy
Fetching
Mode
Average CPU Usage (%) Average GPU Usage (%)
Length Mean Median SD Mean Median SD
Short On-device 4.93 4.43 1.84 77.95 77.81 11.65
Remote 9.95 8.60 4.10 0.72 0.72 0.27
Medium On-device 3.54 3.37 0.76 93.06 92.79 94.23
Remote 5.12 4.53 2.14 0.29 0.23 0.15
Long On-device 3.52 3.36 0.68 93.23 93.72 4.25
Remote 4.51 4.22 1.68 0.26 0.22 0.13
Fetching
Mode
Average Memory Usage (%)
Length Mean Median SD
Short On-device 70.13 71.25 7.21
Remote 57.03 56.00 5.86
Medium On-device 71.27 72.85 7.20
Remote 56.81 56.48 5.04
Long On-device 71.26 72.65 7.31
Remote 56.63 56.22 5.06
▸ Linearity between Energy Usage and Execution Time
▸ Higher CPU, Lower Energy Usage
▸ Correlation between Output Length and GPU usage on
On-Device
▸ High Memory Usage on-device
▸ No significant correlation between
Energy and Memory in Remote Mode
12.
Conclusion
12
On-Device Processing Uses4–9× More Energy Than Remote Implications
▸ Low battery (<10%)? Prioritize cloud-based LLMs to reduce
client energy consumption
▸ Privacy/offline needs? Use on-device LLMs but limit
response length (e.g., ≤100 words) to minimize energy drain
Optimization Strategies
▸ Quantization testing: Compare 4-bit/8-bit/16-bit models for
accuracy-energy tradeoffs
▸ Focus on Resource Utilization: the interplay between
energy and usage of other computational resources (e.g.,
network, GPU, CPU)



![Subjects Selection
5
7 Quantized LLMs via Ollama
● 10 to 30 seconds to generate content
● More than 3 million downloads as of October
2024
Llama 3.1 8B
Gemma1.1 2B and 7B
Qwen2 1.5B and 7B
Phi3 3B
Mistral 0.3 7B
Prompt Topics
● Most-viewed Wikipedia pages from Dec. 1, 2007 to Jan. 1, 2023
● Extracted 101 topics
“Please give me information about [topic]”](https://image.slidesharecdn.com/cain25-on-250509090634-334d12ff/75/On-Device-or-Remote-On-the-Energy-Efficiency-of-Fetching-LLM-Generated-Content-CAIN-2025-5-2048.jpg)
![Experiment Execution
6
HTTP Requests:
- On-device: the Python code makes on-device HTTP GET requests to
http://localhost/api/generate
- Remote: we expose the server’s IP address publicly so it can be called by
our test on-device machine http://[server_IP_address]/api/generate
Experiment Runner: Python-based framework to define and execute the steps
of an experiment on any platform
Steps to mitigate confounding factors:
- Randomize the order of all individual runs
- Cooldown period of 90 seconds
- Control fan speed (6000 rotations per minutes)
S2 Group, Experiment Runner, https://github.com/S2-group/experiment-runner](https://image.slidesharecdn.com/cain25-on-250509090634-334d12ff/75/On-Device-or-Remote-On-the-Energy-Efficiency-of-Fetching-LLM-Generated-Content-CAIN-2025-6-2048.jpg)
![9
(Results) RQ2: Energy vs Performance Correlation
RQ2.2: Energy Usage vs Memory Usage
RQ2.2: Energy Usage vs GPU Usage
GPU usage has greater impact on longer, more complex
generated content
No evident pattern between energy and memory usage
Small positive difference in On-Device
Statistically significant negative correlation in Remote (p < 0.001)
No significant correlation in Remote (p in [0.57 - 0.89])
Significant positive correlation in On-Device (p < 0.001)](https://image.slidesharecdn.com/cain25-on-250509090634-334d12ff/75/On-Device-or-Remote-On-the-Energy-Efficiency-of-Fetching-LLM-Generated-Content-CAIN-2025-9-2048.jpg)



















![FL Studio Crack 24 Free Serial Key [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/webnn-maximsalnikov-april2025-250414171347-bc8c21fc-250419080023-bd655bb3-thumbnail.jpg?width=640&height=640&fit=bounds)










![[2017/2018] AADL - Architecture Analysis and Design Language](https://cdn.slidesharecdn.com/ss_thumbnails/ivano04saaadl-171122165132-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017/2018] Introduction to Software Architecture](https://cdn.slidesharecdn.com/ss_thumbnails/ivano02softwarearchitecture-171120182731-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017/2018] RESEARCH in software engineering](https://cdn.slidesharecdn.com/ss_thumbnails/ivano01seresearch-171120182253-thumbnail.jpg?width=640&height=640&fit=bounds)
![Object-oriented design patterns in UML [Software Design] [Computer Science] [...](https://cdn.slidesharecdn.com/ss_thumbnails/04designpatterns-180228160652-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017/2018] Architectural languages](https://cdn.slidesharecdn.com/ss_thumbnails/ivano03salanguages-171122083931-thumbnail.jpg?width=640&height=640&fit=bounds)
![Modeling objects interaction via UML sequence diagrams [Software Design] [Com...](https://cdn.slidesharecdn.com/ss_thumbnails/06sequencediagrams-180314152521-thumbnail.jpg?width=640&height=640&fit=bounds)
![Requirements engineering with UML [Software Design] [Computer Science] [Vrije...](https://cdn.slidesharecdn.com/ss_thumbnails/02requirements-180213083117-thumbnail.jpg?width=640&height=640&fit=bounds)
![Modeling behaviour via UML state machines [Software Design] [Computer Science...](https://cdn.slidesharecdn.com/ss_thumbnails/05statemachines-180306225932-thumbnail.jpg?width=640&height=640&fit=bounds)



![[2017/2018] Agile development](https://cdn.slidesharecdn.com/ss_thumbnails/ivano05agiledevelopment-171123214423-thumbnail.jpg?width=640&height=640&fit=bounds)
![How Maintainability Issues of Android Apps Evolve [ICSME 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/icsme2018-180928081558-thumbnail.jpg?width=640&height=640&fit=bounds)


![Modeling and abstraction, software development process [Software Design] [Com...](https://cdn.slidesharecdn.com/ss_thumbnails/01intro-180206151252-thumbnail.jpg?width=640&height=640&fit=bounds)
![Structure modeling with UML [Software Design] [Computer Science] [Vrije Unive...](https://cdn.slidesharecdn.com/ss_thumbnails/03structuremodeling-180219151135-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



