Downloaded 23 times






![Typical OLAP query profile
16.57% postgres postgres [.] slot_deform_tuple
13.39% postgres postgres [.] ExecEvalExpr
8.64% postgres postgres [.] advance_aggregates
8.58% postgres postgres [.] advance_transition_function
5.83% postgres postgres [.] float8_accum
5.14% postgres postgres [.] tuplehash_insert
3.89% postgres postgres [.] float8pl
3.60% postgres postgres [.] slot_getattr
2.66% postgres postgres [.] bpchareq
2.56% postgres postgres [.] heap_getnext](https://image.slidesharecdn.com/hfixdnx2svwbyzitw9oi-signature-dc0af156a173f3f3d25bf64670dba6b4ac9be865f28c24c83500f1fd9d09dd24-poli-201222094036/75/OLTP-OLAP-HTAP-7-2048.jpg)






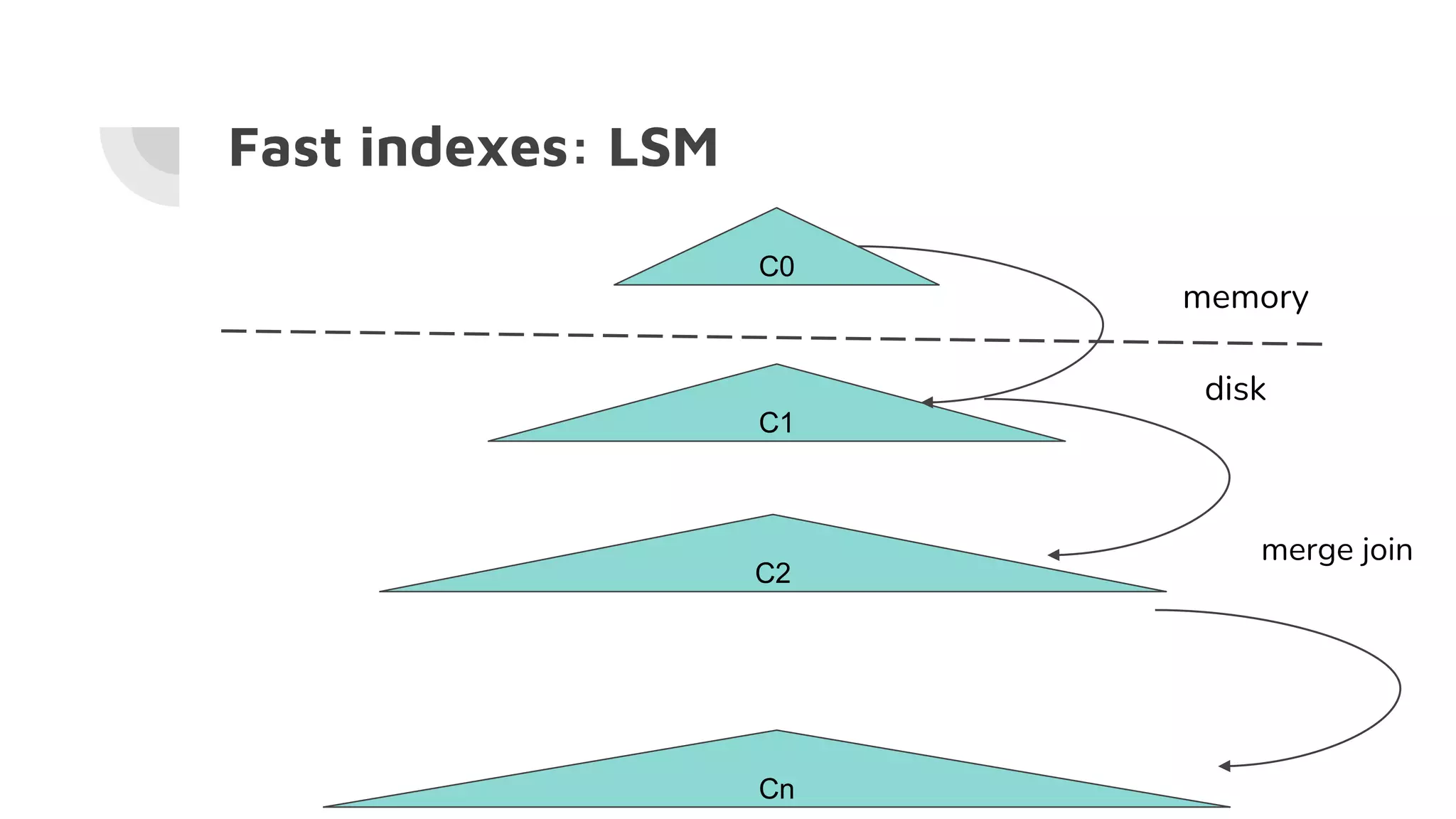




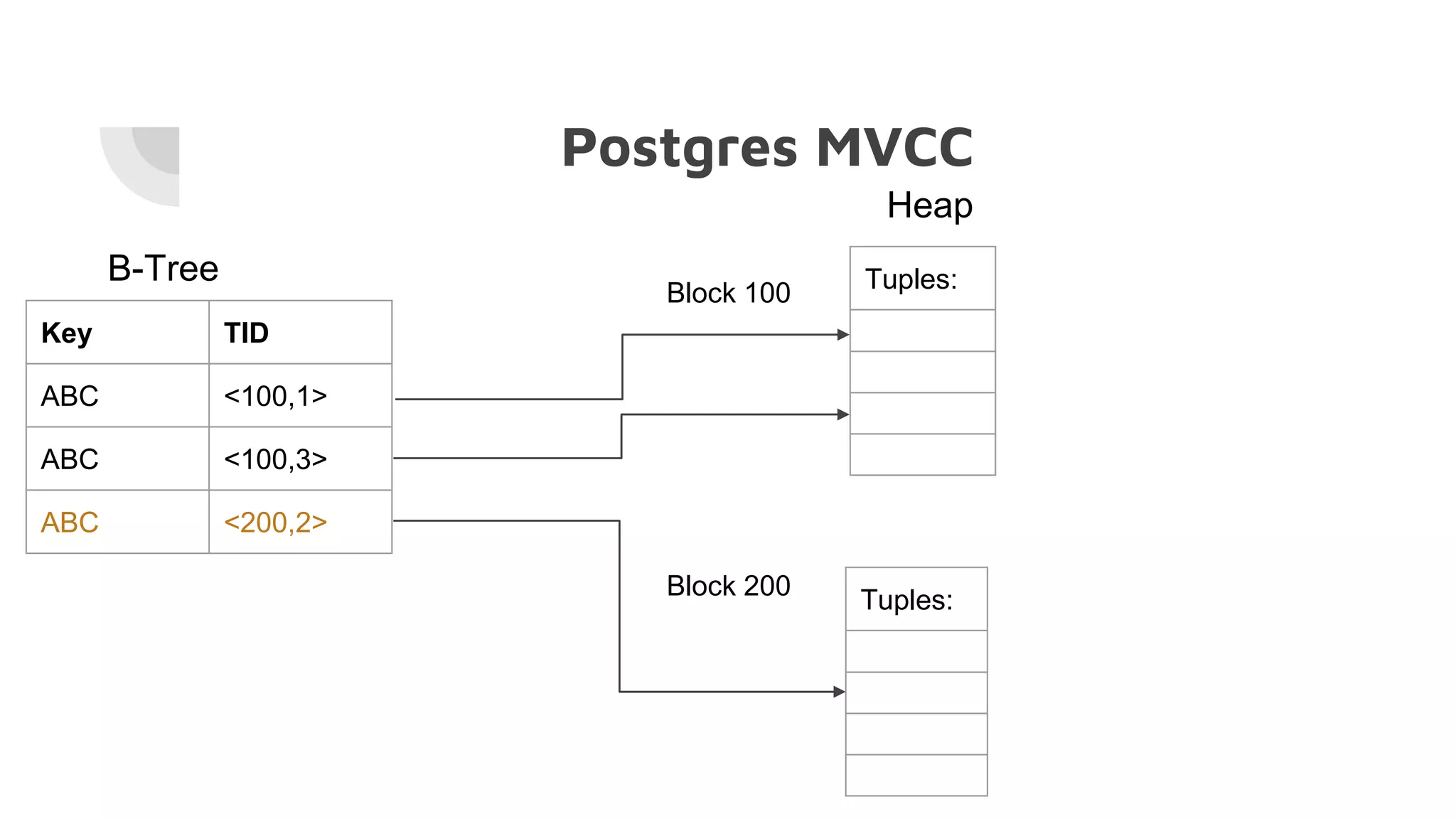
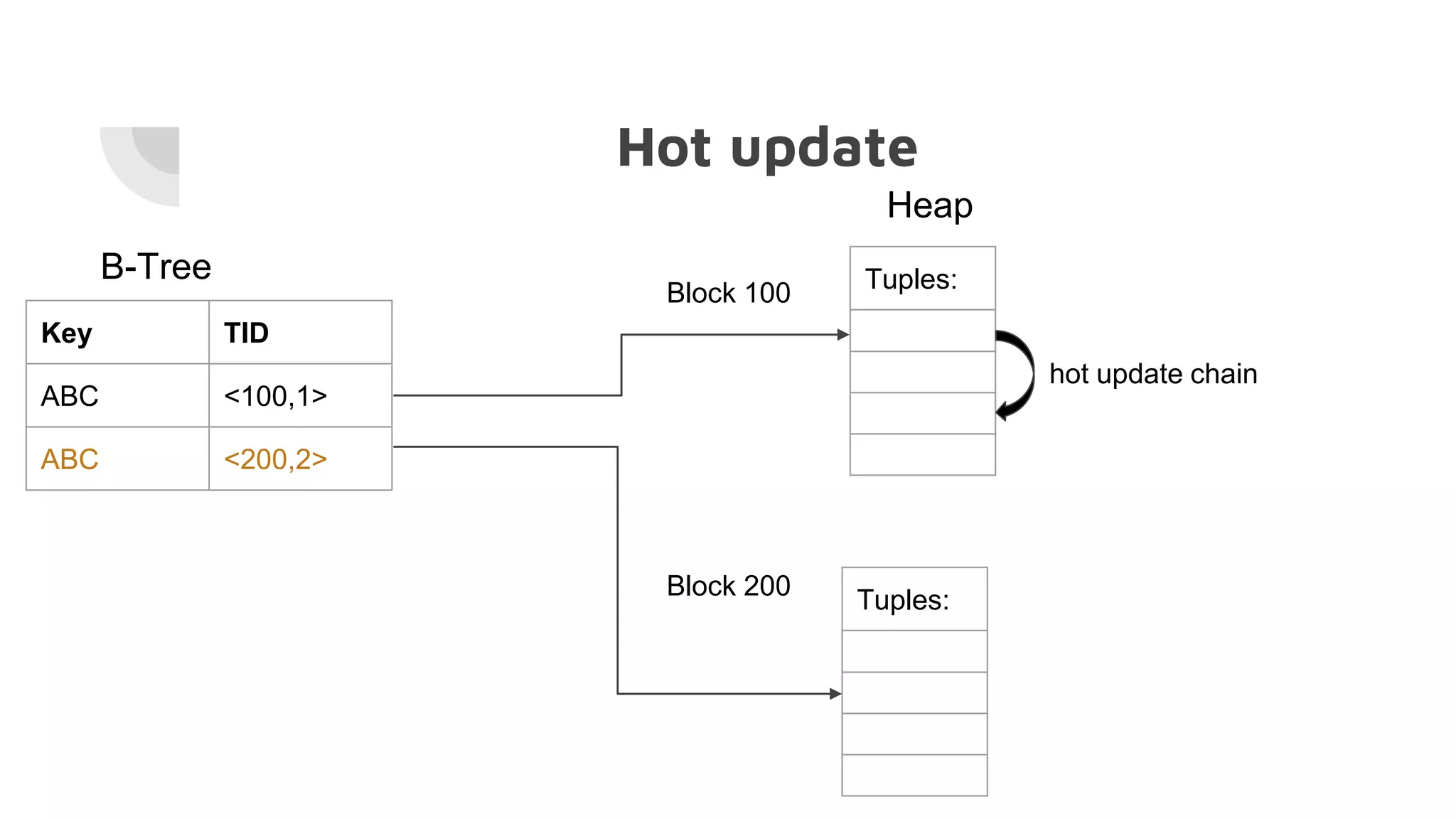
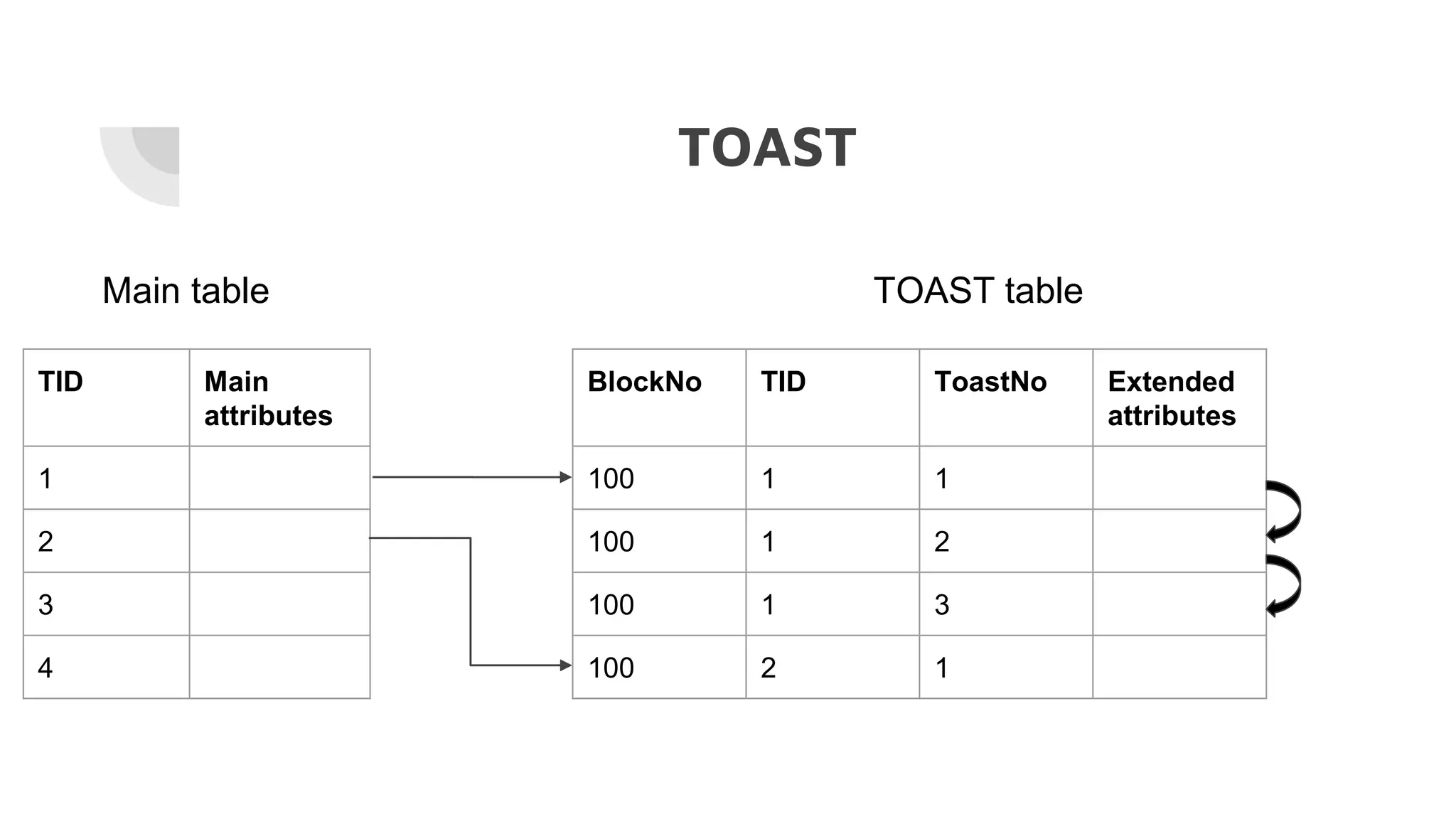

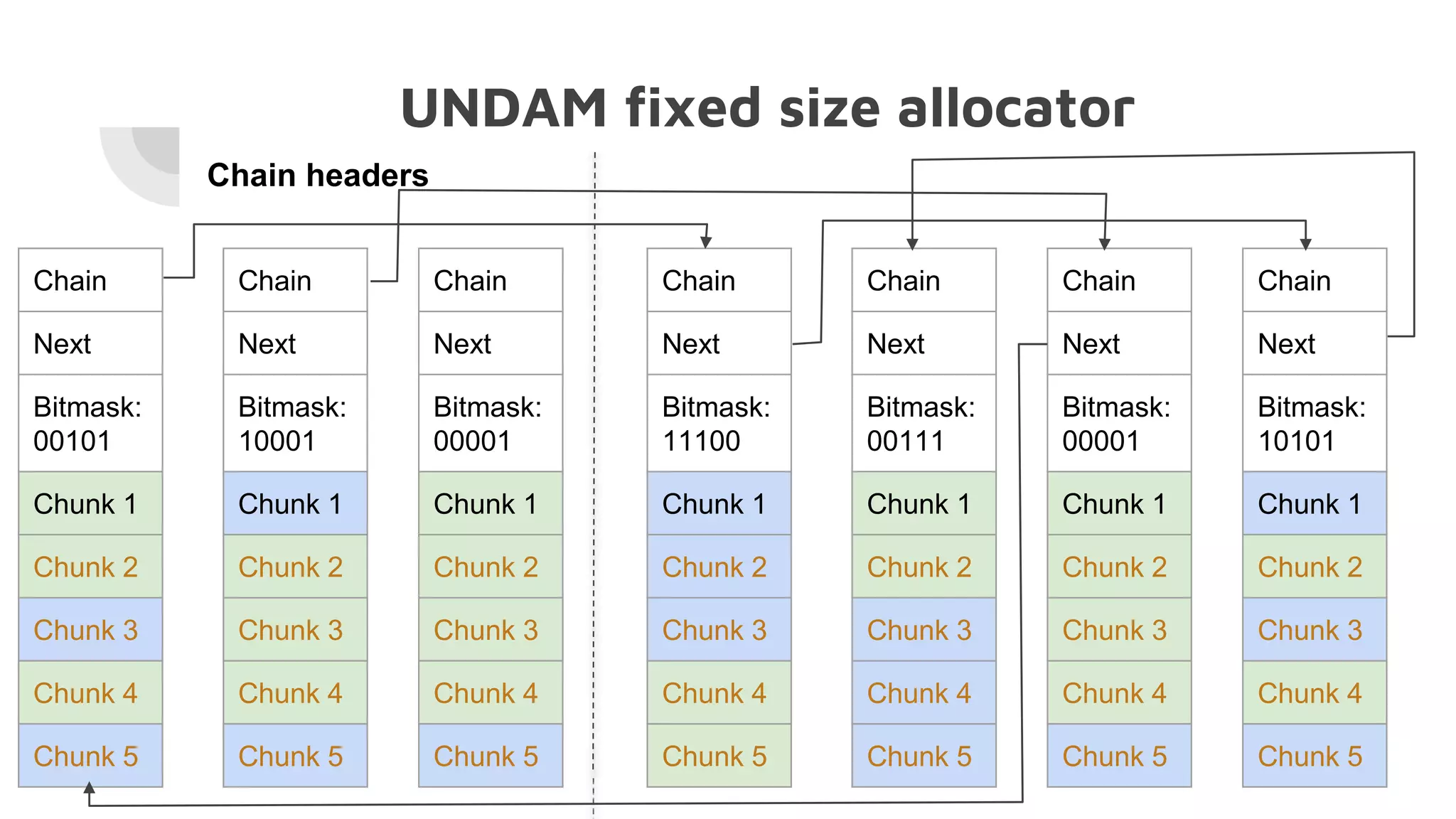




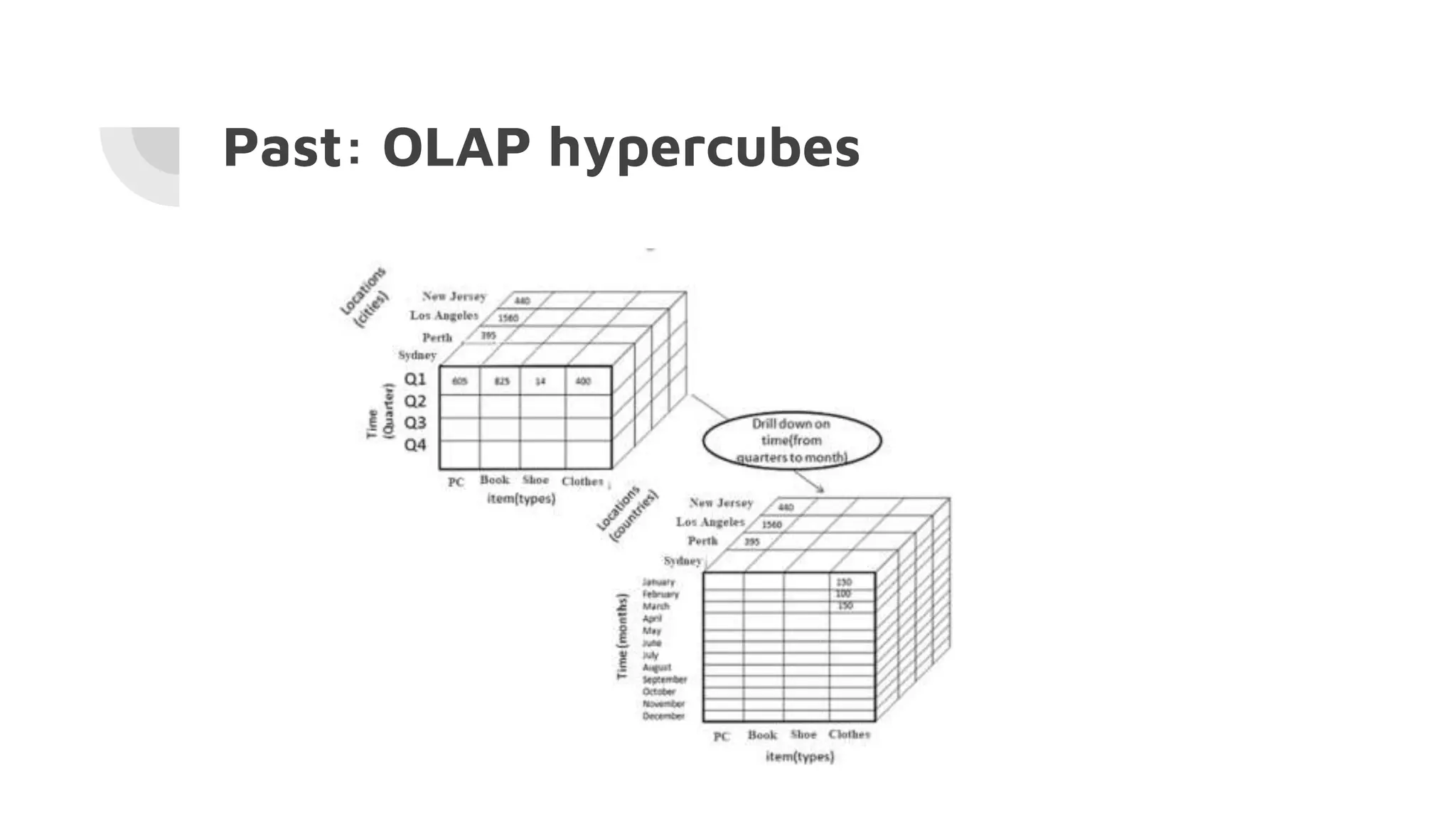
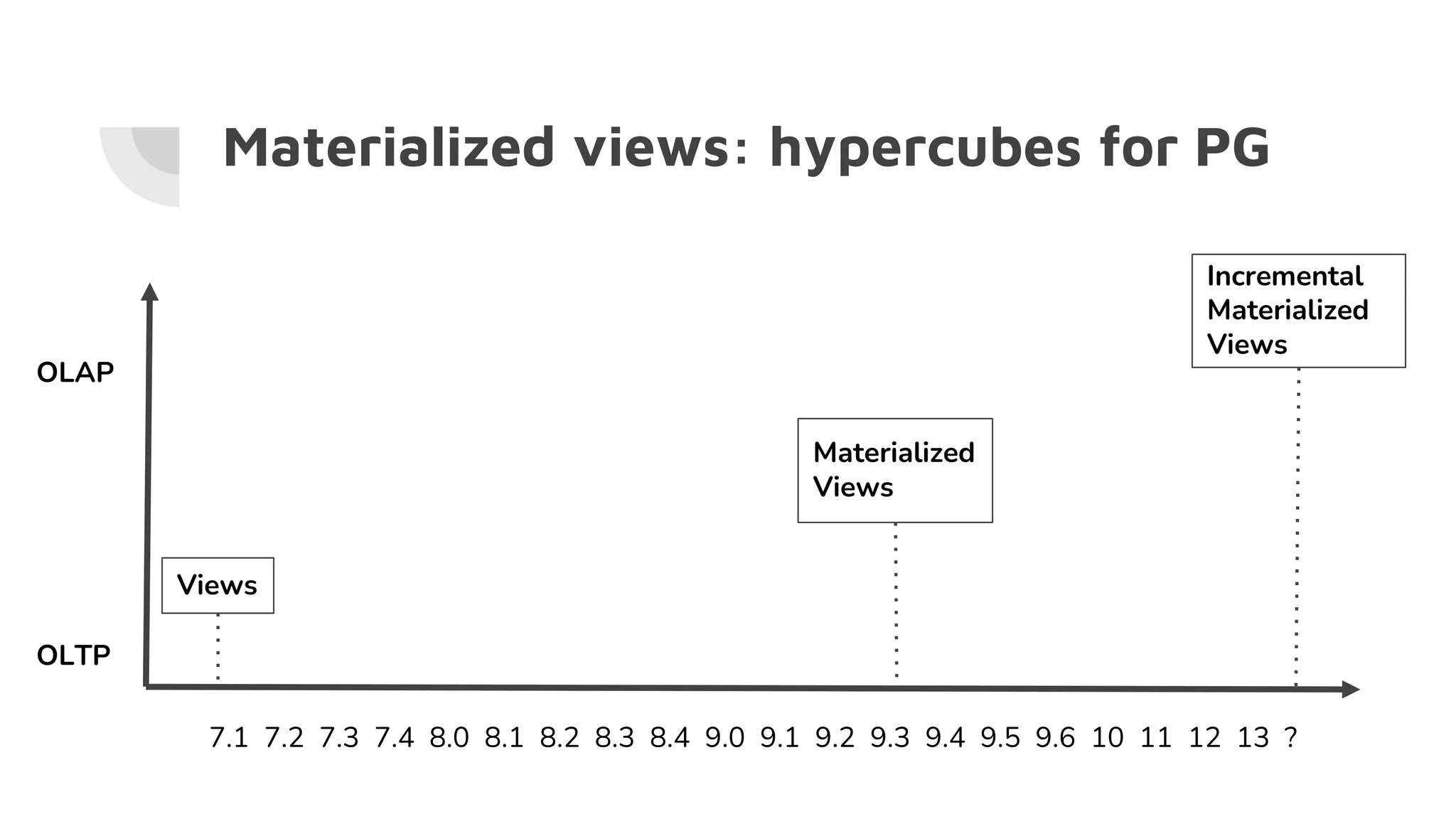

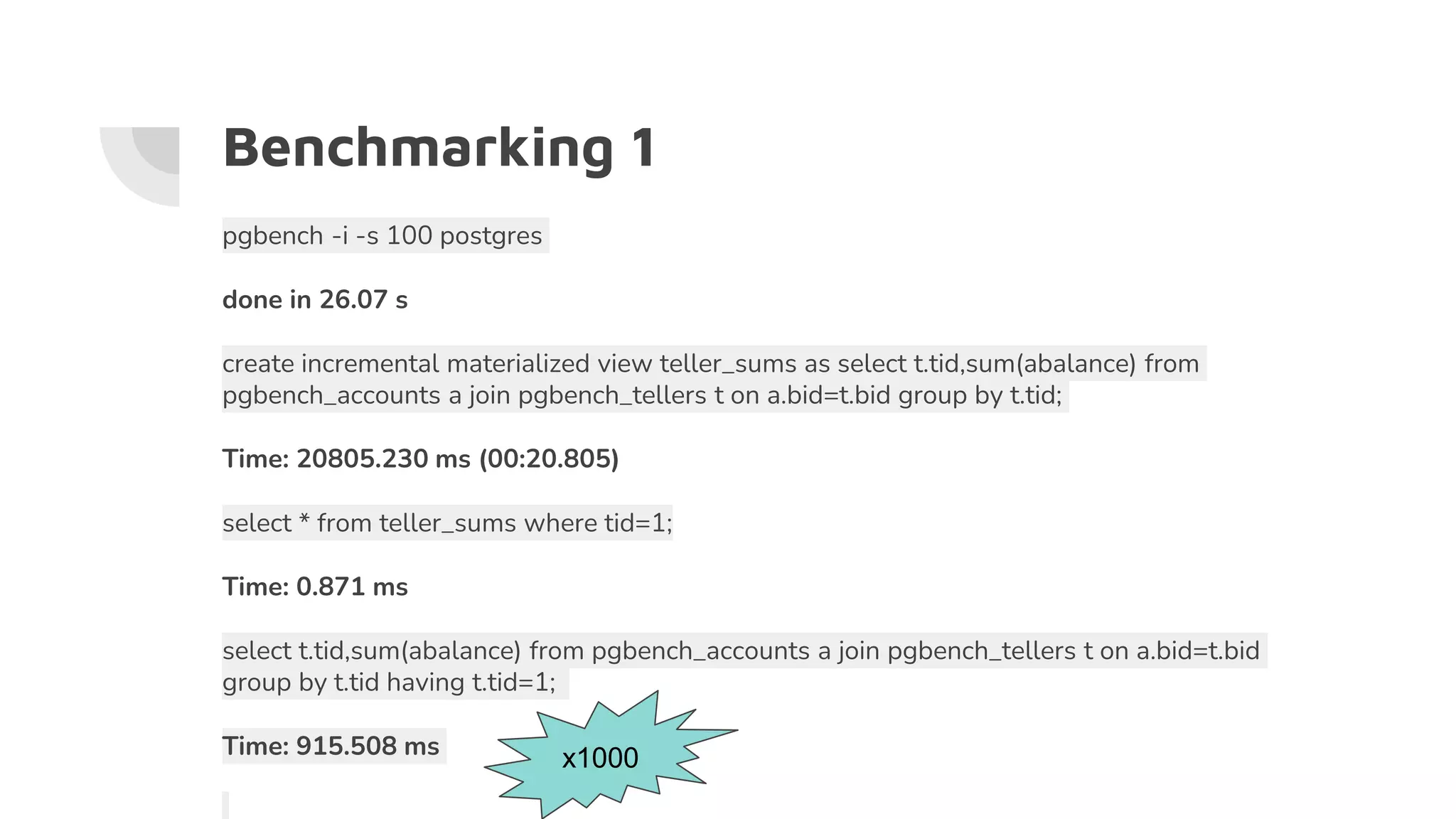

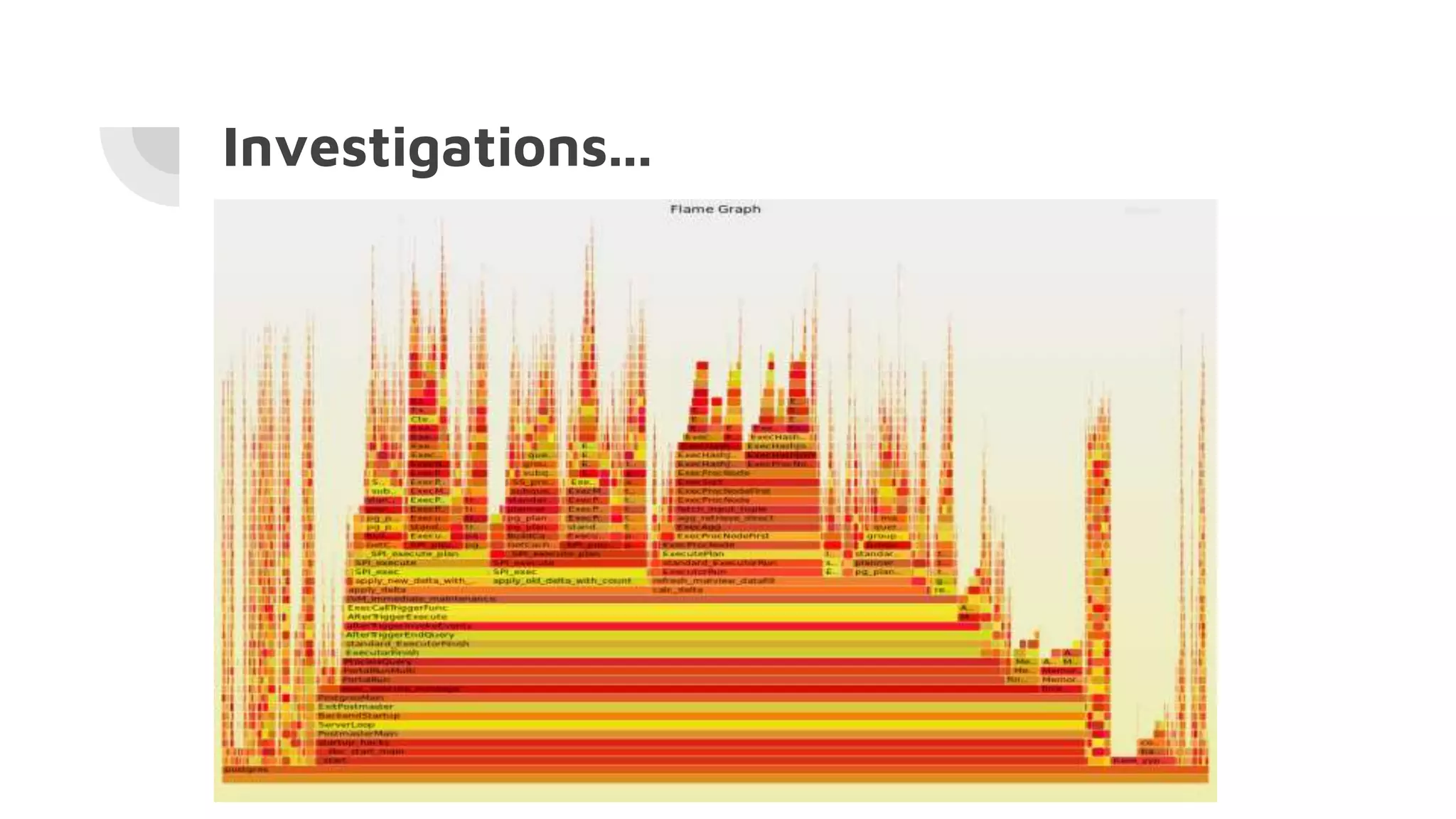







The document discusses the performance challenges of PostgreSQL in OLAP (Online Analytical Processing) and OLTP (Online Transaction Processing) environments, highlighting issues such as overhead from tuple unpacking and interpretation. It compares various database architectures, including vectorized query execution, and provides benchmarks illustrating performance differences across versions and configurations. Additionally, it addresses the effects of indexing and materialized views on performance, concluding that optimizations like just-in-time (JIT) compilation and LSM (Log-Structured Merge) indexing can significantly enhance database efficiency.




































































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)











