Download as PDF, PPTX































This document provides an overview of different database types including relational, NoSQL, document, key-value, graph, and column family databases. It discusses the history and drivers behind the development of NoSQL databases, as well as concepts like horizontal scaling, the CAP theorem, and eventual consistency. Specific databases are also summarized, including MongoDB, Redis, Neo4j, and HBase.
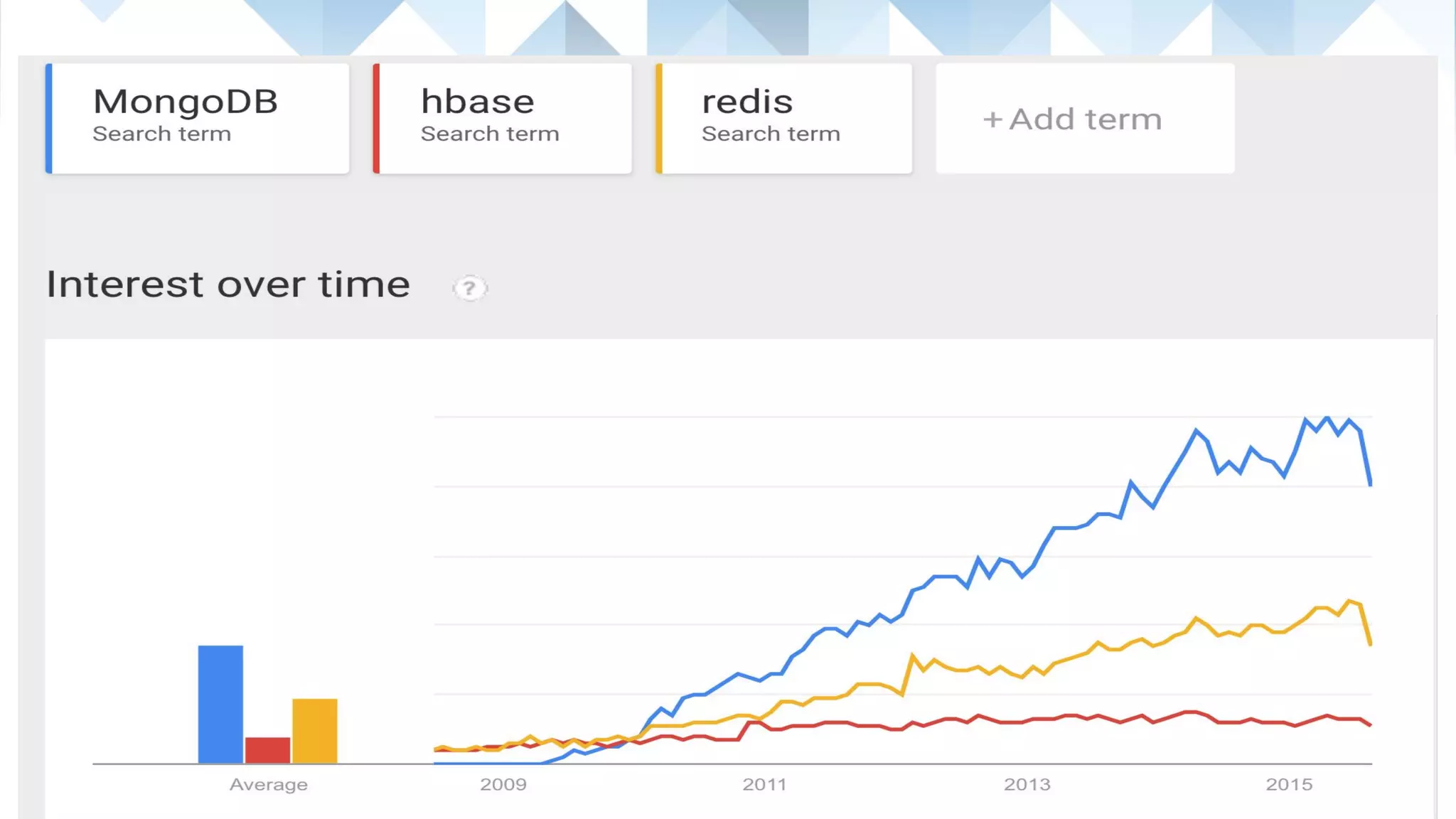
Overview of topics including history, types of databases, scaling methods, and CAP theorem.
Emergence of Non-SQL databases for big data applications, focusing on challenges of horizontal scaling.
Characteristics of relational databases like MySQL and Oracle, highlighting ease of use but complexity.
Relational databases face issues with defined schemas, data volume, and scalability.
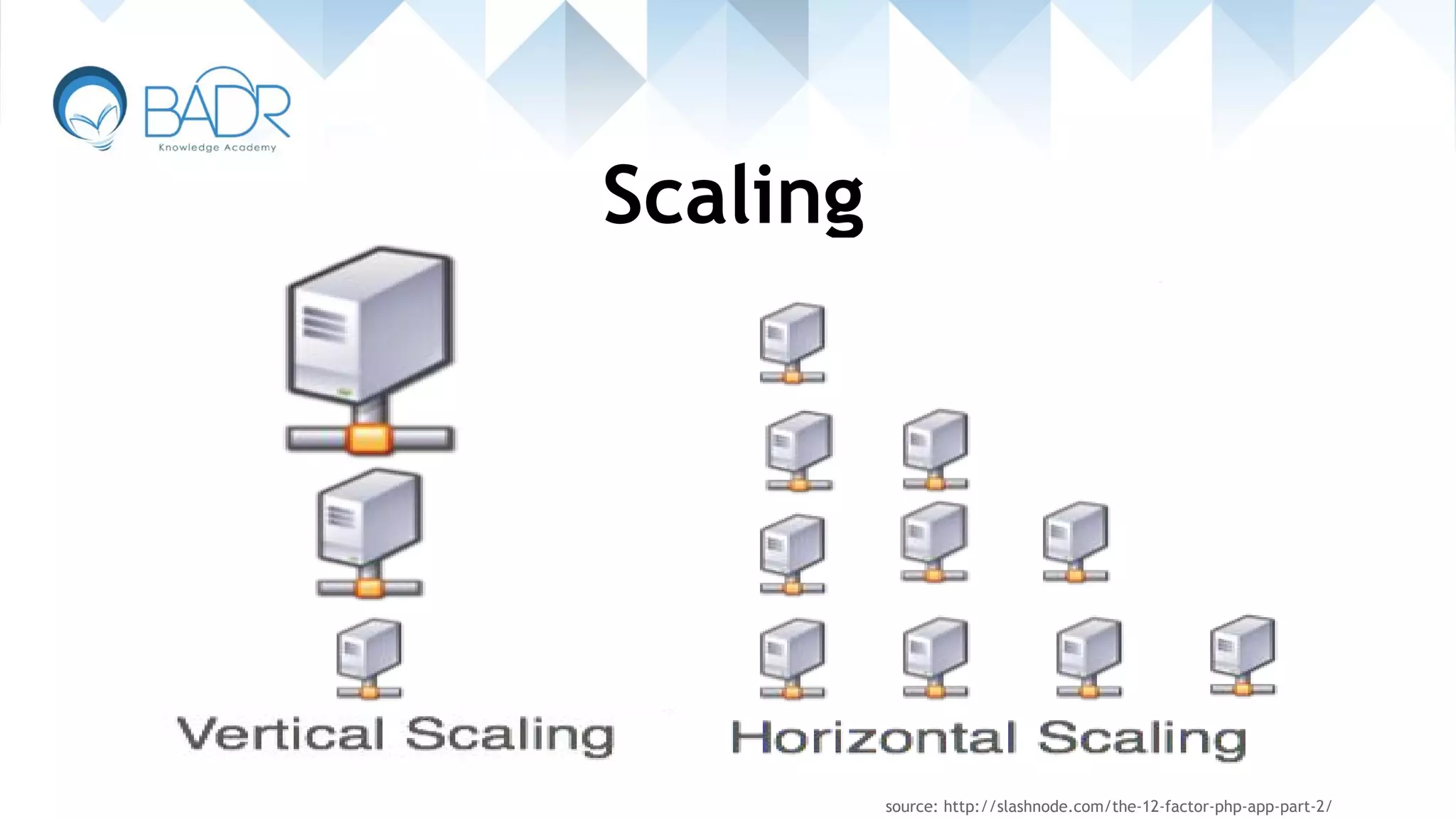
Visual representations discussing scaling techniques for databases.
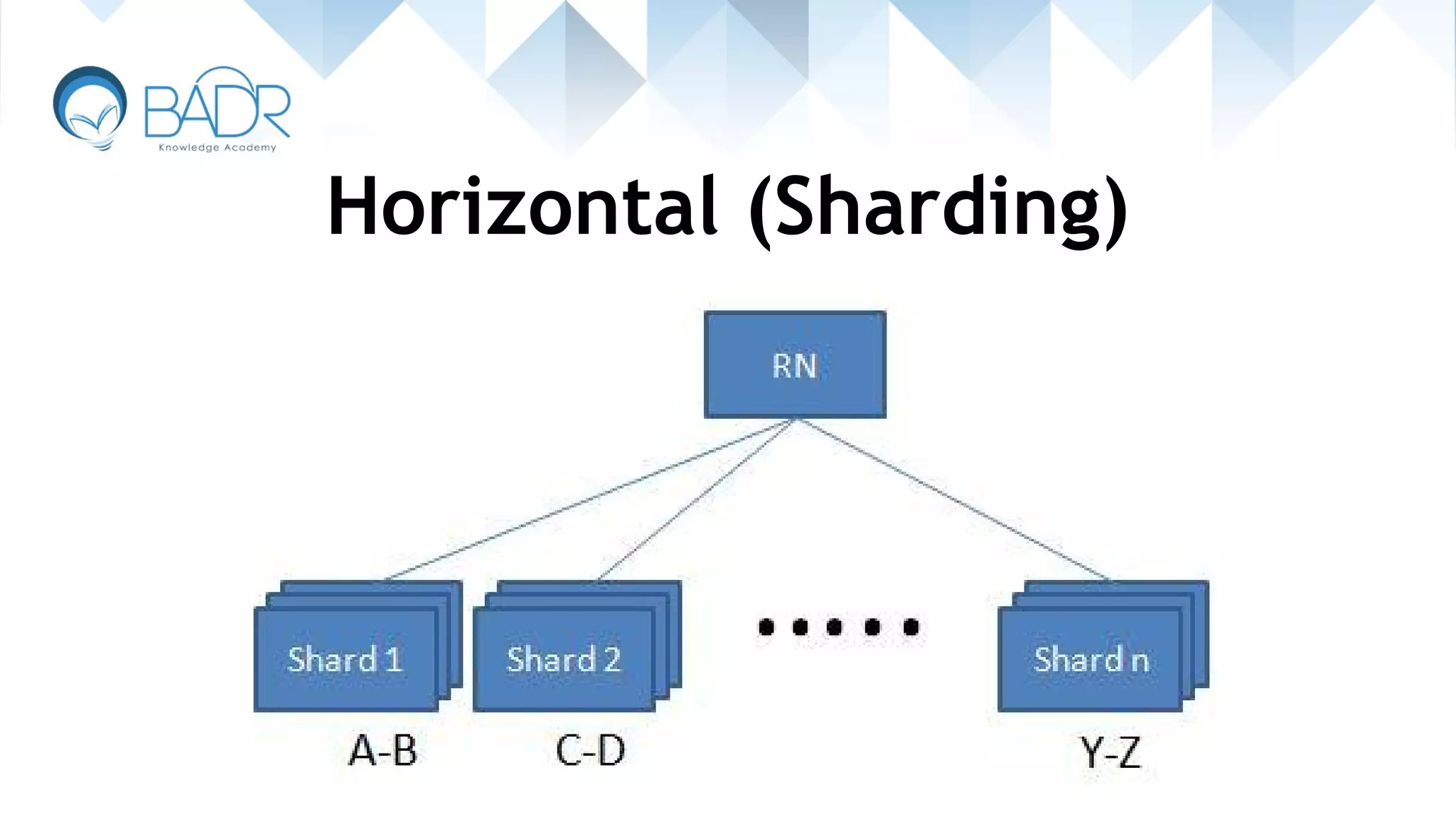
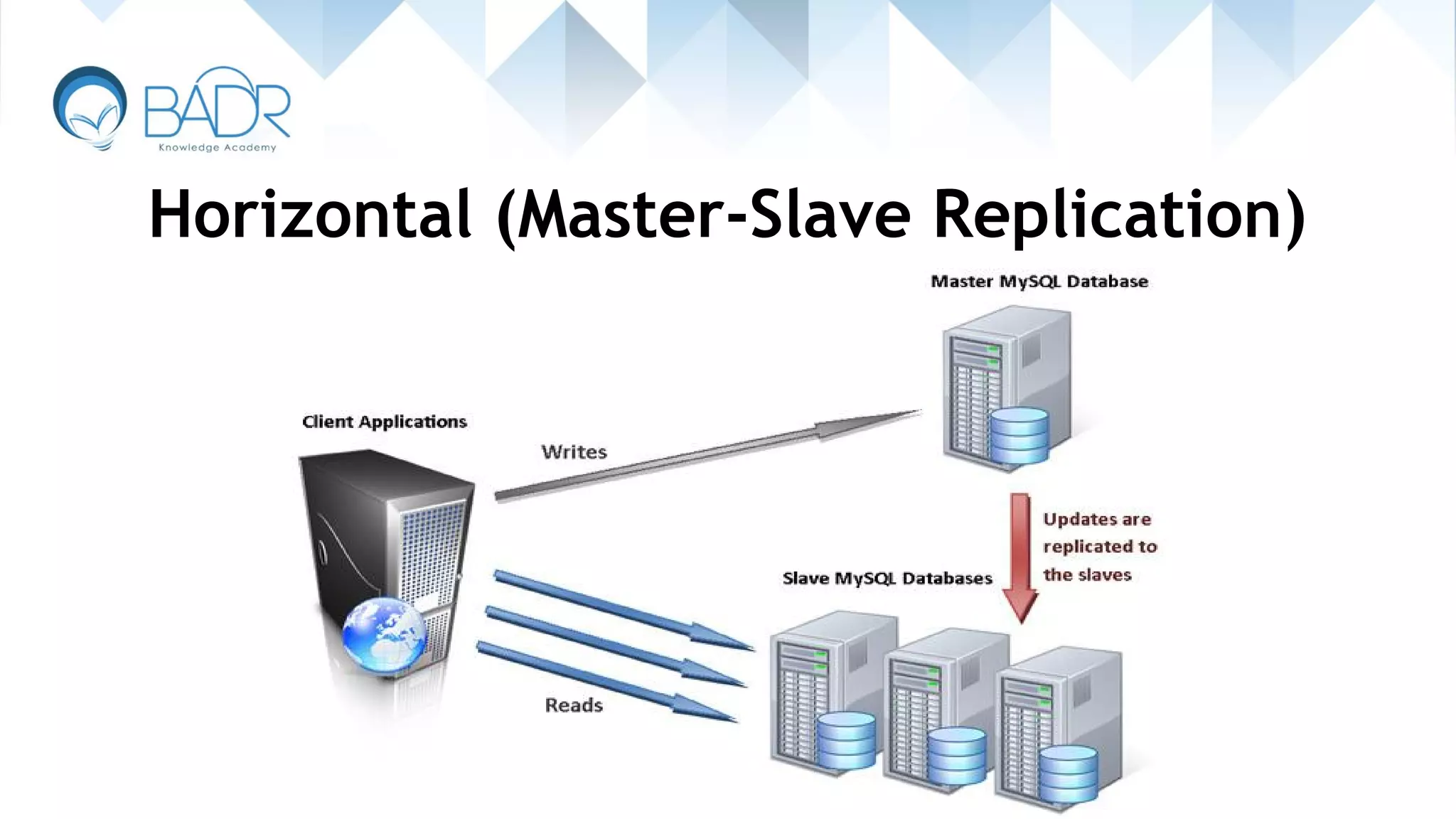
Explanation of horizontal scaling methods like sharding and master-slave replication.
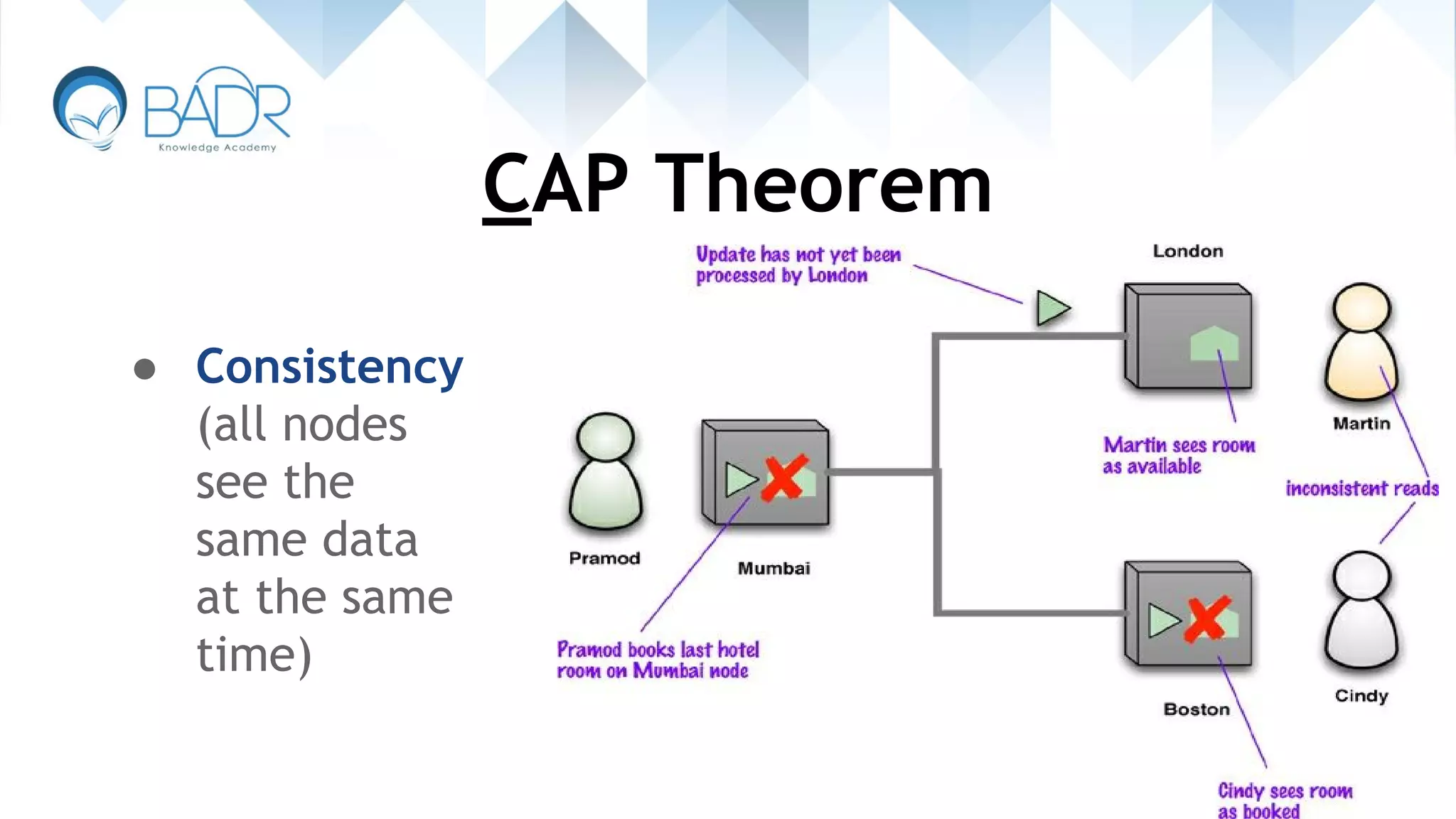
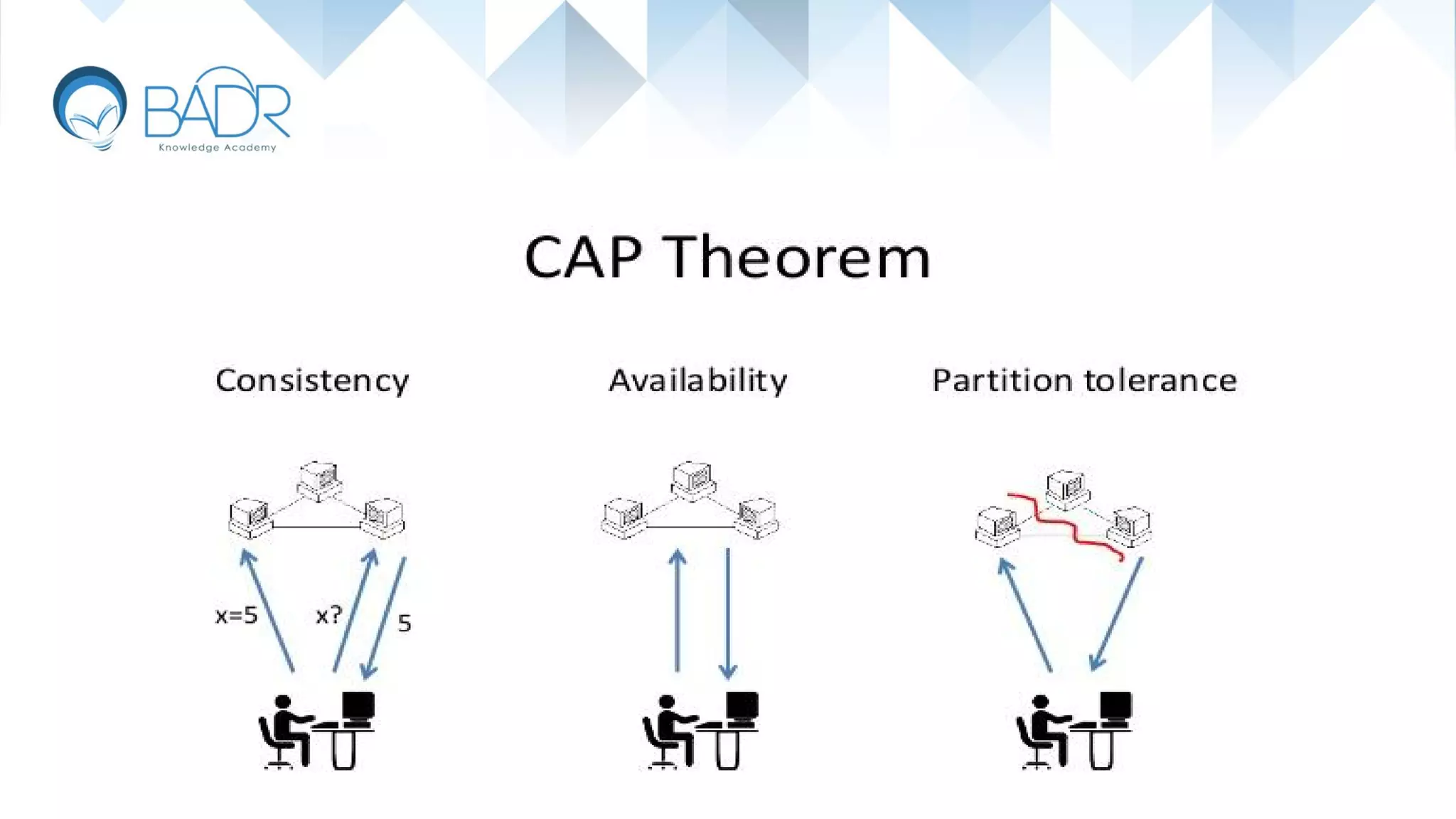
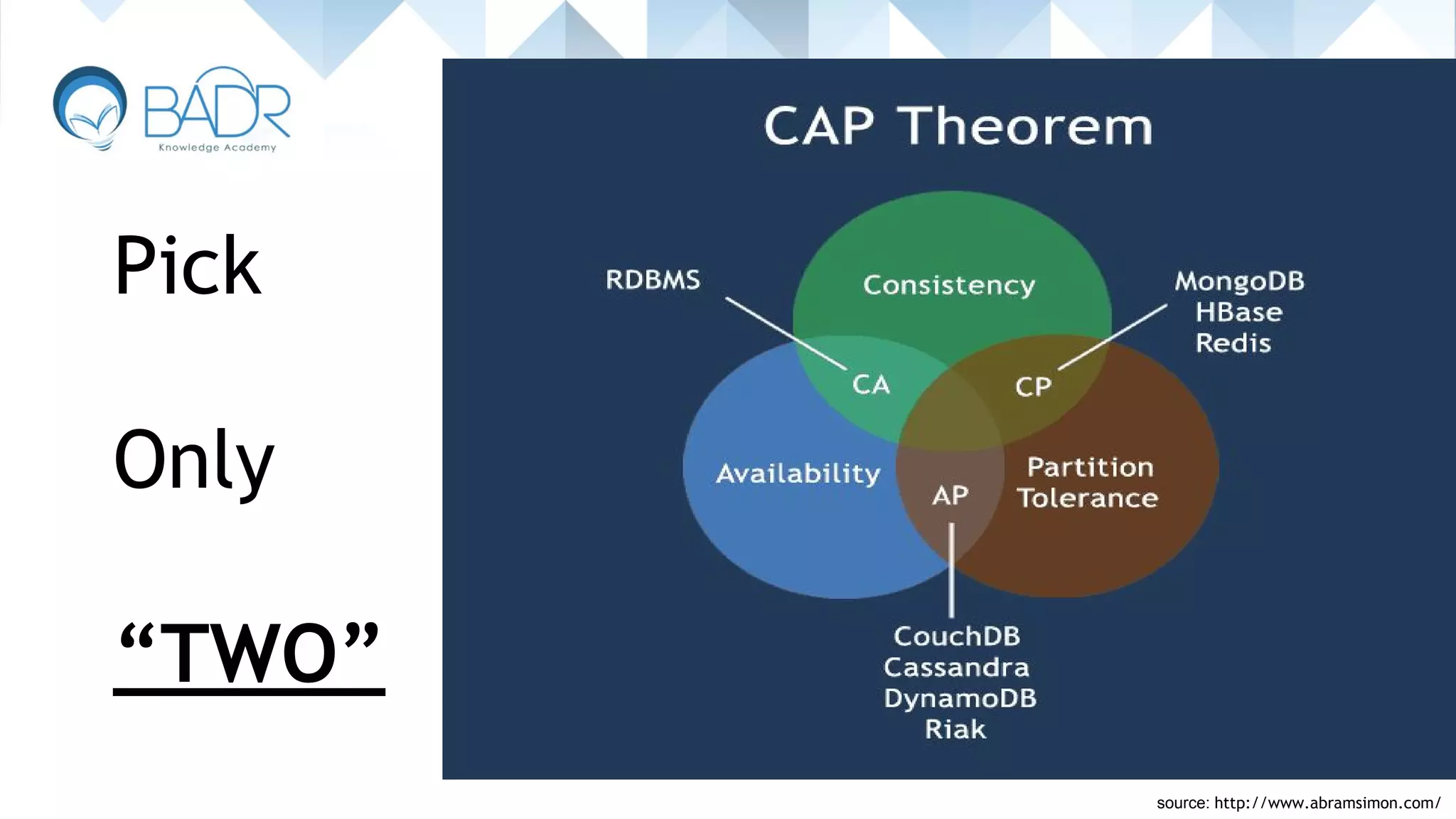
Details on CAP theorem's principles: Consistency, Availability, and Partition tolerance.
Explains the challenges of fully satisfying the CAP theorem and the need to choose two characteristics.
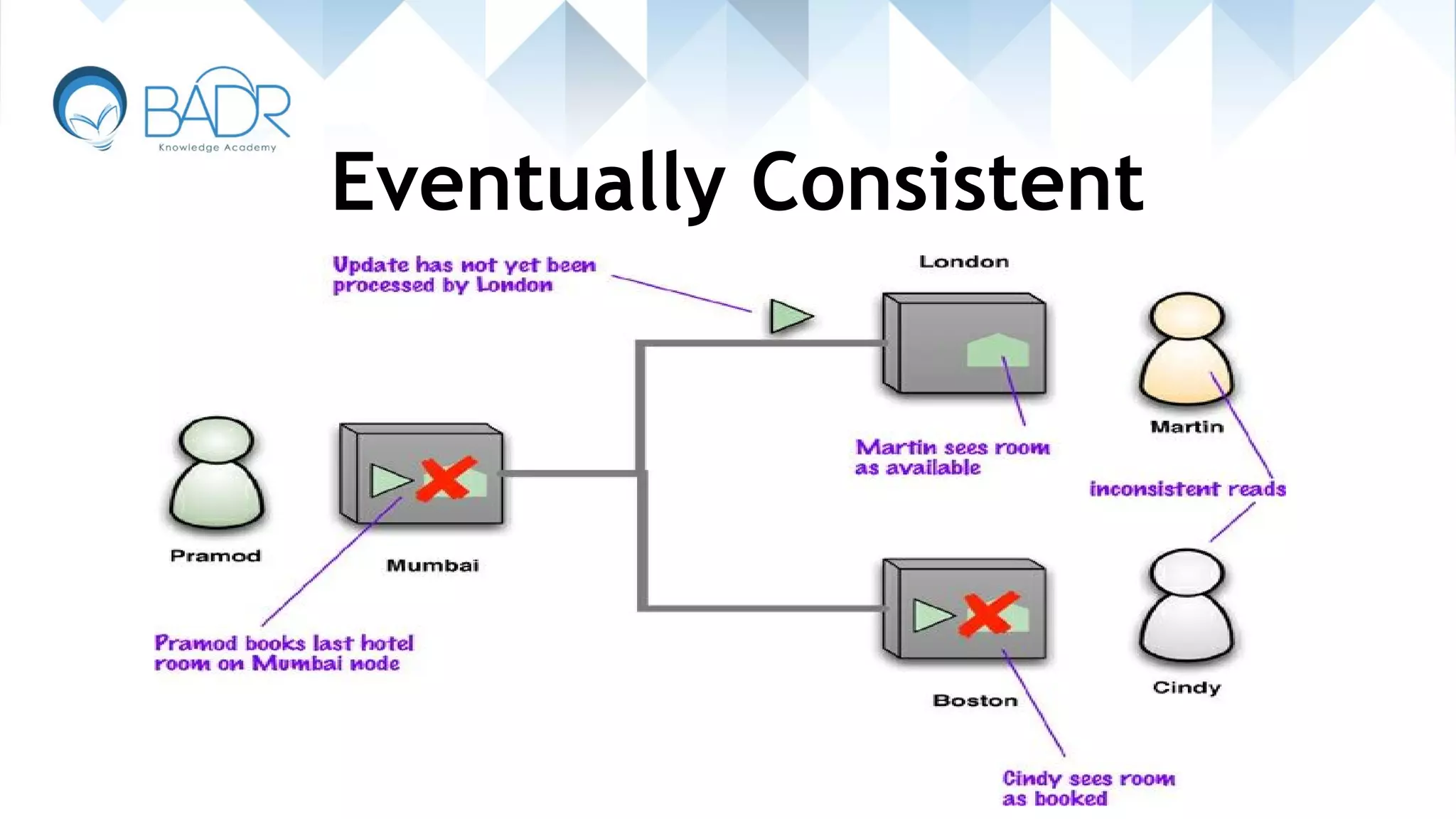
Concept of eventual consistency used in distributed systems and databases.
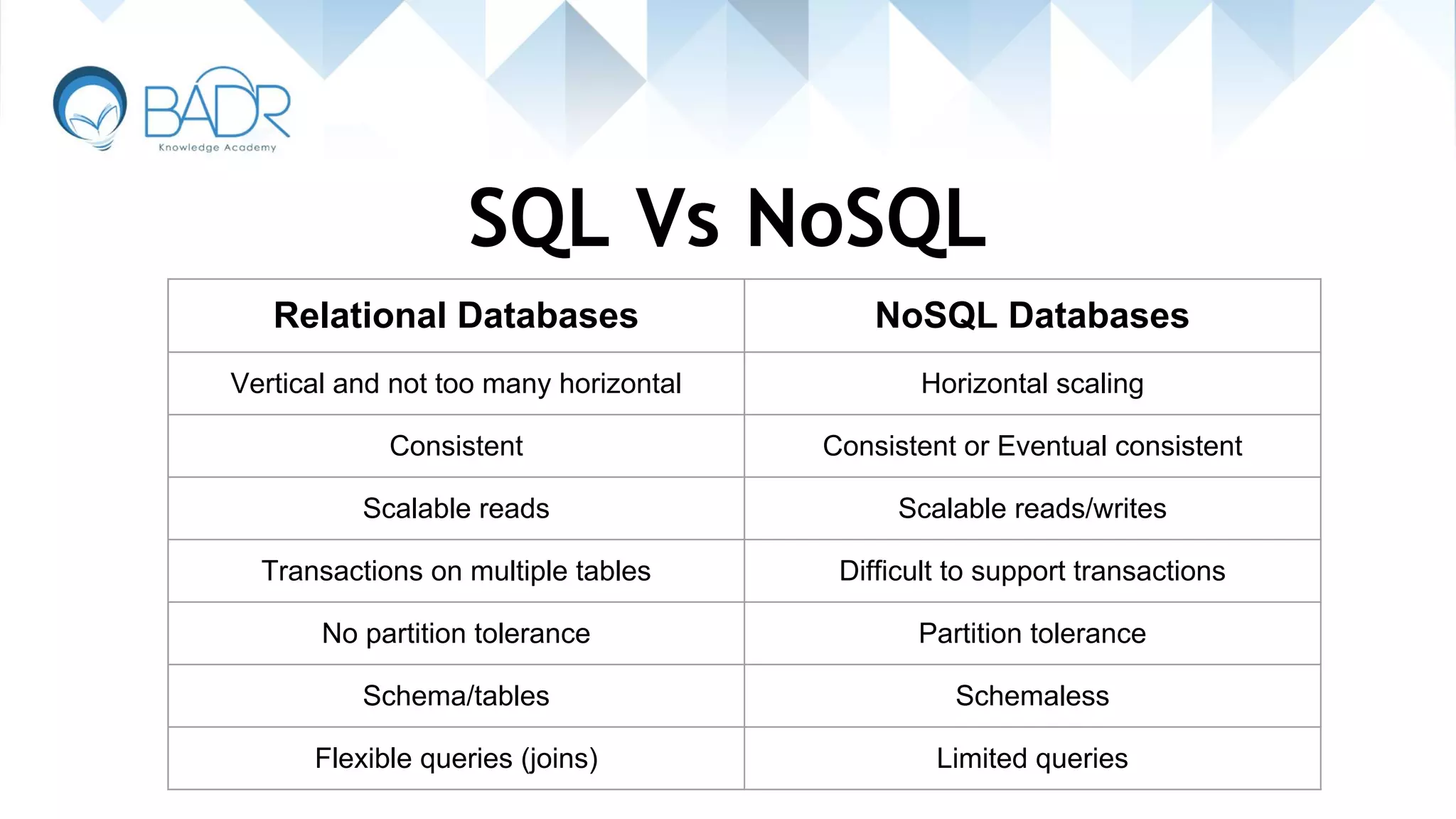
Contrast between relational and NoSQL databases including scalability and data consistency.
Introduction to document databases like MongoDB, which align closely with relational concepts.
Detailed comparison between JSON documents and relational rows, emphasizing schemaless nature.
Features of MongoDB including consistency, scalability, and embedded documents.
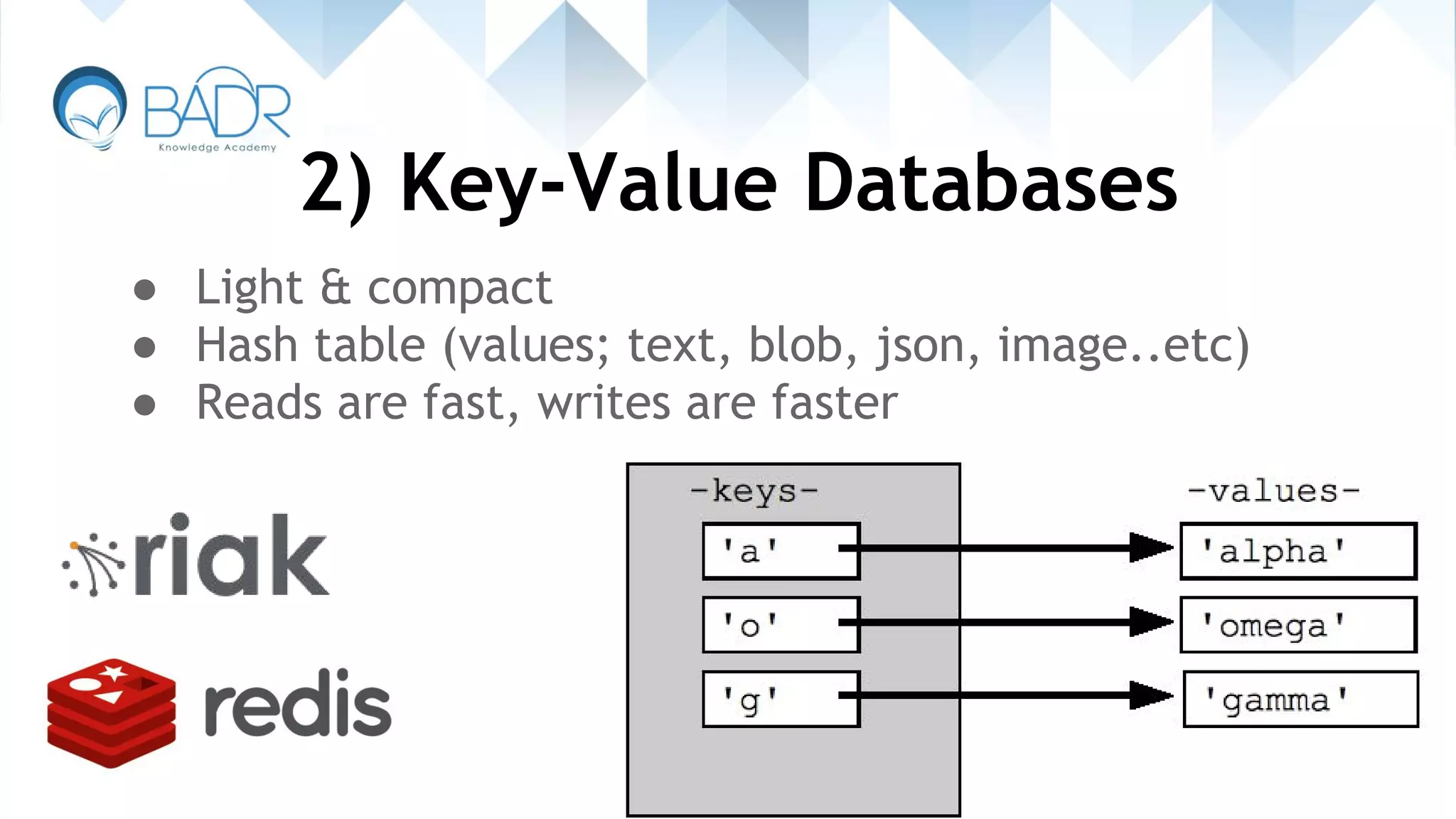
Introduction to key-value databases like Redis, focusing on performance and data types.
Explanation of complex data types in Redis including list types, sets, and caching functionalities.
Persistence methods and replication strategies of Redis, highlighting its eventual consistency.
Key features of Redis highlighting its speed, flexibility, and use in caching and messaging.
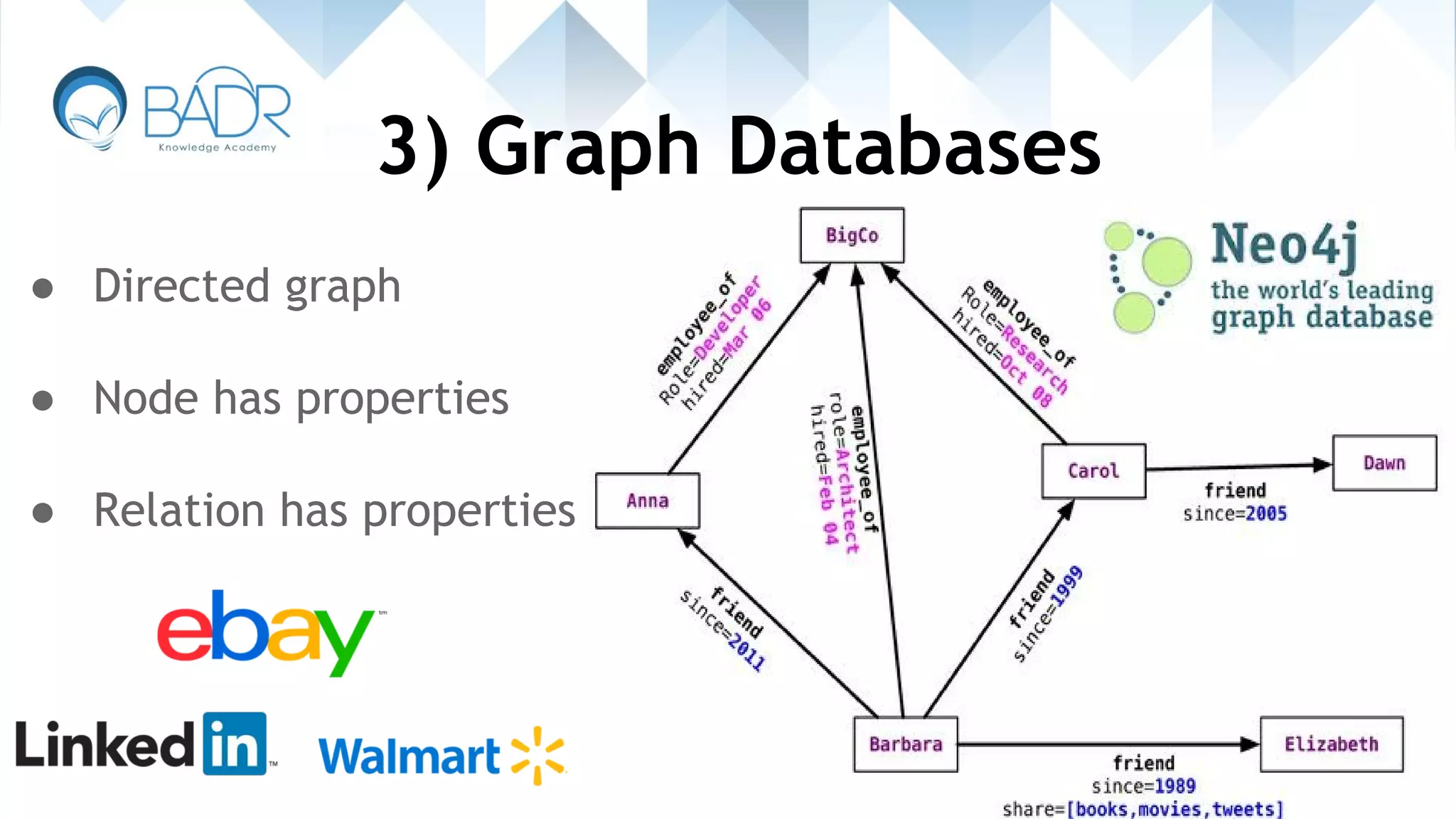
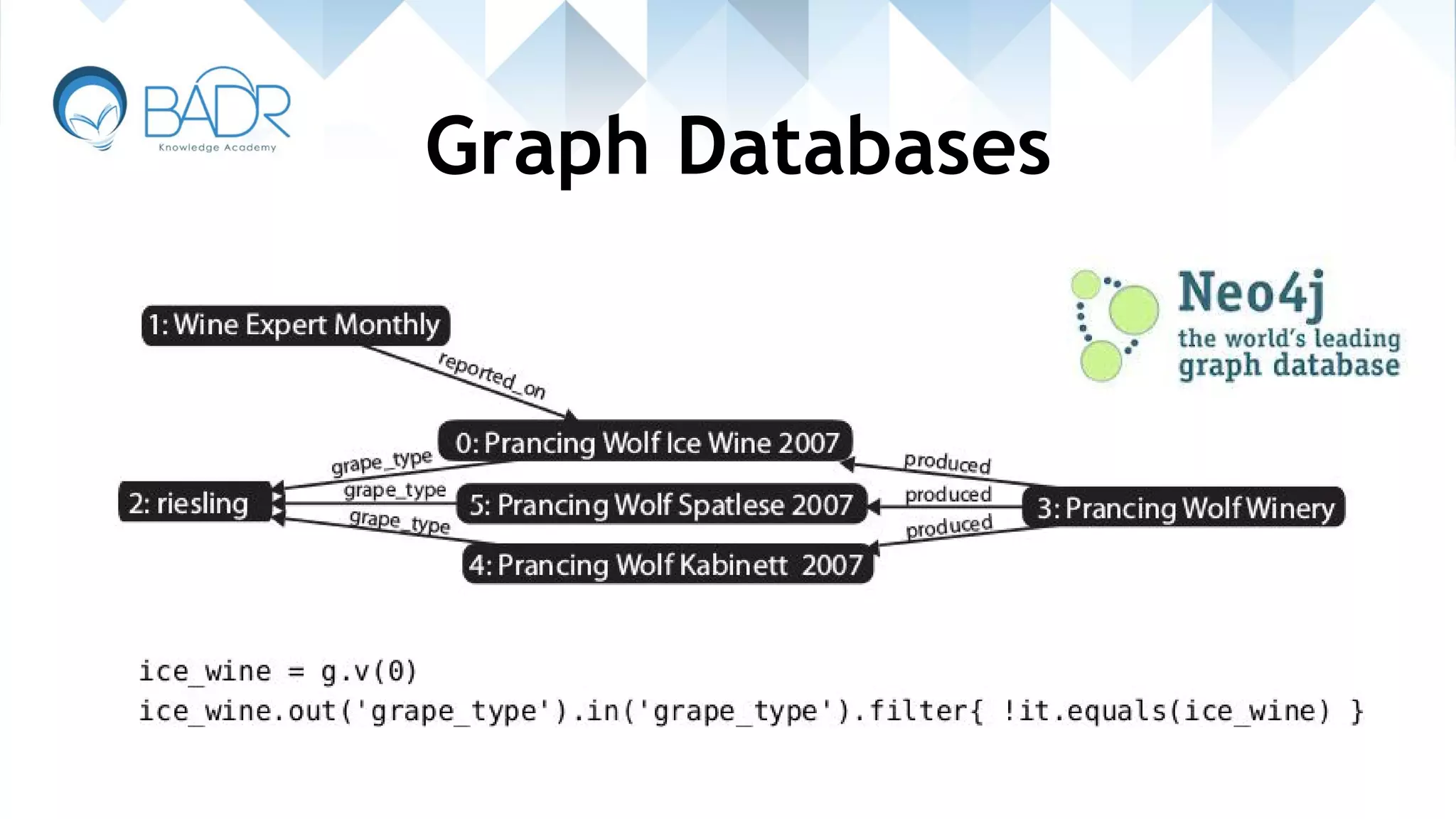
Introduction to graph databases and their property-oriented structure, focusing on relationships.
Details on graph databases emphasizing high availability and replication strategies.
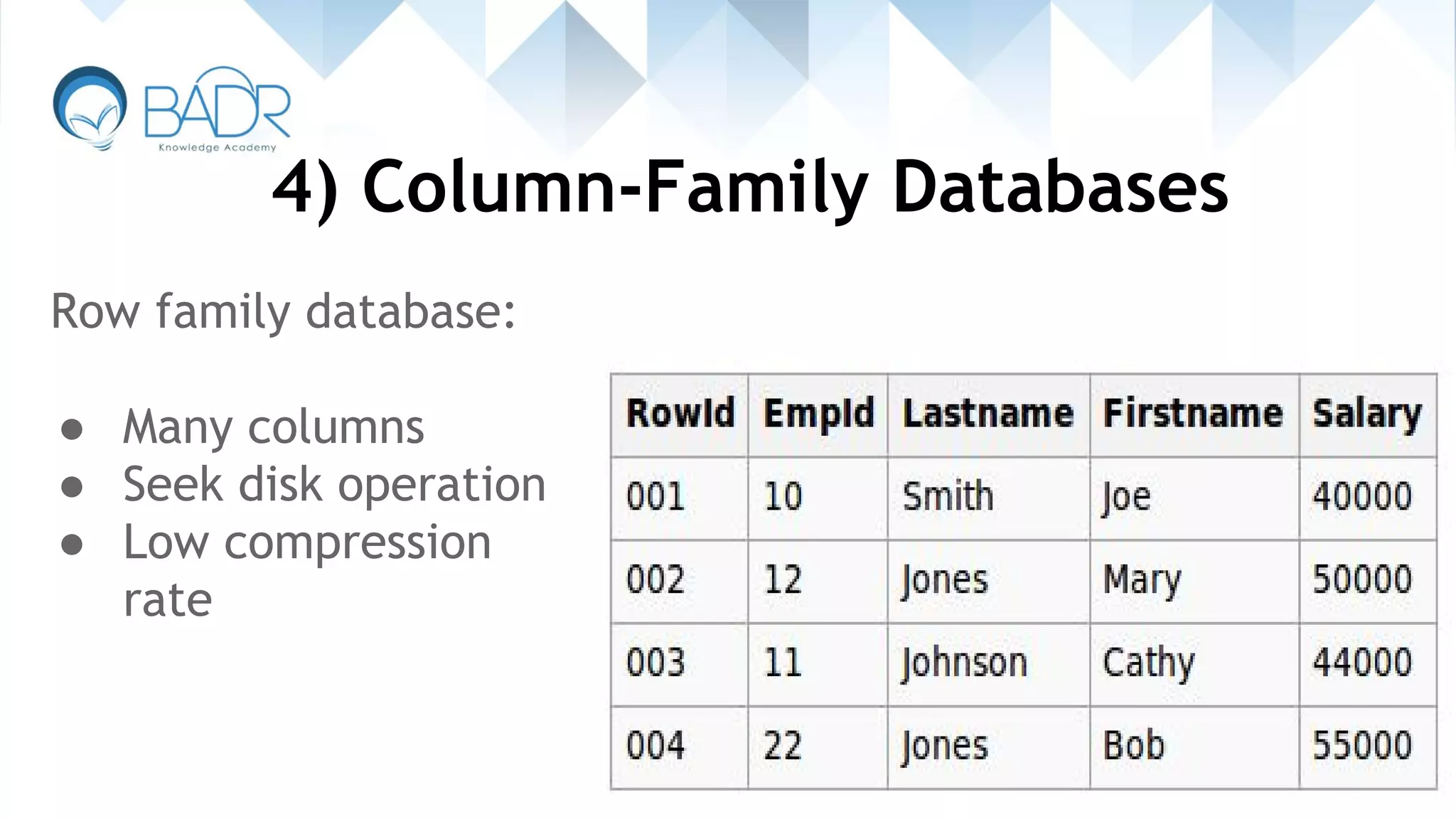
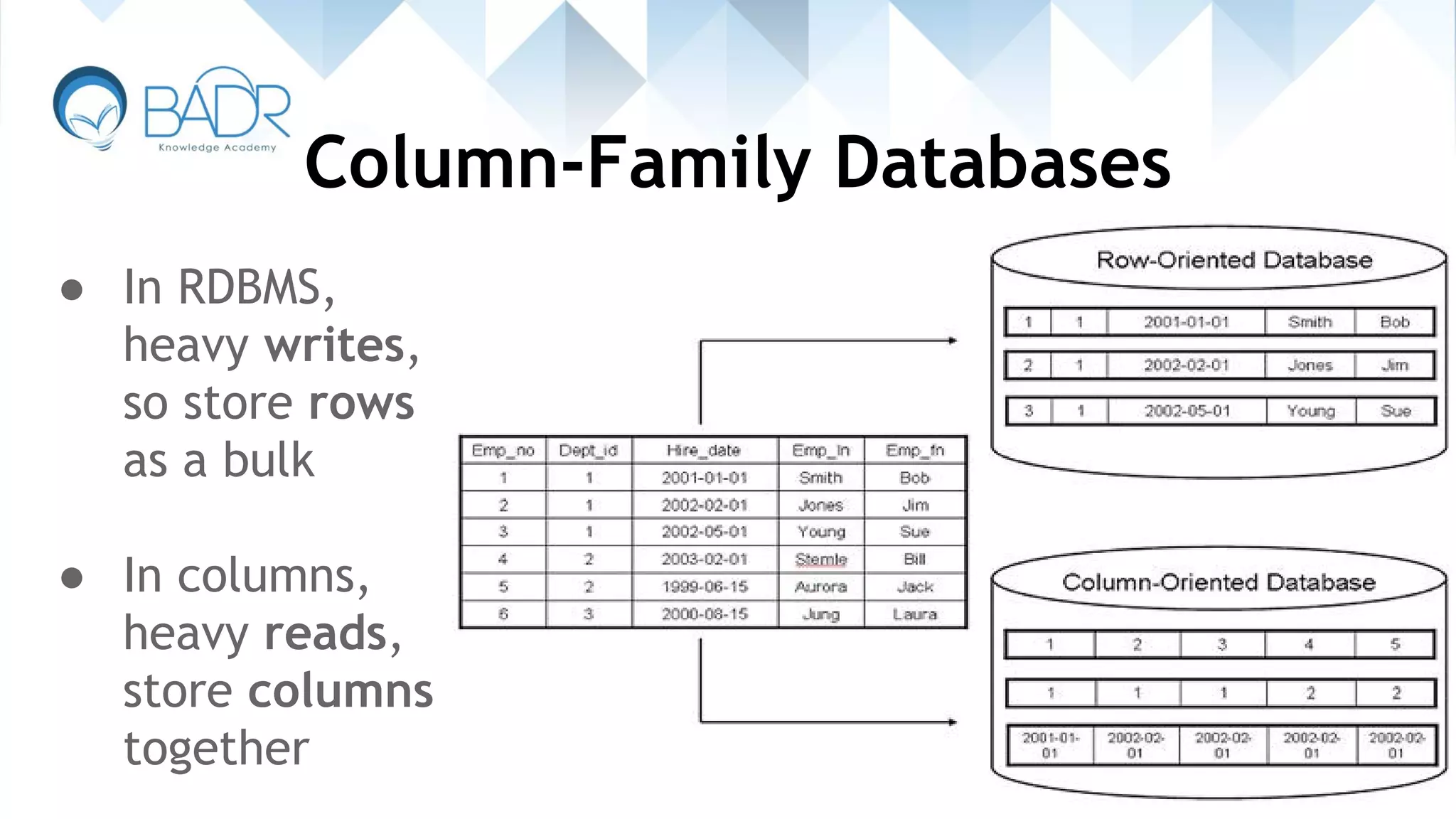
Characteristics of column-family databases, their design for heavy read/write operations.
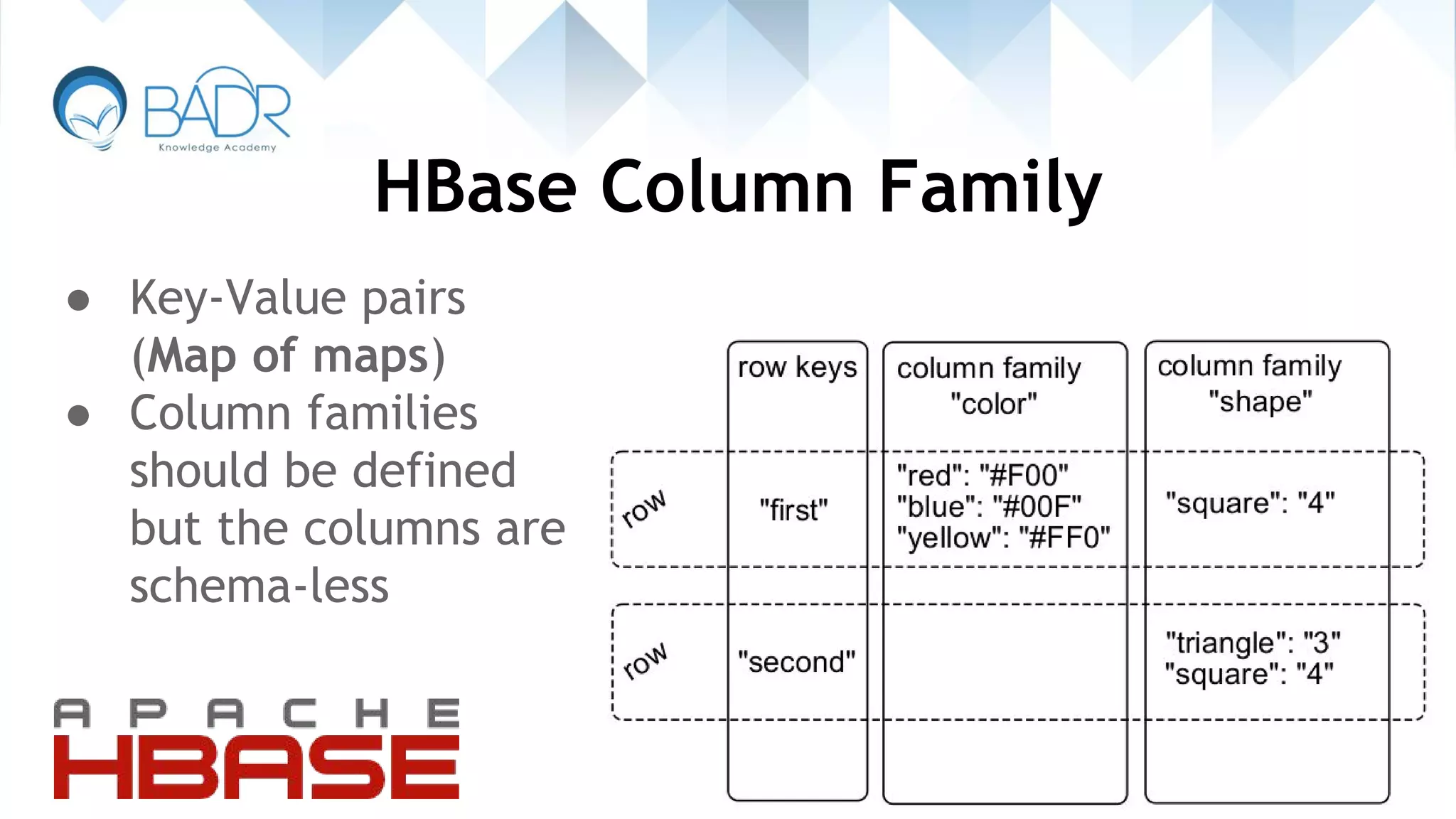
Overview of HBase, its use with Hadoop, and features like versioning and key-value storage.
Comparison between HBase and Cassandra, highlighting their operational features and usage.
Advice on selecting appropriate database technologies based on project requirements.


















































































