



![1
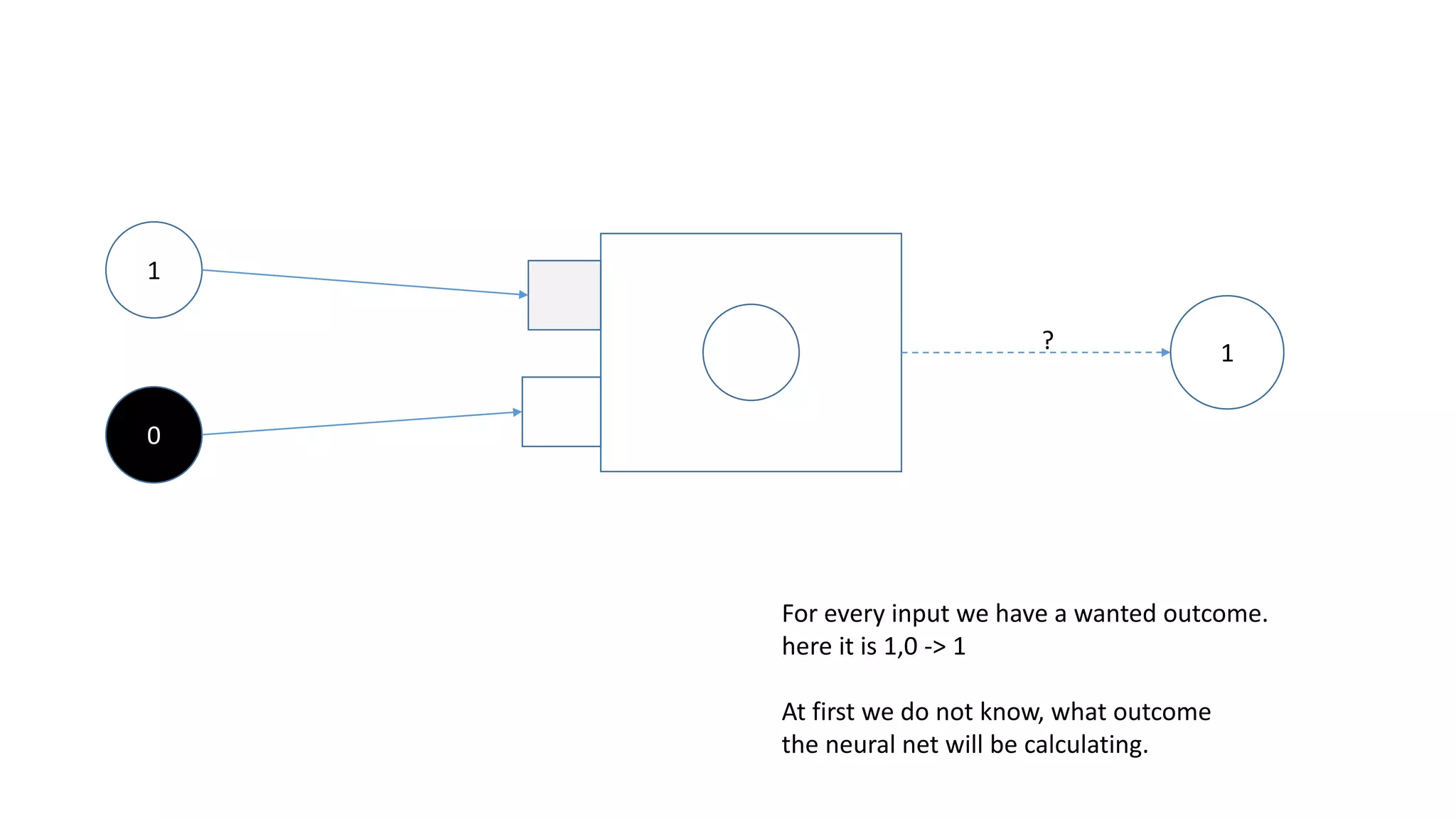
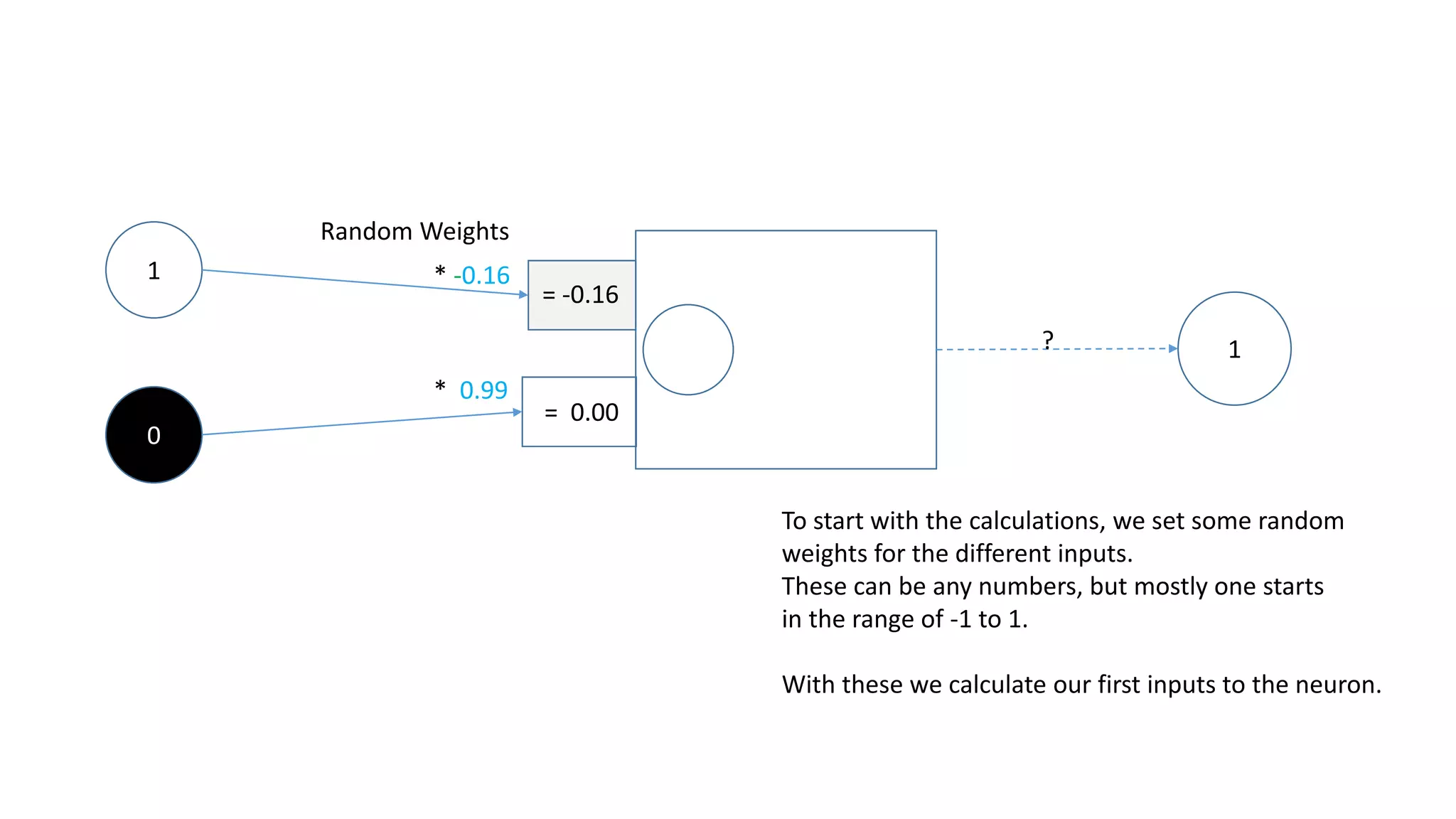
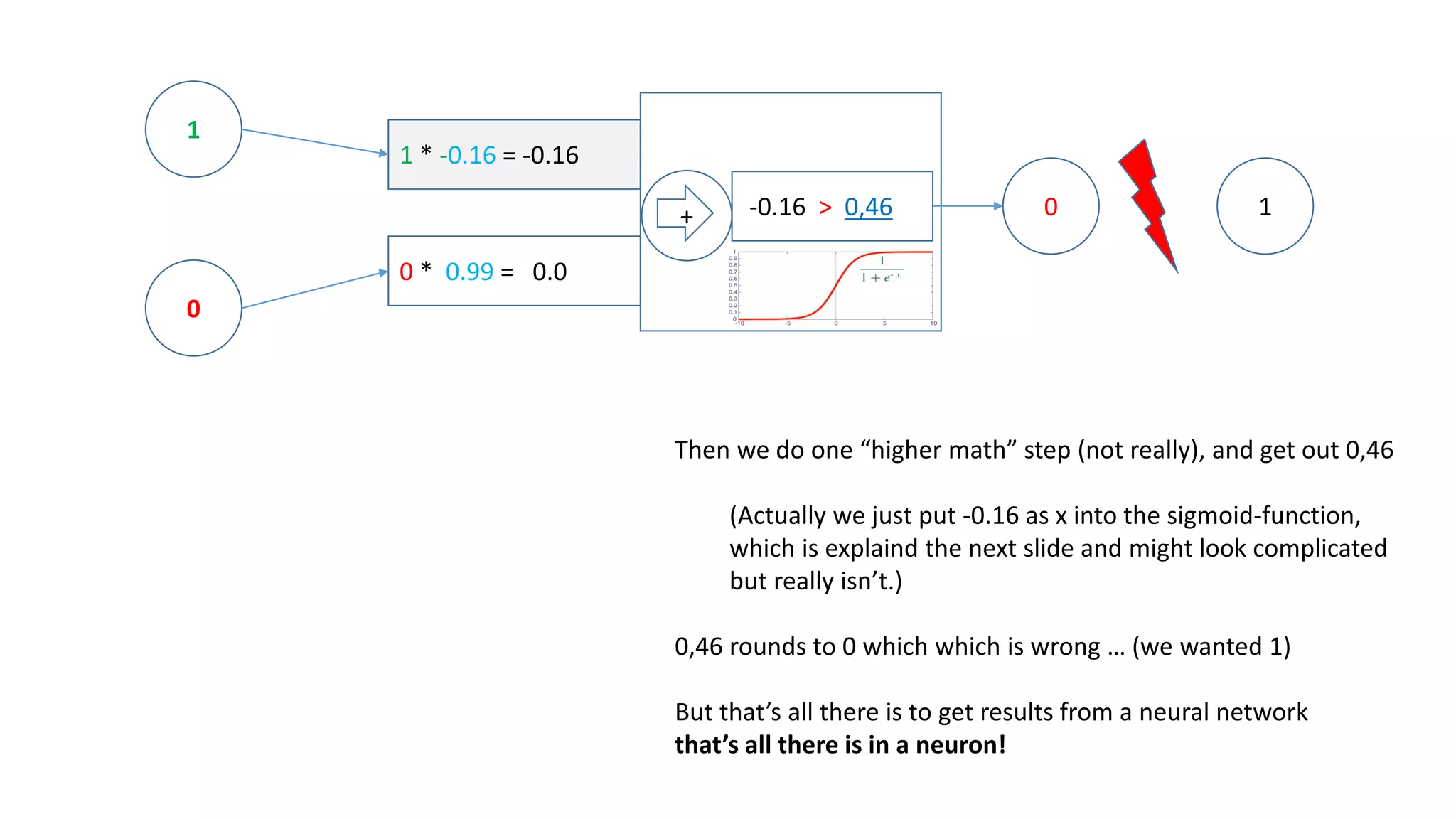
1
0
1
0
1
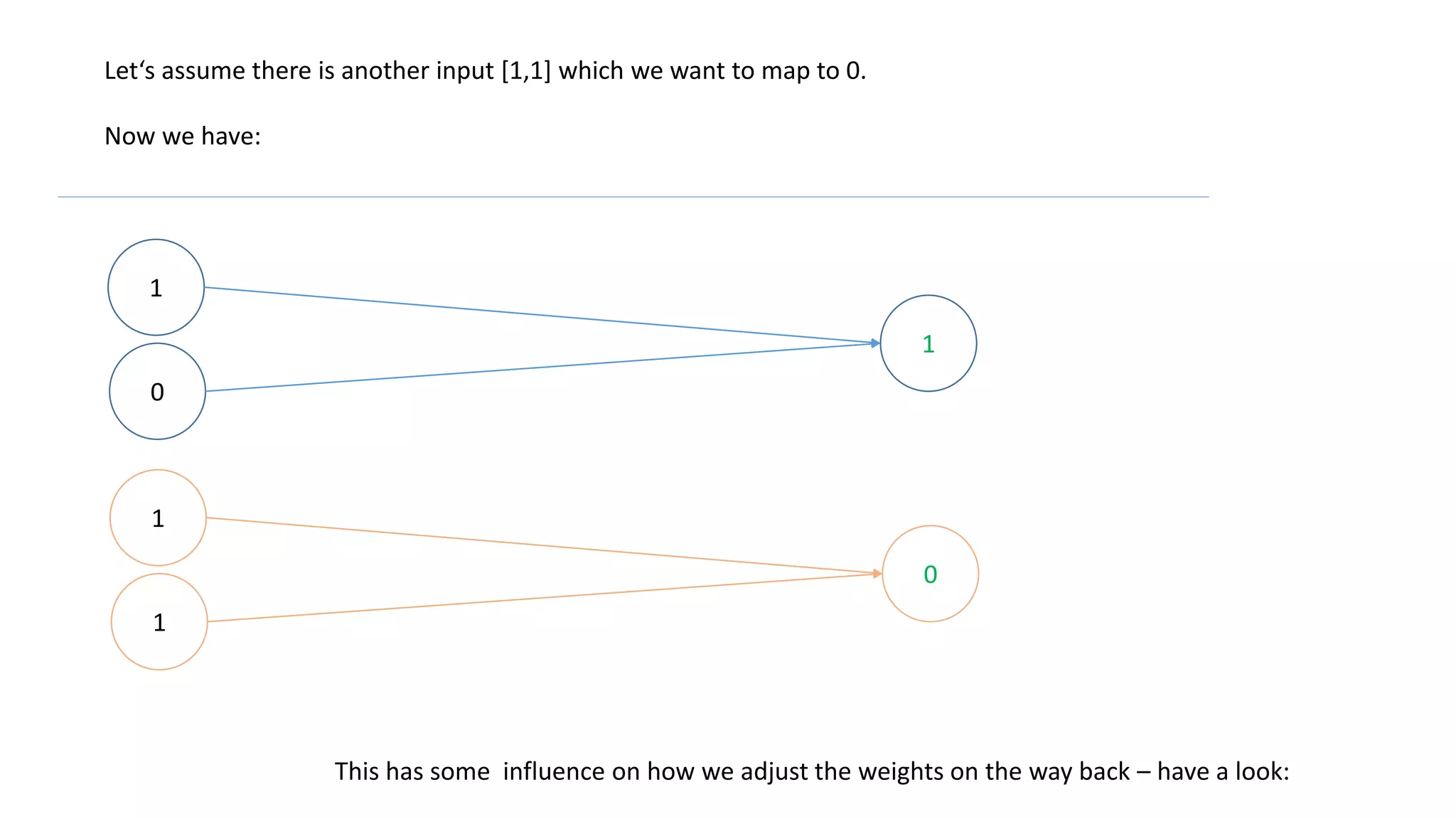
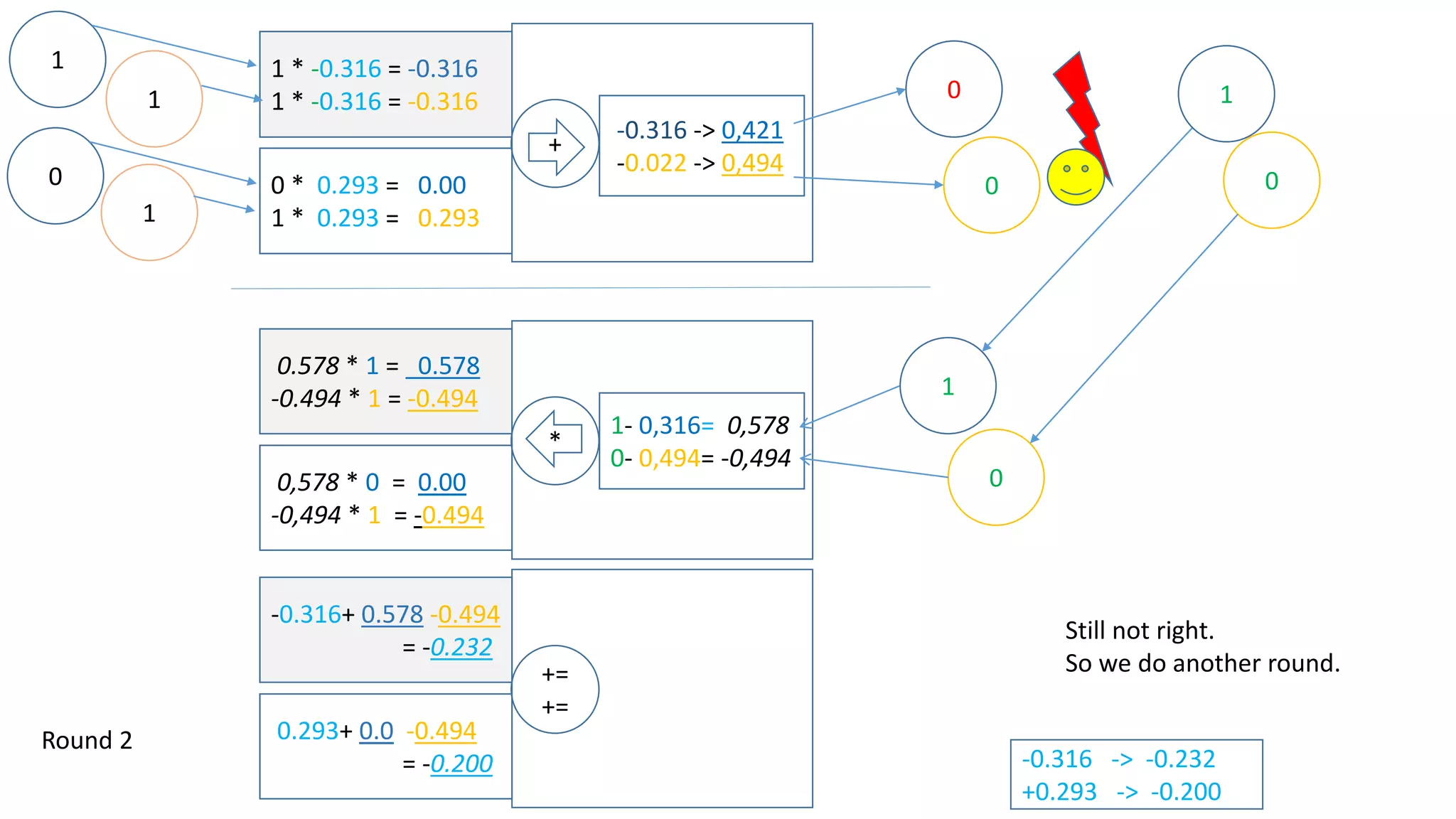
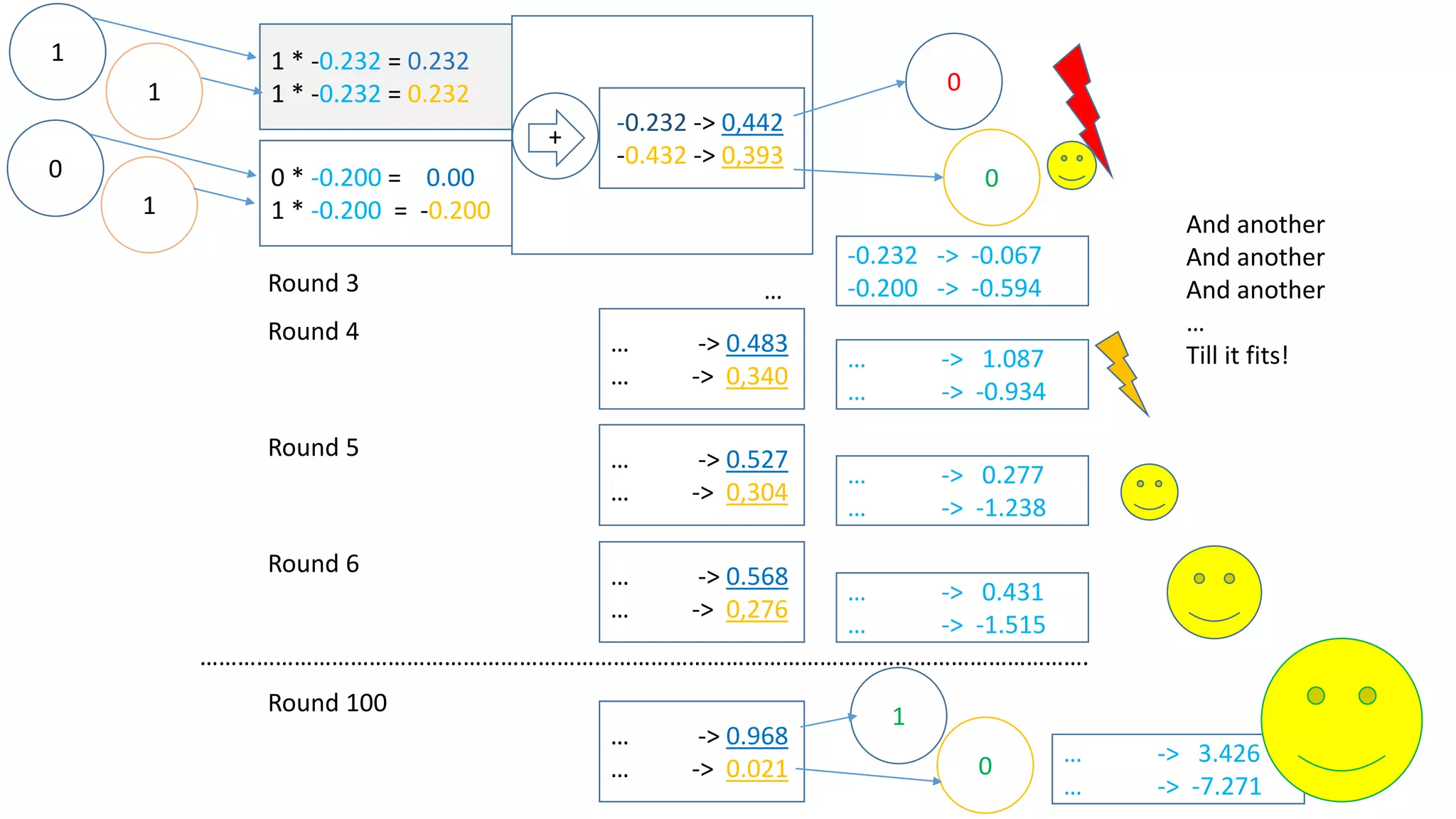
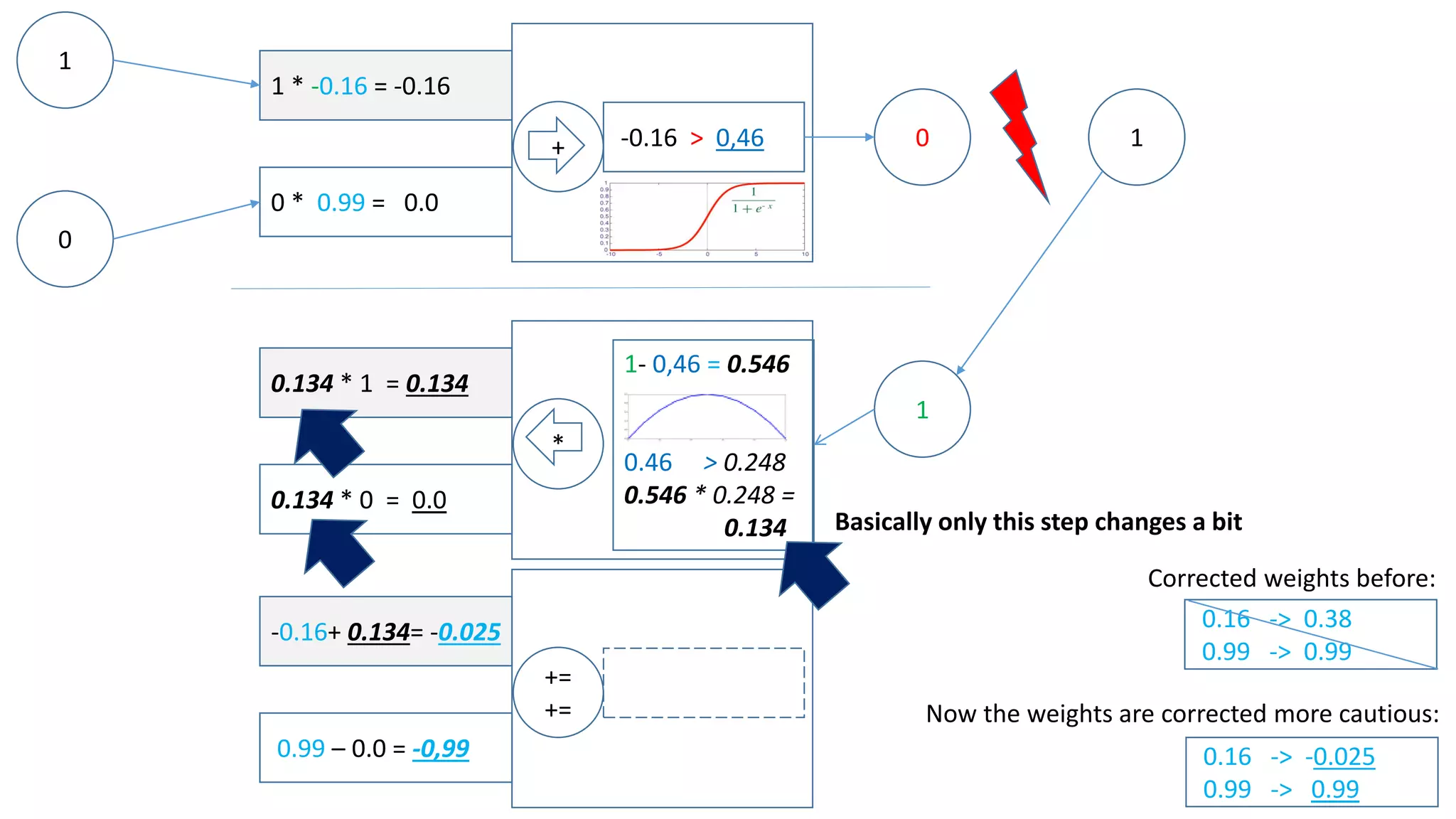
Let‘s assume there is another input [1,1] which we want to map to 0.
Now we have:
This has some influence on how we adjust the weights on the way back – have a look:](https://image.slidesharecdn.com/neuralnetwork-160326102101/75/Neural-network-how-does-it-work-I-mean-literally-14-2048.jpg)
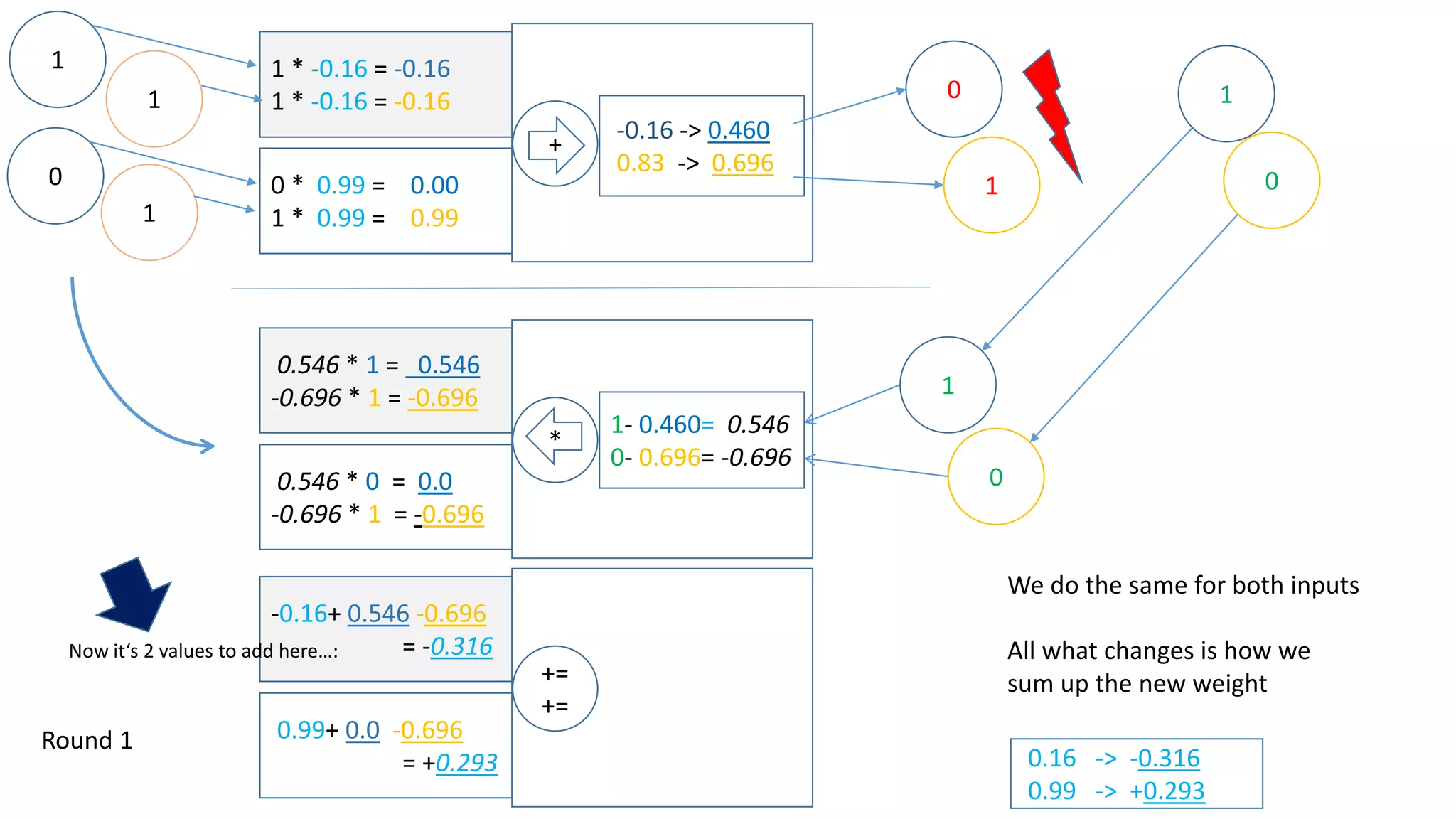
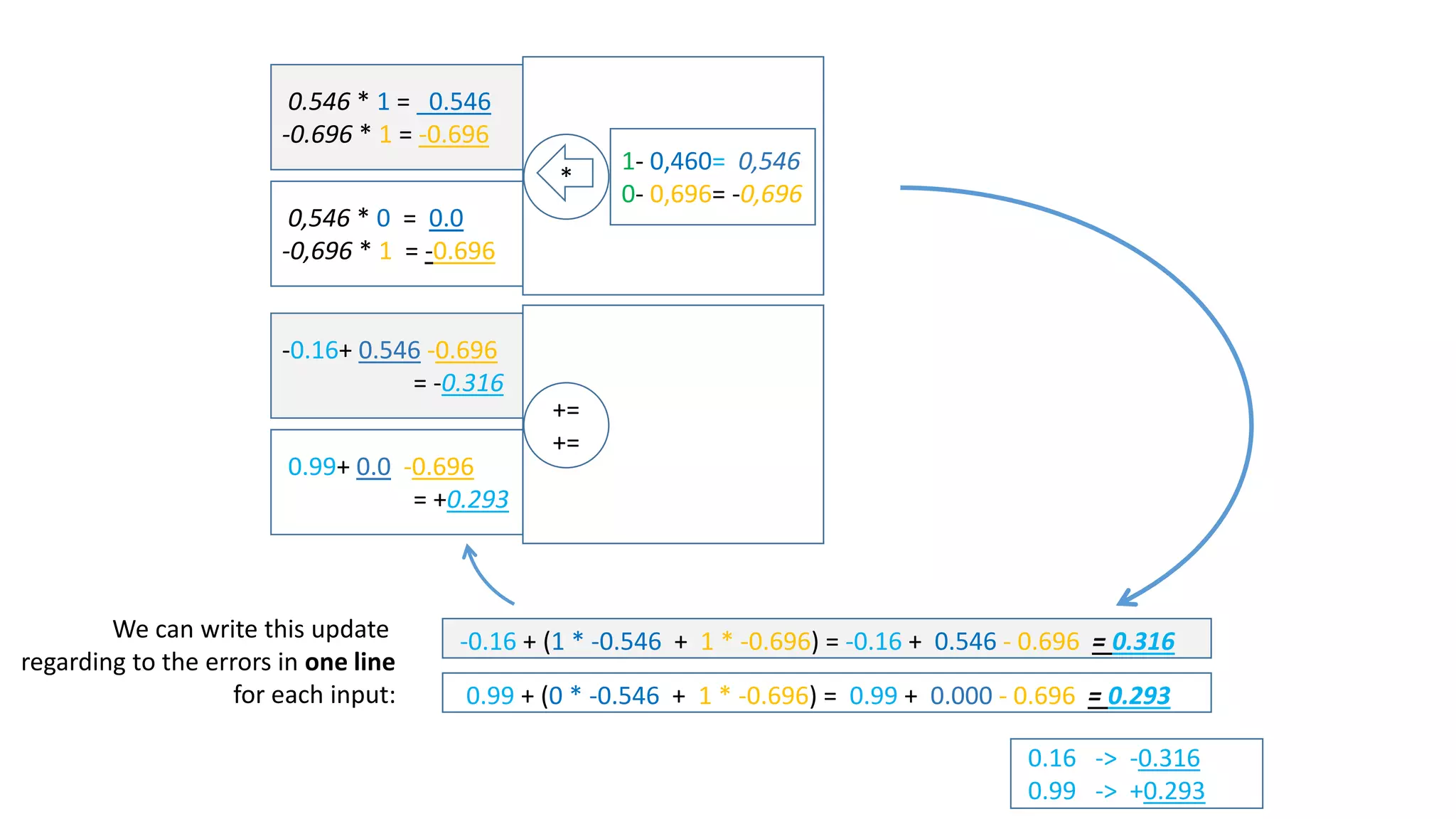
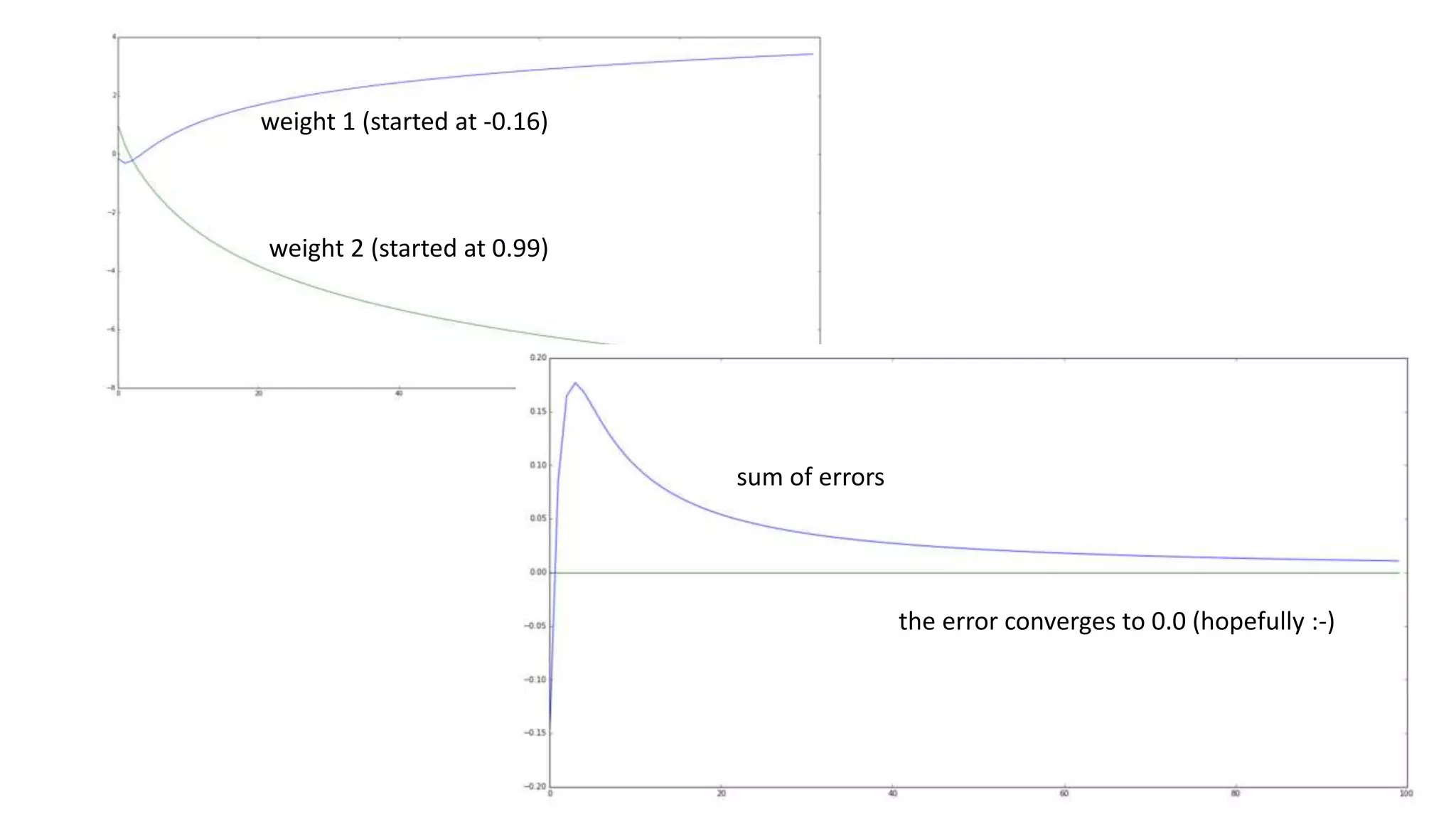

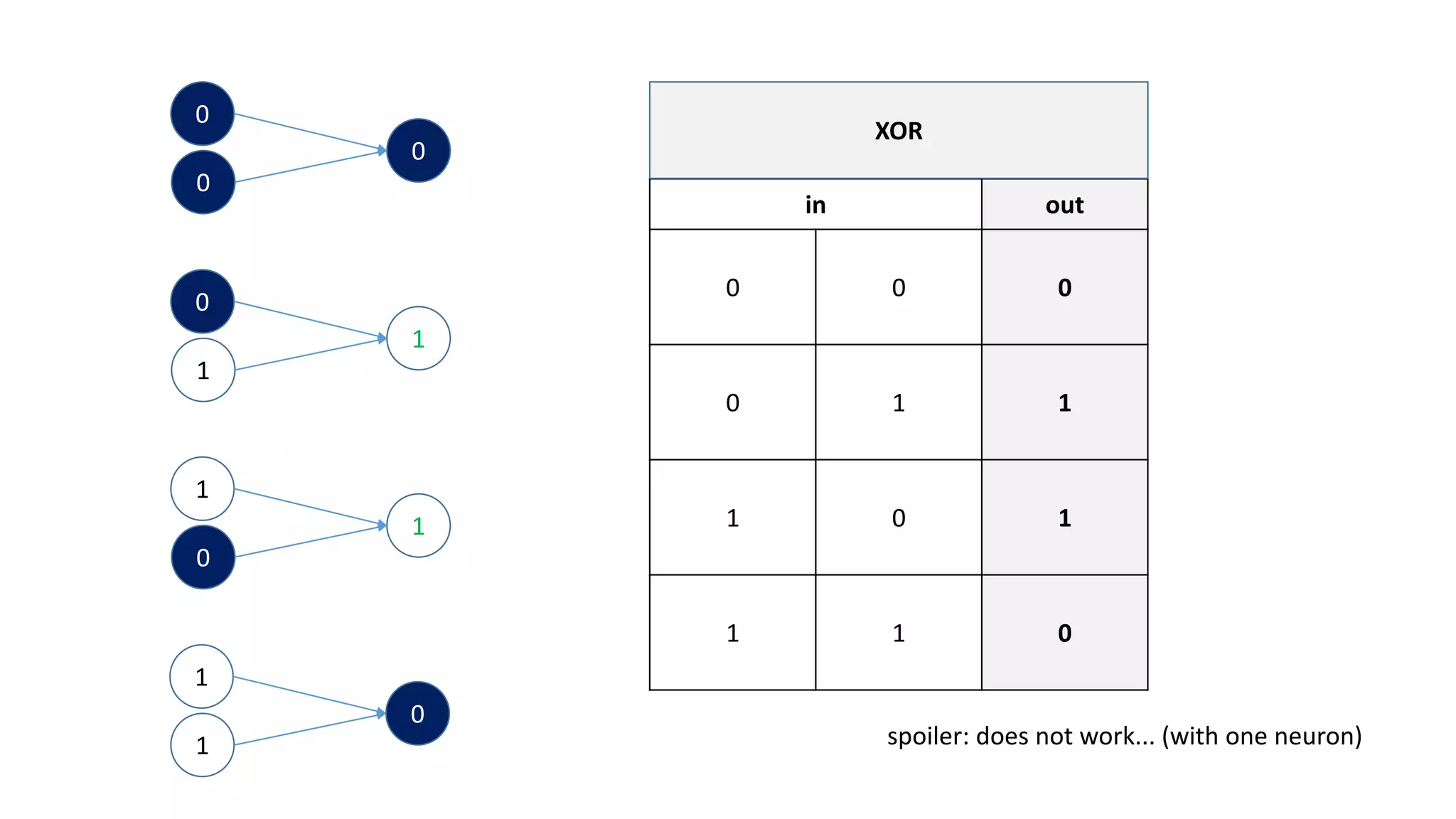
![sum of error == 0!
But…:
[0,0] -> out = 0.5 -> error = -0.5
[0,1] -> out = 0.5 -> error = 0.5
[1,0] -> out = 0.5 -> error = 0.5
[1,1] -> out = 0.5 -> error = -0.5
The weights are actually both 0!
If you think about it, it‘s pretty obvious.
Every weight has to be the same, because
a 1 or 0 leads to 0 or 1
in the same amount of cases
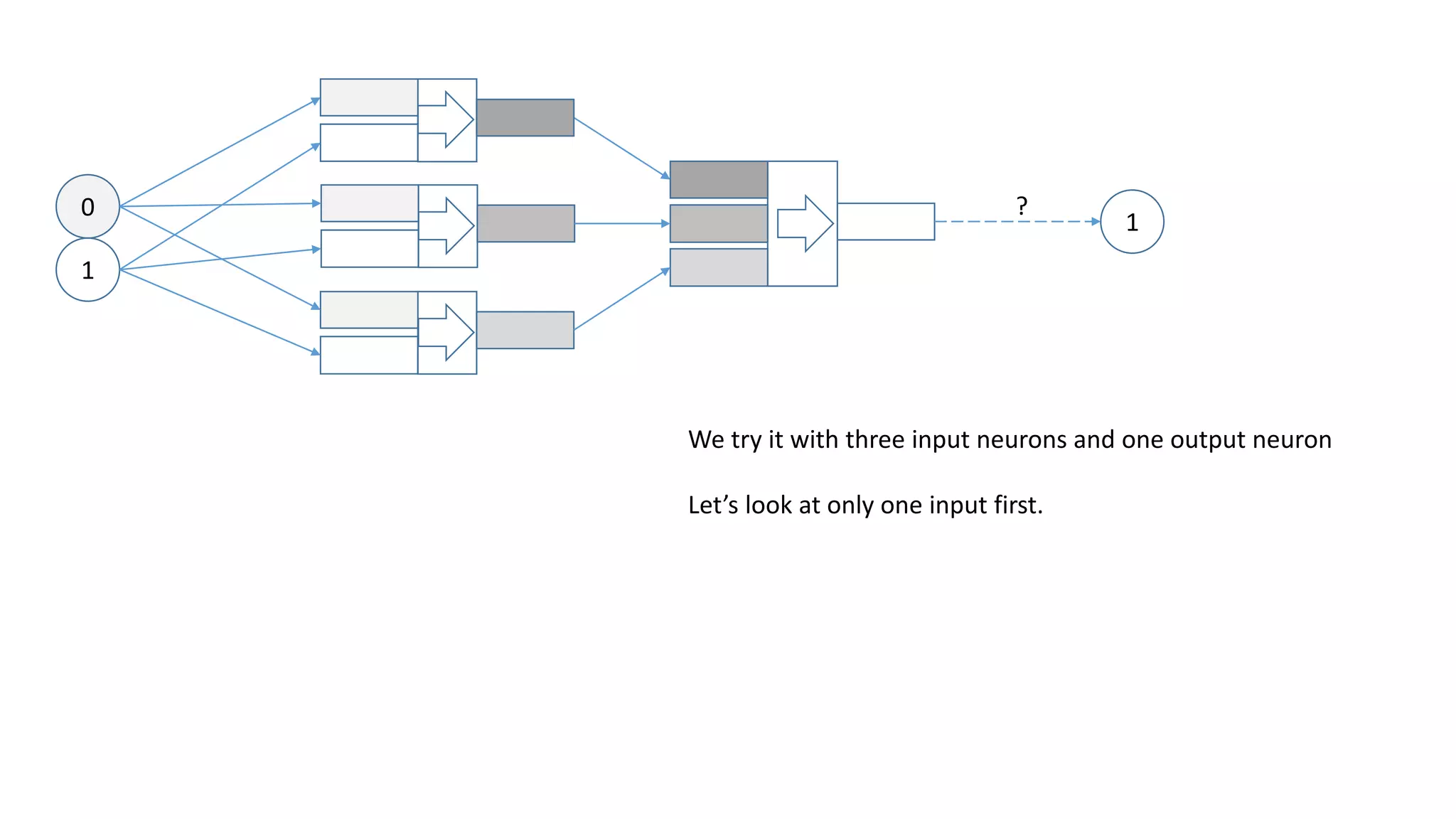
For XOR to work we need more layers!](https://image.slidesharecdn.com/neuralnetwork-160326102101/75/Neural-network-how-does-it-work-I-mean-literally-25-2048.jpg)
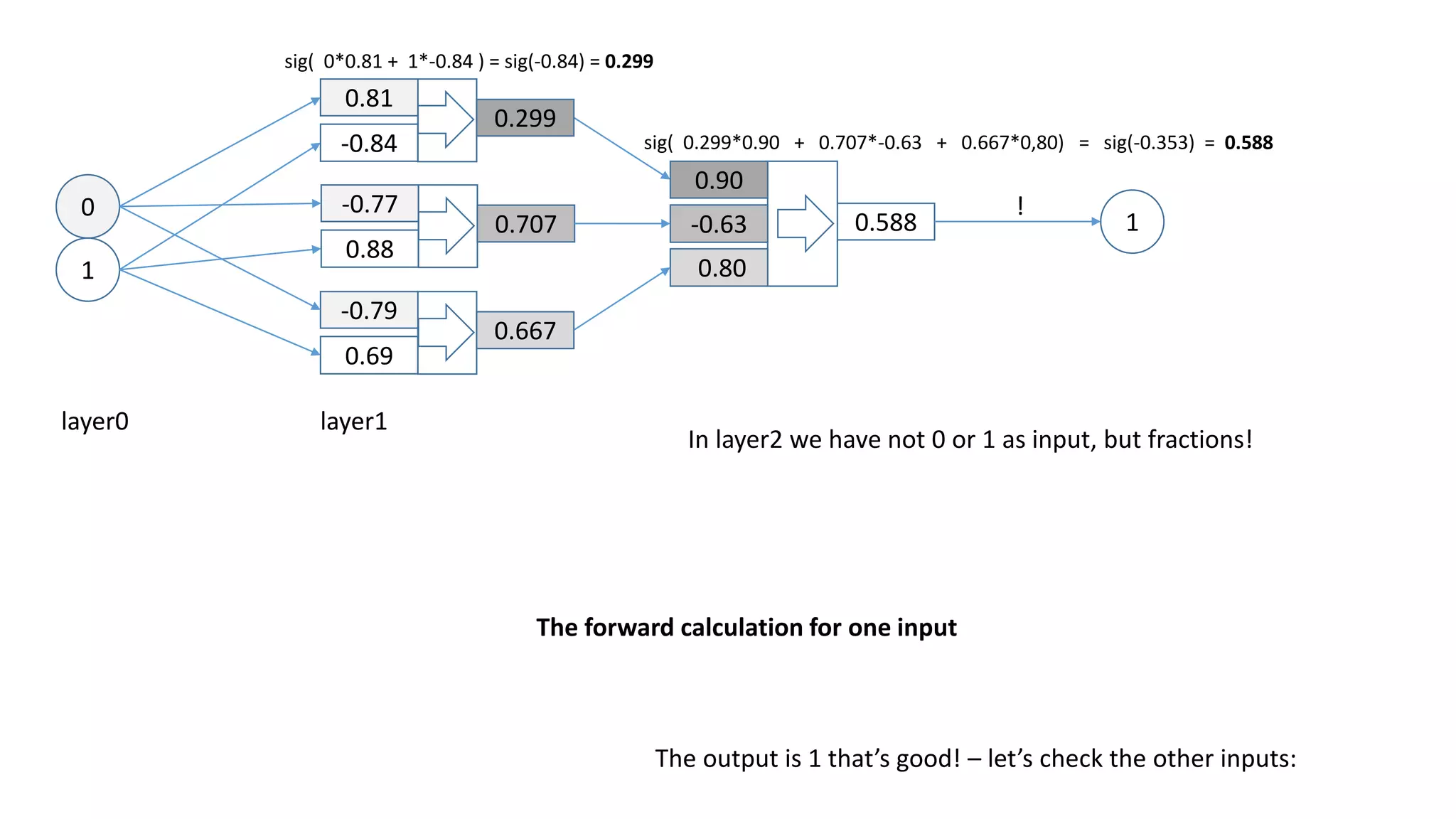
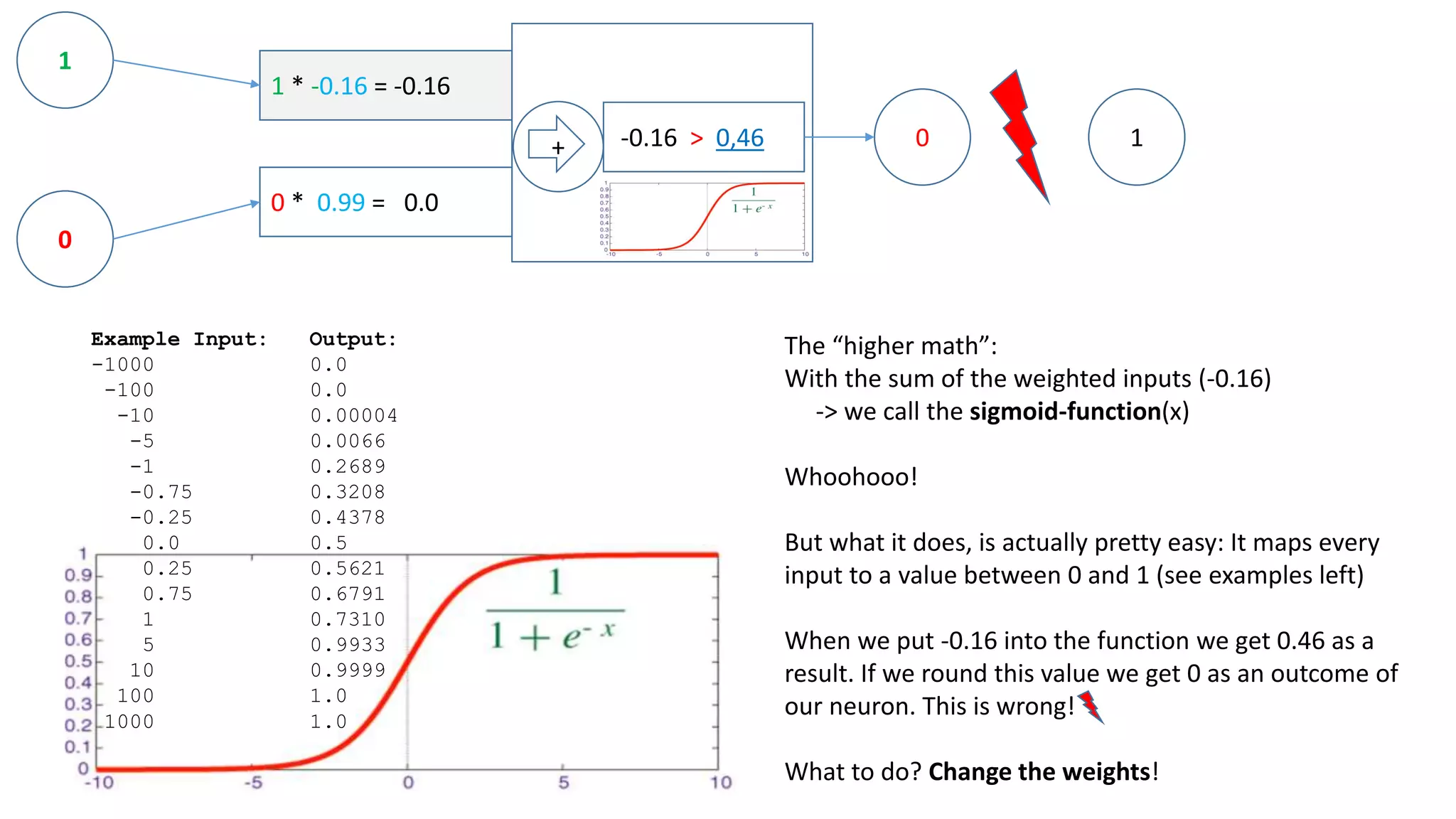
![np.random.seed(25)
WOOPS!
Output:
0,0 -> [ 0.0214737 ]
0,1 -> [ 0.98097769]
1,0 -> [ 0.9810124 ]
1,1 -> [ 0.50051869] ? – probably runs into a local minimum…](https://image.slidesharecdn.com/neuralnetwork-160326102101/75/Neural-network-how-does-it-work-I-mean-literally-32-2048.jpg)


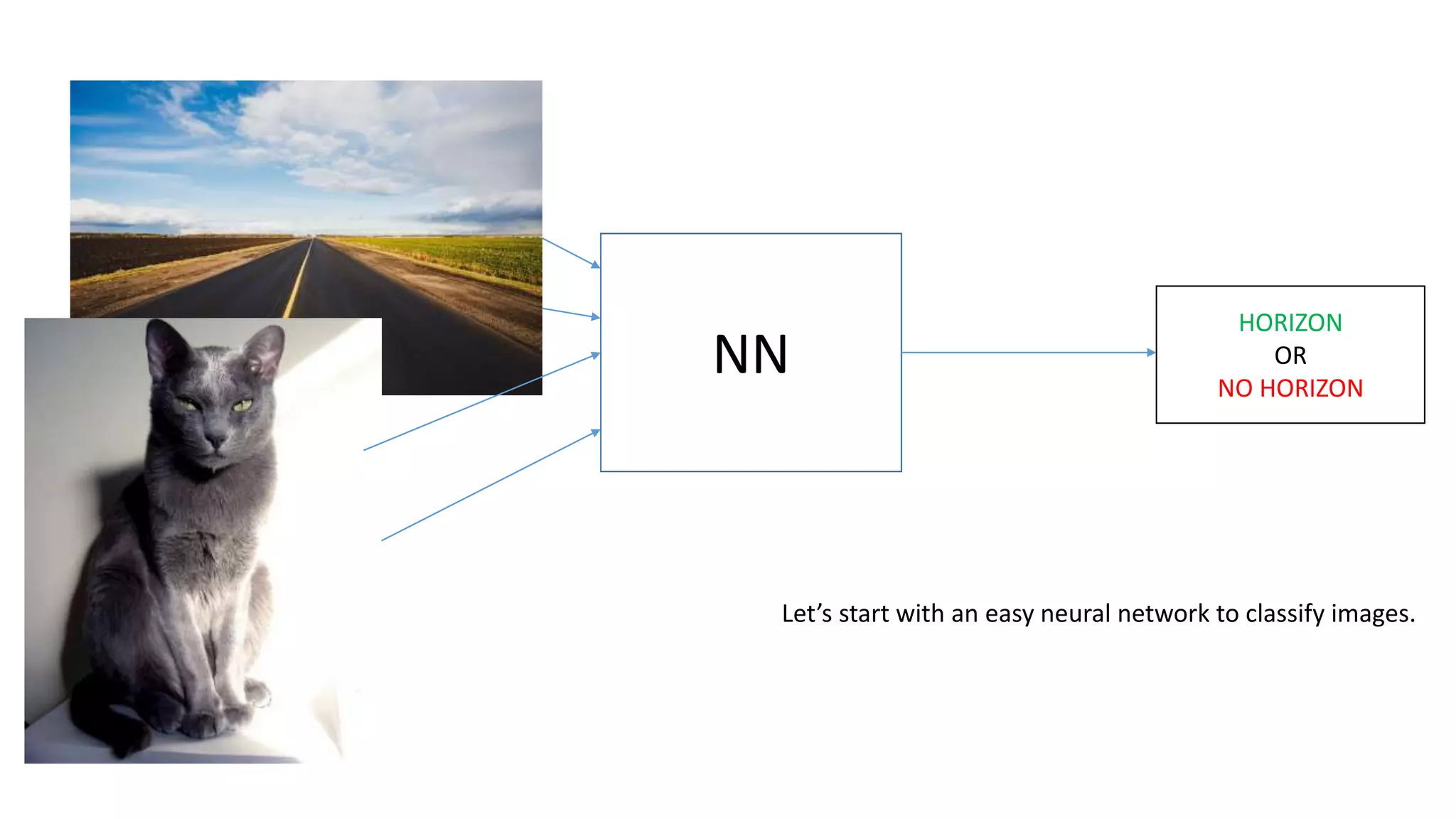
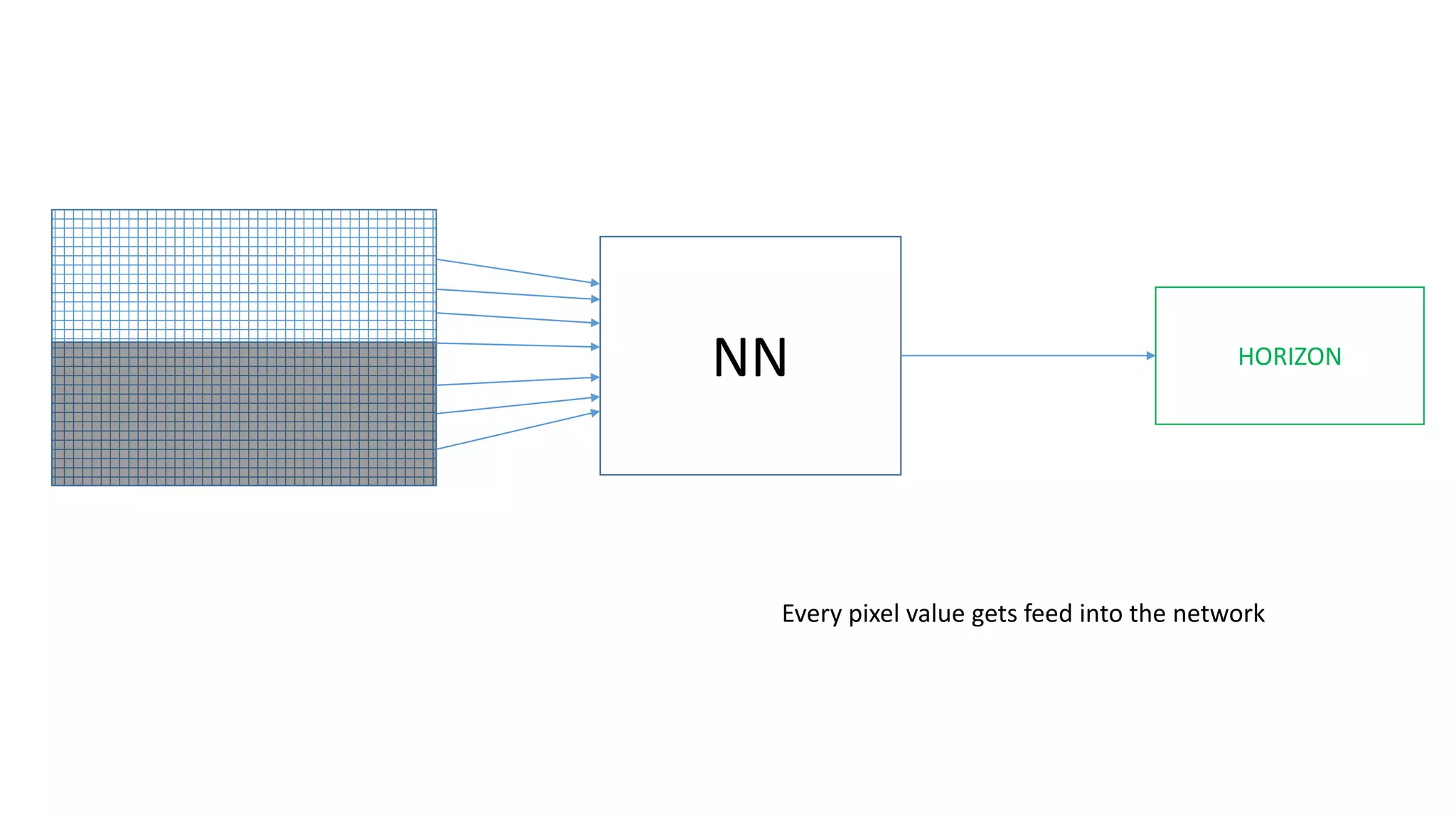
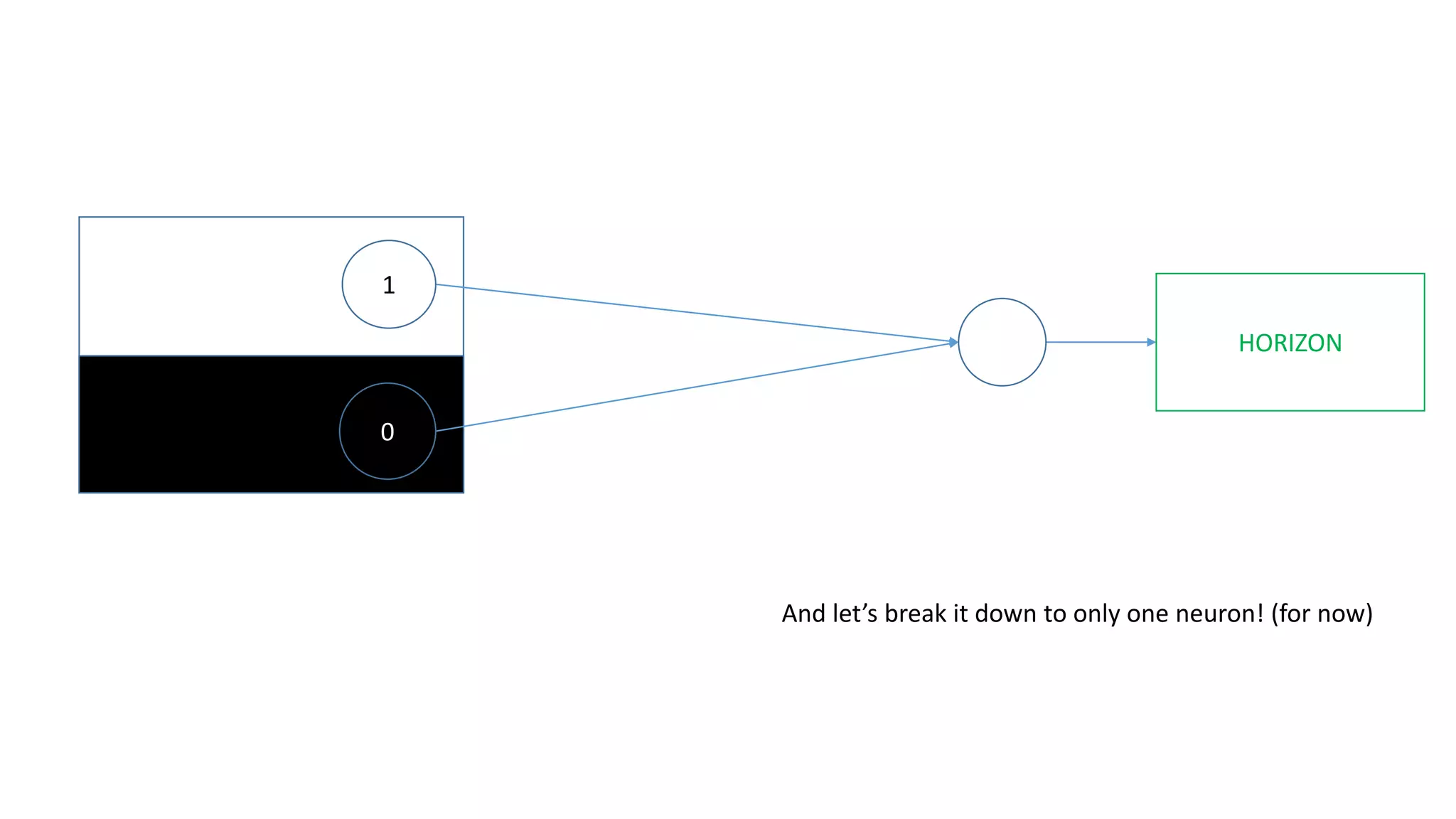
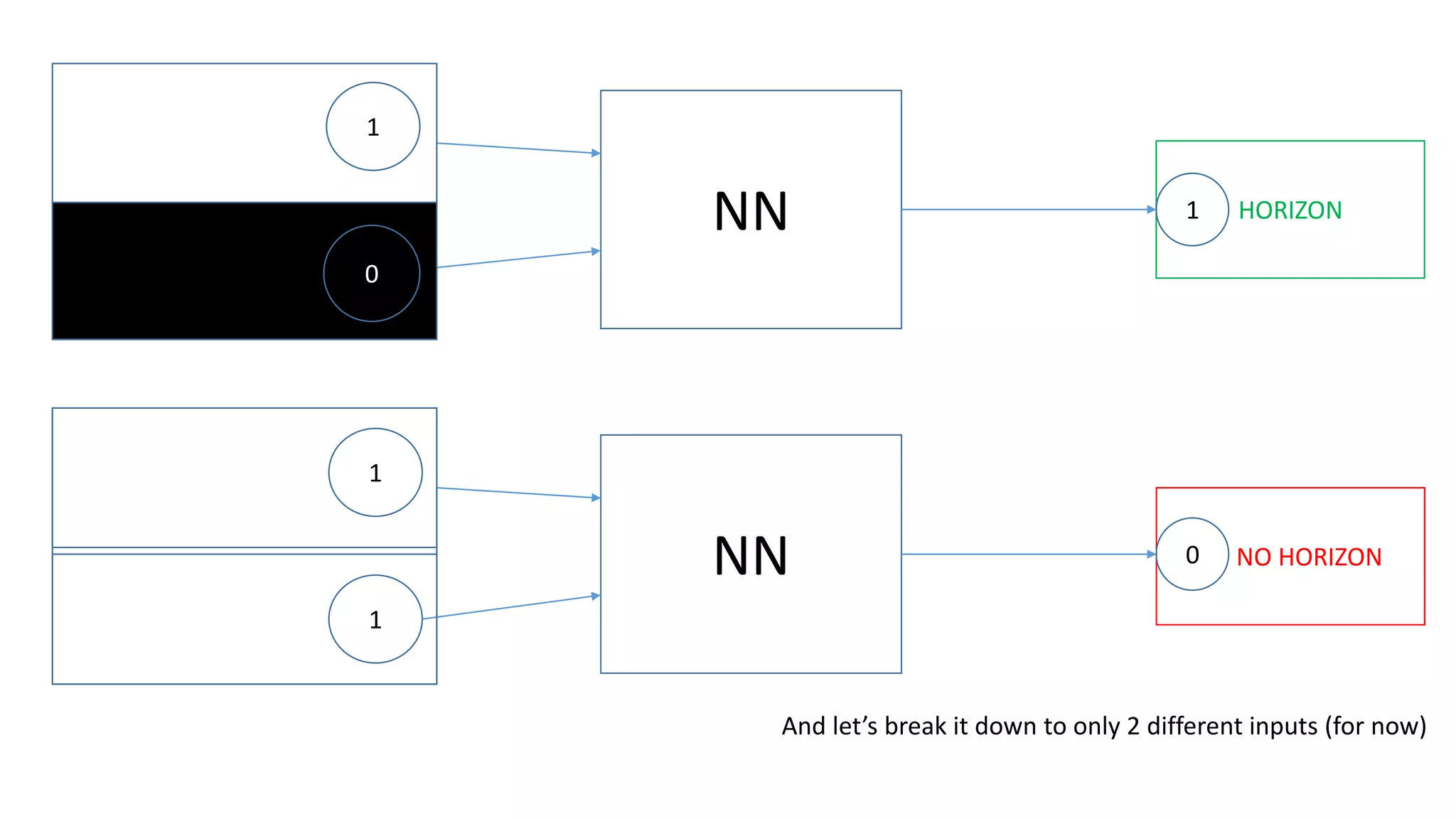
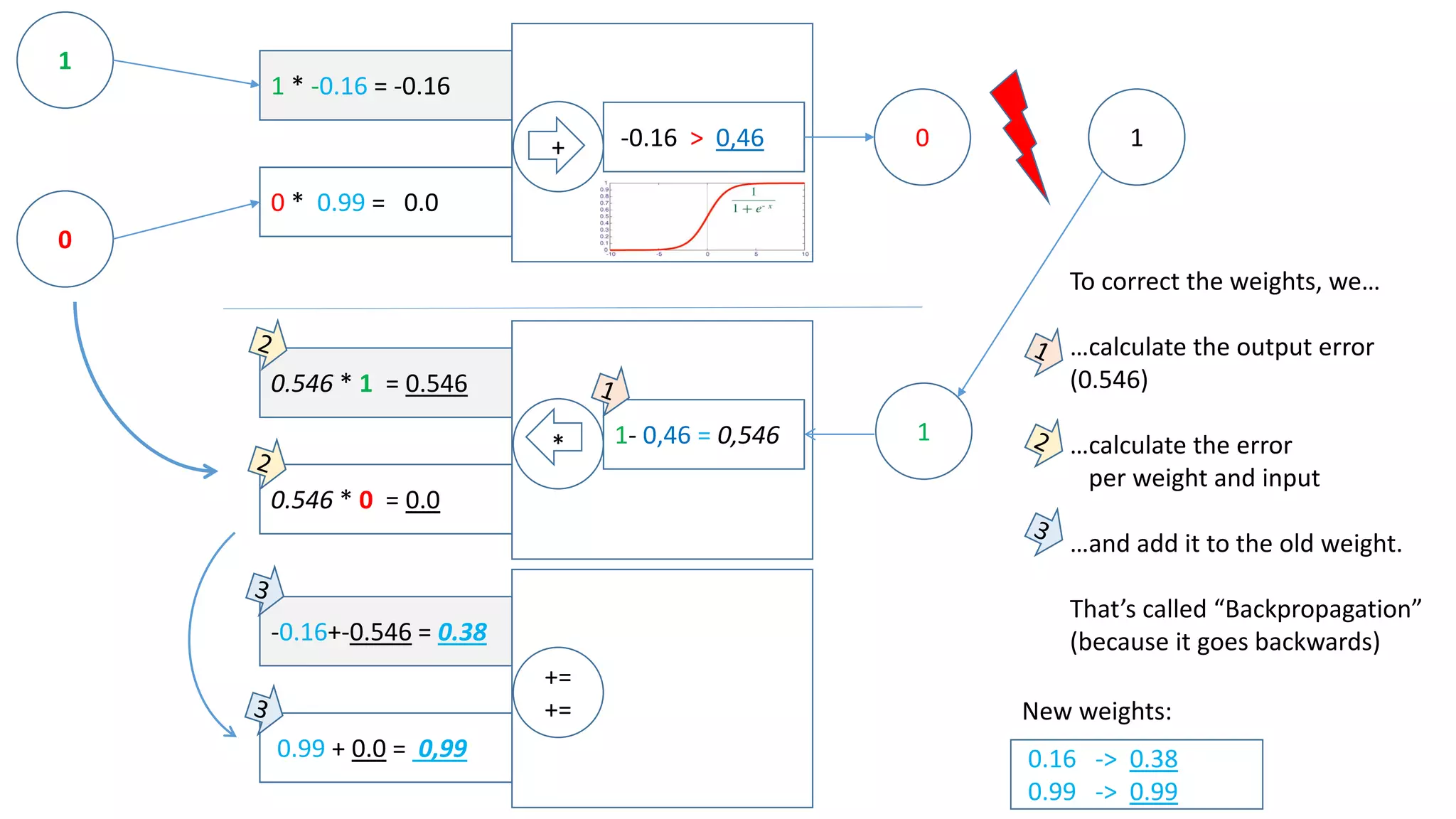
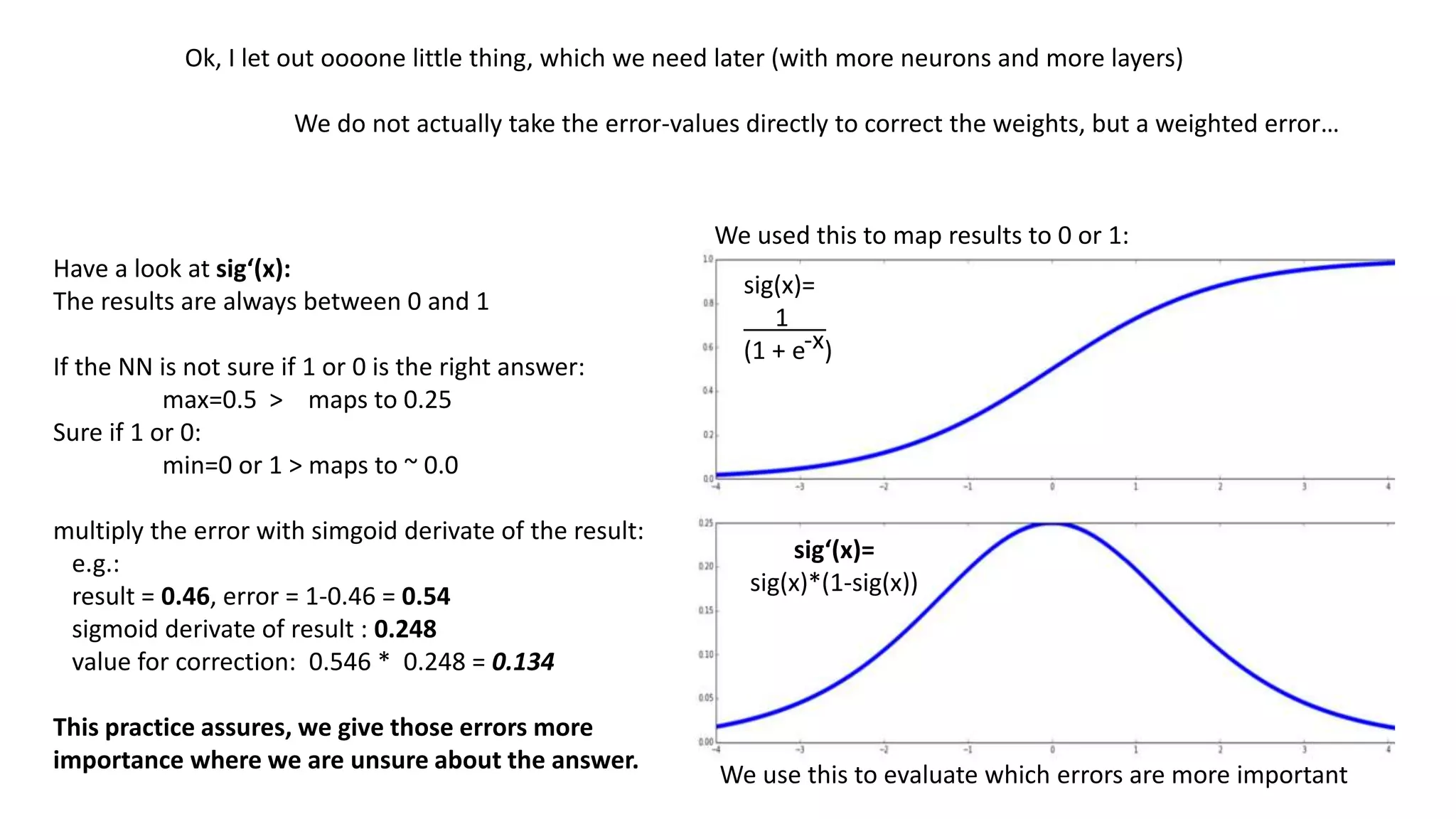
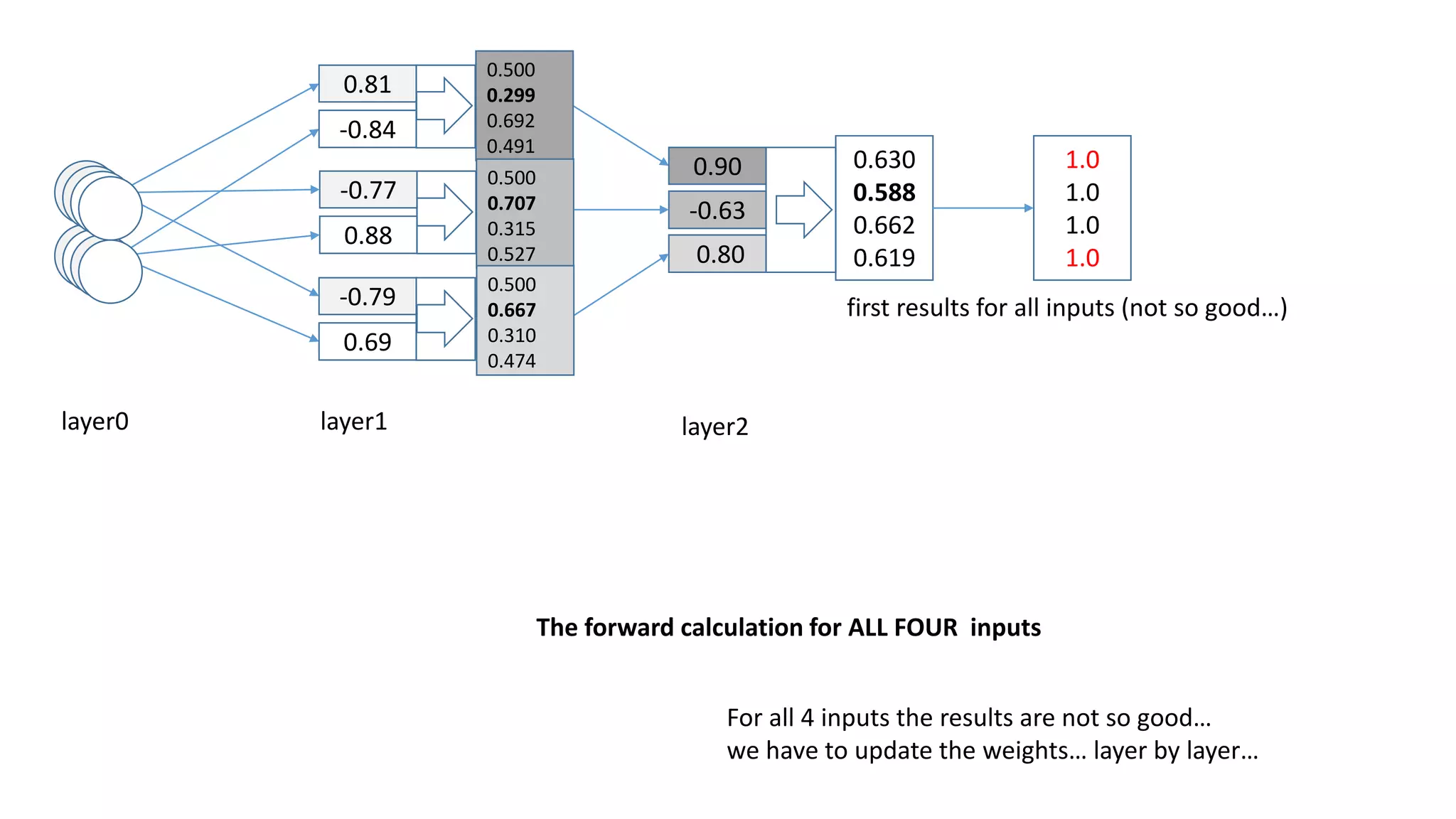
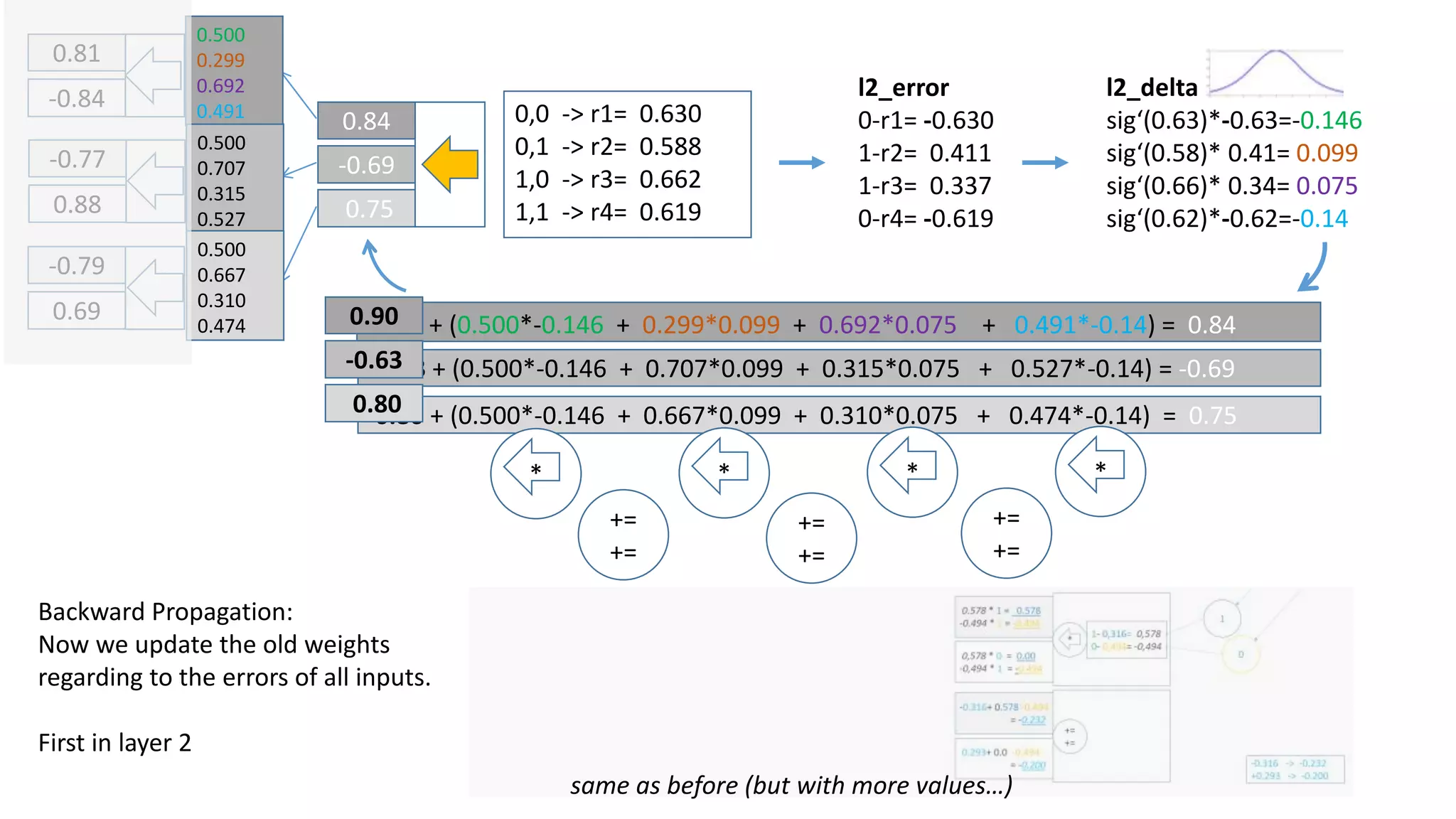
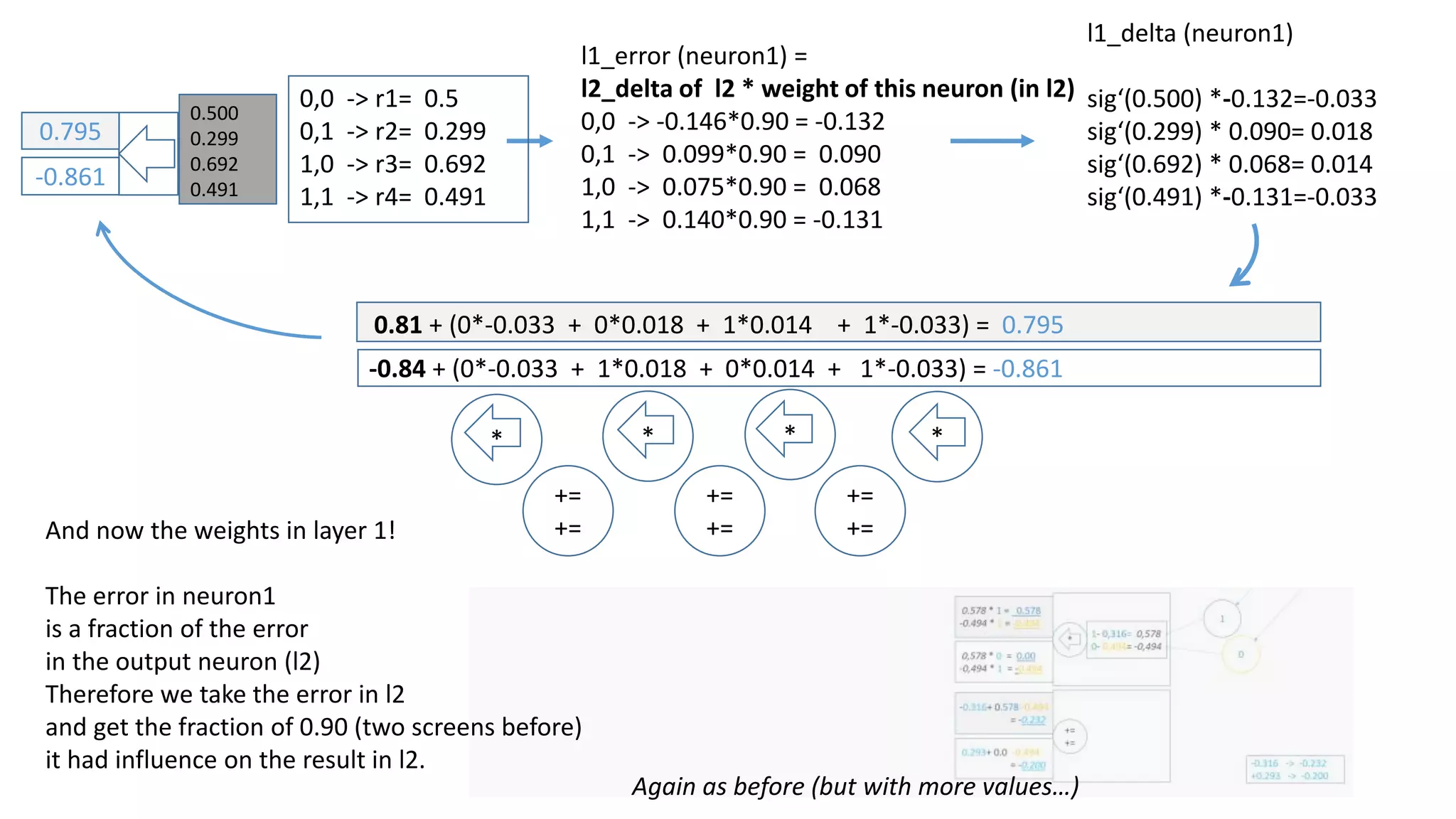
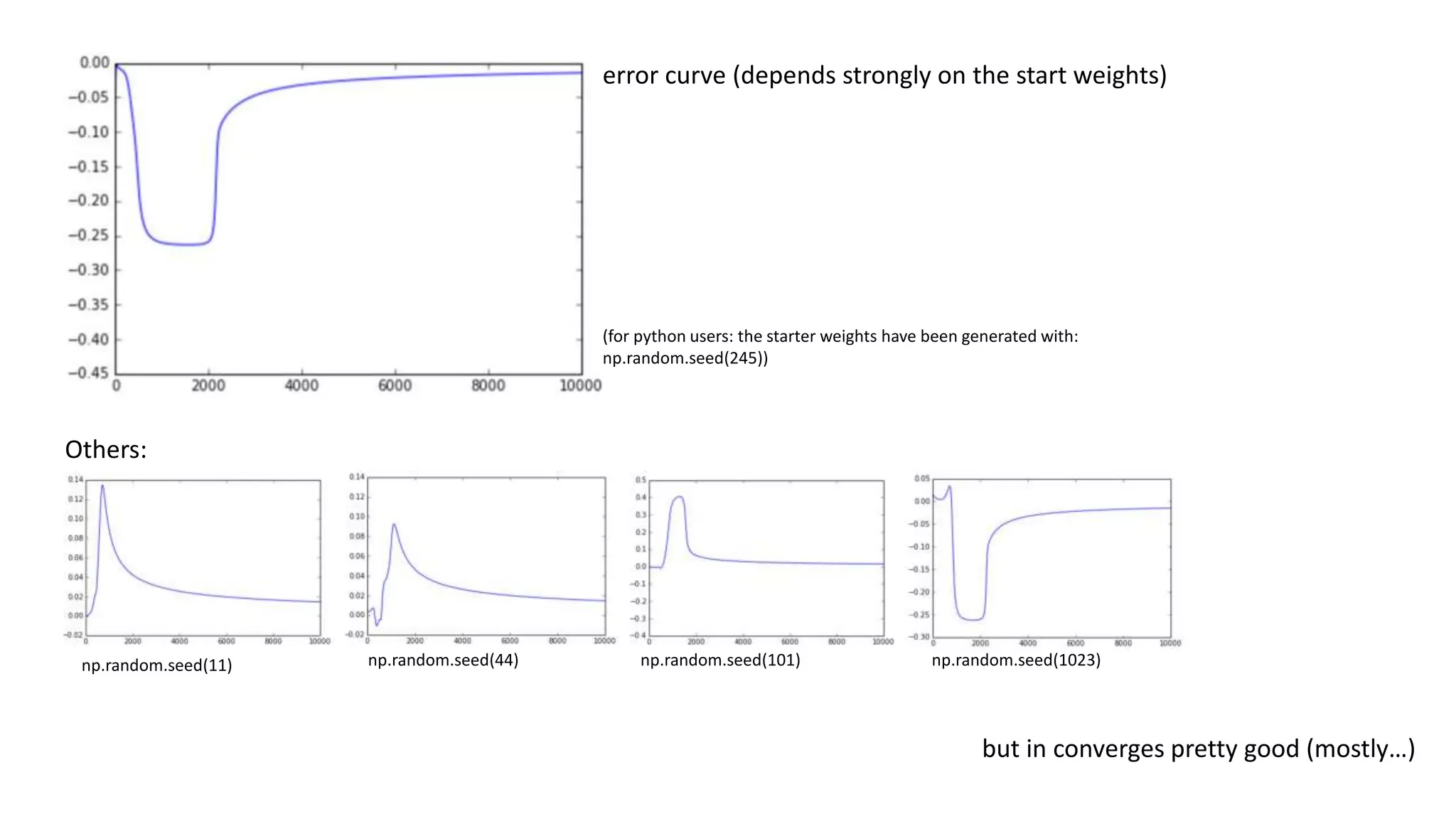
The document explains the functioning of a neural network in a simplified manner, focusing on how inputs are processed through neurons to produce outputs. It describes the concepts of weights, calculations, the sigmoid function, error adjustment, and backpropagation, using examples with pixel inputs for classification. The text highlights the iterative nature of training neural networks, including the necessity of multiple layers to successfully handle complex functions like XOR.
![reductio [ad absurdum]](https://cdn.slidesharecdn.com/ss_thumbnails/taualywhssudecboubib-signature-40f4714a7511dbefb3f8b81978ee26a52b8bc17a56b46da771a1d673a5b4d7df-poli-170804175449-thumbnail.jpg?width=640&height=640&fit=bounds)









































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)









![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)







![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
