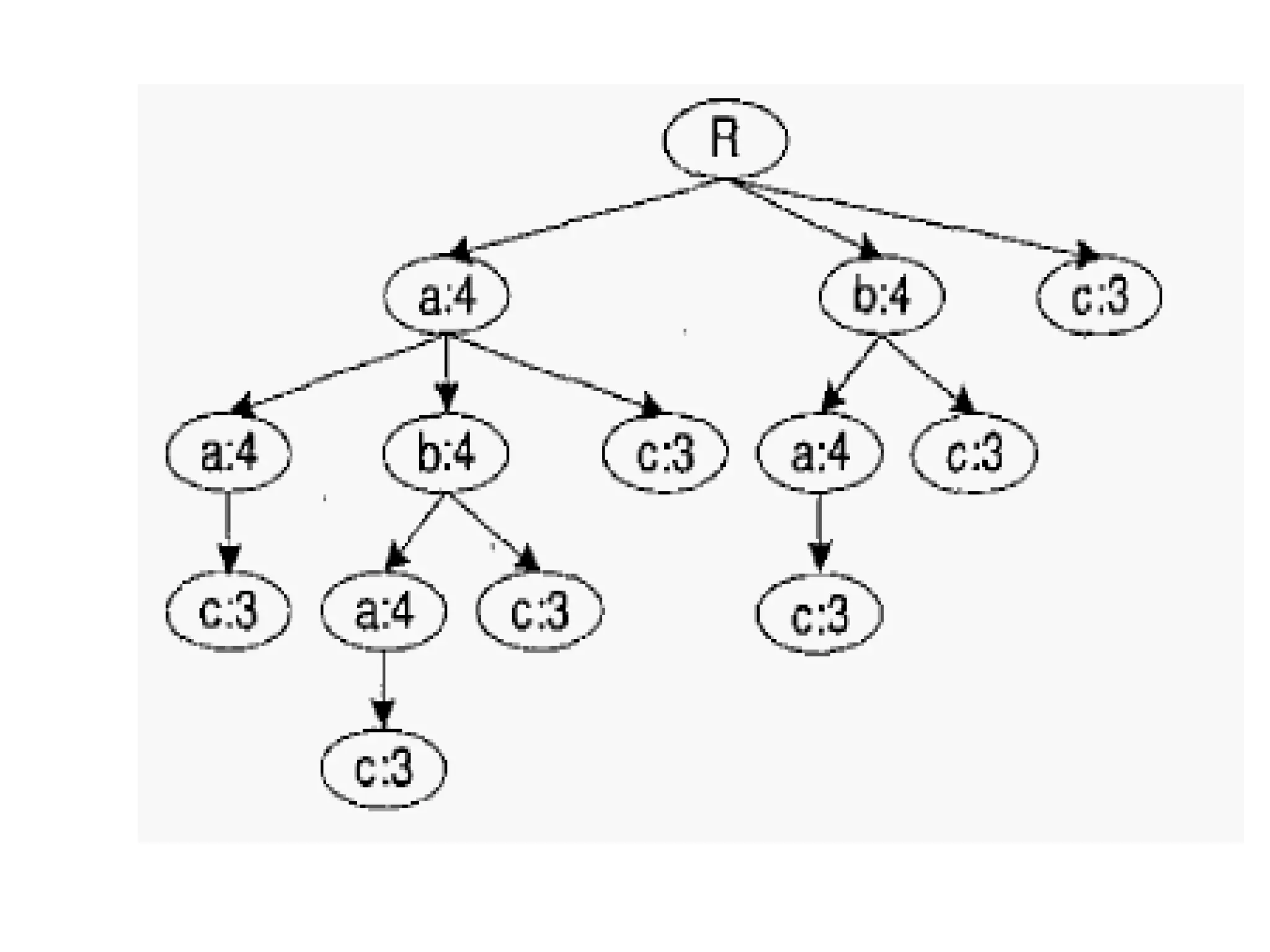
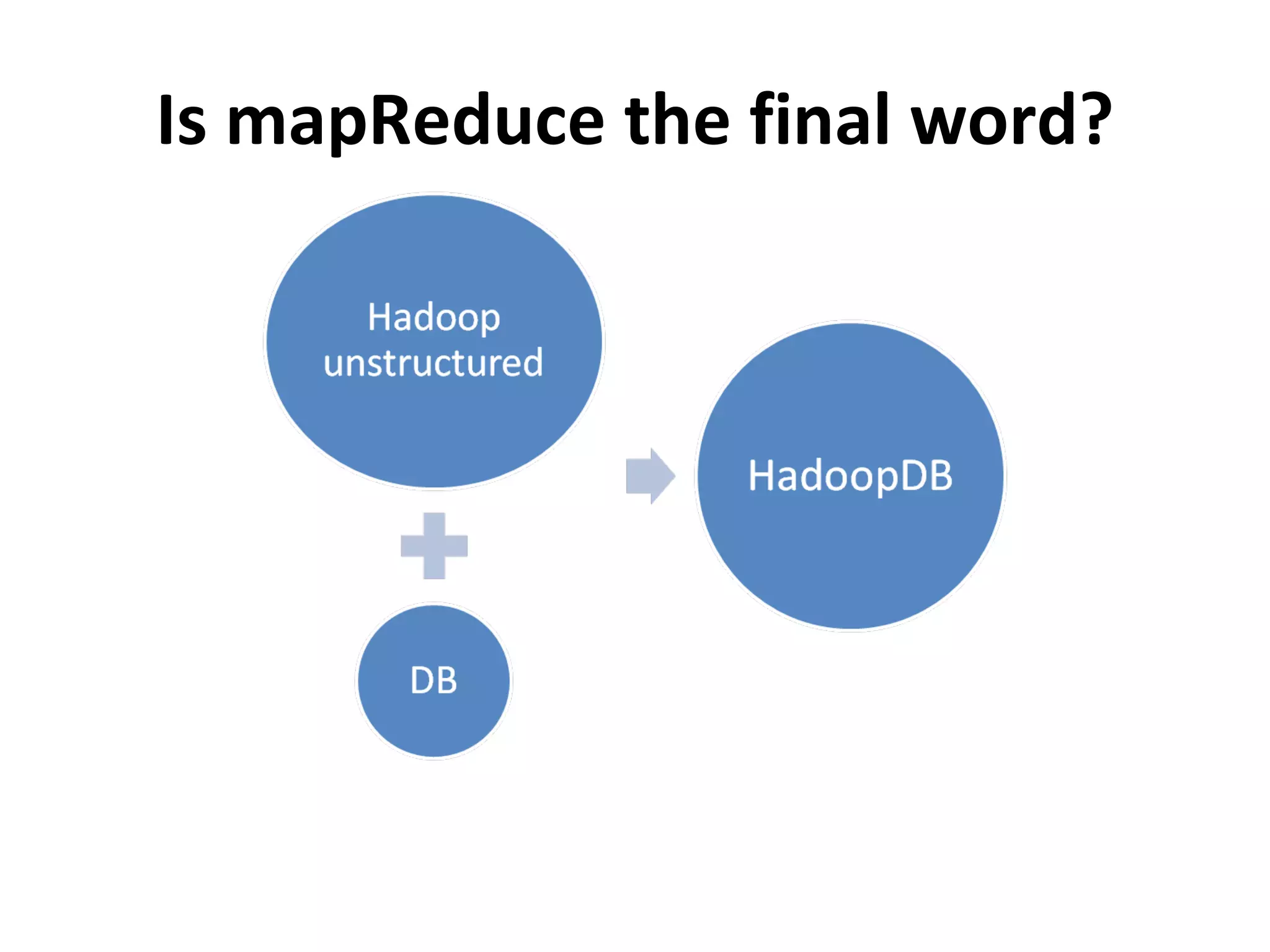
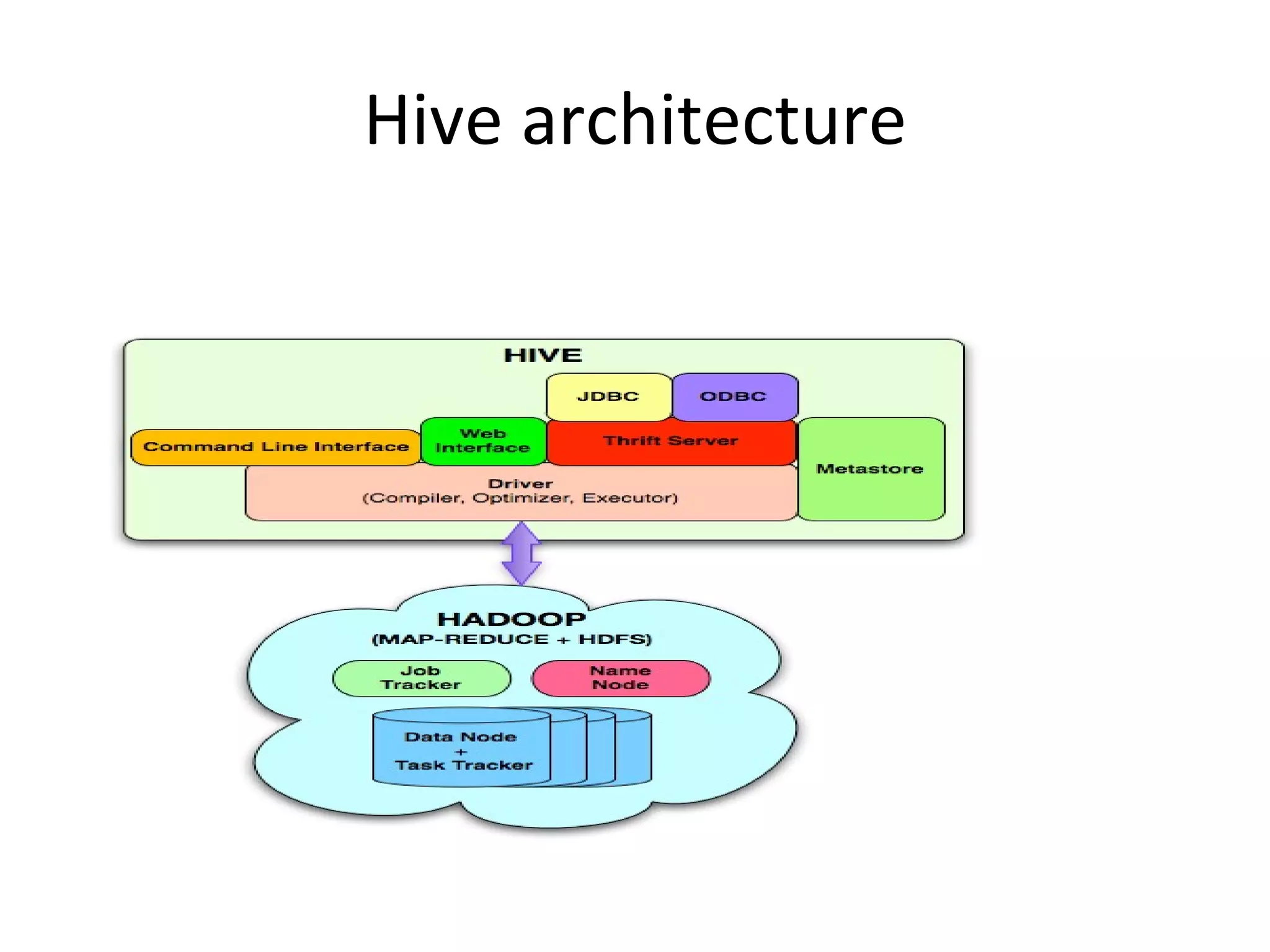
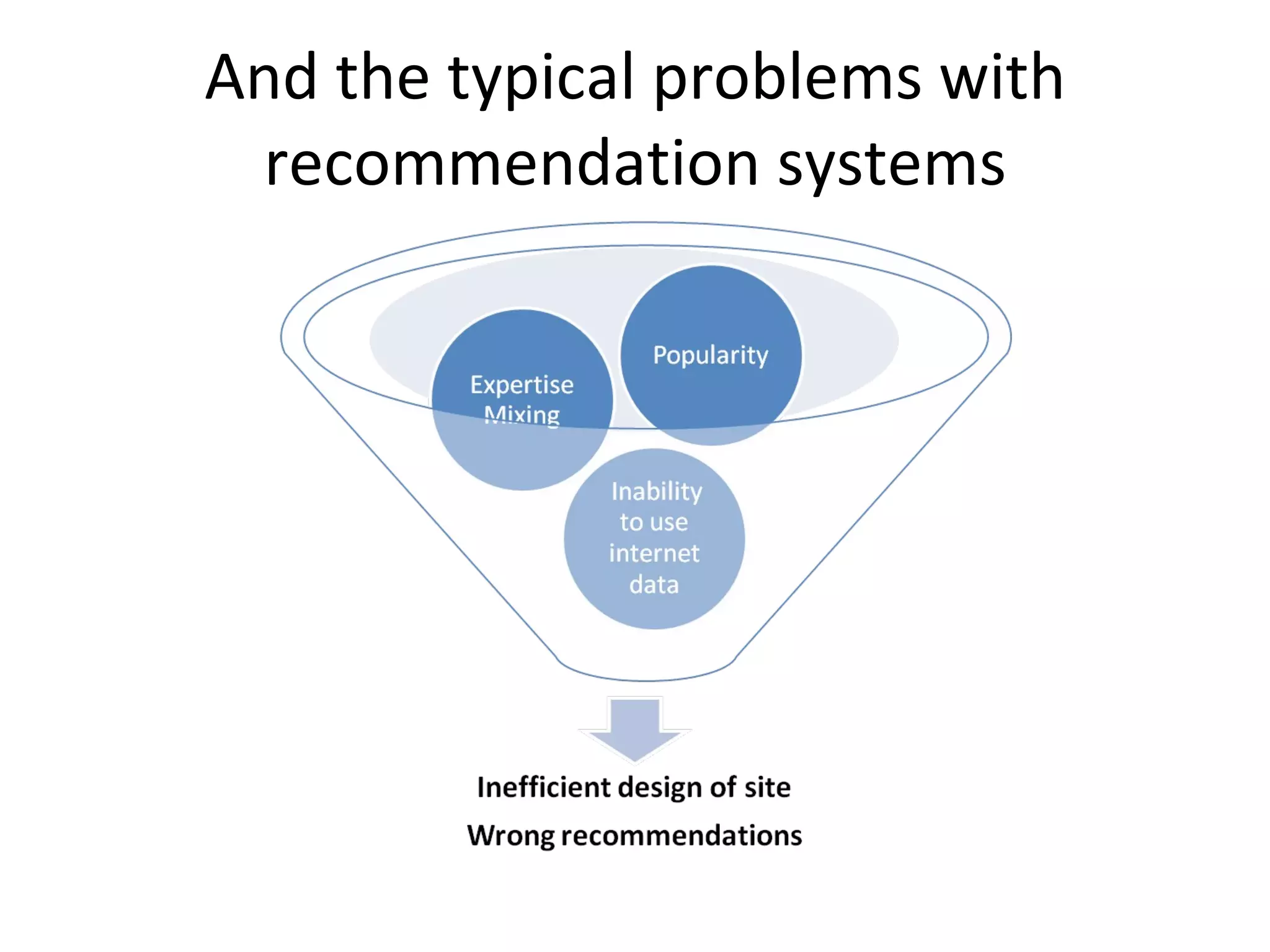
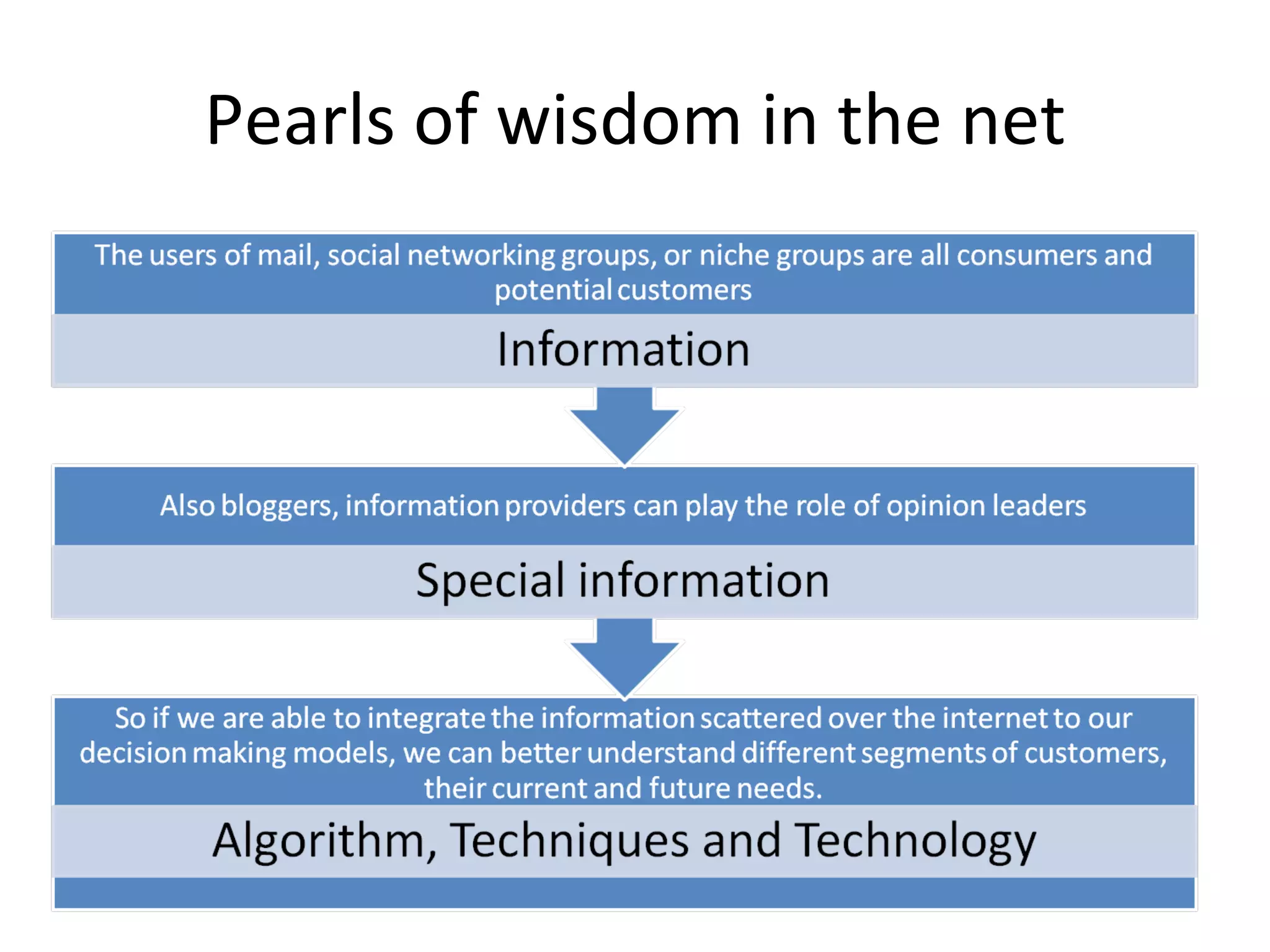
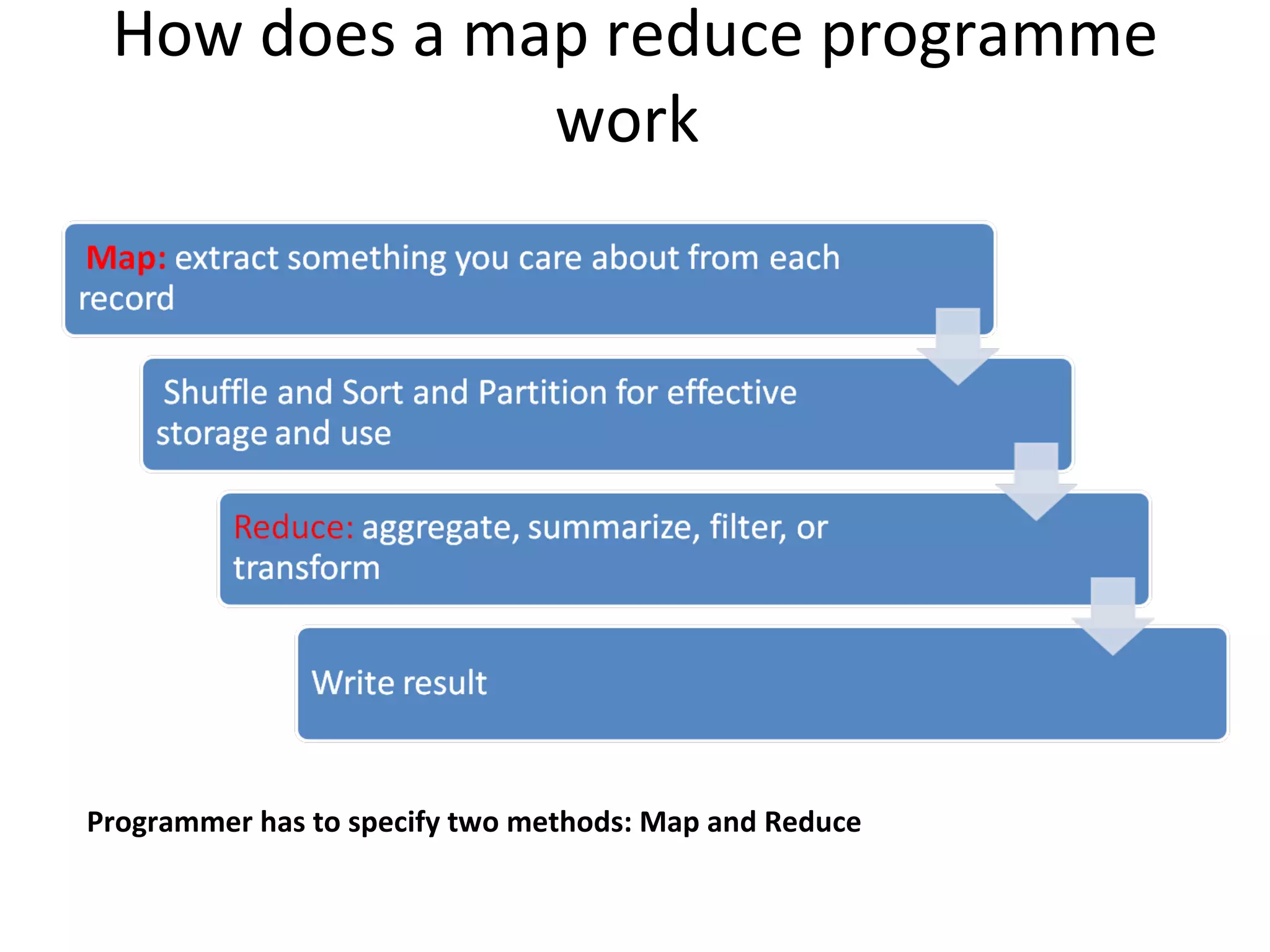
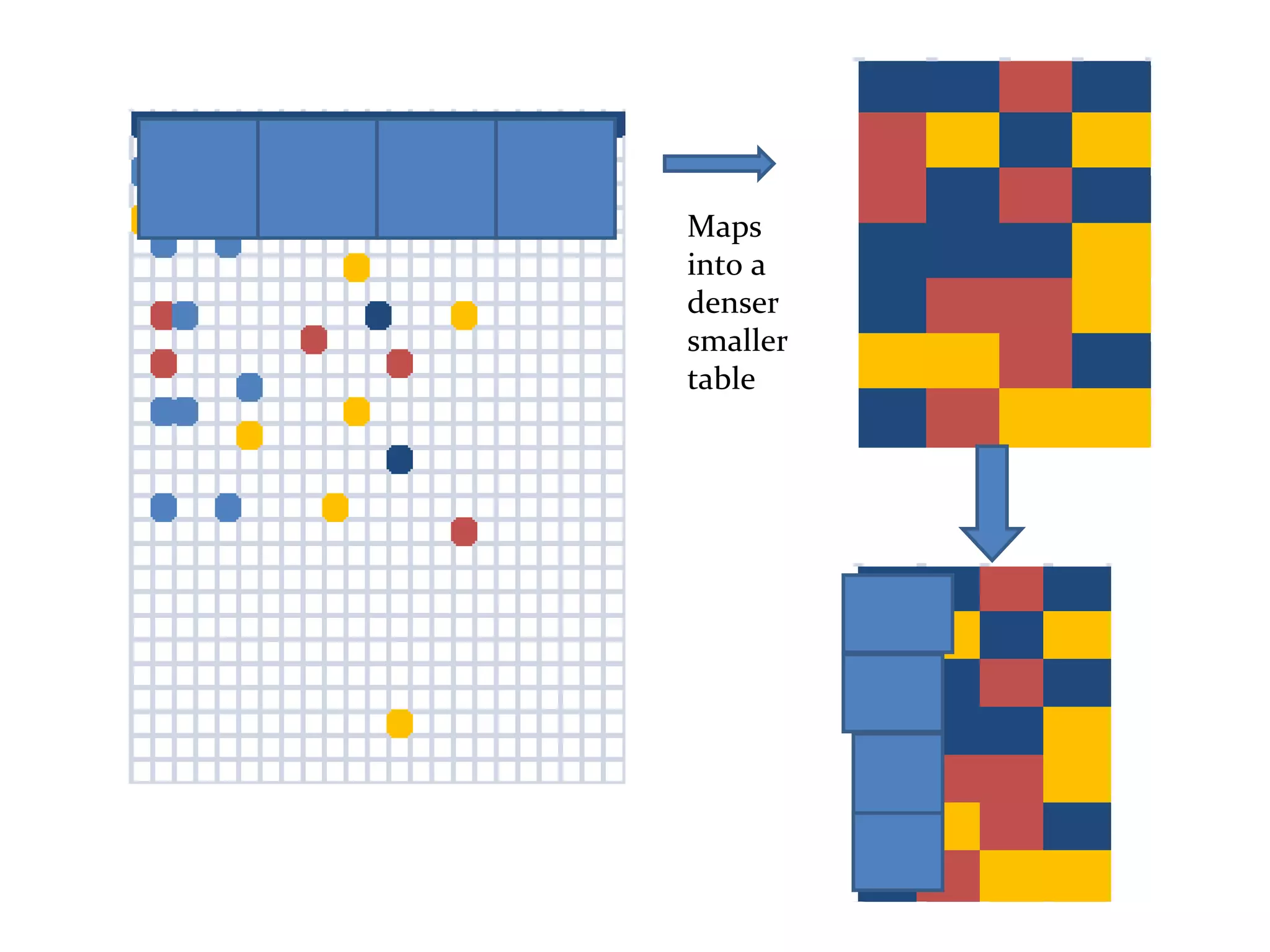
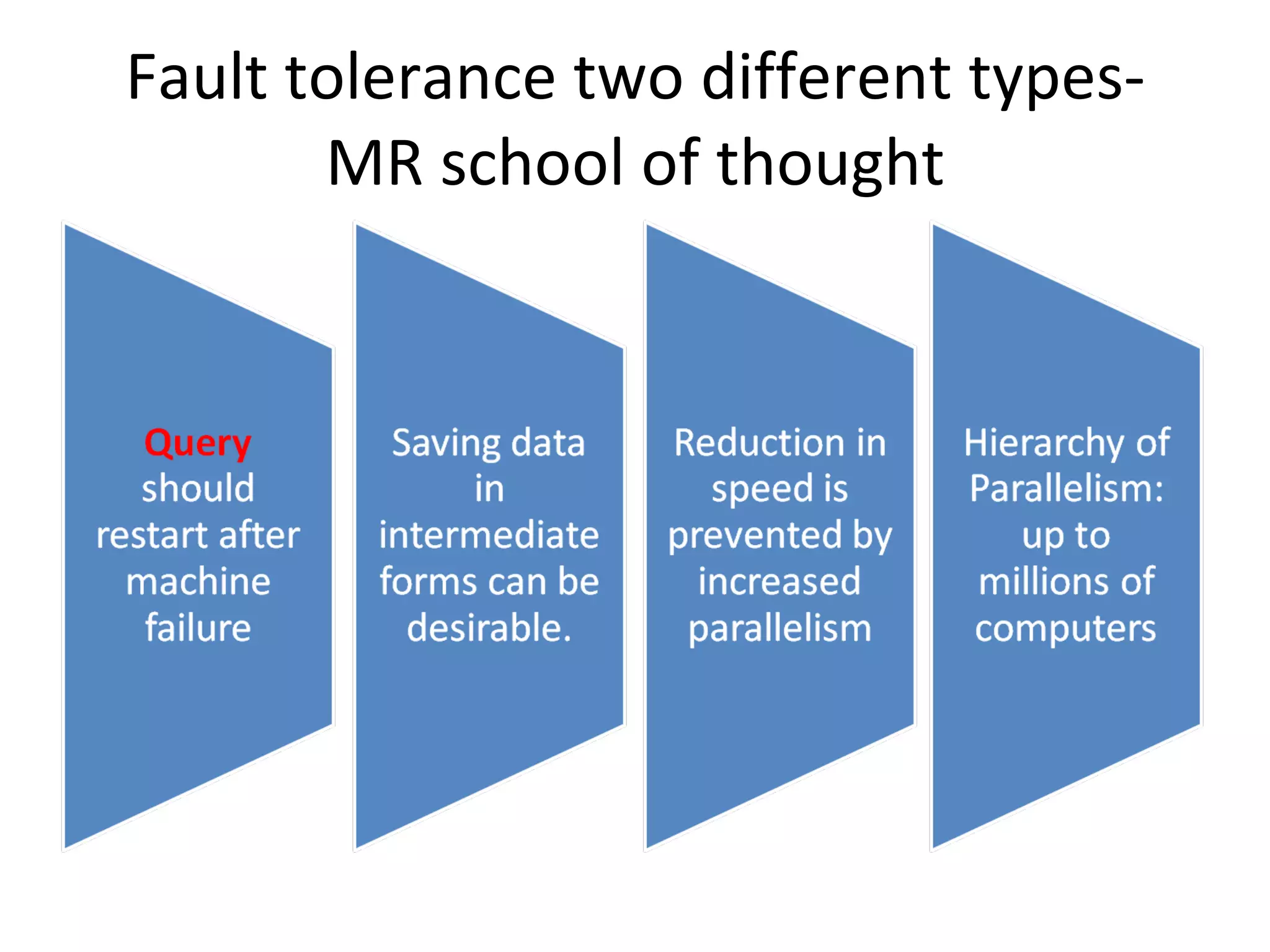
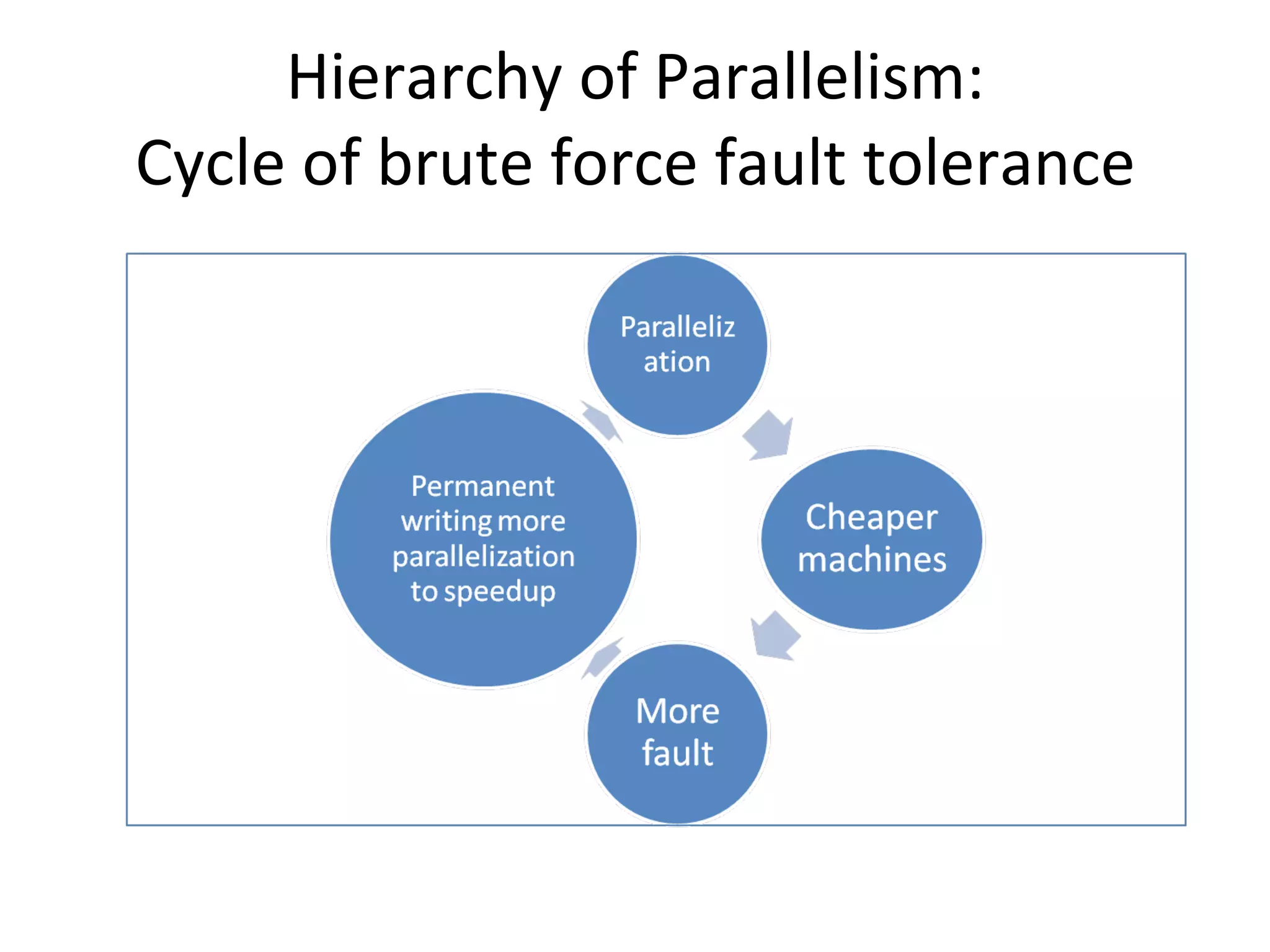
The document discusses using MapReduce for a sequential web access-based recommendation system. It explains how web server logs could be mapped to create a pattern tree showing frequent sequences of accessed web pages. When making recommendations for a user, their access pattern would be compared to patterns in the tree to find matching branches to suggest. MapReduce is well-suited for this because it can efficiently process and modify the large, dynamic tree structure across many machines in a fault-tolerant way.


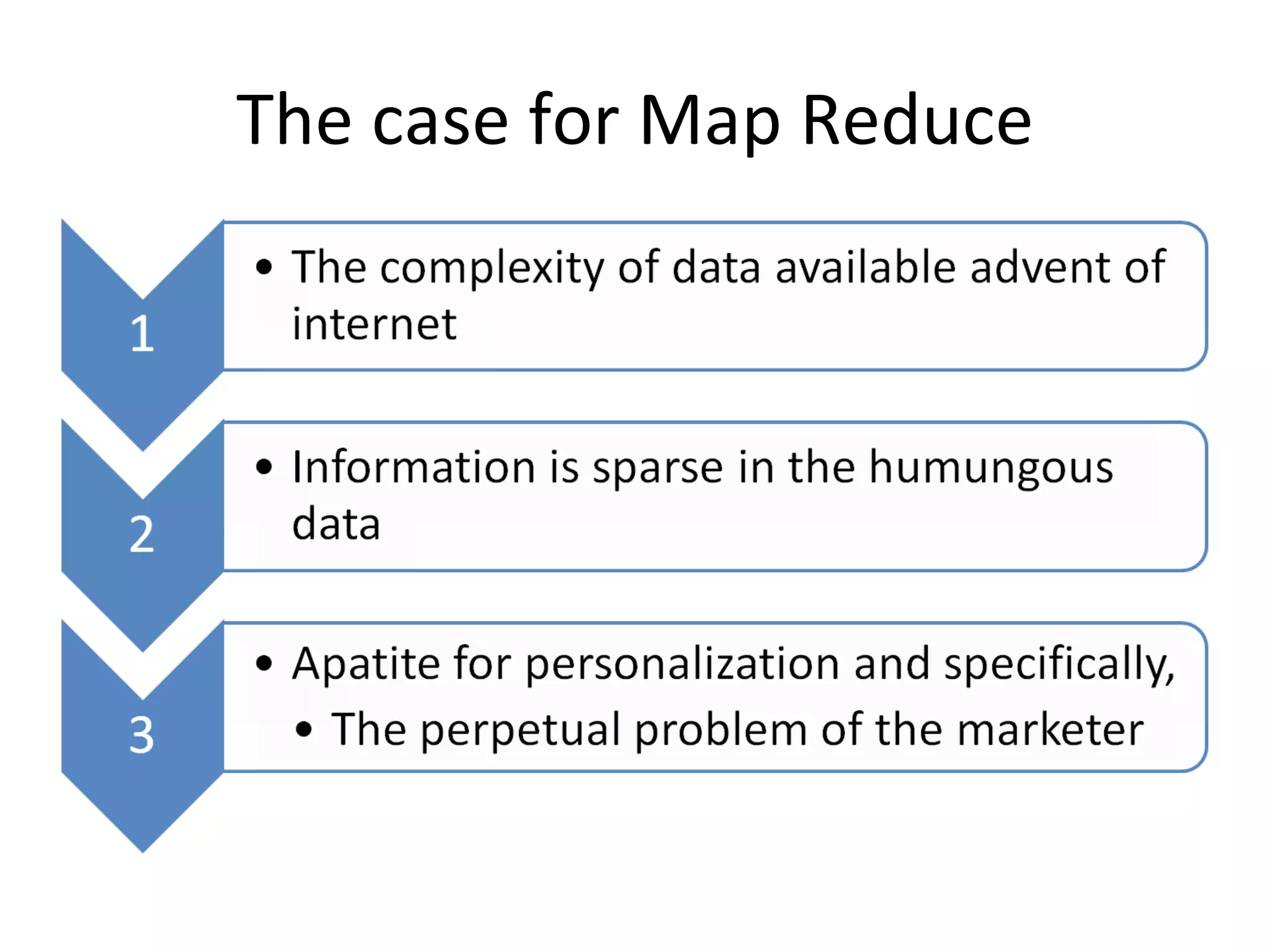


















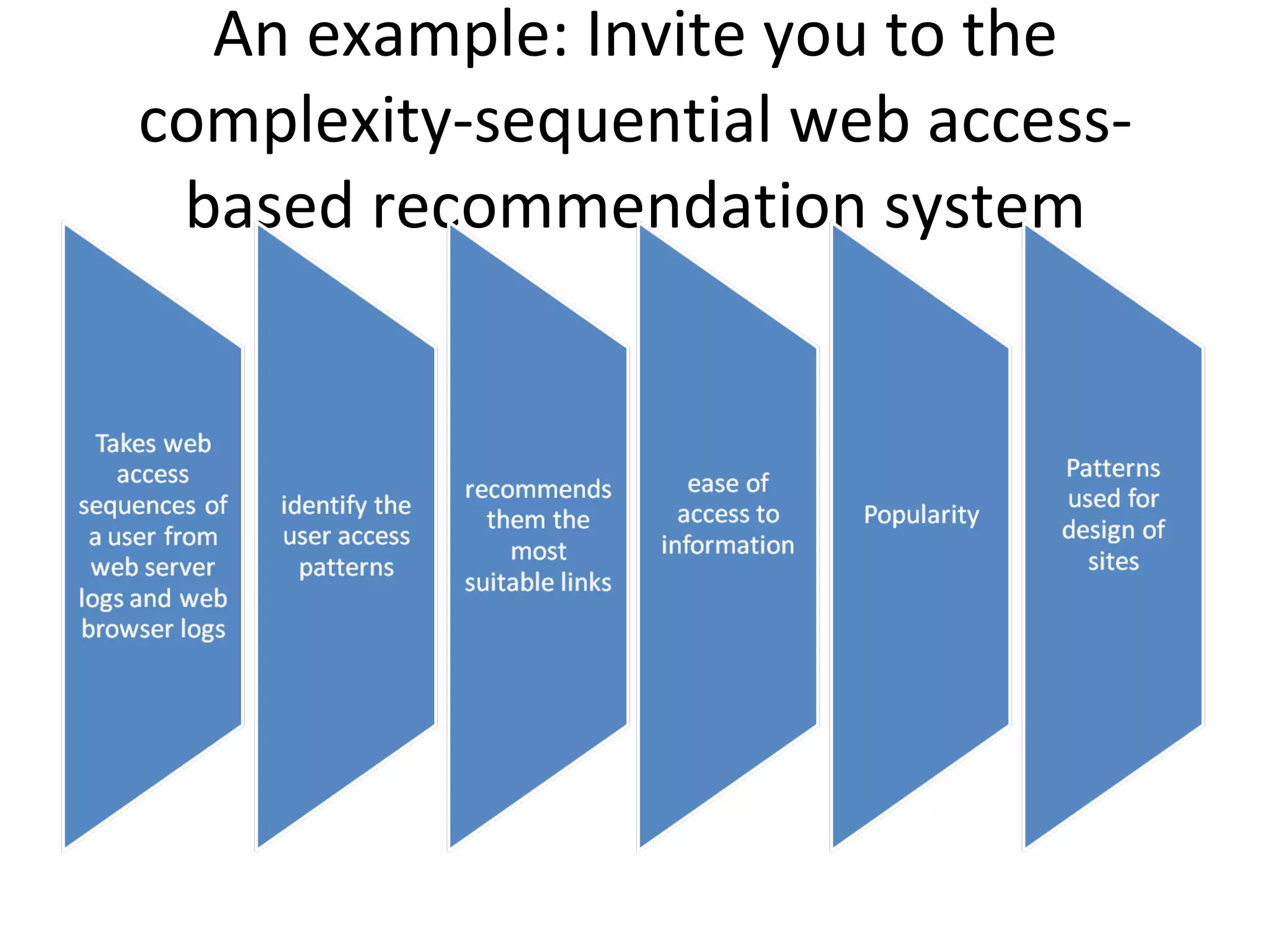
![sequential web access-based recommendation system It goes through web server logs, mines the pattern in the sequence and then creates a pattern tree. And the pattern tree is continuously modified taking the data from different servers.[Zhou et al]](https://image.slidesharecdn.com/mrbi-110417212212-phpapp01/75/Mr-bi-29-2048.jpg)