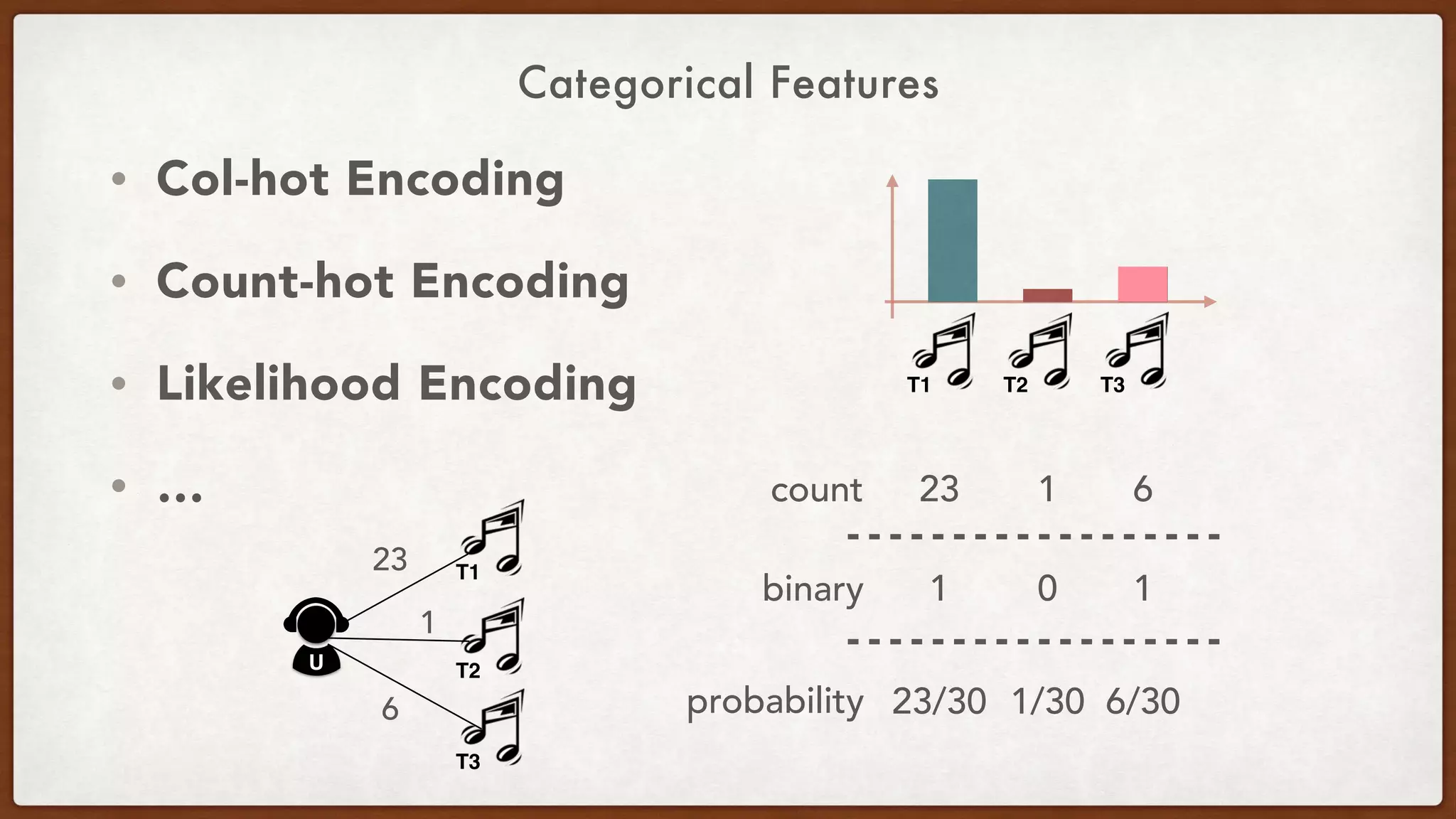
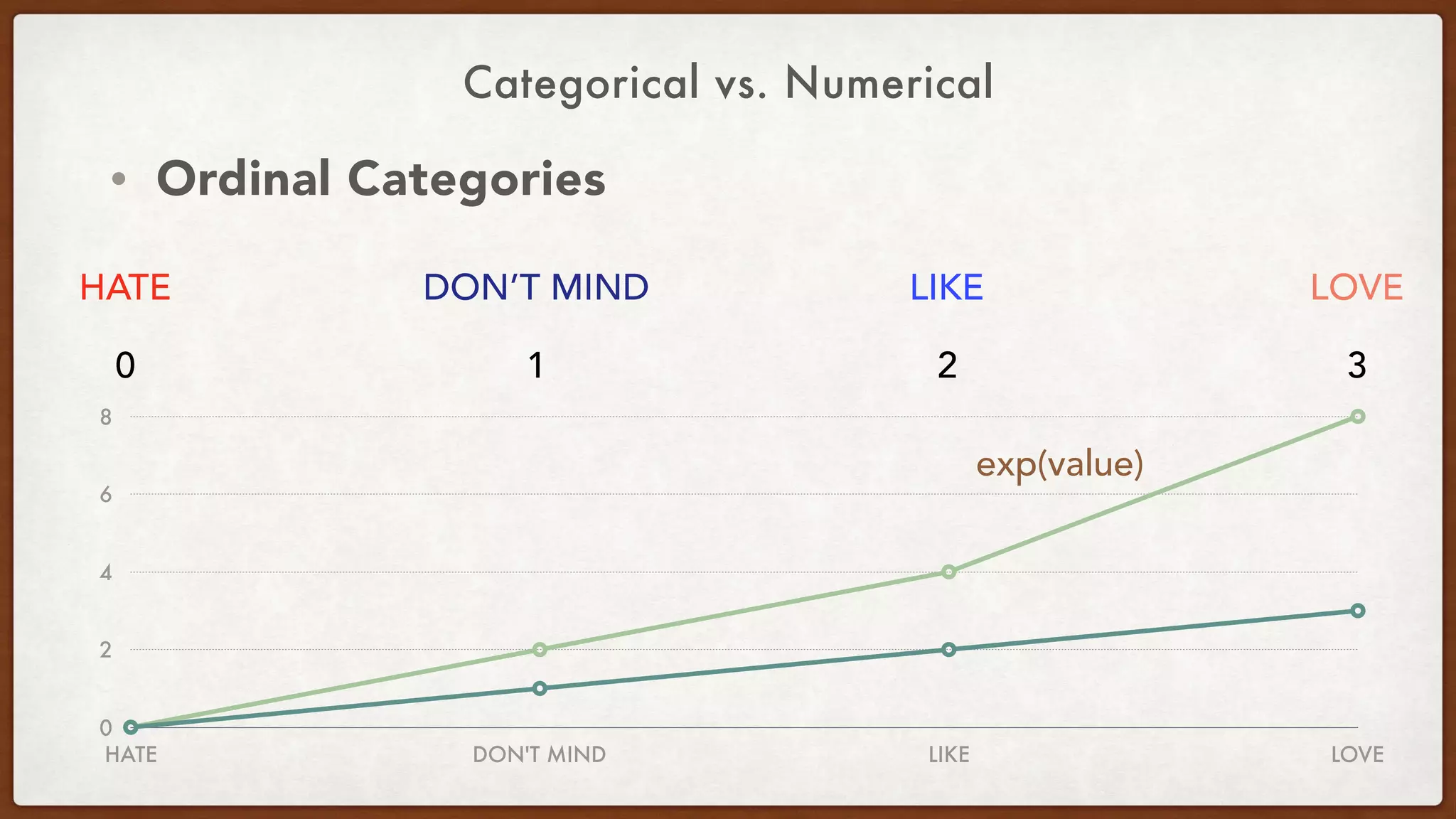
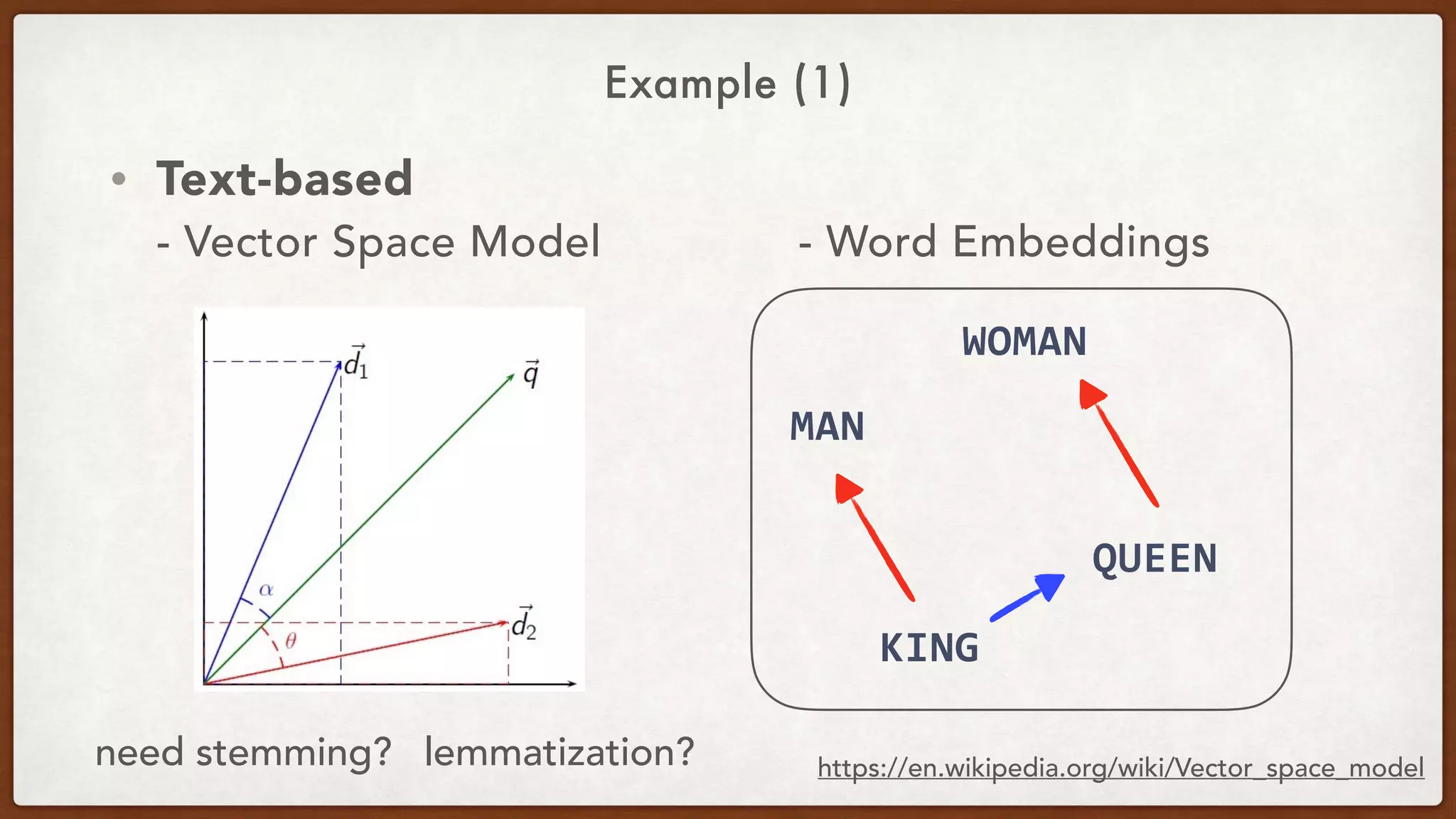
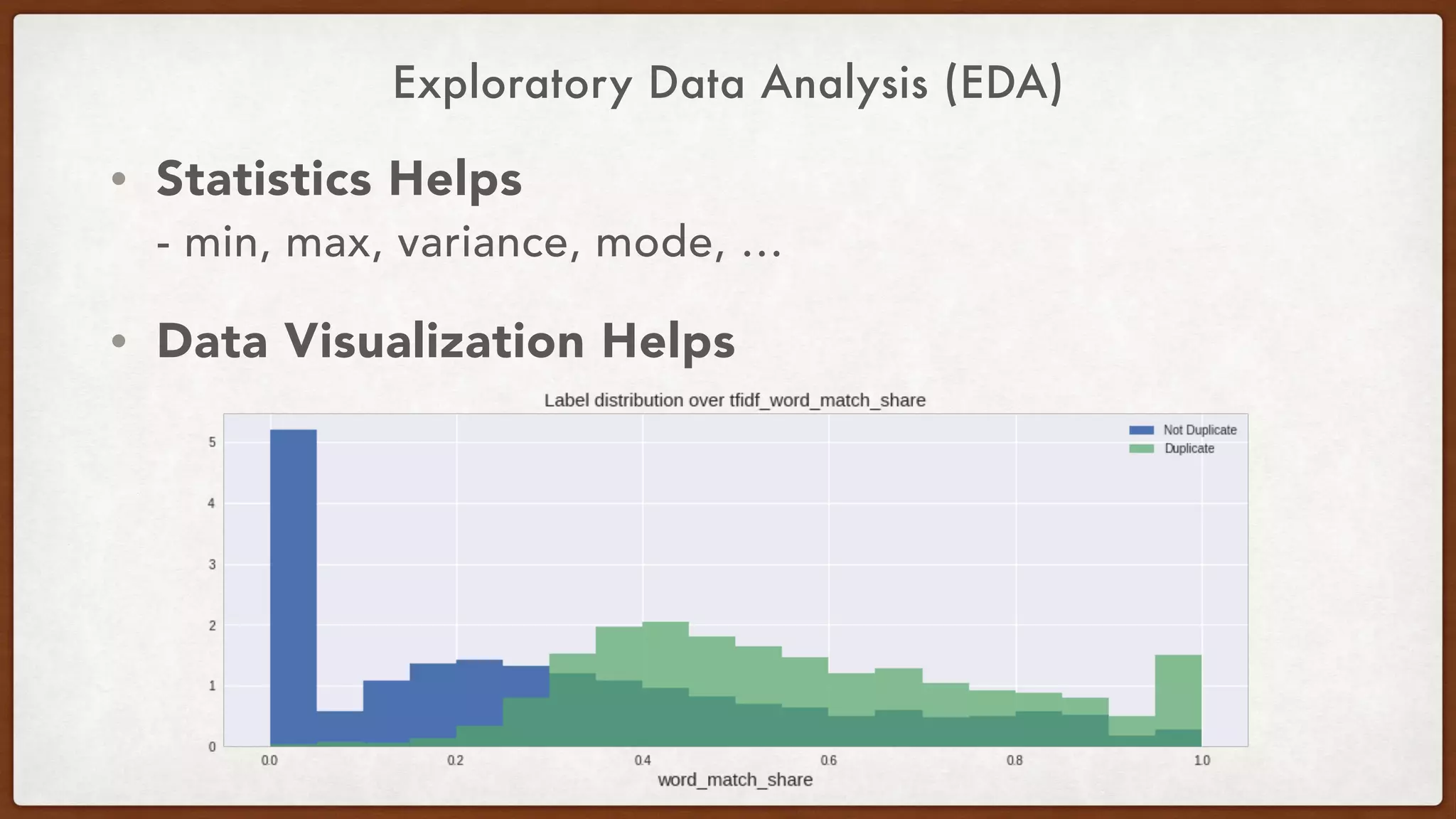
Downloaded 21 times














![Example (2)
Text
服務好、環境整潔 …
服務⼈人員笑容溫暖...
今天點了商業午餐...
segmentation
[服務] [好] [環境] [整潔]
[服務] [⼈人員] [笑容] [溫暖]
[今天] [點了] [商業午餐]
服務:1 好:1 環境:1 整潔:2
服務:1 笑容:1 溫暖:2
商業午餐:1filtering
Word
Embeddings?
dummy
variables
服務:2 好:1 環境:1 整潔:4
服務:2 笑容:1 溫暖:1
商業午餐:0.8
Advanced
Weighting?](https://image.slidesharecdn.com/cmkaggleshare-170703151102/75/MLDM-CM-Kaggle-Tips-26-2048.jpg)






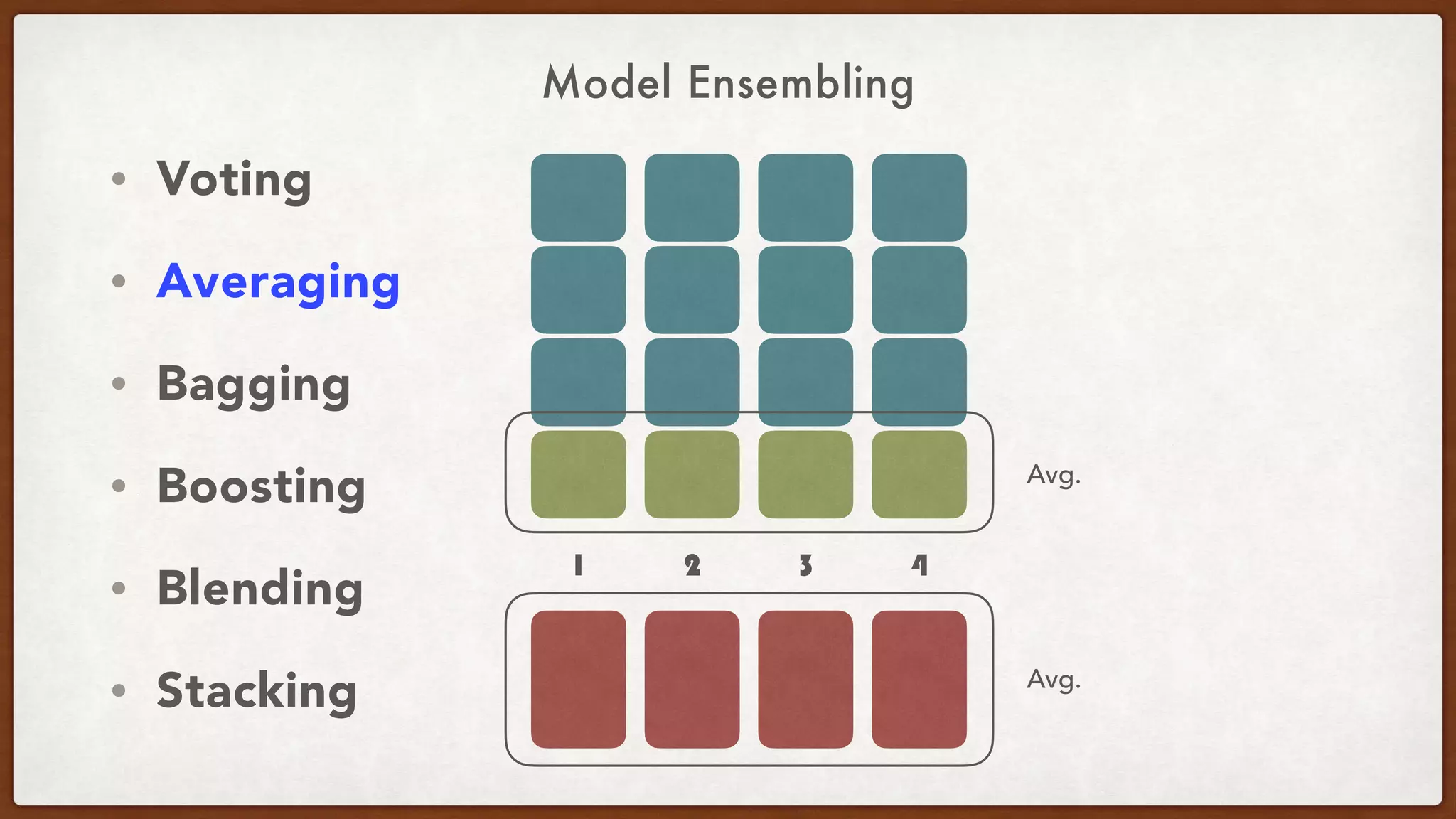
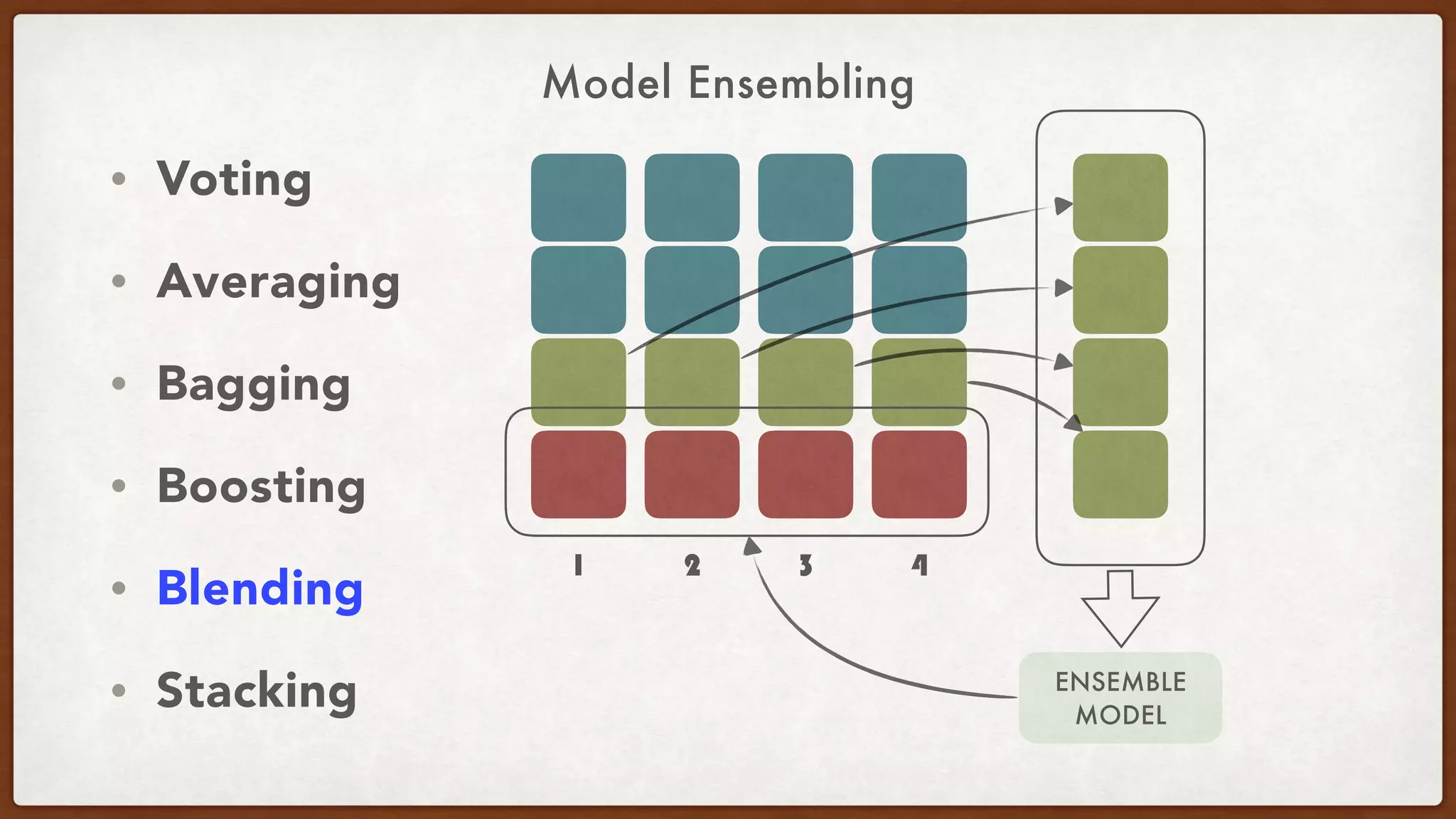
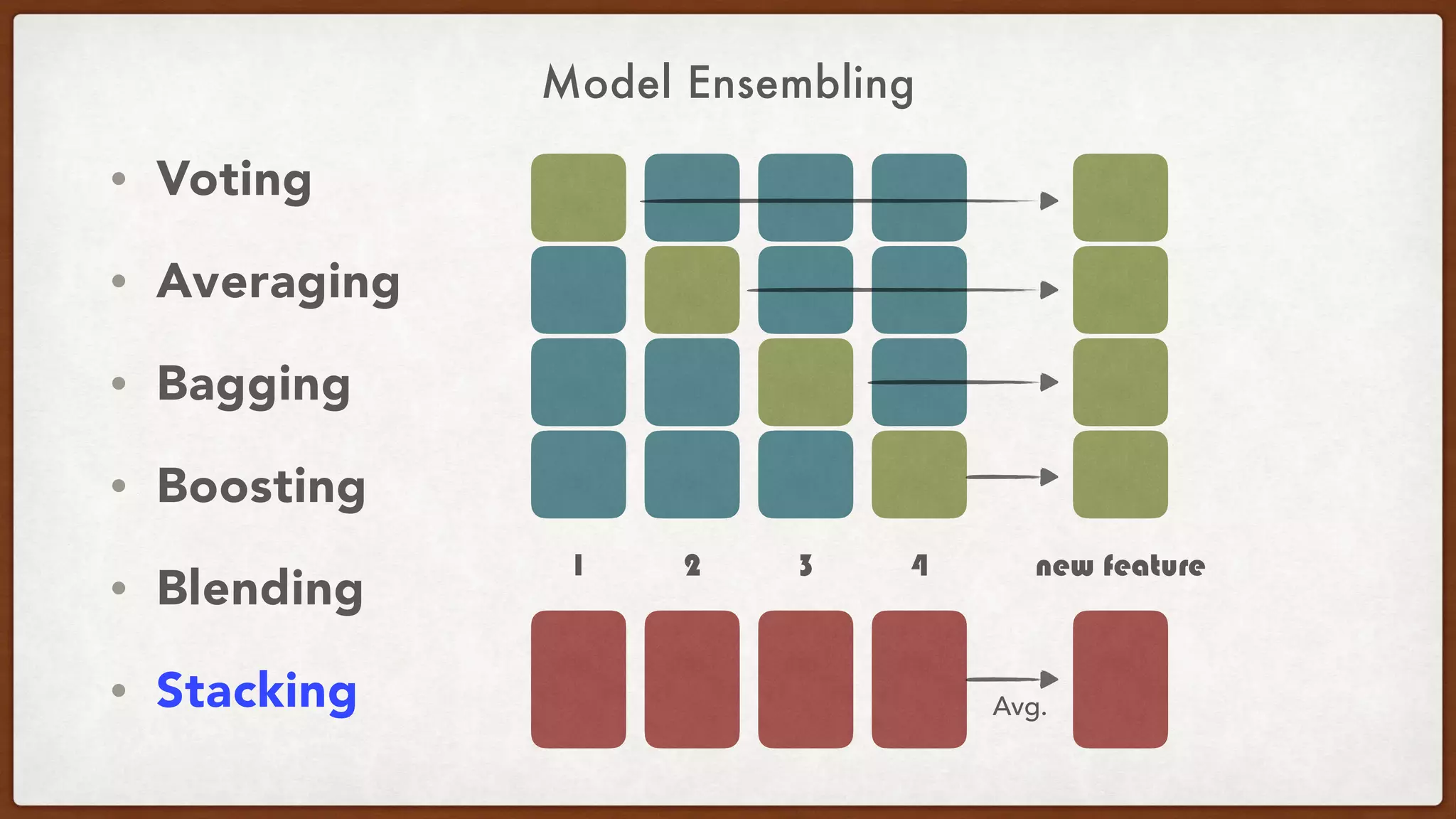


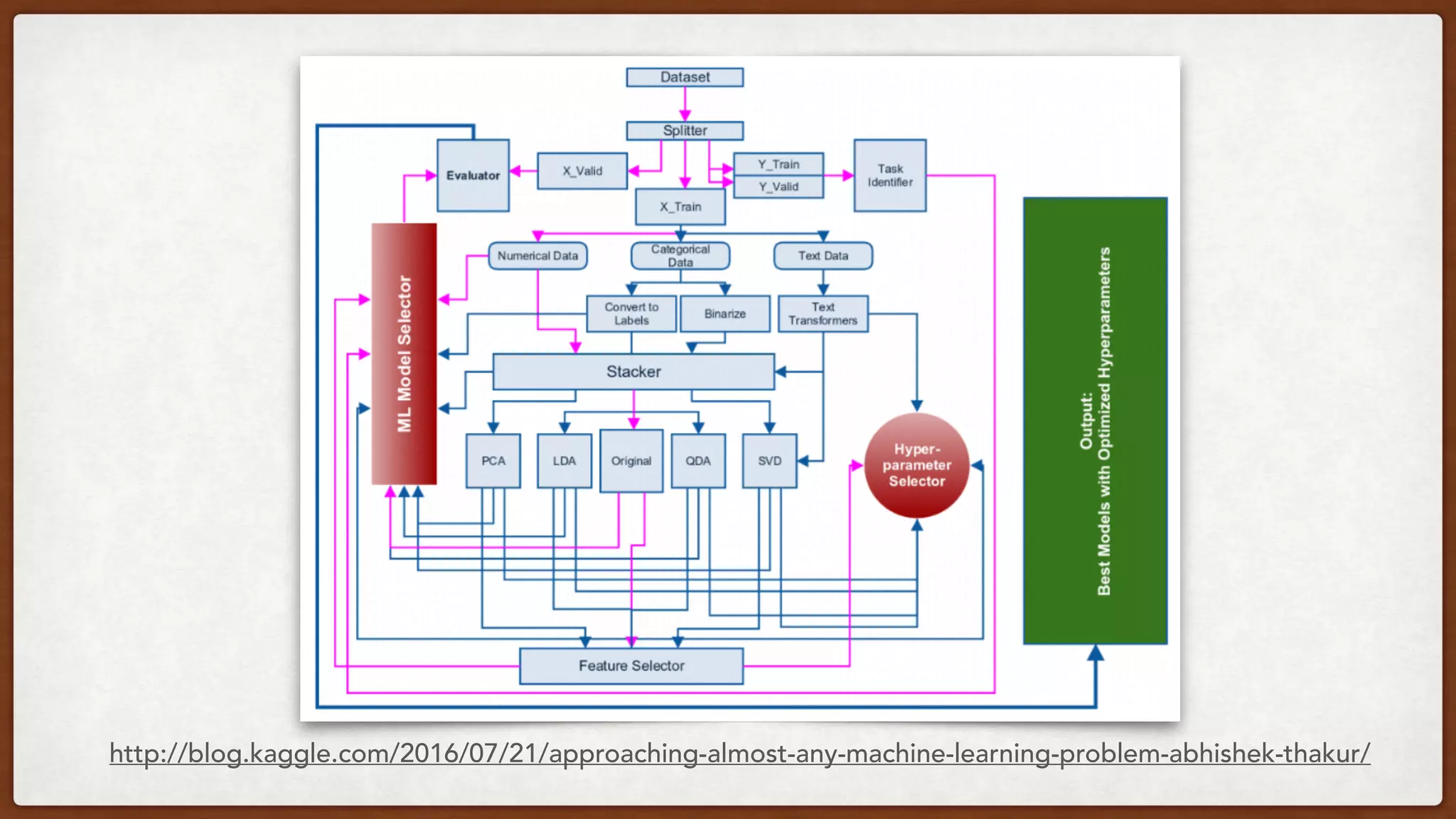



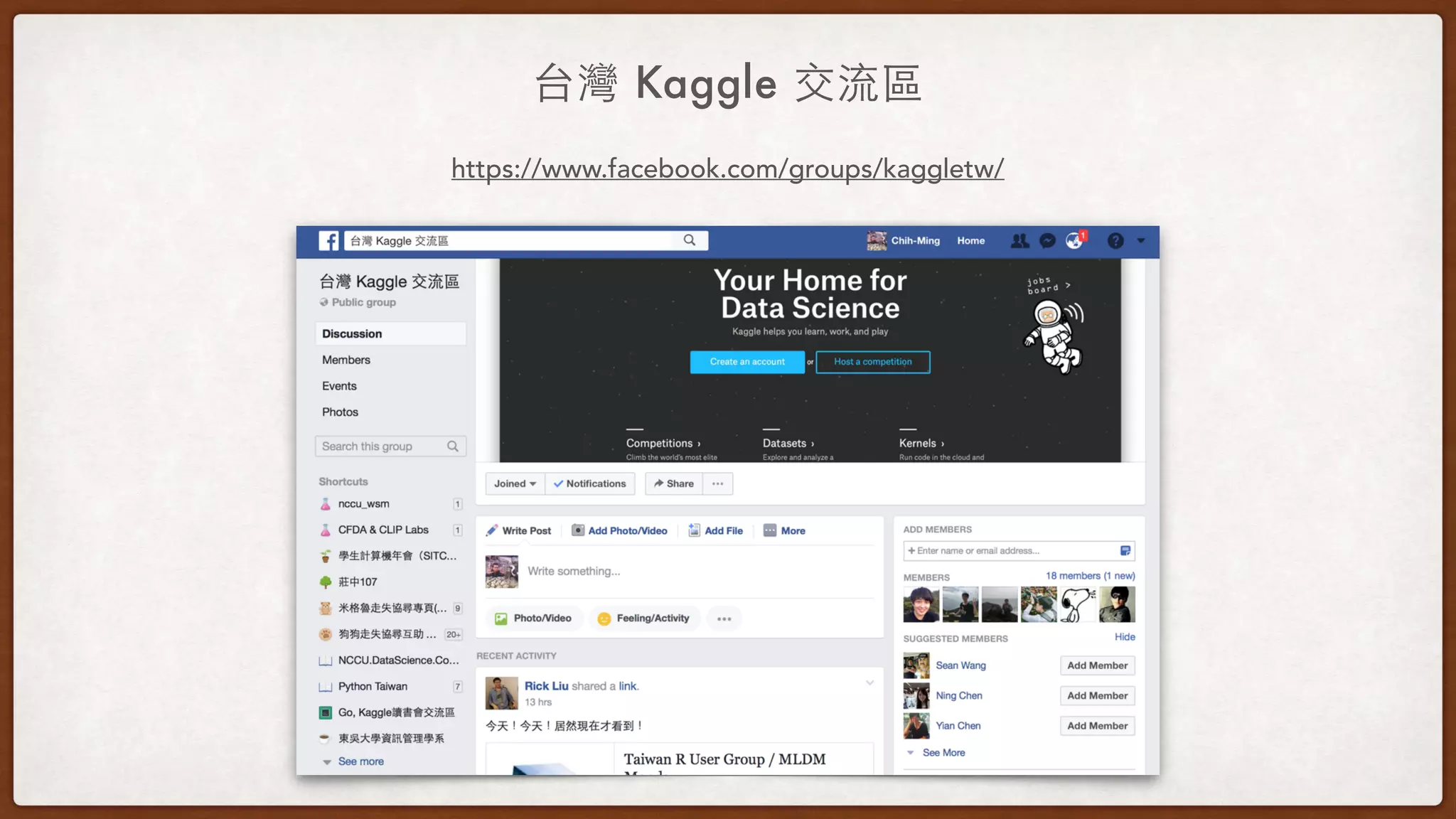
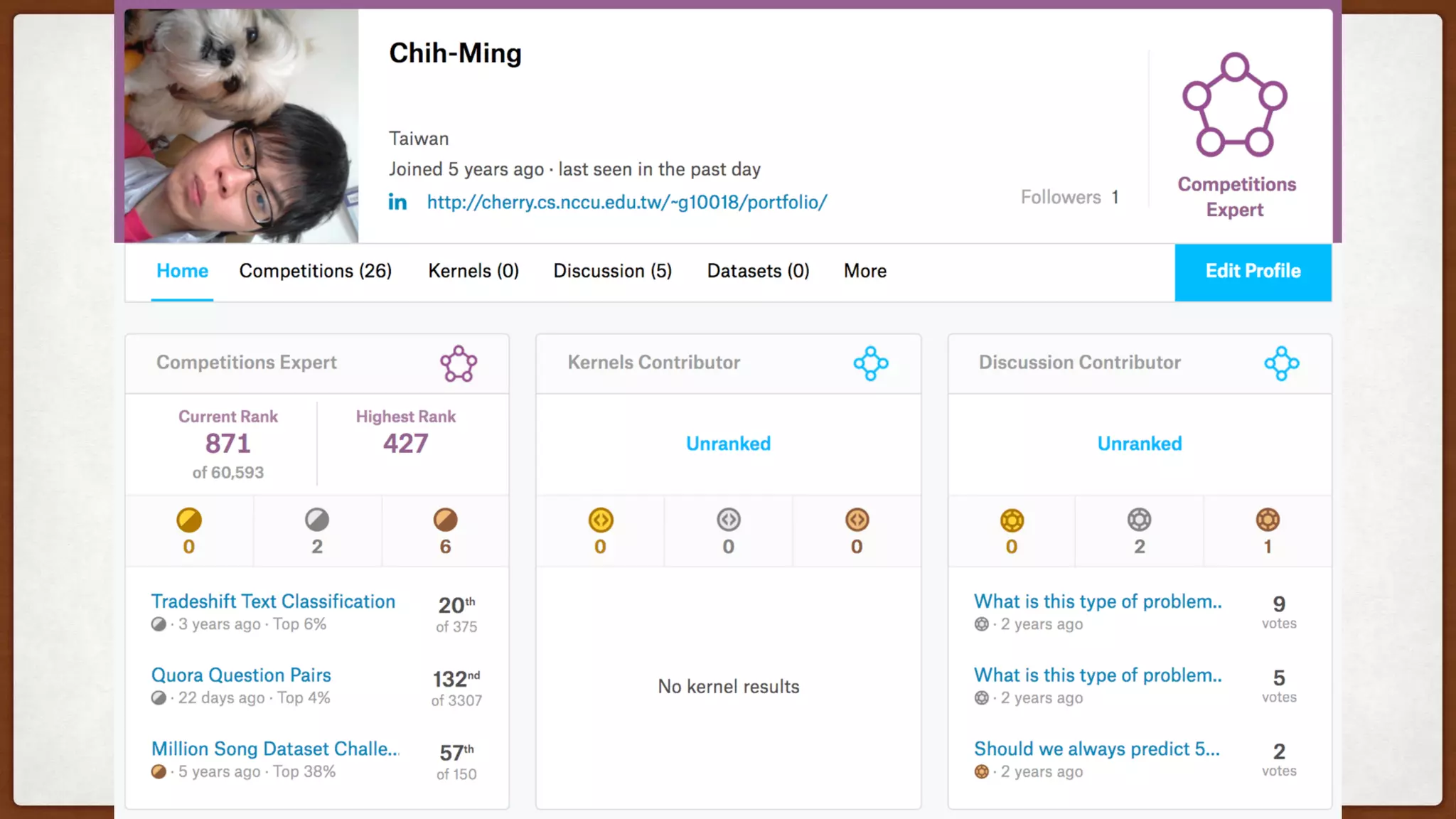
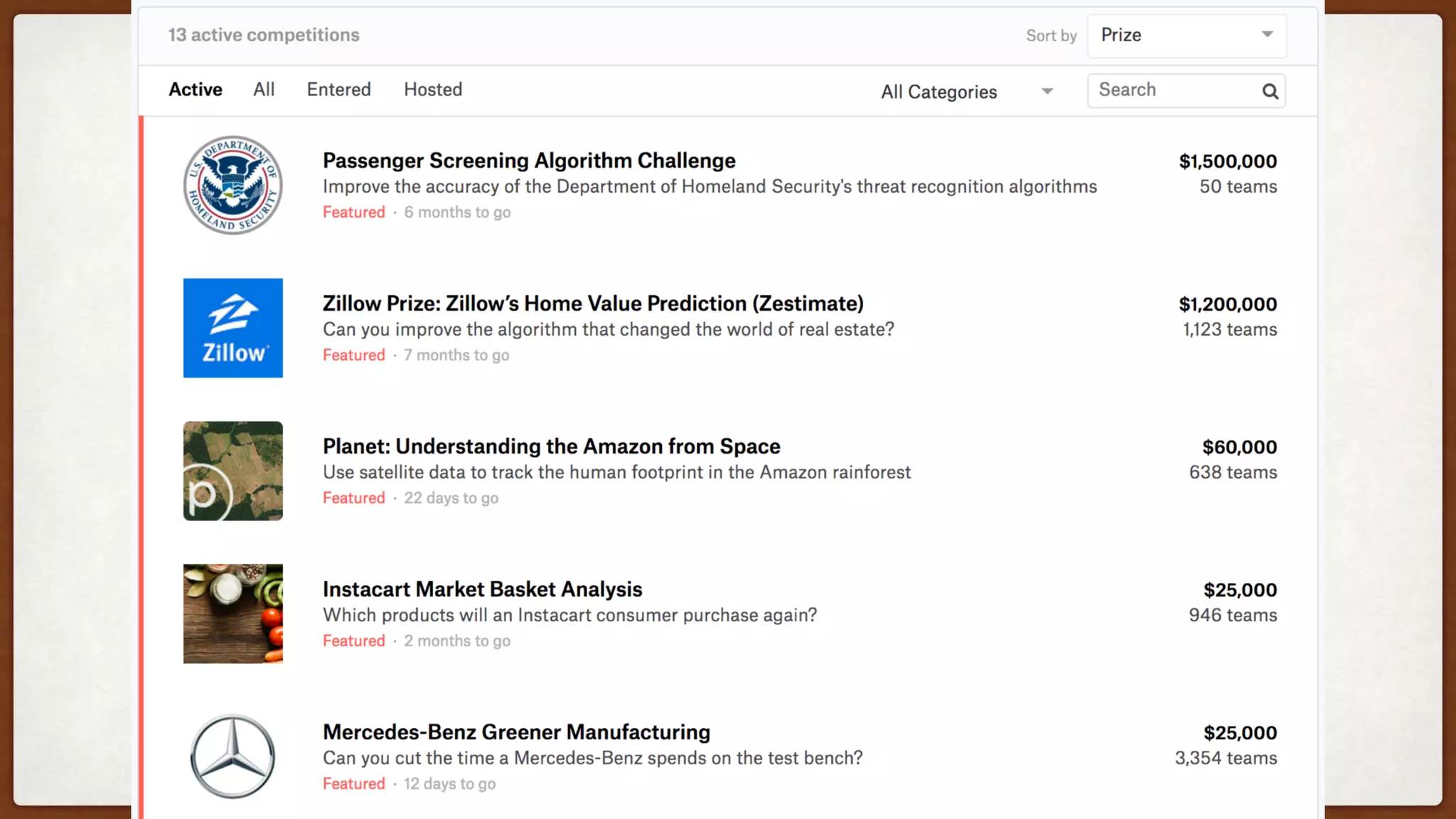
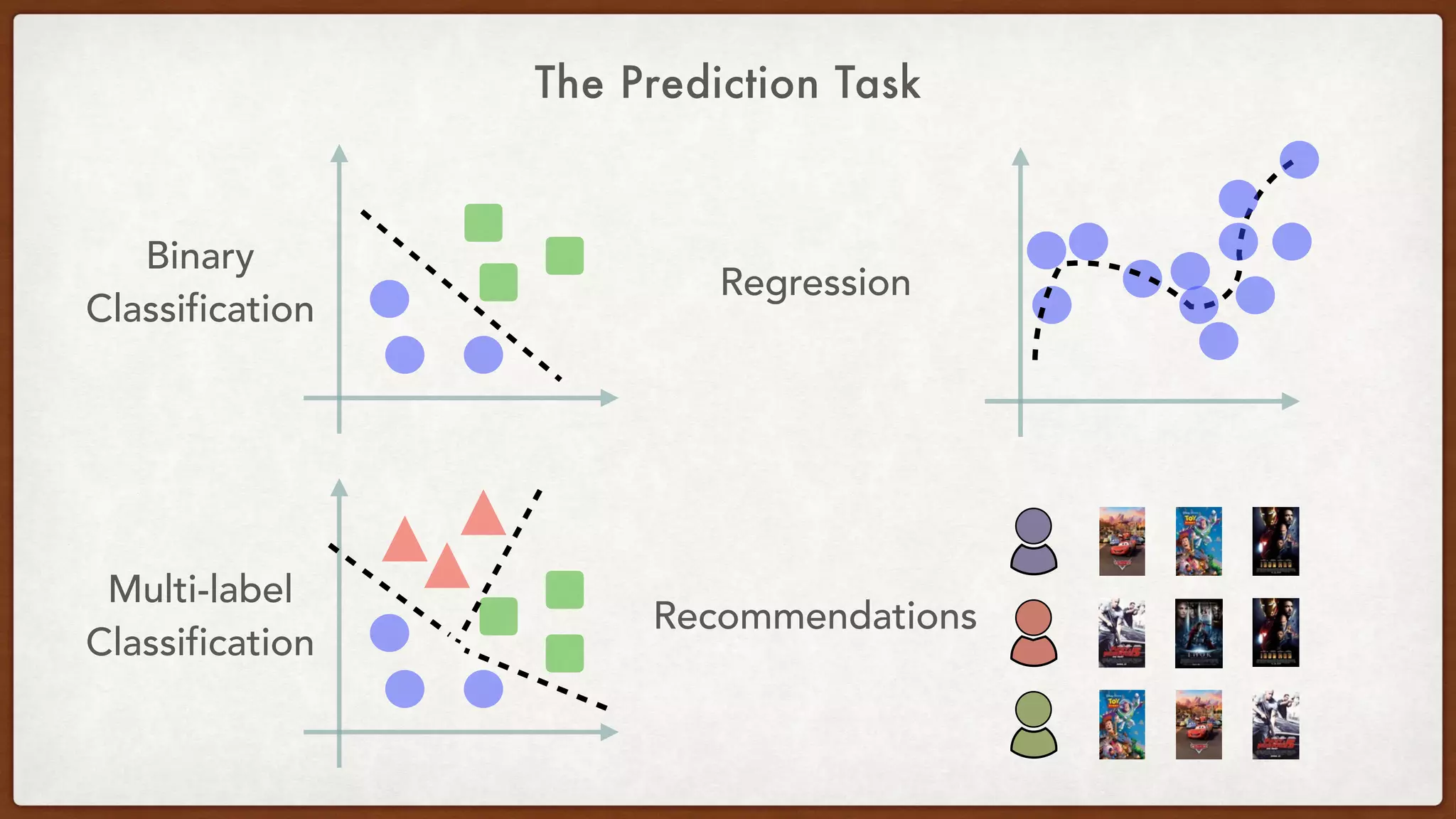
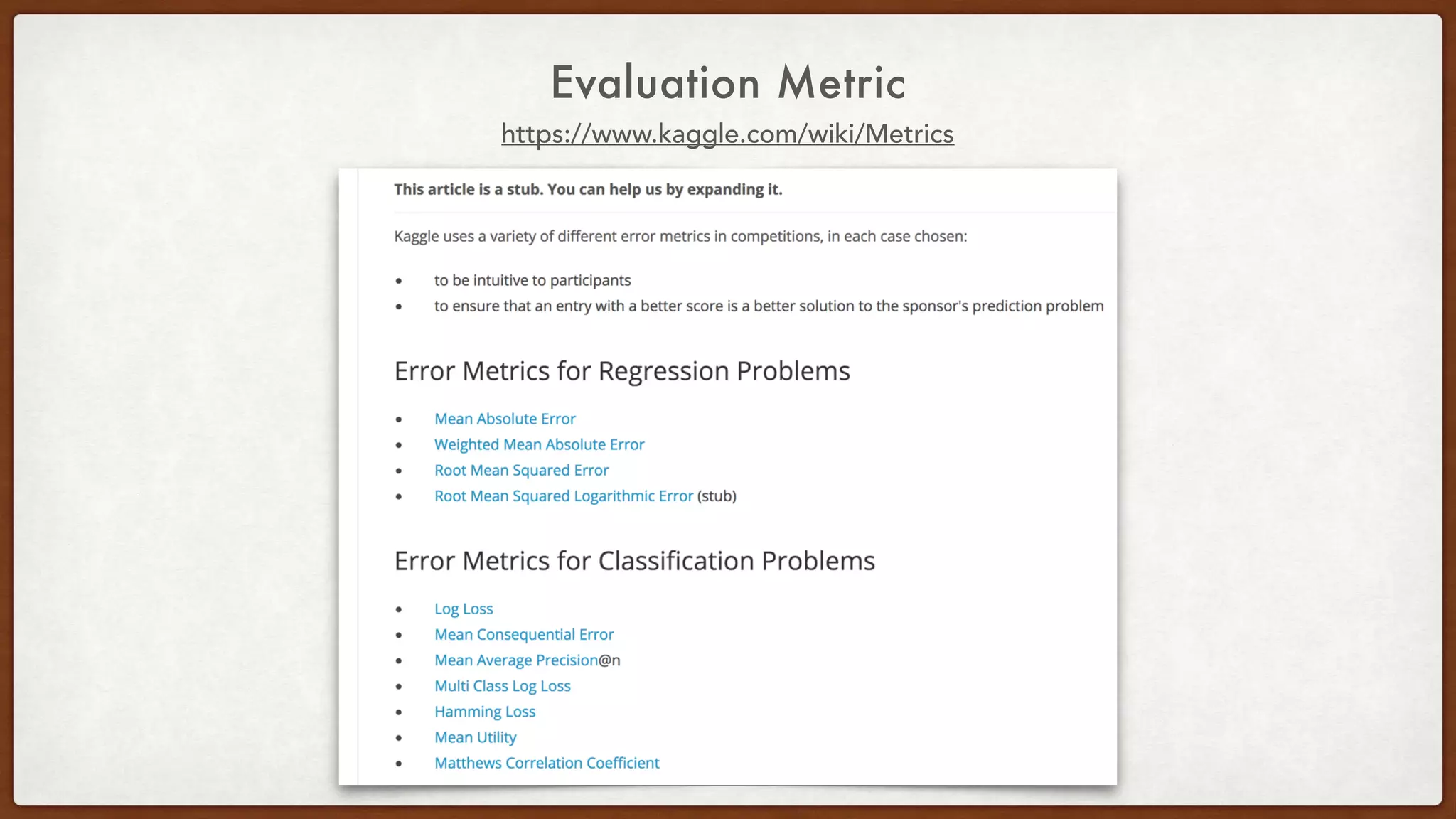
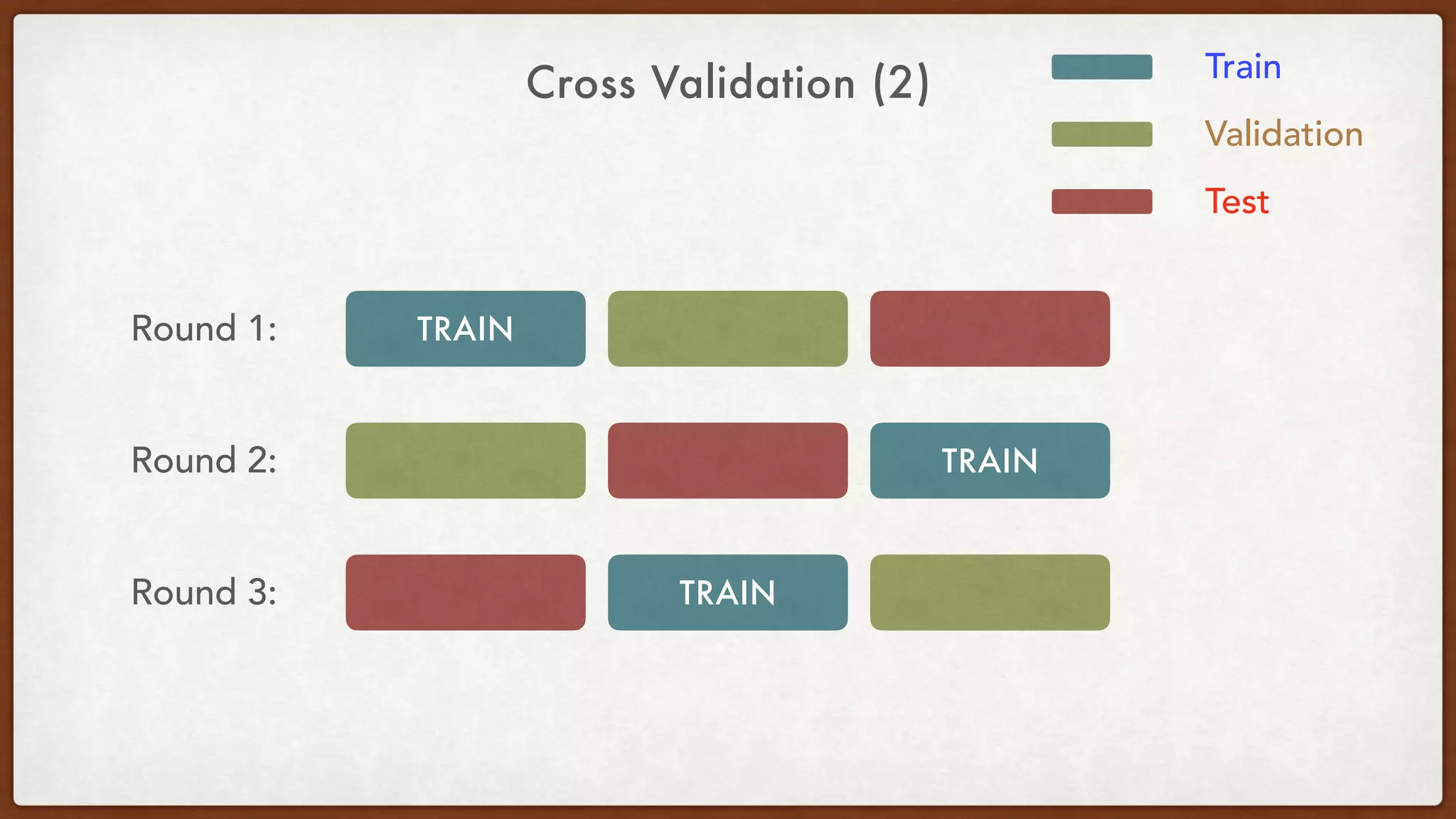
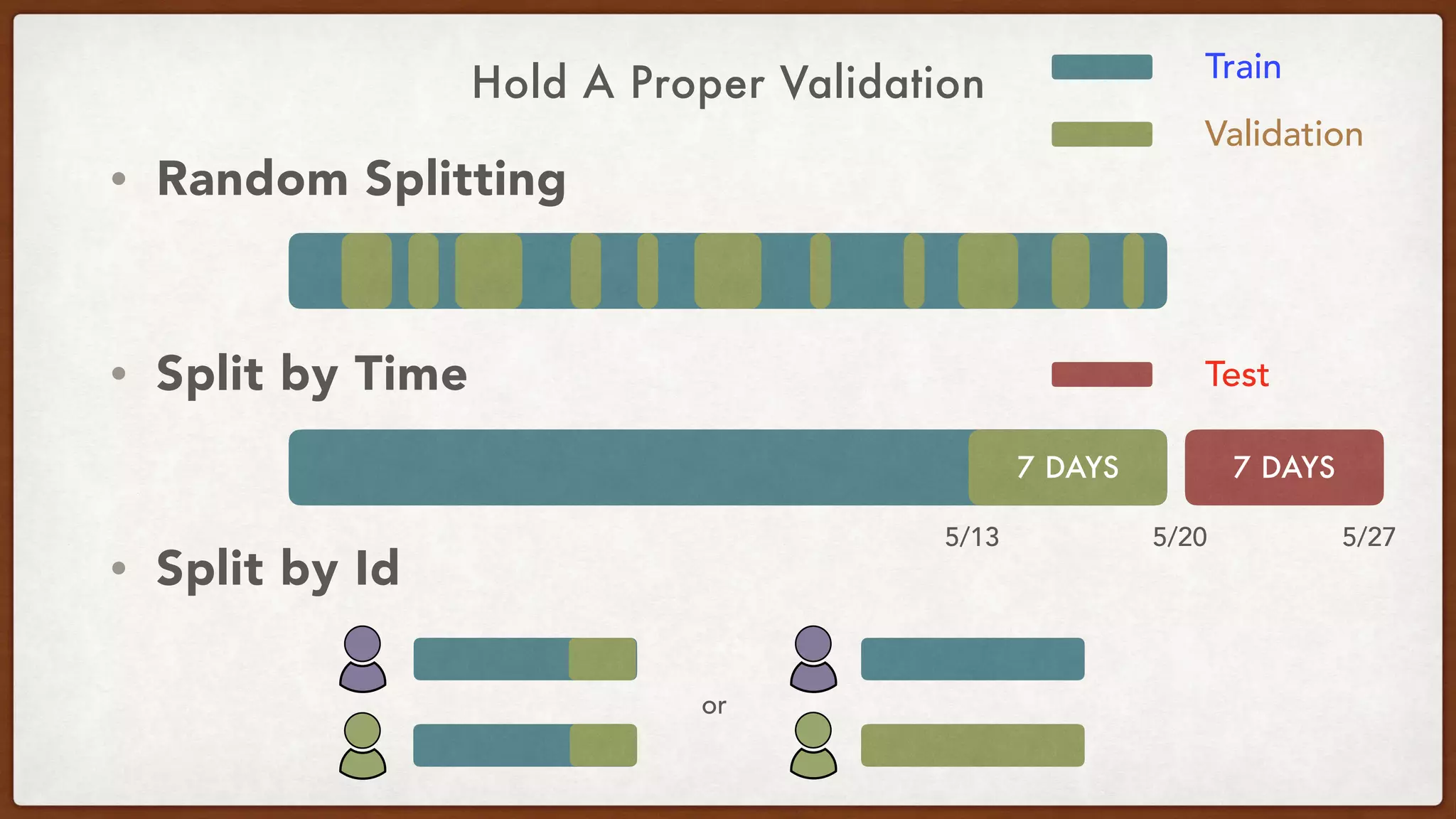
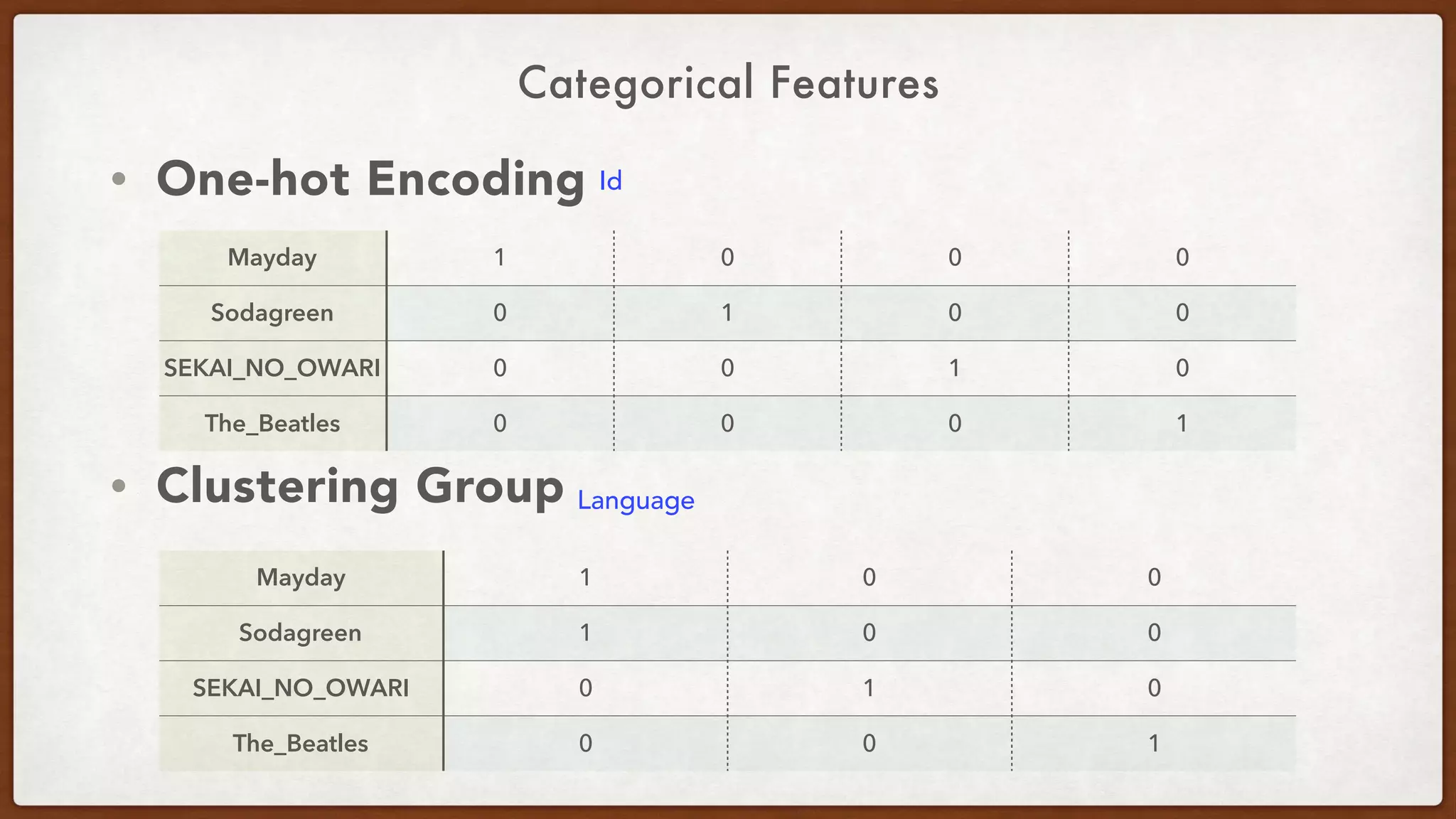
This document provides an overview of machine learning competitions on Kaggle and tips for participating. It begins with introducing the types of prediction tasks, including classification, regression, and recommendations. It then discusses important considerations like evaluation metrics, data size, and motivation for competing. The rest of the document offers advice on data preprocessing, feature engineering, model selection, ensembling techniques, and learning from other competitors. The overall goal is to understand the machine learning process and get better results by applying diverse models and proper validation.



































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)


