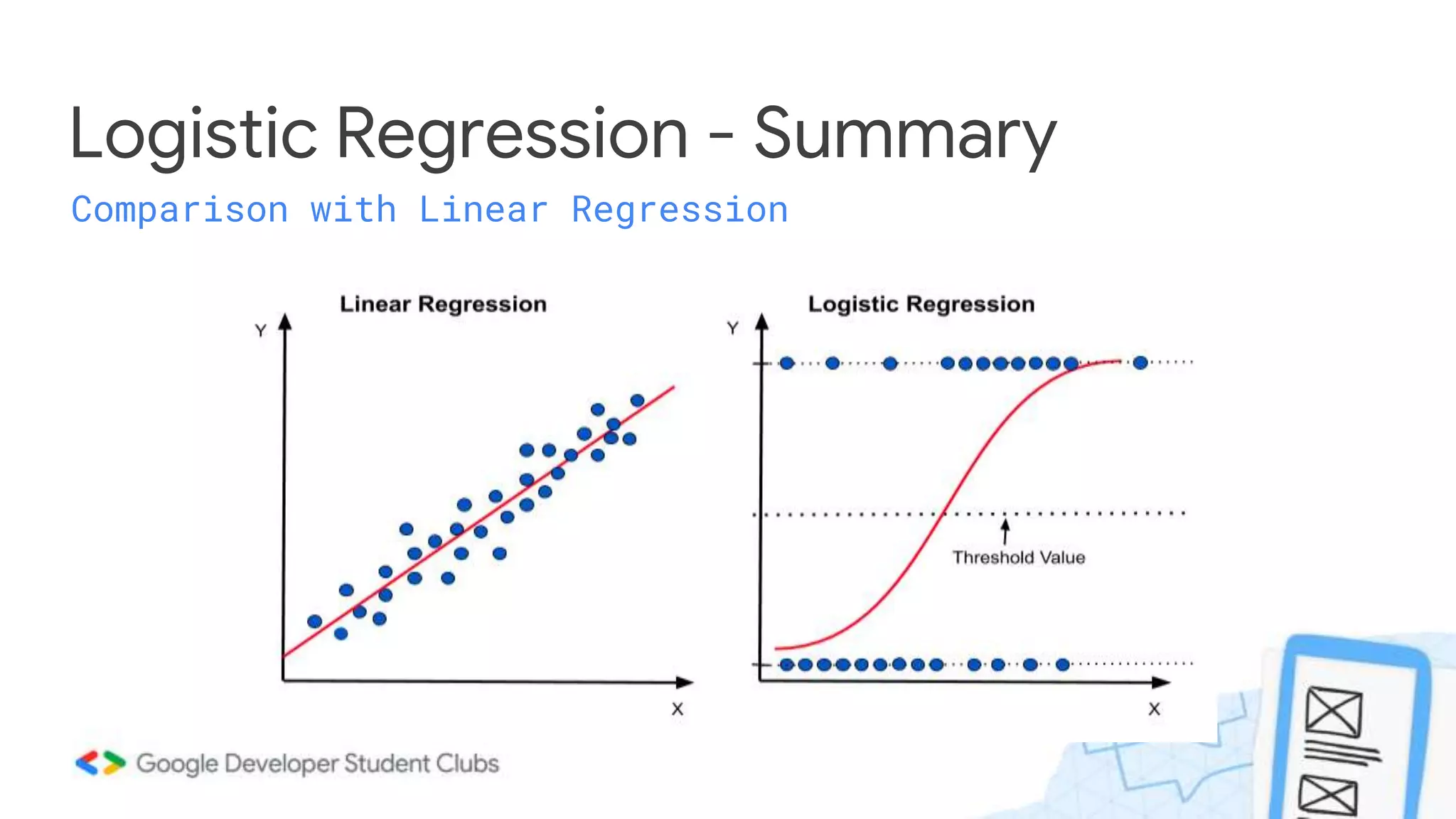
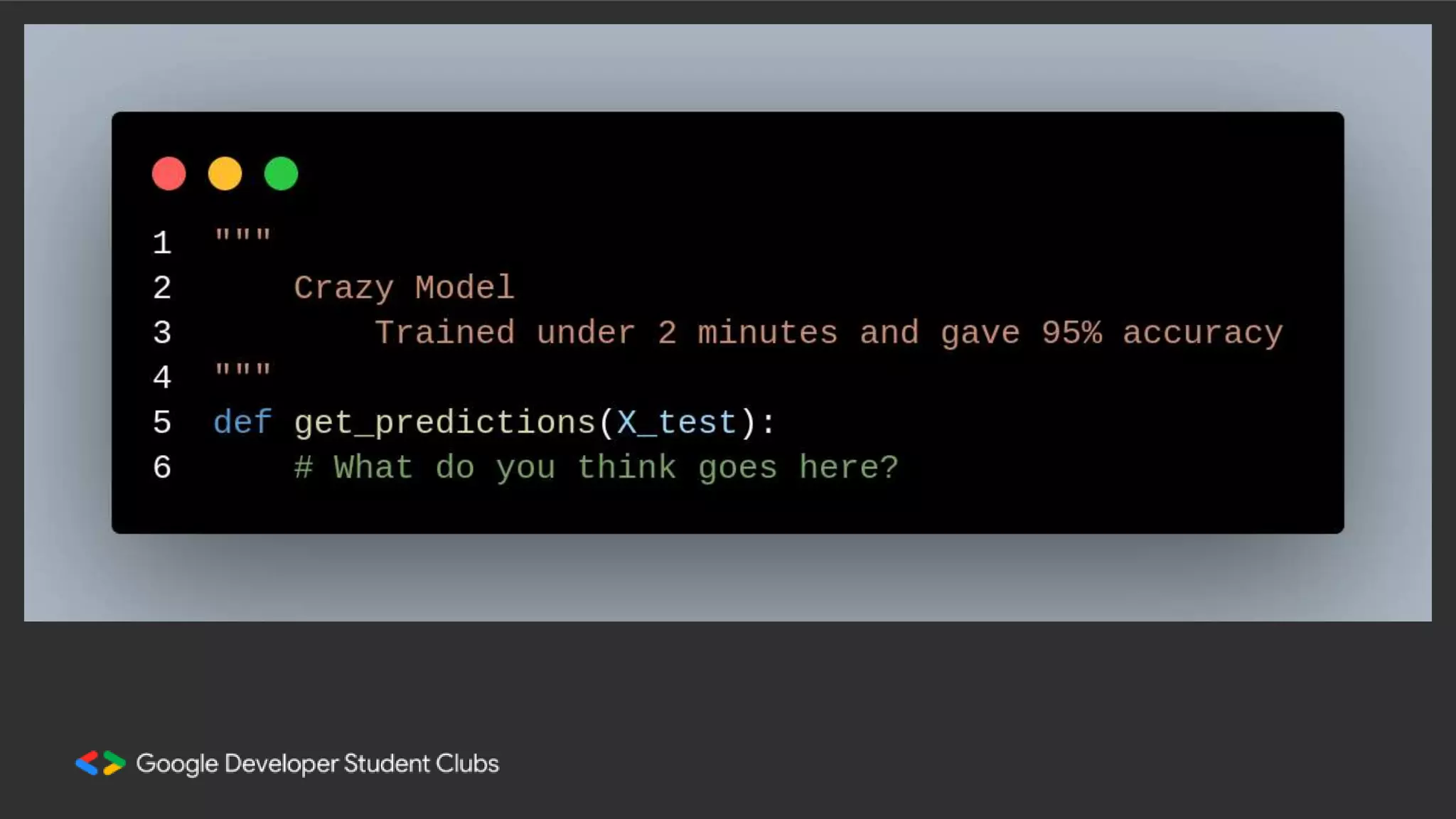
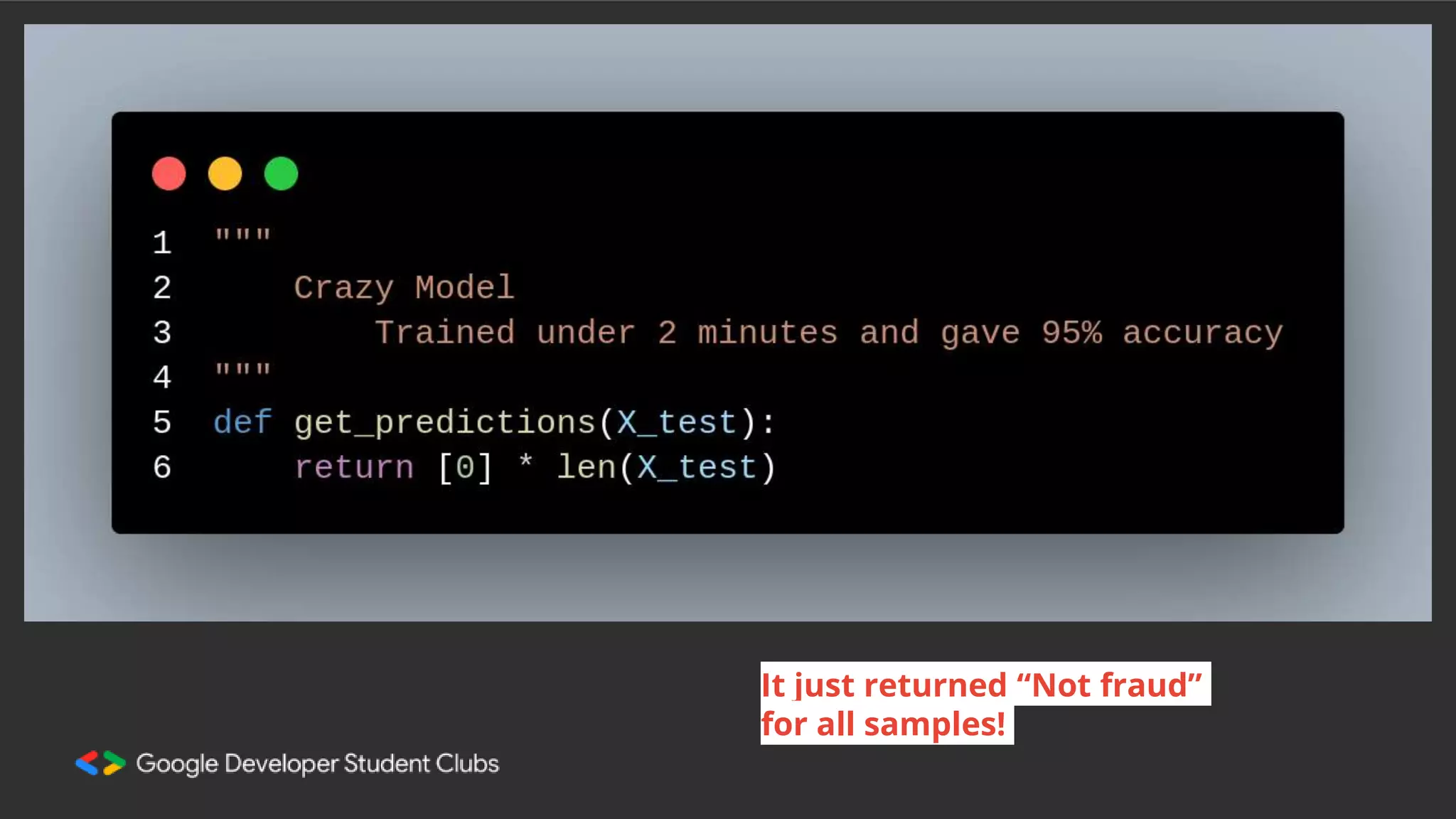
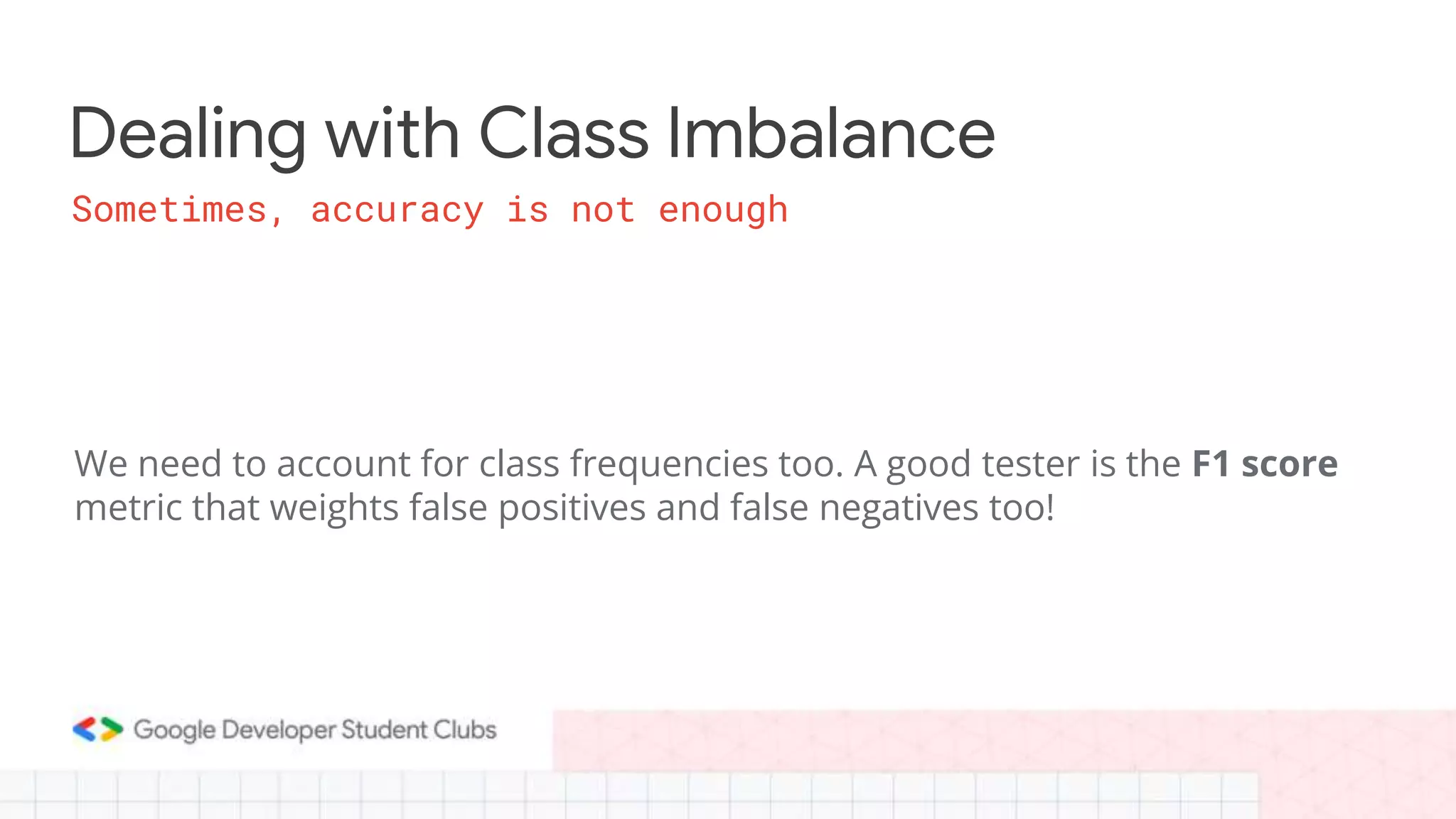
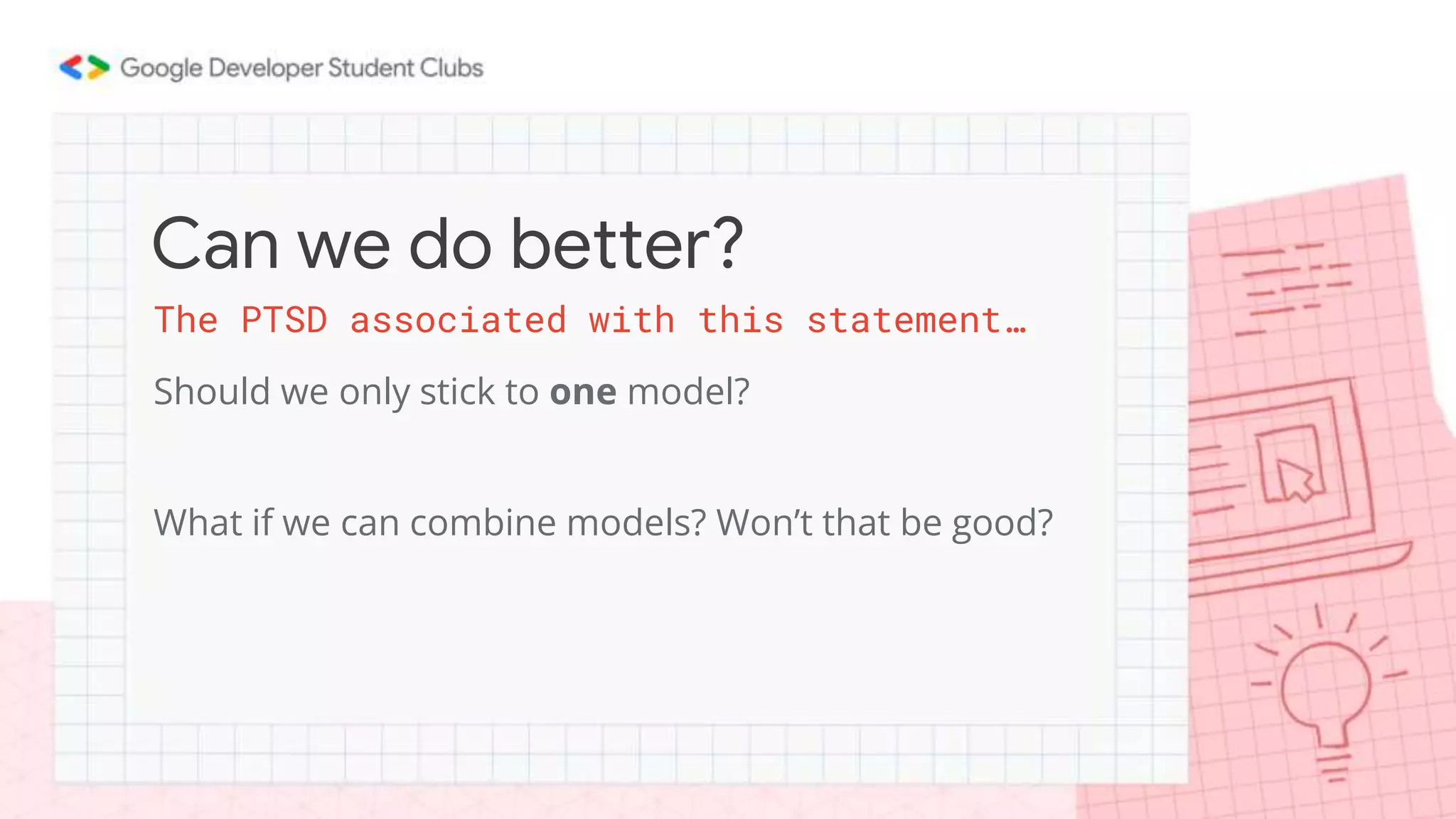
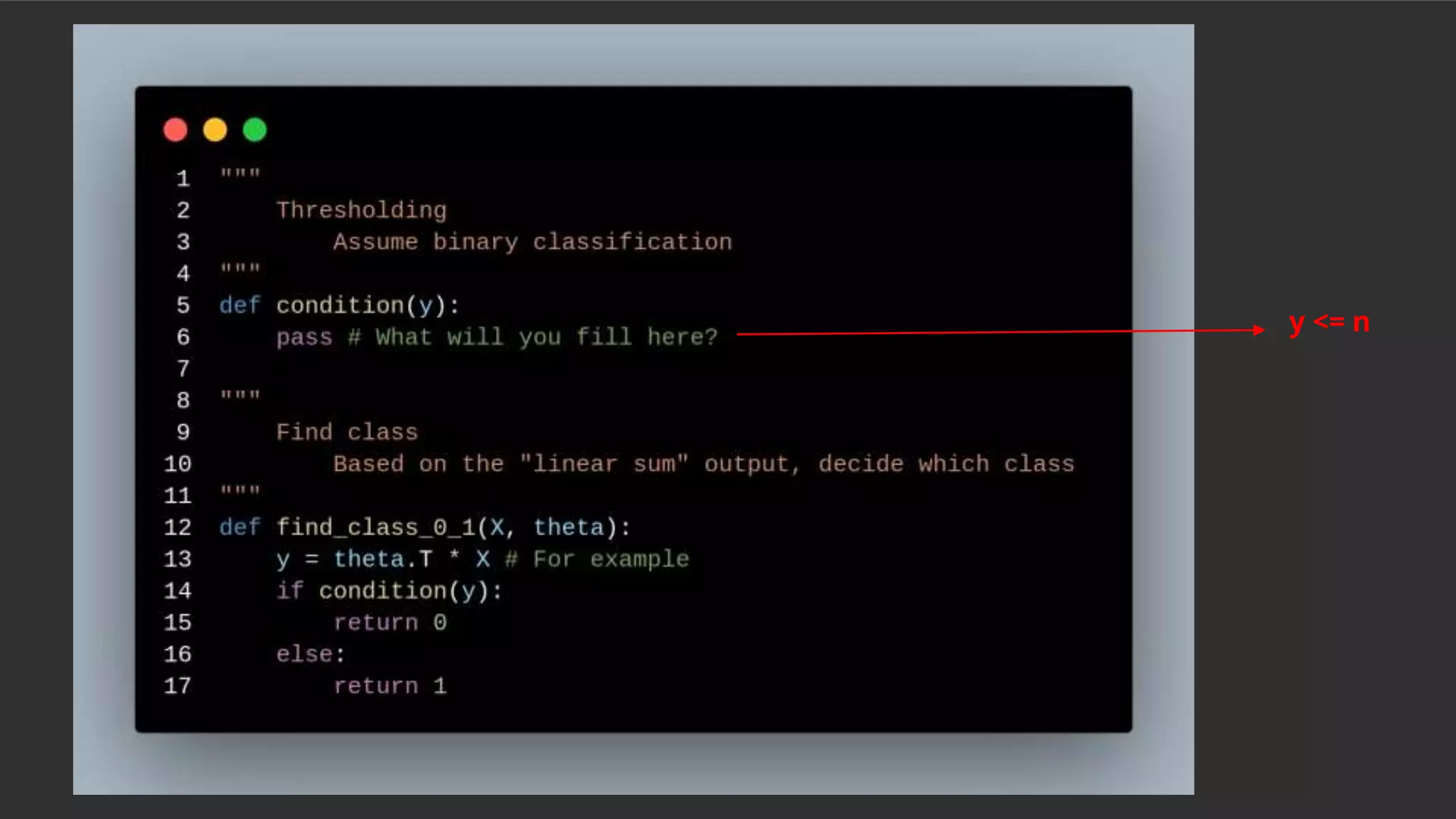
This document summarizes a session on classification models. It discusses classifying data by learning classification rules from labeled input data. Specifically, it covers k-nearest neighbors classification, where the target point is assigned the majority class of its k nearest neighbors. It also discusses extending linear regression to classification by using it to generate real-valued outputs, then thresholding those values to classify instances into classes 0 or 1. However, it notes that logistic regression is a better approach, using a sigmoid function to convert real-valued outputs to a probability between 0 and 1 before thresholding for classification. The document highlights key considerations for classification like dealing with multiple classes and class imbalance. It also discusses evaluating classifiers, ensemble methods, and overfitting/under













![Do you think it's easier to work with
(threshold) any value in R or a smaller
range say [0,1]?
ⓘ Start presenting to display the poll results on this slide.](https://image.slidesharecdn.com/mlstudyjams-session3-221030105530-cbcc080d/75/ML-Study-Jams-Session-3-pptx-19-2048.jpg)




![How do we generate h(θ) though?
How does one convert a real number into a range from [0,1]?](https://image.slidesharecdn.com/mlstudyjams-session3-221030105530-cbcc080d/75/ML-Study-Jams-Session-3-pptx-24-2048.jpg)