Download as PDF, PPTX









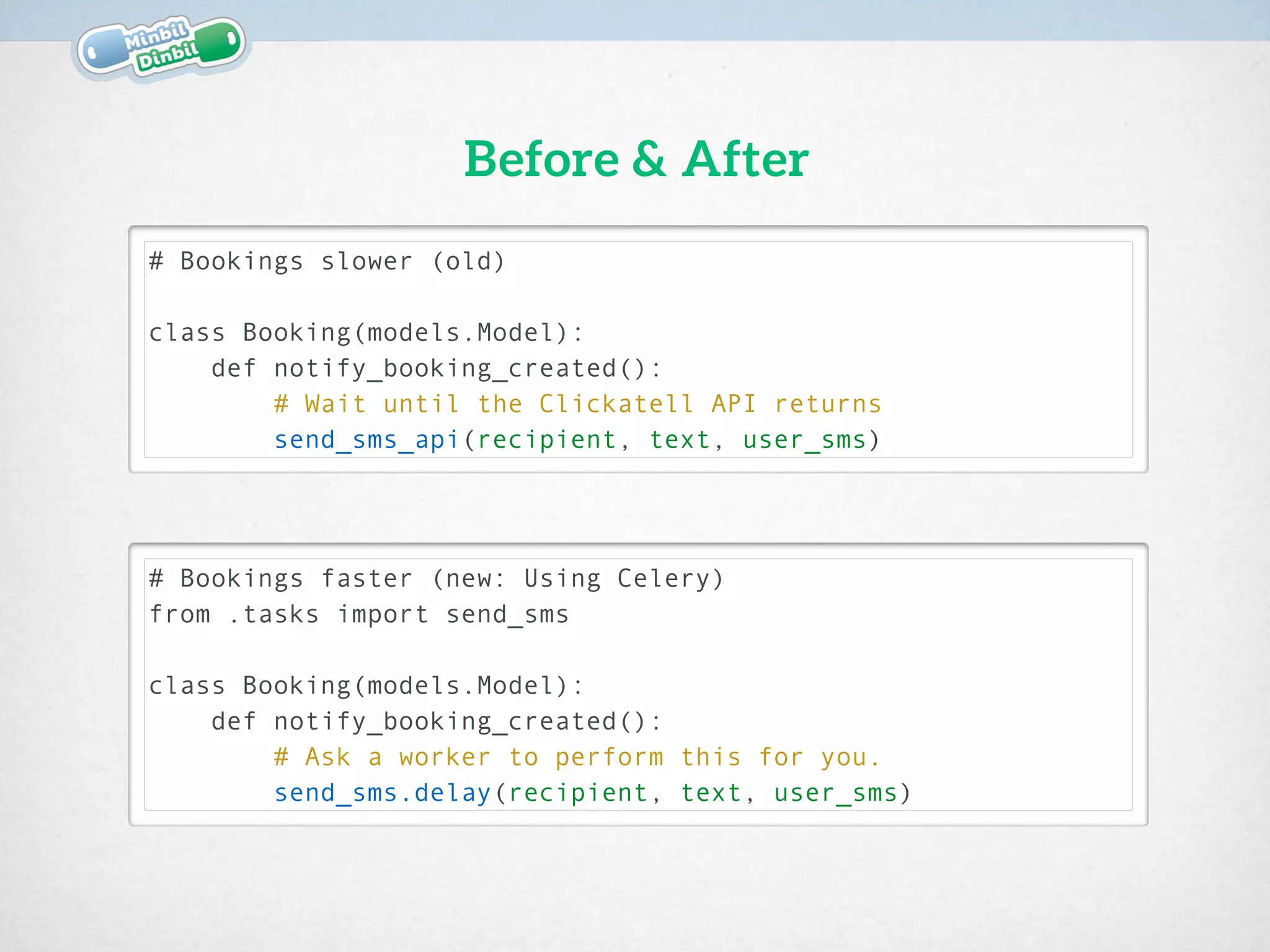
![# notifications/tasks.py
# django-celery>=3.0.23,<3.0.99
@celery.task(default_retry_delay=60, ignore_result=False)
def send_sms(recipient, text, user_sms, **kwargs):
"This task will send an sms message.”
try:
send_sms_api(recipient, text, user_sms)
except Exception, e:
send_sms.retry(
args=[recipient, text, user_sms],
countdown=60, max_retries=5,
exc=e, kwargs=kwargs
)
Retry in case of error.
Using the CeleryTask method .retry() we can perform the task again,
in case of failure: In this way even if the process is detached form the
main thread, we are sure that we will perform it even if it fails](https://image.slidesharecdn.com/20150209mbdbdjangospeedtricks-150209144127-conversion-gate02/75/MinbilDinbil-Django-Speed-Tricks-11-2048.jpg)





![{
"uwsgi": {
// #[…]
"logformat": "[%(ltime)][%(vszM) MB] %(method) %(status) - %(uri)",
"workers": 3,
"max-worker-lifetime": 300,
"max-requests": 100,
"reload-on-as": 512,
"reload-on-rss": 384,
}
}
uWSGI Configuration
The configuration below will set requests, time and memory limit:
in case the process/worker will be reloaded or restarted gracefully.
In this way you will avoid servers hungry of resources.](https://image.slidesharecdn.com/20150209mbdbdjangospeedtricks-150209144127-conversion-gate02/75/MinbilDinbil-Django-Speed-Tricks-18-2048.jpg)


![# settings.py
MIDDLEWARE_CLASSES += [
'smart_cache_control.middleware.SmartCacheControlMiddleware'
]
SCC_CUSTOM_URL_CACHE = (
(r'/api/search$', 'public', 60*30),
)
SCC_MAX_AGE_PUBLIC = 60*60*24*7 # 7 Days
SCC_MAX_AGE_PRIVATE = 0
Configure django-smartcc middleware
This django middleware will force cache headers if we define some
rules. In the following code the /api/search is always considered as
public and cached for a maximum of 1800 seconds (30 minutes).
$ pip install -U django-smartcc](https://image.slidesharecdn.com/20150209mbdbdjangospeedtricks-150209144127-conversion-gate02/75/MinbilDinbil-Django-Speed-Tricks-21-2048.jpg)




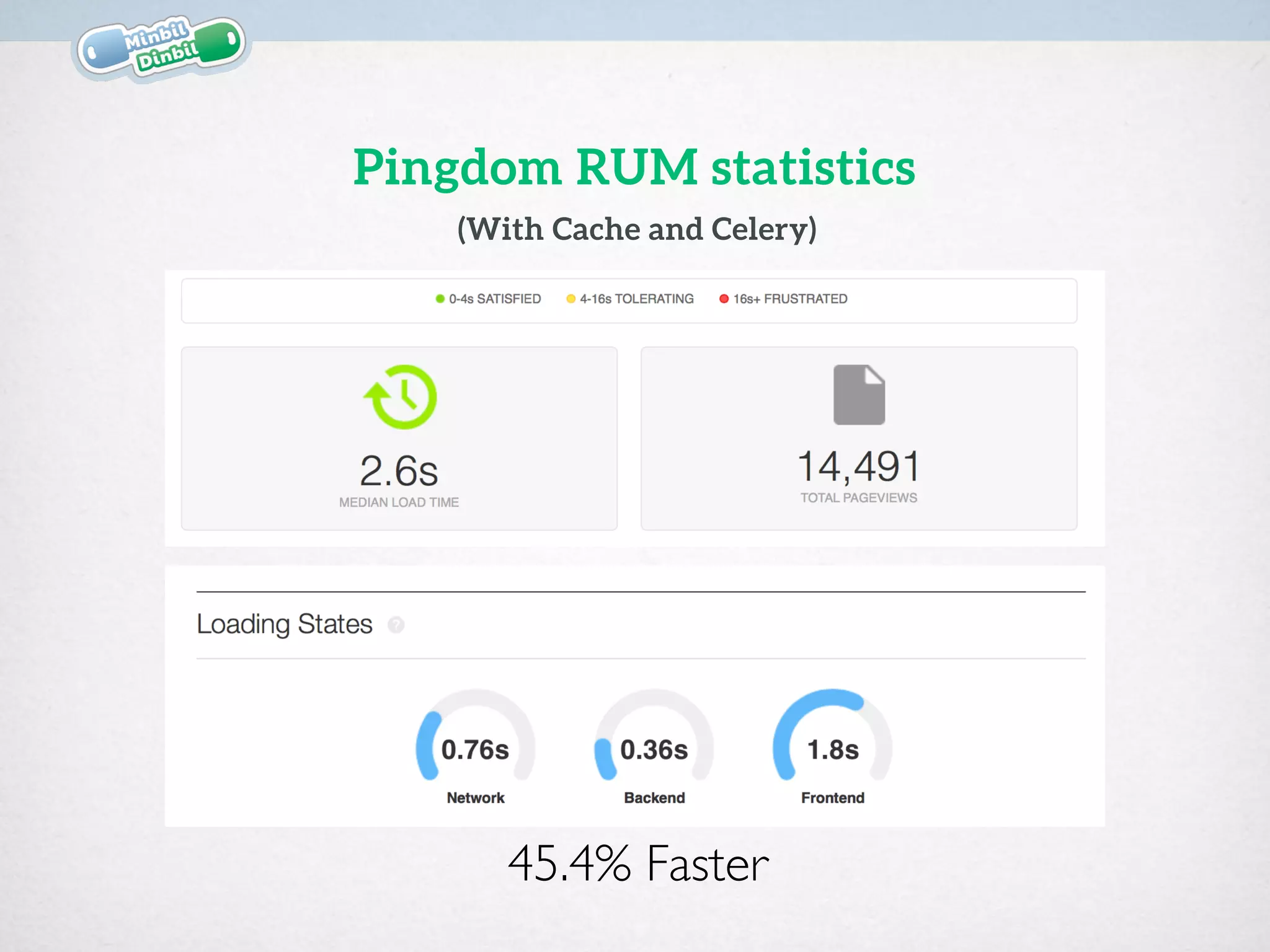




Lorenzo Setale presented strategies at Django Meetup #9 to enhance performance in a peer-to-peer car-sharing service, minbildinbil.dk, using technologies like Nginx, uWSGI, Celery, and caching. Key approaches included implementing asynchronous tasks with Celery for notifications, smart load balancing with Nginx, and extensive caching techniques to optimize response times. The session highlighted the importance of efficient configuration and middleware to manage resources and improve the speed of the application.
















![Let Grunt do the work, focus on the fun! [Open Web Camp 2013]](https://cdn.slidesharecdn.com/ss_thumbnails/2013-gruntjs-openwebcamp-130715113721-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)















































