Downloaded 24 times





![6
Algorithm 1
Simple C code for matrix in-place transposition:
for ( i=0 ; i < N ; i++) {
for ( j = i+1; j < N ; j++ ) {
tmp = A[i][j];
A[i][j] = A[j][i];
A[j][i] = tmp;
}
}](https://image.slidesharecdn.com/matrix-transposition-140405085008-phpapp01/75/Matrix-transposition-6-2048.jpg)




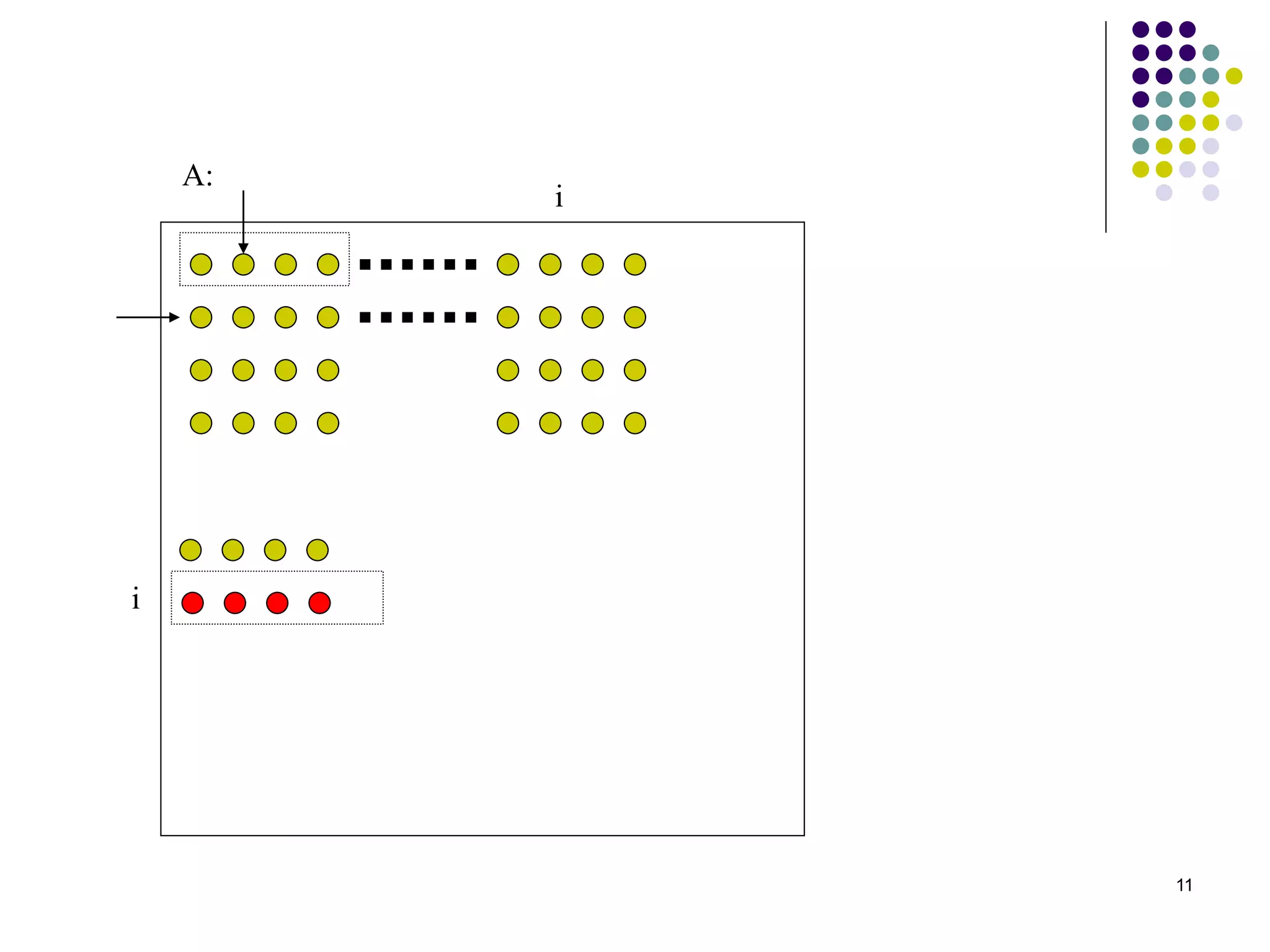
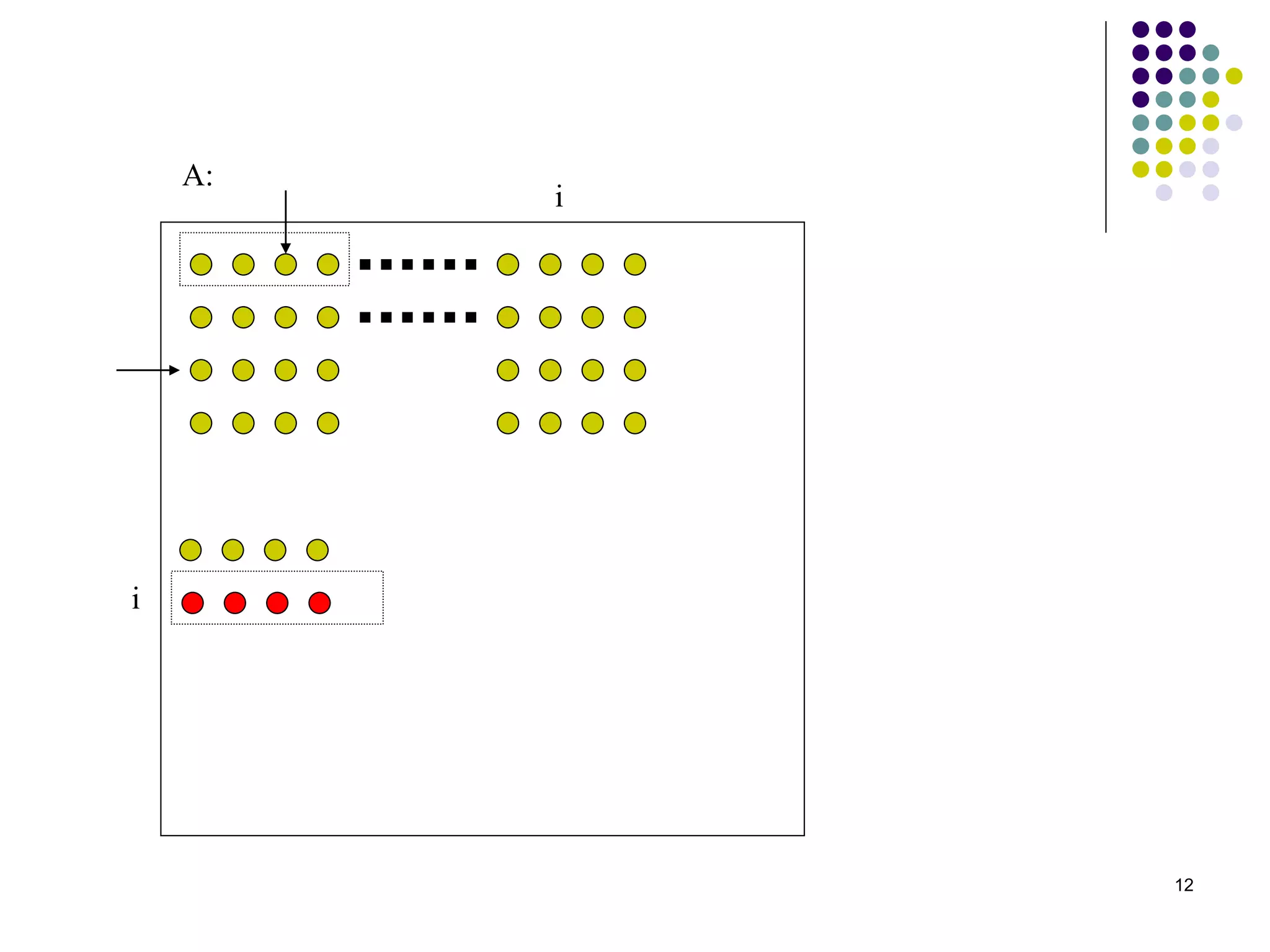
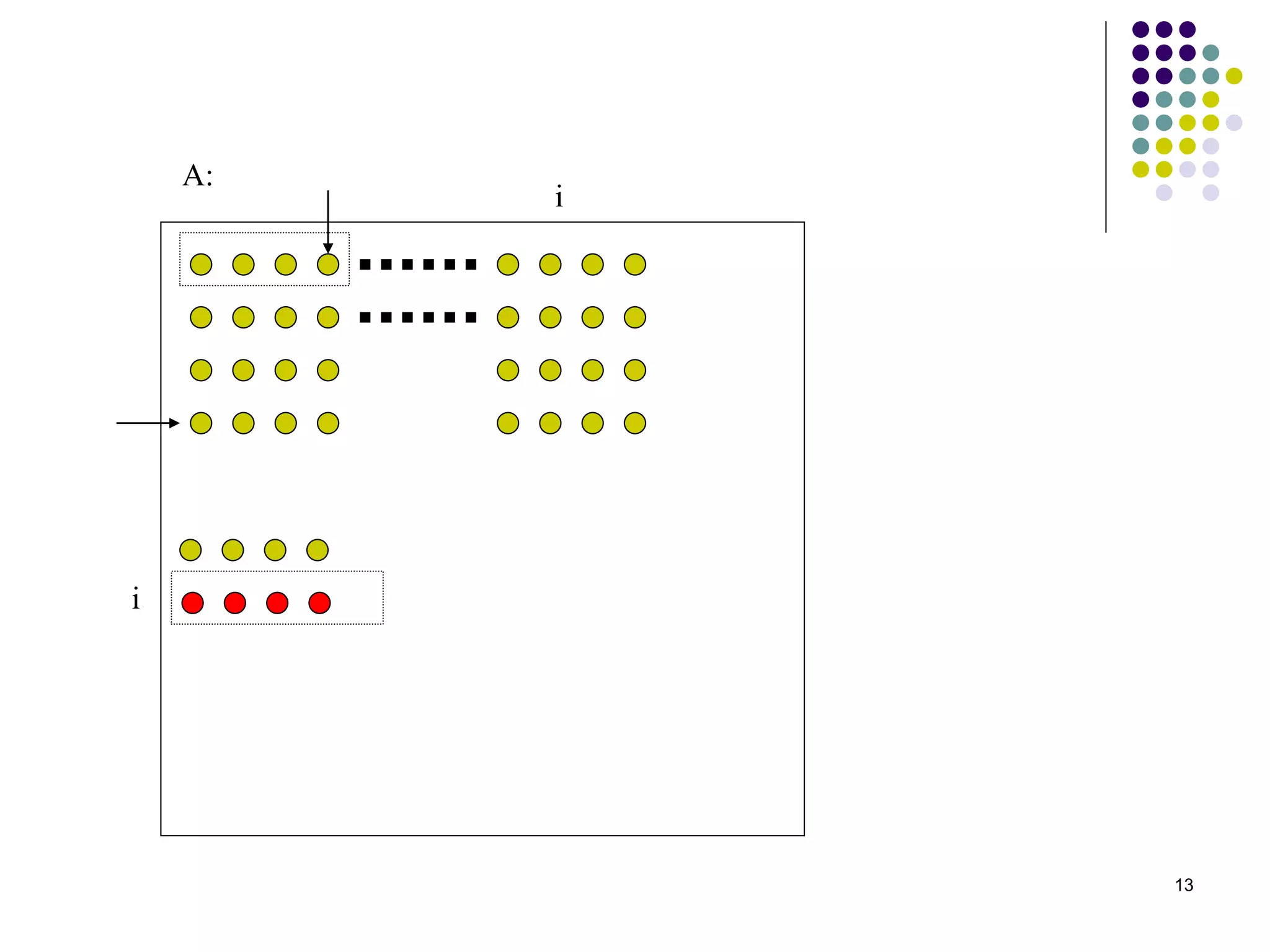
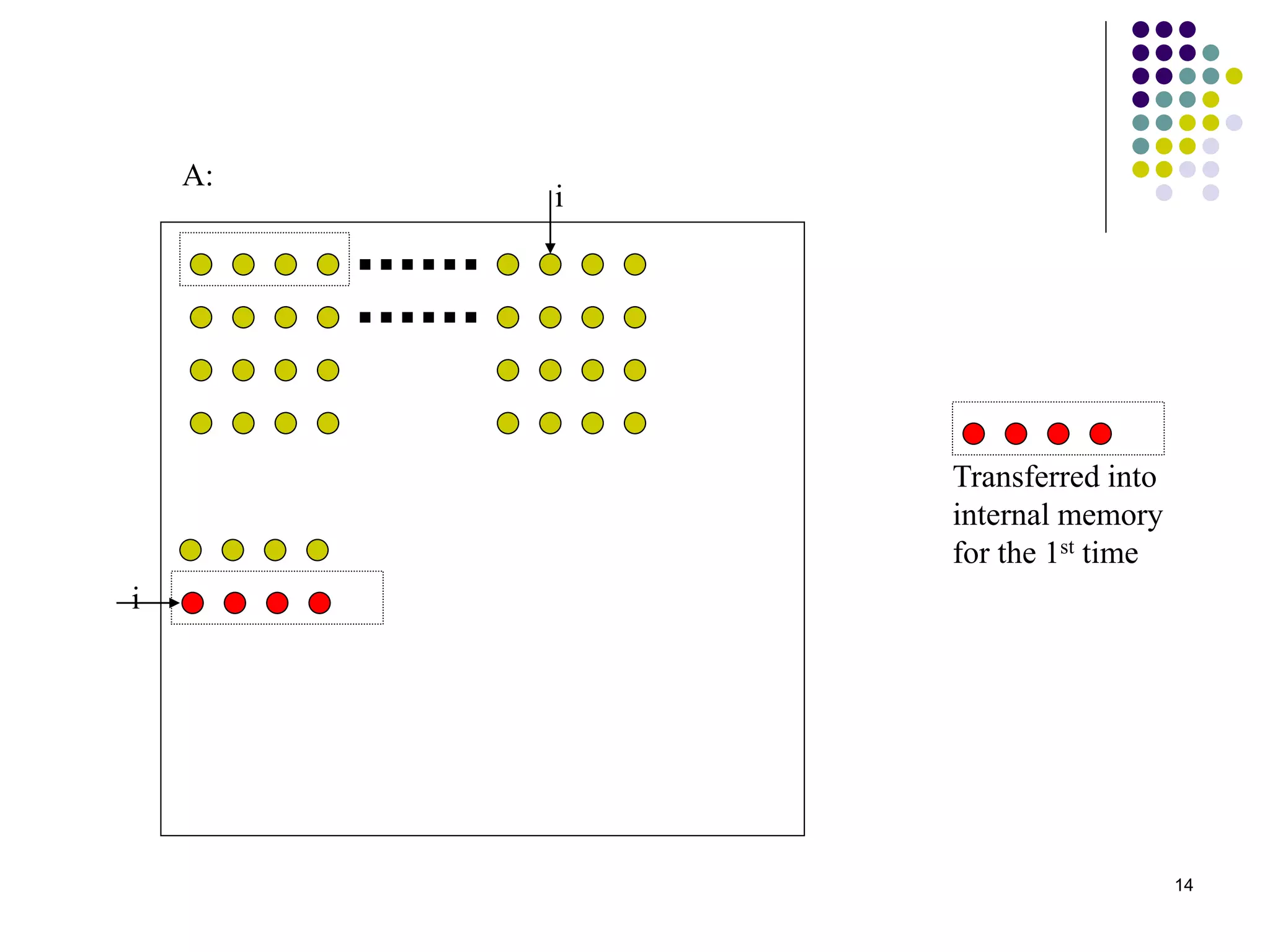
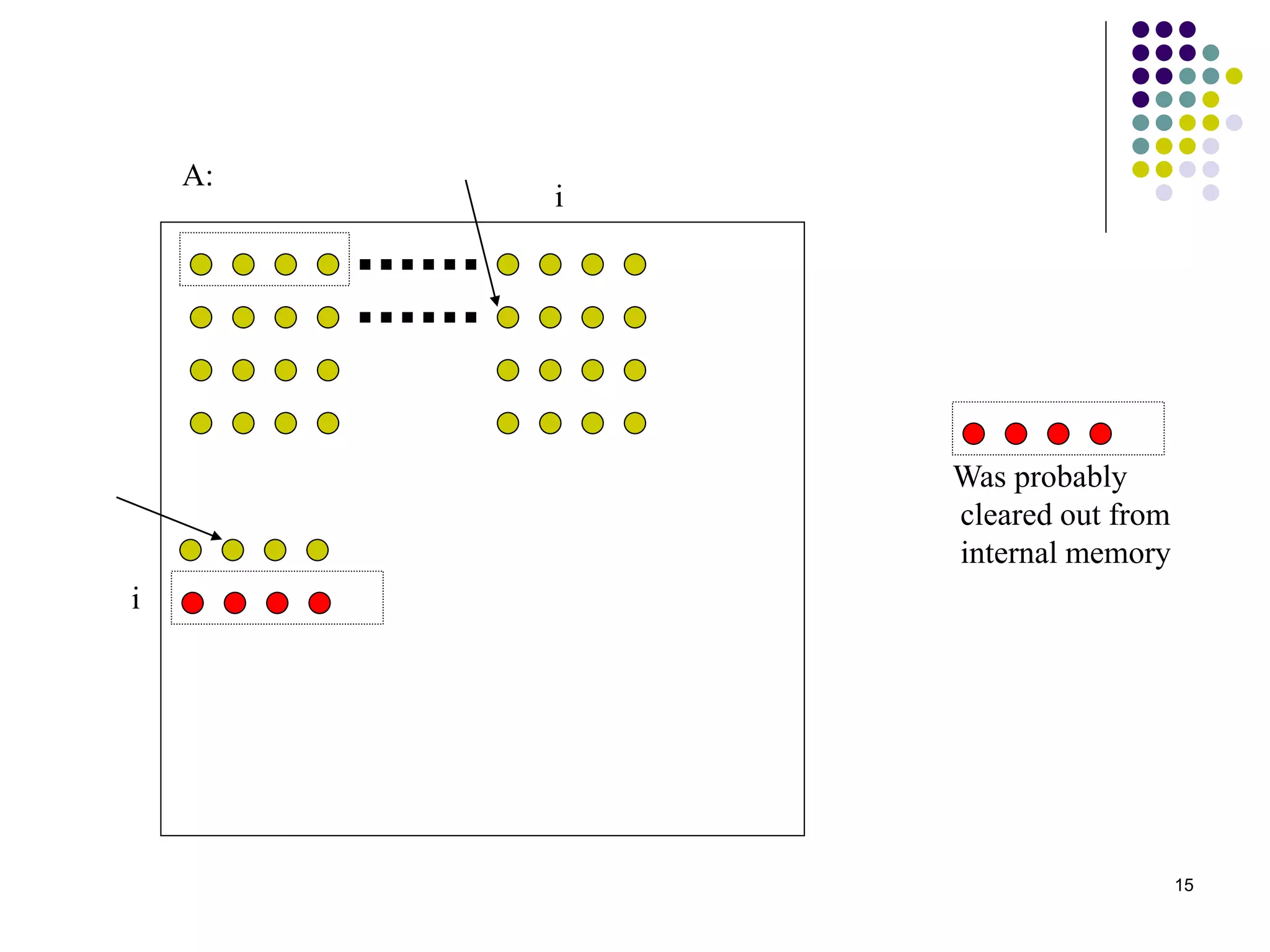
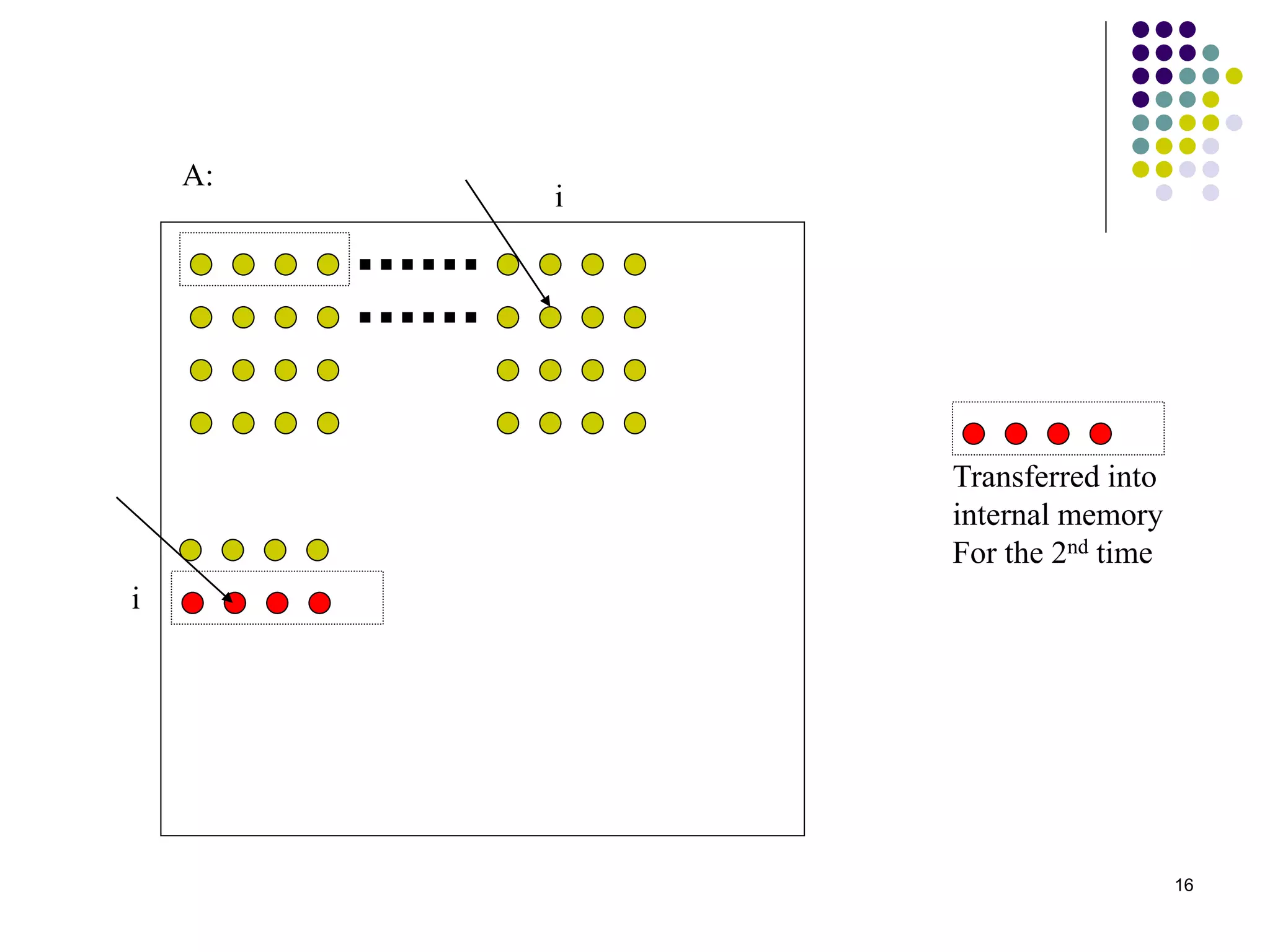
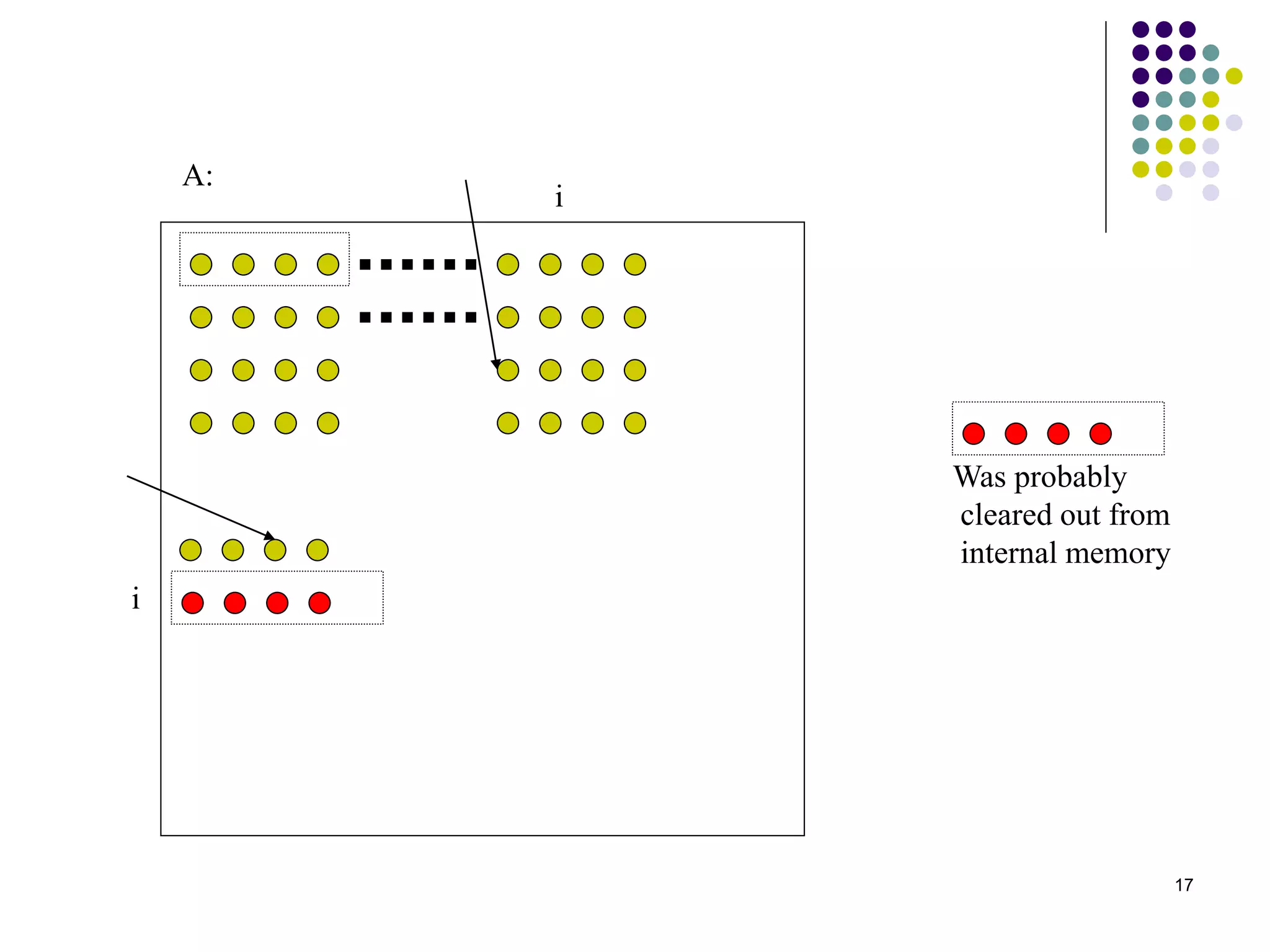
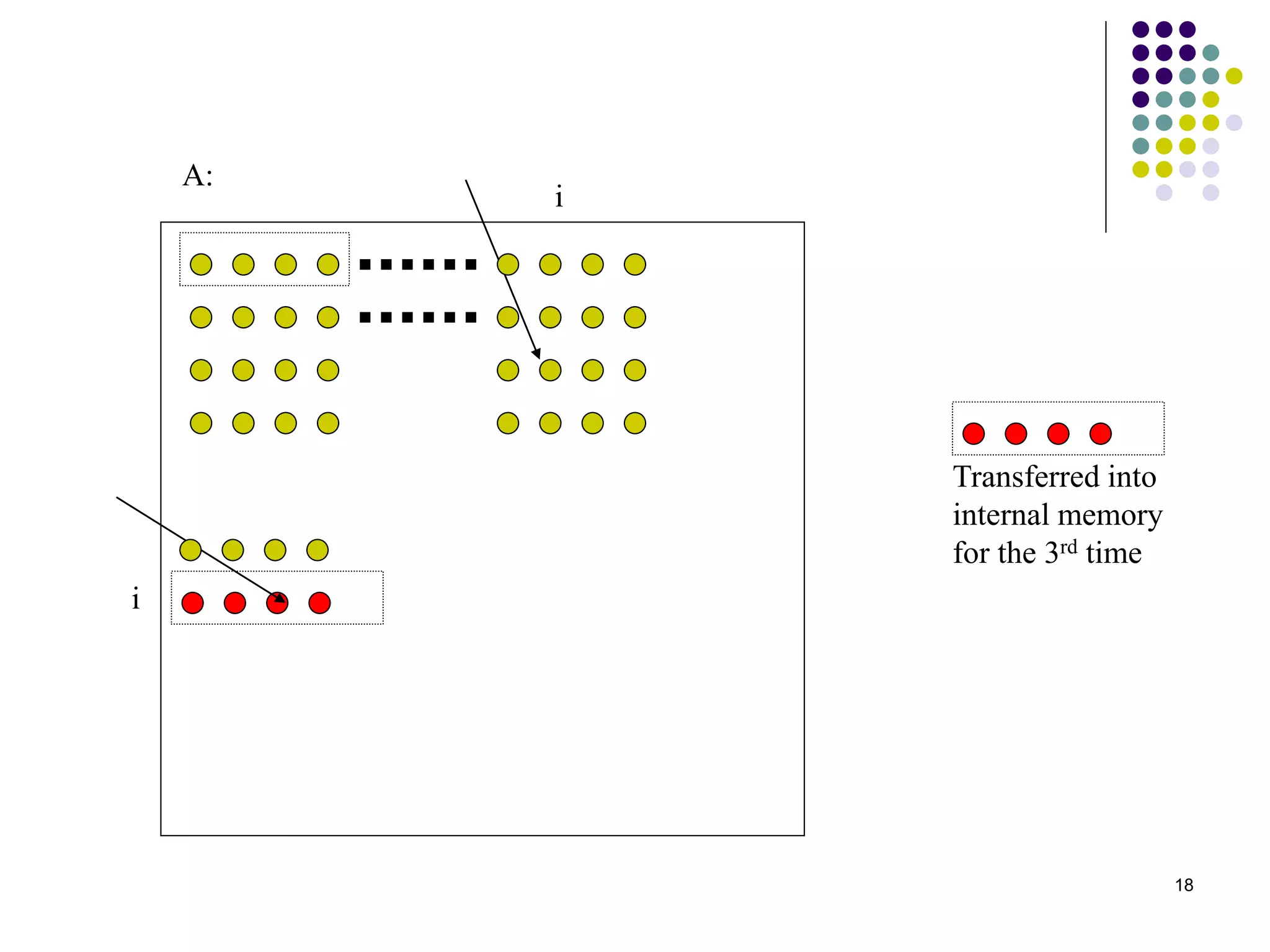
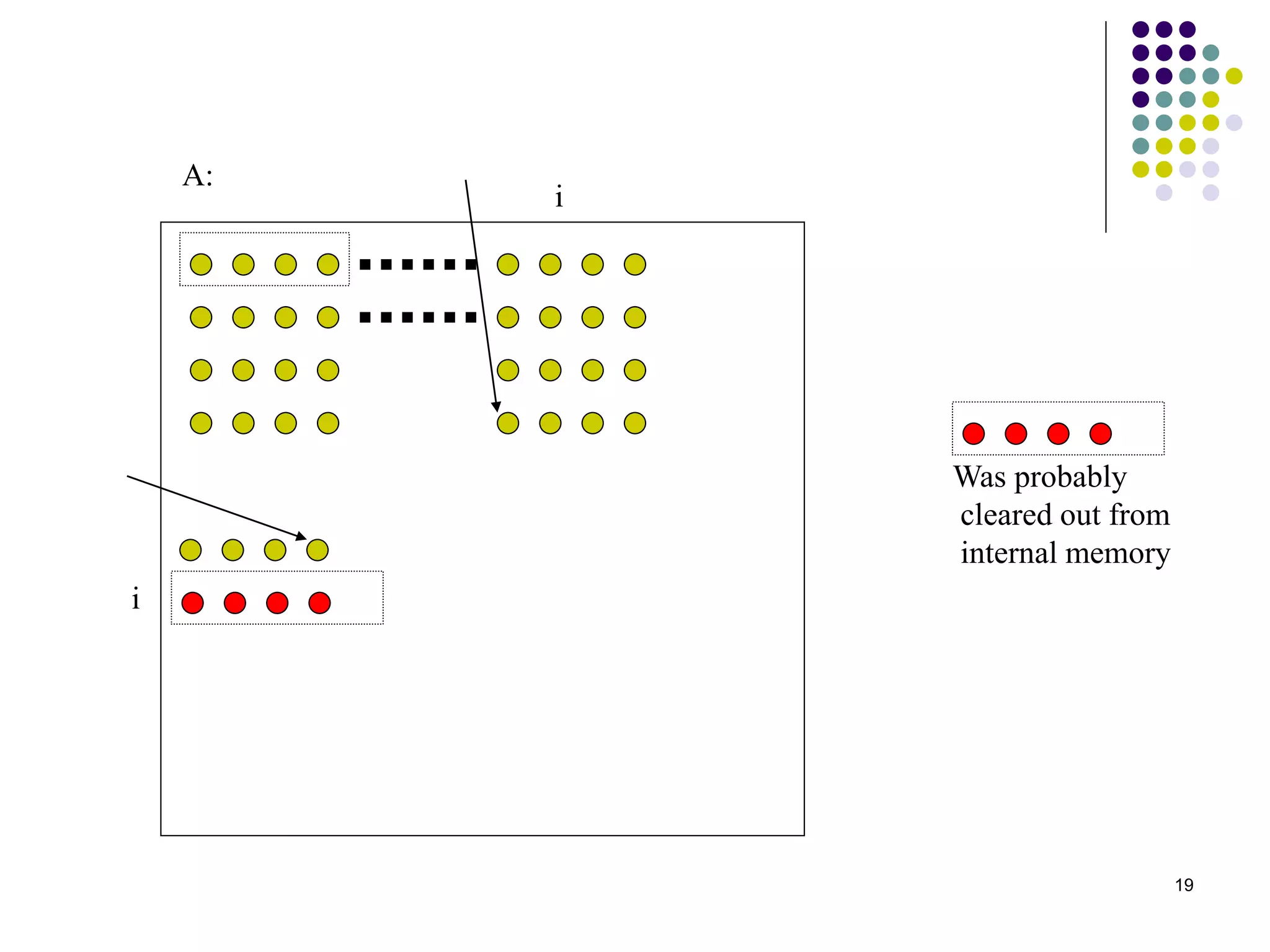
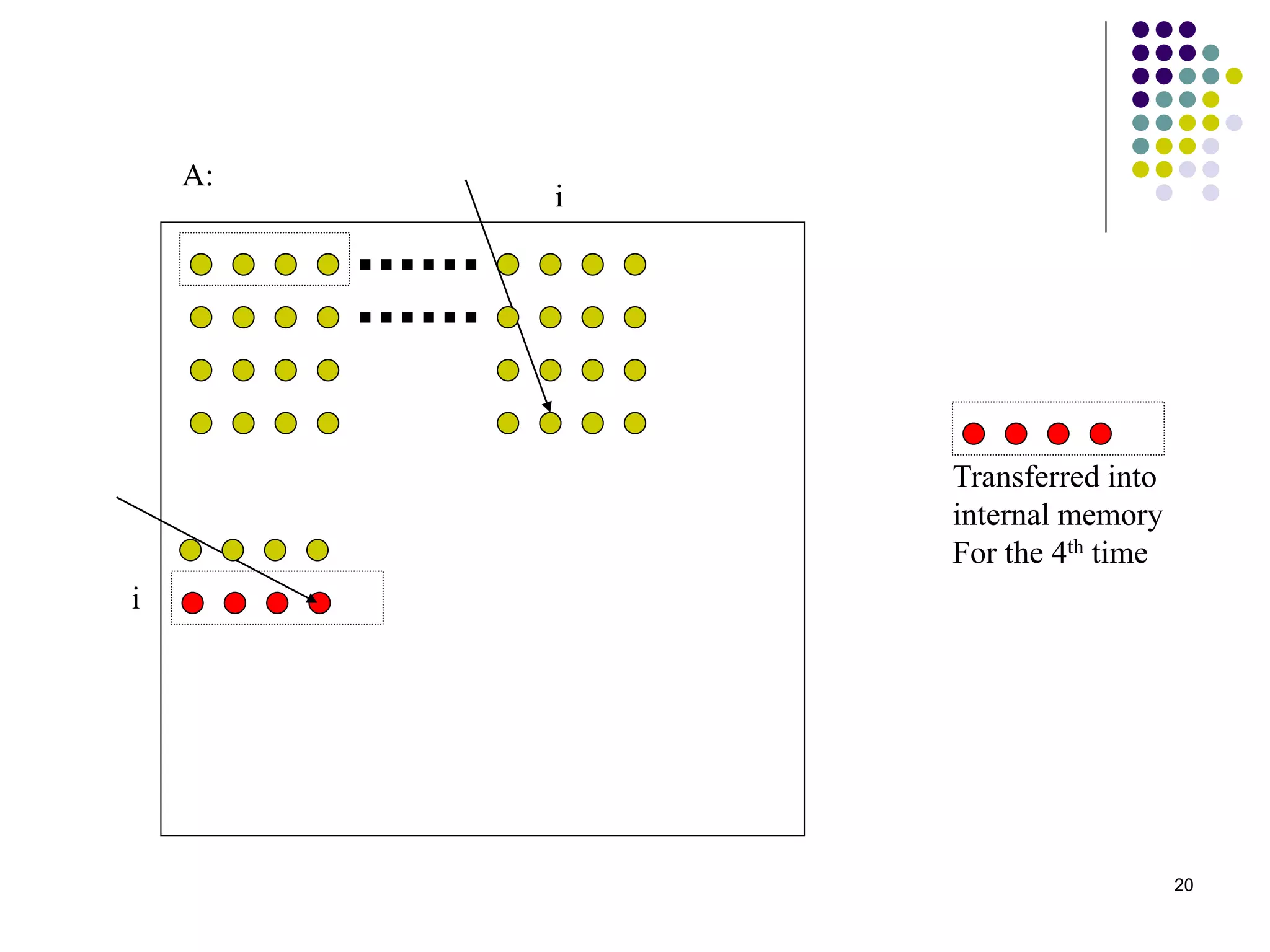





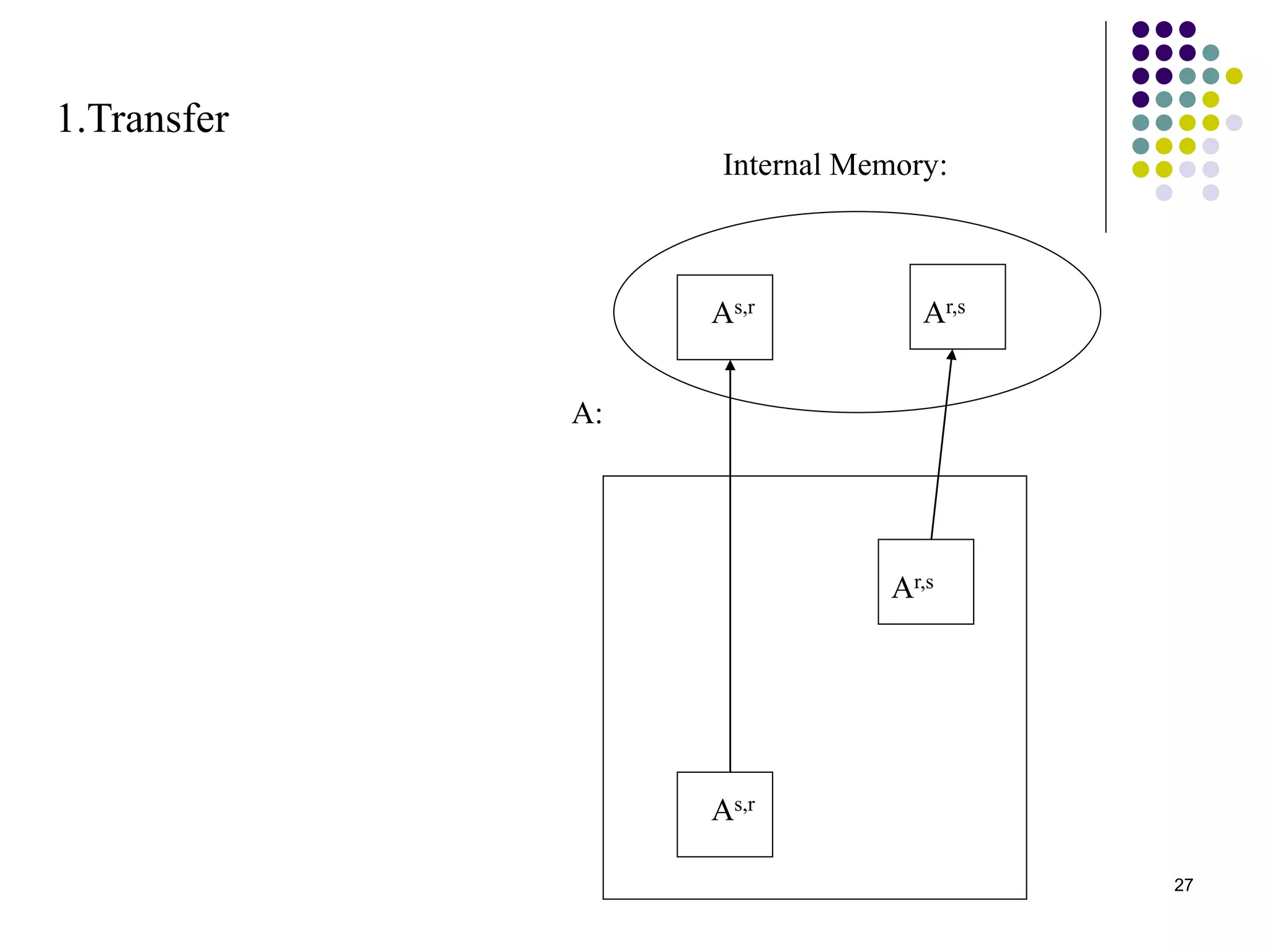






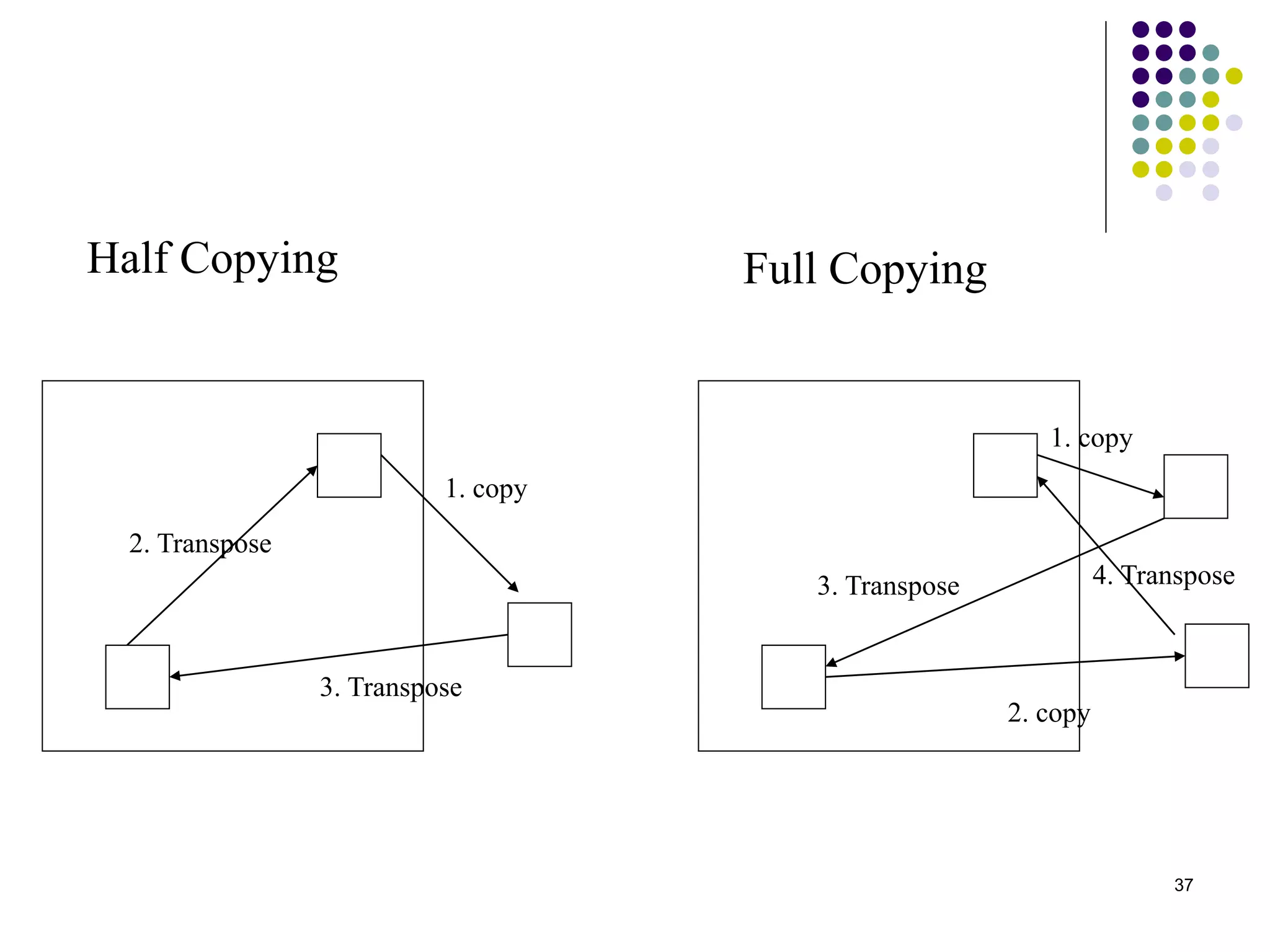





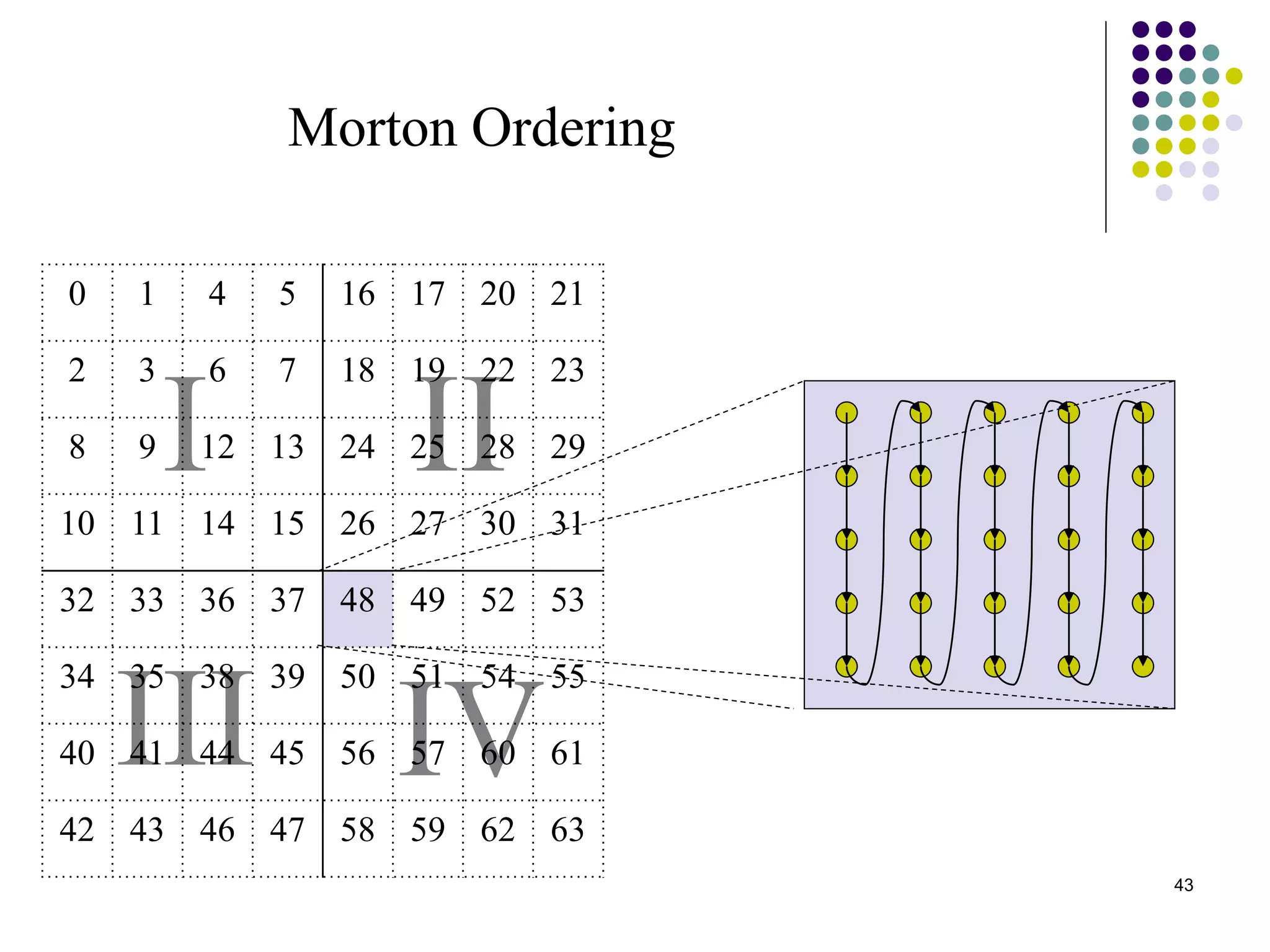



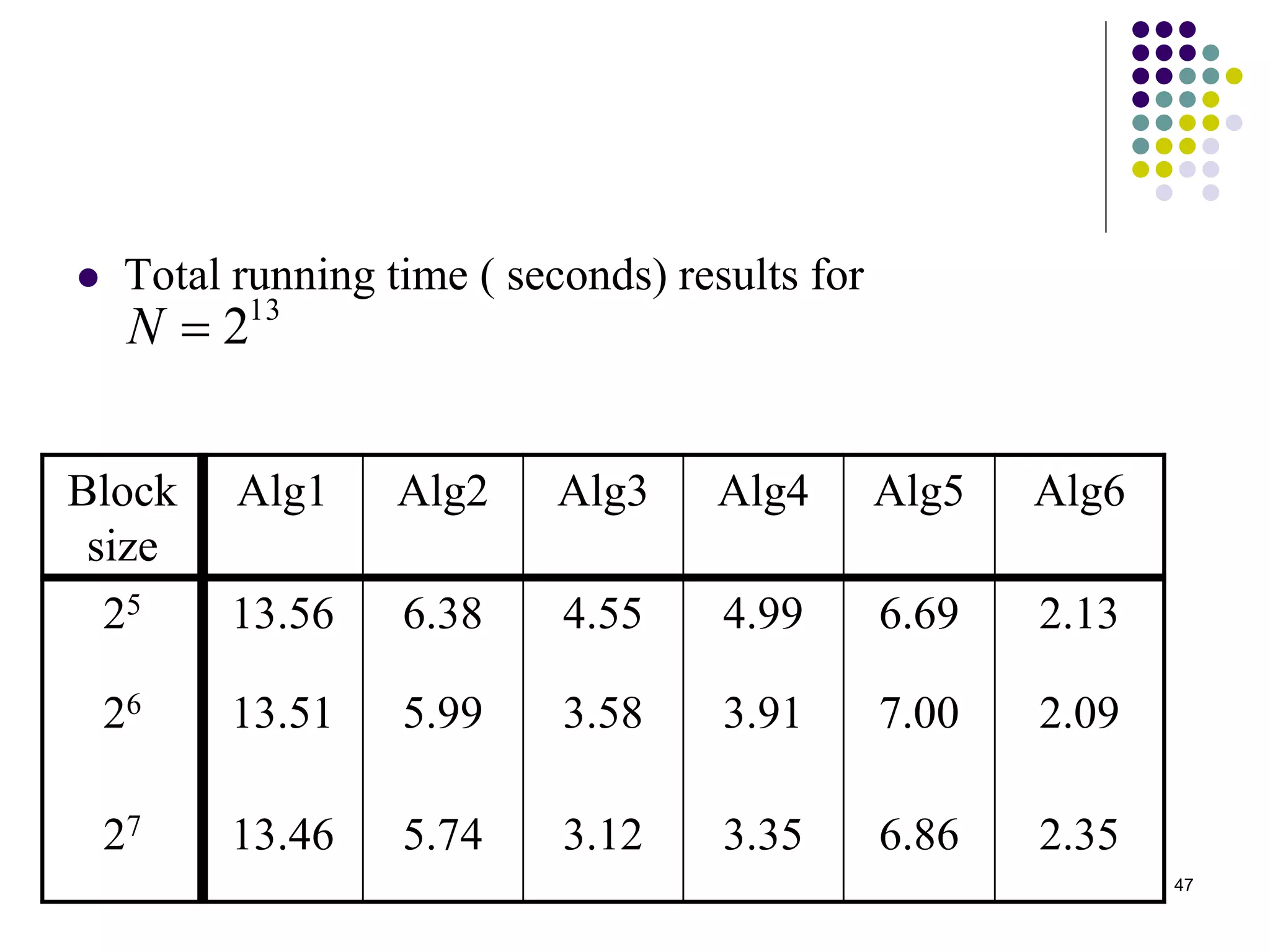


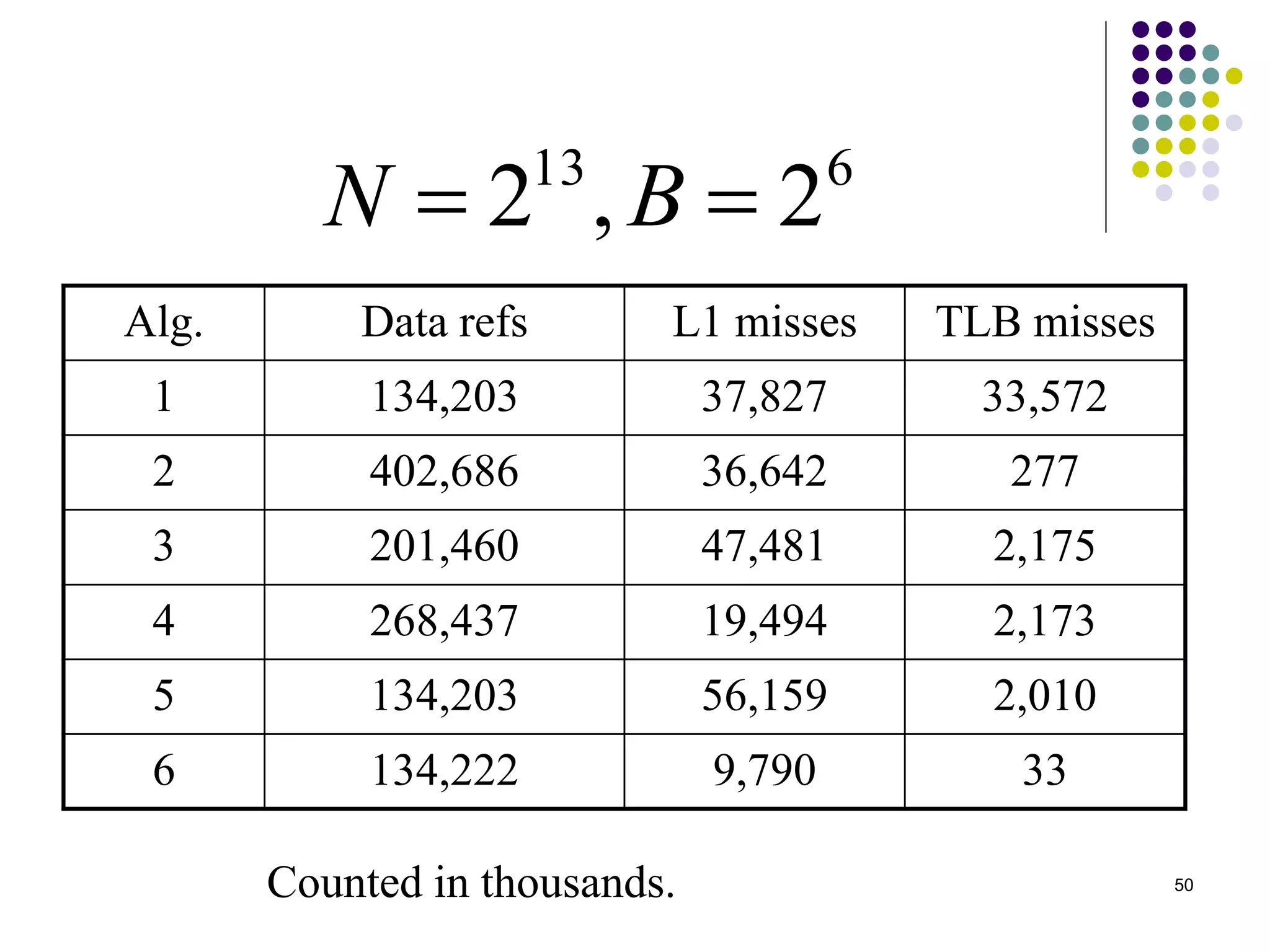




1) The document presents various algorithms for efficiently transposing matrices while minimizing memory accesses and cache misses. 2) It analyzes the algorithms under different memory models: RAM, I/O, cache, and cache-oblivious. The block transpose, half/full copying, and Morton layout algorithms improve performance by reusing data blocks. 3) Experimental results on a 300MHz system show the Morton layout and half copying algorithms have the fastest runtimes due to minimizing data references, L1 misses, and TLB misses. The relative performance of algorithms depends on cache miss latency.



































































