Download to read offline





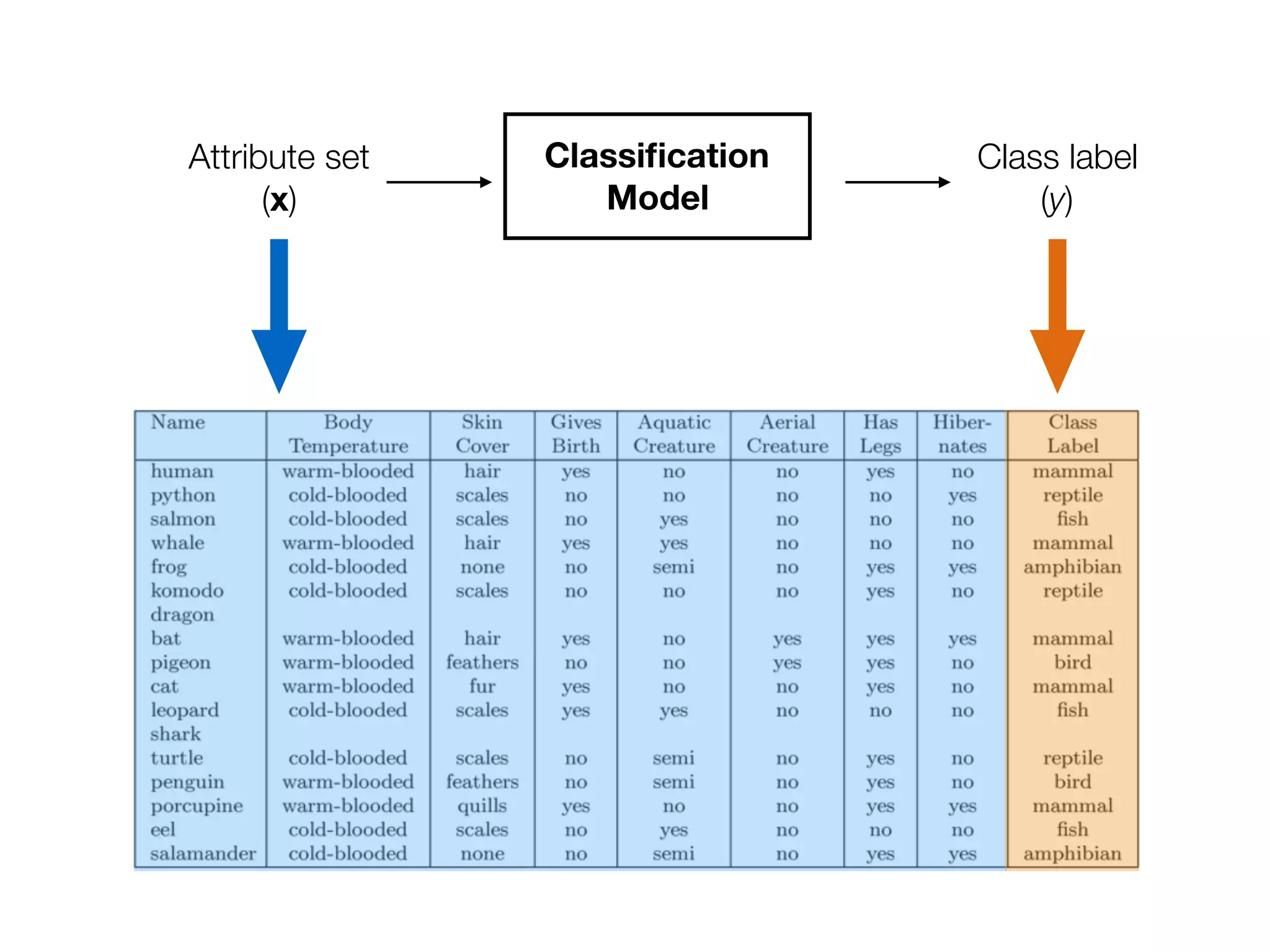
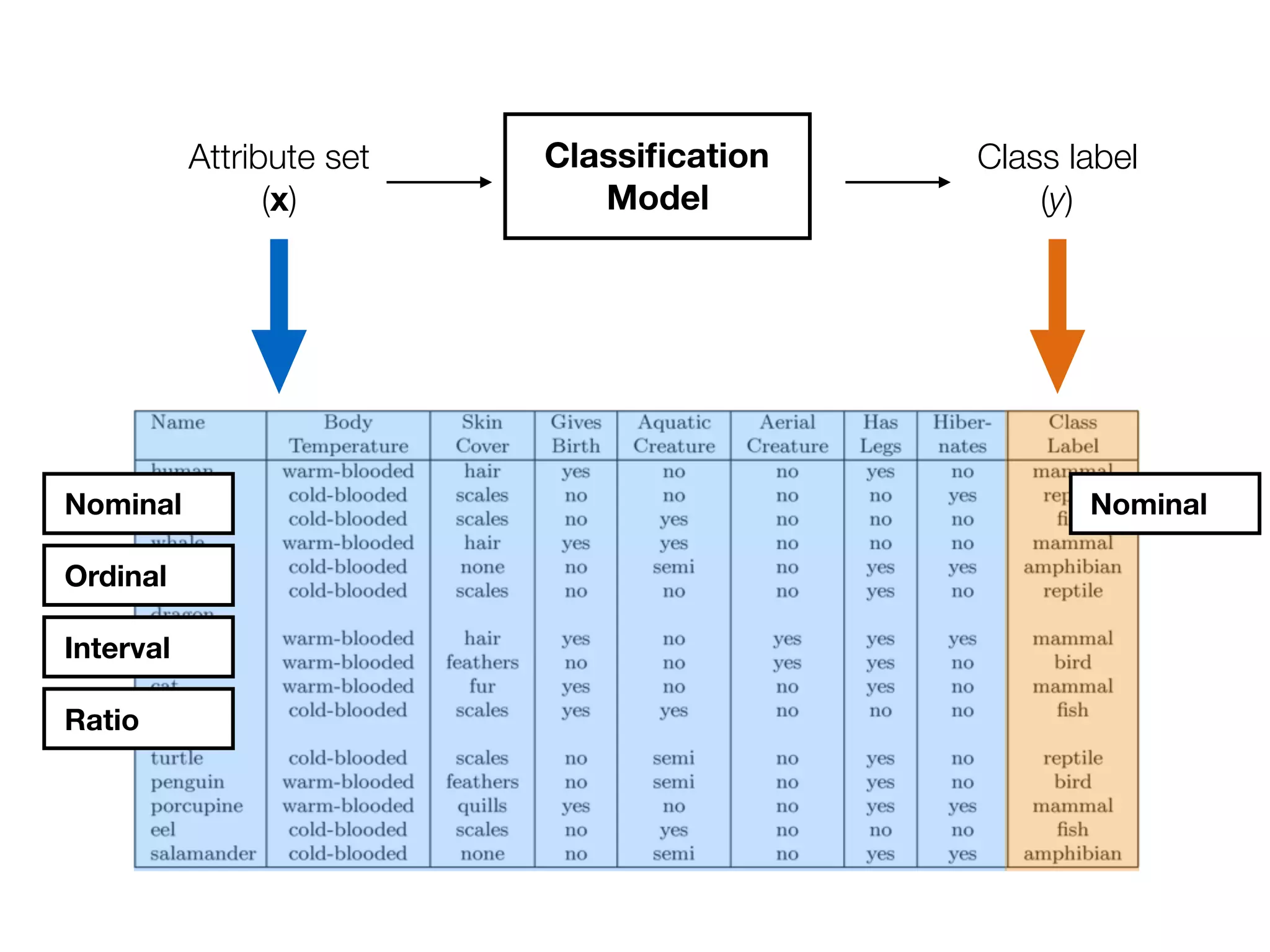
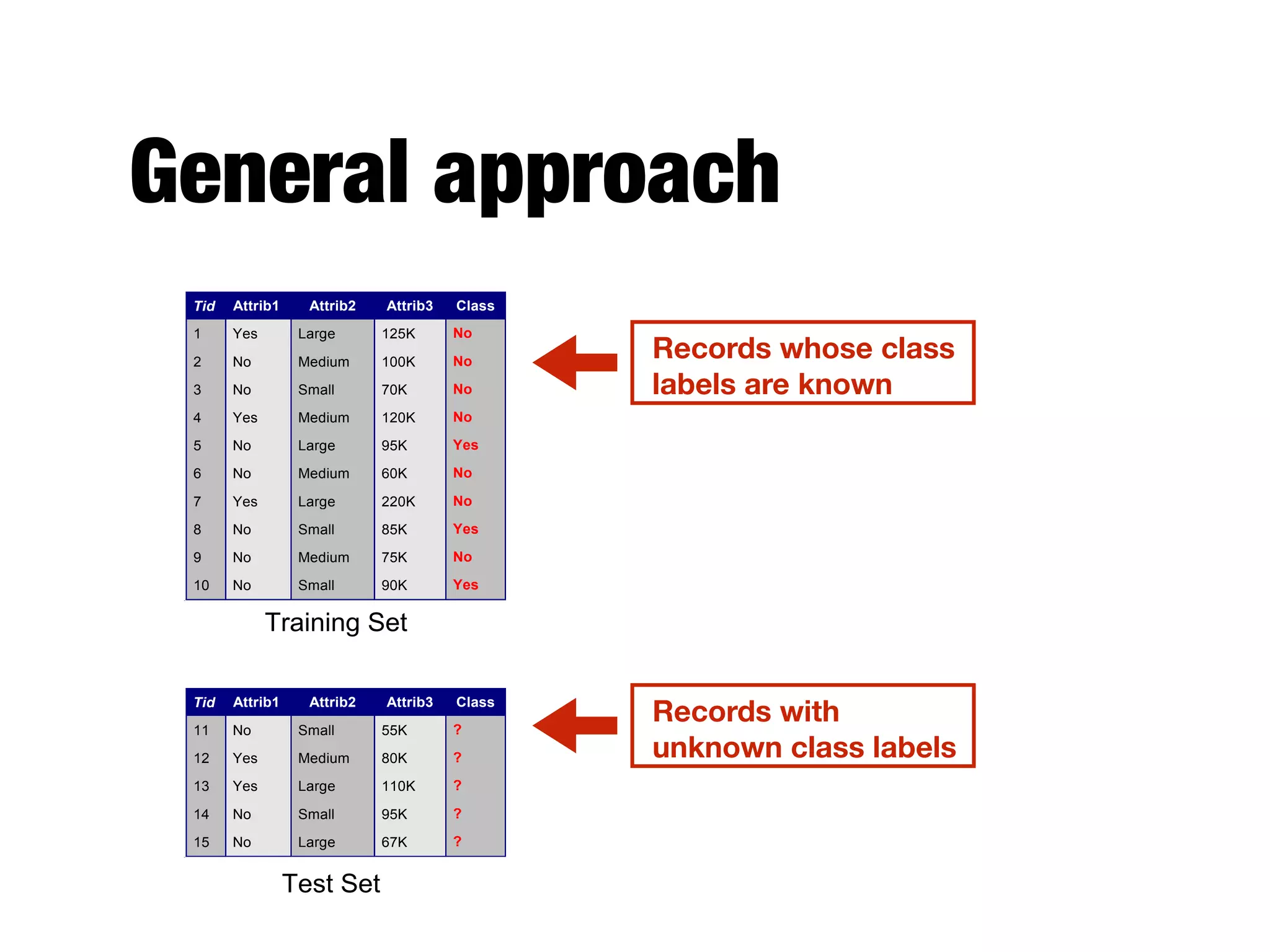
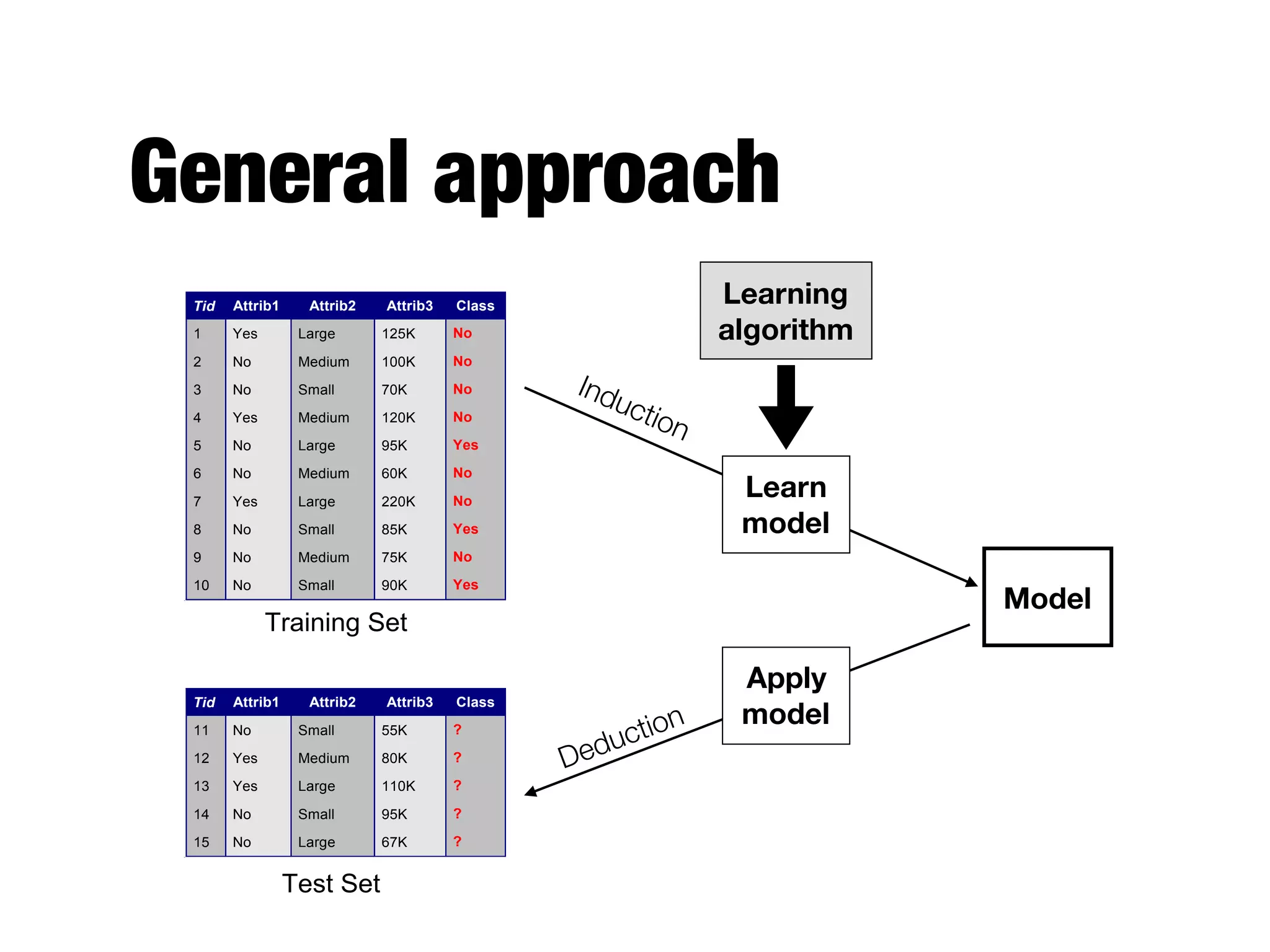
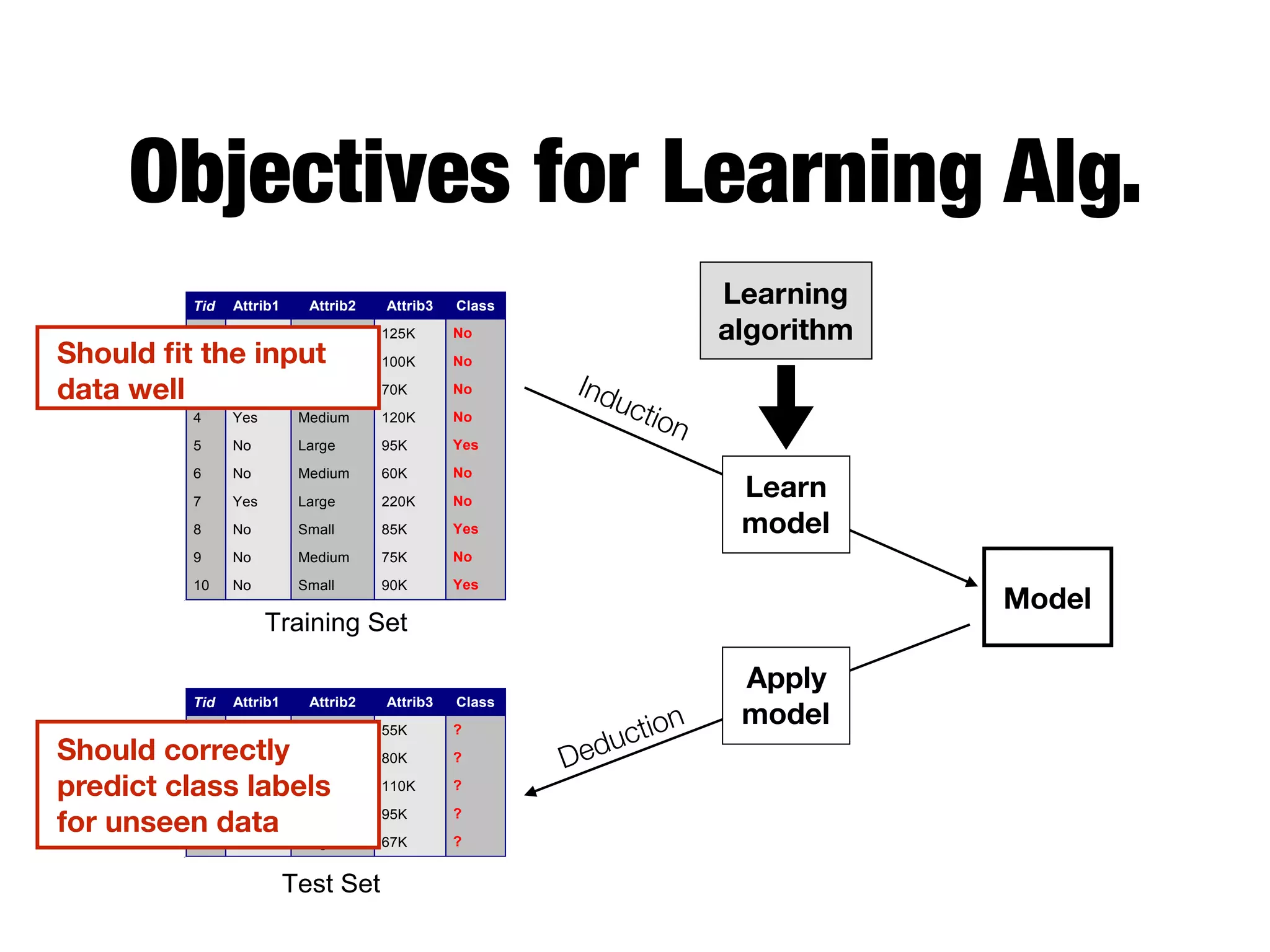







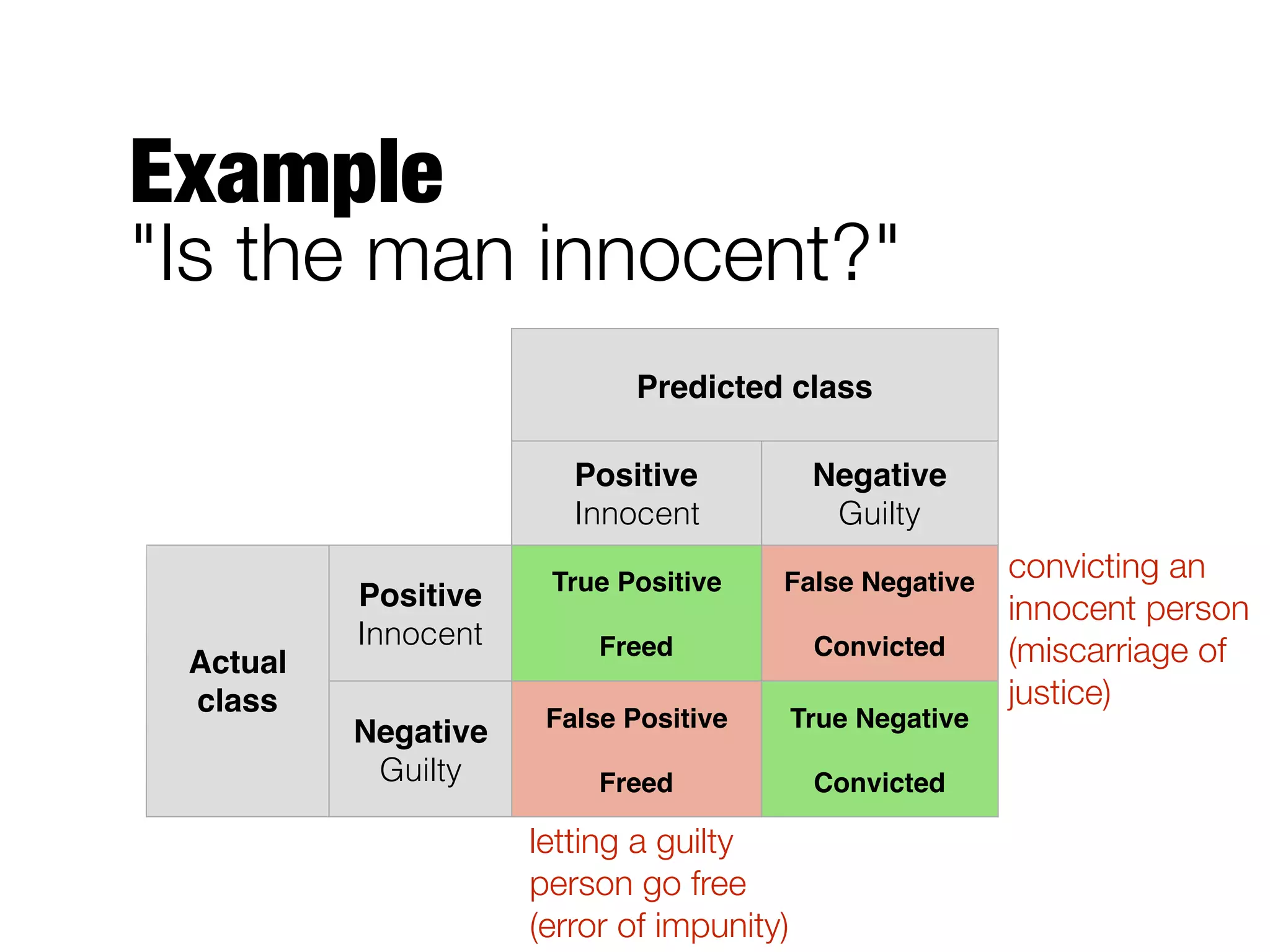


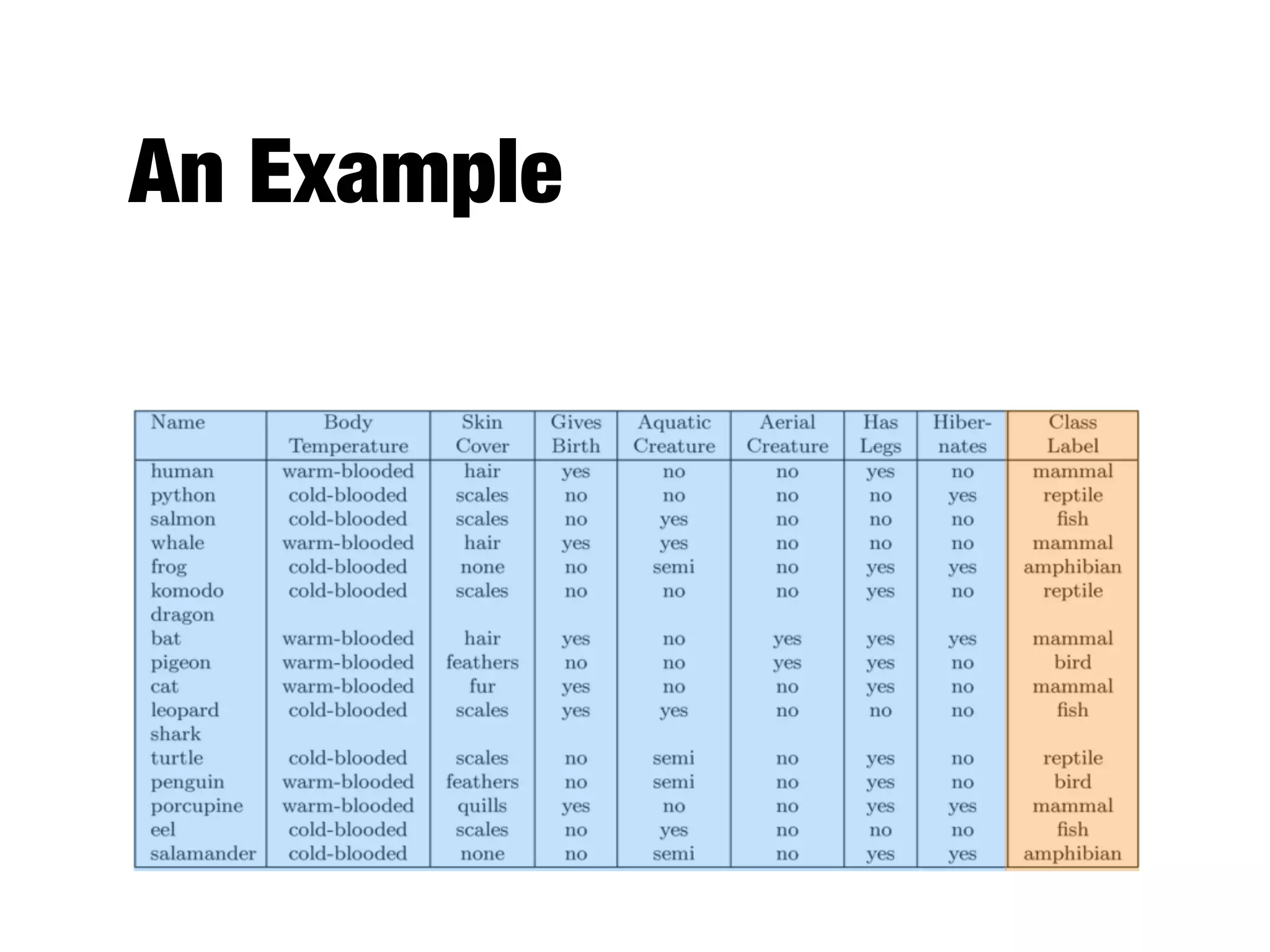

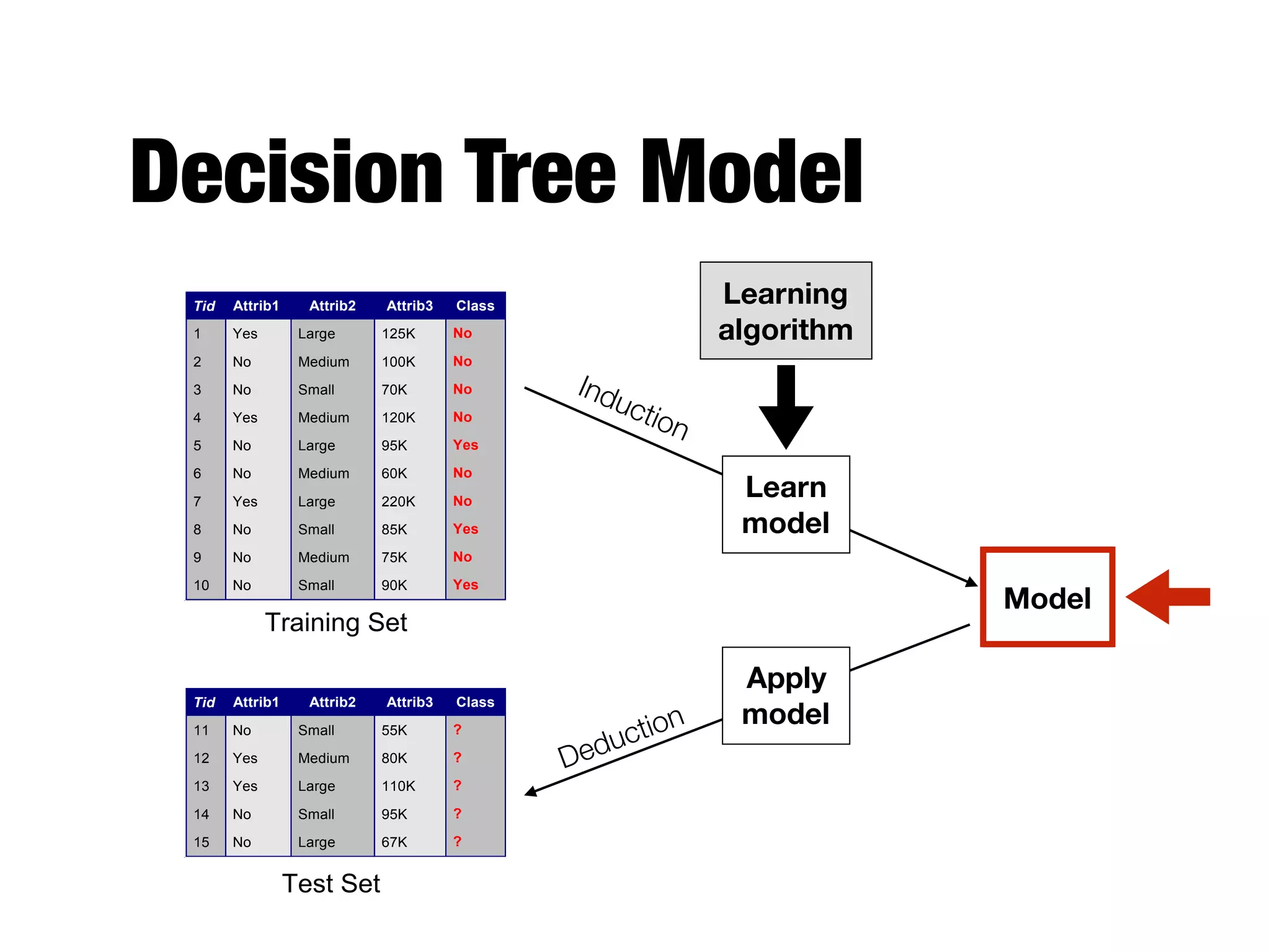
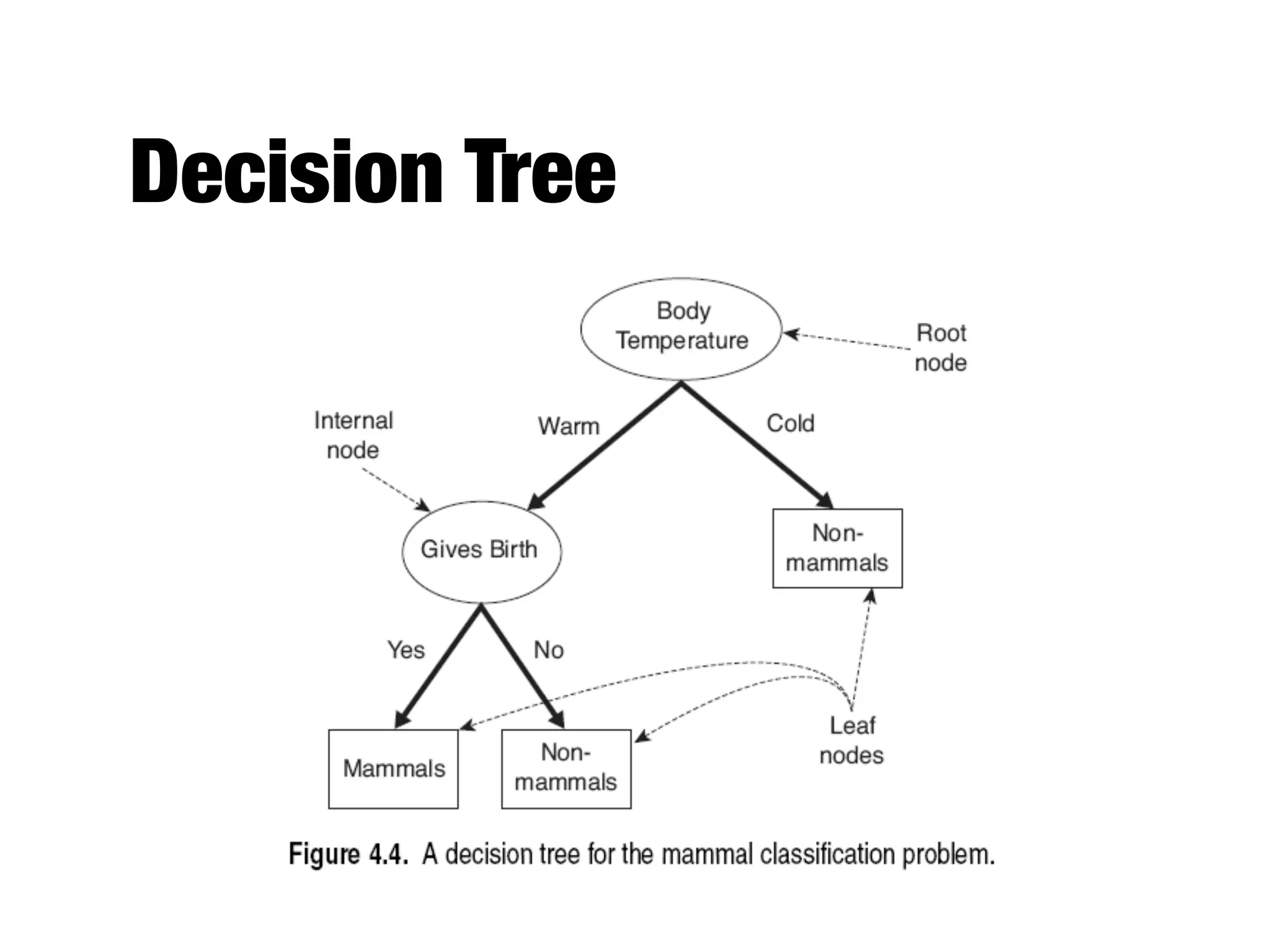
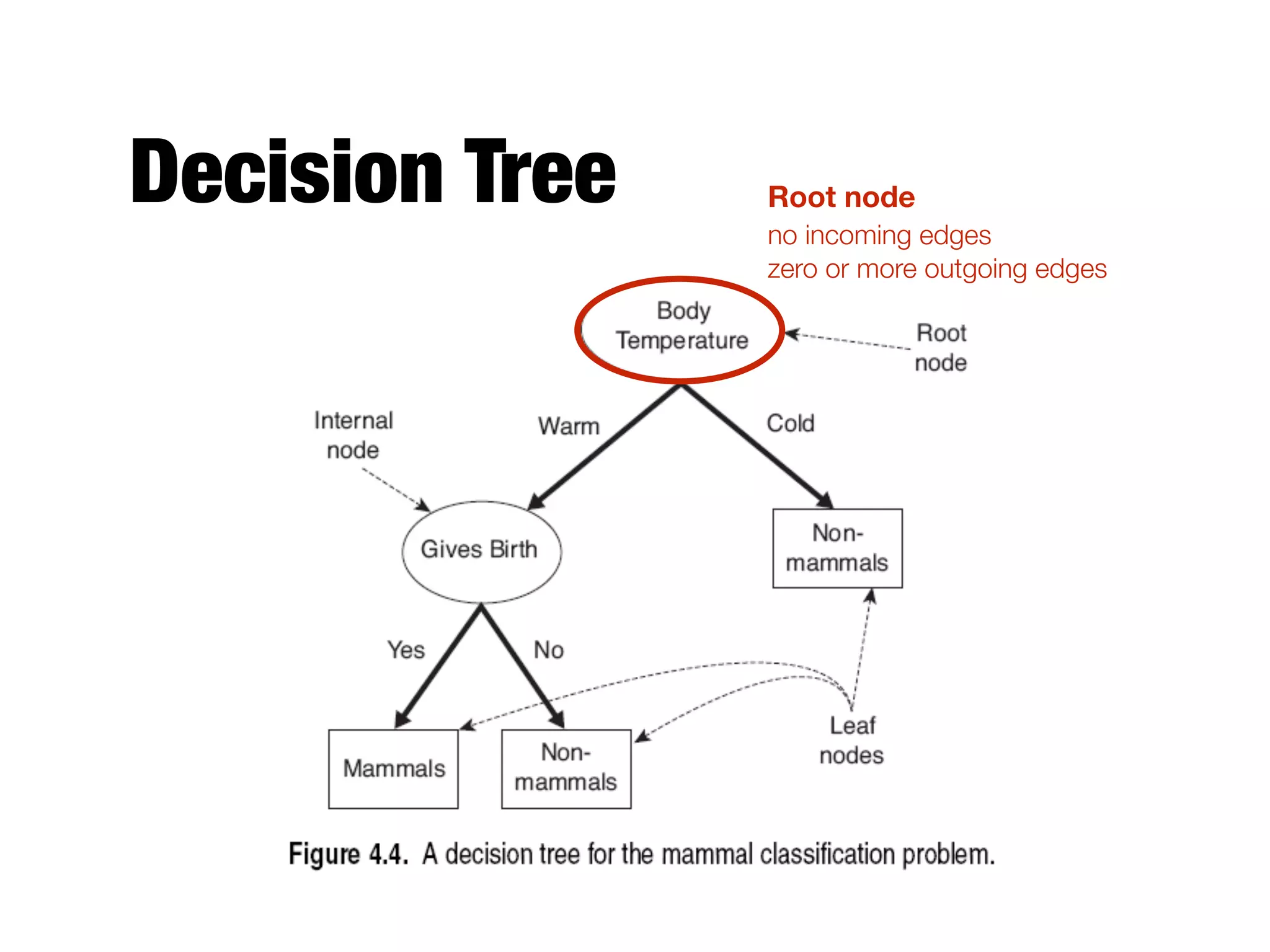

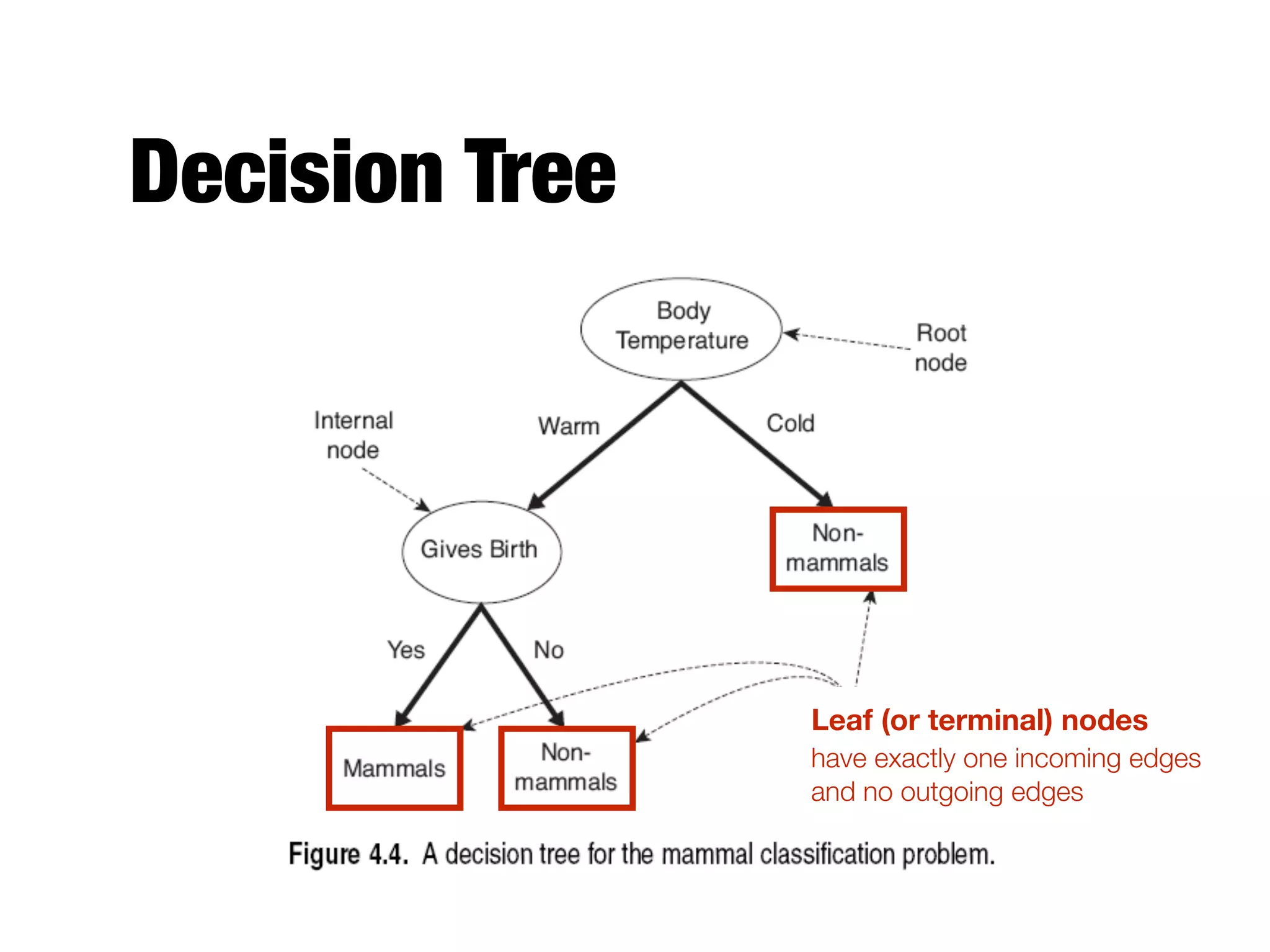
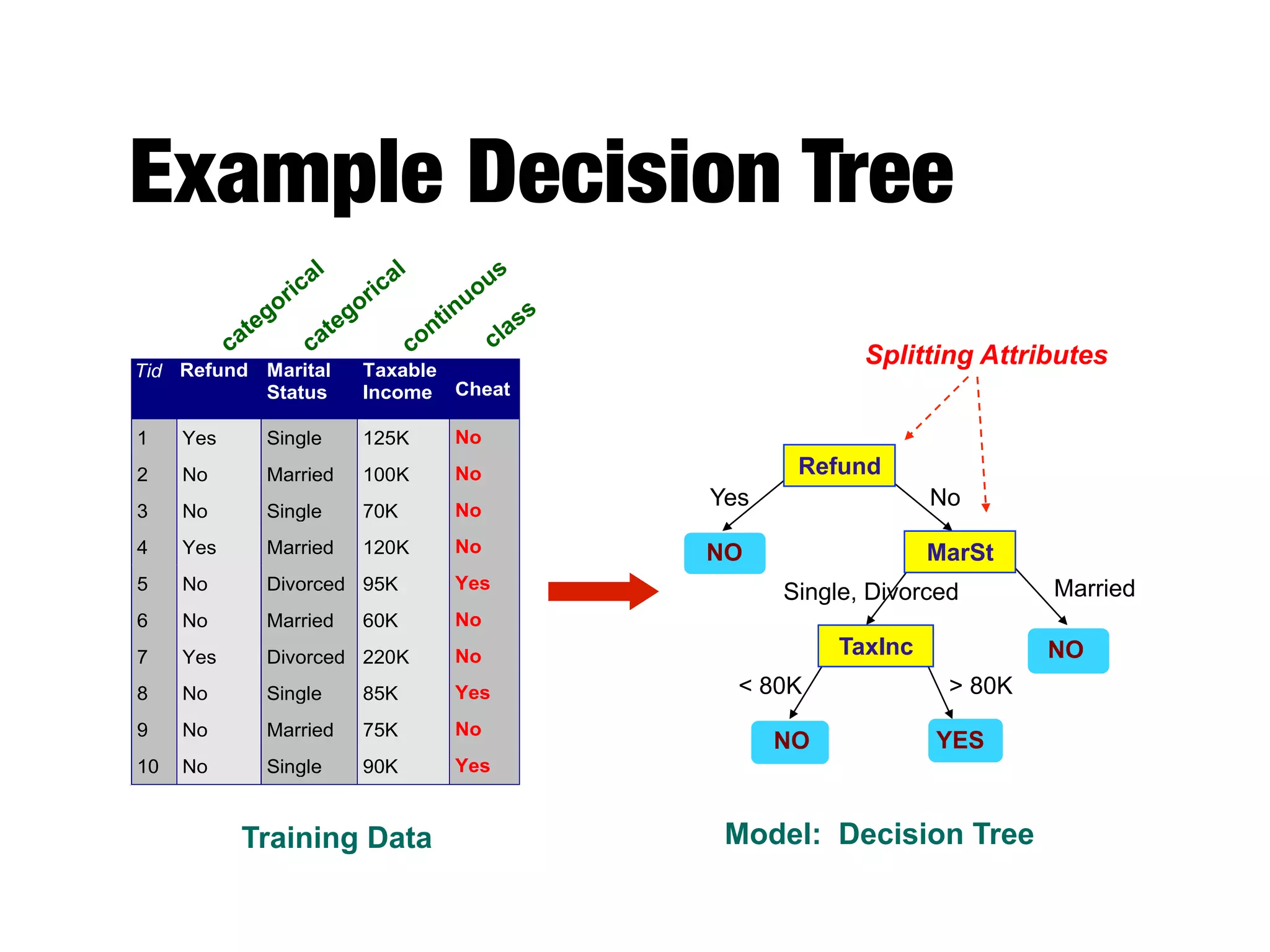
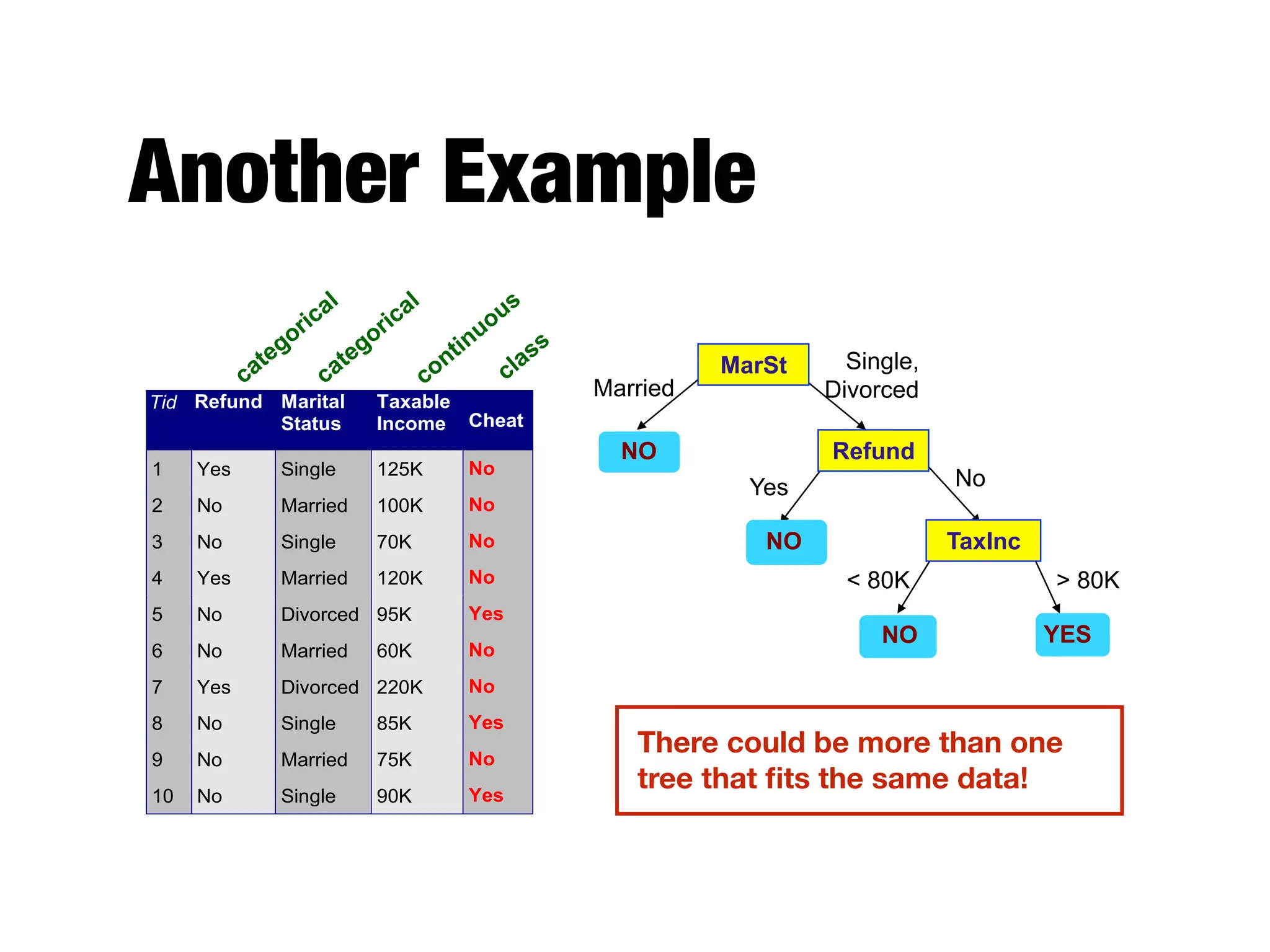
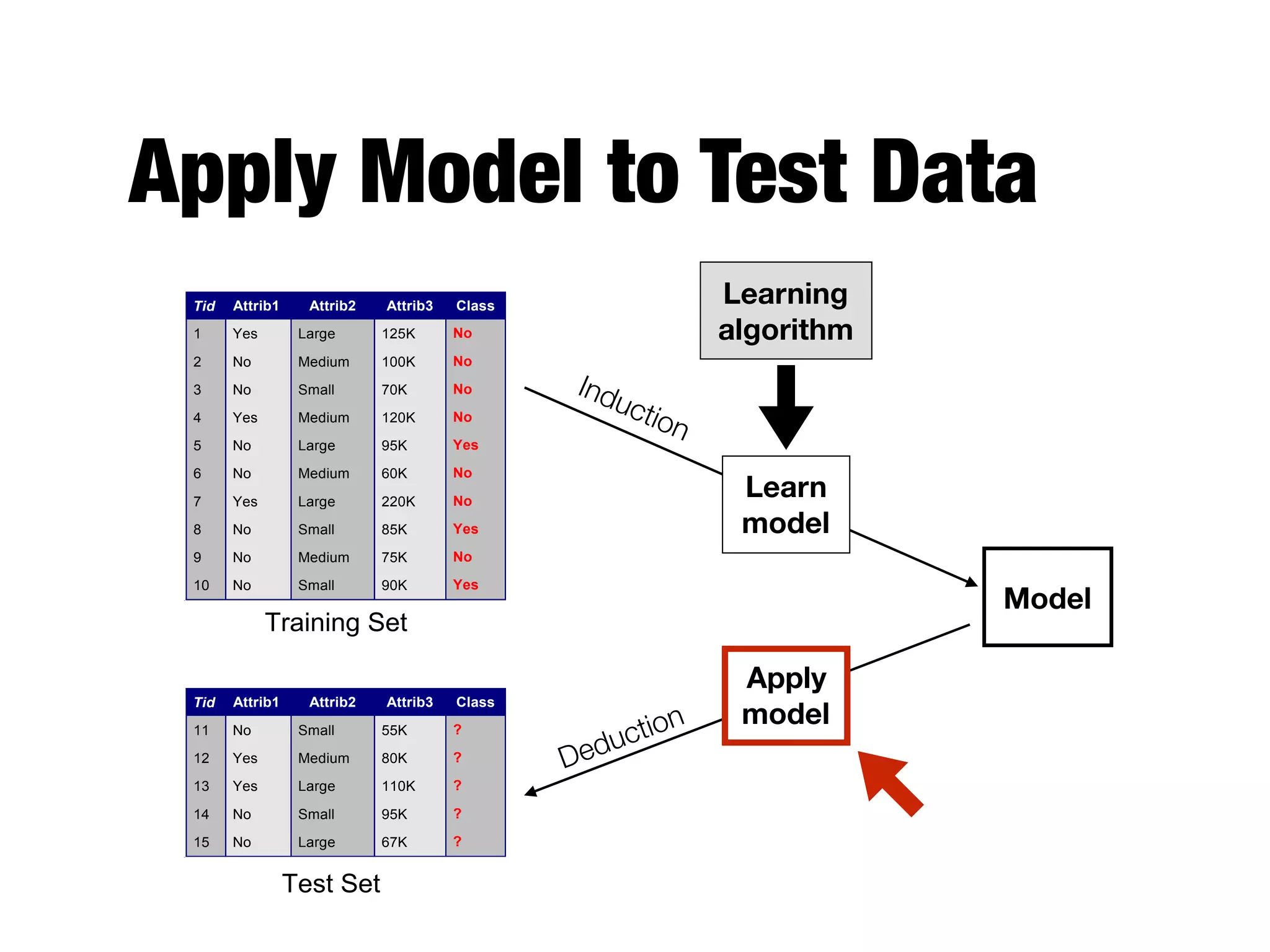
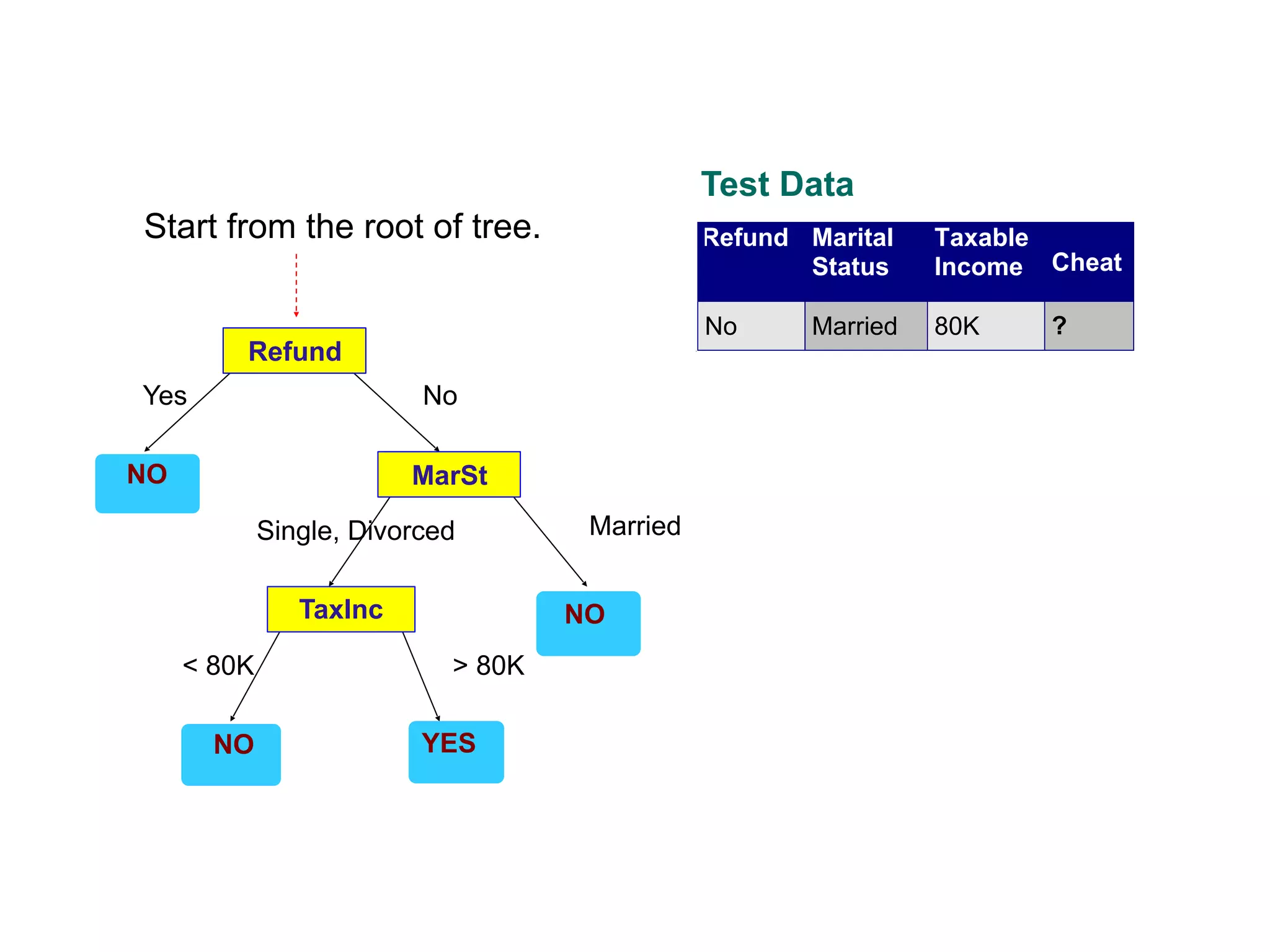
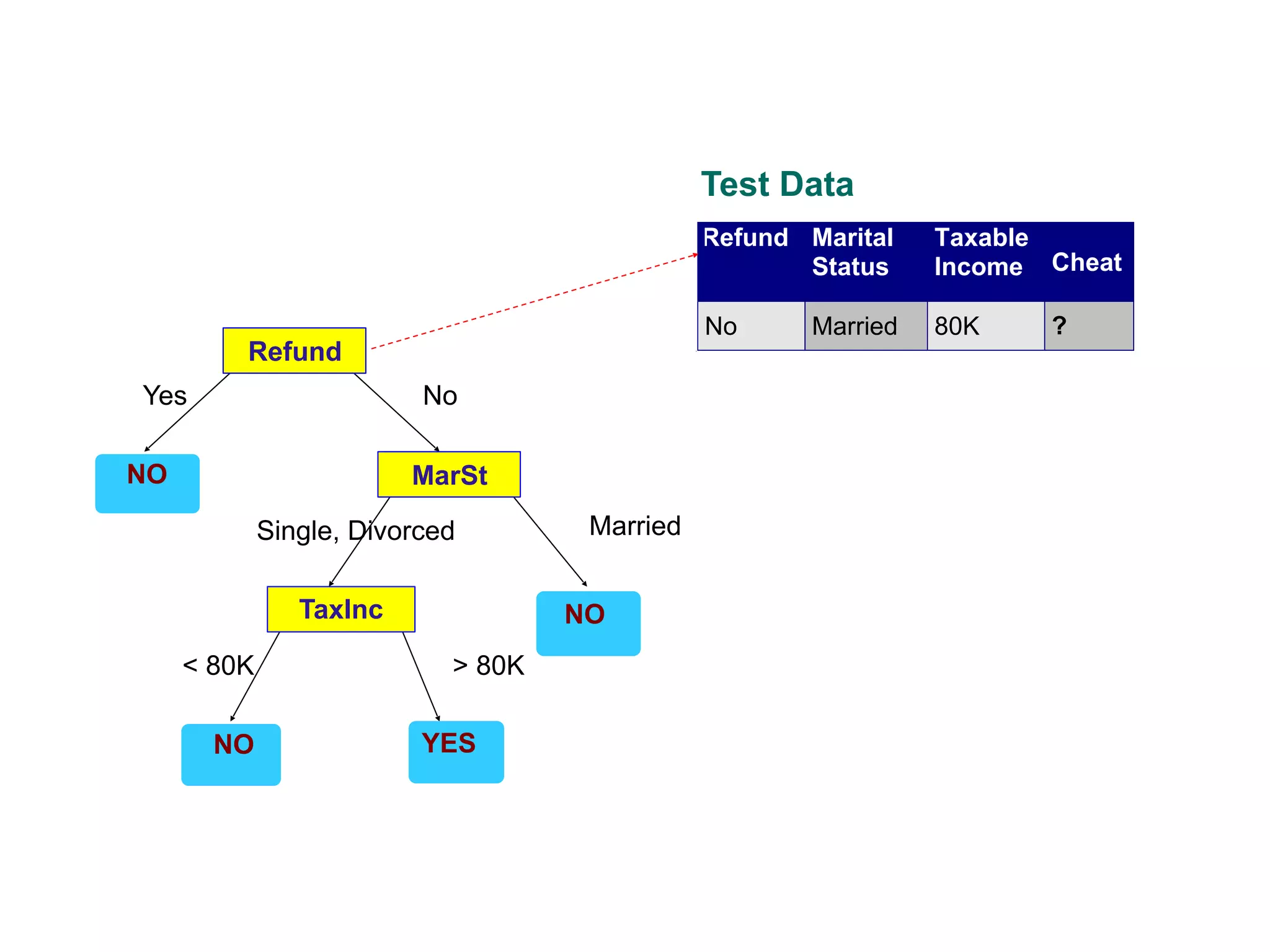
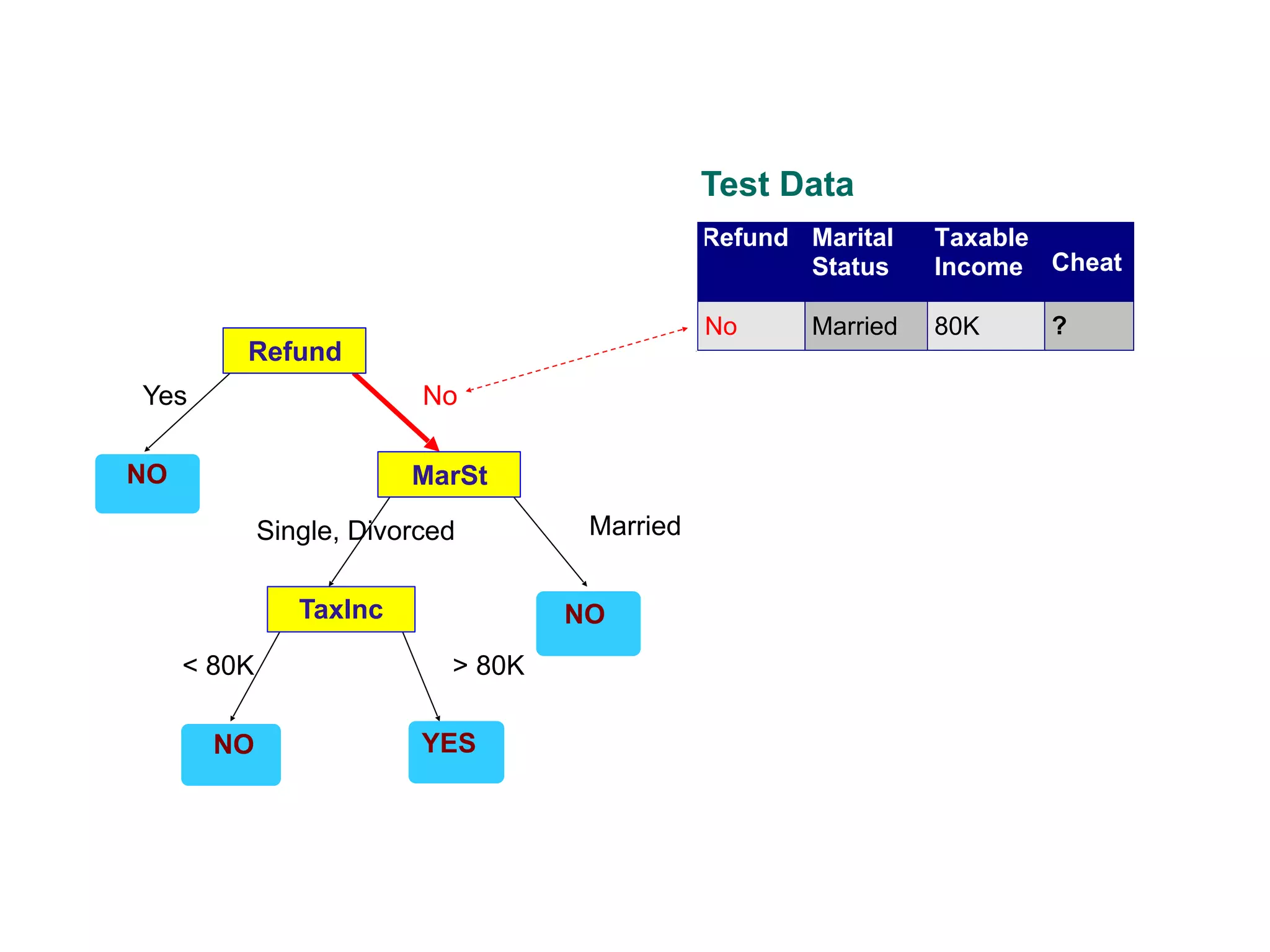
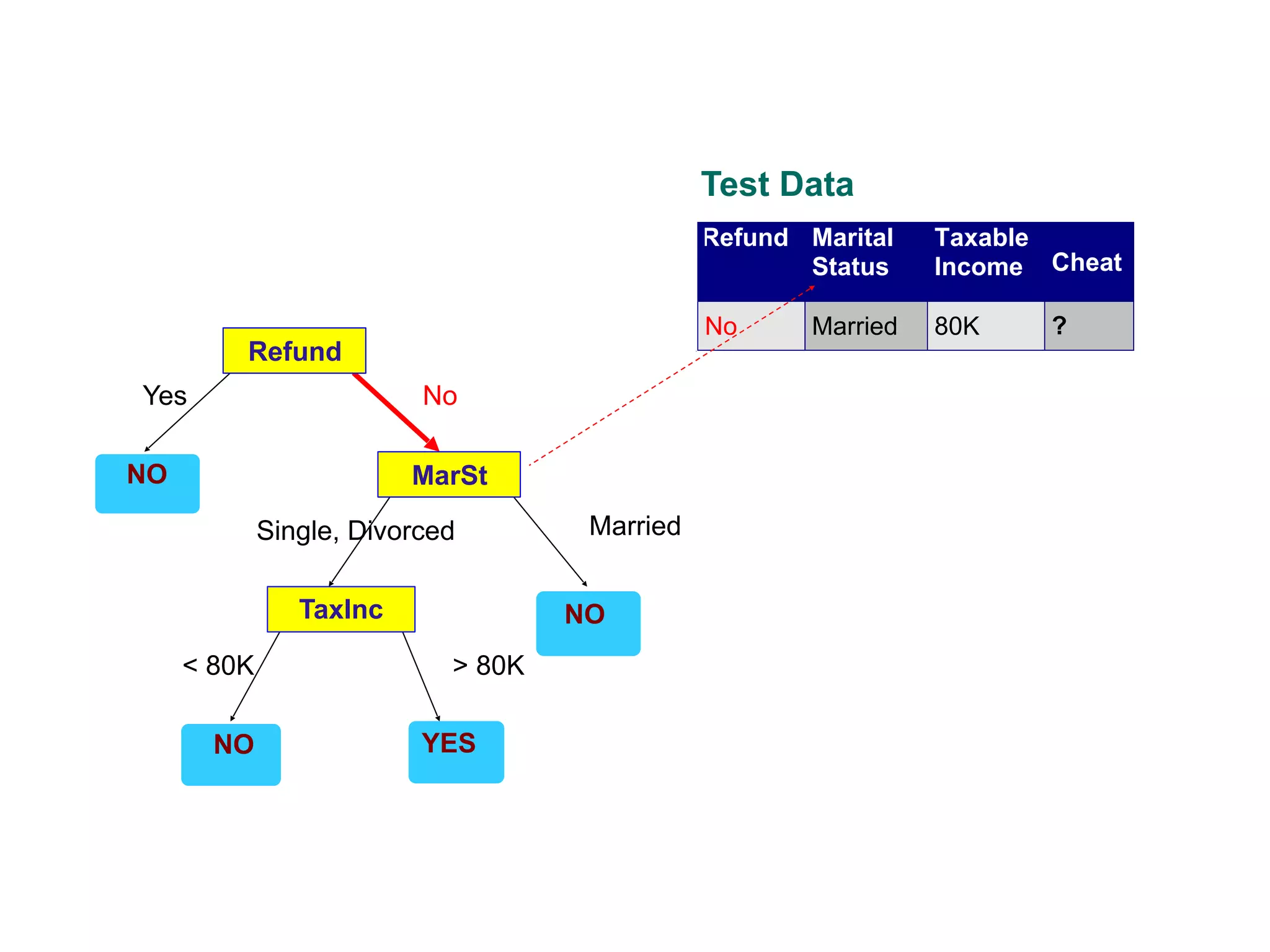
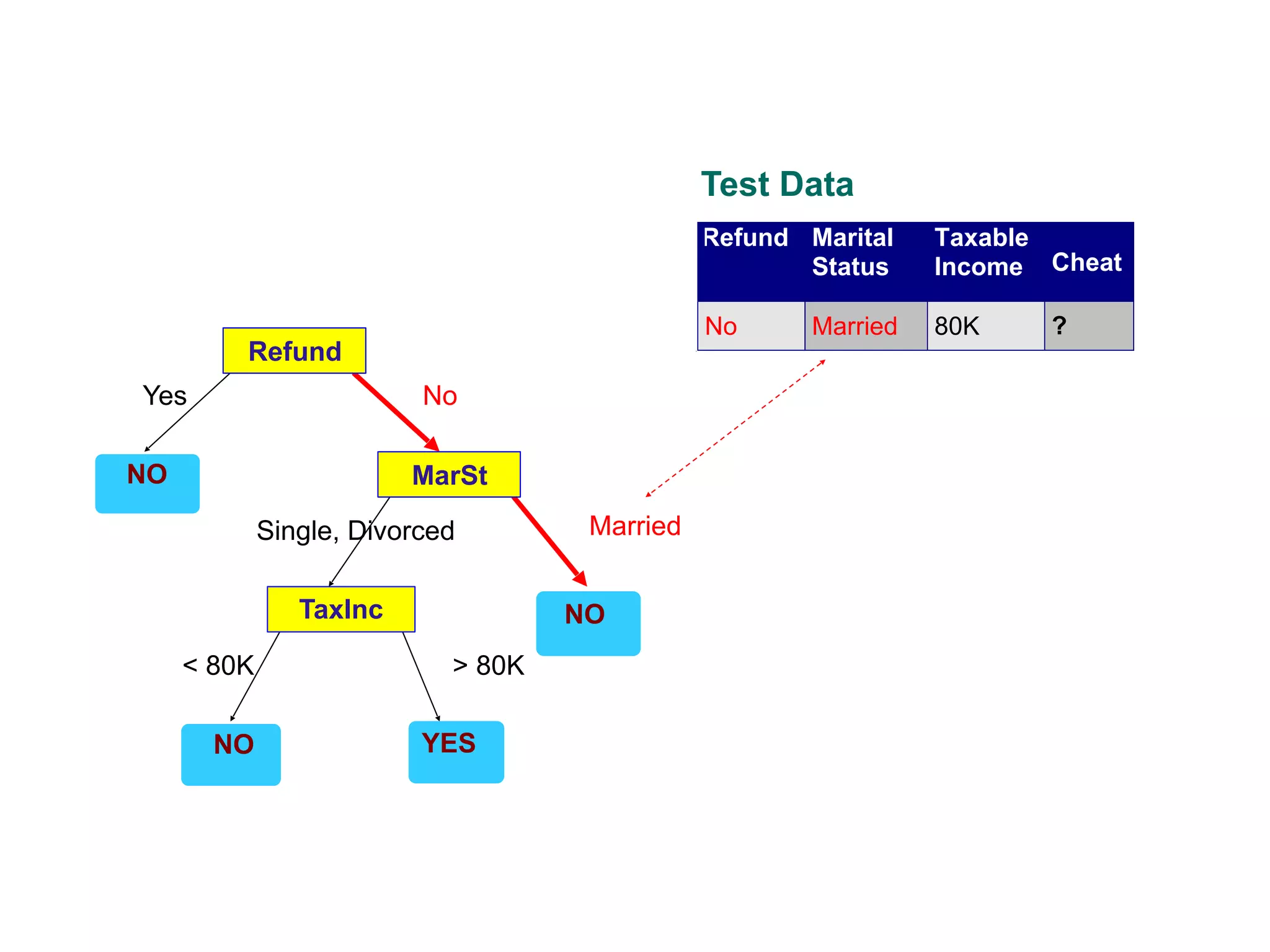
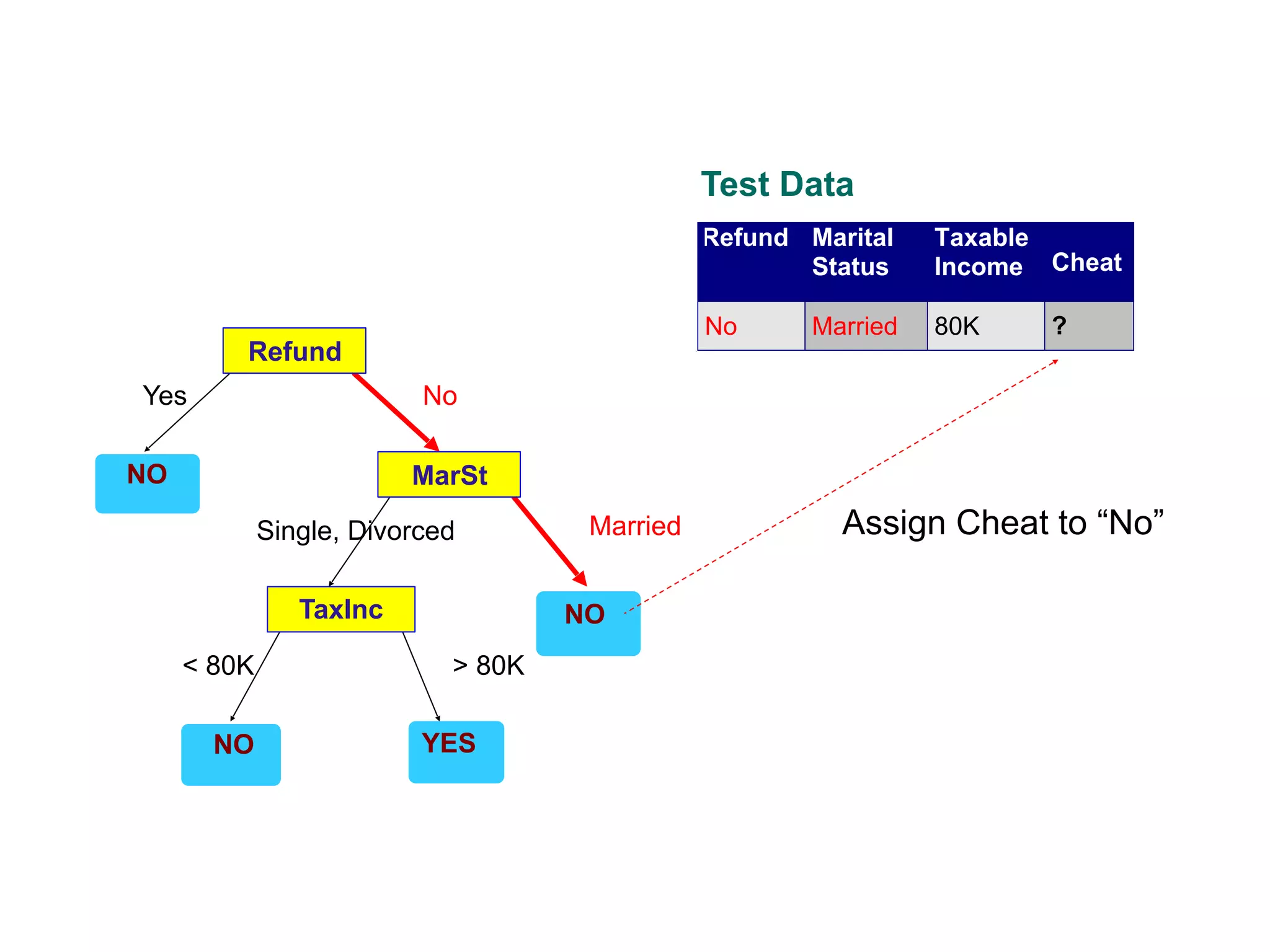
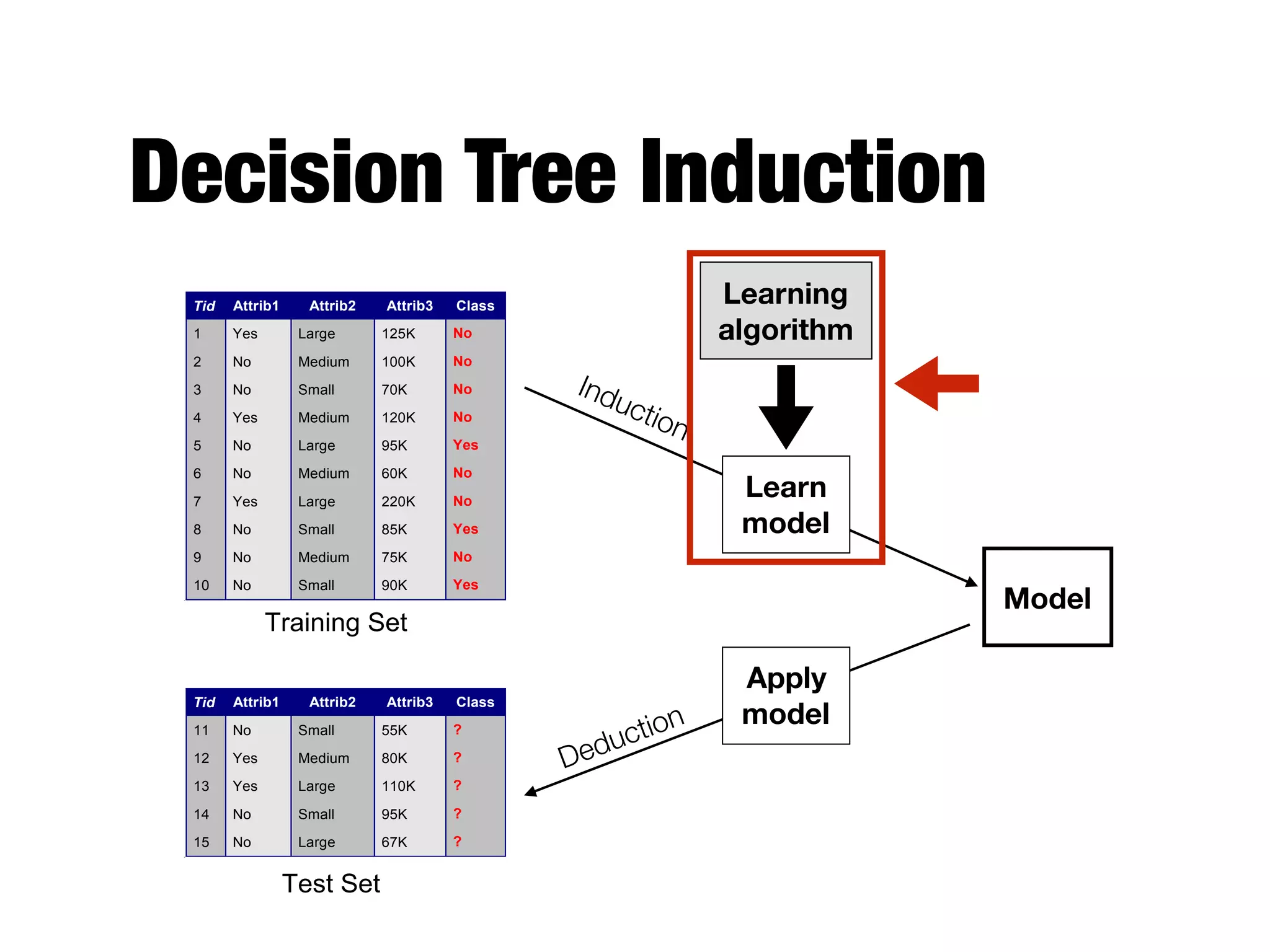






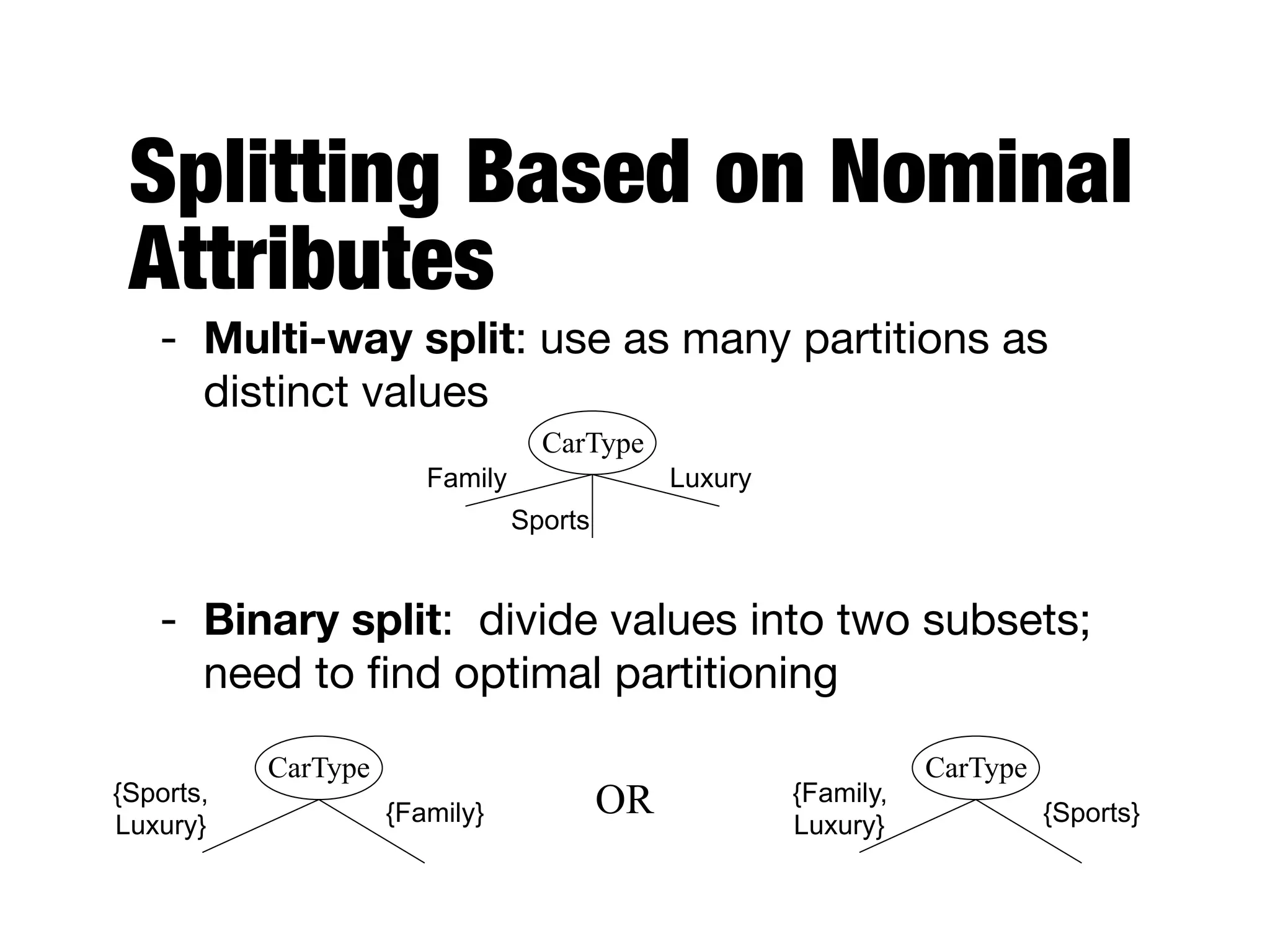
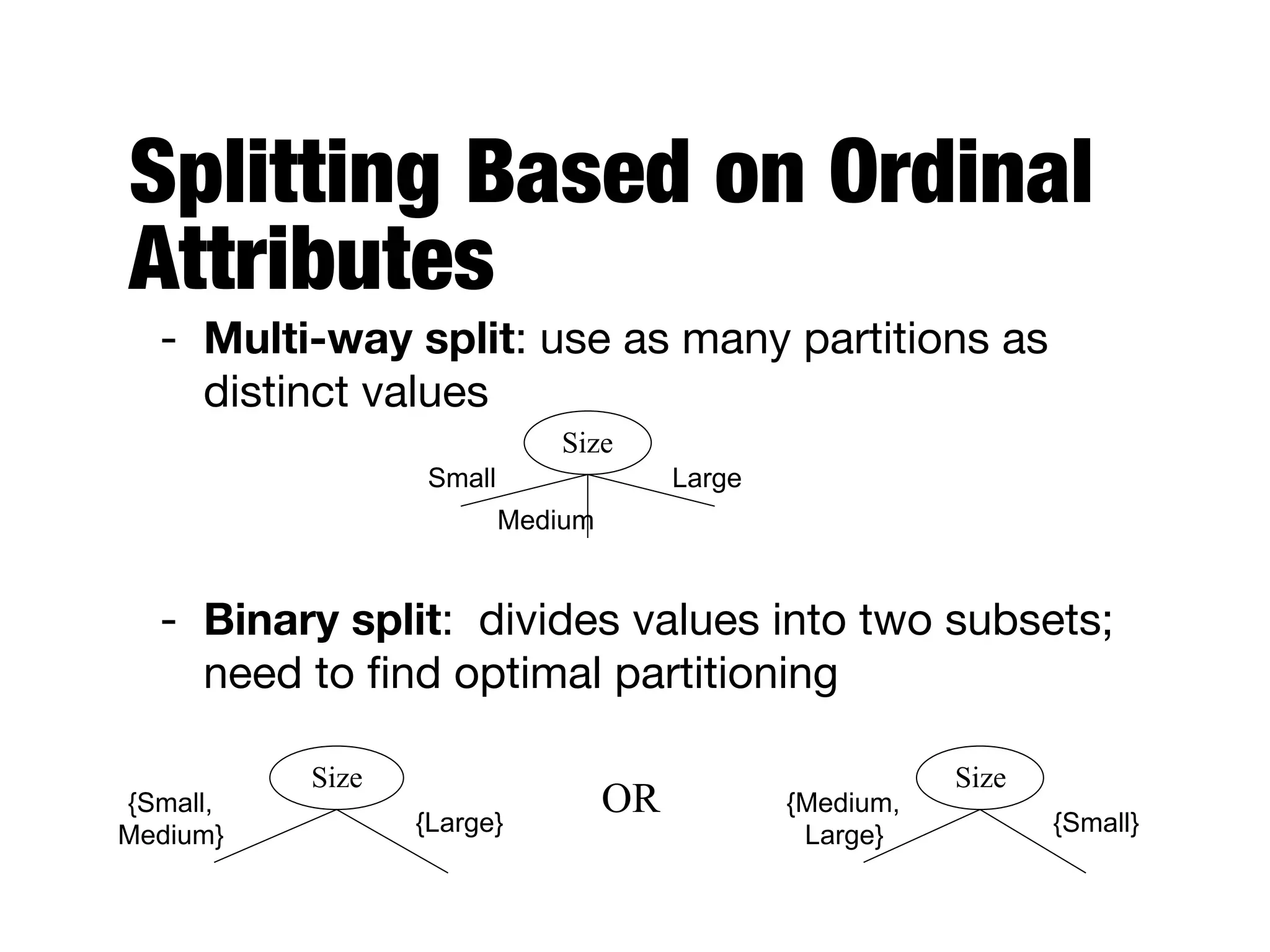







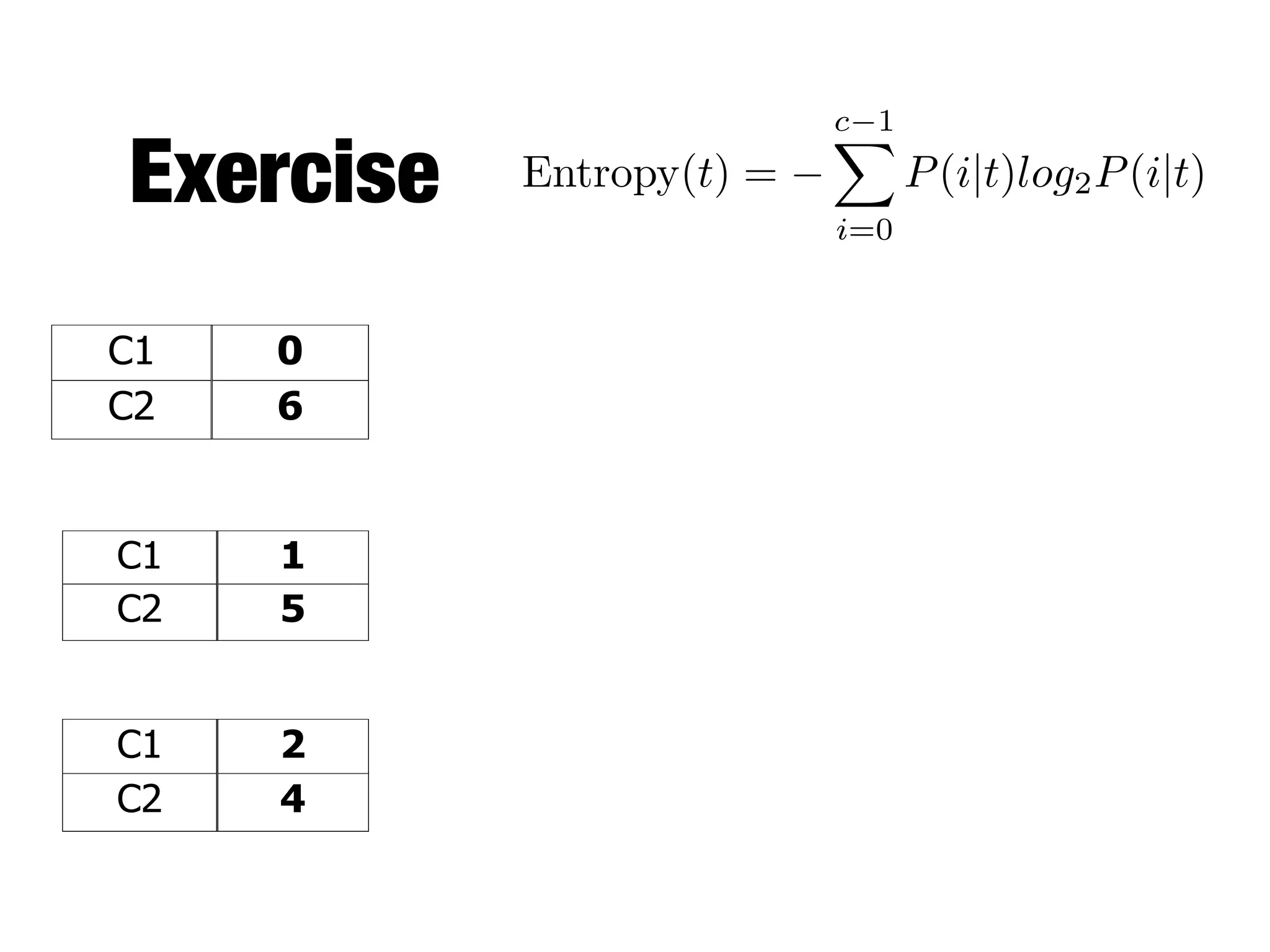



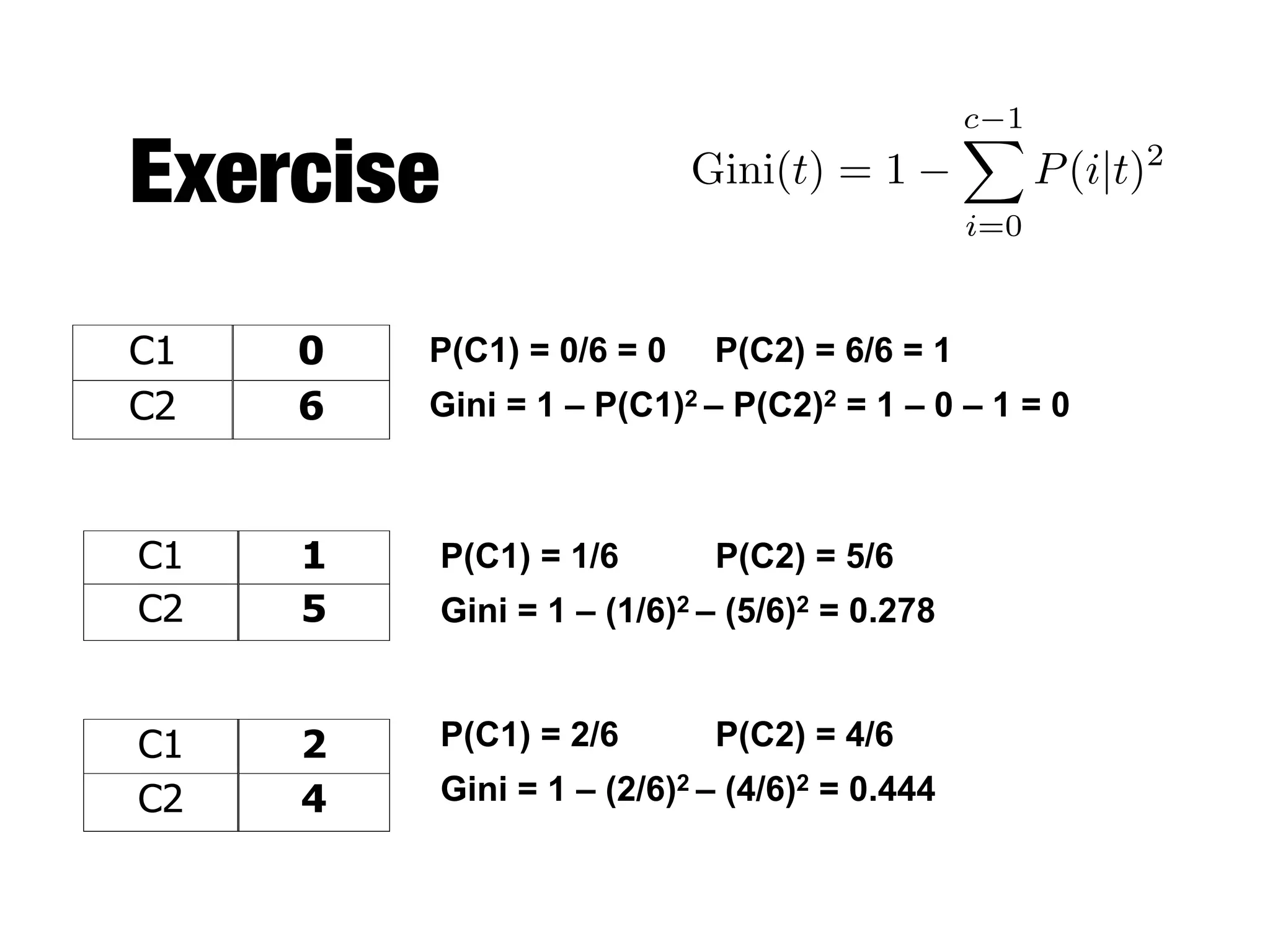



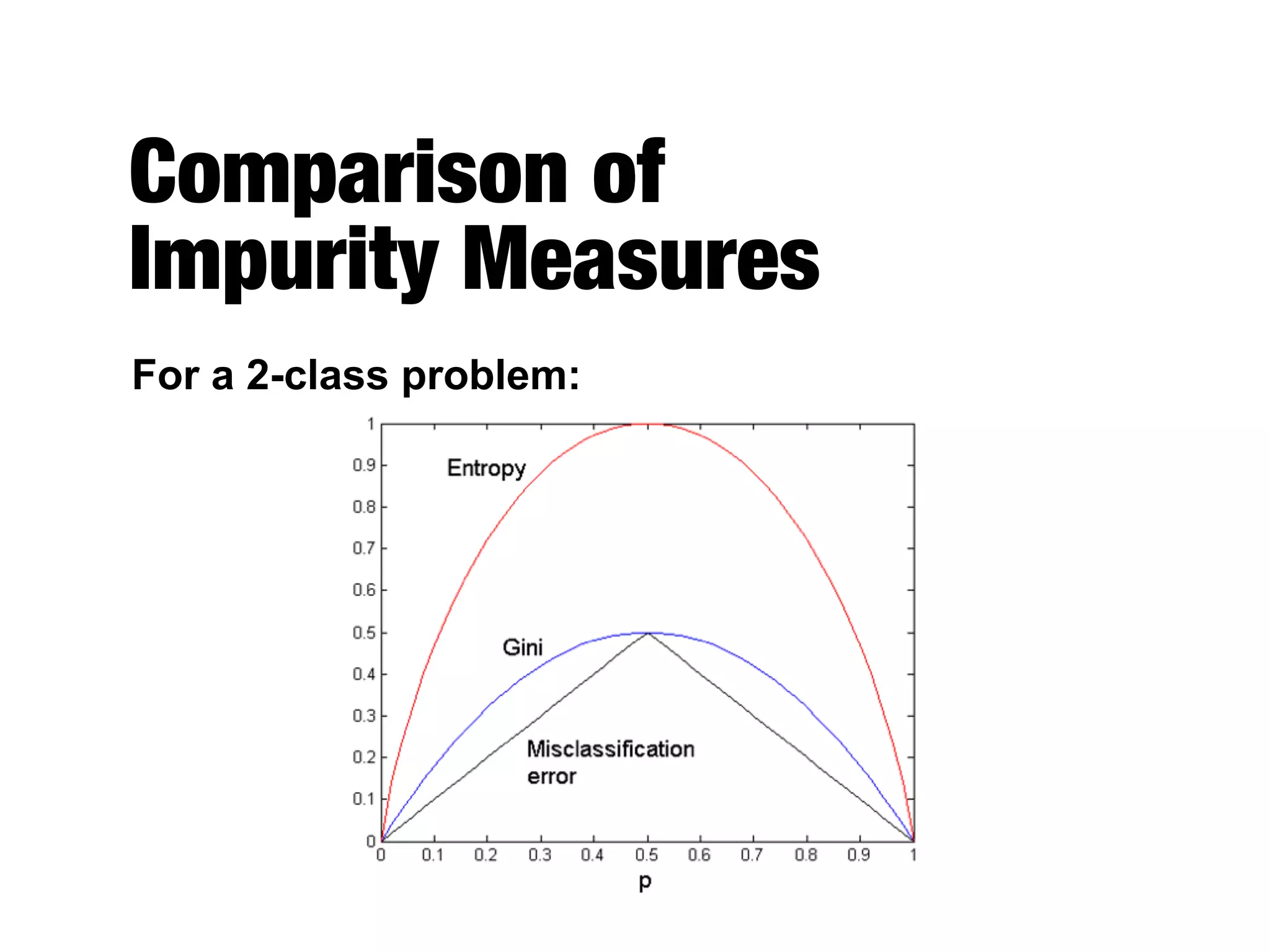
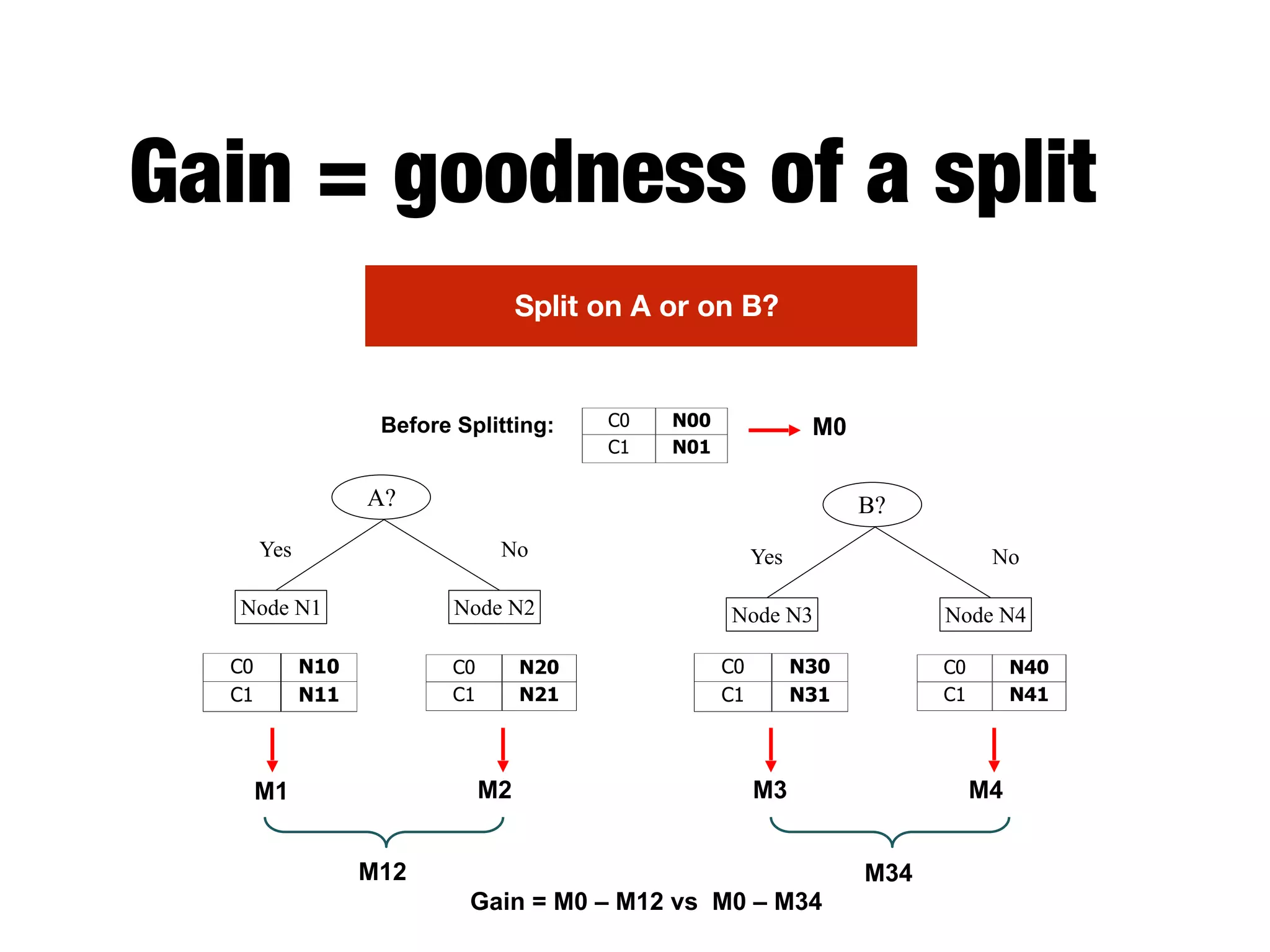
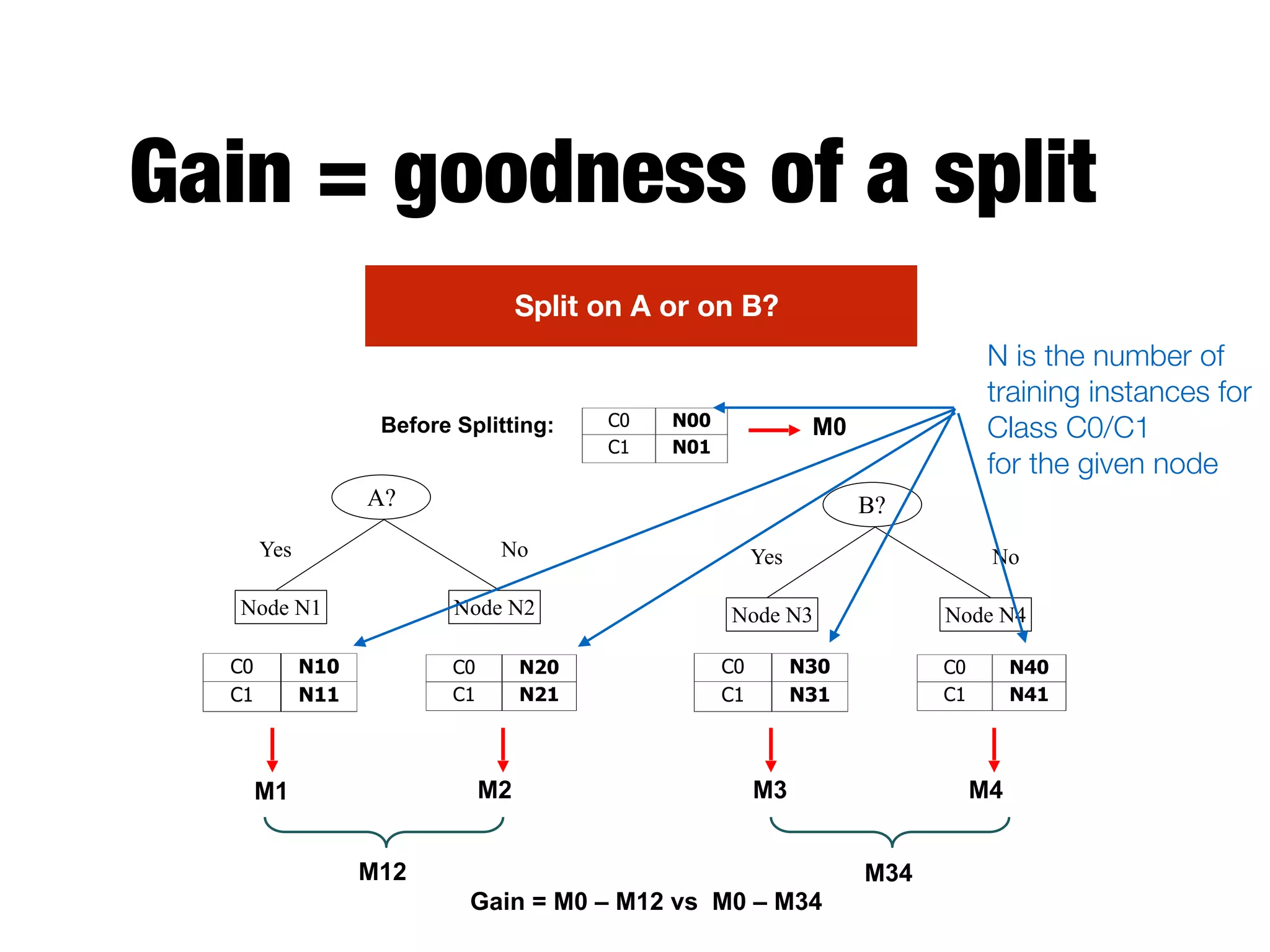
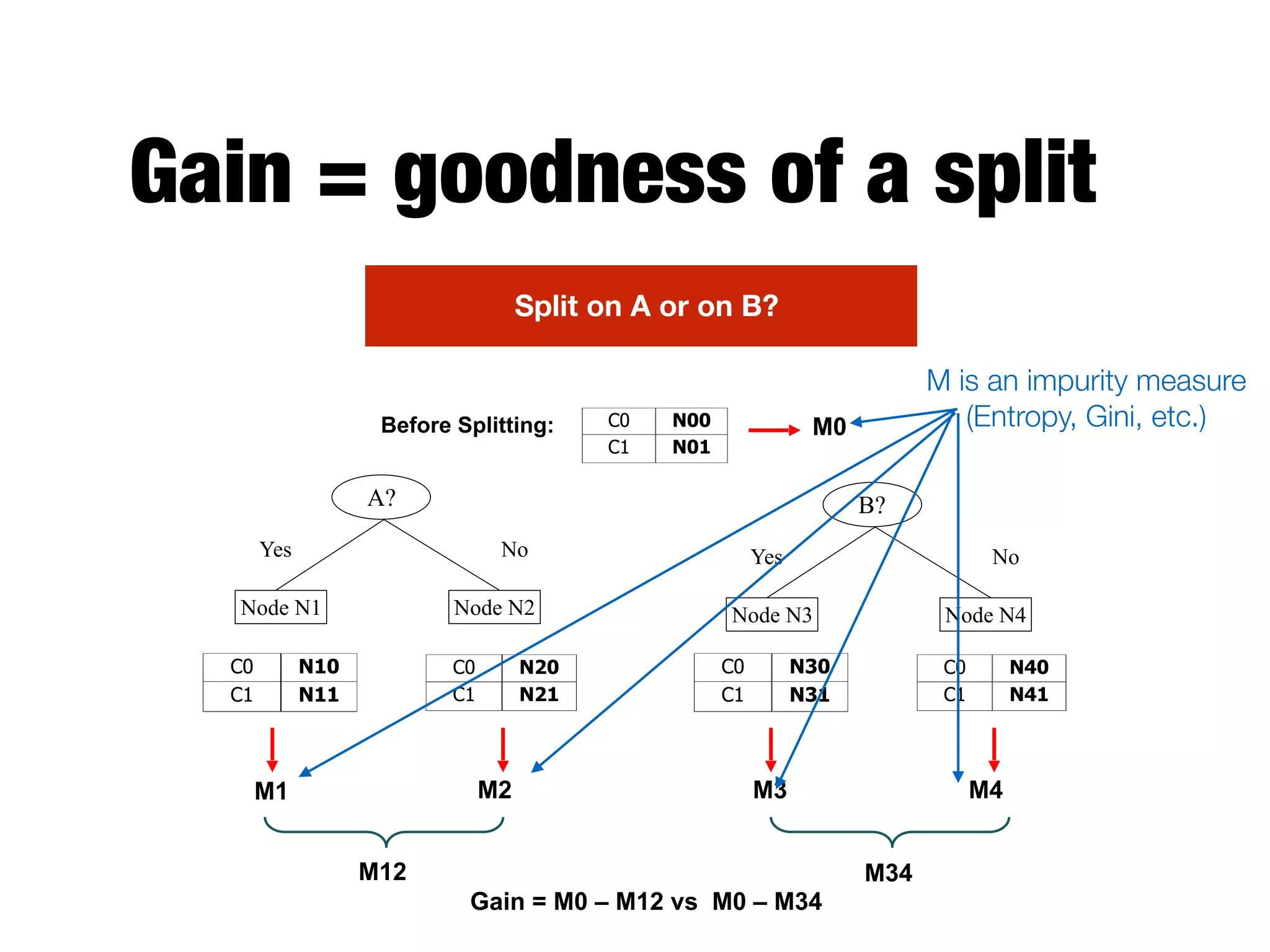
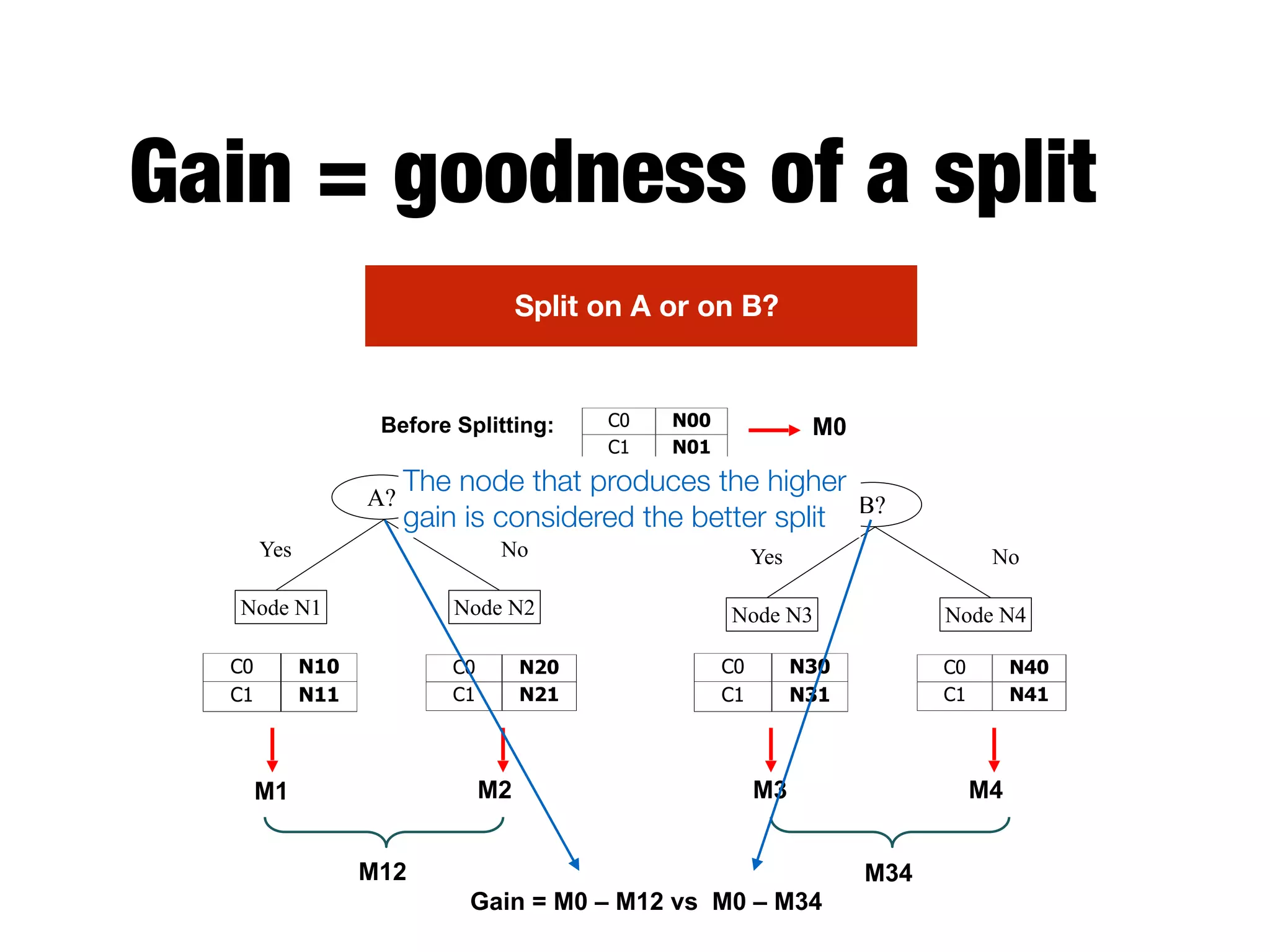
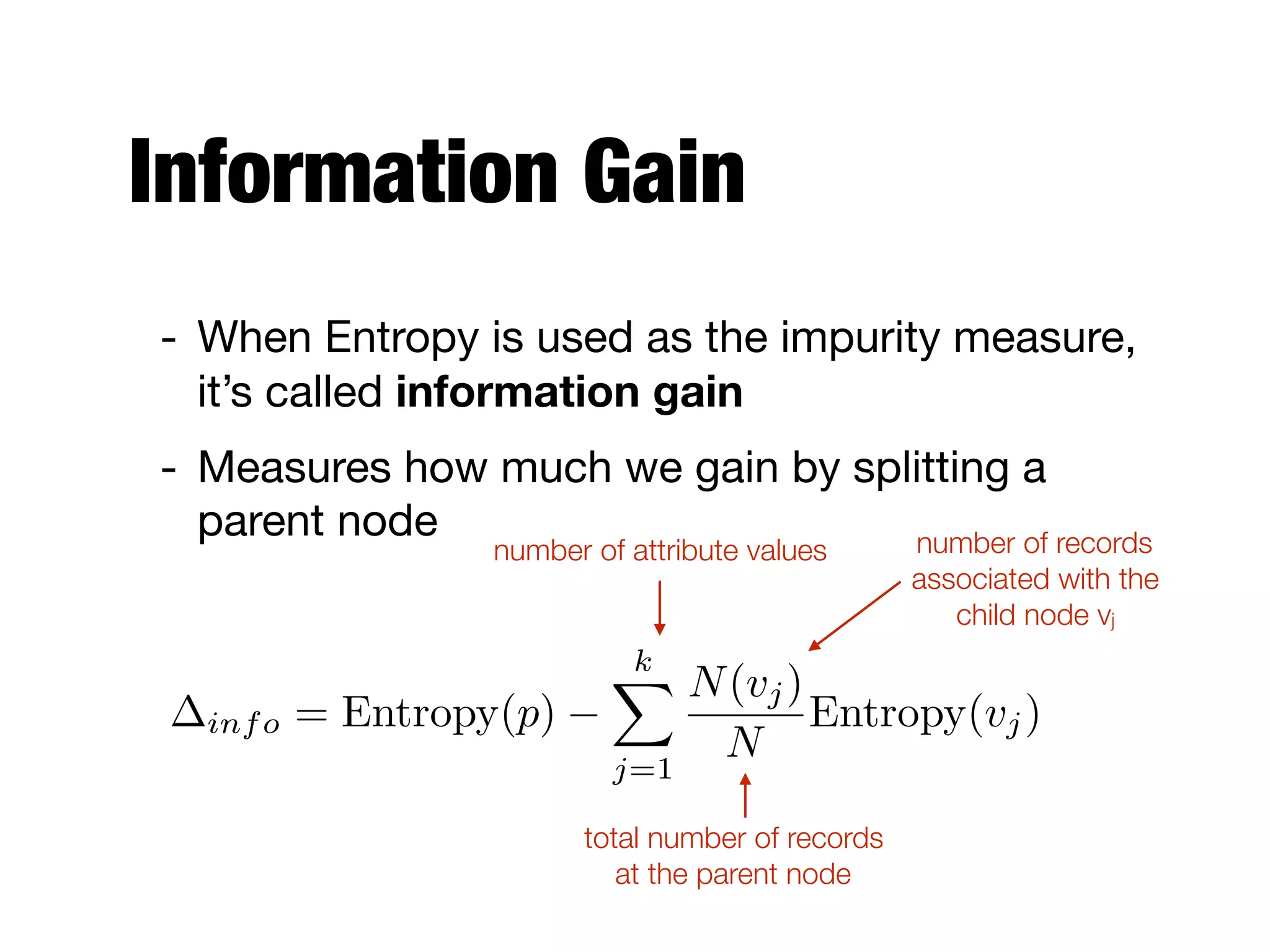






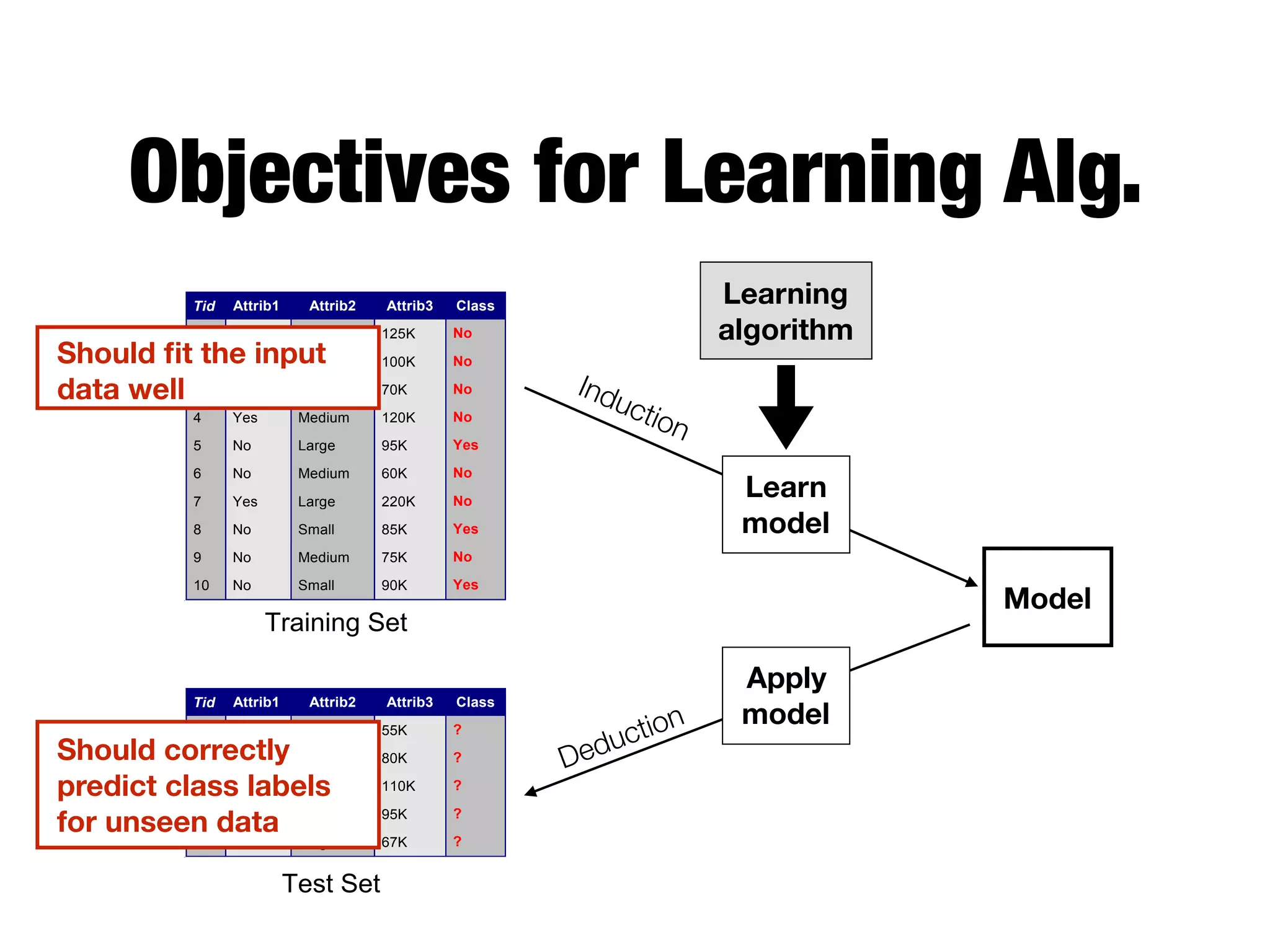
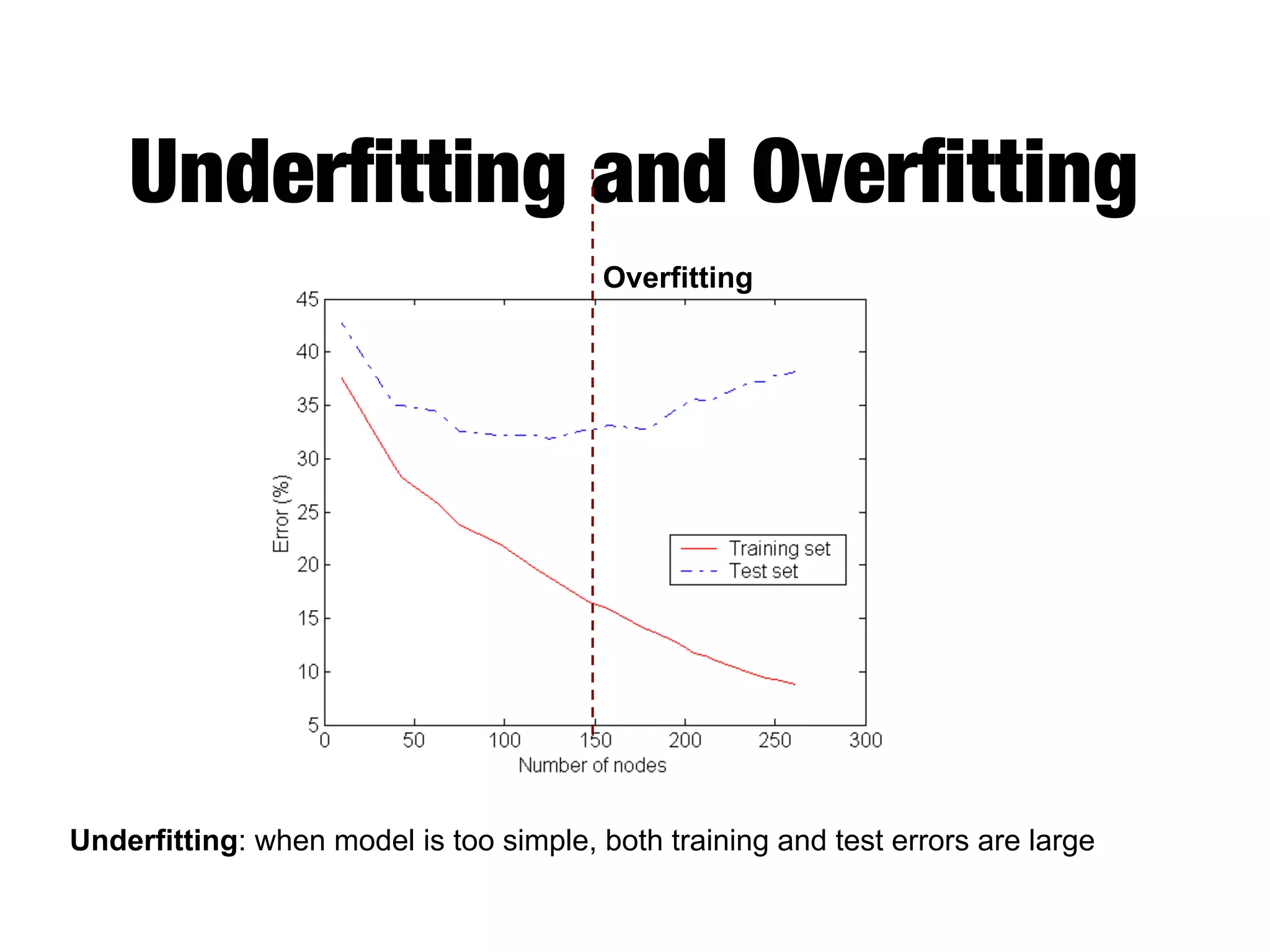



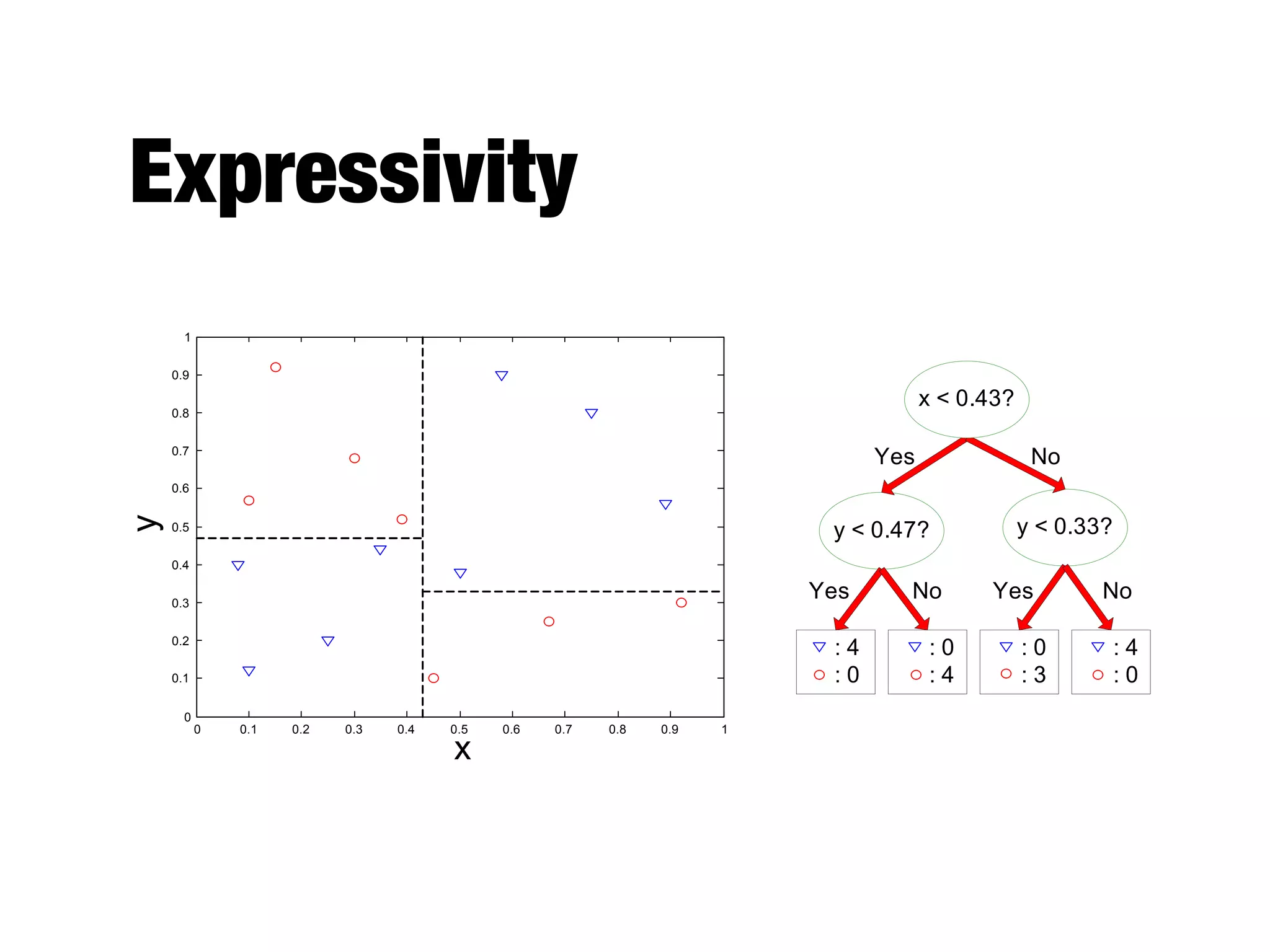
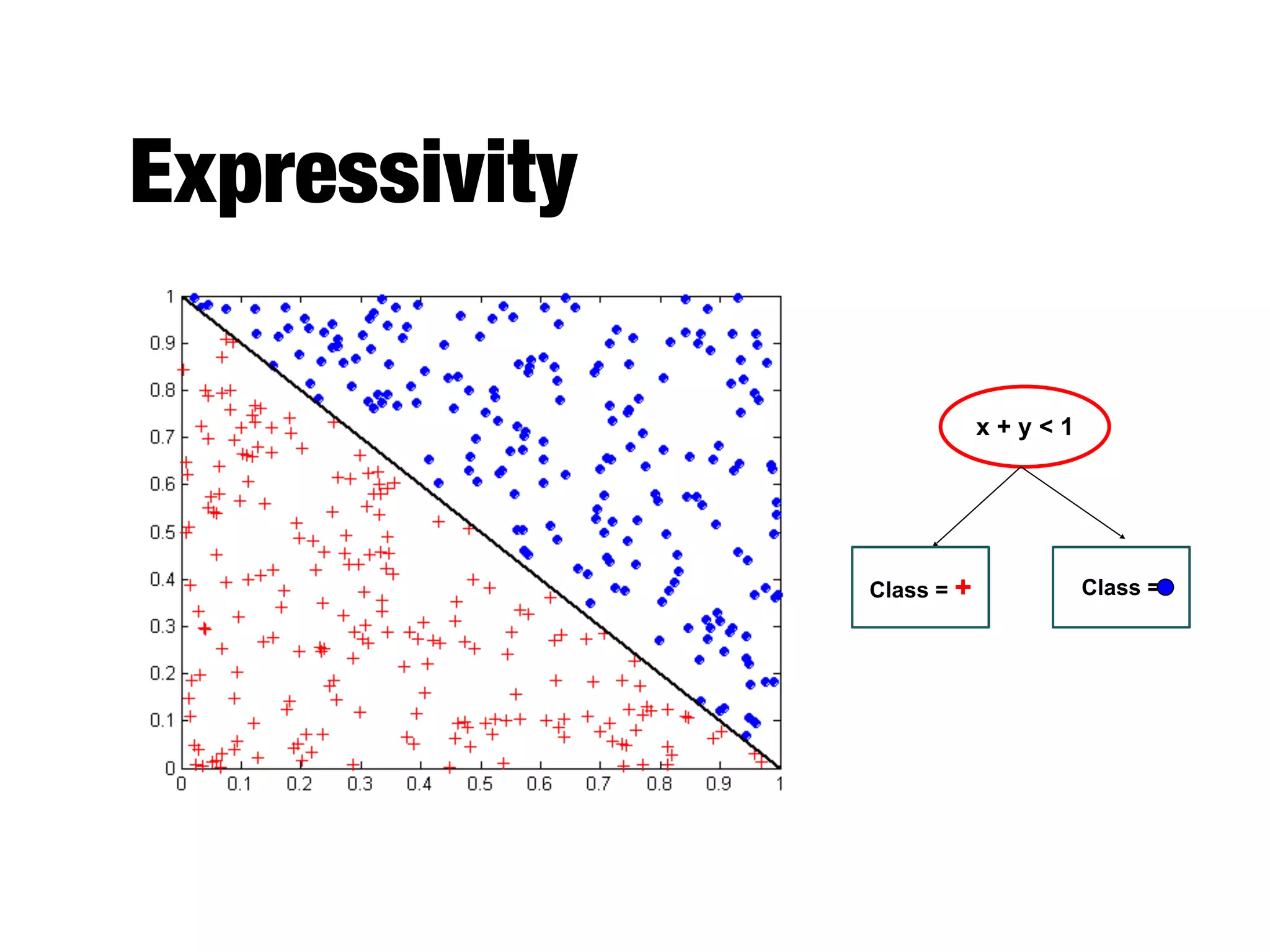


This document provides an overview of classification in data mining, focusing on the task of assigning objects to predefined categories using various algorithms like decision trees, rule-based methods, and support vector machines. It discusses the importance of model evaluation through metrics such as accuracy and the use of confusion matrices to assess classifier performance. Key concepts include the learning process, decision tree induction, and the criteria for splitting data to optimize classification results.



































































