Download as PDF, PPTX


















![Integration is the key element, example vulnerability in one of the systems:
POST /voice_auth HTTP/1.1
(…)
-----boundary12345
Content-disposition: form-data; name=d
Content-type: audio/x-wav
[WAV file]
-----boundary12345
Content-disposition: form-data; name=f
Content-Type: text/plain
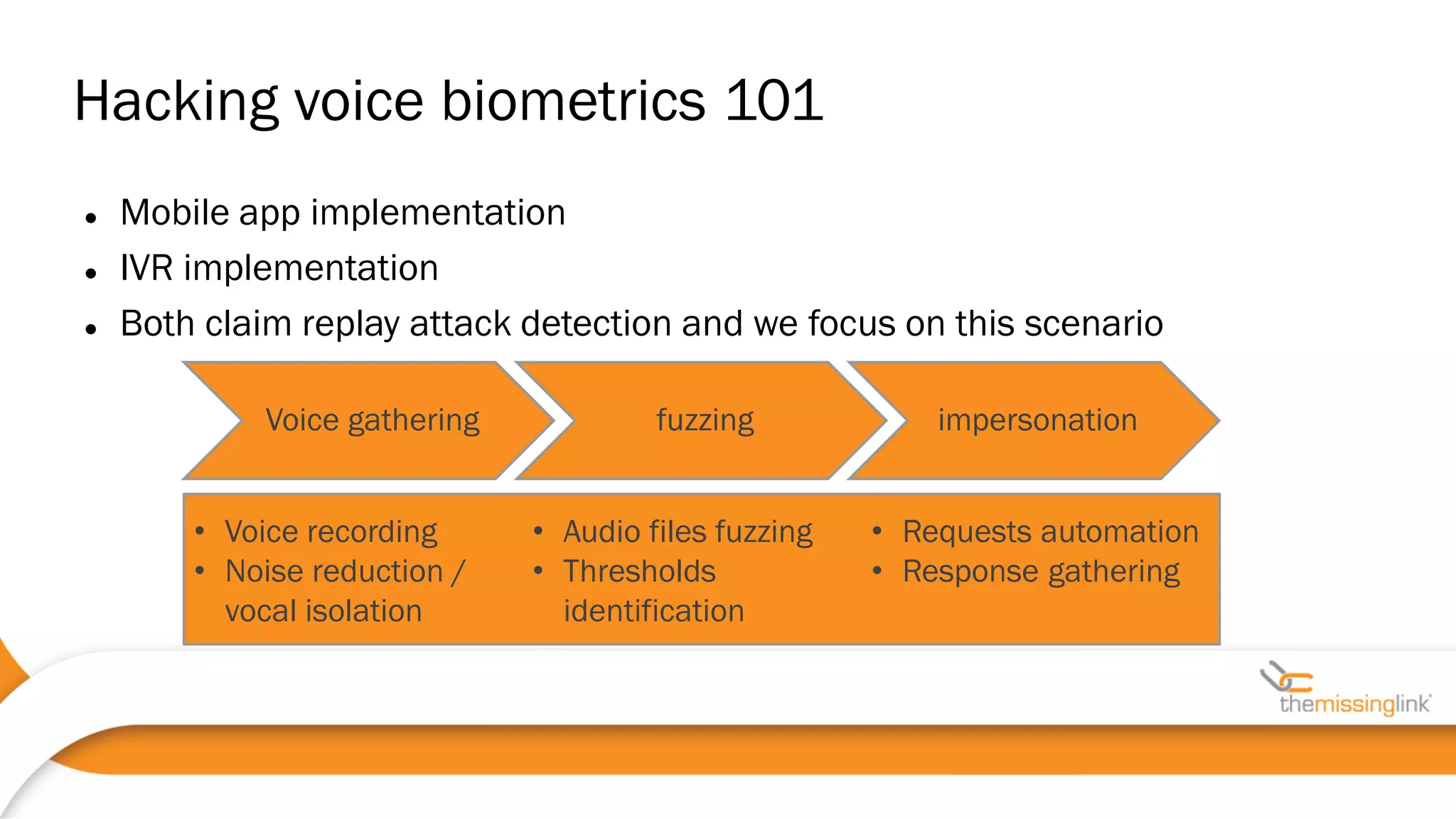
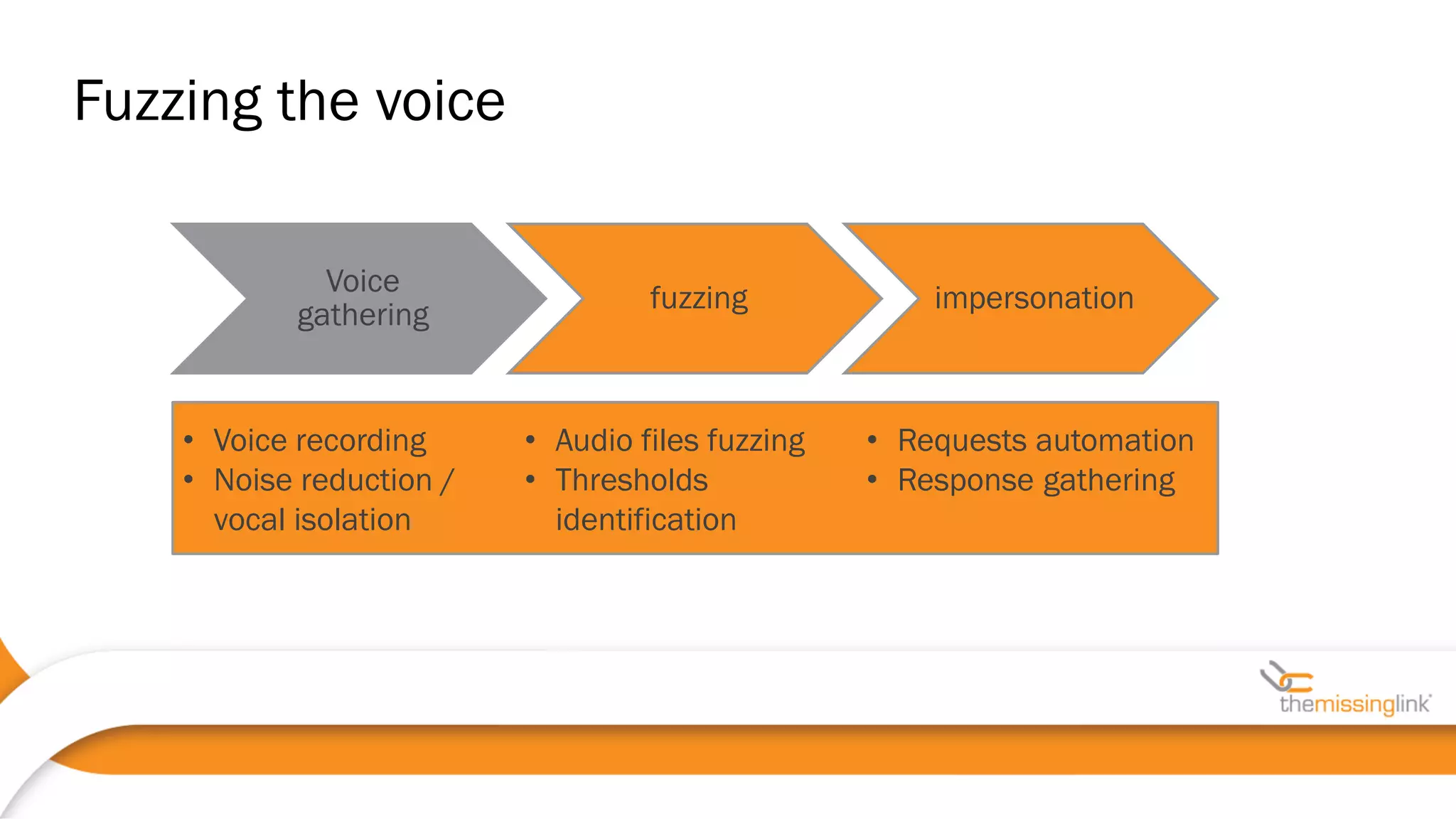
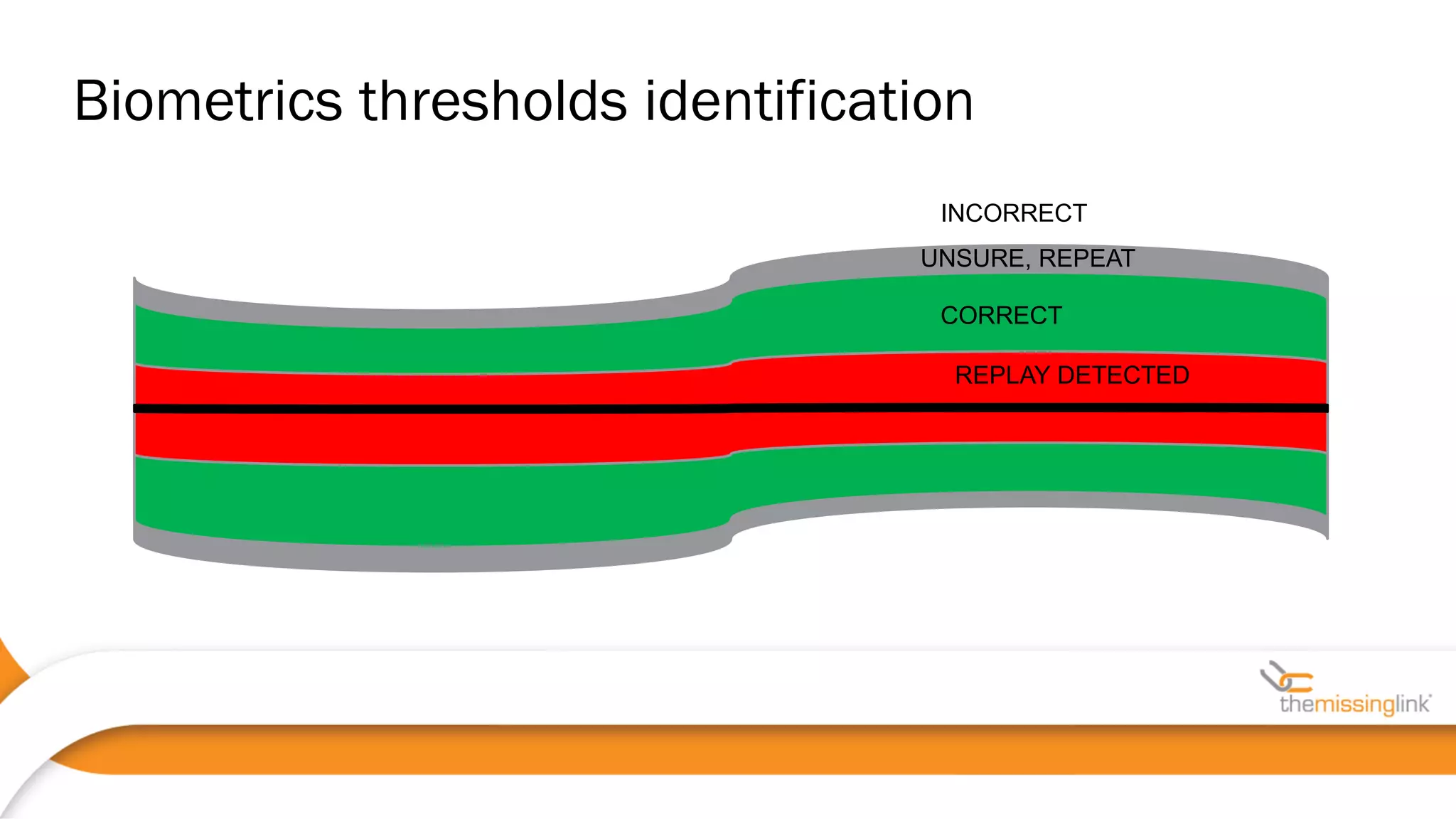
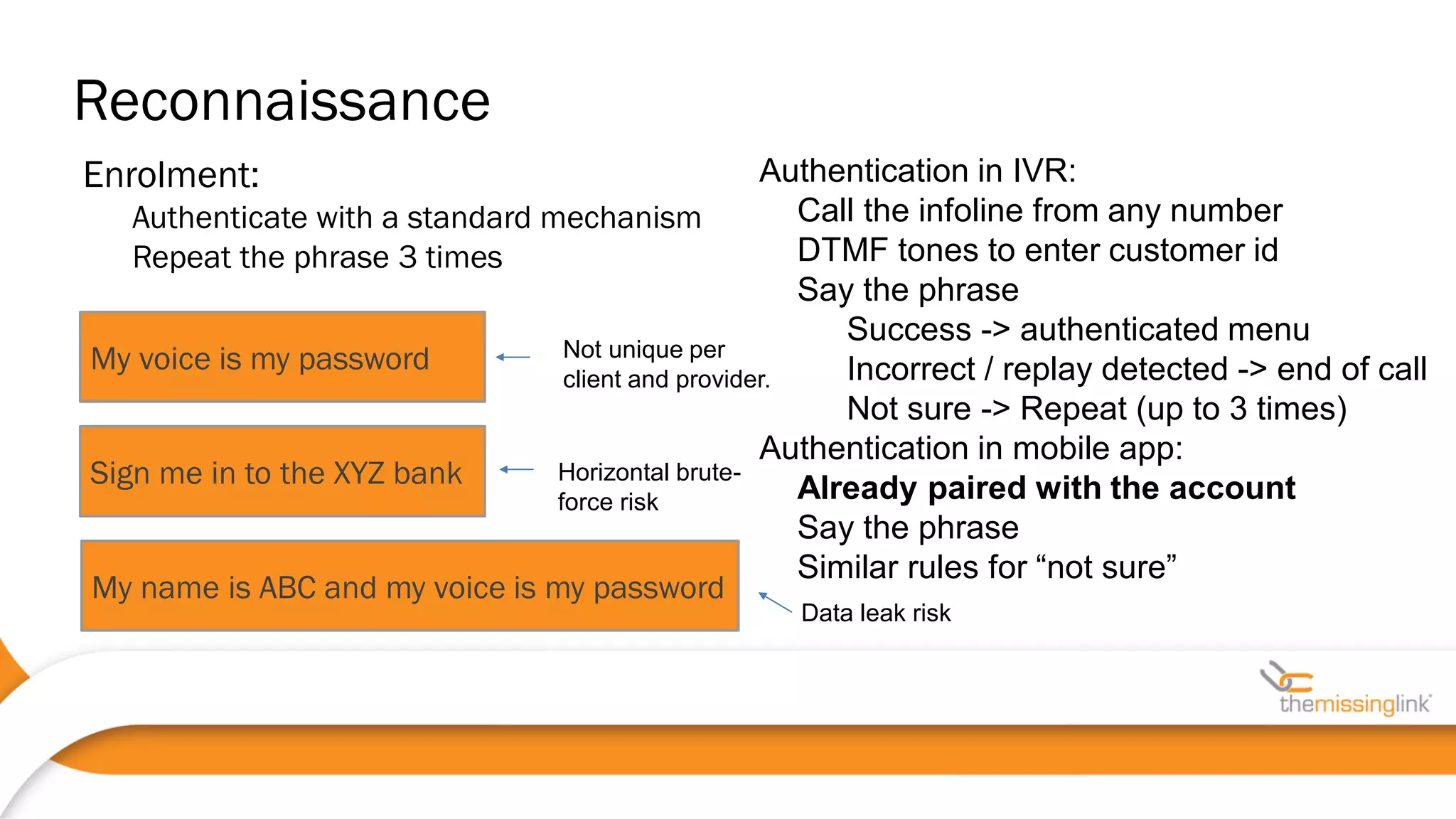
44100 • Often, voice biometrics as a separate box
• Web/IVR/mobile code as a third-party lib, SDLC?
• HTTPS requests may have another endpoint (possible MiTM)
• Voice-authenticated sessions should be distinguished from
standard ones !
2MB file limit but
f=1 DoSed the system
Mobile applications](https://image.slidesharecdn.com/kaluznypentesting-voice-biometricsauscert2017-170528230458/75/Pentesting-voice-biometrics-solutions-AusCERT-2017-39-2048.jpg)



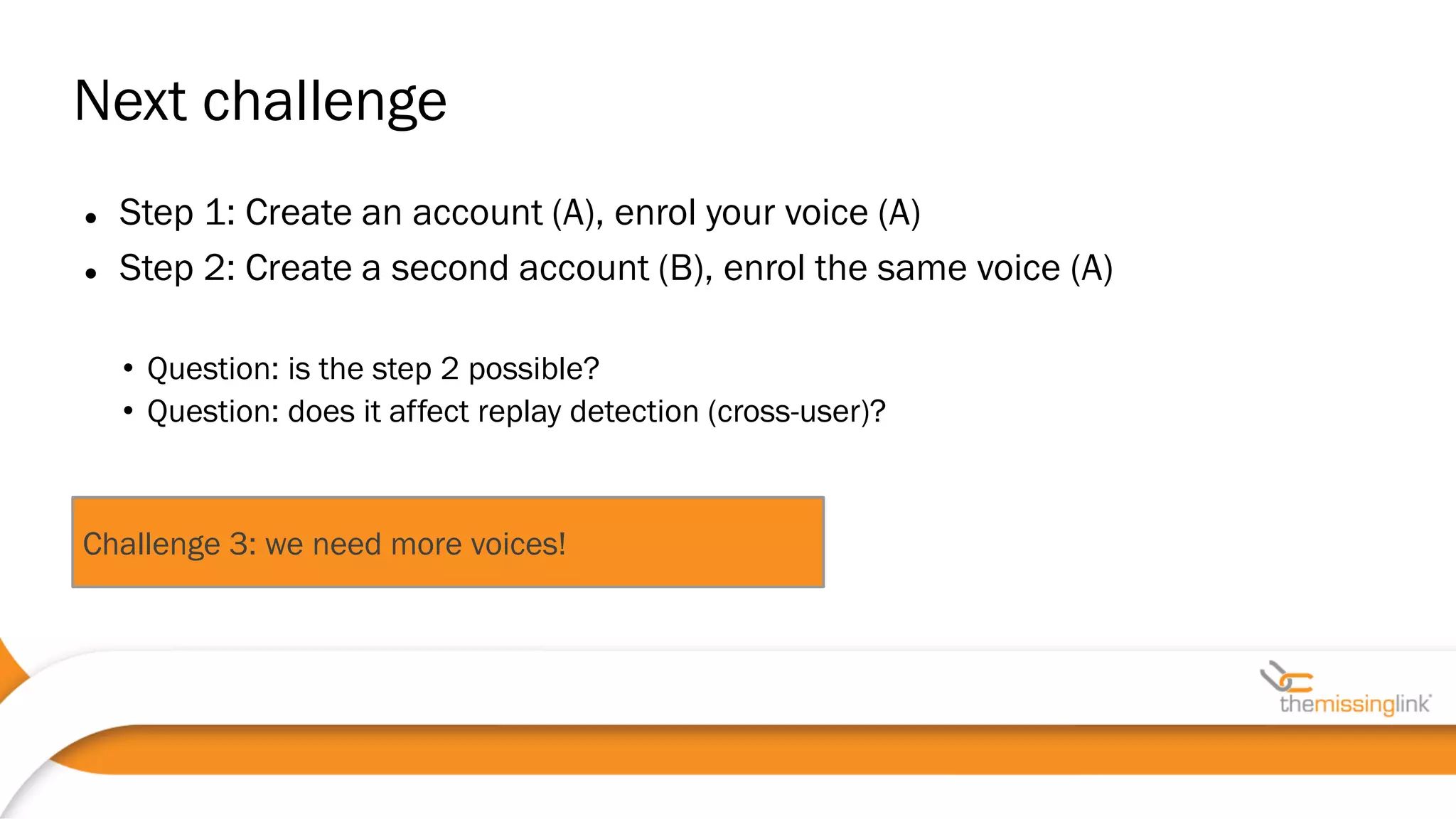
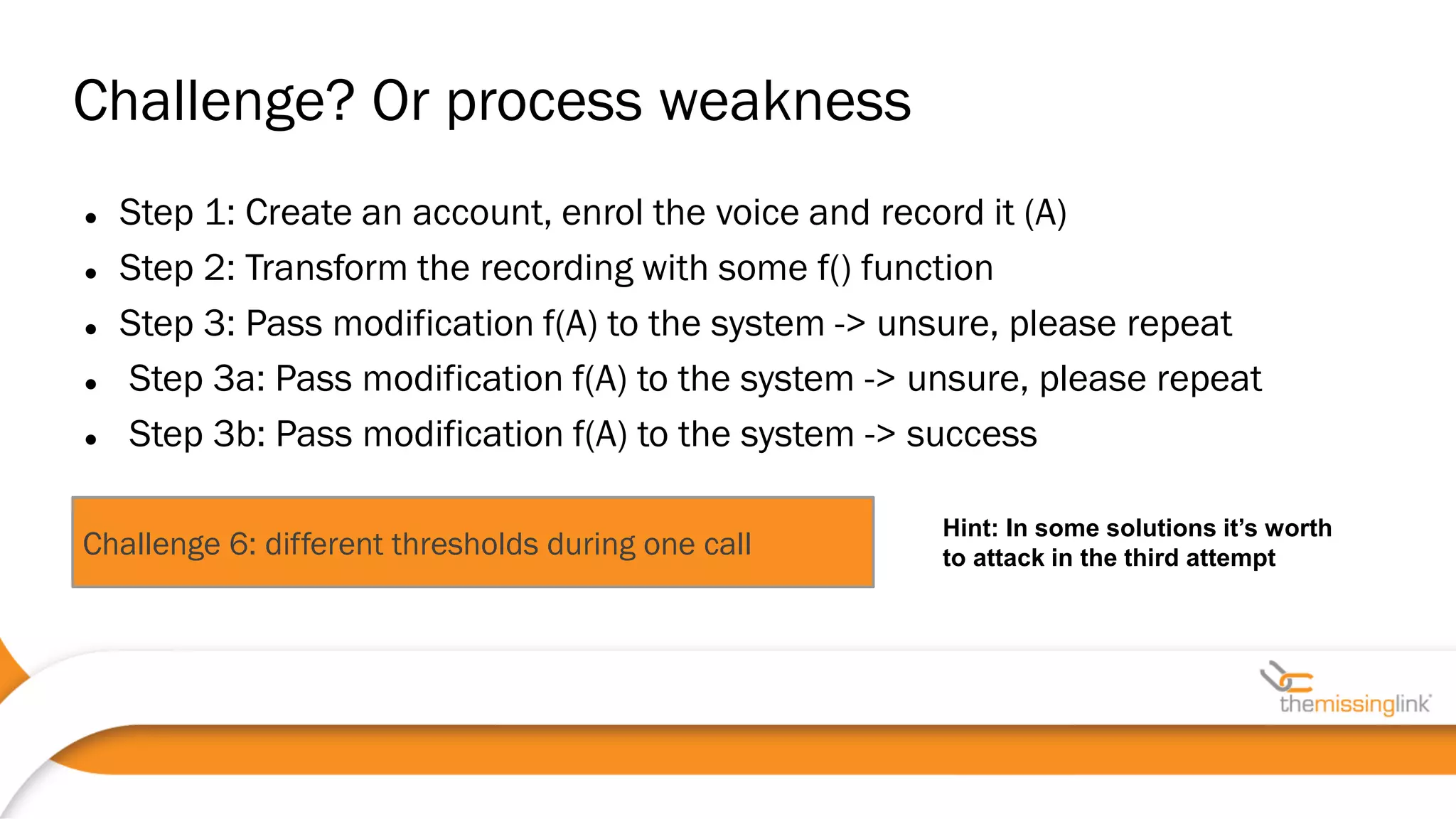
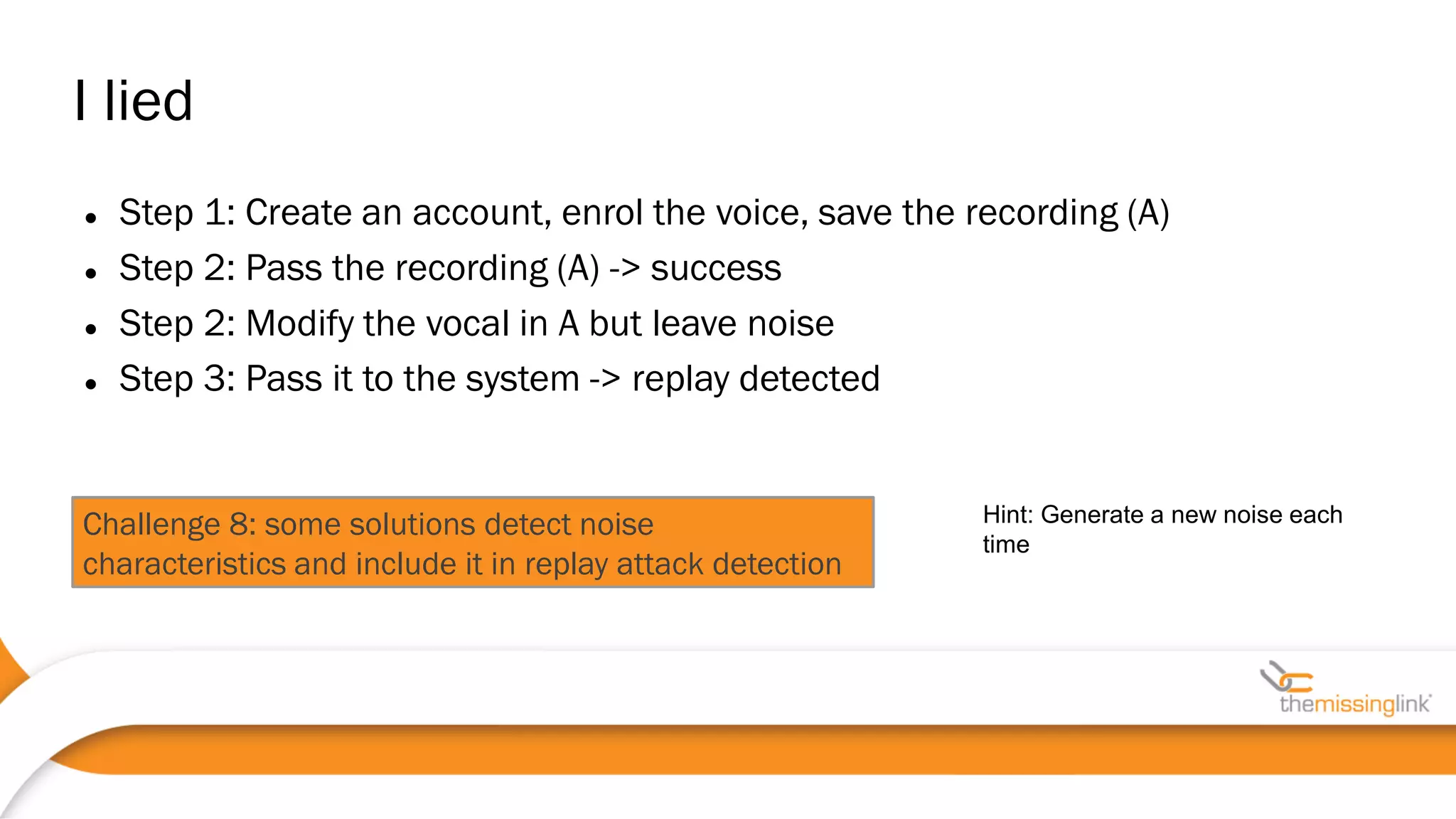
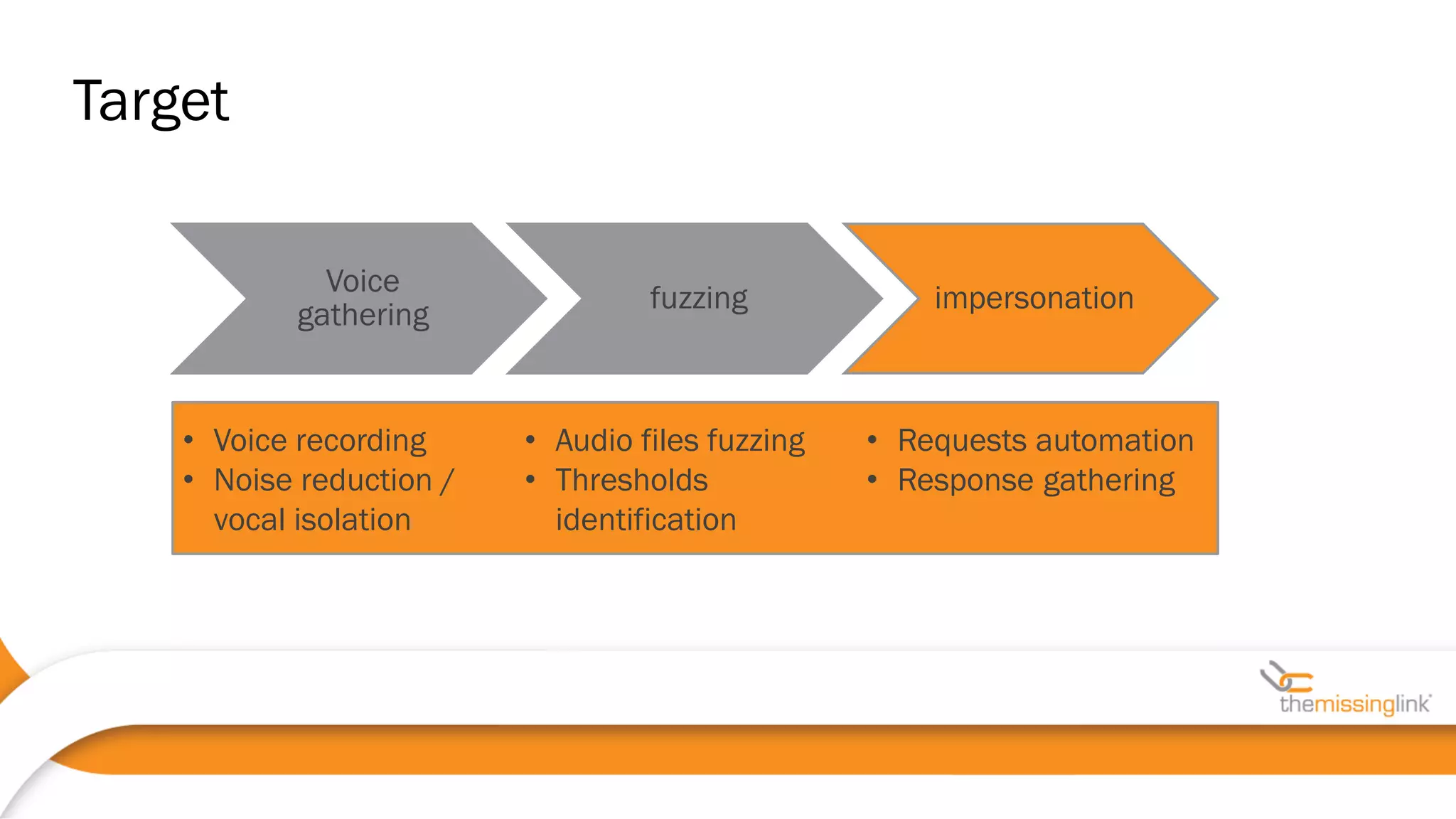
Jakub Kaluzny discusses the security challenges and potential vulnerabilities in voice biometrics systems, emphasizing the importance of pentesting due to the non-deterministic nature of such systems. The paper outlines various attack vectors, challenges in voice authentication, and the need for rigorous testing to ensure security. It concludes by highlighting collaboration with vendors and privacy movements as essential in addressing non-functional security requirements.
![RRP-PPT[1].pptxTransposition techniques in NSC](https://cdn.slidesharecdn.com/ss_thumbnails/rrp-ppt1-250821042709-9b6623cb-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




