Downloaded 12 times
![V.Kavitha, Dr.M.Punithavalli / International Journal of Engineering Research and
Applications (IJERA) ISSN: 2248-9622 www.ijera.com
Vol. 3, Issue 1, January -February 2013, pp.1627-1633
Evaluating Cluster Quality Using Modified Density Subspace
Clustering Approach
V.Kavitha1, Dr.M.Punithavalli2,
1
Research Scholar, Dept of Computer Science, Karpagam University Coimbatore, India.
2
Director,Dept of MCA, Sri Ramakrishna College of Engineering Coimbatore, India.
Abstract
Clustering of the time series data faced Identifying the groups of similar objects and helps to
with curse of dimensionality, where real world discover distribution of patterns, finding the
data consist of many dimensions. Finding the interesting correlations in large data sets. It has been
clusters in feature space, subspace clustering is a subject of wide research since it arises in many
growing task. Density based approach to identify application domains in engineering, business and
clusters in dimensional point sets. Density social sciences. Especially, in the last years the
subspace clustering is a method to detect the availability of huge transactional and experimental
density-connected clusters in all subspaces of high data sets and the arising requirements for data
dimensional data for clustering time series data mining created needs for clustering algorithms that
streams Multidimensional data clustering scale and can be applied in diverse domains.
evaluation can be done through a density-based
approach. In this approach proposed, Density The clustering of the times series data
subspace clustering algorithm is used to find best streams becomes one of the important problem in
cluster result from the dataset. Density subspace data mining domain. Most of the traditional
clustering algorithm selects the P set of attributes algorithms will not support the fast arrival of large
from the dataset. Then apply the density amount of data stream. In several traditional
clustering for selected attributes from the algorithms, a few one-pass clustering algorithms
dataset .From the resultant cluster calculate the have been proposed for the data stream problem.
intra and inter cluster distance. Measuring the These methods address the scalability issues of the
similarity between data objects in sparse and clustering problem and evolving the data in the
high-dimensional data in the dataset, Plays a very result and do not address the following issues:
important role in the success or failure of a
clustering method. Evaluate the similarity (1)The quality of the clusters is poor when the data
between data points and consequently formulate evolves considerably over time.
new criterion functions for clustering .Improve
the accuracy and evaluate the similarity between (2) A data stream clustering algorithm requires much
the data points in the clustering,. The proposed greater functionality to discovering accurate result
algorithm also concentrates the Density and exploring clusters over different portions of the
Divergence Problem (Outlier). Proposed system stream.
clustering results compared them with existing Charu C. Aggarwal [5] proposed micro-
clustering algorithms in terms of the Execution clustering phase in the online statistical data
time, Cluster Quality analysis. Experimental collection portion of the algorithm. This method is
results show that proposed system improves not dependent on any user input such as the time
clustering quality result, and less time than the horizon or the required granularity of the clustering
existing clustering methods. process. The aim of the method is to maintain
statistics based on sufficiently high level granularity
Keywords— Density Subspace Clustering, Intra used by the online components such as horizon-
Cluster, Inter Cluster, Outlier, Hierarchical specific macro-clustering as well as evolution
Clustering. analysis.
I. INTRODUCTION The clustering of the time series data
Clustering is one of the most important stream and incremental models are requiring a
tasks in data mining process for discovering similar decisions before all the data are available in the
groups and identifying interesting distributions and dataset. The models are not identical to find the best
patterns in the underlying data. Clustering of the clustering result.
time series DataStream problem is about partitioning Finding clusters in the feature space,
a given data set into groups such that the data points subspace clustering is an emergent task. Clustering
in a cluster are more similar to each other than points with dissimilarity measure is robust method to
in different clusters .Cluster analysis [3] aims at handle large amount of data and able to estimate the
1627 | P a g e](https://image.slidesharecdn.com/ir3116271633-130226001838-phpapp01/75/Ir3116271633-1-2048.jpg)

![V.Kavitha, Dr.M.Punithavalli / International Journal of Engineering Research and
Applications (IJERA) ISSN: 2248-9622 www.ijera.com
Vol. 3, Issue 1, January -February 2013, pp.1627-1633
hierarchic methods, only a single partition of the system splits the cluster and assigns each of the
dataset has to be formed. chosen variables to one of the new clusters,
Three of the main categories of non-hierarchical becoming this pivot variable for that cluster.
method are single-pass, relocation and nearest Afterwards, all remaining variables on the old
neighbour: cluster are assigned to the new cluster which has the
Single-pass methods (e.g. Leader) produce closest pivot. New leaves start new statistics,
clusters that are dependent upon the order assuming that only forthcoming information will be
in which the compounds are processed, and useful to decide whether or not this cluster should be
so will not be considered further; split. This feature increases the system's ability to
Relocation methods, such as k-means, cope with changing concepts as, later on, a test is
assigns compounds to a user-defined performed such that if the diameters of the children
number of seed clusters and then iteratively leaves approach the parent's diameter, then the
reassign compounds to see if better clusters previously taken decision may no longer recent the
result. Such methods are prone to reaching structure of data, so the system re-aggregates the
local optima rather than a global optimum, leaves on the parent node, restarting statistics. We
and it is generally not possible to determine propose our work to solve the density based
when or whether the global optimum subspace system comparing to the different densities
solution has been reached; at each of the subspace attributes system, each time
Nearest neighbor methods, such as the series data streams.
Jarvis-Patrick method, assign compounds to
the same cluster as some number of their B .Disadvantages of the existing system
nearest neighbors. User-defined parameters The split decision used in the algorithm
determine how many nearest neighbors focus only focus on measuring the distance
need to be considered, and the necessary between the two groups, which implies
level of similarity between nearest neighbor high risk to solve the density problems at
lists. different densities.
The different density at sub attribute values
III. METHODOLOGY is changes to both intra and inter cluster.
In Methodology, we discussed about the
existing system ODAC and Proposed System of C.IHCA (Improved Hierarchical Clustering
IHCA and MDSC algorithms. Algorithm)
The Improved Hierarchical Clustering
A. Online Divisive Agglomerative Clustering algorithm [IHCA] is an algorithm for an incremental
The Online Divisive-Agglomerative clustering of streaming time sequence. It constructs a
Clustering (ODAC) is an incremental approach for hierarchical tree-shaped structure of clusters by
clustering streaming time series using a hierarchical using a top-down strategy. The leaves are the
procedure over time. It constructs a tree-like resulting clusters, with each leaf grouping a set of
hierarchy of clusters of streams, using a top-down variables. The system includes an incremental
strategy based on the correlation between streams. distance measure and executes procedures for
The system also possesses an agglomerative phase to expansion and aggregation of the tree based
enhance a dynamic behaviour capable of structural structure. The system will be monitoring the flow of
change detection. The ODAC (Online Divisive- continuous time series data. Then time interval will
Agglomerative Clustering) system is a variable be fixed. Within the specific time interval the data
clustering algorithm that constructs a hierarchical points will be partitioned. In a partition the diameter
tree-shaped structure of clusters using a top-down is calculated. Diameter is nothing but the maximum
strategy. The leaves are the resulting clusters, with a distance between the two points. Each and every
set of variables at each leaf. The union of the leaves data point of the partition will be compare with the
is the complete set of variables. The intersection of diameter value. If the data point is greater than the
leaves is the empty set. The system encloses an diameter value then the split process will be execute
incremental distance measure and executes otherwise the Aggregate (Merge) process will be
procedures for expansion and aggregation of the performed. Based on the above criteria the
tree-based structure, based on the diameters of the hierarchical tree will be growing. Here we have to
clusters. The main setting of our system is the observe the splitting process, because the splitting
monitoring of existing cluster's diameters. In a will decide the growth of clusters. In the proposed
divisive hierarchical structure of clusters, technique the Hoeffding Bound is used for to
considering stationary data streams, the overall intra- observe the splitting process. In IHCA the technique
cluster dissimilarity should decrease with each split. unequality vapnik Chervonenkis is used for splitting
For each existing cluster, the system finds the two process. Using this technique the observation of
variables defining the diameter of that cluster. If a splitting process is improved. So, the cluster is
given heuristic condition is met on this diameter, the grouping properly.
1629 | P a g e](https://image.slidesharecdn.com/ir3116271633-130226001838-phpapp01/75/Ir3116271633-3-2048.jpg)
![V.Kavitha, Dr.M.Punithavalli / International Journal of Engineering Research and
Applications (IJERA) ISSN: 2248-9622 www.ijera.com
Vol. 3, Issue 1, January -February 2013, pp.1627-1633
Set minPts
In the Hoeffding Bound,
If (q
{
C=0
(1) best distance =0
i=1…n
Where, the observations starting that after n
independent observations of the real valued random For each unvisited point P in dataset D
mark P as visited
variable r with range R, with confidence
N = getNeighbours (P, eps)
In the proposed algorithm, the range value if sizeof(N) < MinPts
mark P as NOISE
will be increase from R2 [1]to RN .[2] So the
else
observation process is not a fixed one. Depends on
C = next cluster
the number of nodes the system will generating the
expandCluster (P, N, C, eps, MinPts)
observation process.
Calculate the average distance cluster
D. Modified Density Subspace Clustering
Instead of finding clusters in the full feature
space, subspace clustering is an emergent task which
denotes the jth datapoint which belongs to cluster
aims at detecting clusters embedded in subspaces. A
i.
cluster is based on a high-density region in a
Nc stands for number of clusters.
subspace. To identify the dense region is a major
is the distance between datapoint and
problem. And some of the data points are forming
out of the cluster range is called ―the density the cluster centroid .
divergence problem‖. We propose a novel Modified xi stands for datapoint which belongs to cluster
subspace clustering algorithm is to discover the centroid
clusters based on the relative region densities in the best distance =0
subspaces attribute, where the clusters are regarded for each value as
as regions whose densities are relatively high as if (fi >bestdistance)
compared to the region densities in a subspace. {
Based on this idea, different density thresholds are bestdistance=fi
adaptively determined to discover the clusters in selected attribute set = from best distance fi
different subspace attribute. We also devise an Hierarchical _clustering ( )
innovative algorithm, referred to as MDSC }
(Modified Density Subspace clustering), to adopt a d=d+1
divide-and-conquer scheme to efficiently discover }
clusters satisfying different density thresholds in End while
different subspace cardinalities. }
expandCluster (P, N, C, eps, MinPts)
Advantages of the proposed system {
The proposed system efficiently discovers add P to cluster C
clusters satisfying different density thresholds for each point P' in N
in different subspace attributes. if P' is not visited
To reduce the Density Divergence Problem. mark P' as visited
To reduce the outlier. (The data points which N' = getNeighbours(P', eps)
are out of the range). if sizeof(N') >= MinPts
To improve the Intra cluster and Inter cluster N = N joined with N'
performance. if P' is not yet member of any cluster
add P' to cluster C
E. Algorithm for Modified Density Subspace Return the cluster C from the datapoint P.
Clustering }
1. Initialize the selected attribute set and An –total Hierarchical _clustering ( )
attribute set X = {x1, x2, x3... xn} be the set of data points.
2. Select a set of attribute subset from at dataset I. Begin with the disjoint clustering having level L(0)
d=1…n, = 0 and sequence number m = 0.
While ( ==! null II. Find the least distance pair of clusters in the
current clustering, say pair (Ci), (Cj), according to
{
d[(Ci), (Cj),] = min d[(i),(j)] =best distance where
Set (eps)
1630 | P a g e](https://image.slidesharecdn.com/ir3116271633-130226001838-phpapp01/75/Ir3116271633-4-2048.jpg)
![V.Kavitha, Dr.M.Punithavalli / International Journal of Engineering Research and
Applications (IJERA) ISSN: 2248-9622 www.ijera.com
Vol. 3, Issue 1, January -February 2013, pp.1627-1633
the minimum is over all pairs of clusters in the D. Outlier
current clustering. Outlier is nothing but, the data points which
III. Increment the sequence number: are out of the range of the cluster. The outlier is
m = m +1.Merge clusters Ci and Cj into a single calculated for the existing method of ODAC(Online
cluster to form the next clustering m. Set the level Divisive Agglomerative Clustering) and the
of this clustering to L(m) = d[(Ci), (Cj),] proposed method MDSC (Modified Density
IV. Update the distance matrix, D, by Subspace Clustering).
deleting the rows and columns corresponding to
clusters (r) and (s) and adding a row and Outlier Calculation
column corresponding to the newly formed cluster. Step 1: Intra Cluster value is calculated for all
The distance between the new cluster, denoted (Ci), Clusters.
(Cj) and old cluster (Ck) is defined in this way: d Step 2: Mean of the Intra cluster is found out.
[(Ck), (Ci), (Cj)] = min [ d(k,i) ,d(k,j) ] Step 3: All the data points of the clusters will be
V. If all the data points are in one cluster then stop, comparing with the mean value.
else repeat from step 2. Step 4: After comparison, each data point will be
decided whether the point will position within a
3. End cluster or out of the cluster.
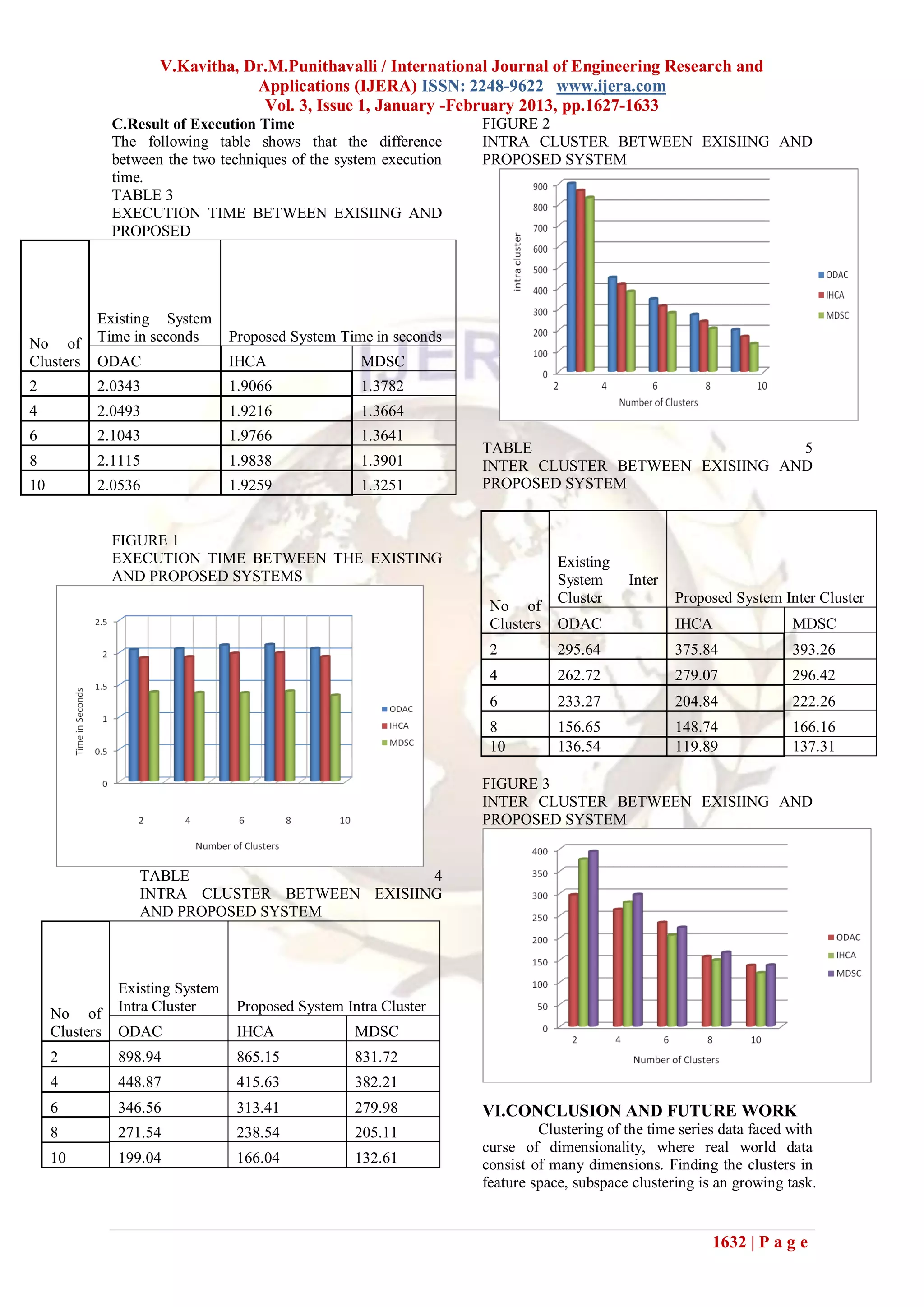
IV. EXPERIMENTAL RESULTS V.SYSTEM EVALUATION ON TIME
The main objective of this chapter to SERIES DATA SET
measure the proposed system result with the existing This proposed method is evaluated with
system. Measuring the performance of cluster results different kinds of time series data sets. Three types
and cluster analysis was measured in terms of the of data sets are used to evaluate the proposed
Cluster Quality (Intra Cluster and Inter Cluster) and algorithm. The data sets are namely ECG Data, EEG
Computation Time. The proposed system is very Data and Network Sensor Data. ECG Data set is
much adapted with the dynamic performance of time used to find out the anomaly Identification. This data
series data stream. We must evaluate our proposed set have three attributes namely time seconds, left
system with real data produced by applications that peek and right peek. EEG Data set is used to find out
generate time series data streams. abnormal personality. The name of the attributes is
Trial number, Sensor value, Sensor position, Sample
A. Evaluation Criteria for Clustering Quality number. The third type of data set is Network sensor.
Generally, the criteria used to evaluate The name of he attributes is Total bytes, in bytes, out
clustering methods concentrate on the quality of the bytes, Total Package, in package, out package,
resulting clusters. Given the hierarchical Events.
characteristics of the system, the quality of the
hierarchy is constructed by our algorithm. And A. Record Set Specification
another evaluation criterion is computation time of TABLE I DATA SET SPECIFICATION
the system. Data Set Number of Number of
Instance Attributes
B. Cluster Quality ECG 1800 3
A good clustering algorithm will produce EEG 1644 4
high quality based on intra cluster similarity and
Sensor 2500 7
inter cluster similarity measures. The quality of the
Network
clustering result depends on the similarity measure
Using the above three kinds of data sets we have
used by the method and its implementation. The
to calculate Execution time of the system, Intra
quality of a clustering method is also measured by
cluster , Inter cluster and outlier of the cluster.
its ability to discover some or all of the hidden
patterns. The criteria for measuring the cluster
B. Result of Outlier
quality of intra clusters similarity will be high. And
TABLE2 OUTLIER SPECIFICATION
the inter cluster similarity will be low. For analysing
cluster quality will be in two forms, First one is
finding groups of objects will be related to one Technique Outlier Points
another. And second one is finding the group of Existing 152
objects that differ from the objects in other groups. System(ODAC)
Existing 123
C. Computation Time System(IHCA)
Another evaluation of this work is Proposed 63
calculating the computation time of the process. The System(MDSC)
complexity of execution time will be decreased
when using the proposed work.
1631 | P a g e](https://image.slidesharecdn.com/ir3116271633-130226001838-phpapp01/75/Ir3116271633-5-2048.jpg)
![V.Kavitha, Dr.M.Punithavalli / International Journal of Engineering Research and
Applications (IJERA) ISSN: 2248-9622 www.ijera.com
Vol. 3, Issue 1, January -February 2013, pp.1627-1633
Density based approach to identify clusters in Simoudis, J. Han, and U. Fayyad, Eds.
dimensional point sets. Density subspace clustering AAAI Press, 1996, pp. 226–231.
is a method to detect the density connected clusters [3] Y. Kim, W. Street, and F. Menczer,
in all subspaces of high dimensional data for ―Feature Selection in Unsupervised
clustering time series data streams Multidimensional Learning via Evolutionary Search,‖ Proc.
data clustering evaluation can be done through a Sixth ACM SIGKDD Int’l Conf.
density-based approach. The Modified Density Knowledge Discovery and Data Mining, pp.
subspace clustering algorithm is used to find best 365-369, 2000.
cluster result from the dataset. Improve the Cluster [4] M. Halkidi, Y. Batistakis, and M.
Quality and evaluate the similarity between the data Varzirgiannis, ―On clustering validation
points in the clustering, The MDSC algorithm also techniques,‖ Journal of Intelligent
concentrates the Density Divergence Problem Information Systems, vol. 17, no. 2-3, pp.
(Outlier). Proposed system clustering results 107–145, 2001.
compared them with existing clustering algorithms [5]. Pedro Pereira Rodriguess and Joao Pedro
in terms of the Execution time, Cluster Quality Pedroso, ―Hierarchical Clustering of Time
analysis. Experimental results show that proposed Series Data Streams,‖ Sudipto Guha, Adam
system improves clustering quality result, and less Meyerson, Nine Mishra and Rajeev
time than the existing clustering methods. The Motiwani, ―Clustering Data Streams:
problem find out in the proposed work is, to Theory and Practice‖, IEEE Transactions
optimize the centroid point using Multi view point on Knowledge and Data Engineering. Vol.
approach. And to apply this technique in non time 15, no. 3, pp. 515-528, May/June 2003.
series data set also. [6] Ashish Singhal, and Dale E Seborg,
―Clustering Multivarriate Time Series
References Data,‖ Journal of Chemometrics, vol. 19,
[1] Yi-Hong Chu, Jen-Wei Huang, Kun-Ya pp. 427-438, Jan 2006.
Chuang, DeNian Yang, ―Density Conscious [7] Sudipto Guha, Adam Meyerson, Nine
Subspace Clustering for High Dimensional Mishra and Rajeev Motiwani, ―Clustering
Data‖ IEEE Transactions on Knowledge Data Streams: Theory and Practice‖, IEEE
and Data Engineering. Vol 22, No 1, Transactions on Knowledge and Data
January 2010. Engineering. Vol. 15, no. 3, pp. 515-528,
[2] M. Ester, H.-P. Kriegel, J. Sander, and X. May/June 2003.
Xu, ―A density-based algorithm for [8] Ashish Singhal, and Dale E Seborg,
discovering clusters in large spatial ―Clustering Multivarriate Time Series
databases with noise,‖ in Proceedings of the Data,‖ Journal of Chemometrics, vol. 19,
Second International Conference on pp. 427-438, Jan 2006.
Knowledge Discovery and Data Mining, E.
1633 | P a g e](https://image.slidesharecdn.com/ir3116271633-130226001838-phpapp01/75/Ir3116271633-7-2048.jpg)

This document summarizes a research paper that evaluates cluster quality using a modified density subspace clustering approach. It discusses how density subspace clustering can be used to identify clusters in high-dimensional datasets by detecting density-connected clusters in all subspaces. The proposed approach uses a density subspace clustering algorithm to select attribute subsets and identify the best clusters. It then calculates intra-cluster and inter-cluster distances to evaluate cluster quality and compares the results to other clustering algorithms in terms of accuracy and runtime. Experimental results showed that the proposed method improves clustering quality and performs faster than existing techniques.














































