Downloaded 180 times



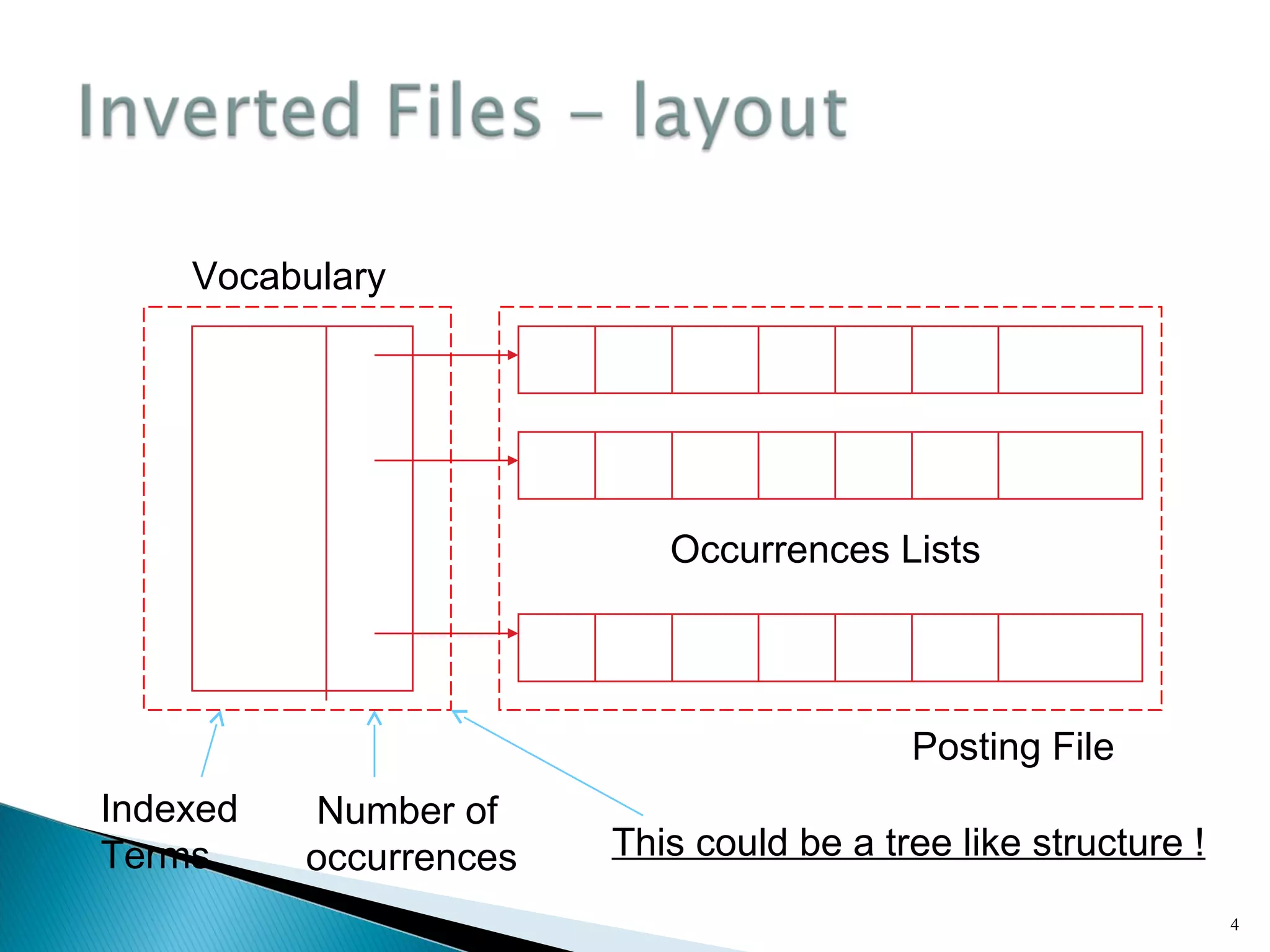





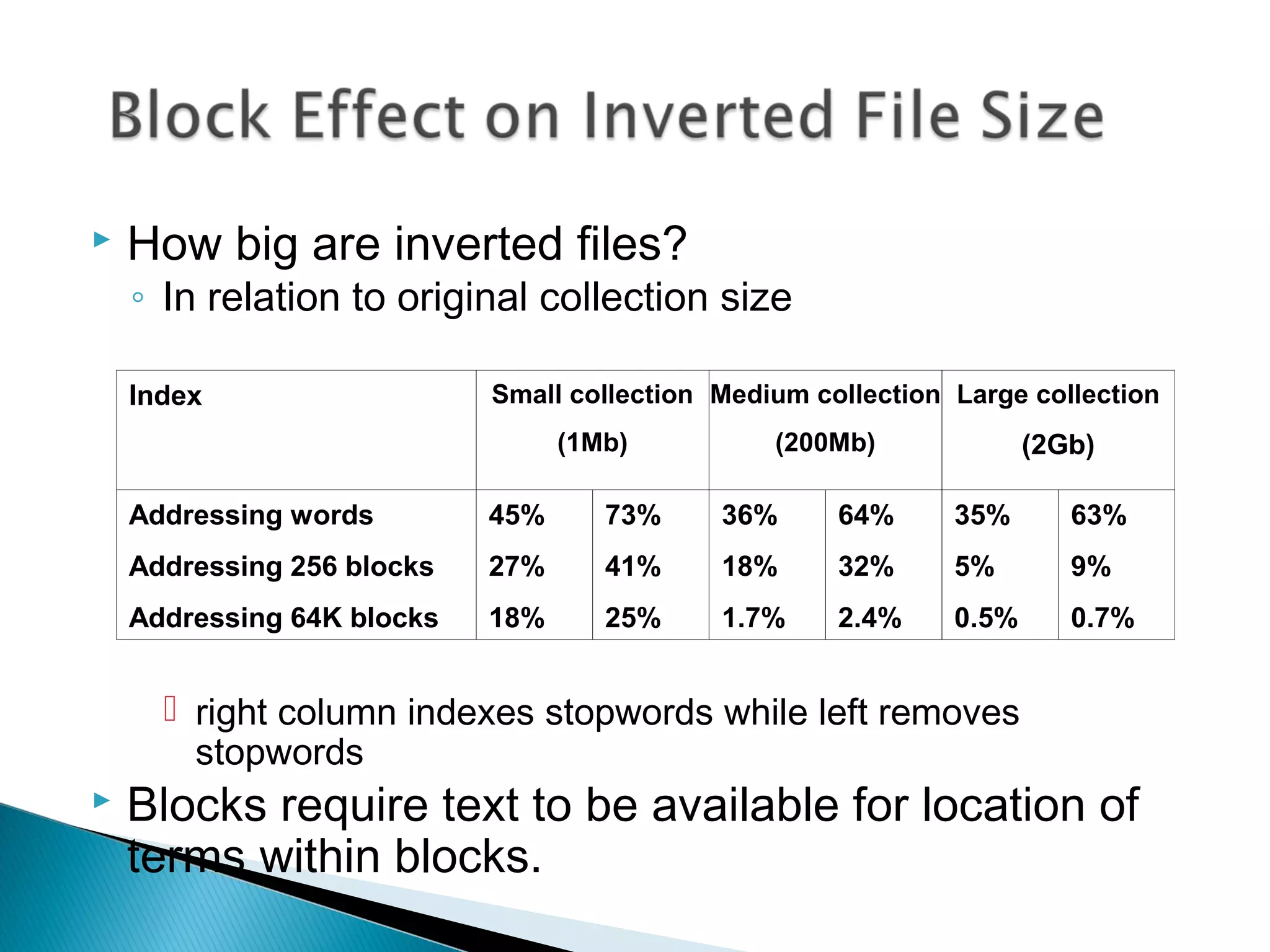





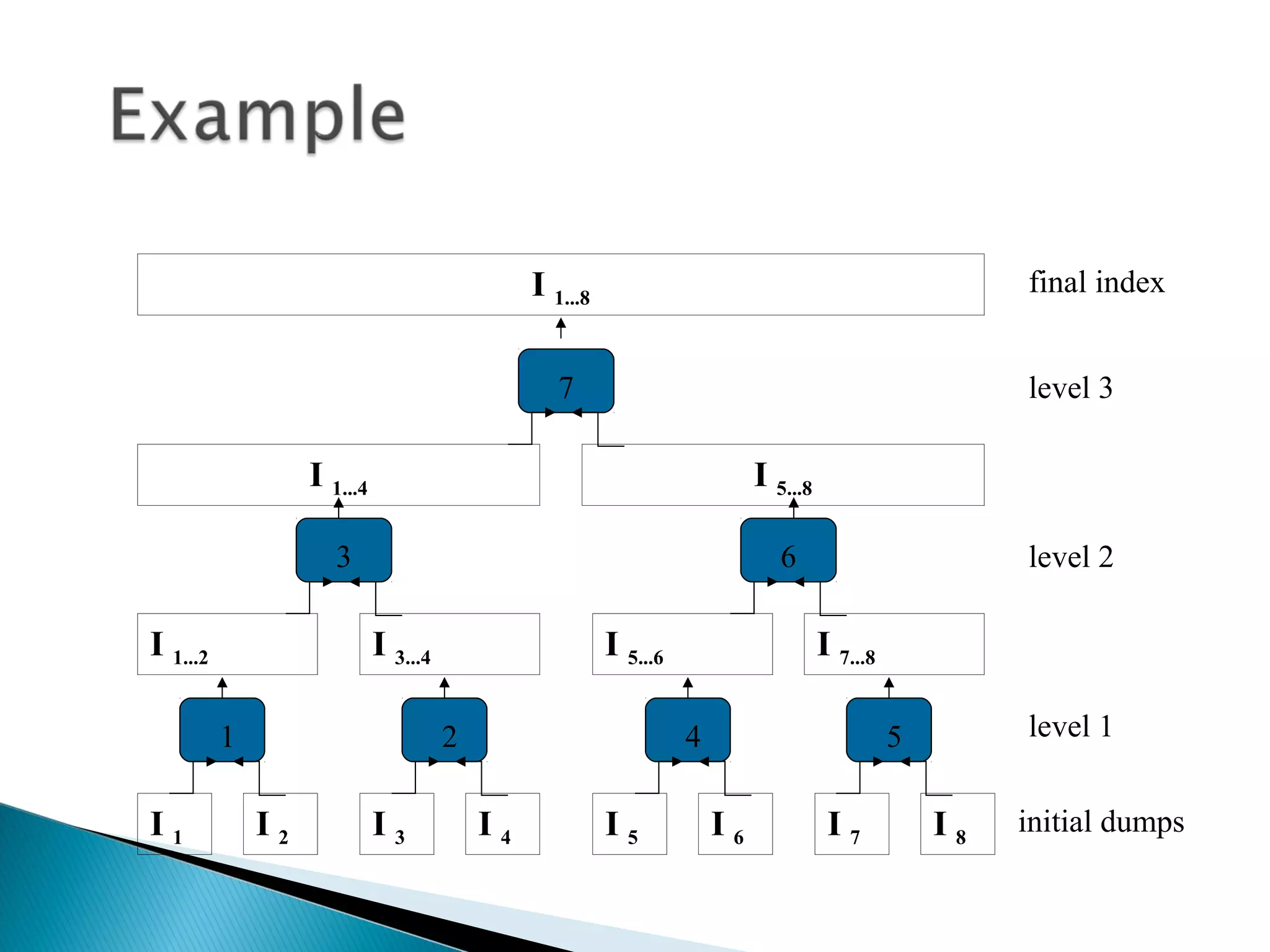




An inverted file indexes a text collection to speed up searching. It contains a vocabulary of distinct words and occurrences lists with information on where each word appears. For each term in the vocabulary, it stores a list of pointers to occurrences called an inverted list. Coarser granularity indexes use less storage but require more processing, while word-level indexes enable proximity searches but use more space. The document describes how inverted files are structured and constructed from text and discusses techniques like block addressing that reduce their space requirements.























































































