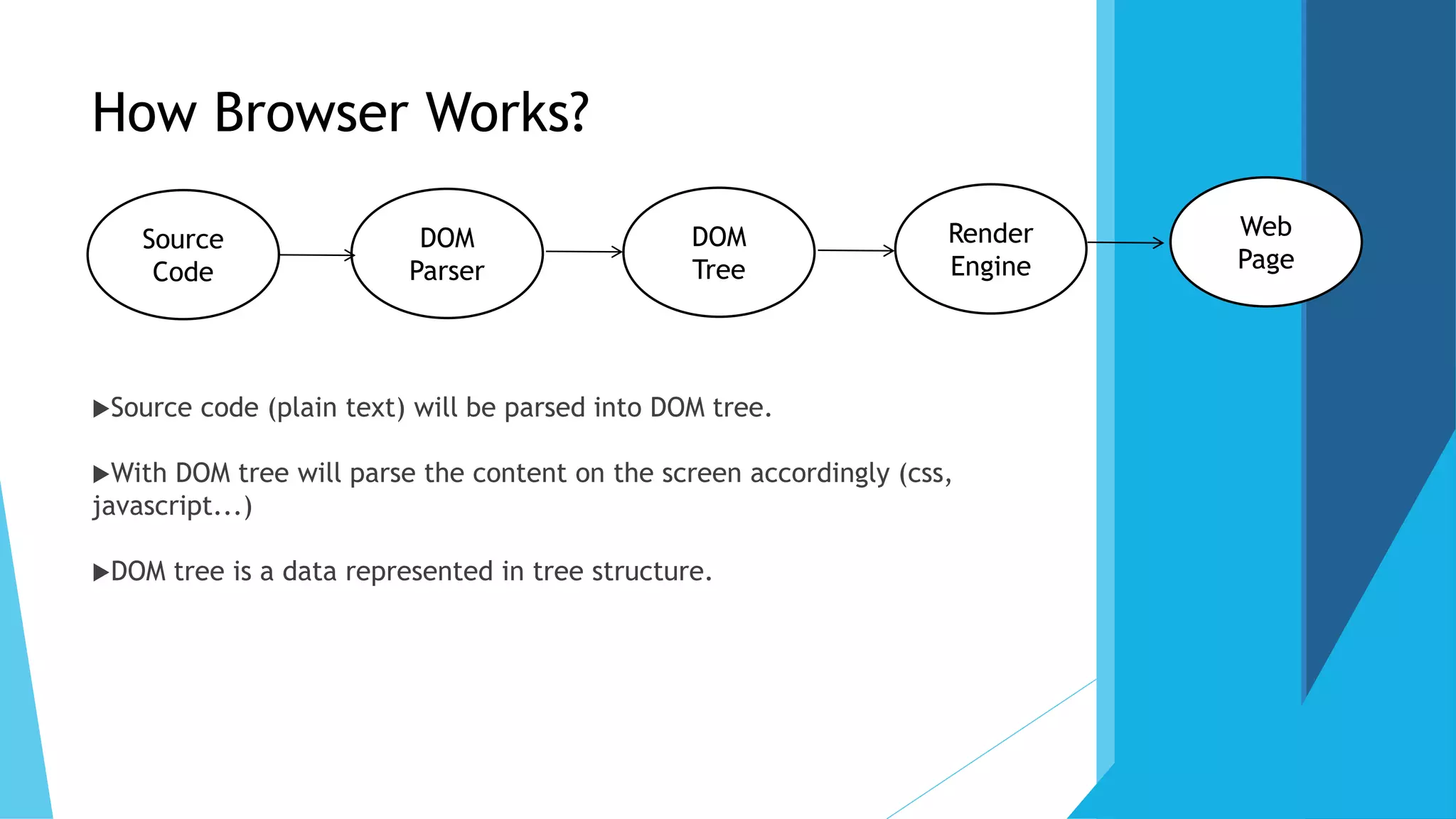
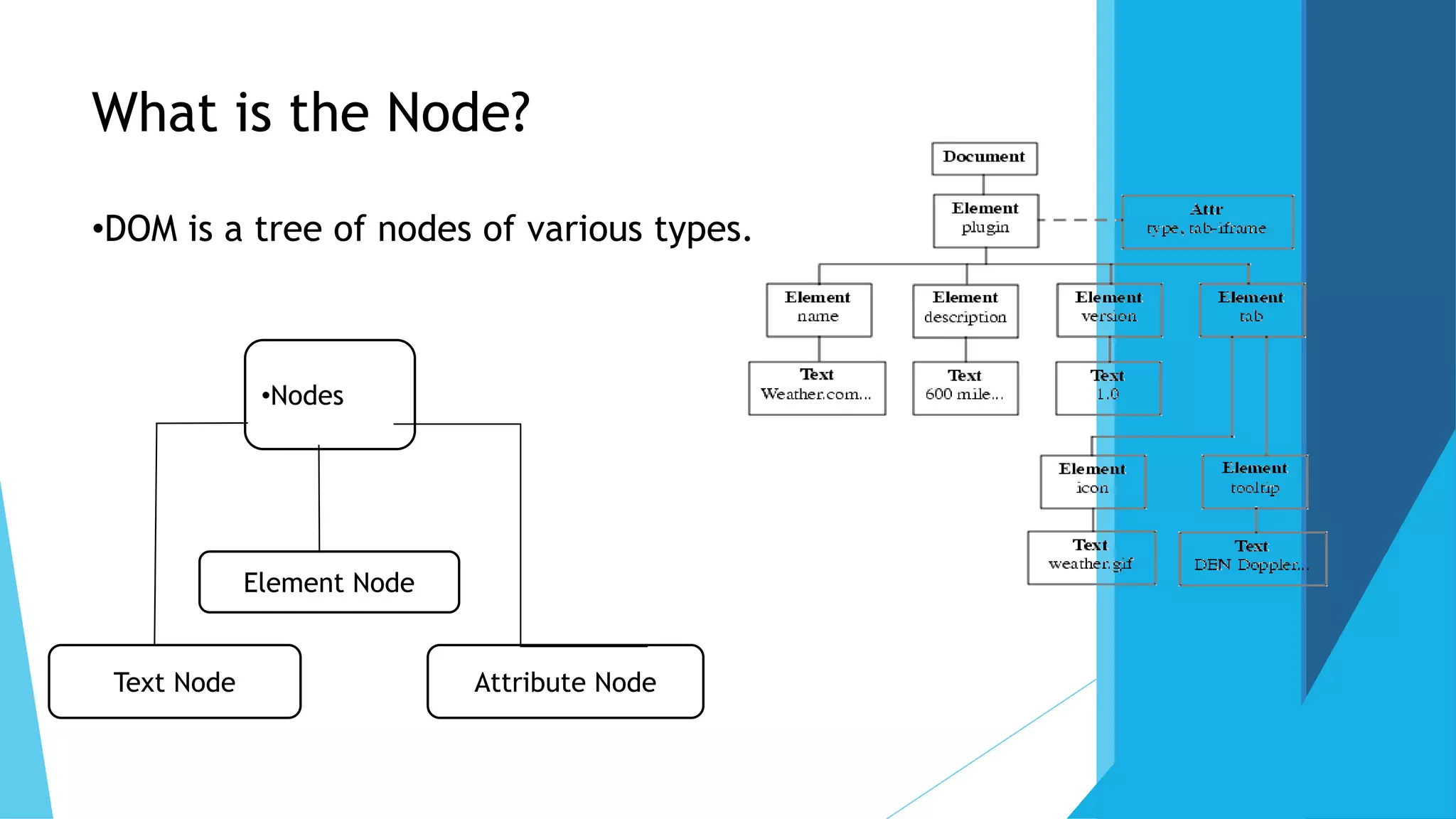
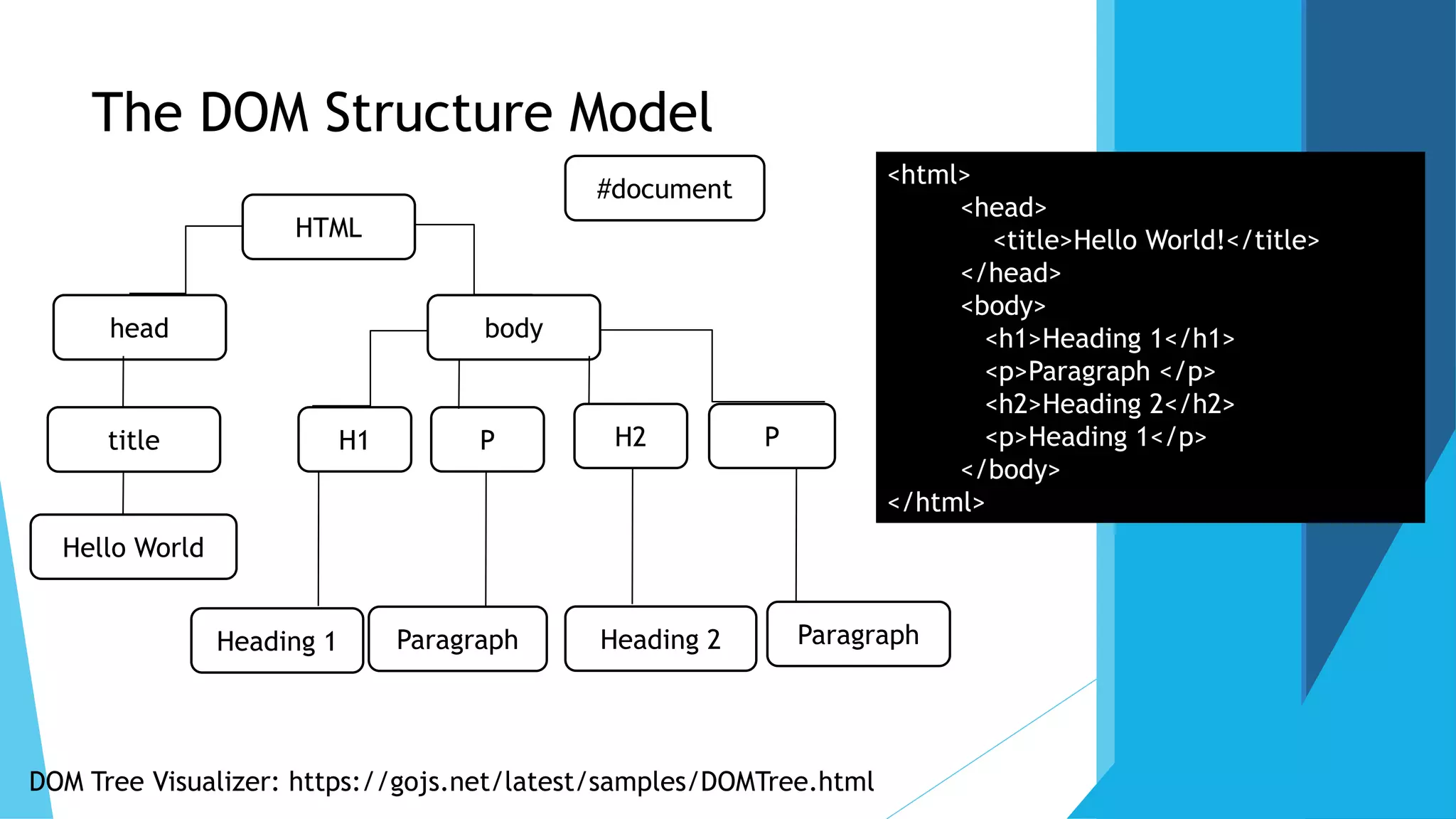
The document discusses the Document Object Model (DOM), which defines a standard for accessing and manipulating HTML and XML documents. It allows programming interfaces to dynamically access and update the content and structure of documents. The DOM represents the page as nodes and objects. It describes the DOM tree structure with parent-child relationships, and methods for accessing nodes by name, ID, tag name, or relative positioning. Examples are given for adding a new text node to the DOM tree. Advantages are robust APIs and easy data modification. Disadvantages include storing the entire document in memory.




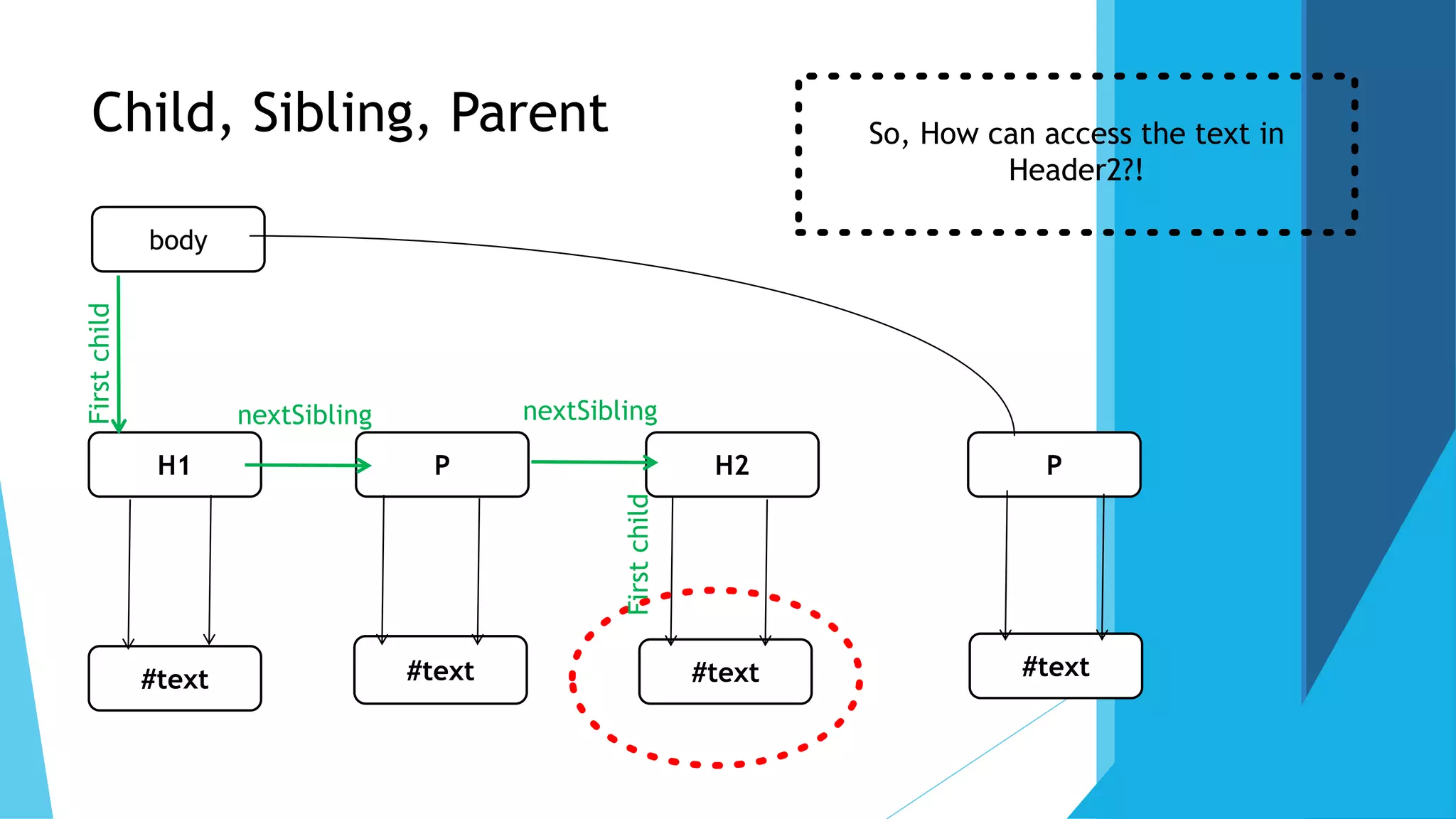
![How can access the nodes?
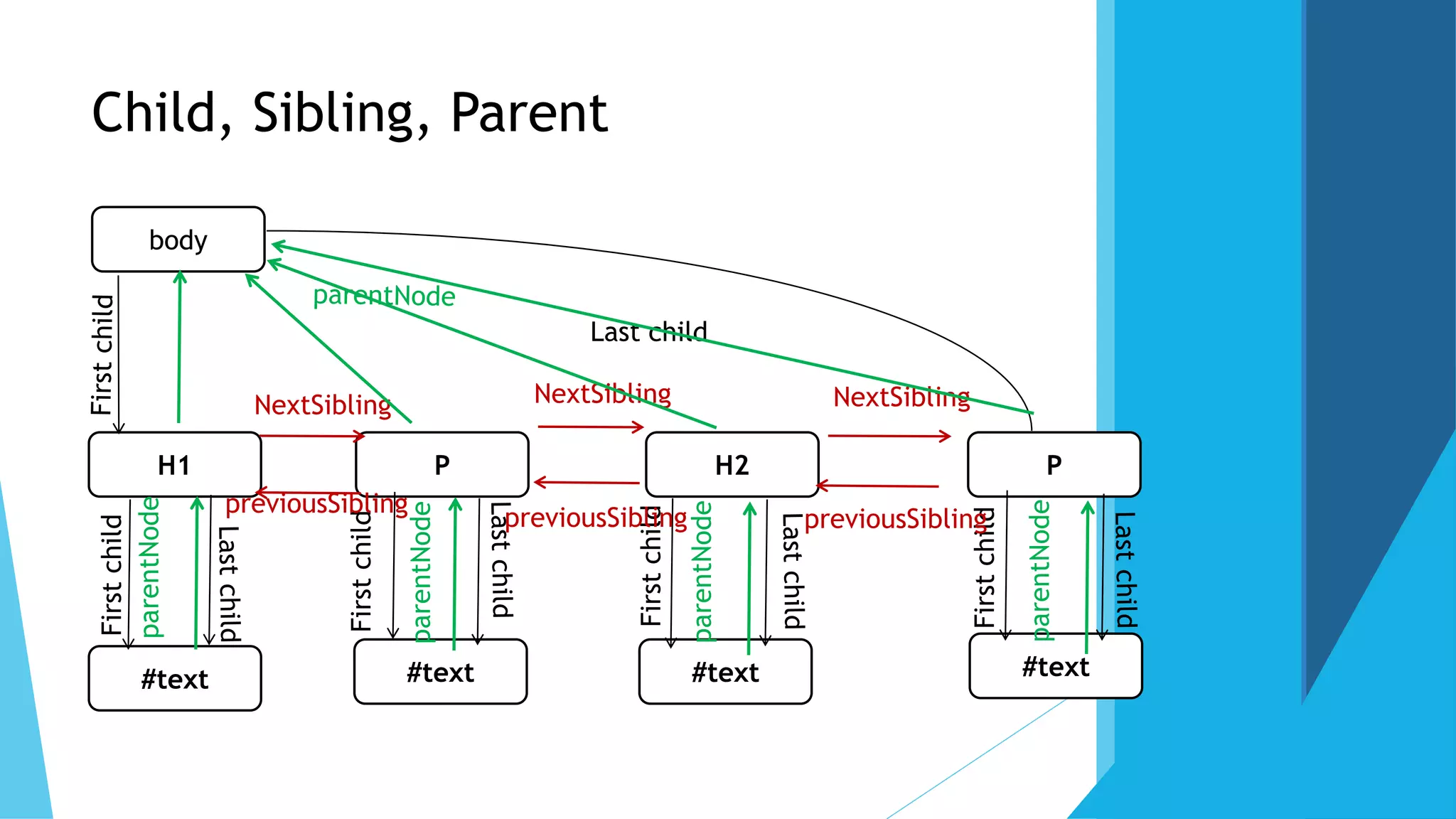
By their name or Id (it will allow you to work with one element, and it's the
easiest way)
GetElementByName(NodeName)
GetEllemtById(IdName)
By Tag Name (GetElementsByTagName), it will return array of nodes
By their relation to parent, child, sibling
(nextSibling,previousSibling,parentNode,lastchild, firstchild, childNode) , childNode[0] ==
first child](https://image.slidesharecdn.com/dom2-170226122602/75/Introduction-to-the-DOM-10-2048.jpg)










































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

