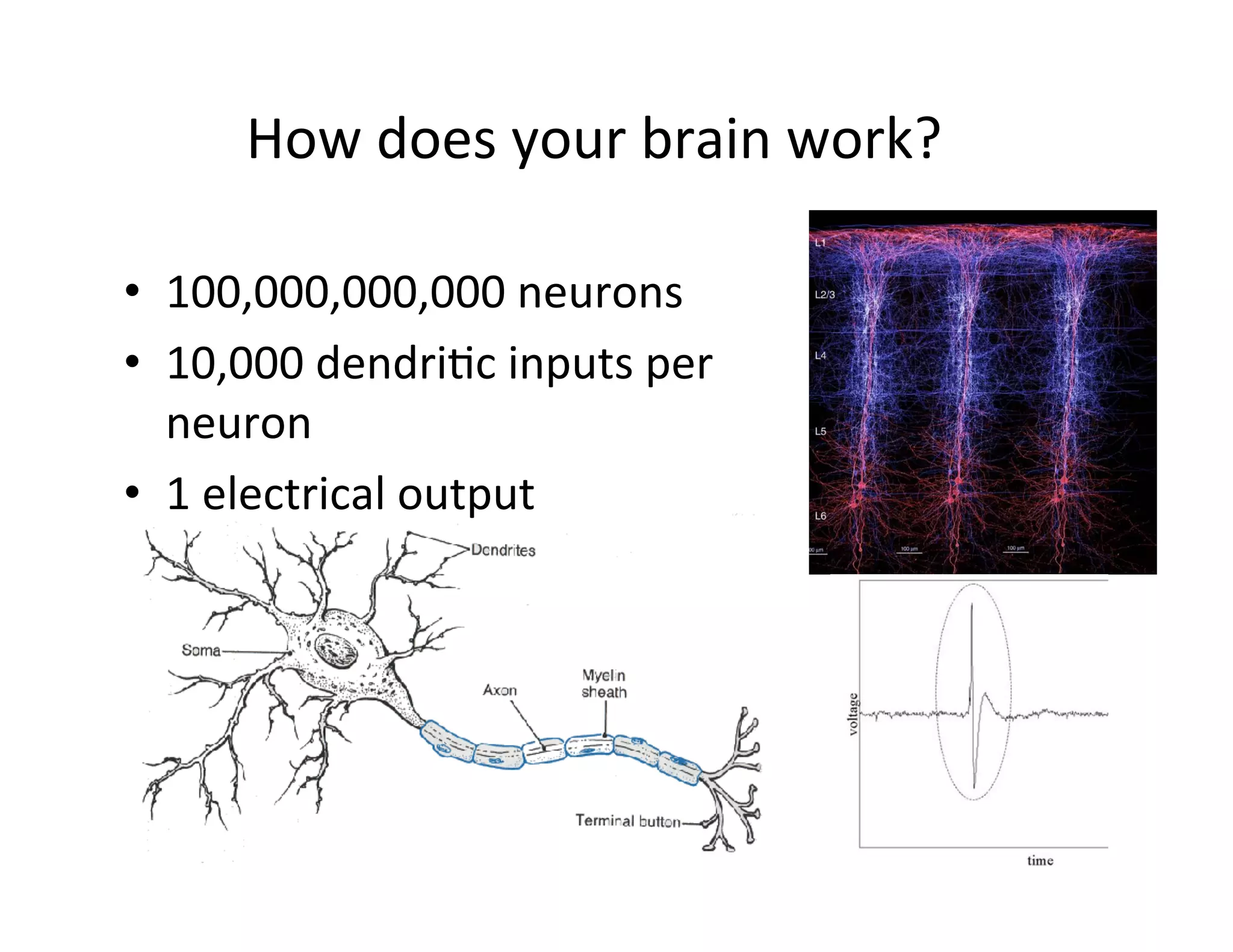
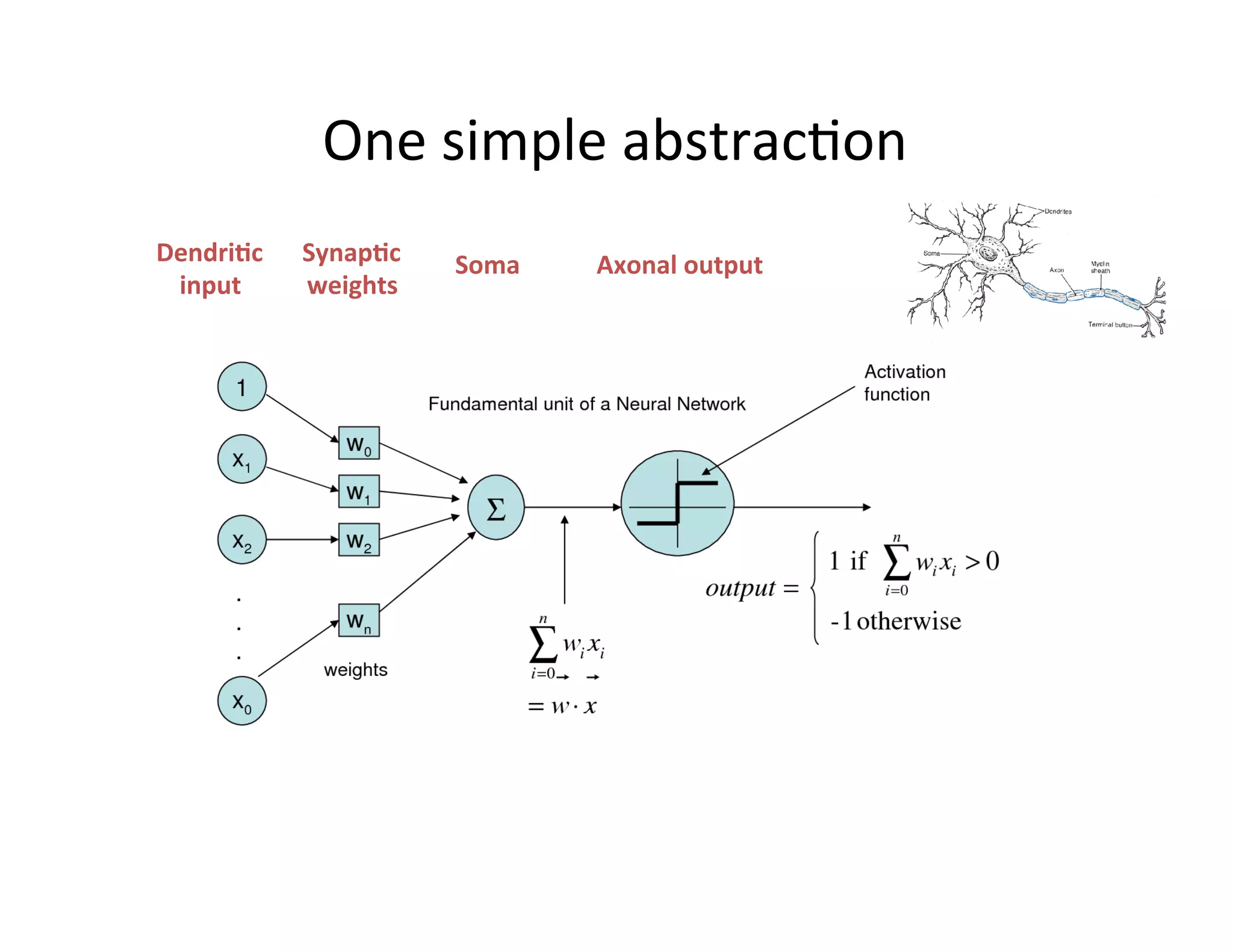
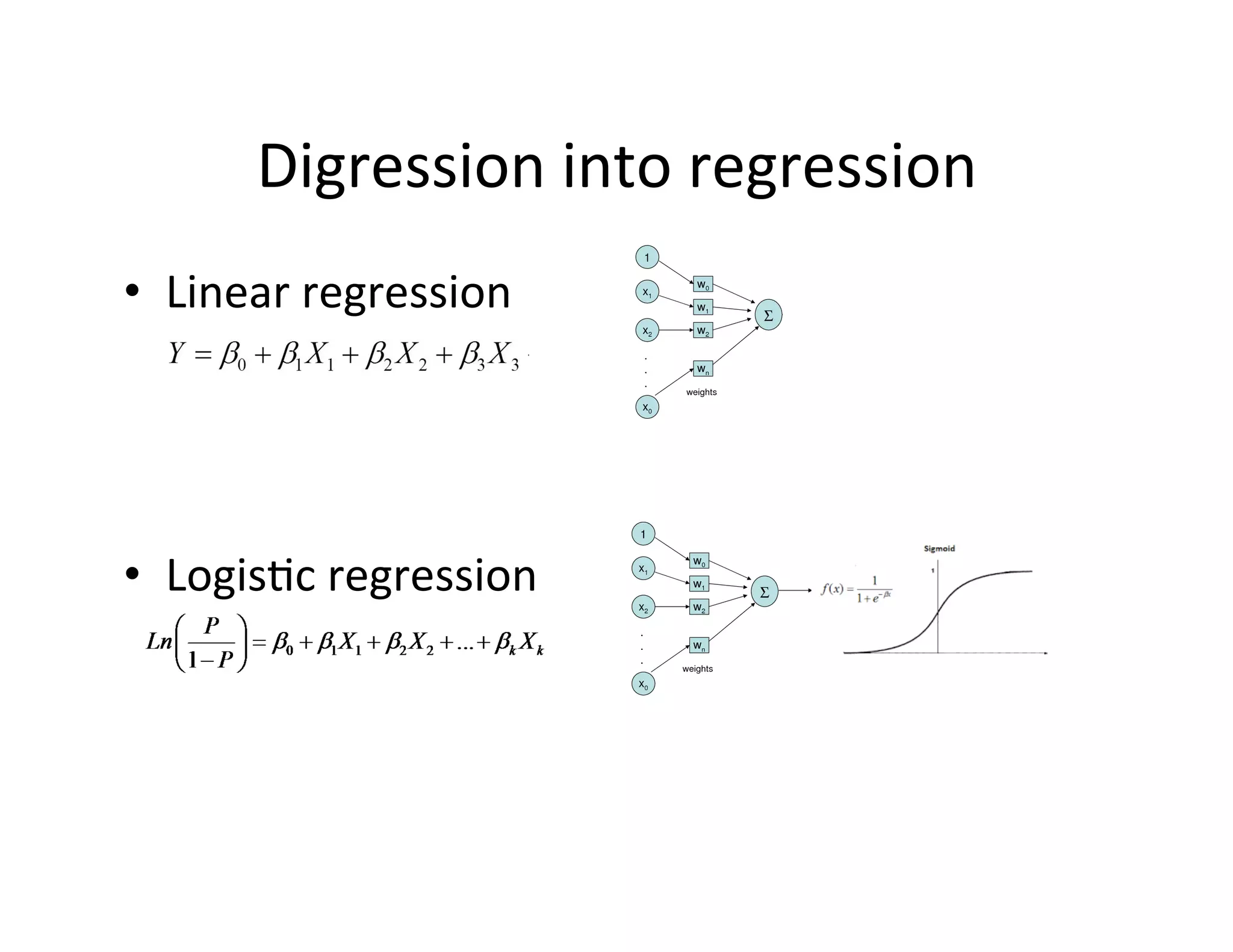
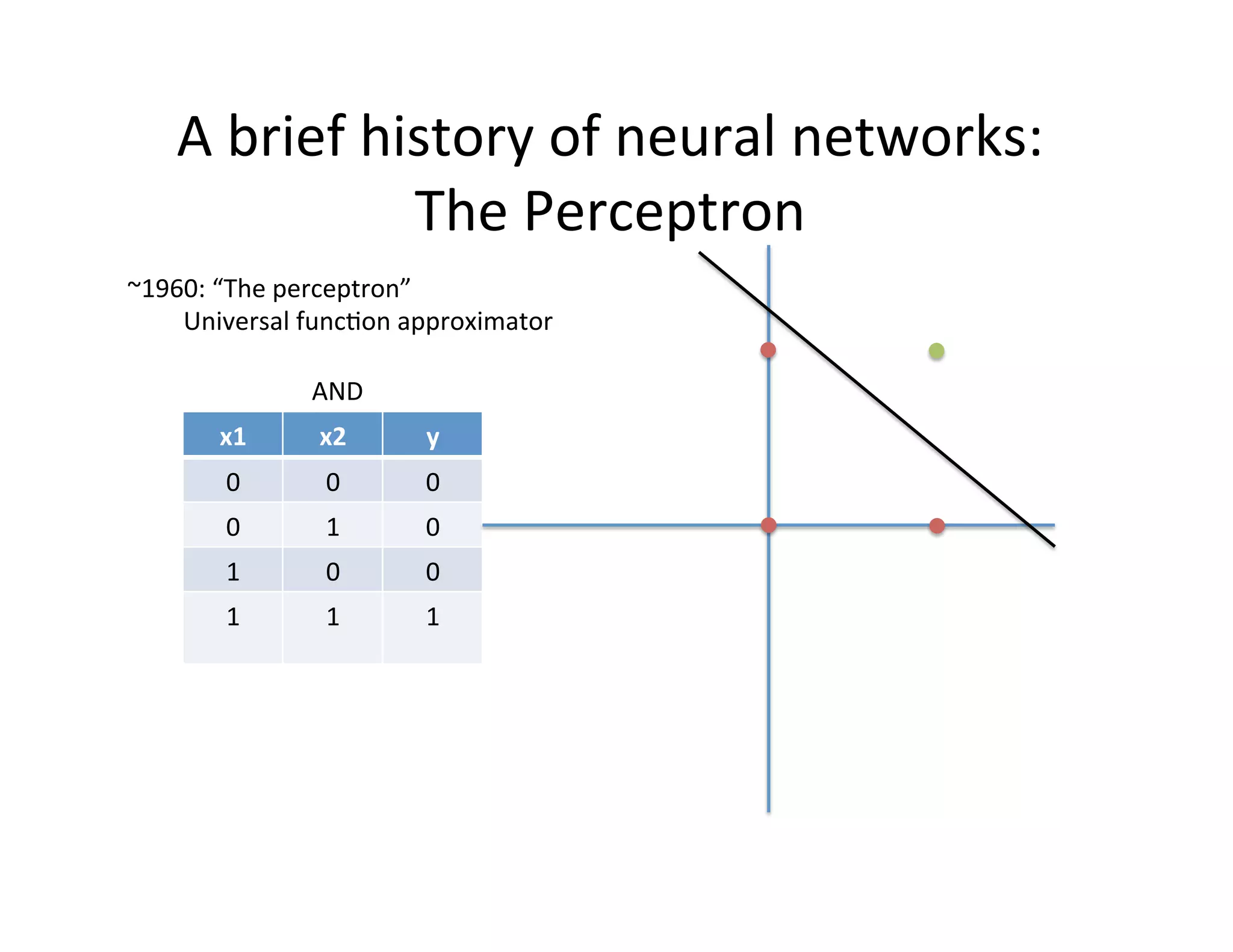
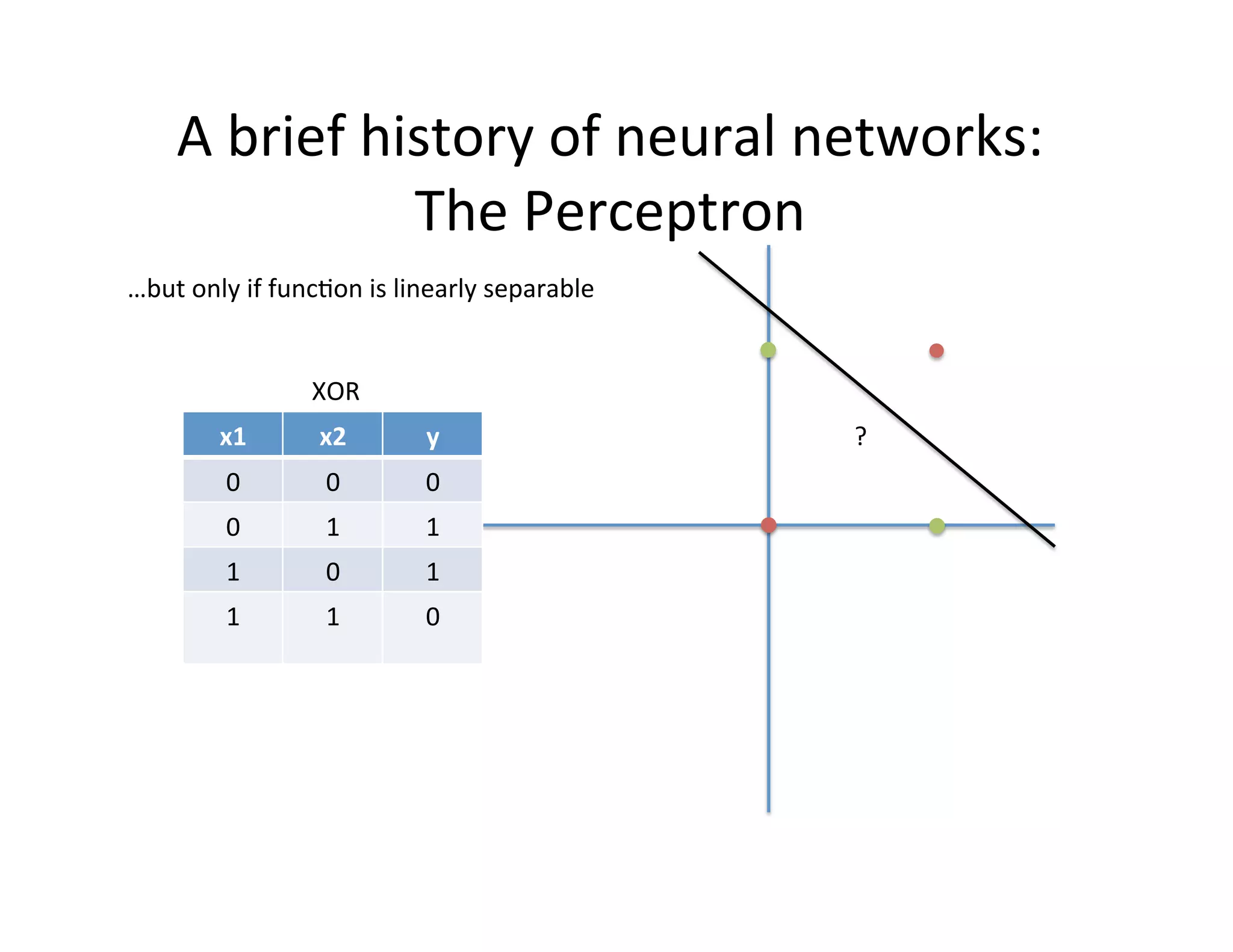
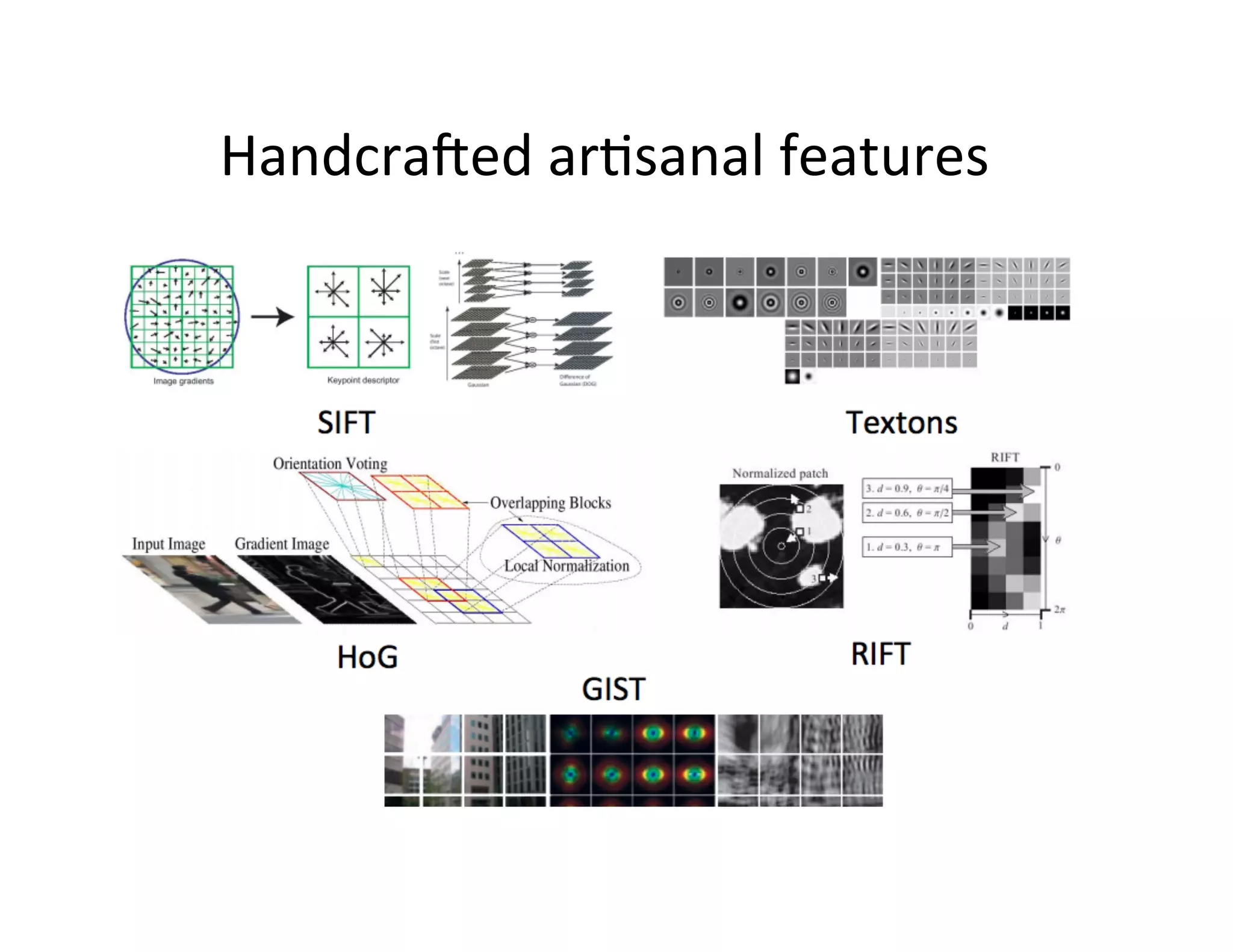
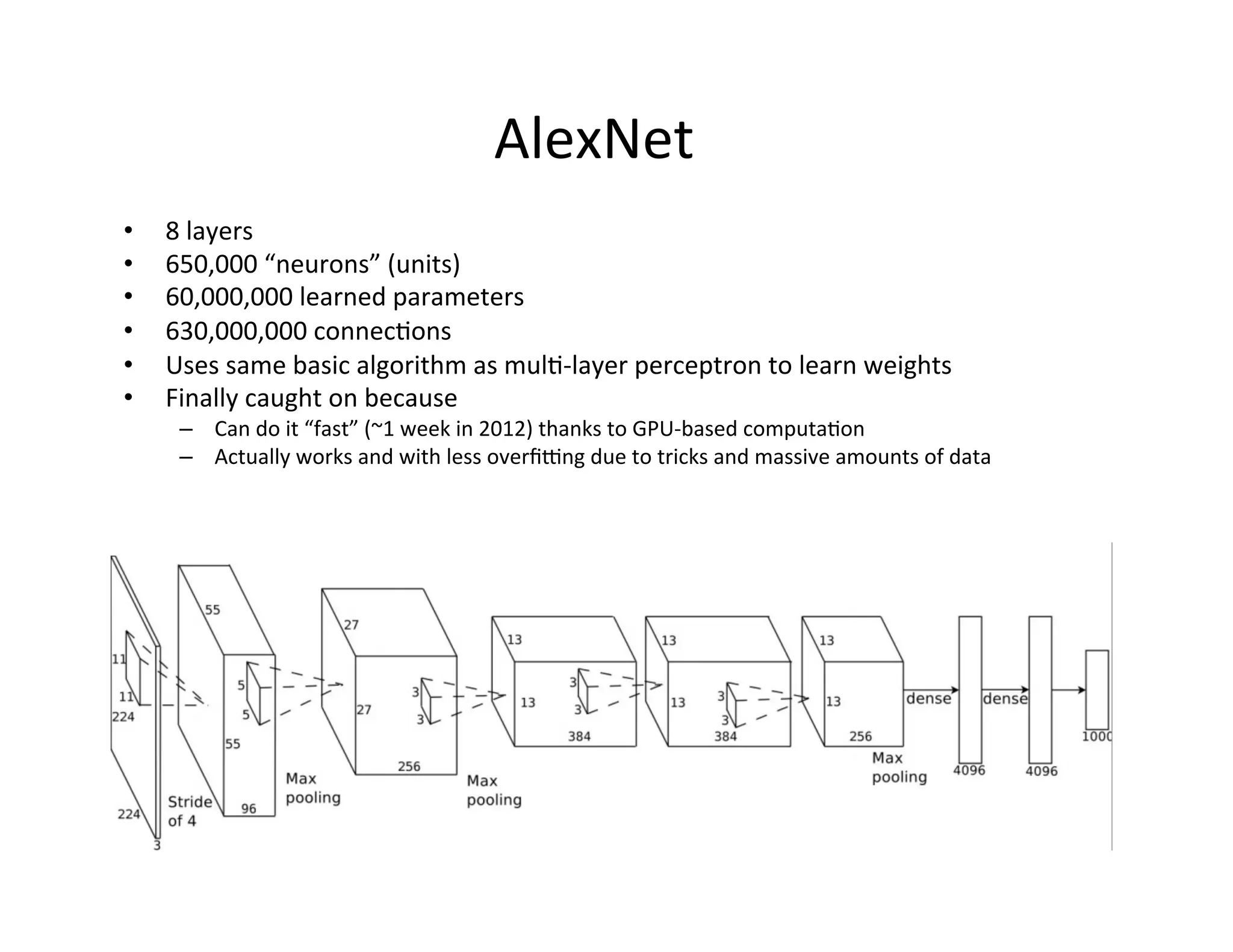
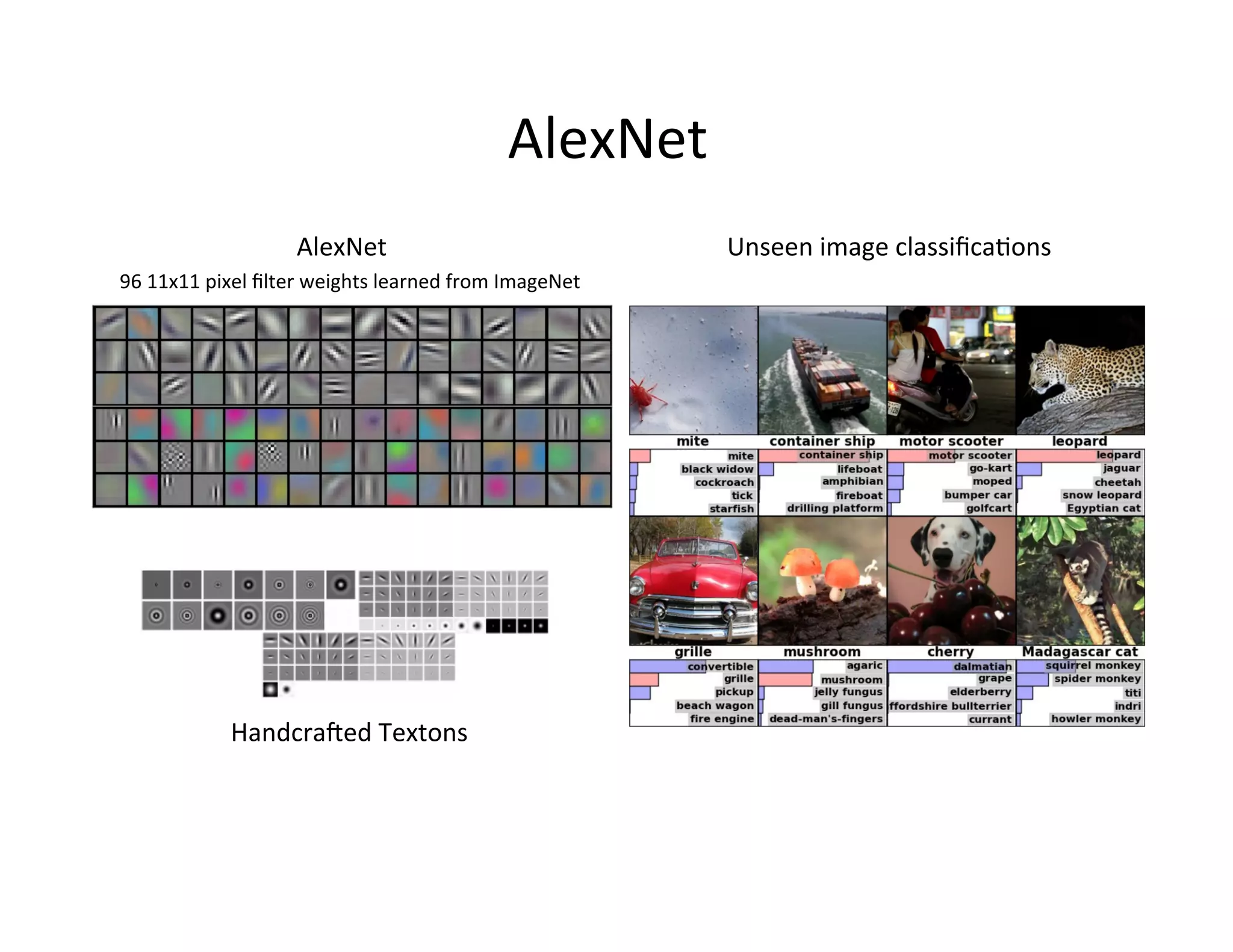
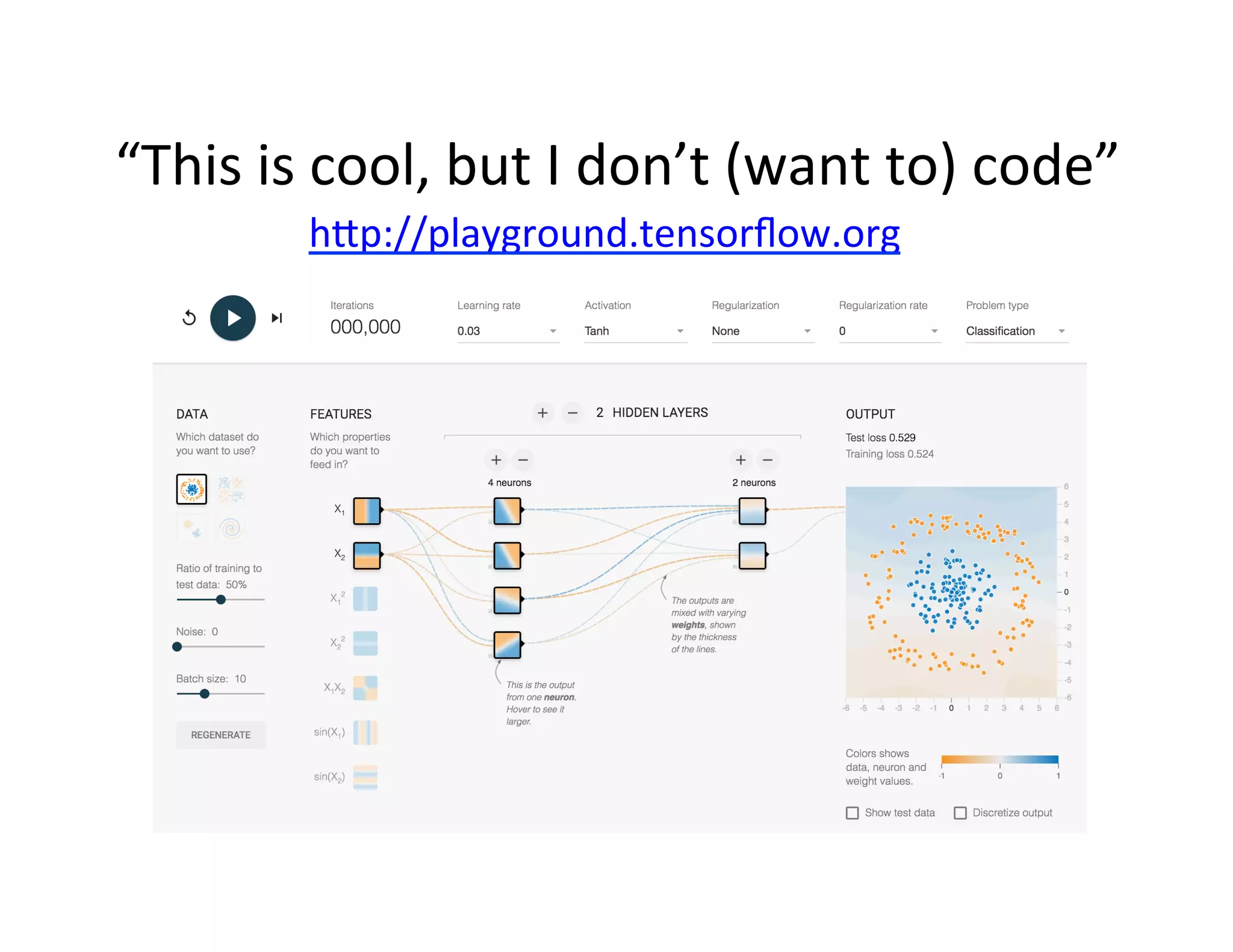
This document provides an introduction to neural networks. It discusses how neural networks have recently achieved state-of-the-art results in areas like image and speech recognition and how they were able to beat a human player at the game of Go. It then provides a brief history of neural networks, from the early perceptron model to today's deep learning approaches. It notes how neural networks can automatically learn features from data rather than requiring handcrafted features. The document concludes with an overview of commonly used neural network components and libraries for building neural networks today.