Download to read offline



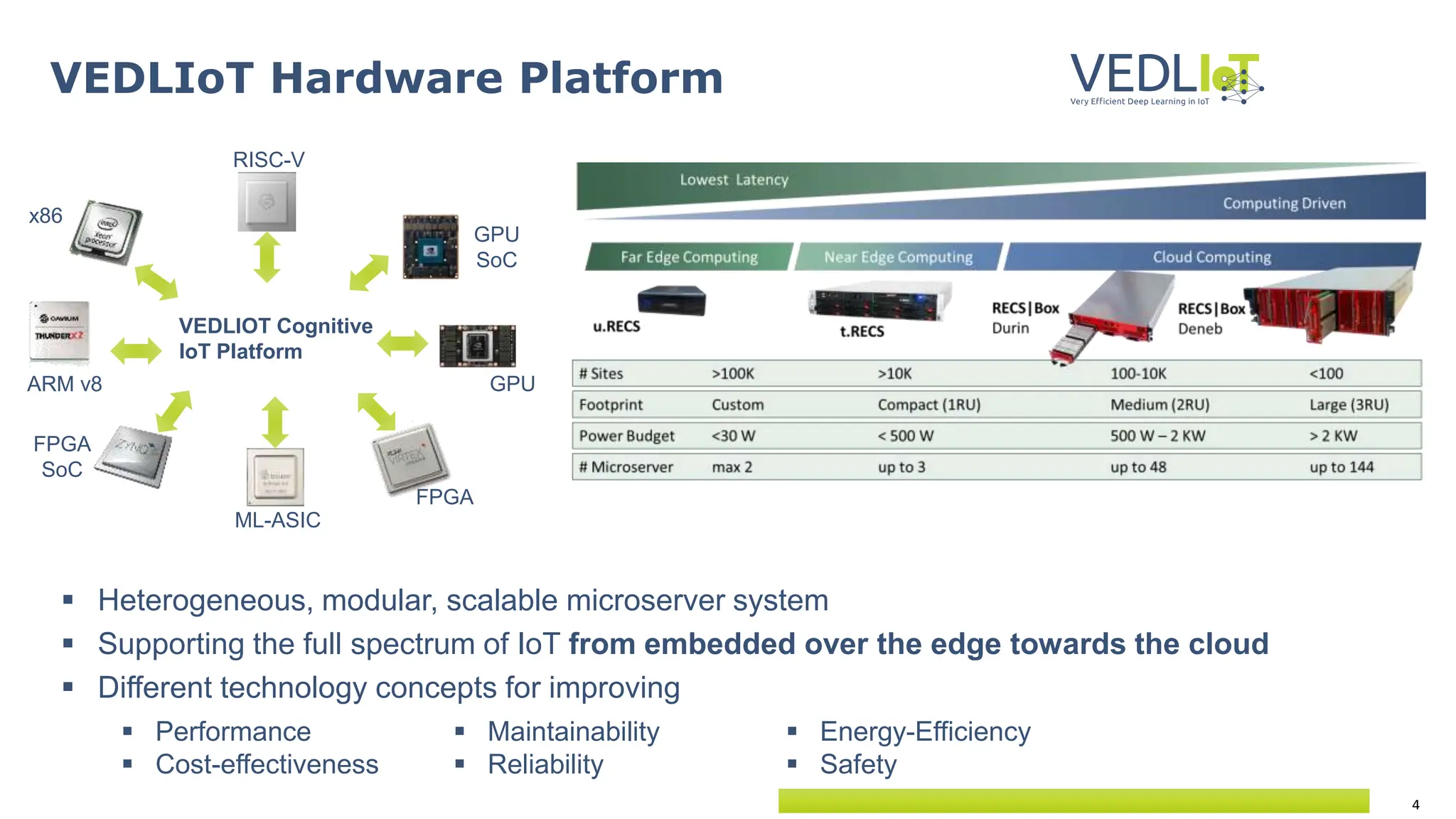

![9
Peak performance values of specialized accelerators, provided by the vendors
(precisions varying from INT8 to FP32)
Peak Performance of DL Accelerators
Average efficiency at 1000 GOPS /W
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
1
10
100
1,000
10,000
100,000
1,000,000
10,000,000
0.01 0.1 1 10 100 1000
Performance
[GOPS]
Power [Watt]
ASIC
GPU
FPGA
Ultra Low Power
High Performance
Low Power](https://image.slidesharecdn.com/hipeac2023dl4iotvedliotoverview-240206104750-ece29291/75/HiPEAC2023-DL4IoT-Workshop_Jean-Hagemeyer-presentation-9-2048.jpg)







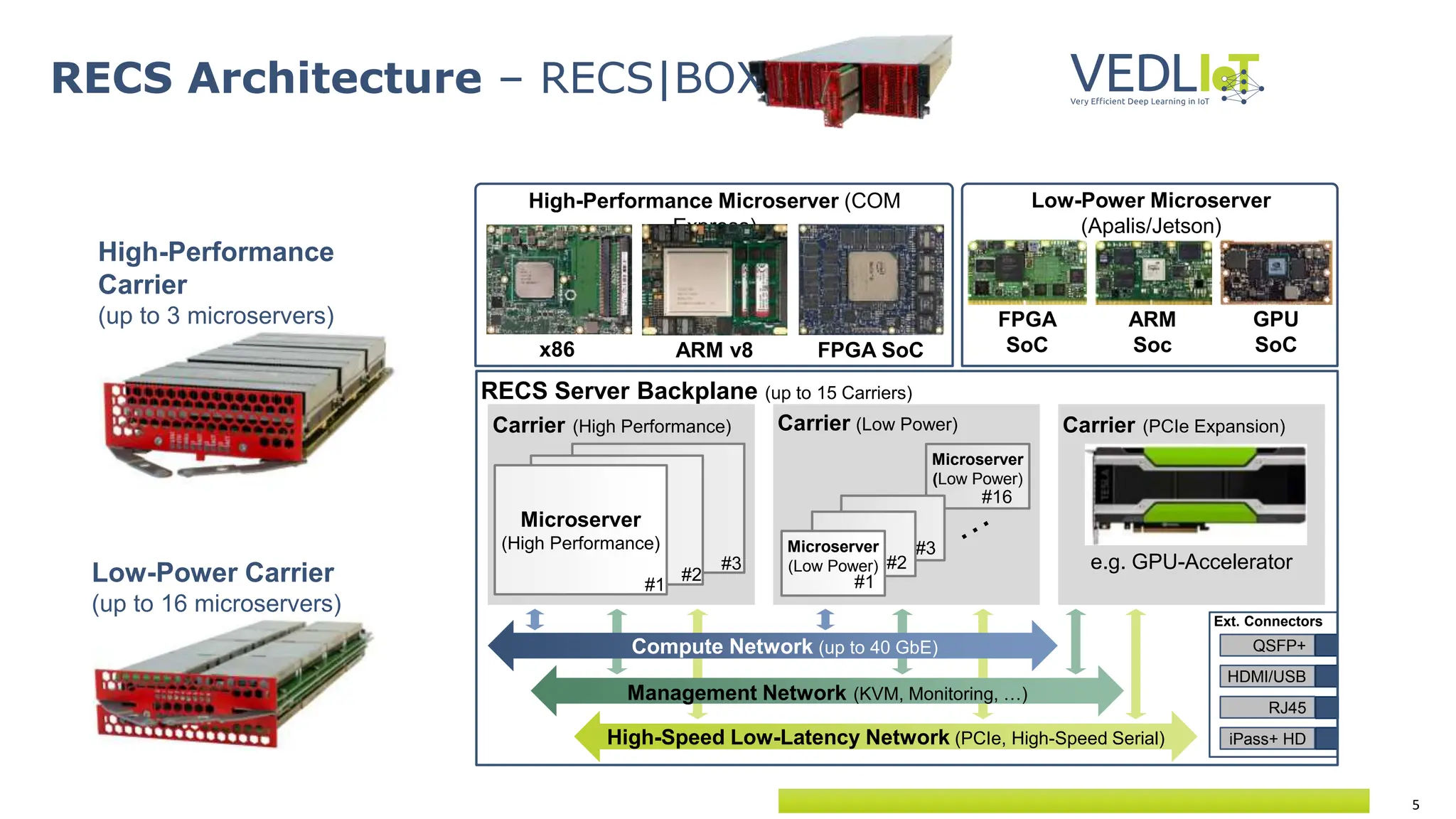
![25
Benchmark performance of DL accelerators
Comparison based on currently available architectures
VEDLIoT will include new specialized accelerators
0
50
100
150
200
250
300
350
Coral (M.2) Coral (Dev.) Xavier AGX
(LP)
Xavier AGX
(HP)
Xavier NX TX2 Nano GTX1660 ZU15 ZU3 Xeon-D1577 Epyc3451 Myriad GAP8
Energy Efficiency [GOPS/W]
ResNet50 Int 8 ResNet50 FP16 ResNet50 FP32
YoloV4 Int 8 YoloV4 FP16 YoloV4 FP32
MobileNet Int 8 MobileNet FP16 MobileNet FP32](https://image.slidesharecdn.com/hipeac2023dl4iotvedliotoverview-240206104750-ece29291/75/HiPEAC2023-DL4IoT-Workshop_Jean-Hagemeyer-presentation-25-2048.jpg)

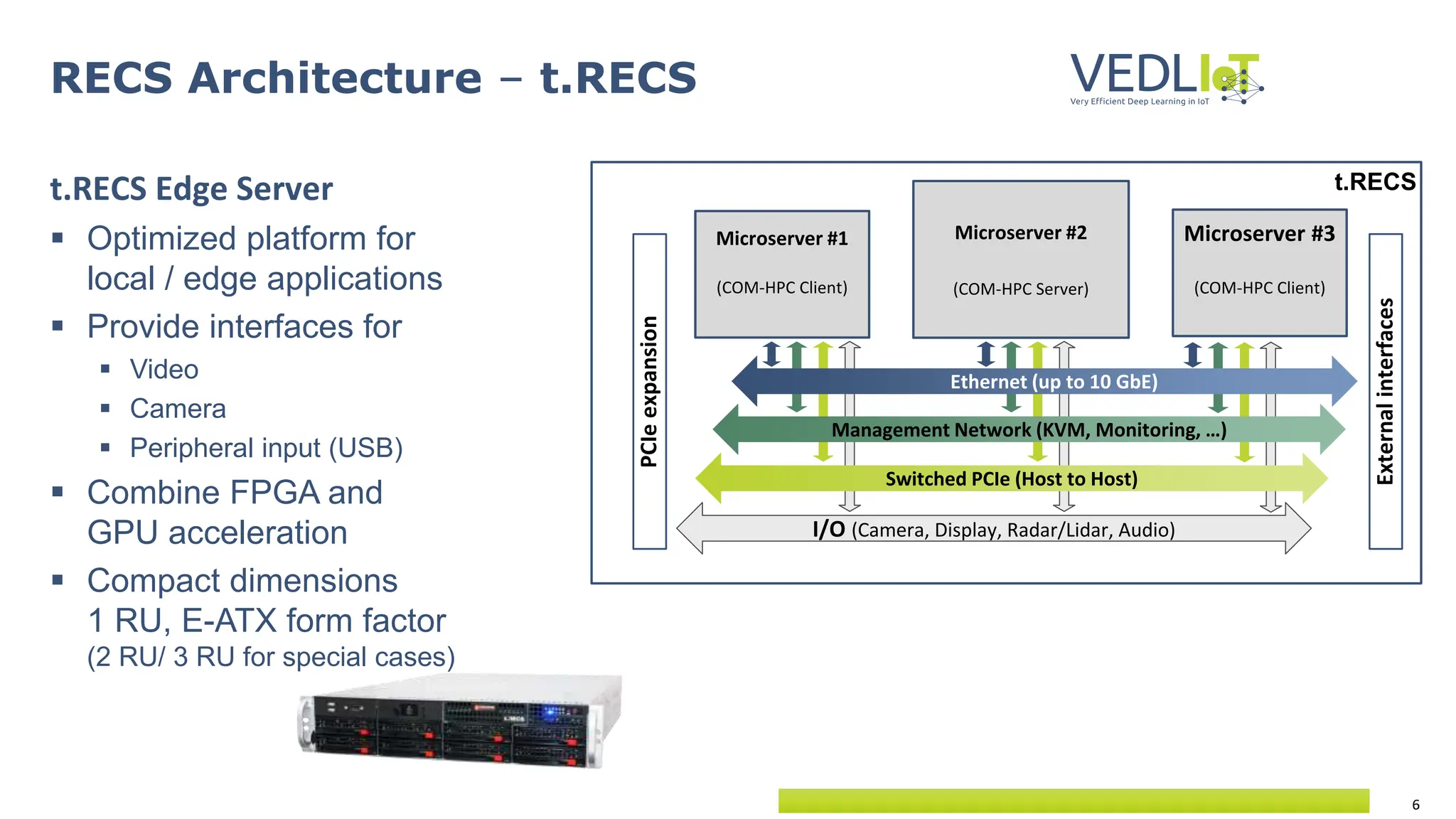
![28
Benchmark performance of DL accelerators
YoloV4
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLR…
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRA…
[CELLRANGE]
10
100
1000
10000
2 4 8 16 32 64 128
Performance
[GOPS]
Power [Watt]
INT8 FP16 FP32](https://image.slidesharecdn.com/hipeac2023dl4iotvedliotoverview-240206104750-ece29291/75/HiPEAC2023-DL4IoT-Workshop_Jean-Hagemeyer-presentation-28-2048.jpg)
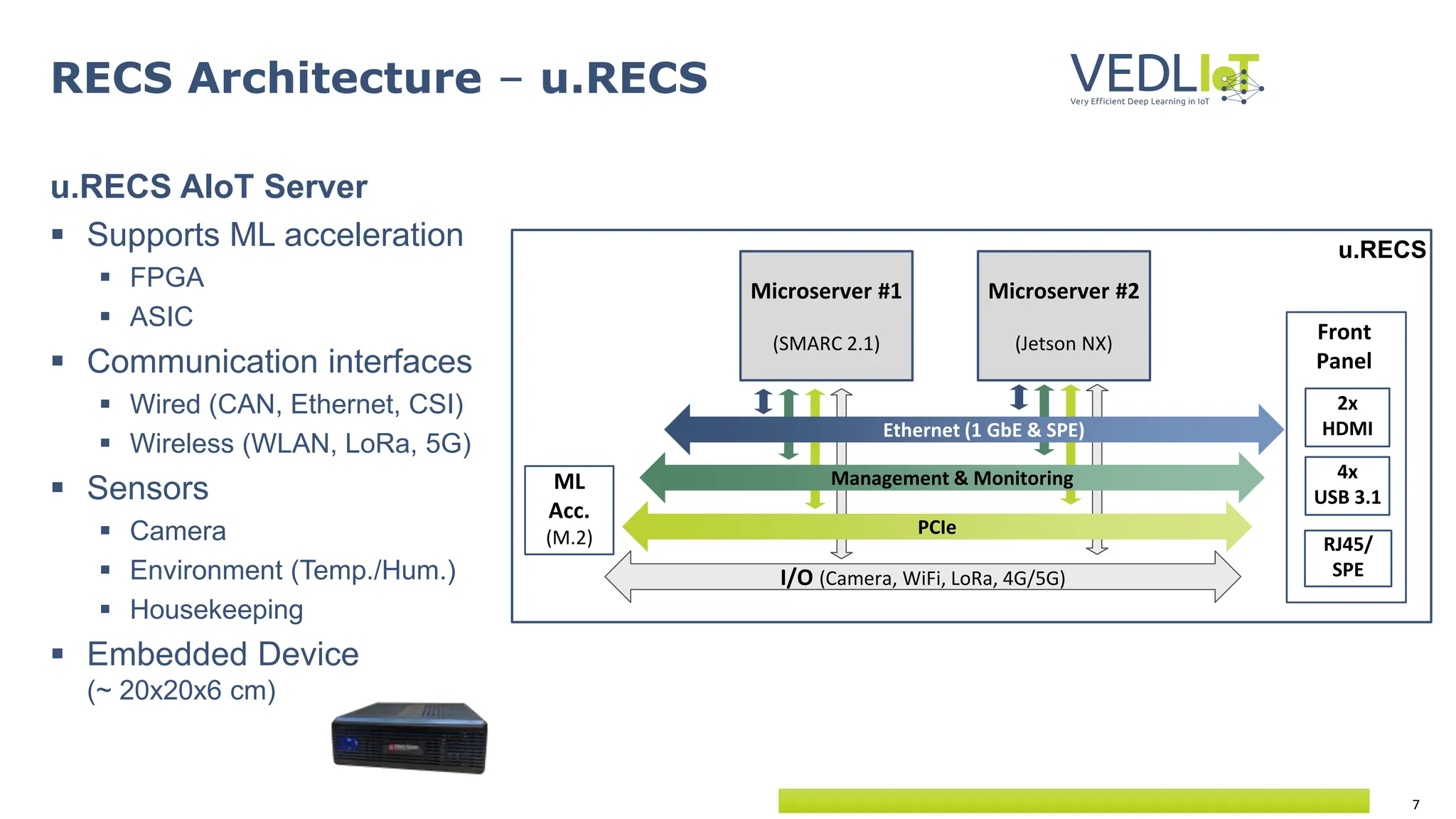
![29
Benchmark performance of DL accelerators
ResNet50
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE] [CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELL…
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
10
100
1000
10000
2 4 8 16 32 64 128
Performance
[GOPS]
Power [Watt]
INT8 FP16 FP32](https://image.slidesharecdn.com/hipeac2023dl4iotvedliotoverview-240206104750-ece29291/75/HiPEAC2023-DL4IoT-Workshop_Jean-Hagemeyer-presentation-29-2048.jpg)
![30
[CELLRANGE] [CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CEL…
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
[CELLRANGE]
10
100
1000
10000
2 4 8 16 32 64 128
Performance
[GOPS]
Power [Watt]
INT8 FP16 FP32
Benchmark performance of DL accelerators
MobileNetV3](https://image.slidesharecdn.com/hipeac2023dl4iotvedliotoverview-240206104750-ece29291/75/HiPEAC2023-DL4IoT-Workshop_Jean-Hagemeyer-presentation-30-2048.jpg)

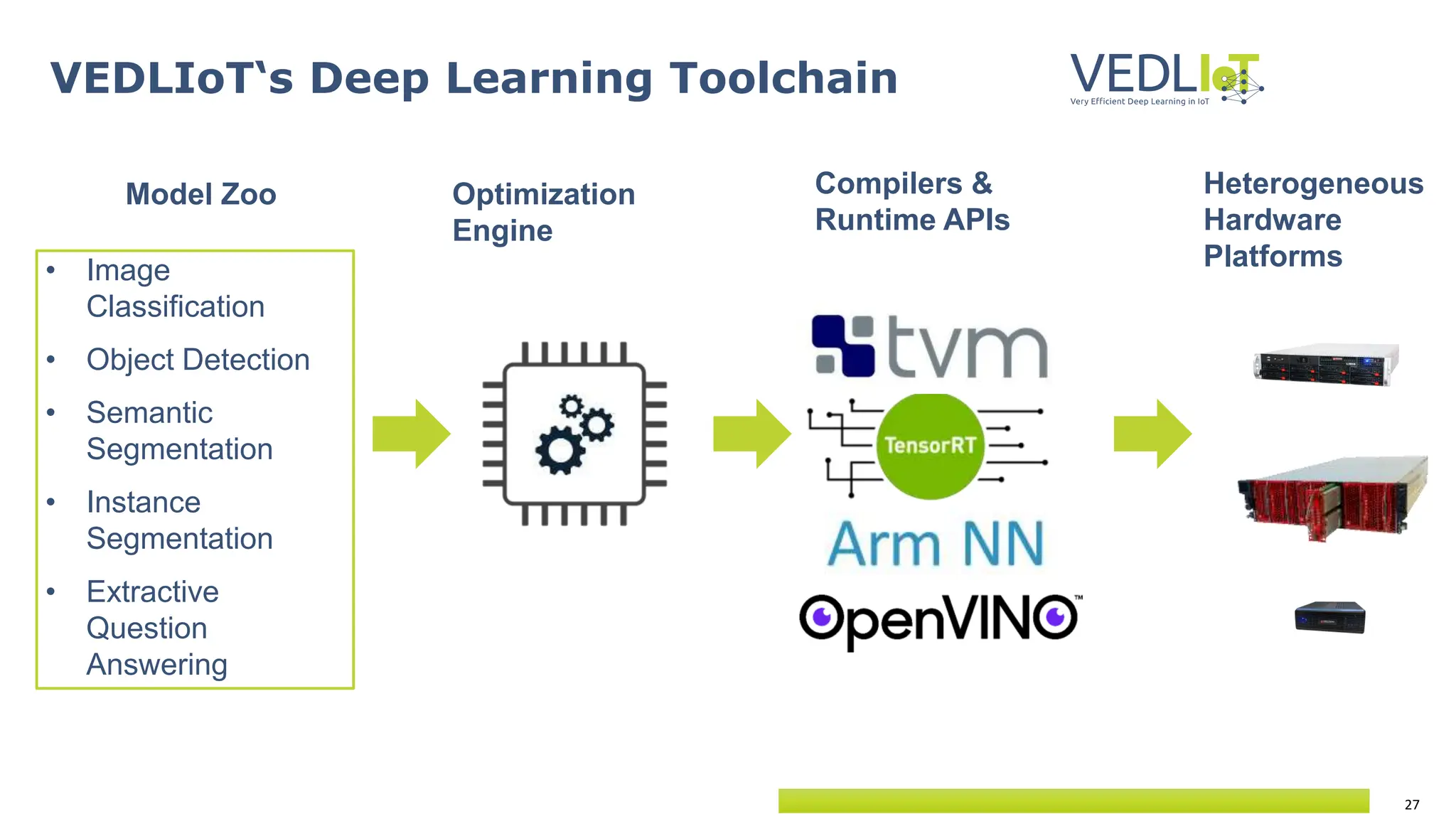
Vedliot is a project coordinated by Bielefeld University focused on enhancing deep learning for IoT through scalable and heterogeneous hardware platforms. It encompasses various use cases, including industrial IoT, automotive, and smart home applications, with a consortium of 12 partners from multiple EU countries and an overall budget of approximately 8 million euros. The project emphasizes the development of efficient, flexible deep learning accelerators utilizing FPGA and ASIC technologies, aiming for improved performance and energy efficiency in IoT systems.






















































