Download to read offline



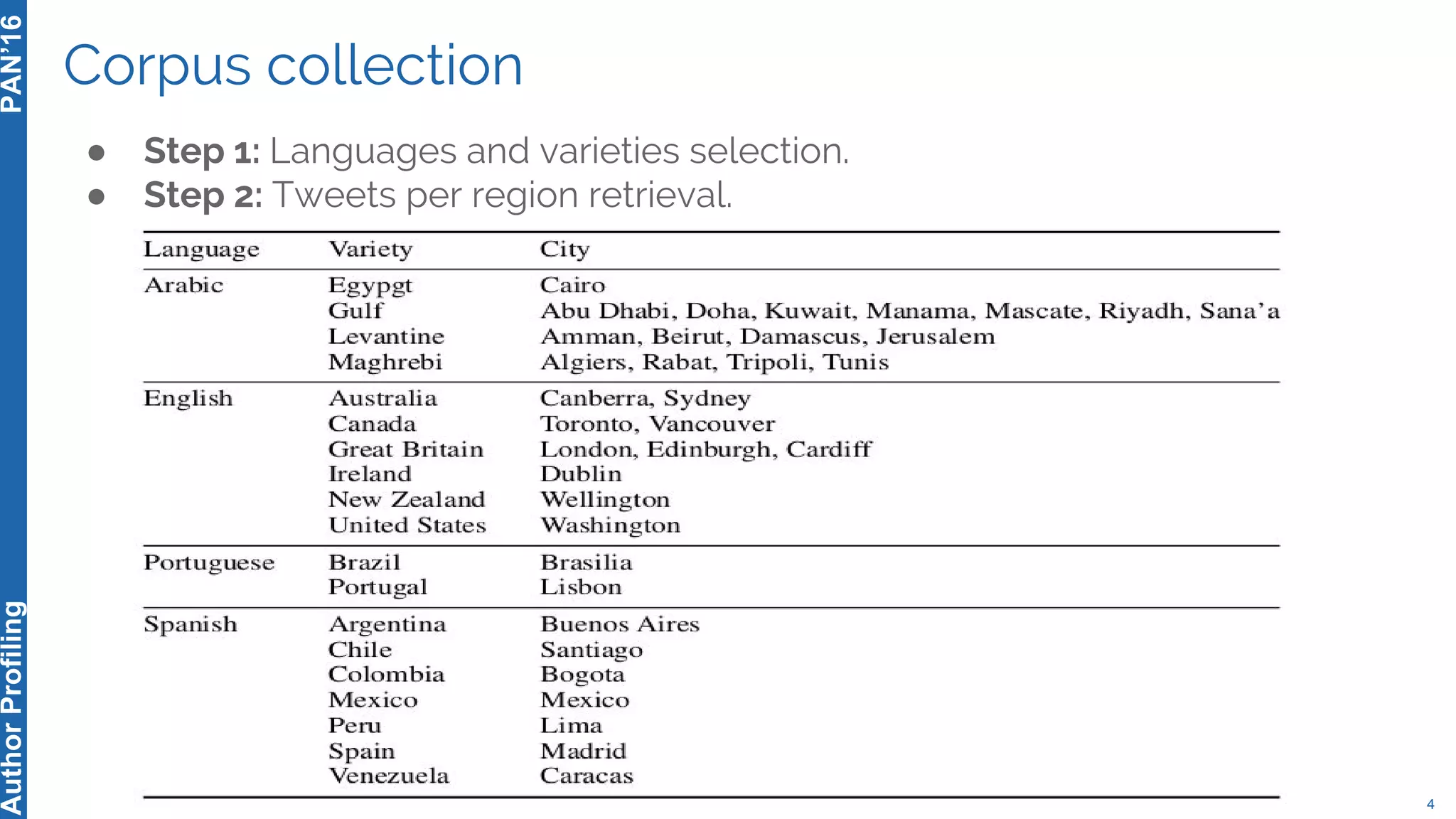

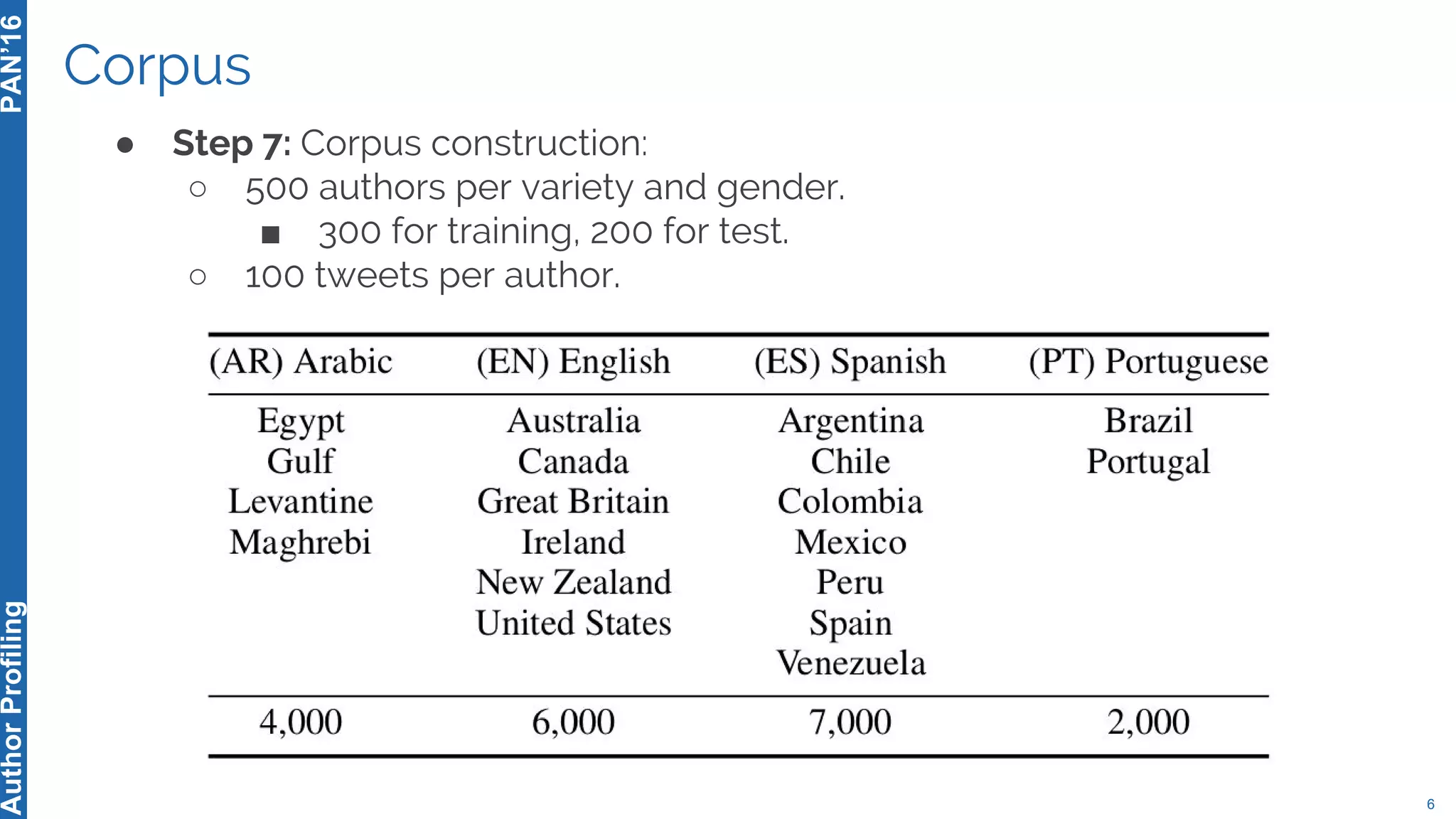


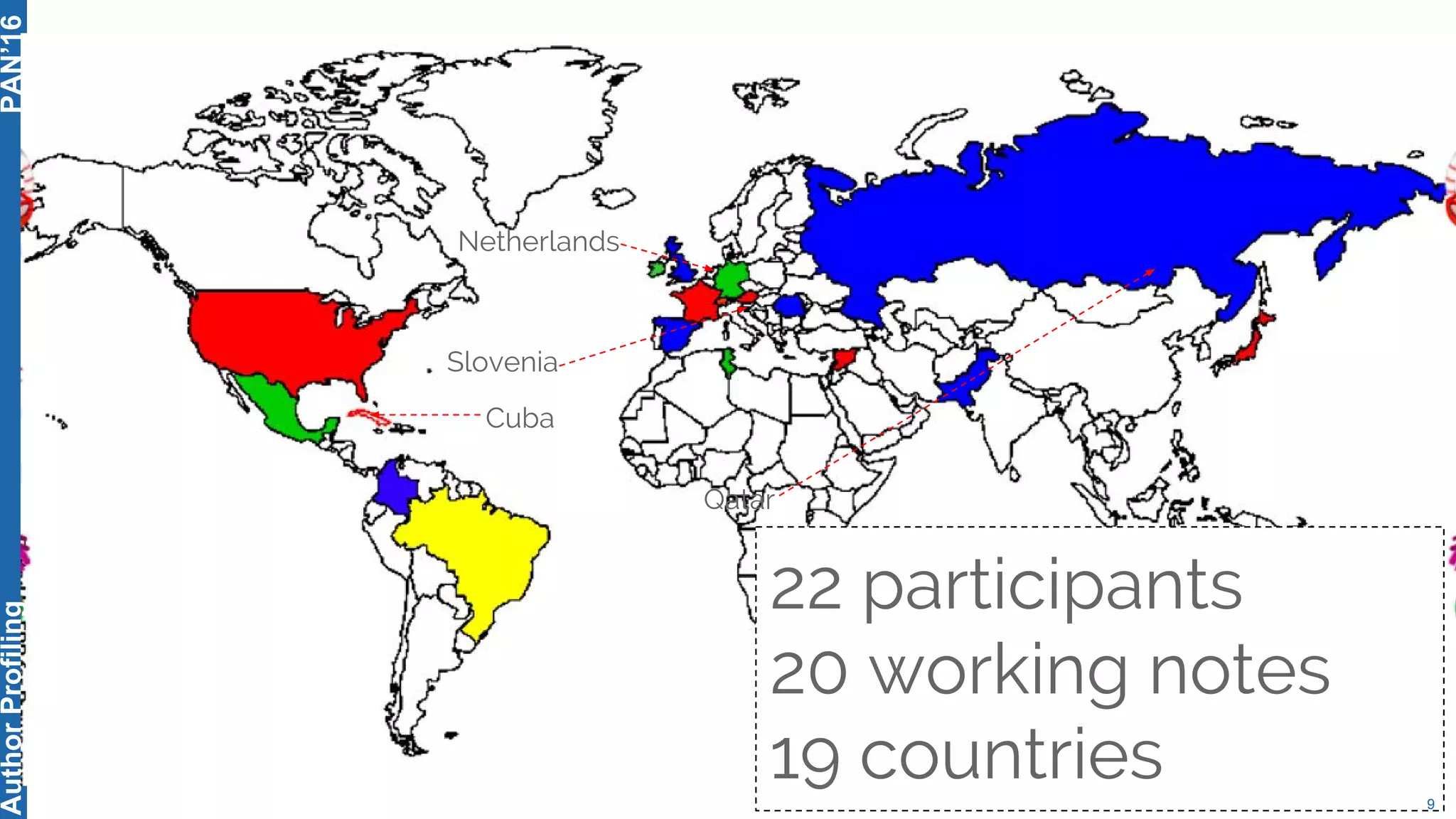

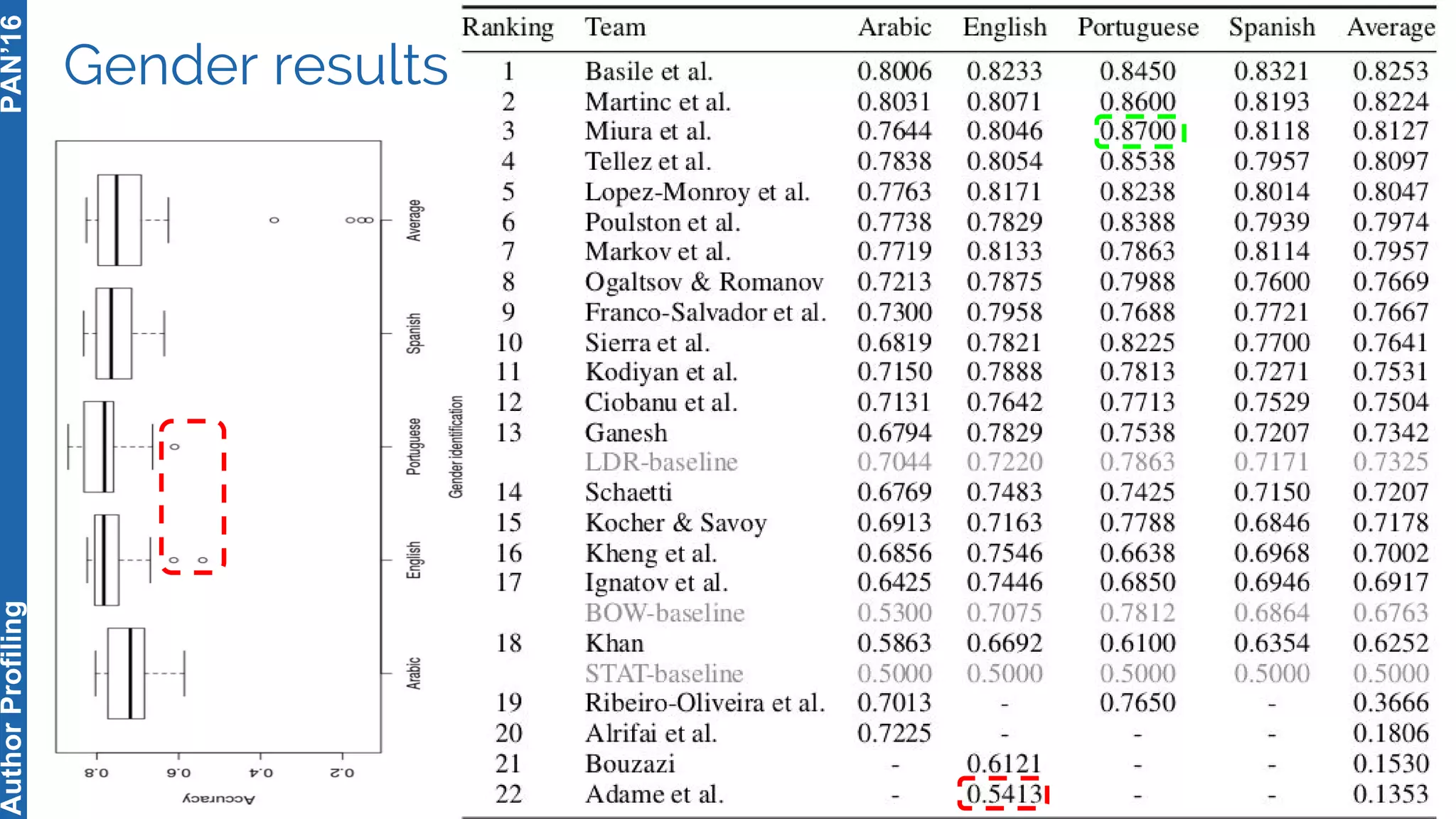
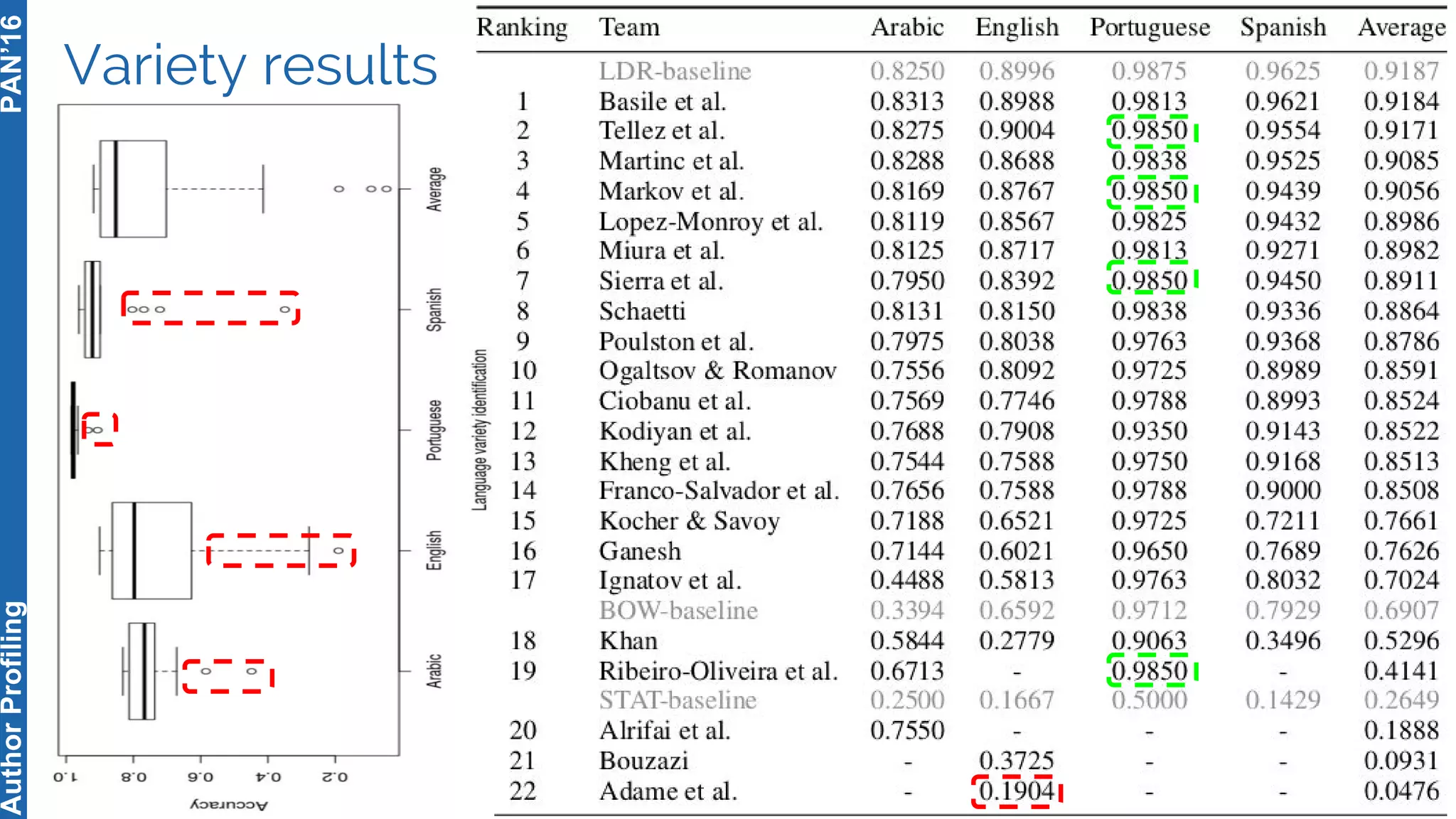
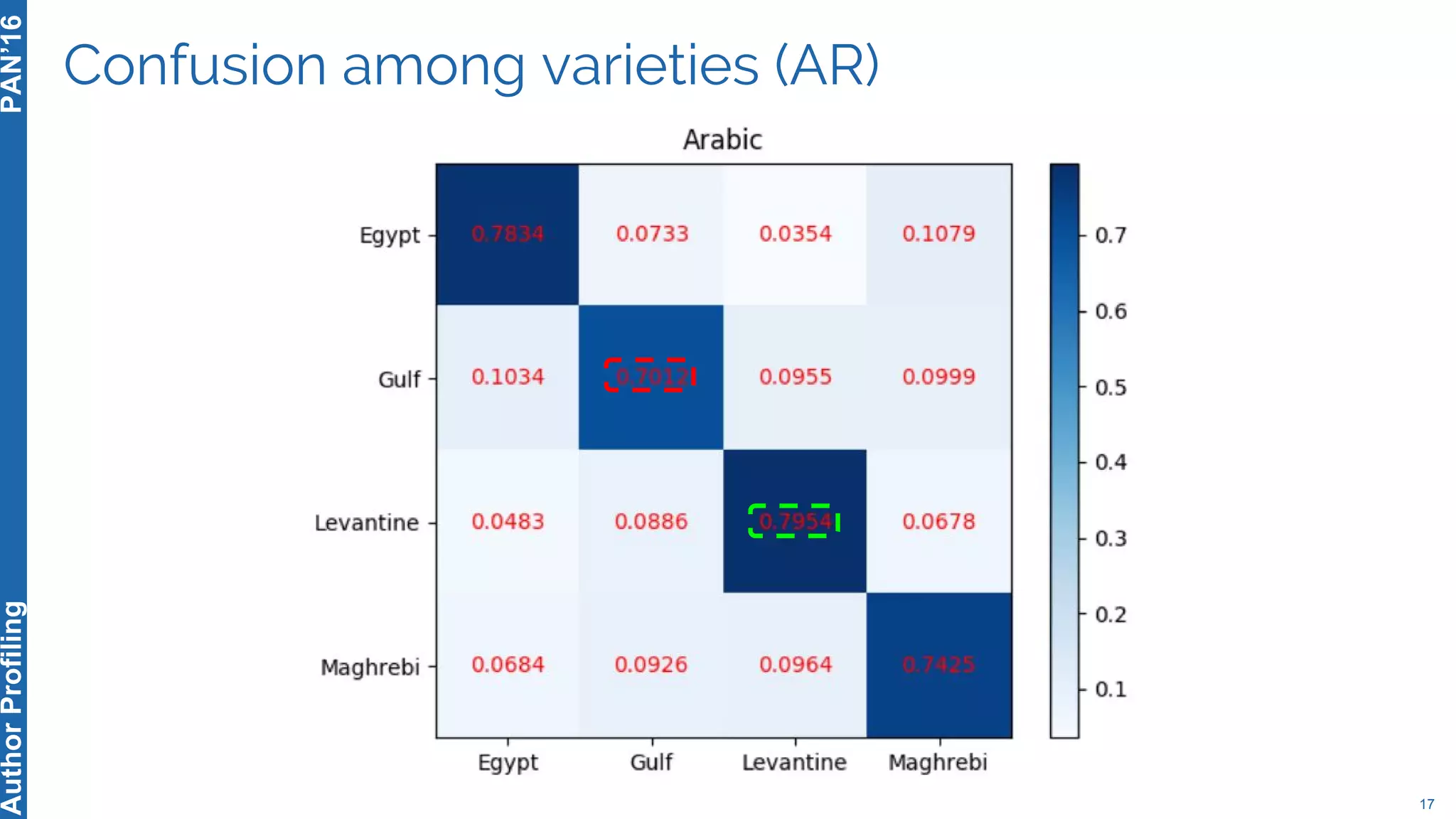
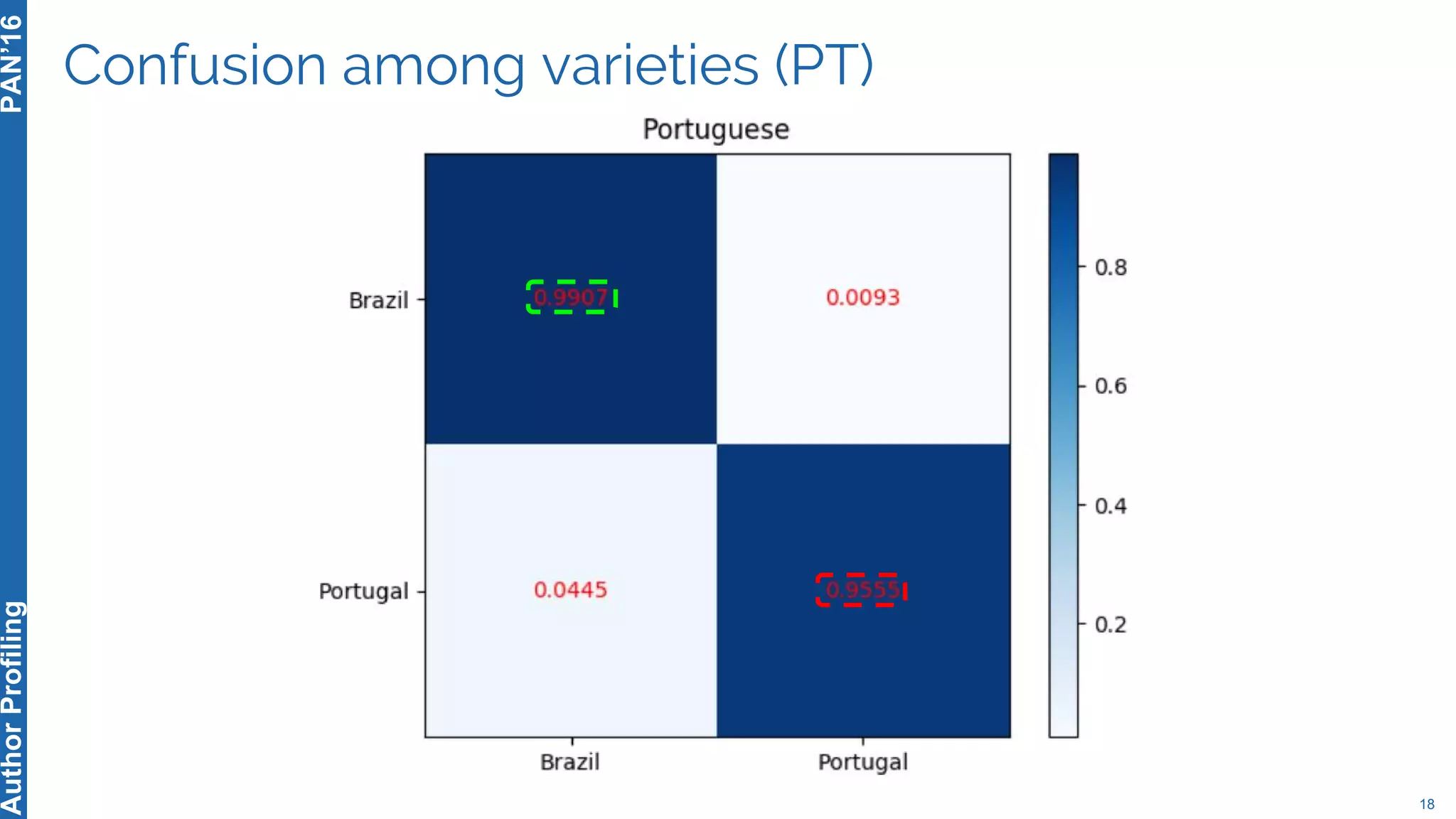
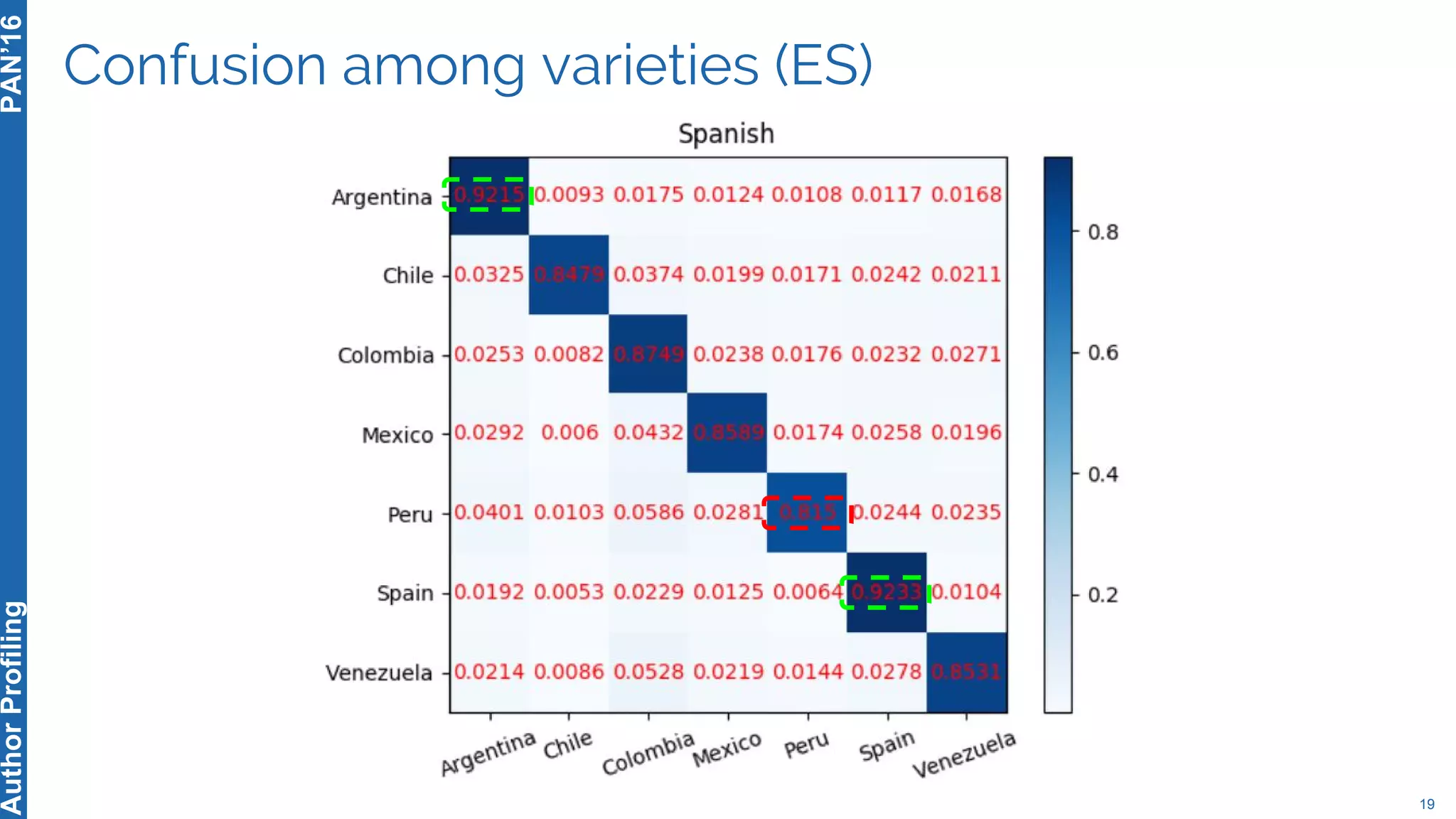
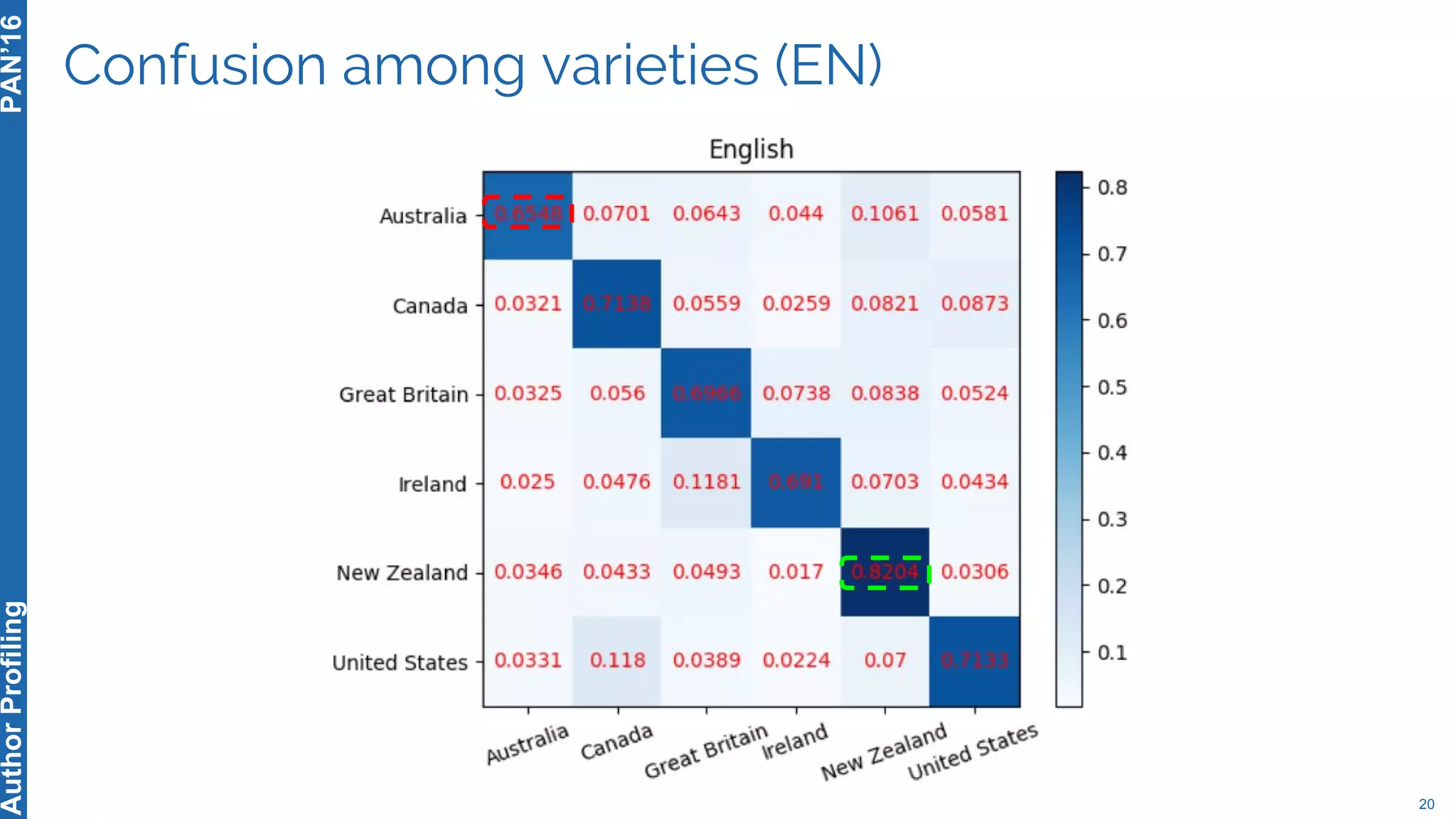
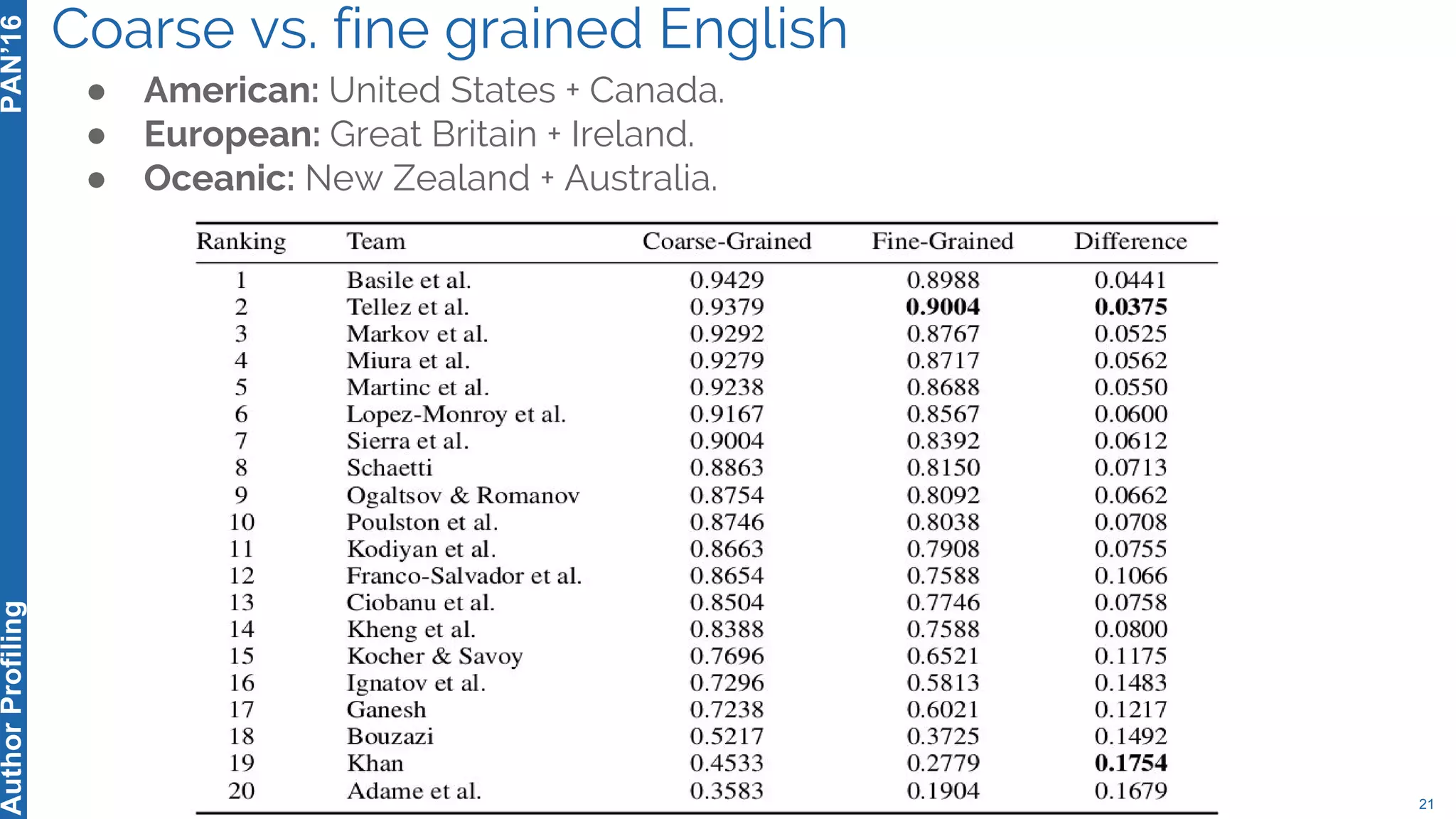
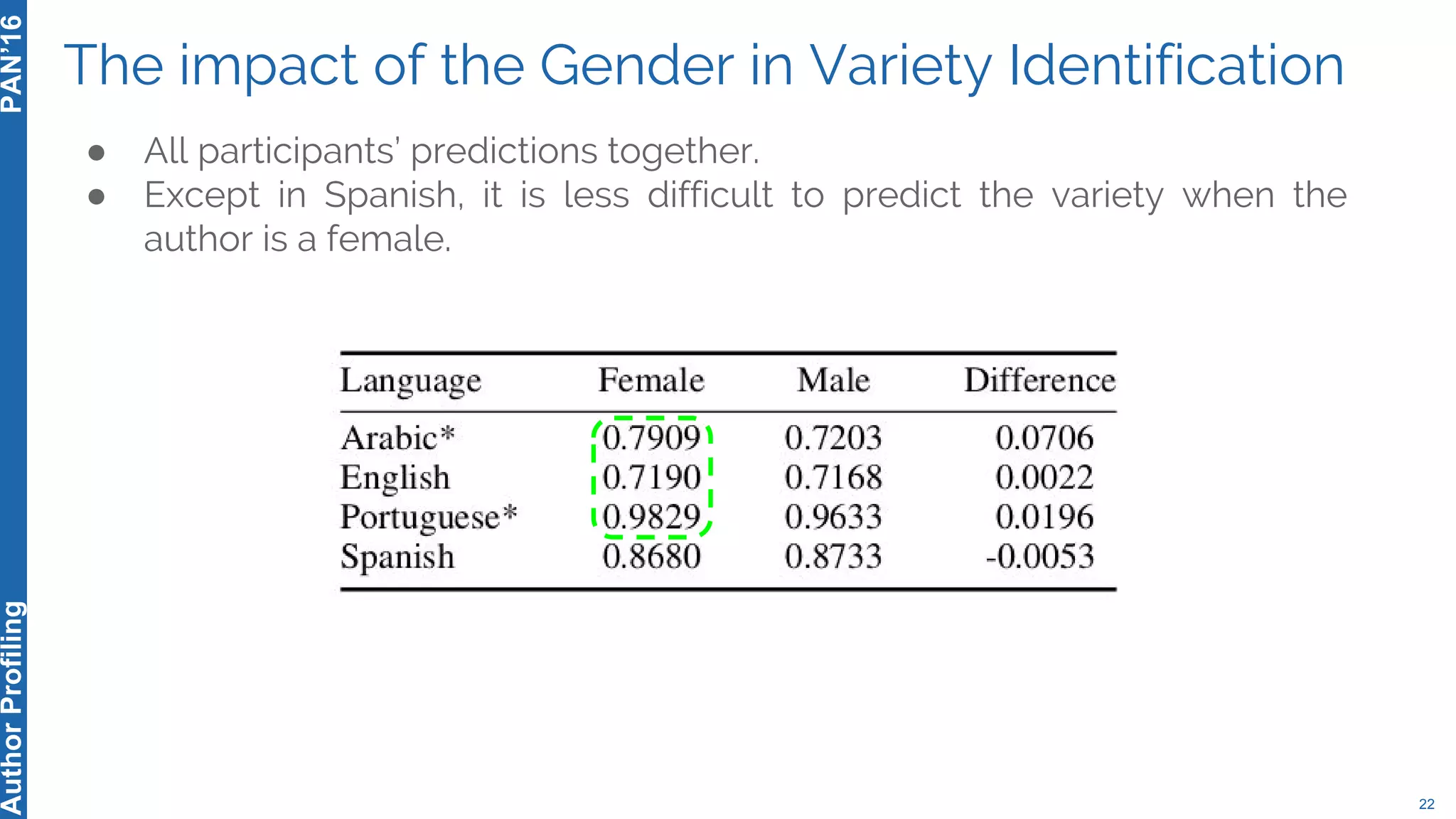

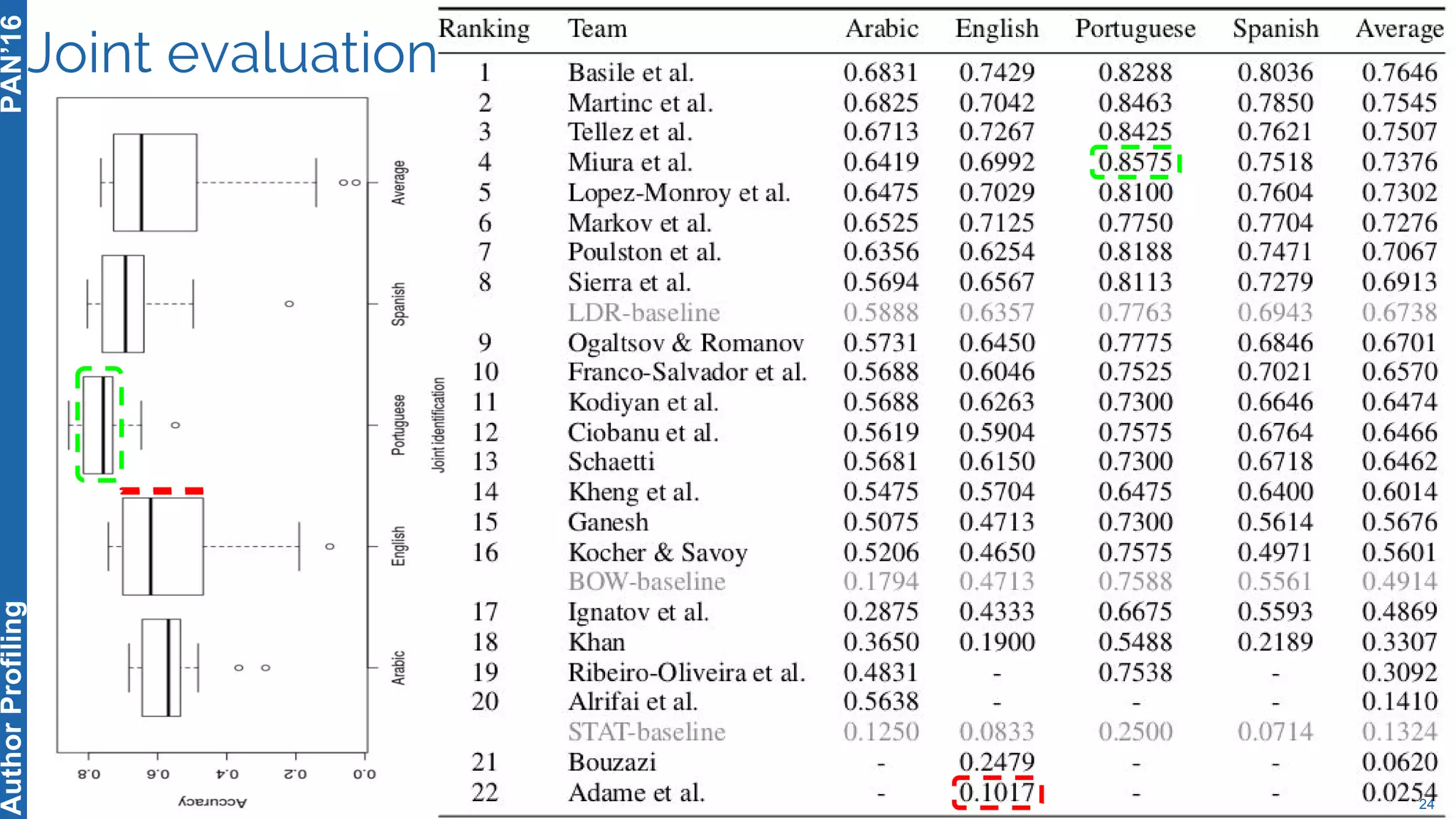
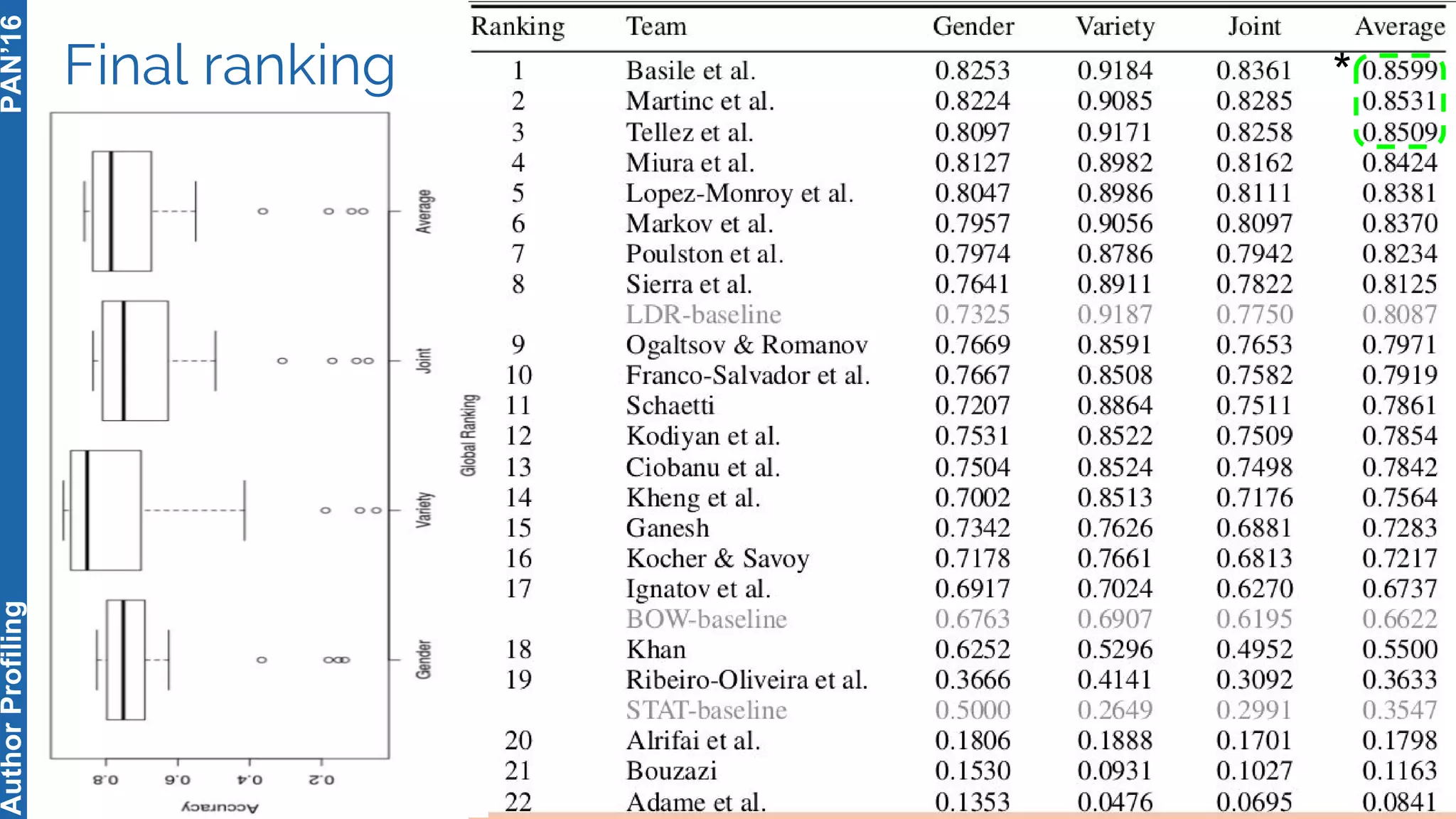
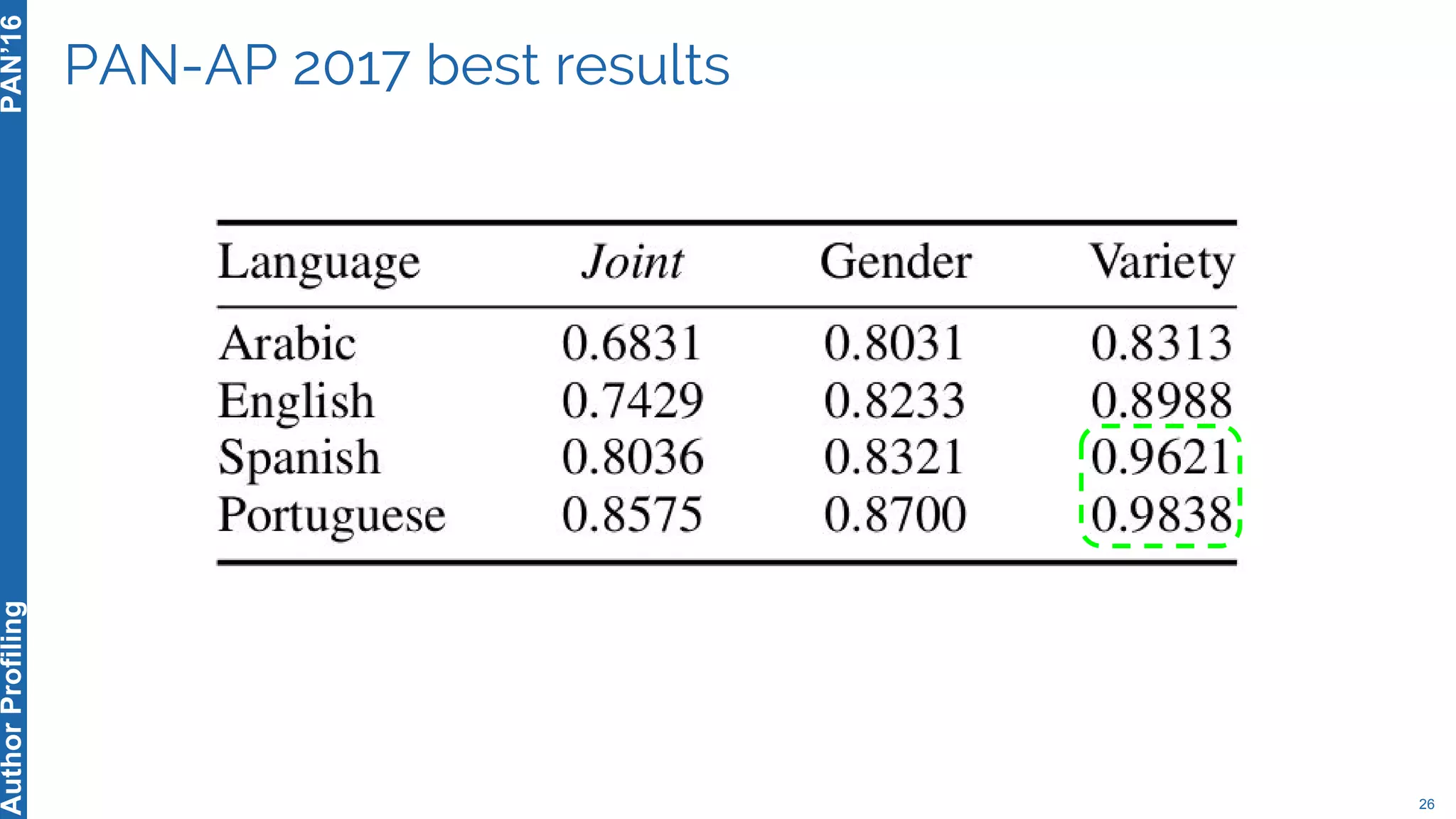

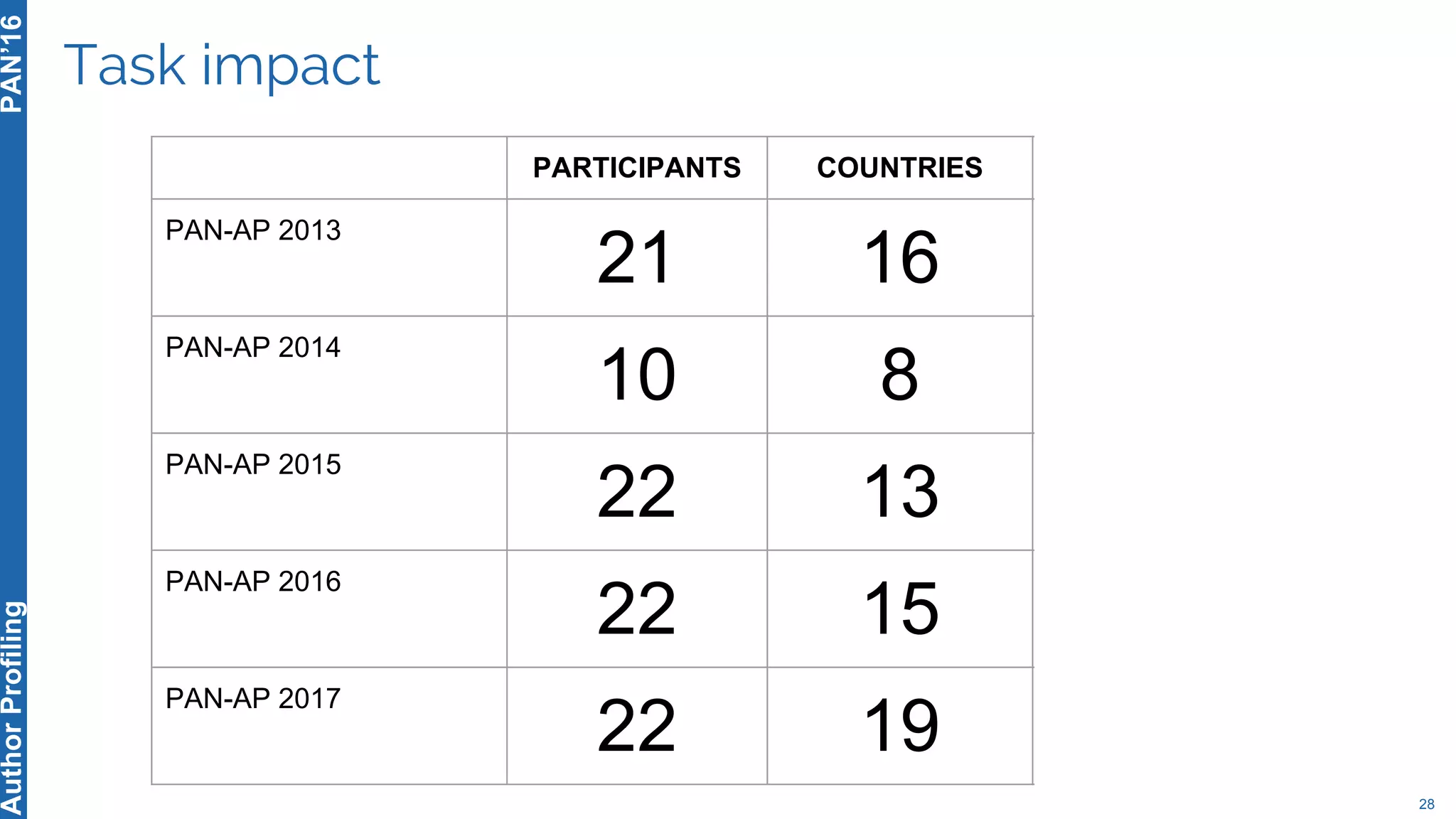




The 5th Author Profiling Task at PAN 2017 focused on identifying gender and language variety in Twitter posts, utilizing a multi-step approach for corpus collection and annotation across four languages. Various machine learning methods, including deep learning, were employed, with Portuguese achieving the best results and Arabic showing challenges in both gender identification and language variety recognition. The evaluation highlighted significant differences in identification success based on gender, language, and regional varieties, indicating complexity in accurately profiling authors based on their tweets.































































