













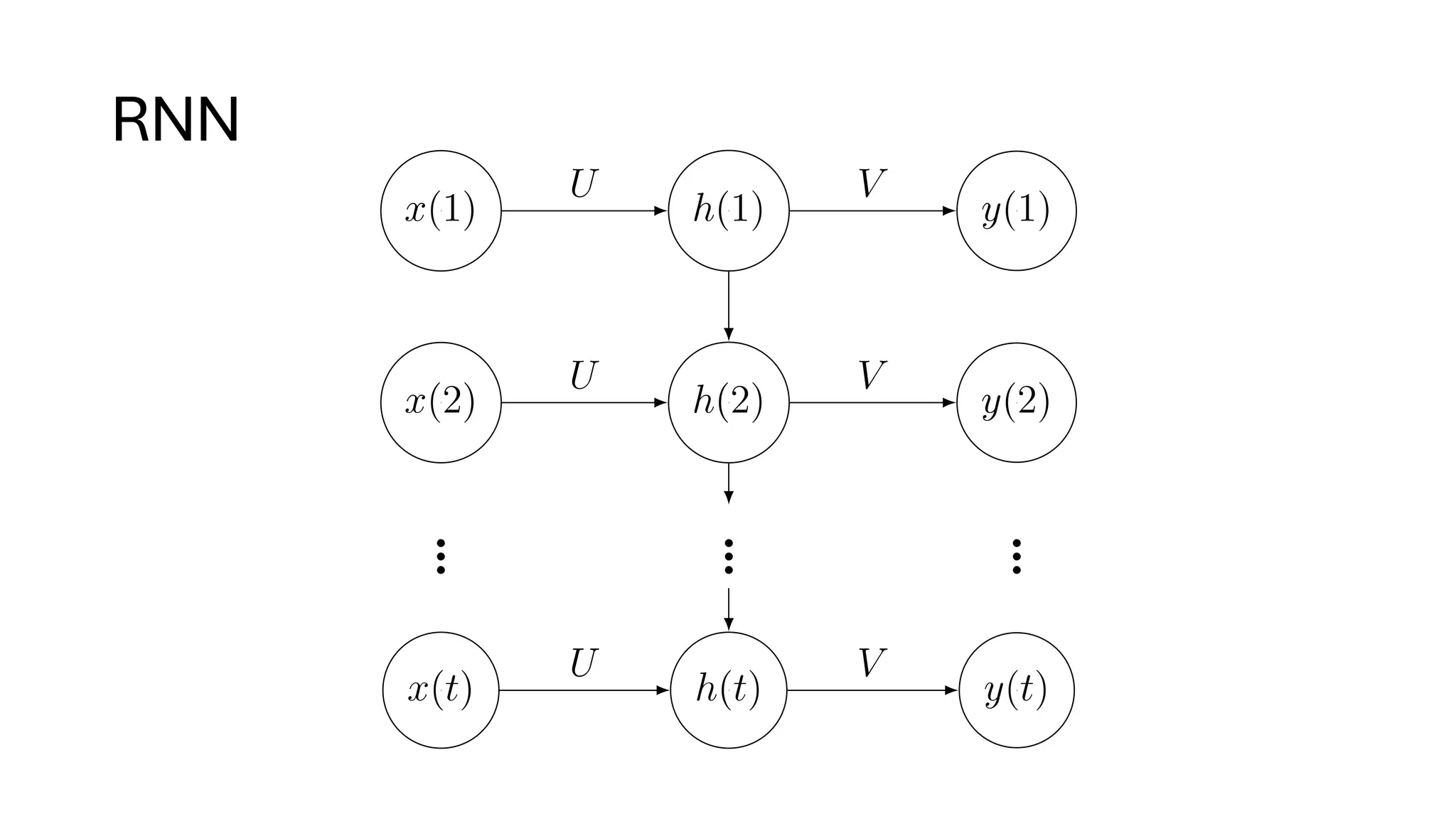


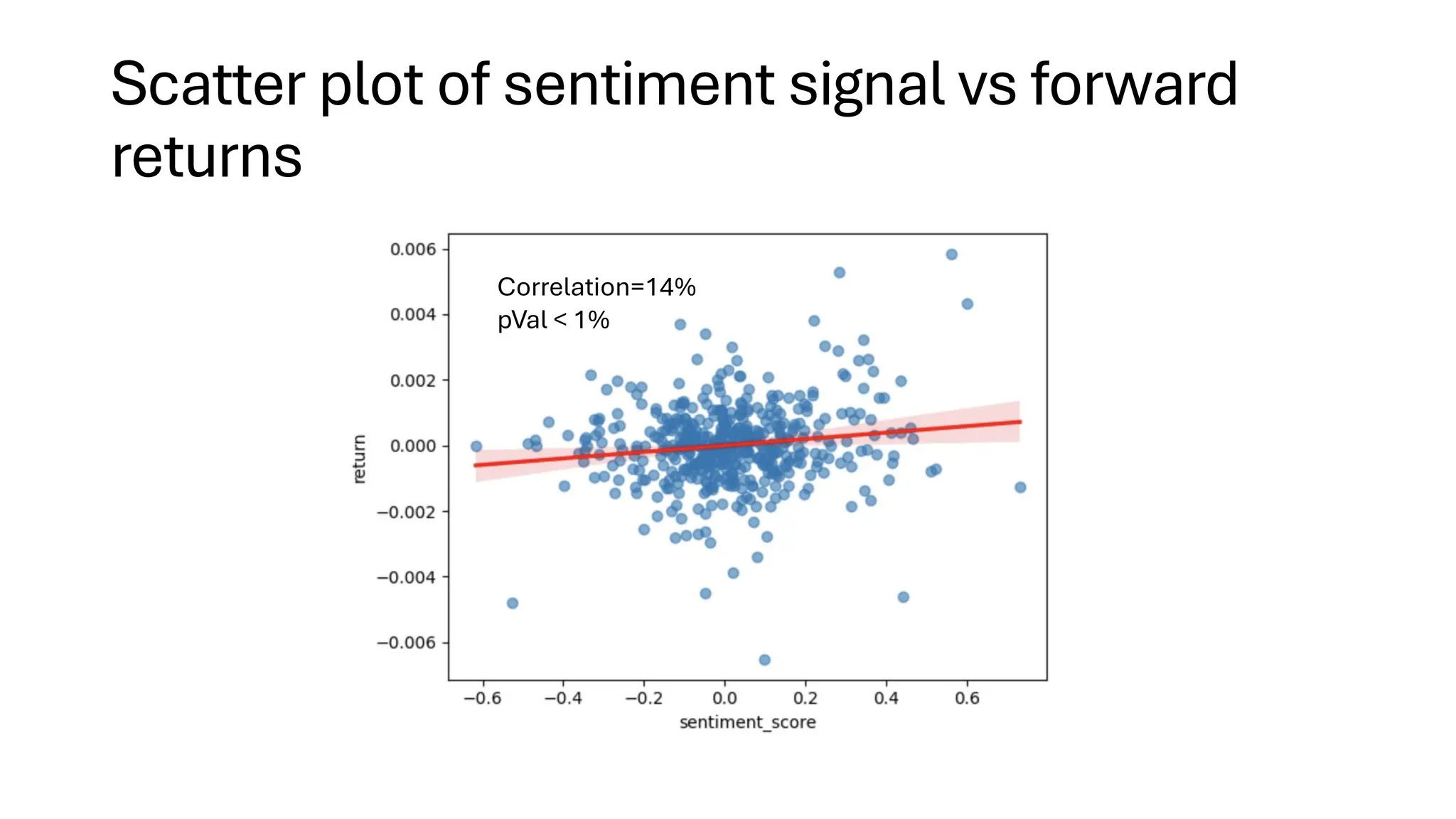
![Example application: sentiment analysis
• Use open-source pre-trained LLM to compute
sentiment score [-1, 1] on Fed Chair’s speech.
➢FinBERT. BERT is a pre-trained LLM by Google.
➢FinBERT is finetuned on financial data.
➢See our book on how to fine-tune a model using your own data.
➢Predict short term price moves in SPY during FOMC press
conferences using such sentiment scores every 30
second.](https://image.slidesharecdn.com/genaifortradingandassetmanagementwebinarv31-250411073104-298d833c/75/GenAI-for-Trading-and-Asset-Management-by-Ernest-Chan-18-2048.jpg)




Presentation from the power-packed webinar on AI-driven trading and automation, bringing together leading experts and a community of over 6000 traders, analysts, developers, and students. Participants got the chance to interact live with experts, ask questions, and gain practical, actionable skills in automated trading—making this webinar a useful resource for anyone serious about the future of trading technology. In Session 1, renowned quant expert Dr. Ernest Chan explores the evolving role of Generative AI in finance, diving into advanced trading strategies that go beyond traditional language models (LLMs). About the author: Dr. Ernest P. Chan is a recognized expert in applying statistical models and machine learning to finance. He is the Founder and Chief Scientist at PredictNow.ai, where he helps investors make informed decisions using advanced data-driven insights. Additionally, he is the Founder and Non-executive Chairman of QTS Capital Management, LLC, which focuses on systematic trading strategies. Dr. Chan has worked at notable organizations like IBM Research, Morgan Stanley, and Credit Suisse, gaining experience in pattern recognition, data mining, and quantitative trading. Dr. Chan obtained his PhD in Physics from Cornell University and his B.Sc. in Physics from the University of Toronto. He has also authored several influential books, including Quantitative Trading and Algorithmic Trading. He was an Adjunct Associate Professor of Finance at Nanyang Technological University in Singapore and an adjunct faculty at Northwestern University’s Masters in Data Science program. Dr. Chan combines extensive industry experience with deep technical knowledge, making him an excellent resource for understanding how to apply machine learning to trading effectively. This webinar was conducted on: Thursday, April 10, 2025























































































