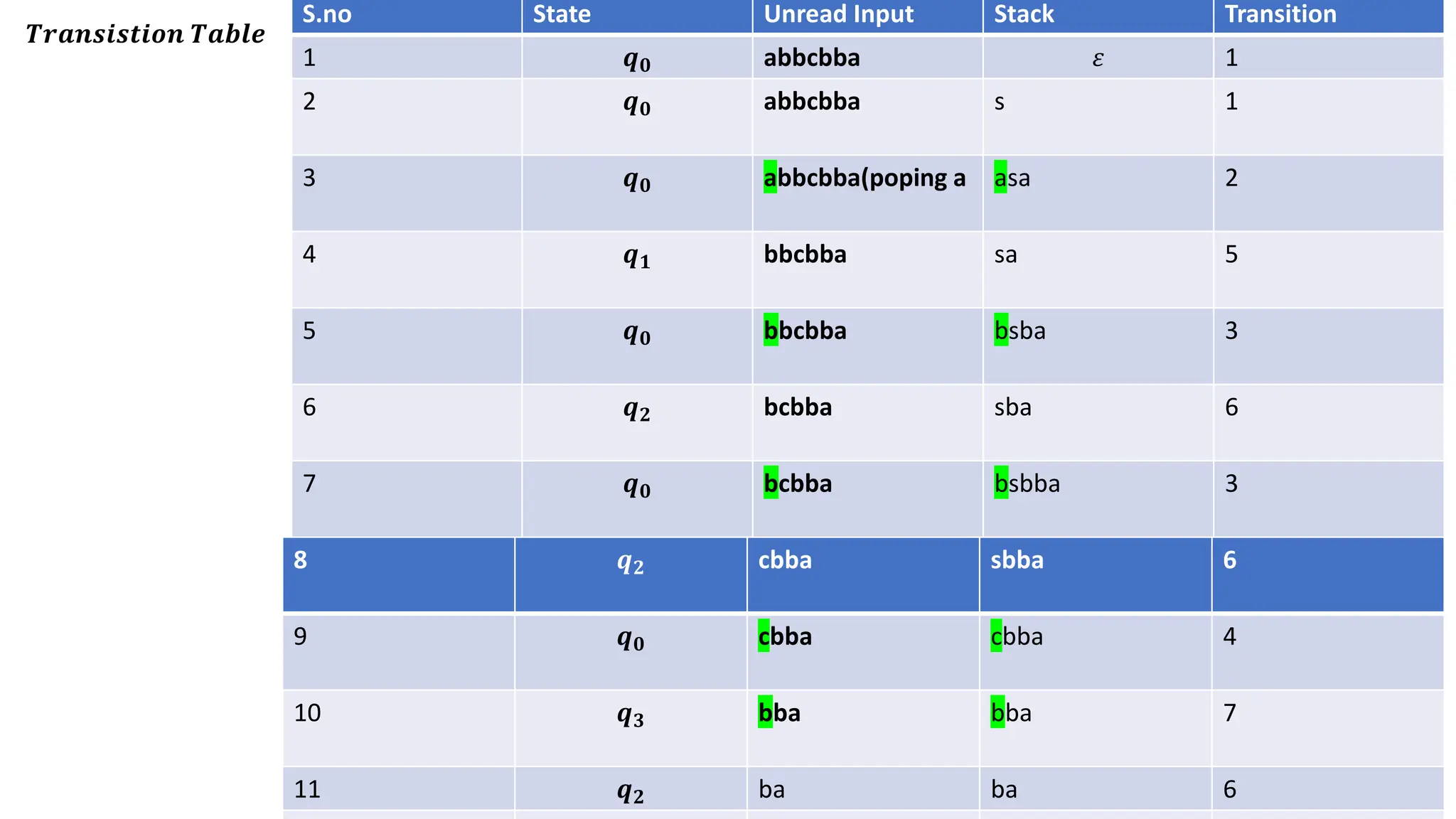
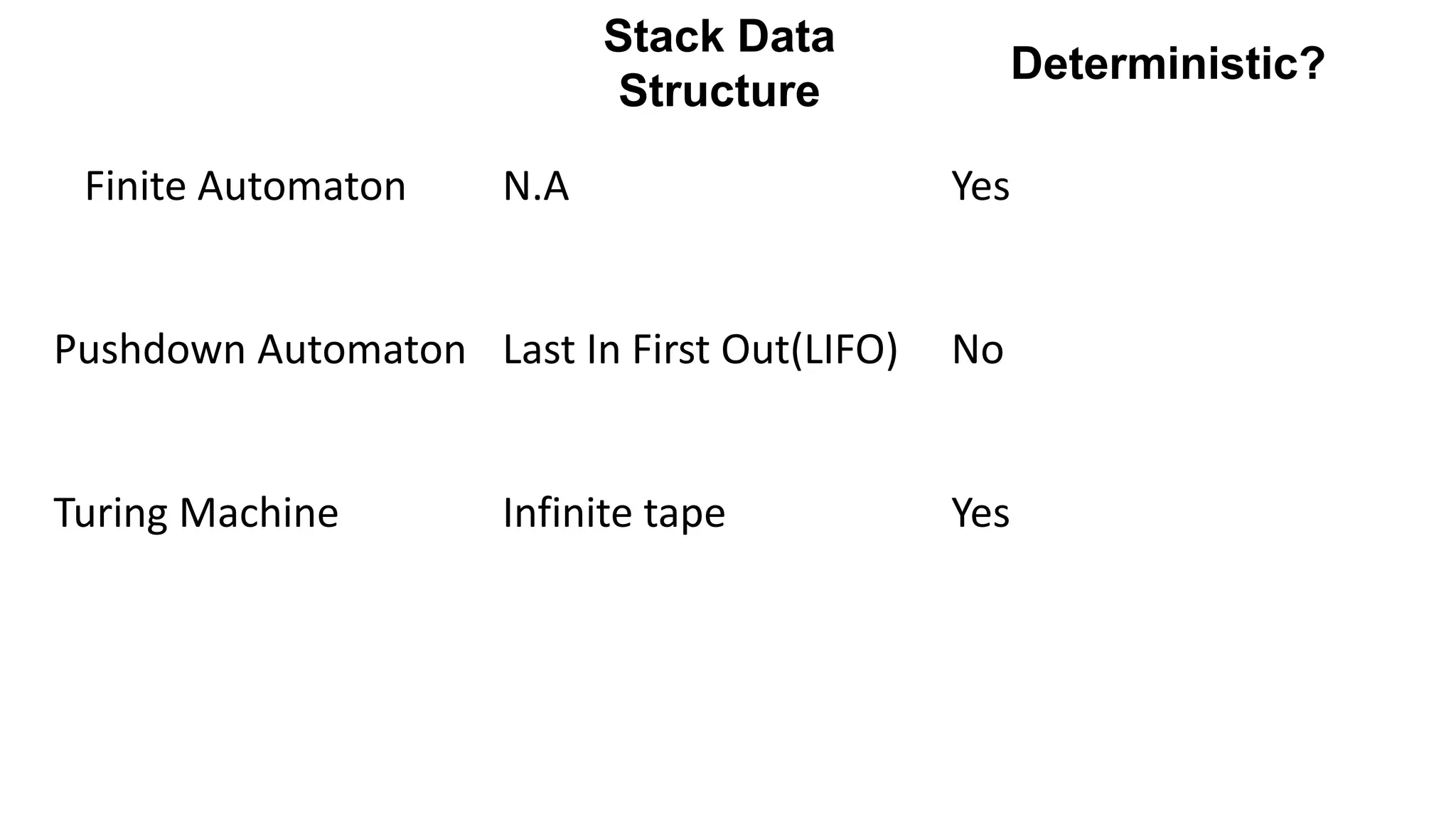
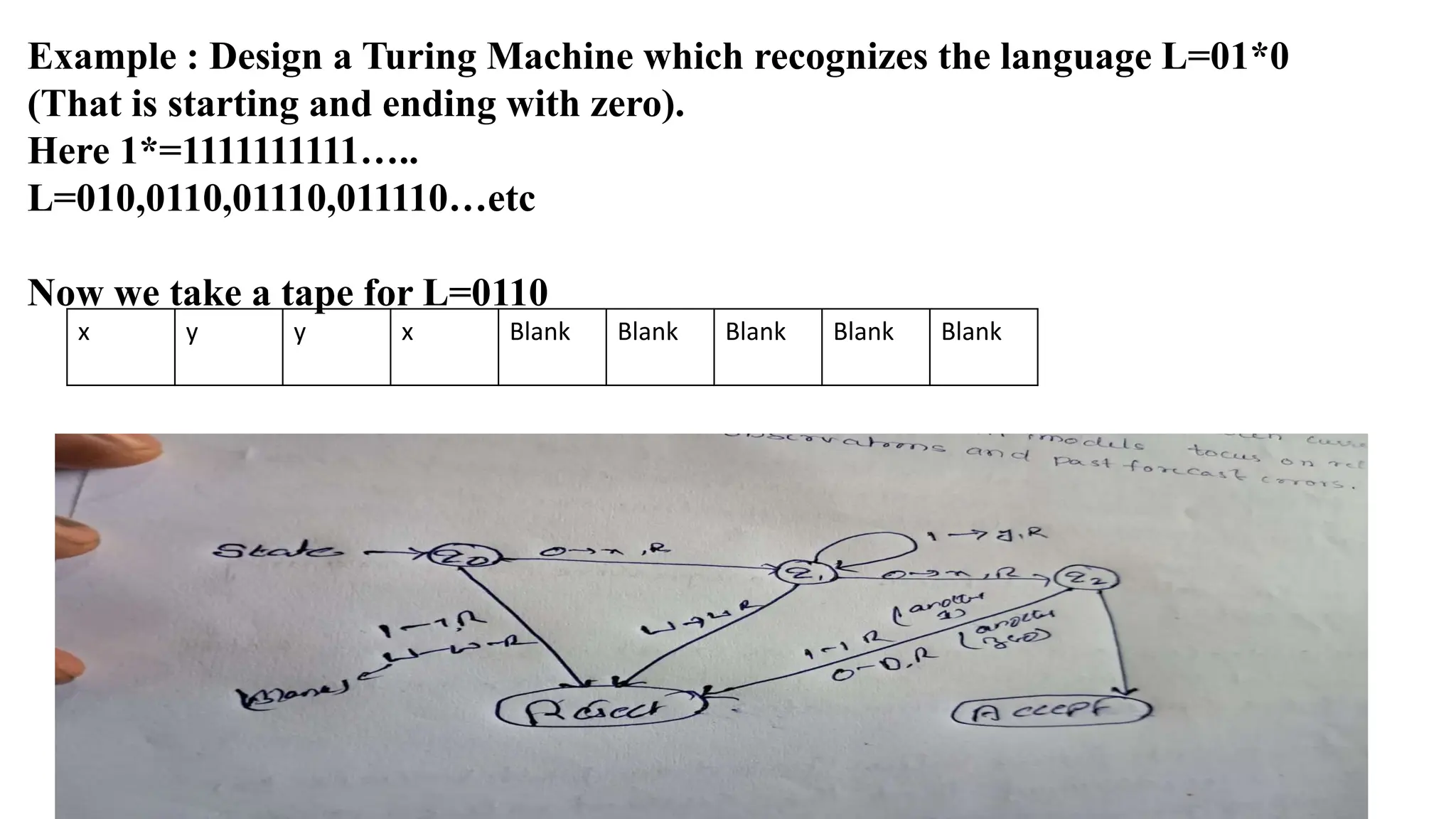
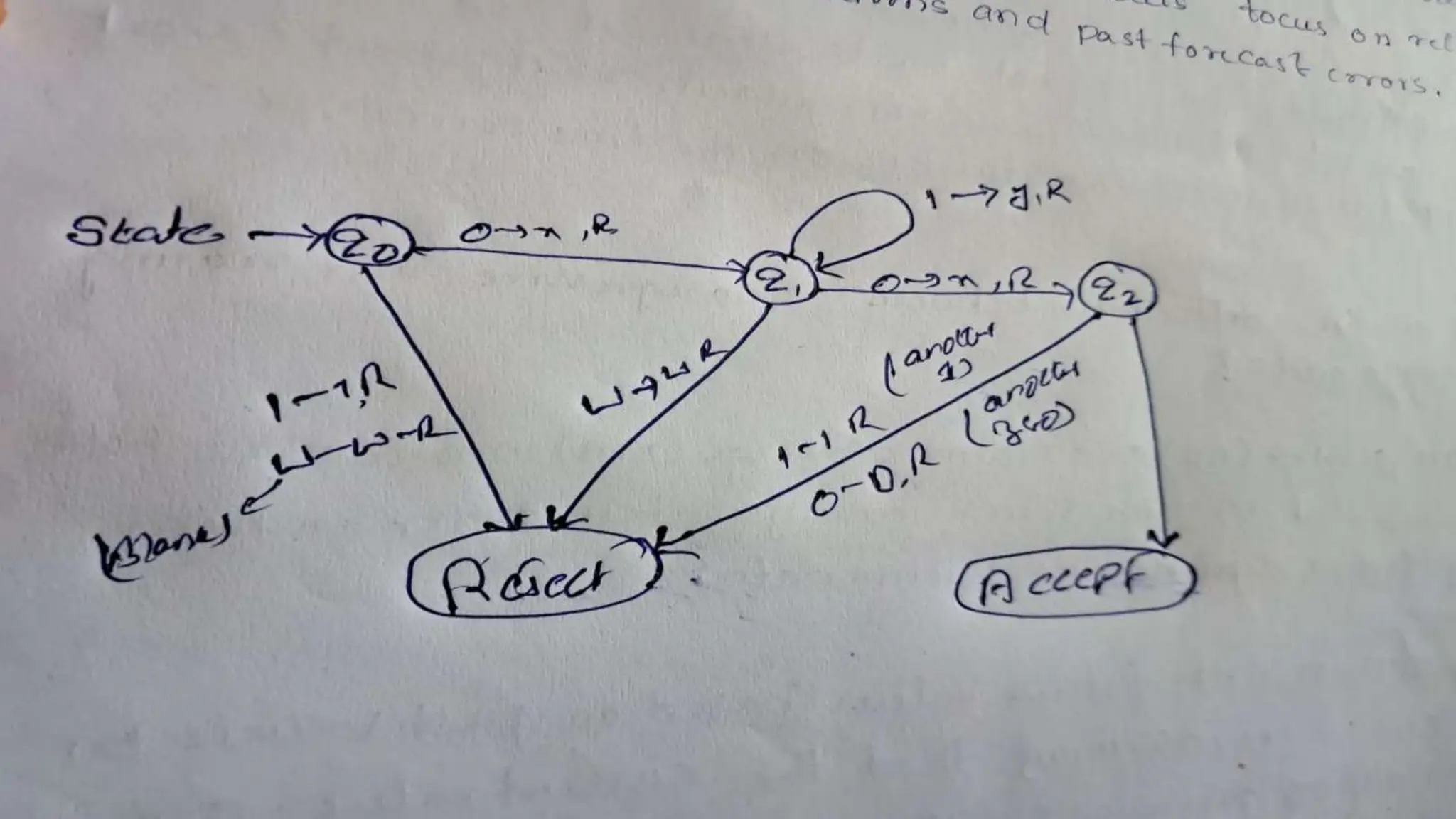
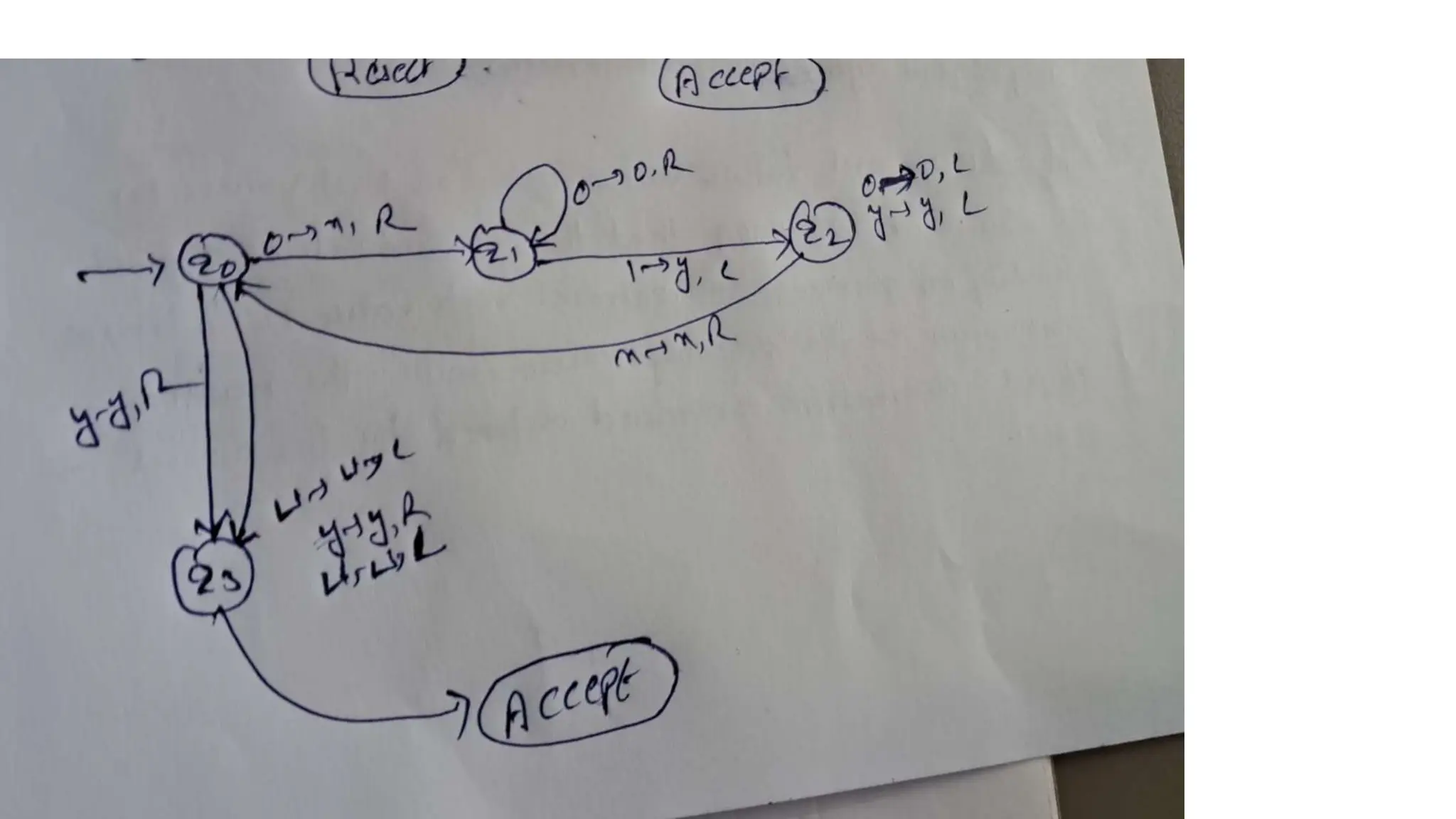
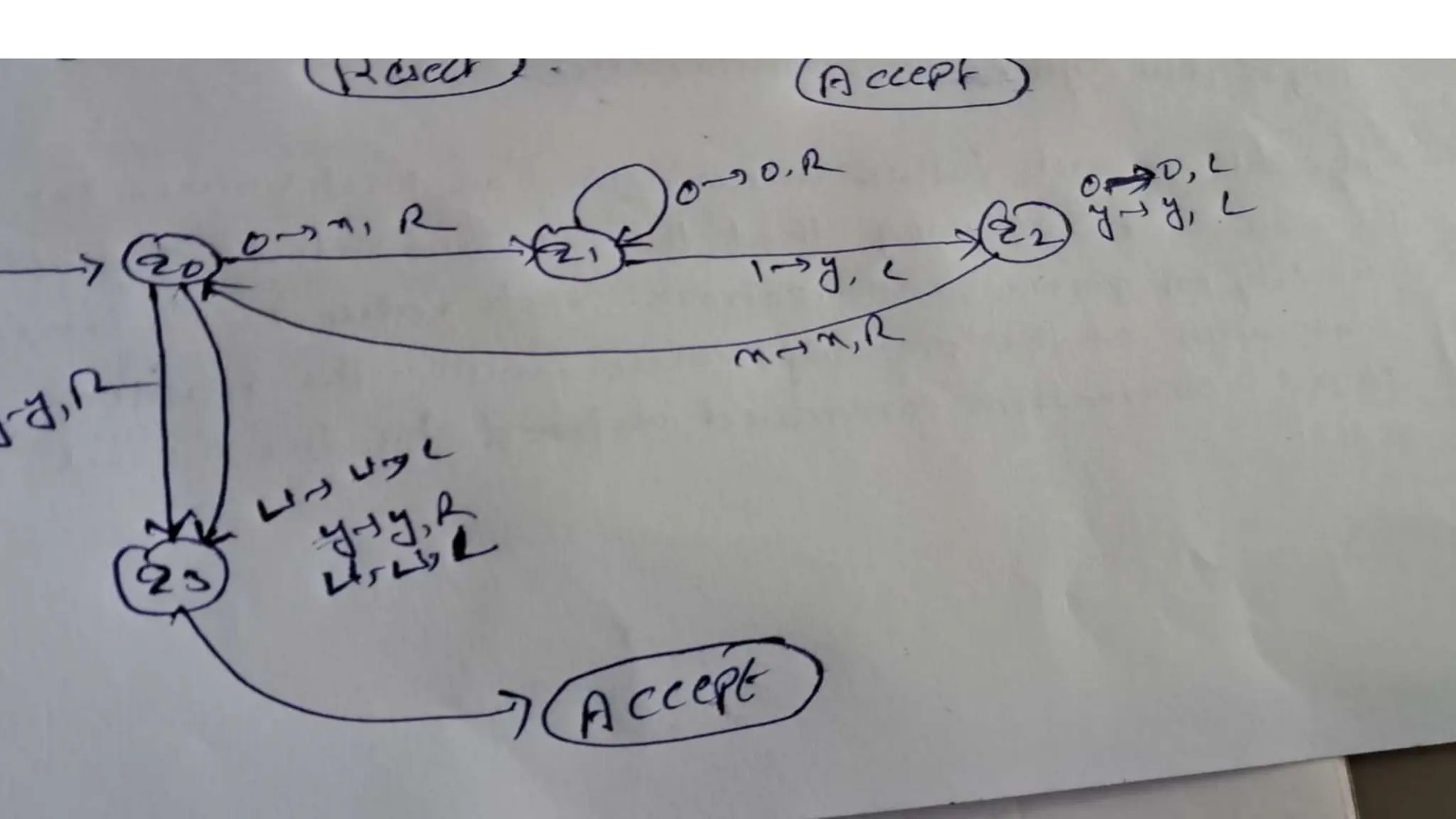
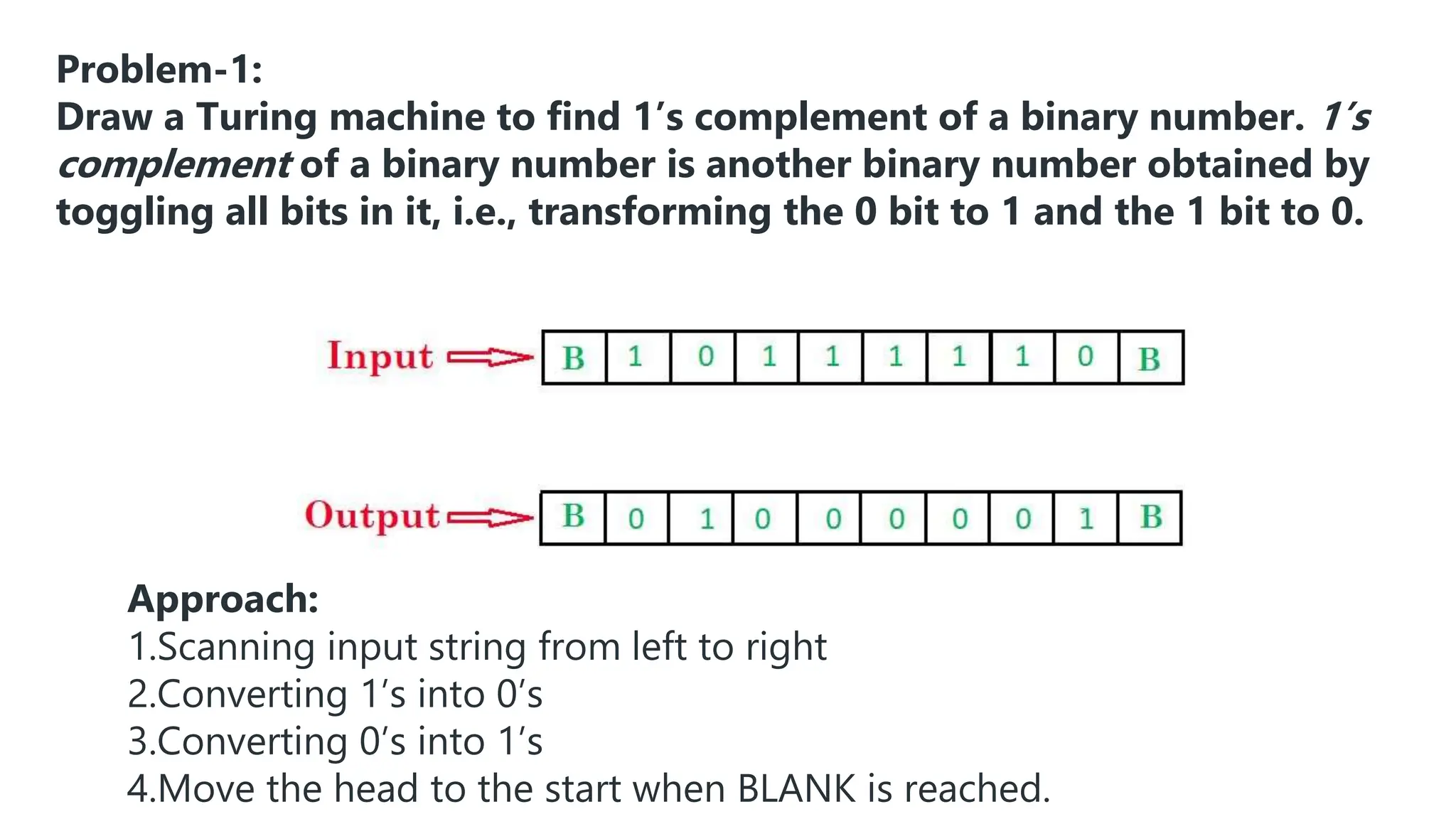
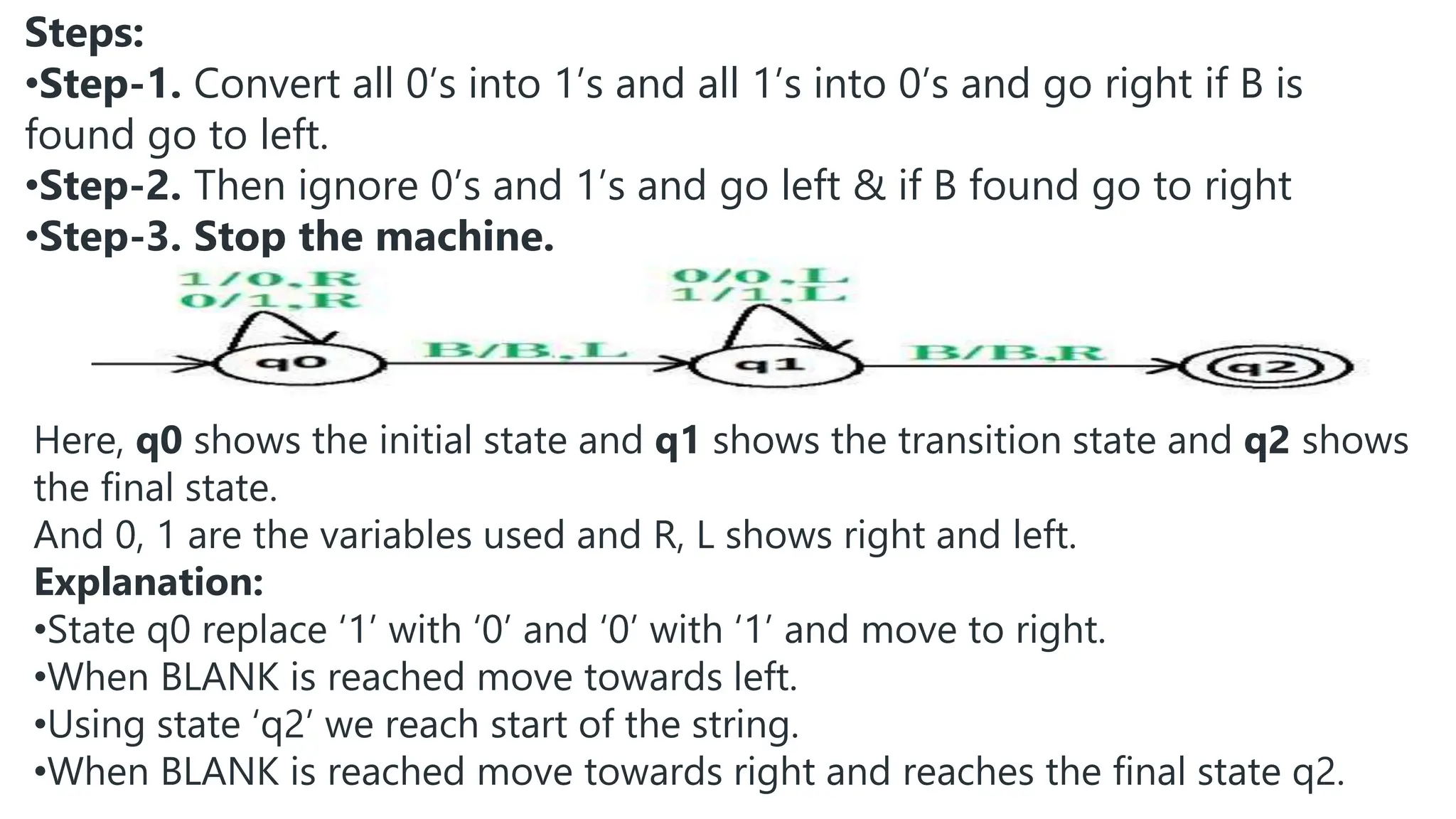
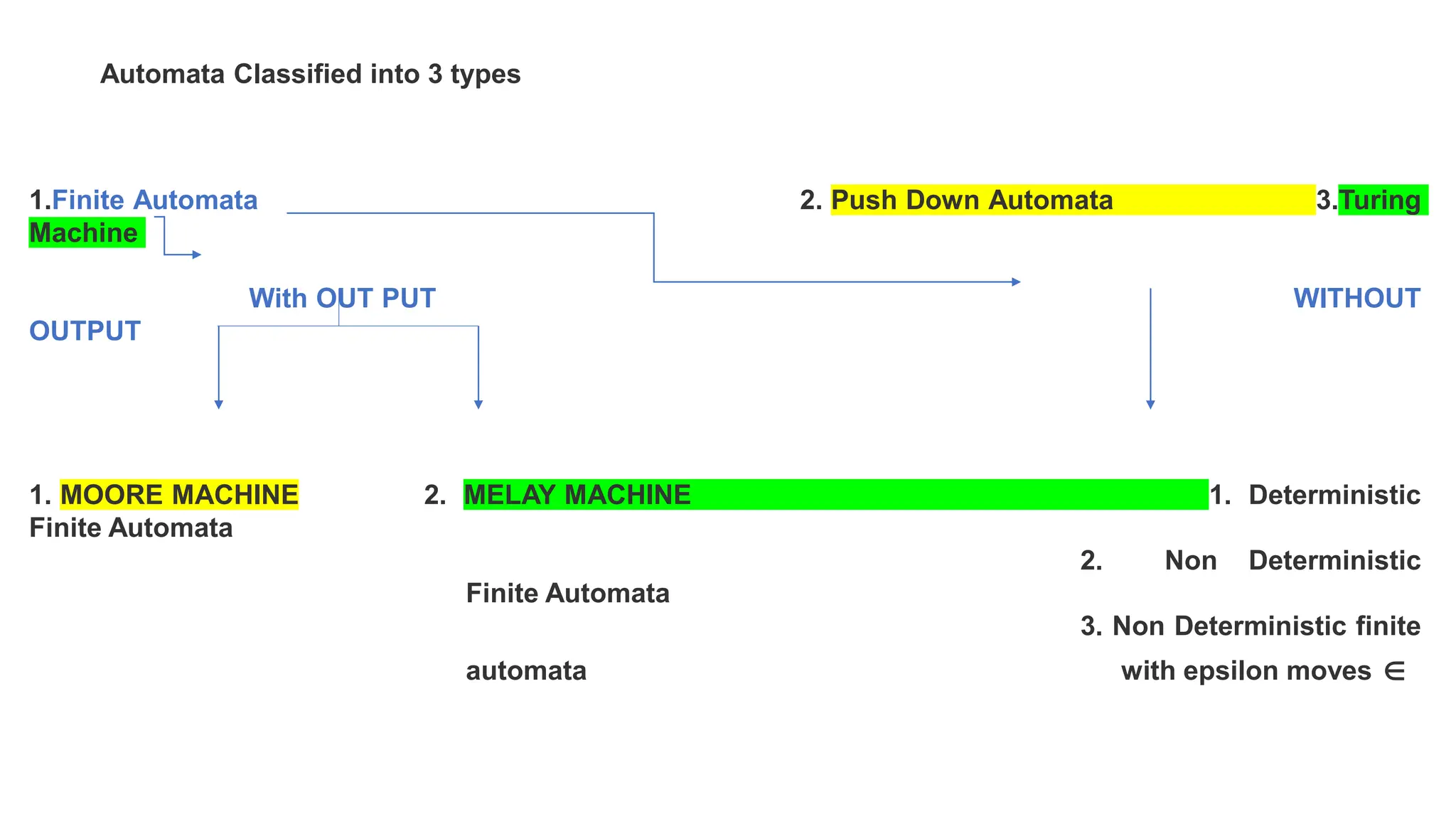
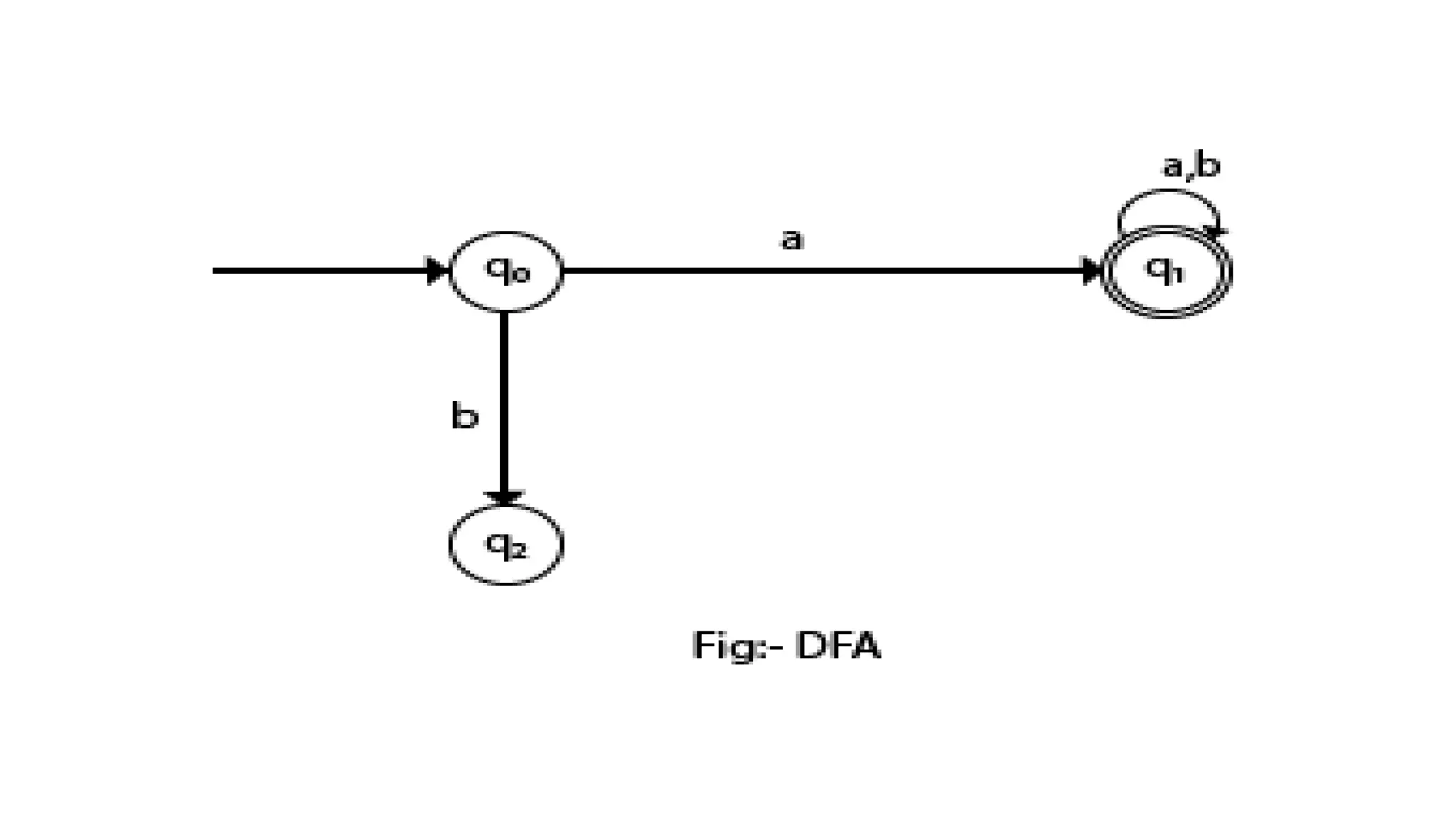
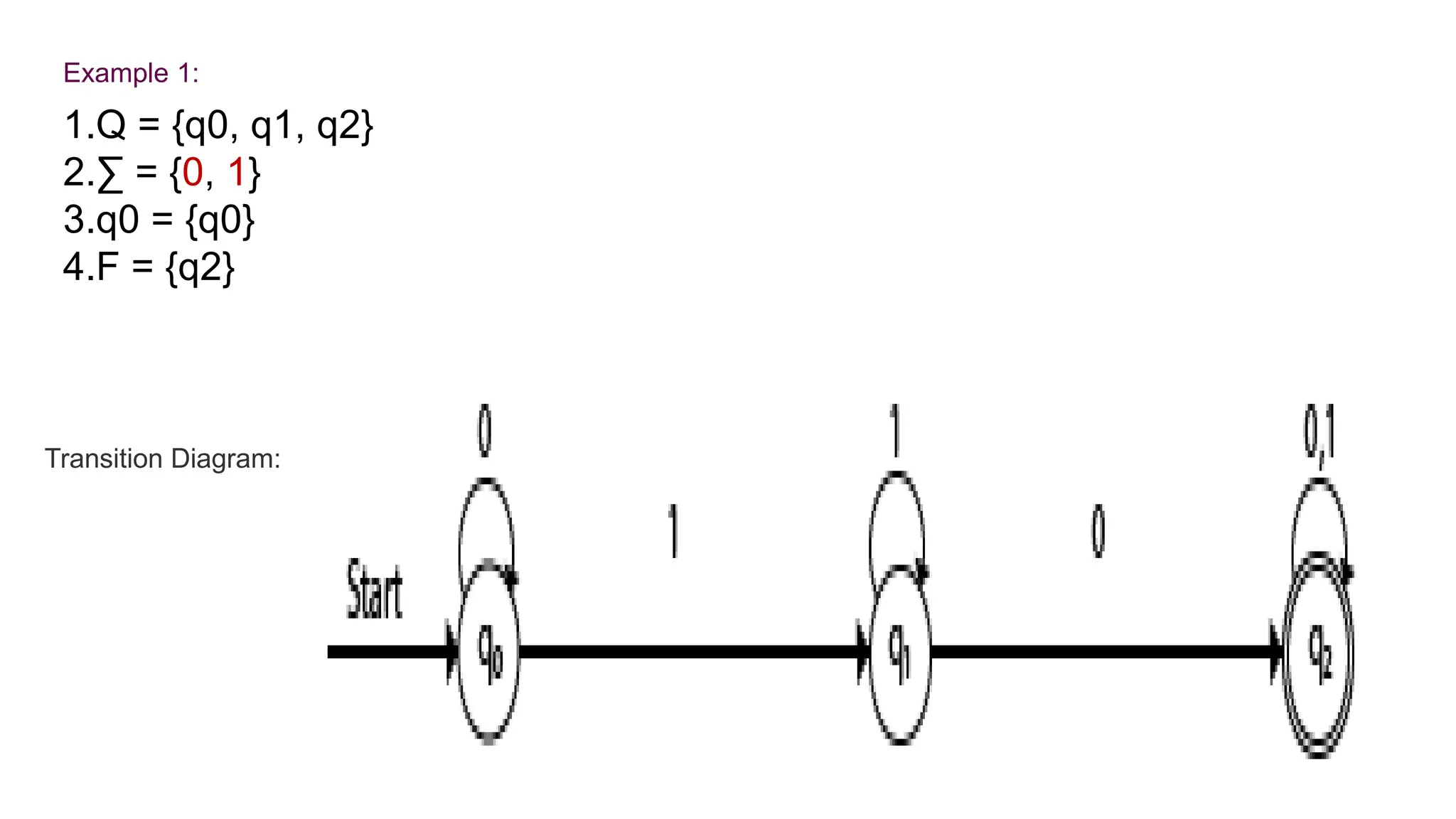
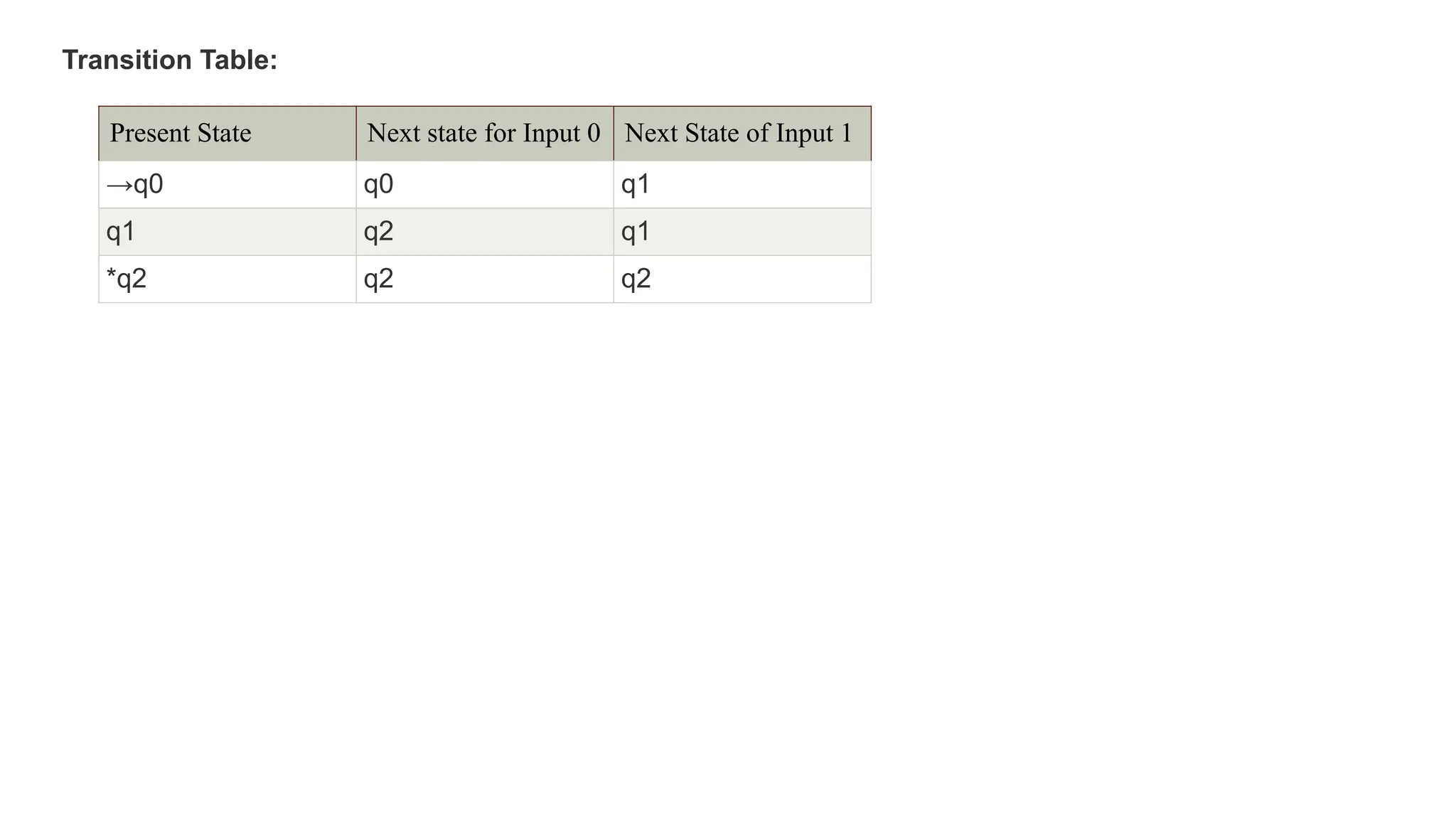
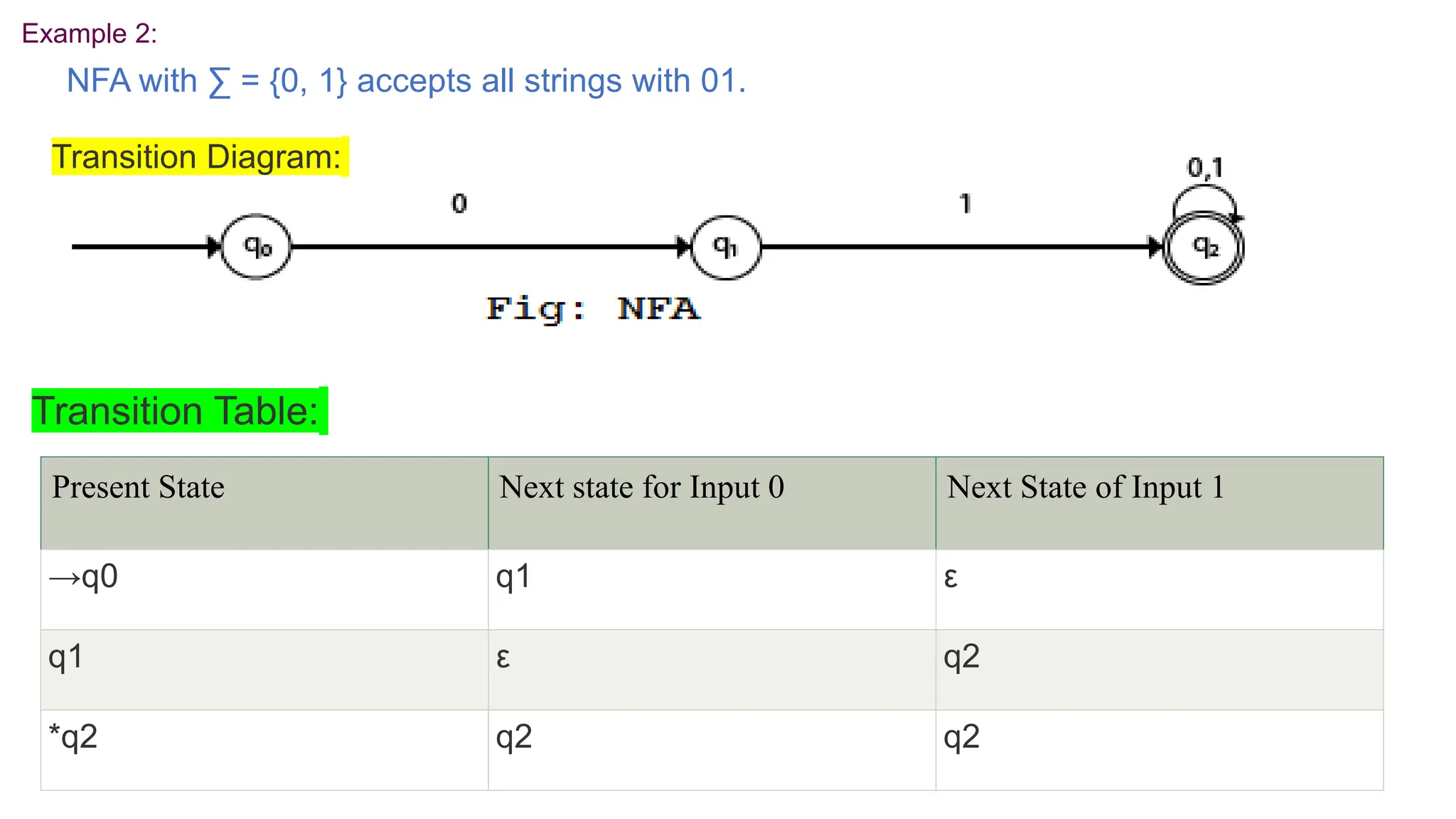
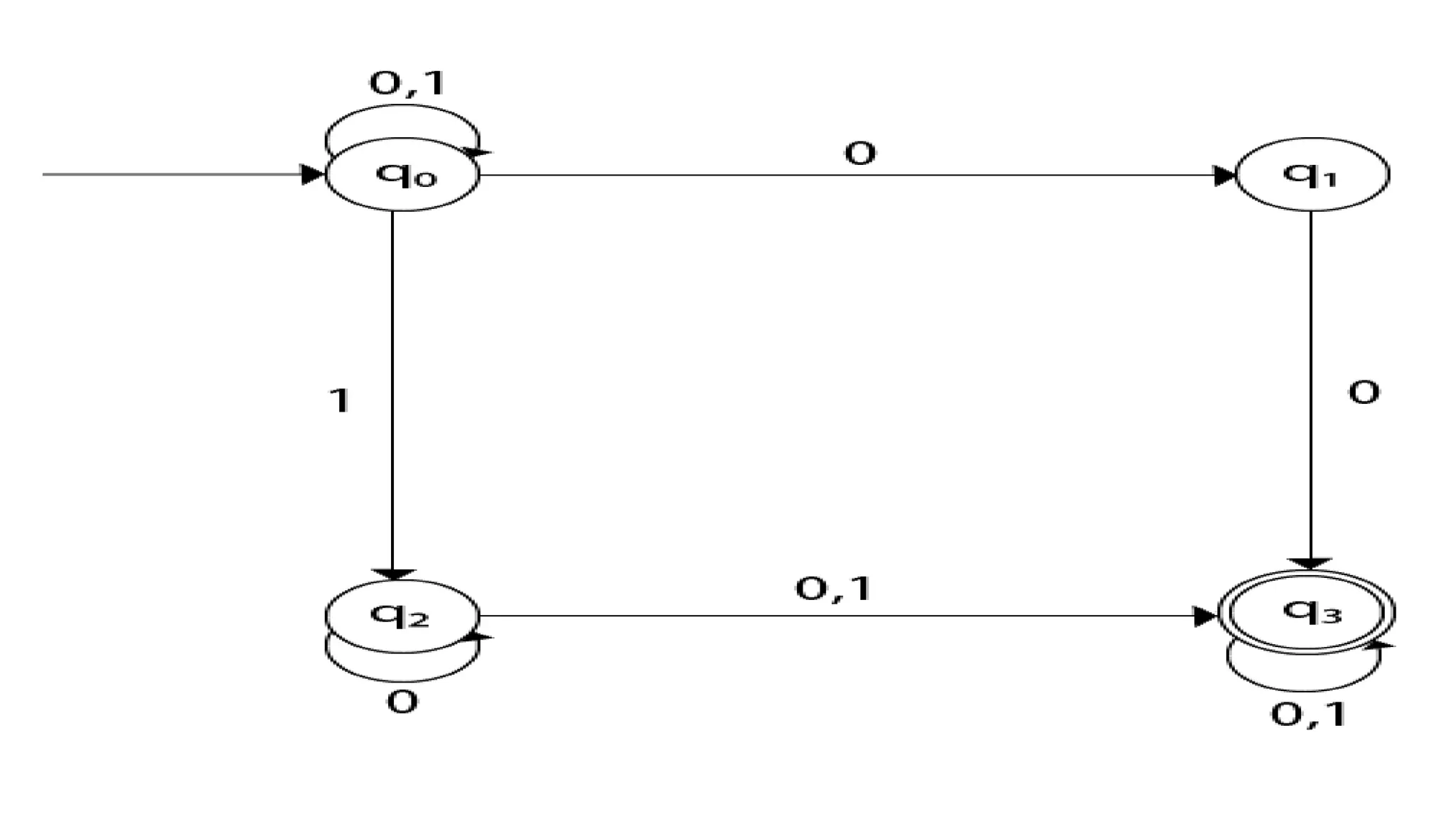
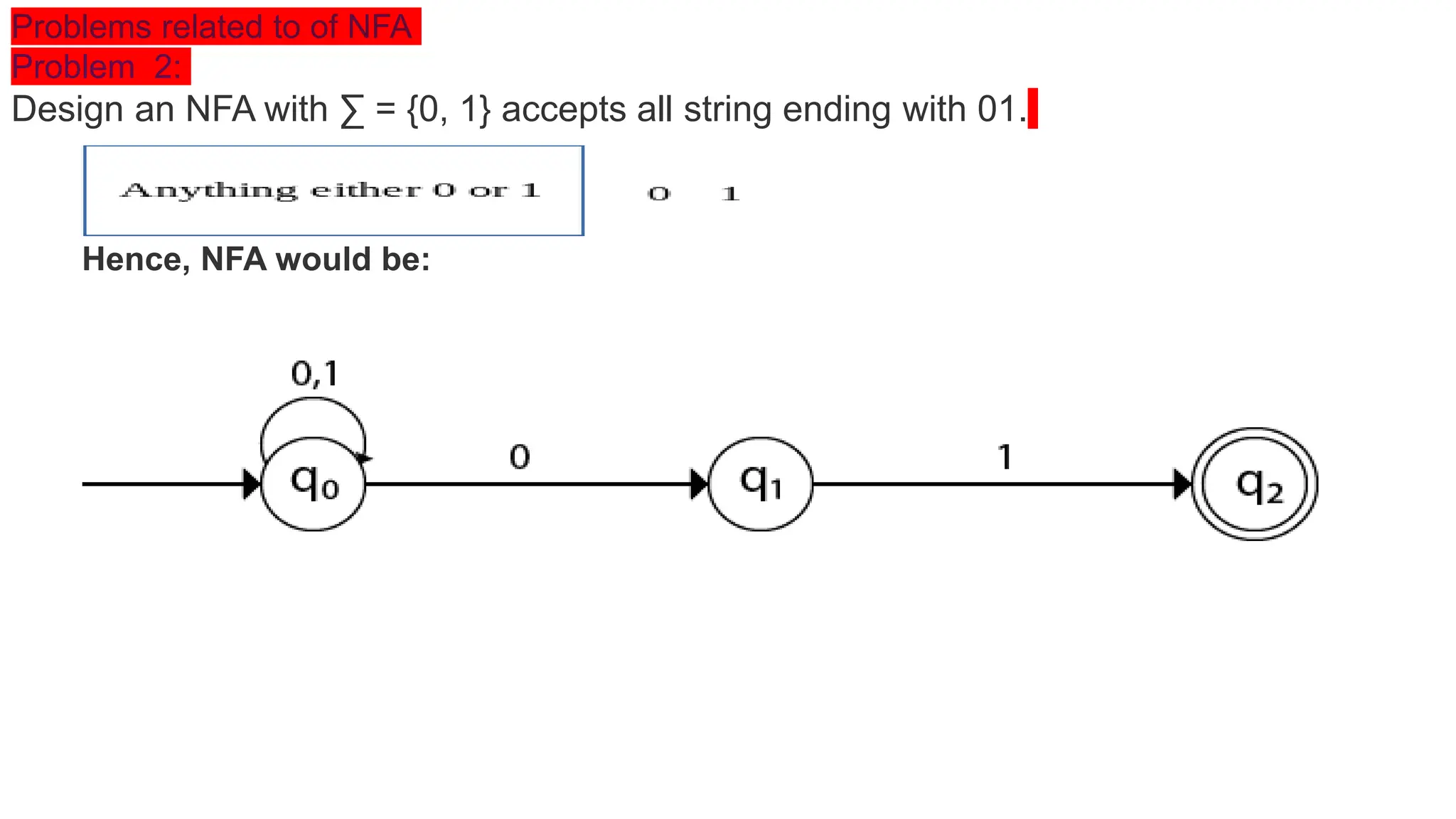
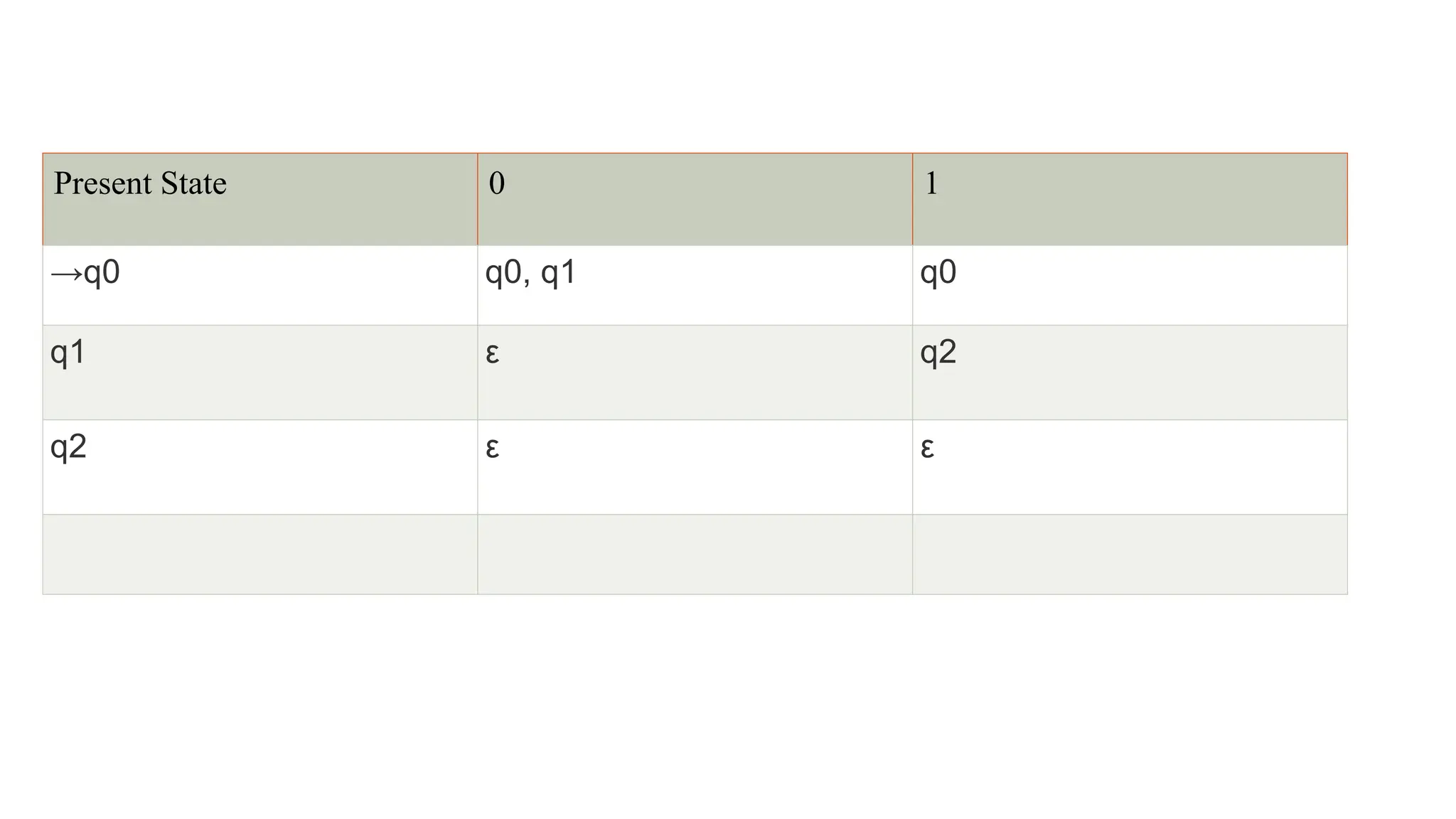
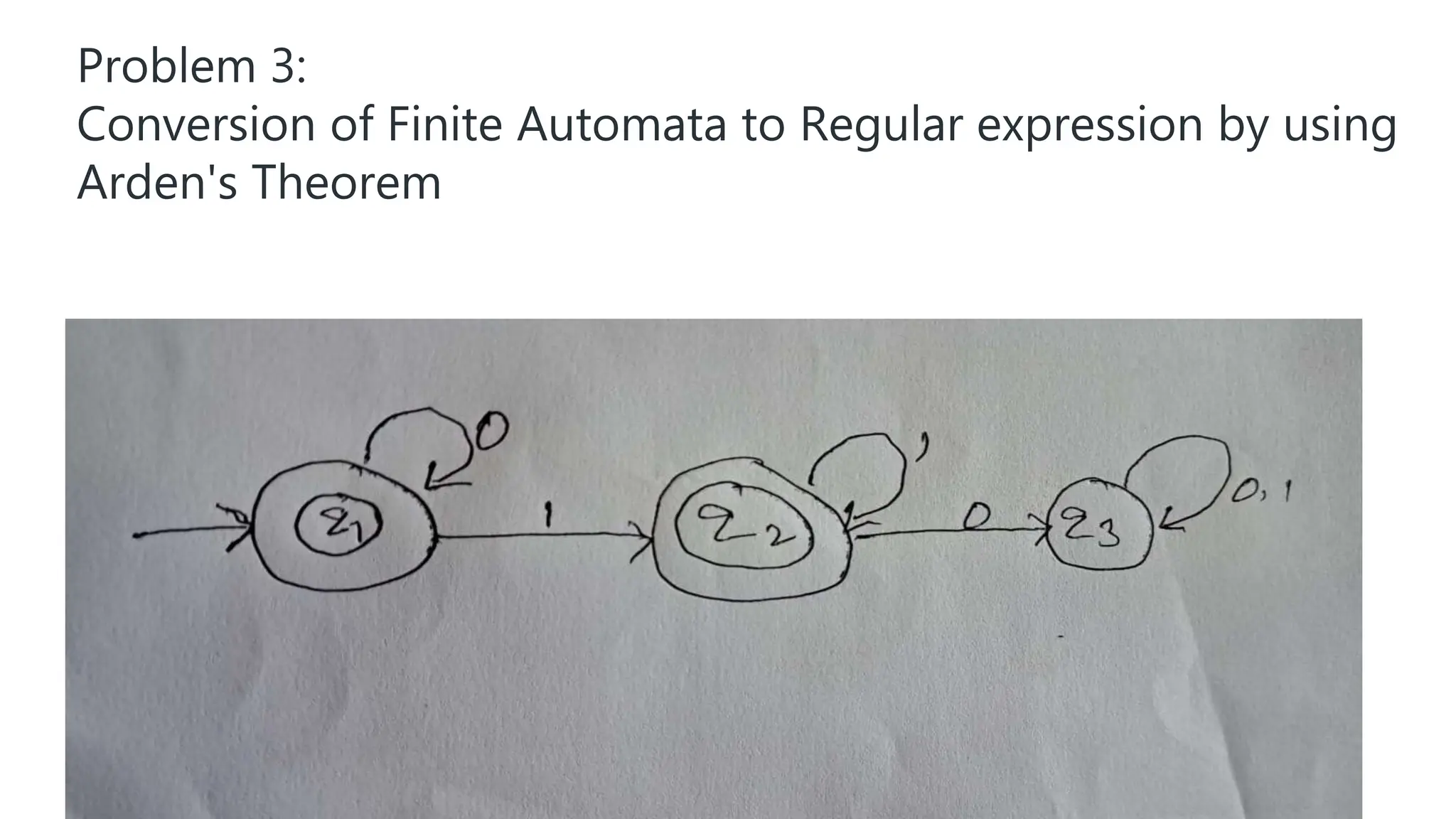
The document elaborates on the classification and the characteristics of finite automata, including deterministic finite automata (DFA), non-deterministic finite automata (NFA), and their applications in various fields like compiler construction, text processing, and digital circuit modeling. It describes the differences between Moore and Mealy machines, detailing how their outputs depend on states and inputs. Additionally, it discusses the minimization of DFA through equivalence methods and provides examples of transition diagrams and tables for both DFA and NFA.









































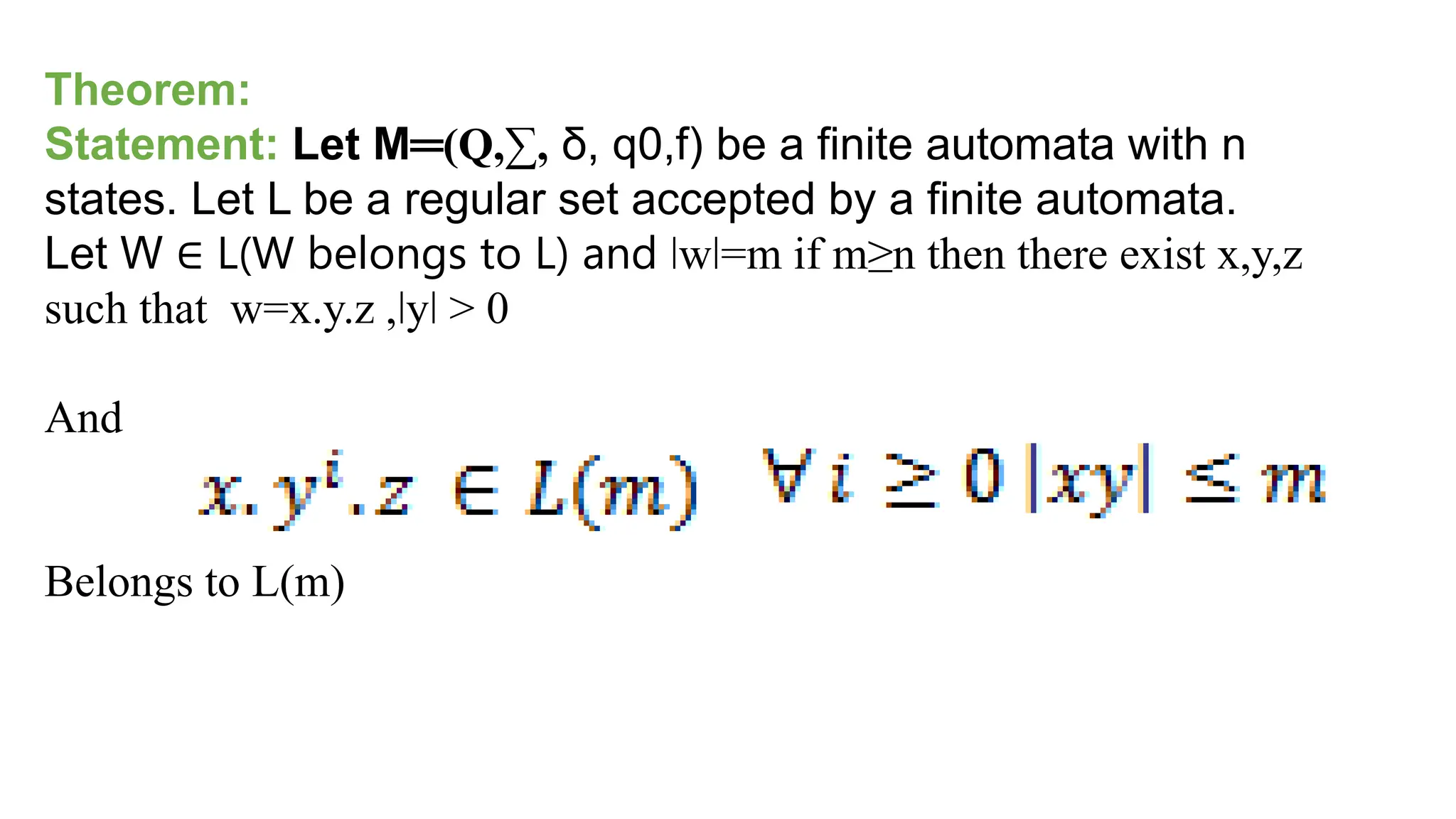

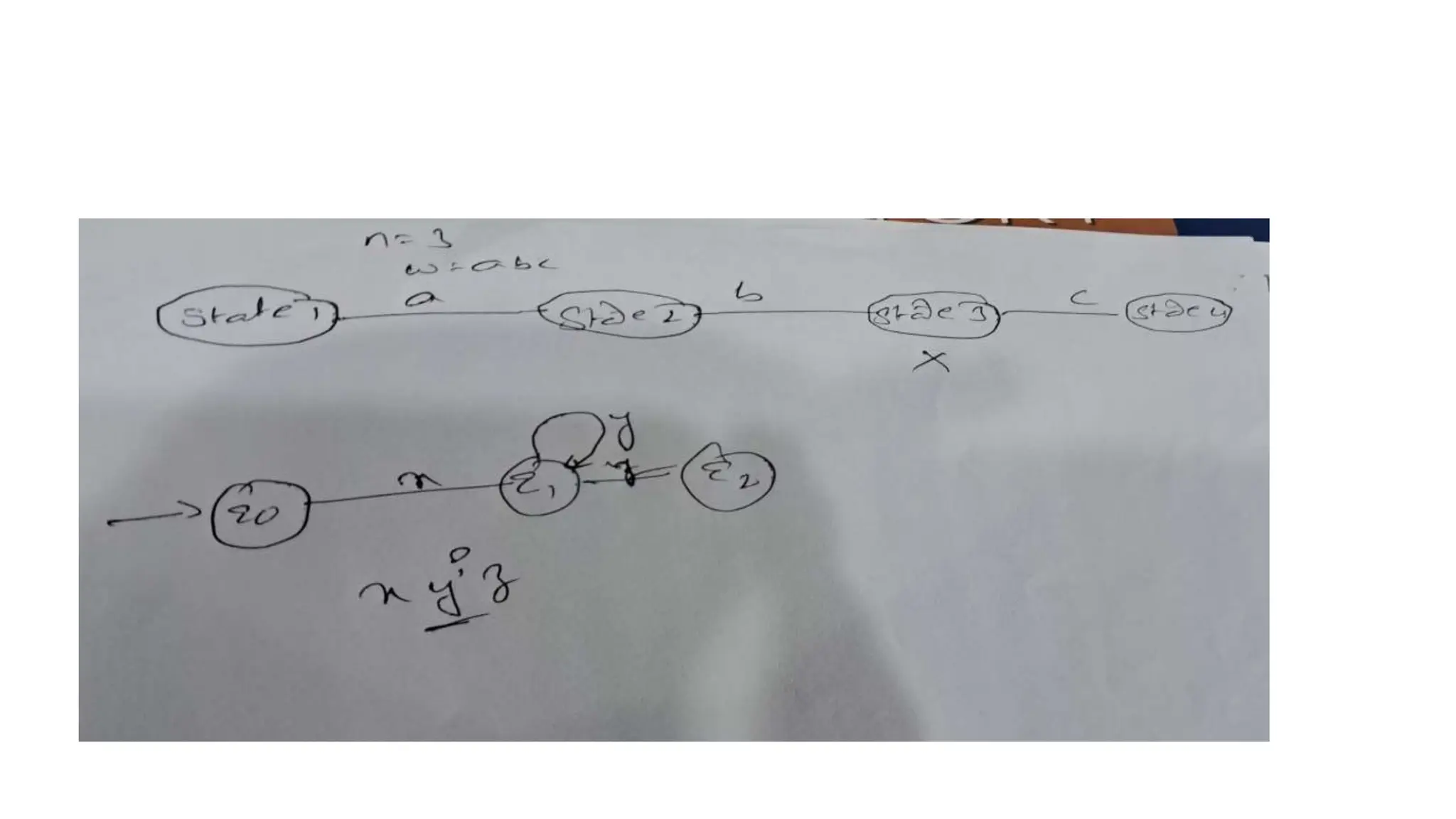





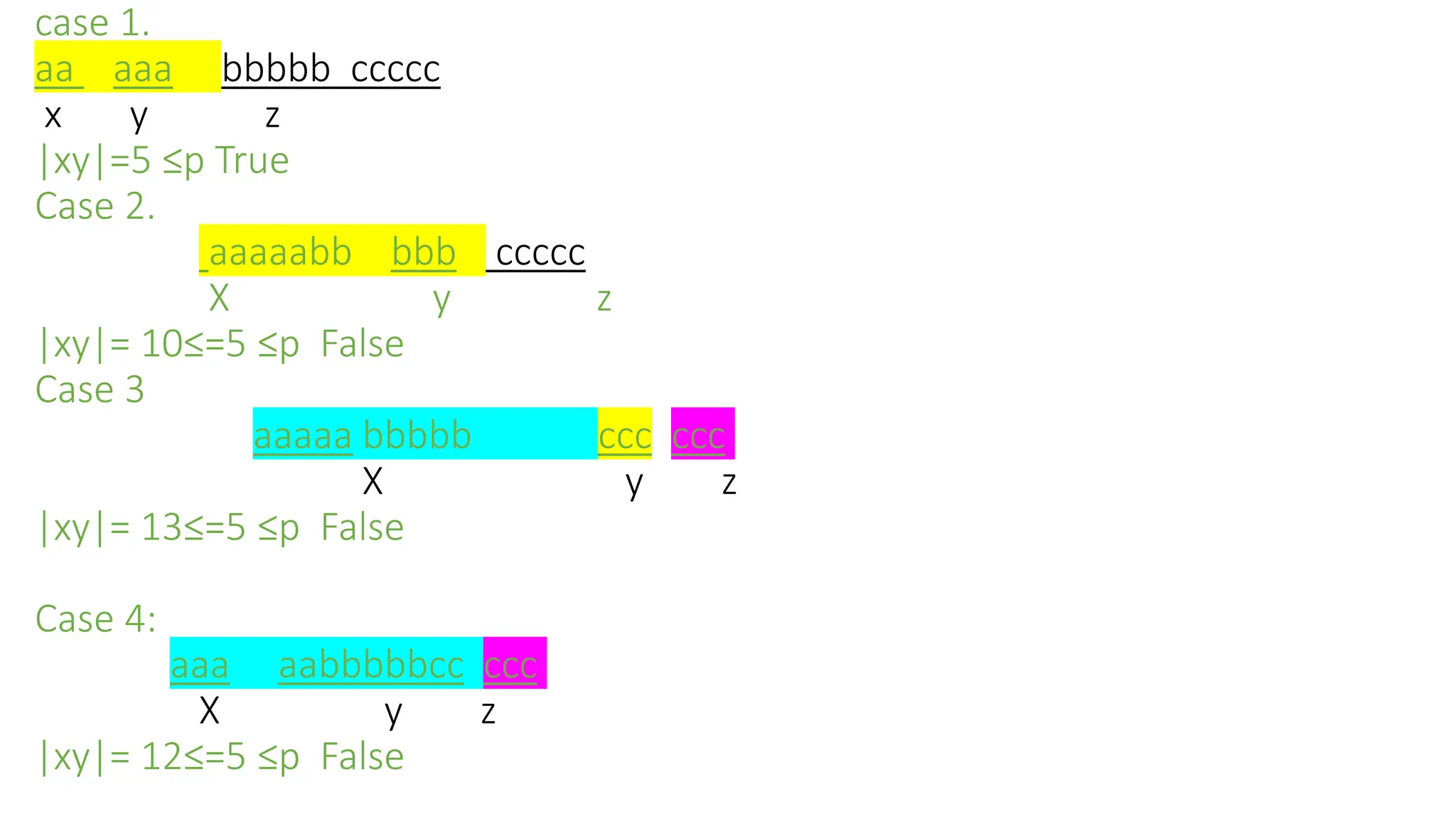
![Let n=5
String s= xyz [since here IwI=m string size]
P= 𝑎𝑛
𝑏𝑛
𝑐𝑛
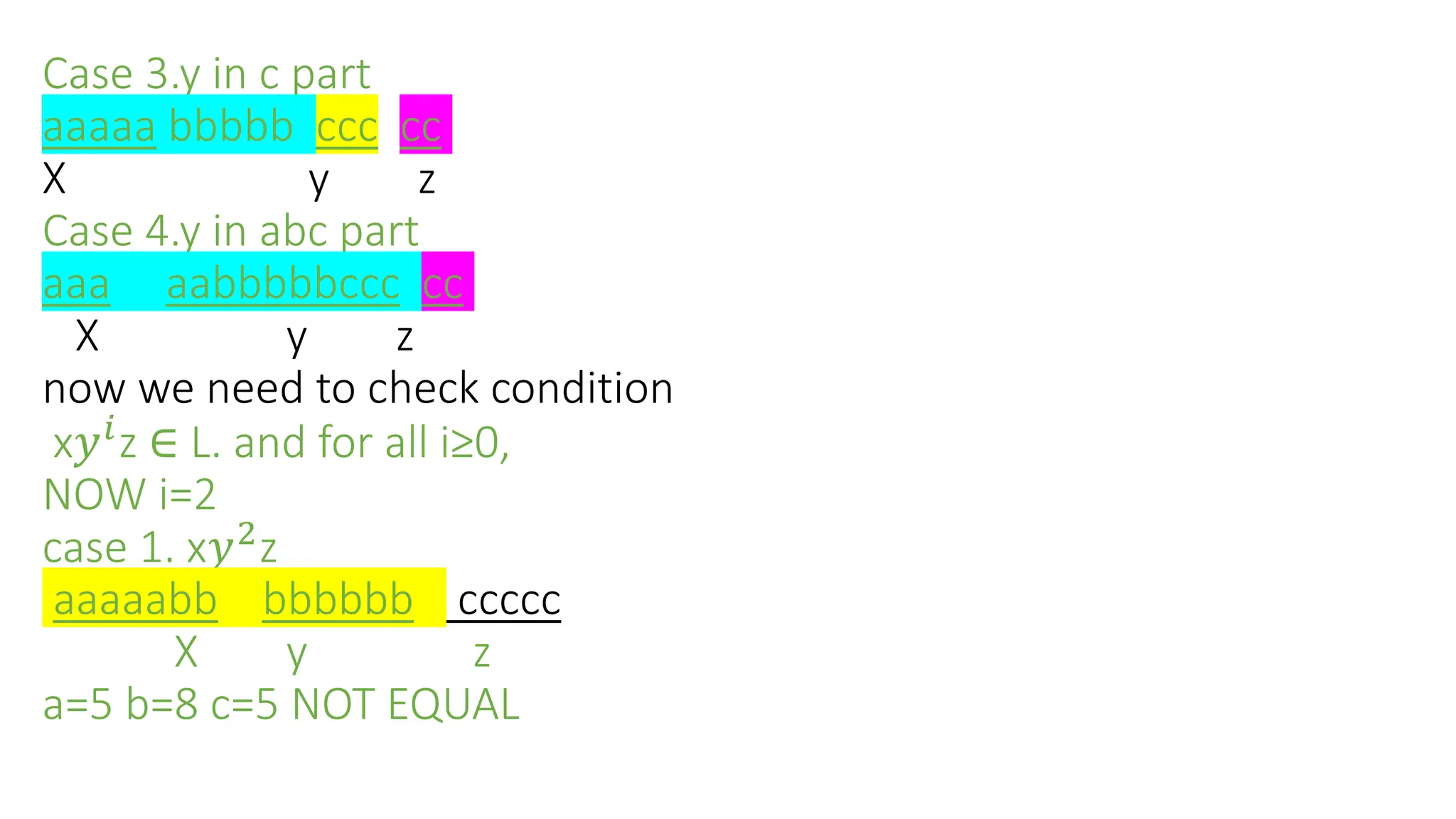
P=aaaaa bbbbb ccccc since m=5
Case i. Given string convert/spilt into xyz
xy z
That is x𝑦𝑖
z The y in ‘a’ part
aa aaa bbbbb ccccc
x y z
Case 2.y in b part
aaaaa bb bbb ccccc
x y z](https://image.slidesharecdn.com/flatclassnotes-240613074332-9f475ef3/75/Formal-language-and-automata-theoryLAT-Class-notes-pptx-71-2048.jpg)







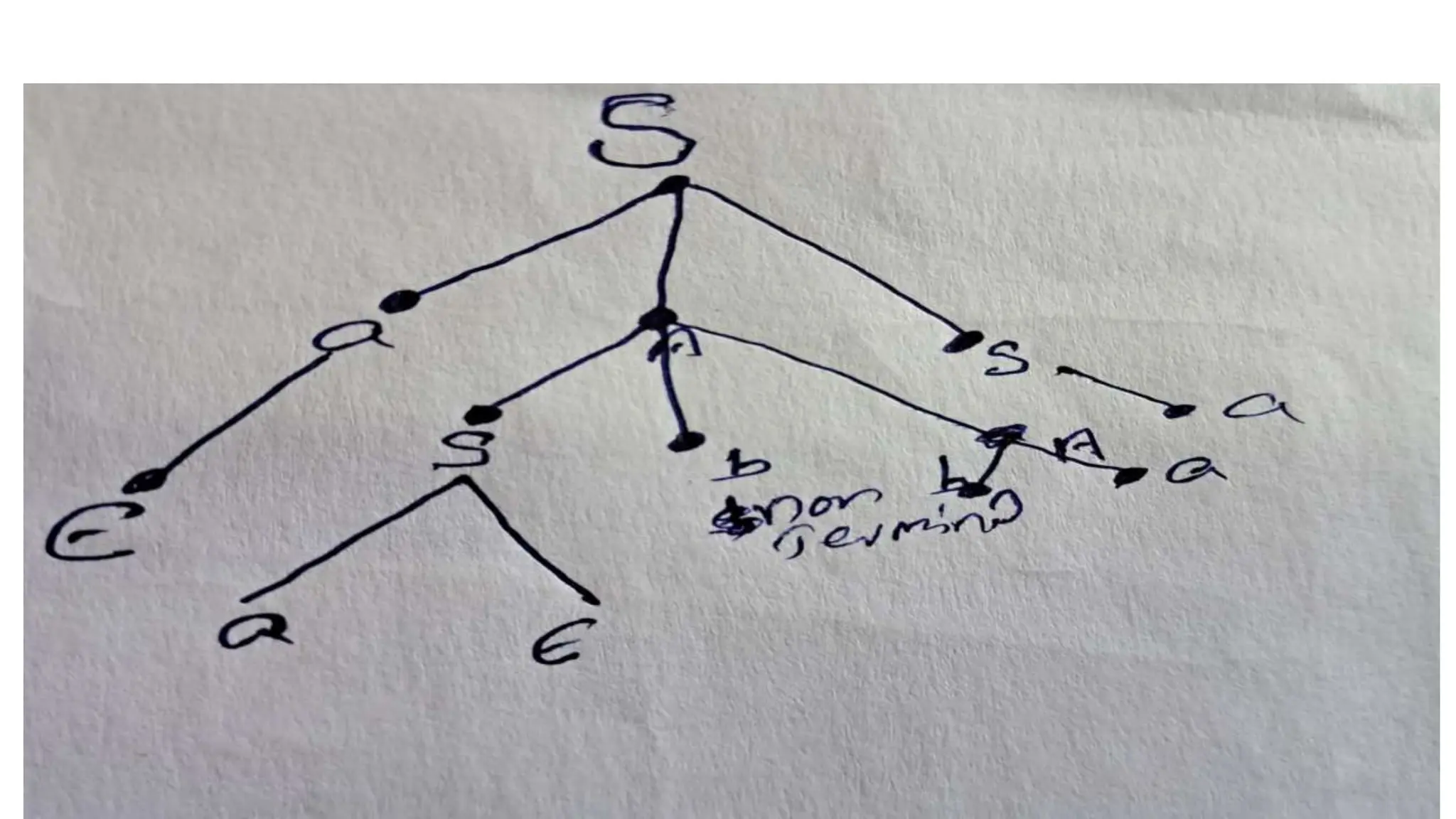


![Example: Construct CFG with accept the strings having at least 2 a’s
over the ={a,b}
Sol :Given data is that
We have to construct the grammar as per the above condition
Let us consider the regular expression= (a + b)* a(a + b)* a
(a + b)* [since at least 2 a’s ]
Let us consider the production rule S T a T a T
T aT/bT/
To construct the grammar
Let us consider S T a T a T
Replace the T values with aT or bT or ](https://image.slidesharecdn.com/flatclassnotes-240613074332-9f475ef3/75/Formal-language-and-automata-theoryLAT-Class-notes-pptx-85-2048.jpg)