Download to read offline














![+
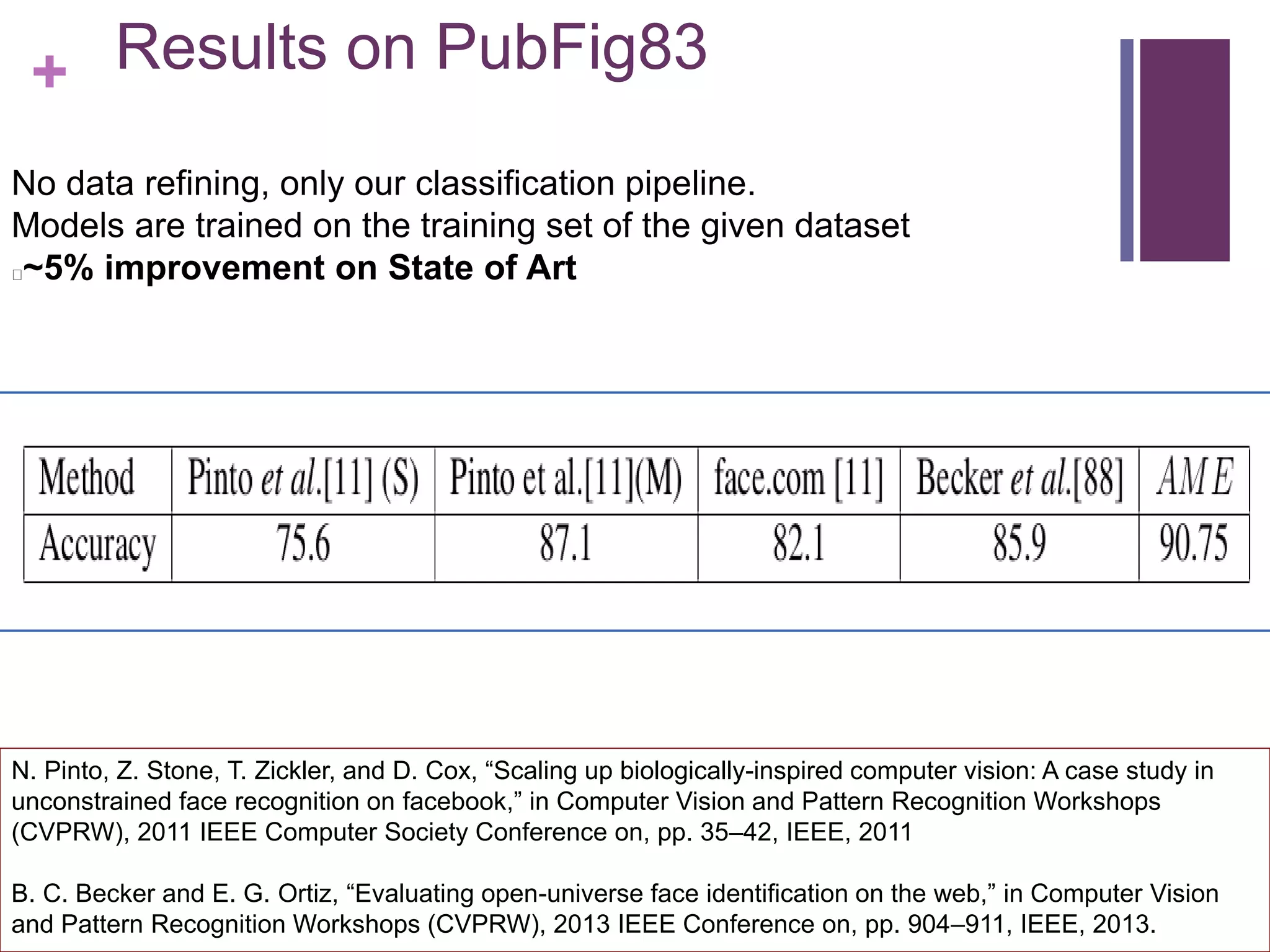
Implementation details
FAME
Data refining : L1 Logistic Regression with Gauss-Seidel algorithm [1]
Final Classifier: L1 Linear SVM with Grafting[2].
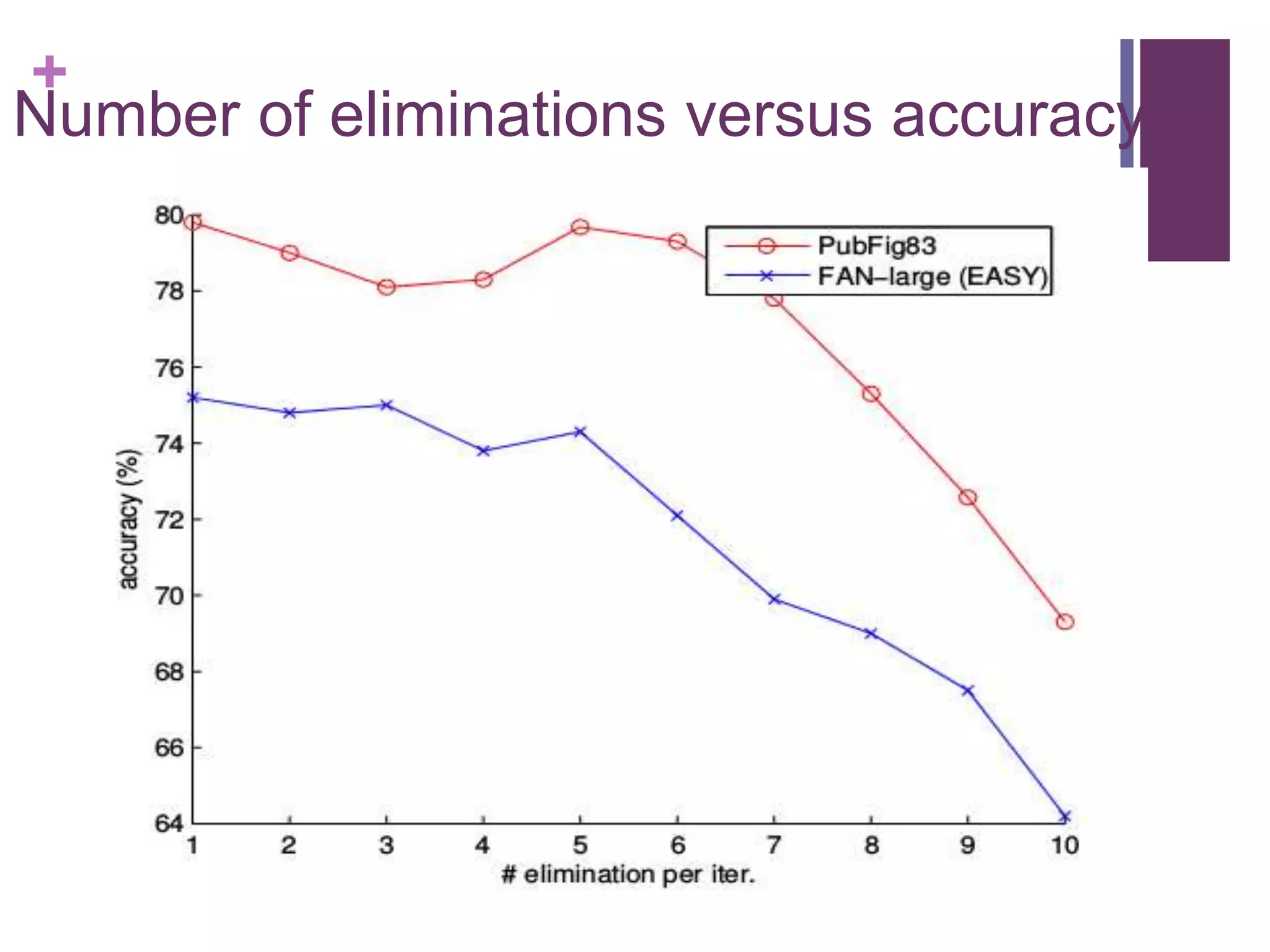
At each iteration 5 images are eliminated.
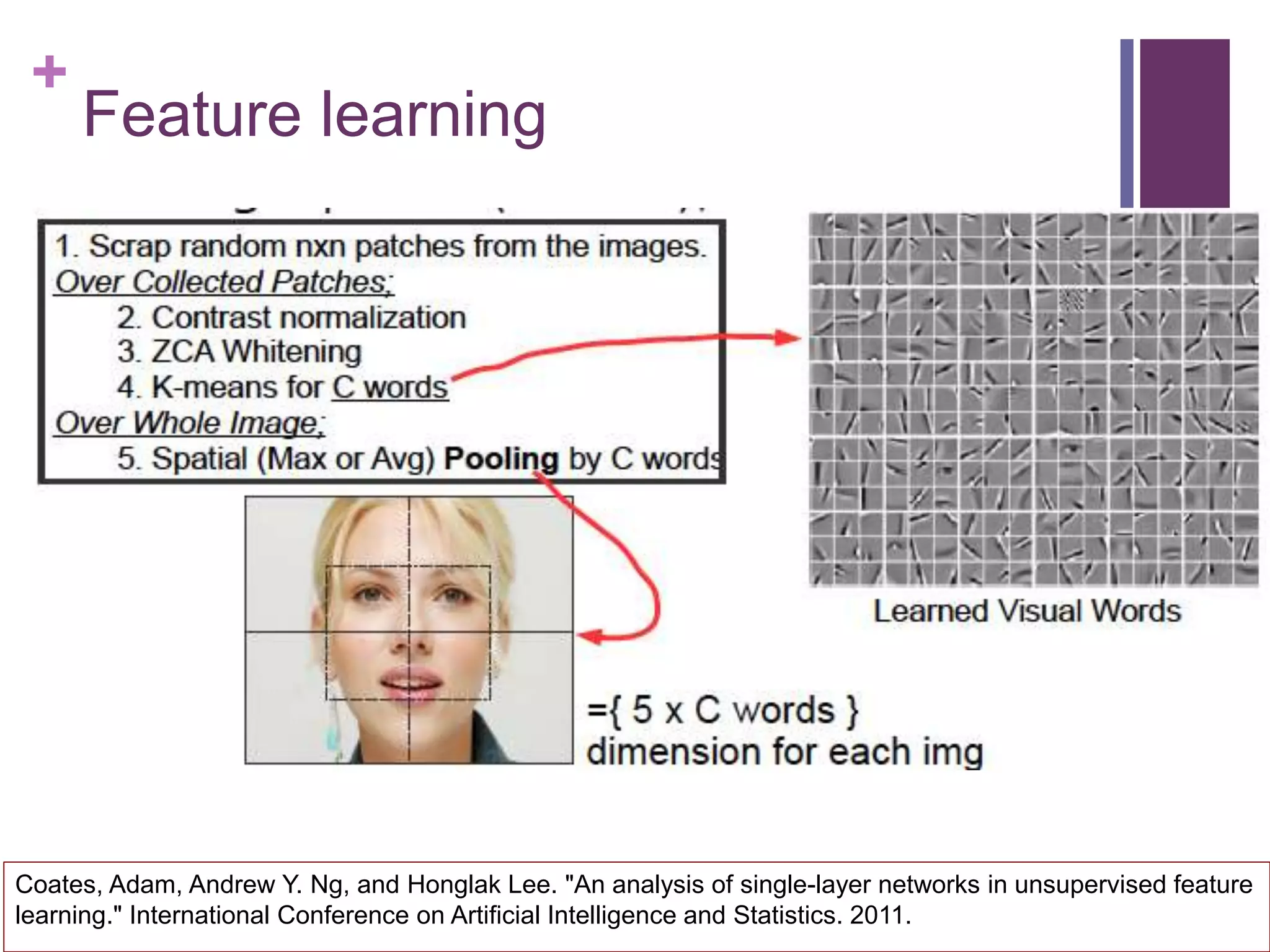
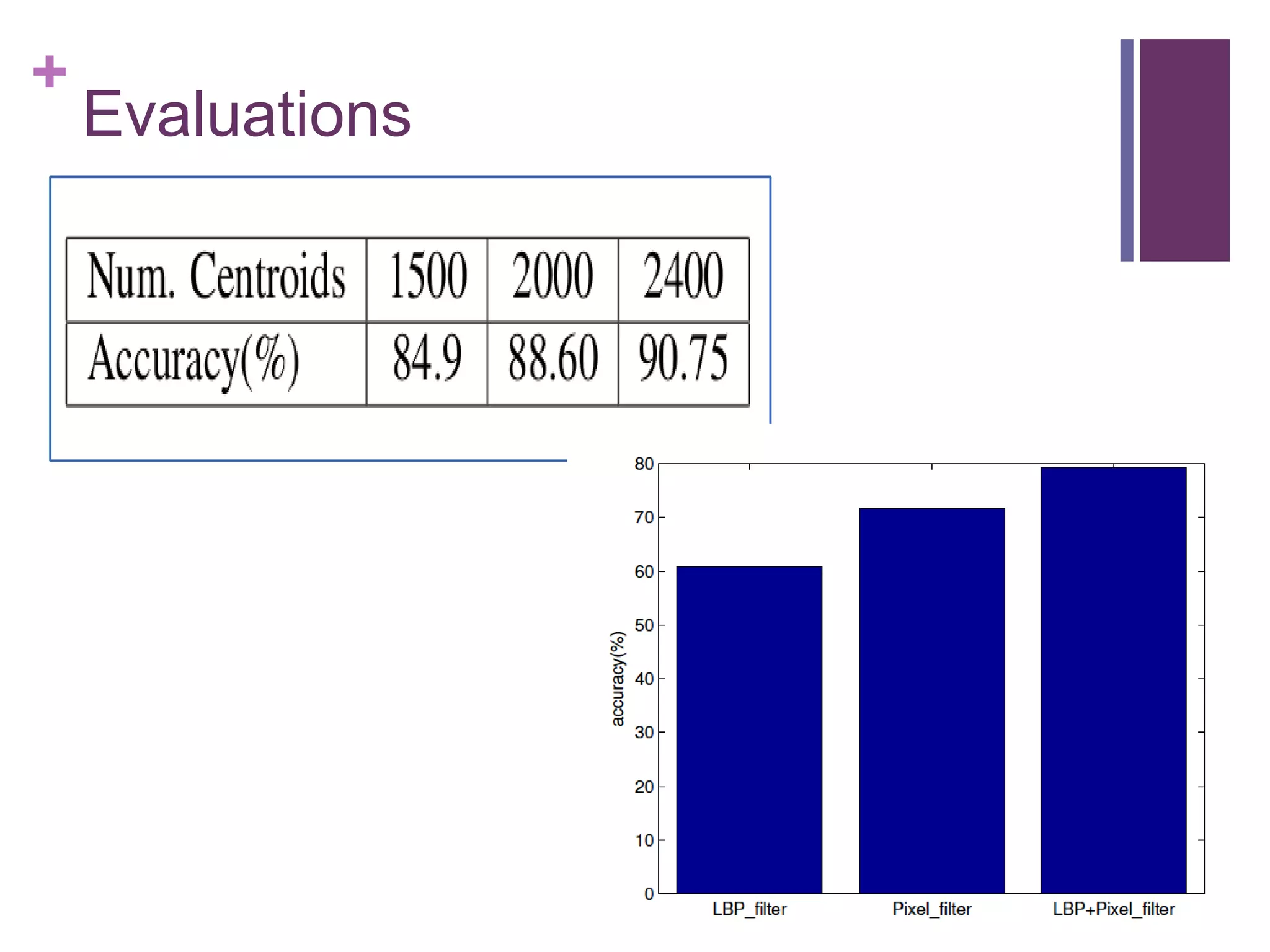
Feature Learning
Augment train data with horizontally flipped images.
Re-size each gray-level image 60px height.
Contrast Normalization to random patches.
ZCA whitening with Ɛ=0.5.
Receptive field (patch) size 6x6 pixels
1 pixel stride with k=2400 words.
Final feature vector has 5x2400 dimensions.
[1] Shirish Krishnaj Shevade and S Sathiya Keerthi. A simple and efficient algorithm for gene selection using sparse logistic
regression. Bioinformatics,19(17):2246–2253, 2003.
[2] Simon Perkins, Kevin Lacker, and JFAMEs Theiler. Grafting: Fast, incremental feature selection by gradient descent in
function space. The Journal of Machine Learning Research, 3:1333–1356, 2003.](https://image.slidesharecdn.com/famecvpr-150612223214-lva1-app6892/75/Fame-cvpr-23-2048.jpg)





![+
Use annotated control set as a start point.
Fergus et. al. [1], OPTIMOL, Li and Fei-Fei [2]
We use fully autonomous framework.
Use Textual Captions
Berg and Forsyth [3]
We use only visual content
Discriminative image cues
Efros et al. [4] “Discriminative Patches”, Q. Li et al.[5]
We use single computer with faster and better results.
[1] Fergus, R., Fei-Fei, L., Perona, P., Zisserman, A.: Learning object categories from google’s image
search. In: Computer Vision, 2005. ICCV 2005
[2] Berg, T.L., Berg, A.C., Edwards, J., Maire, M., White, R., Teh, Y.W., Learned-Miller, E.G., Forsyth,
D.A.: NFAMEs and faces in the news. In: IEEE Conference on Computer Vision
Pattern Recognition (CVPR). Volume 2. (2004) 848–854
[3] Li, L.J., Fei-Fei, L.: Optimol: automatic online picture collection via incremental model learning.
International journal of computer vision 88(2) (2010) 147–168
[4] Li, Q., Wu, J., & Tu, Z. Harvesting Mid-level Visual Concepts from Large-scale Internet Images.](https://image.slidesharecdn.com/famecvpr-150612223214-lva1-app6892/75/Fame-cvpr-34-2048.jpg)

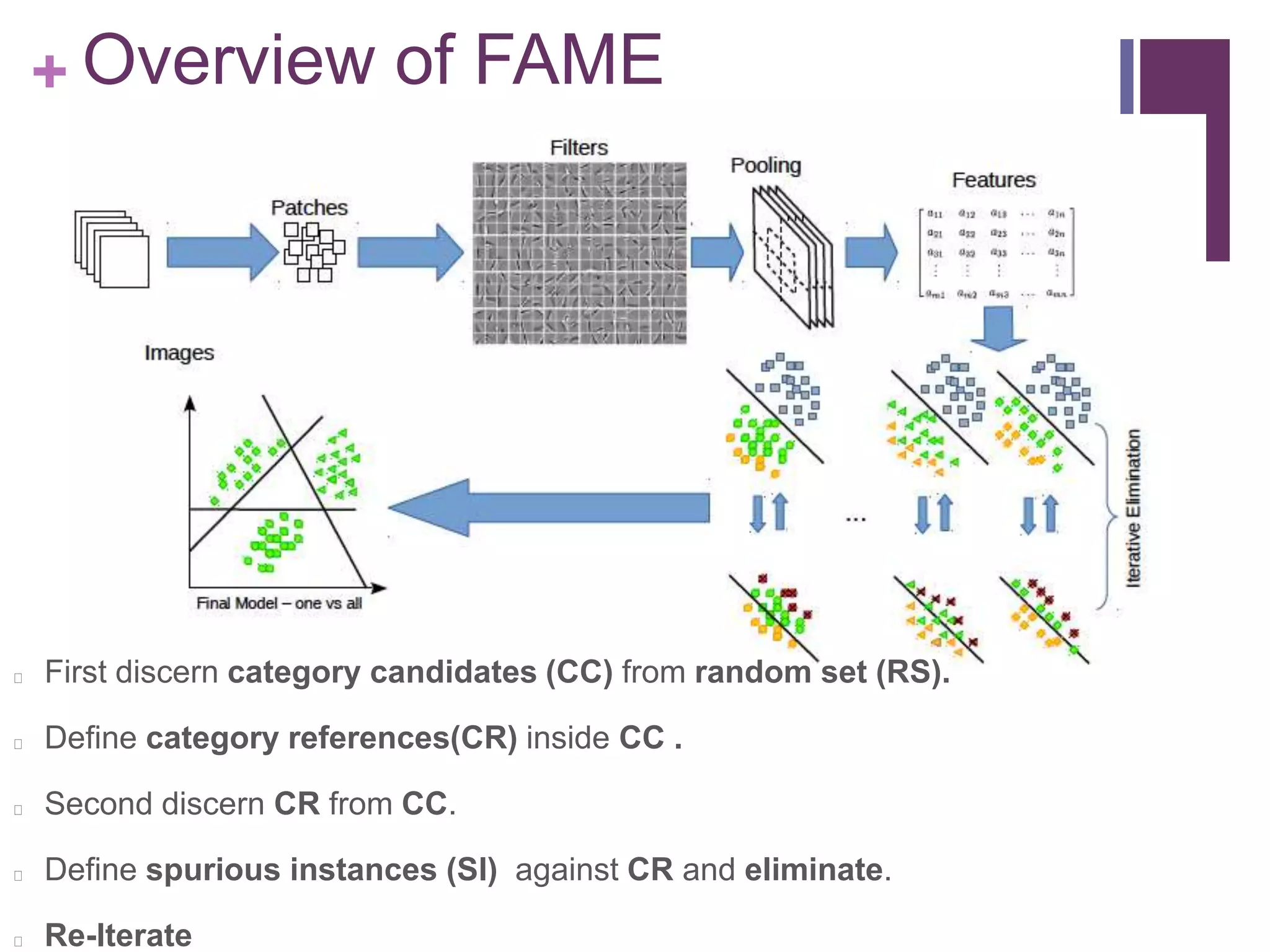
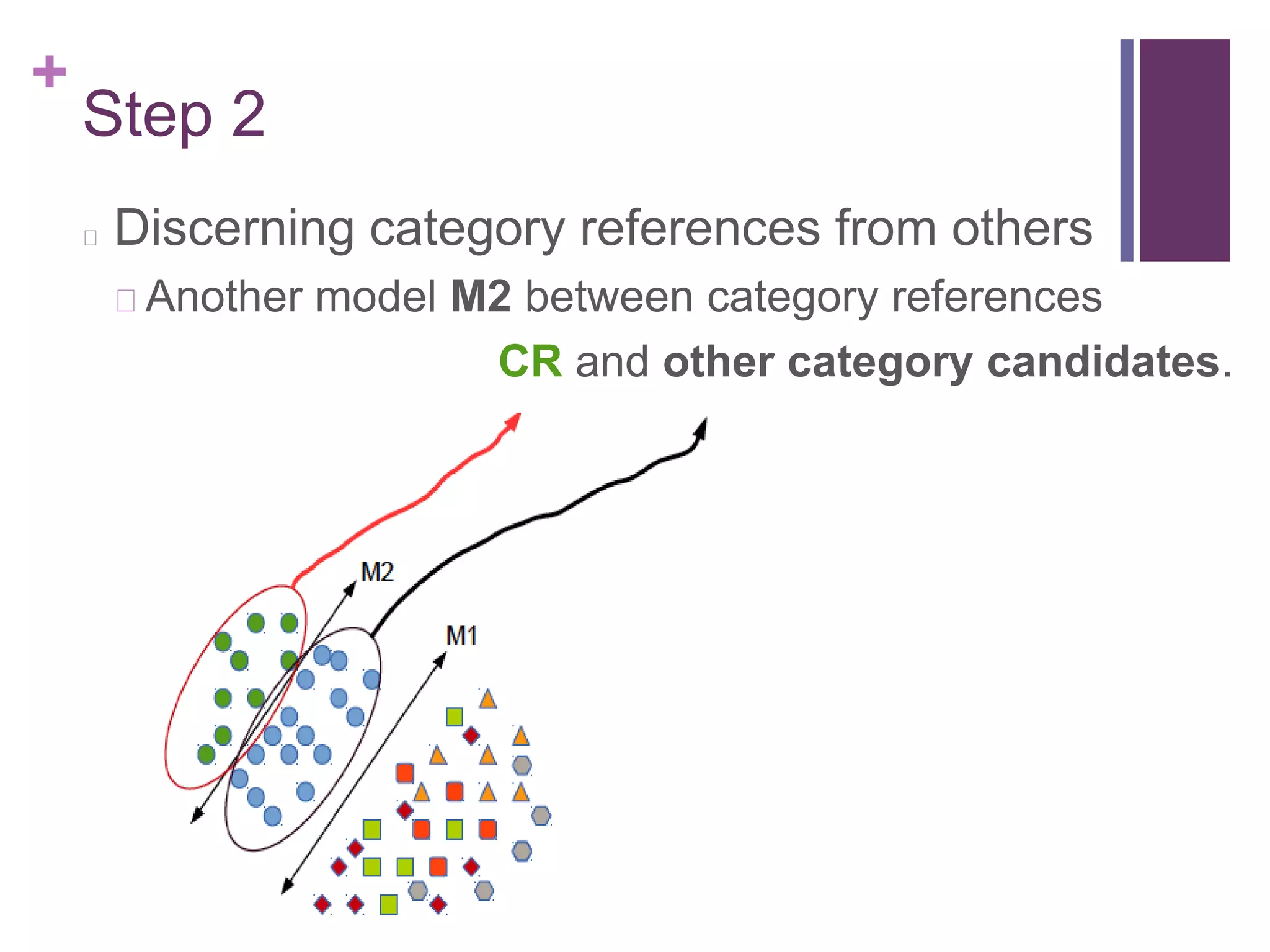
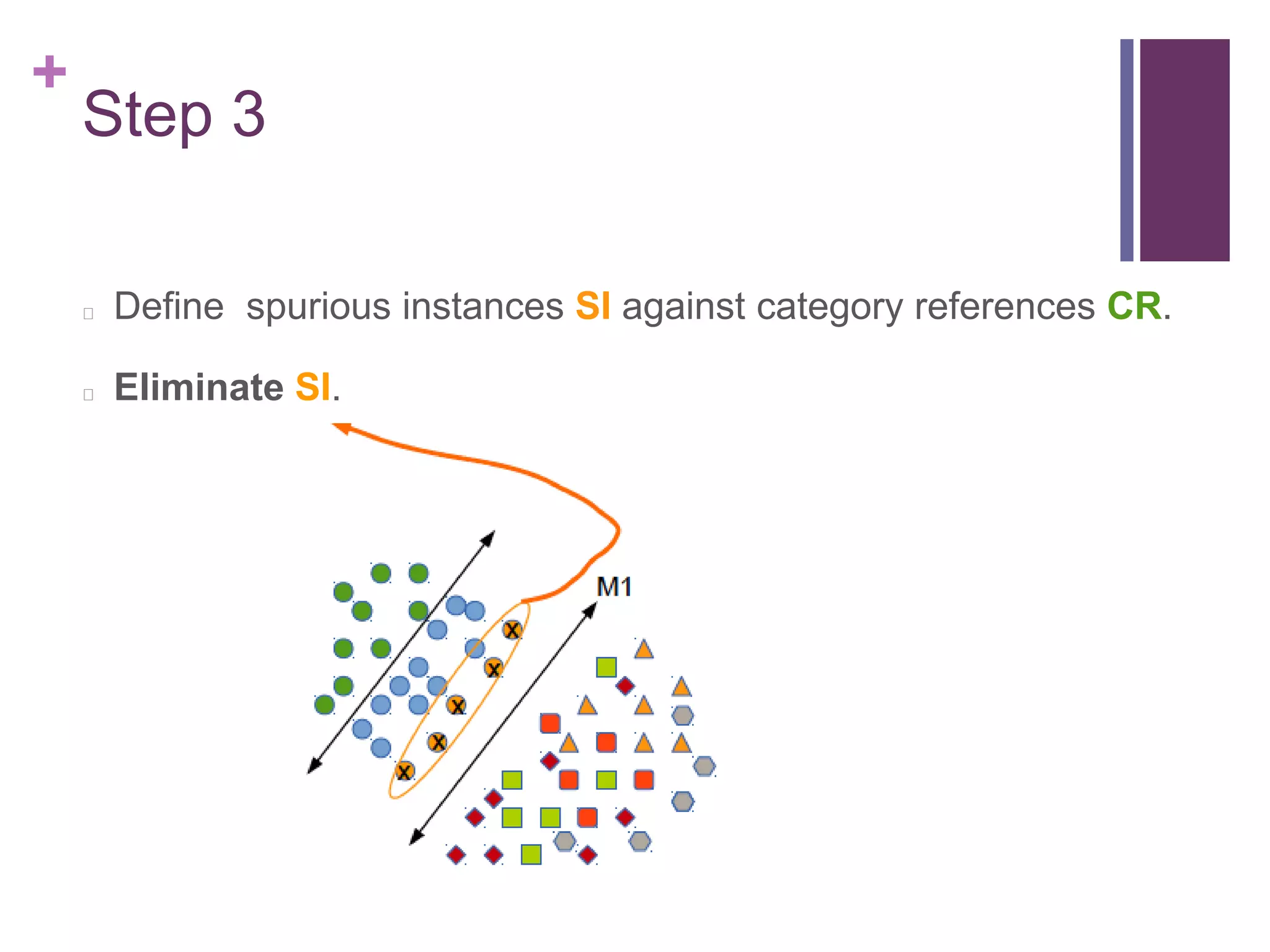
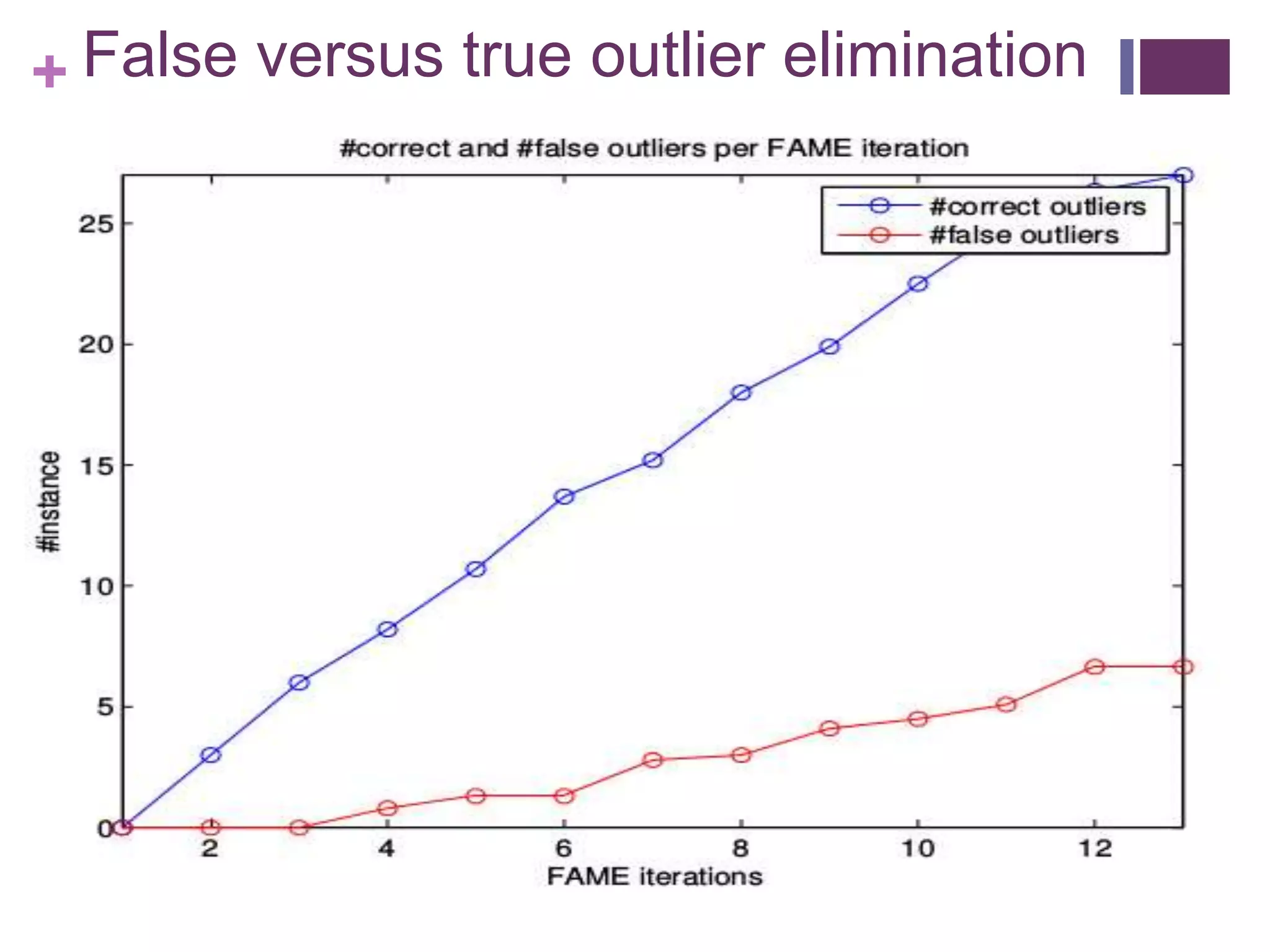
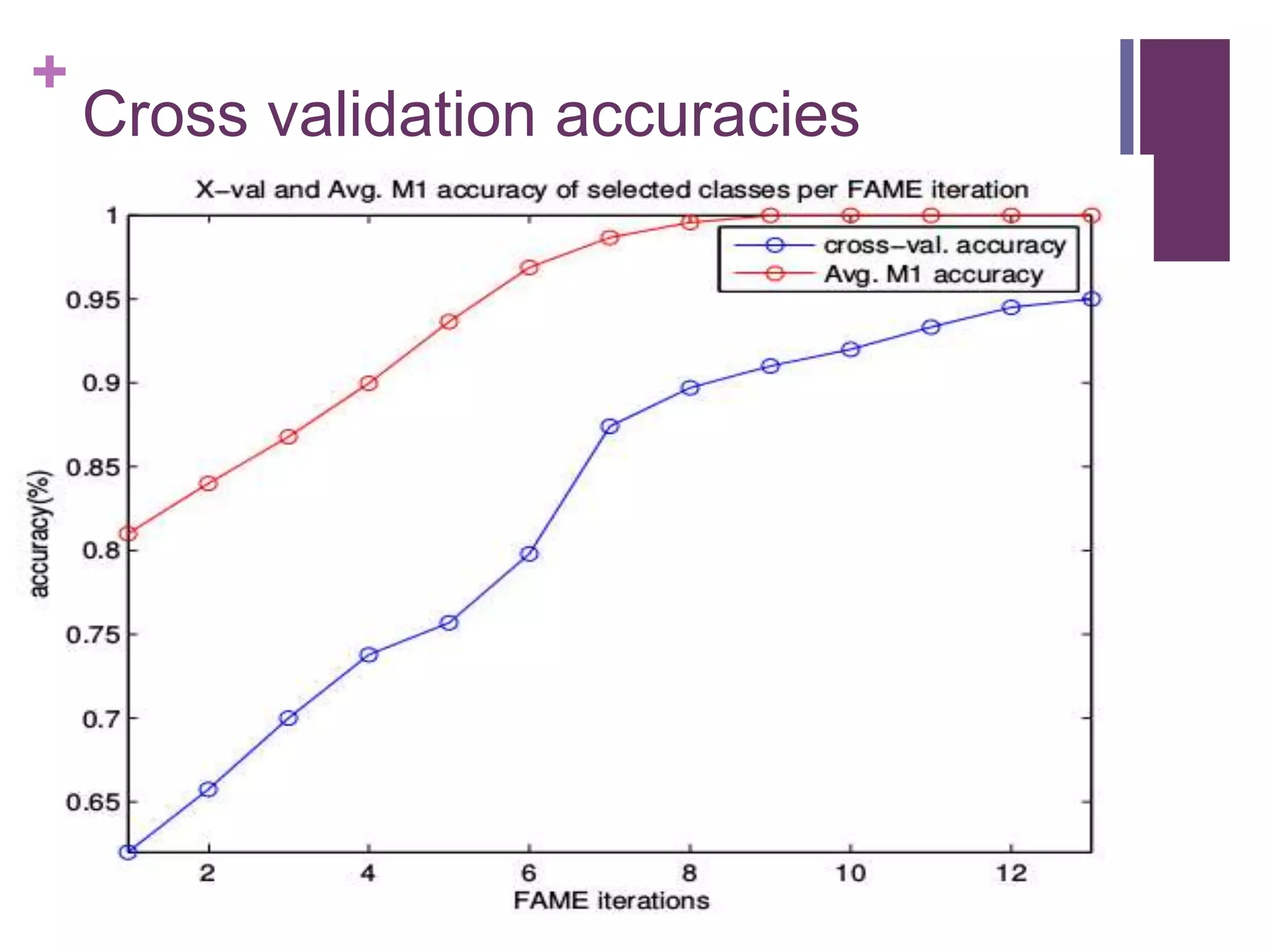
The document describes the FAME (Face Association through Model Evolution) method for improving face recognition using a framework that iteratively prunes outliers from weakly labeled image datasets. It emphasizes high-dimensional feature representation and outlines a series of steps for discerning category candidates and references, eliminating spurious instances to enhance classification accuracy. The work incorporates various datasets and achieves improvements over state-of-the-art methods in face recognition tasks.





















































































