Download as PDF, PPTX





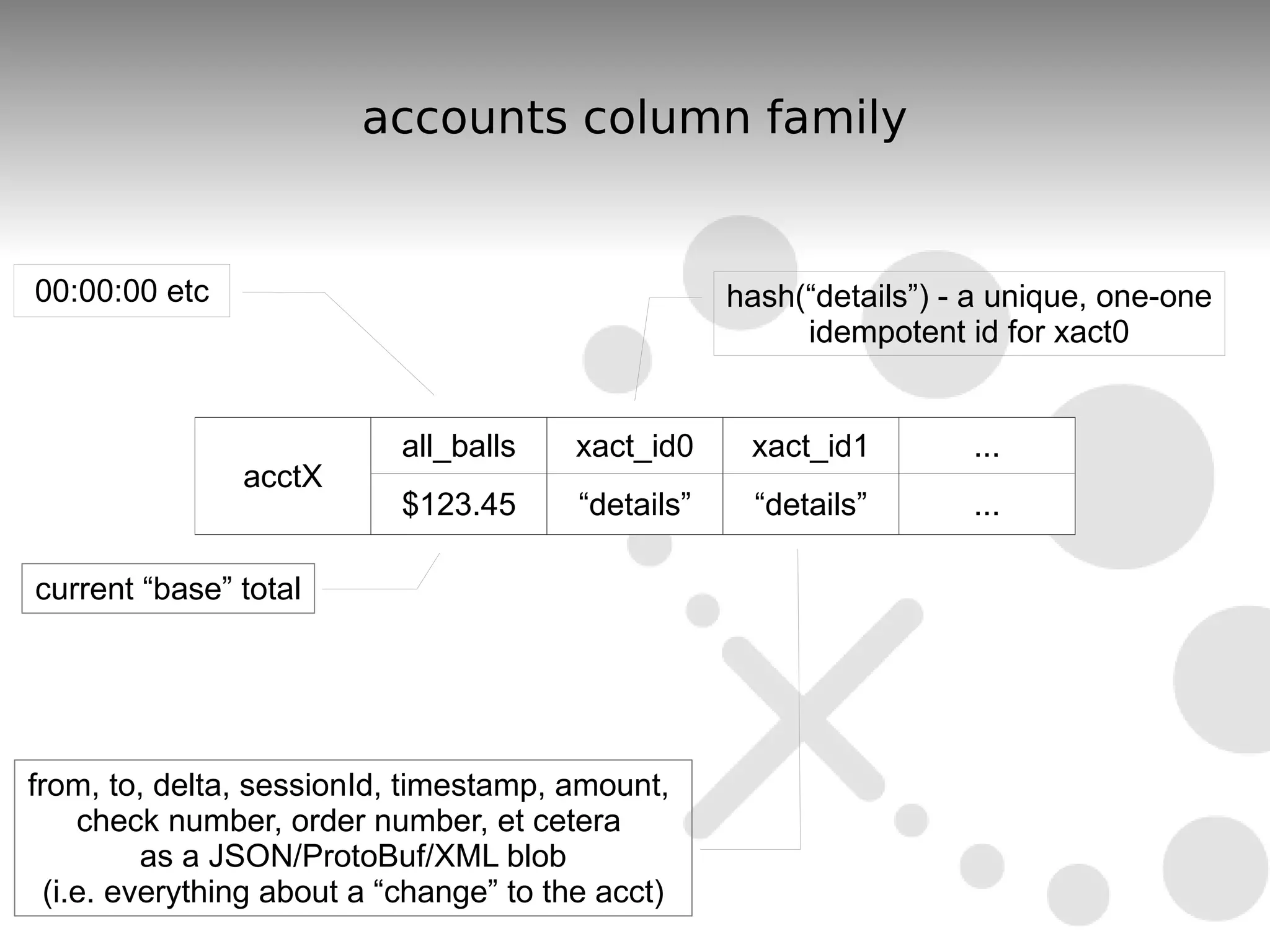





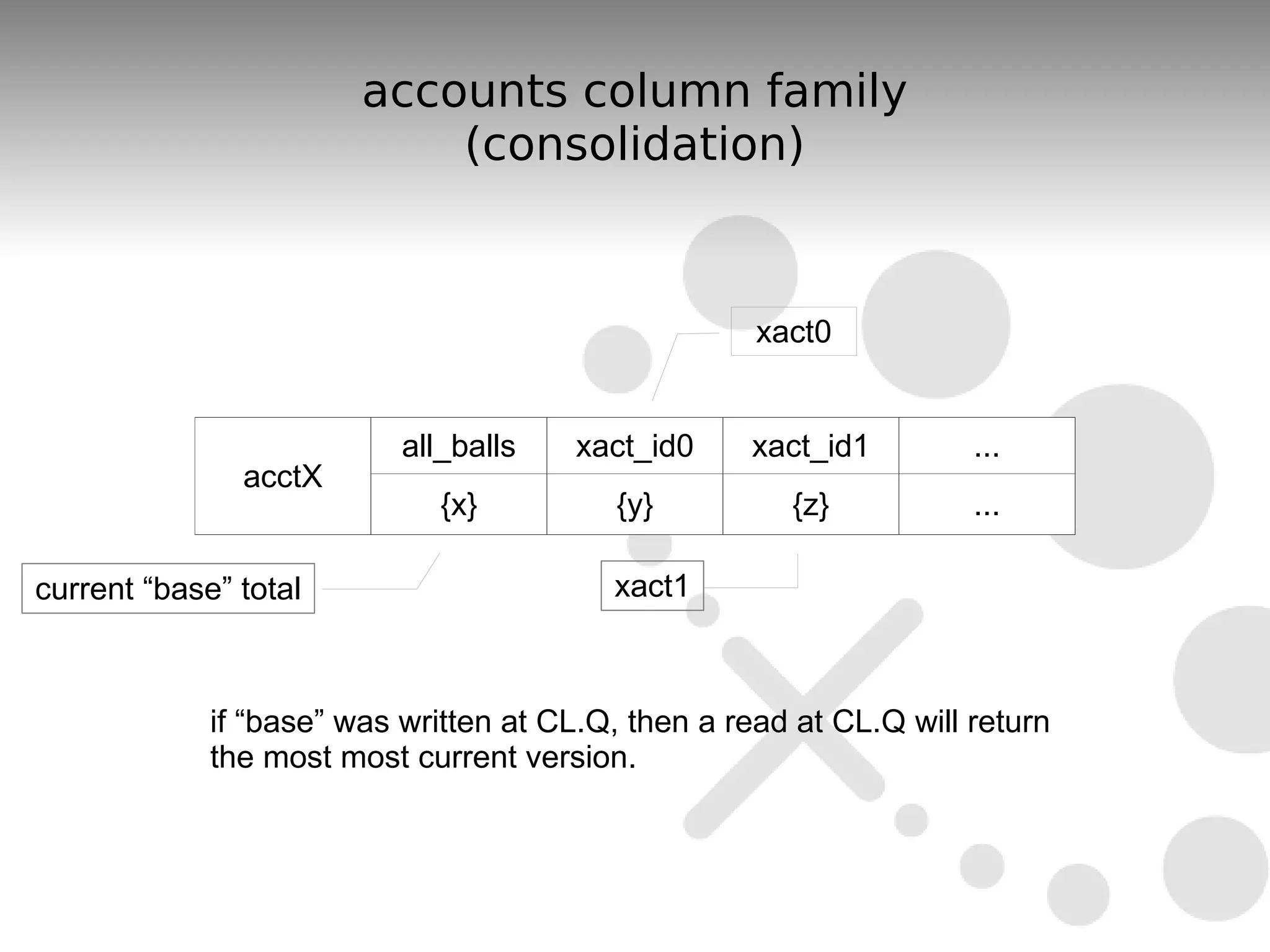
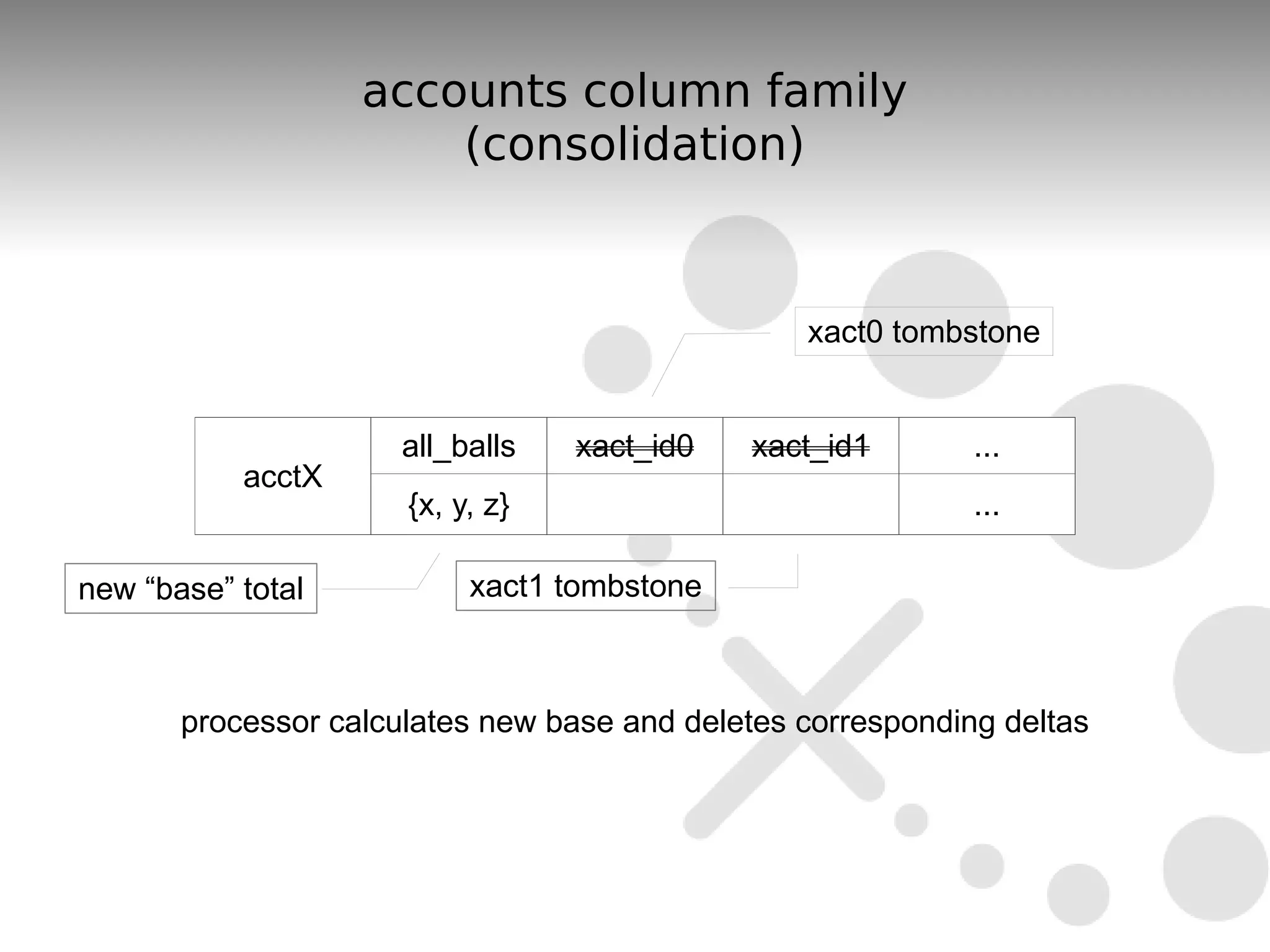





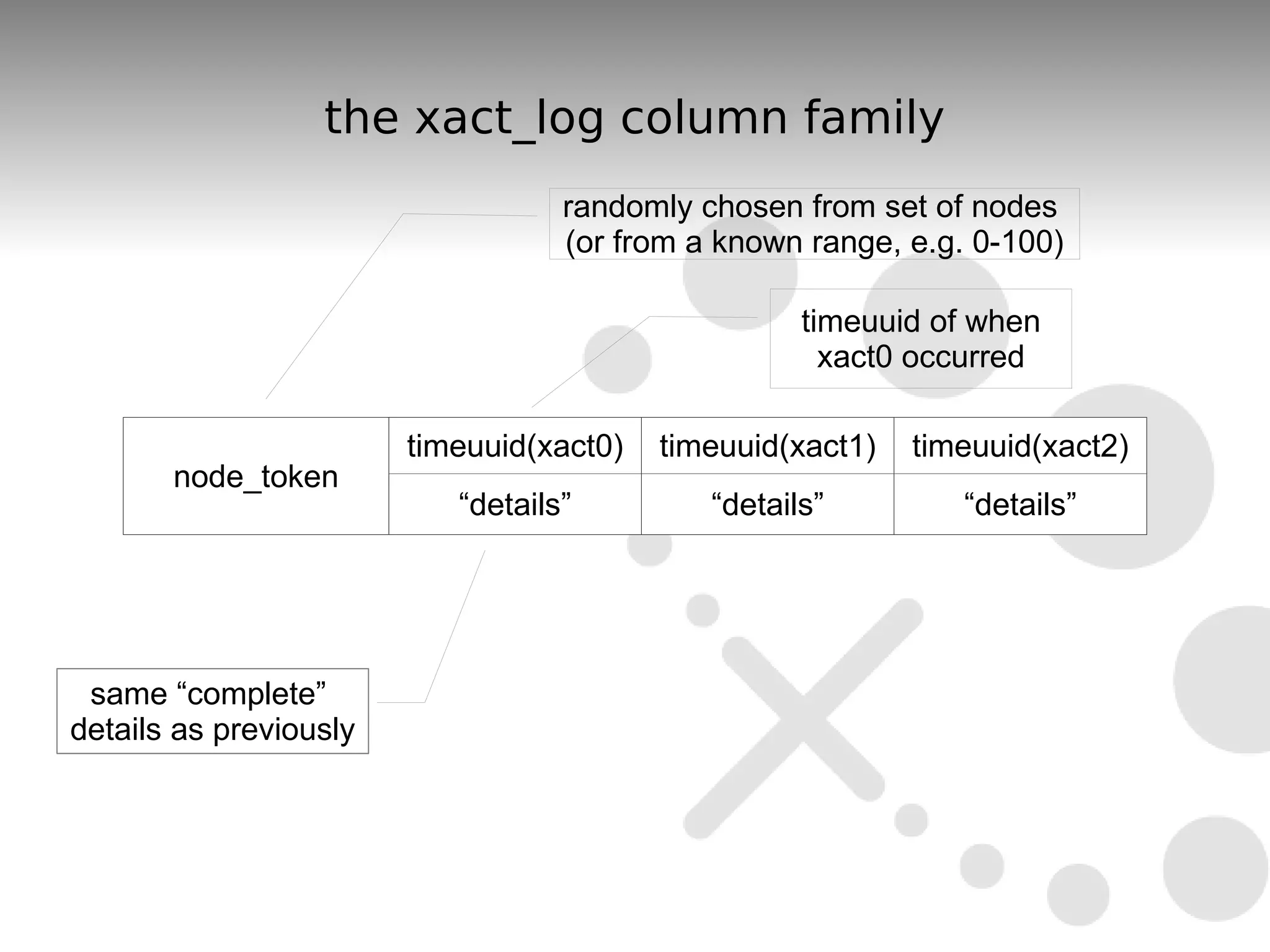











The document discusses the durability and consistency mechanisms in Apache Cassandra, particularly focusing on the accounts column family and transaction logging for a banking application. It describes how to manage account balances, transfers, and consolidations while ensuring data integrity and handling of concurrent transactions. The author emphasizes the need for careful design to maintain consistency across distributed nodes and outlines various strategies for achieving these goals.























































































