Download to read offline


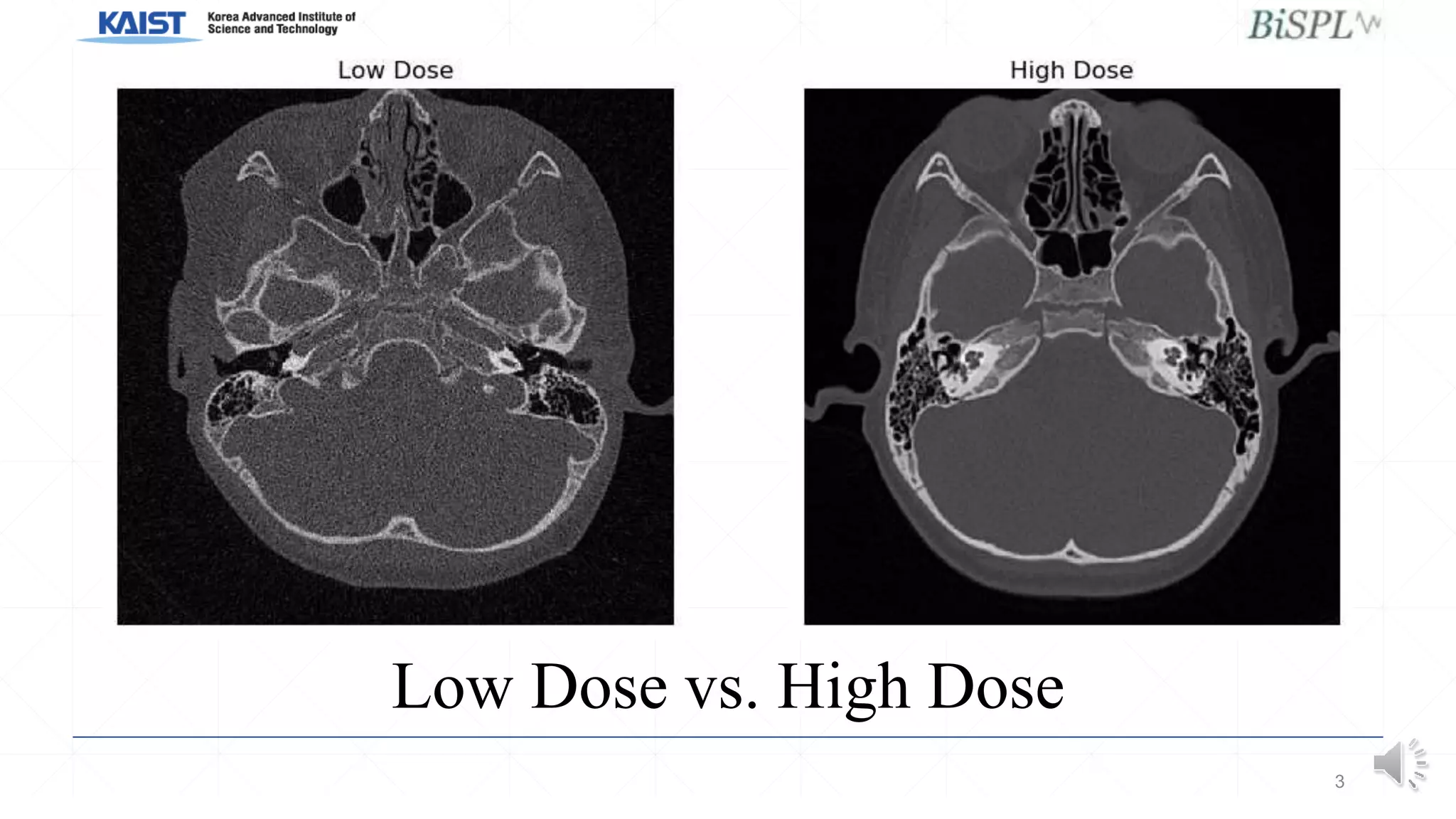
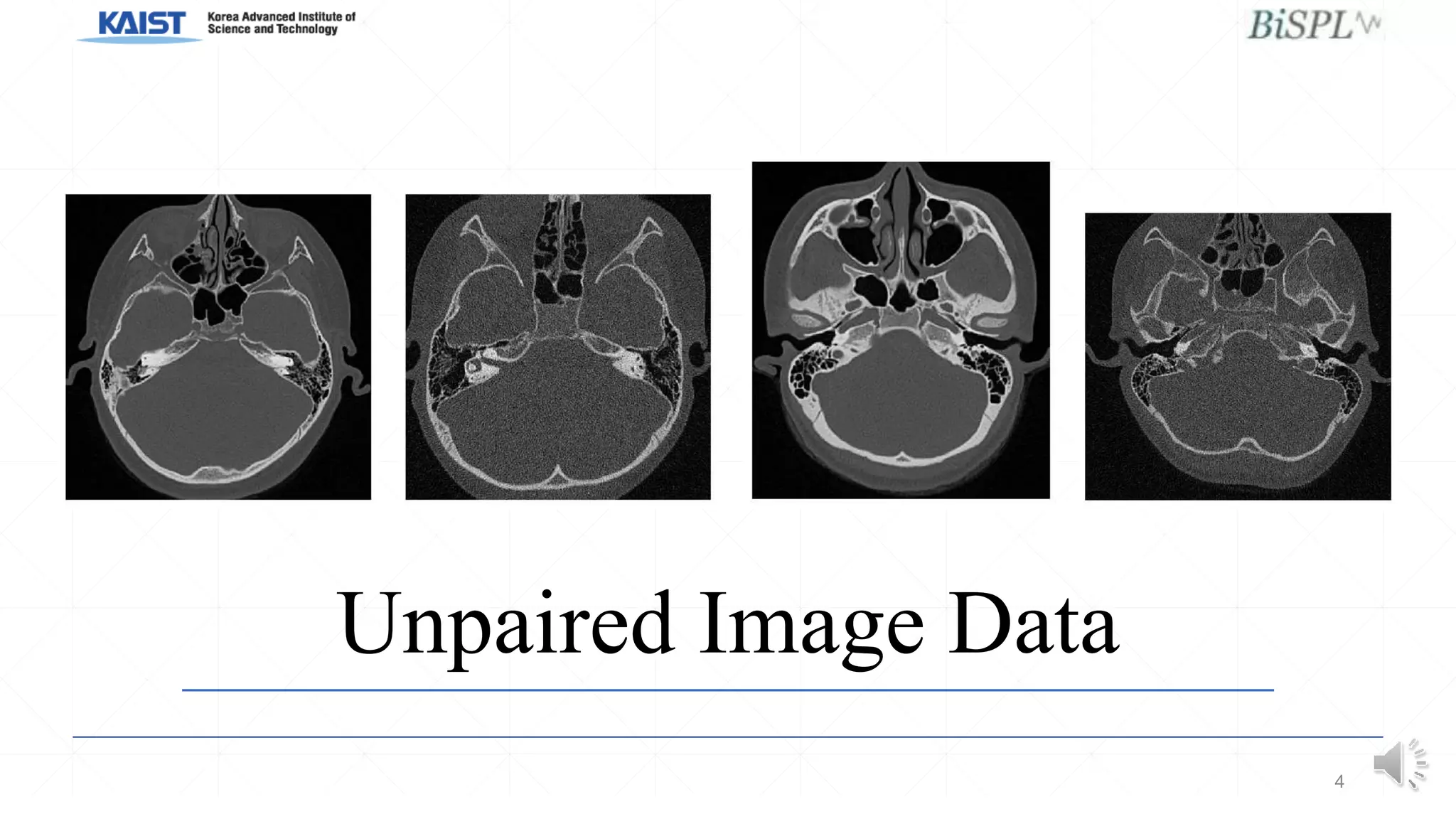
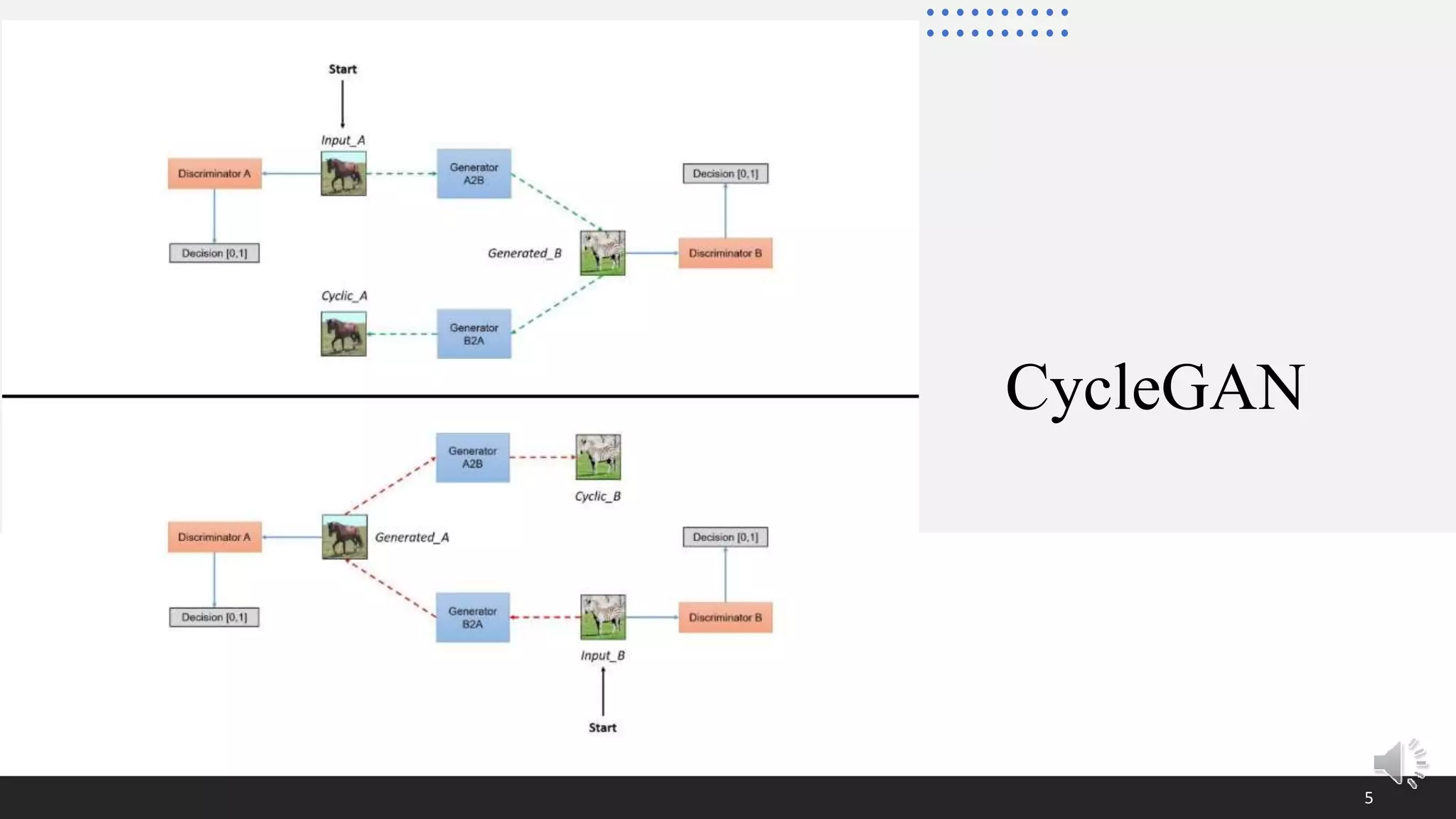
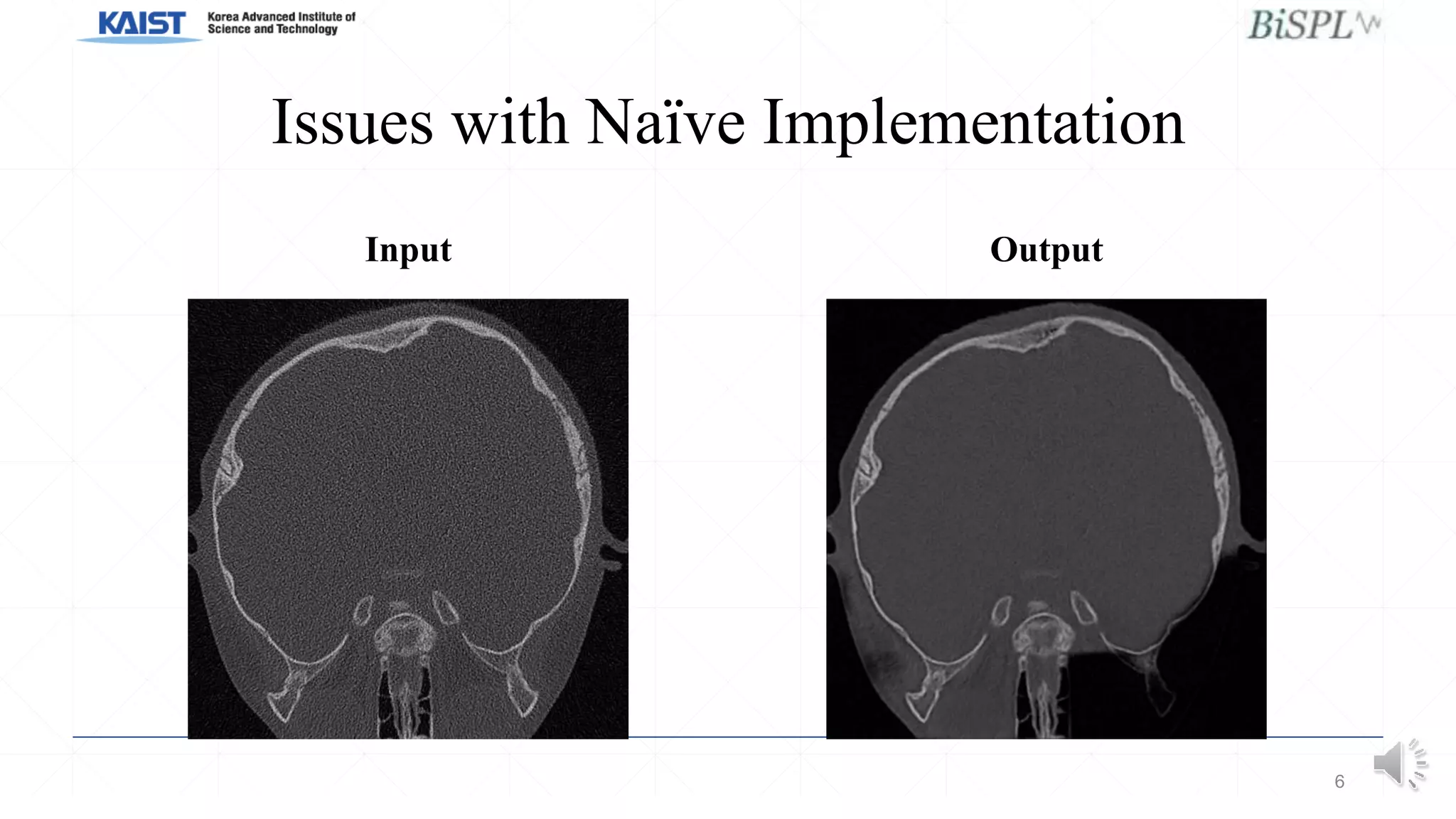

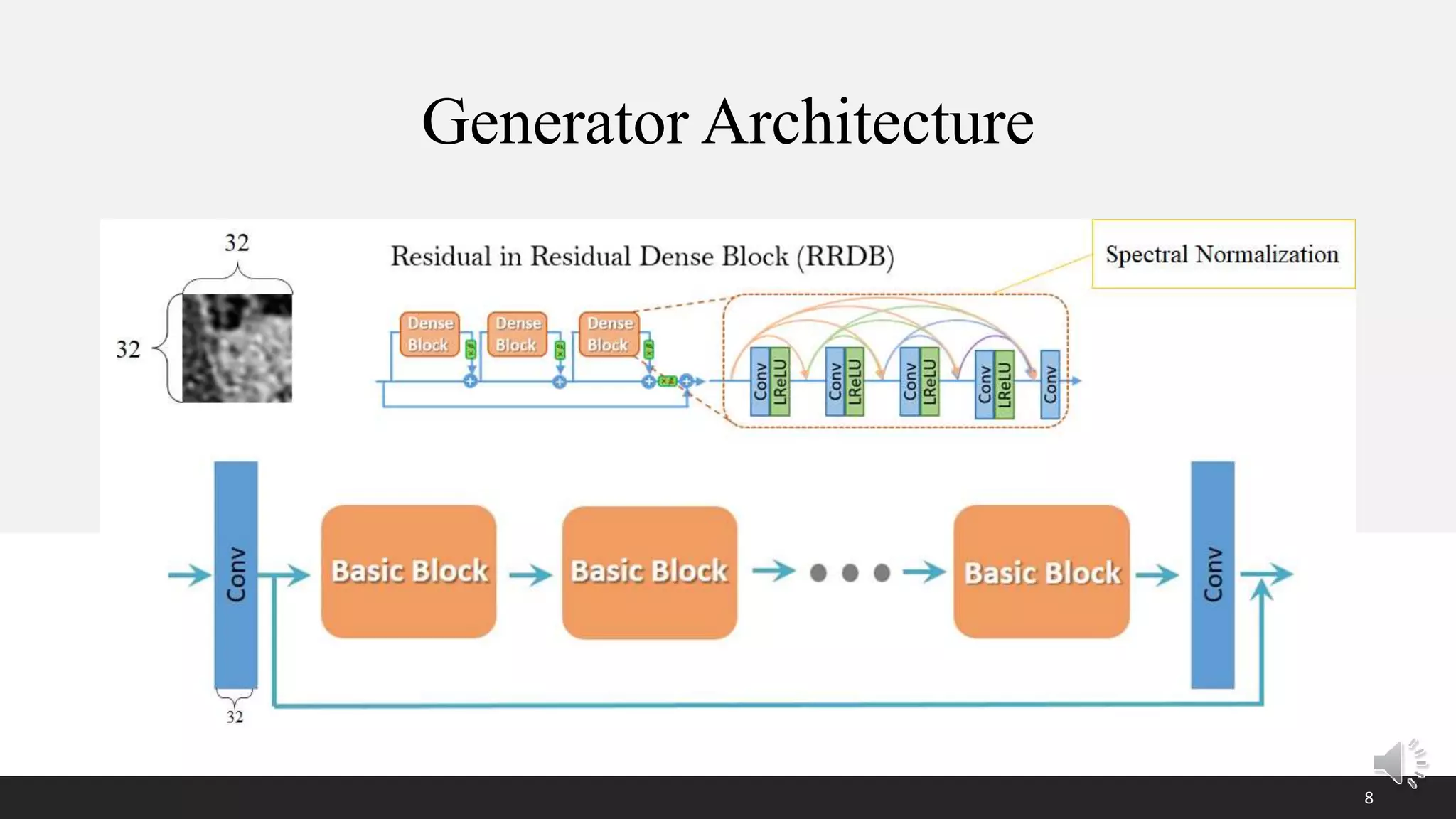
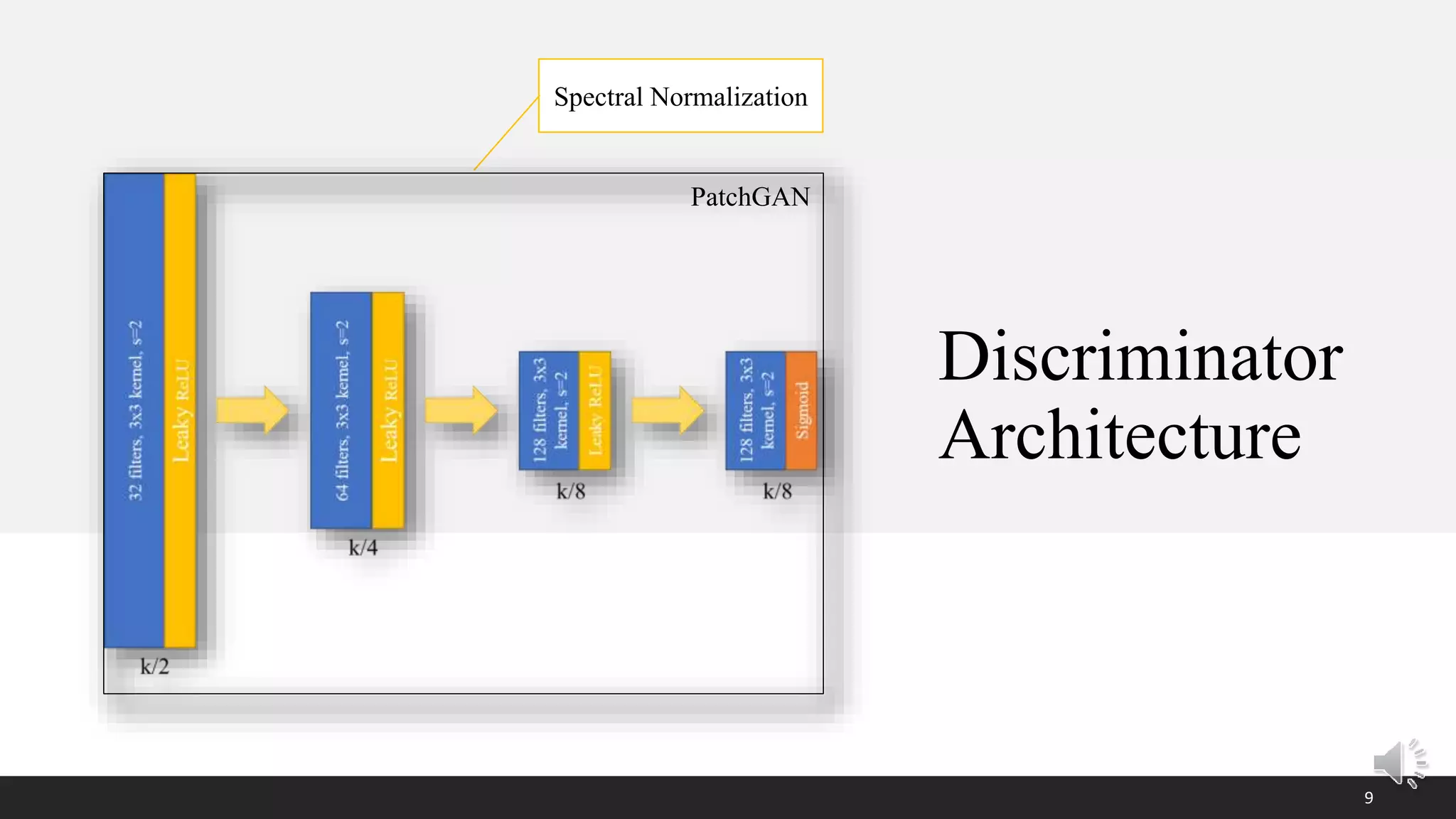


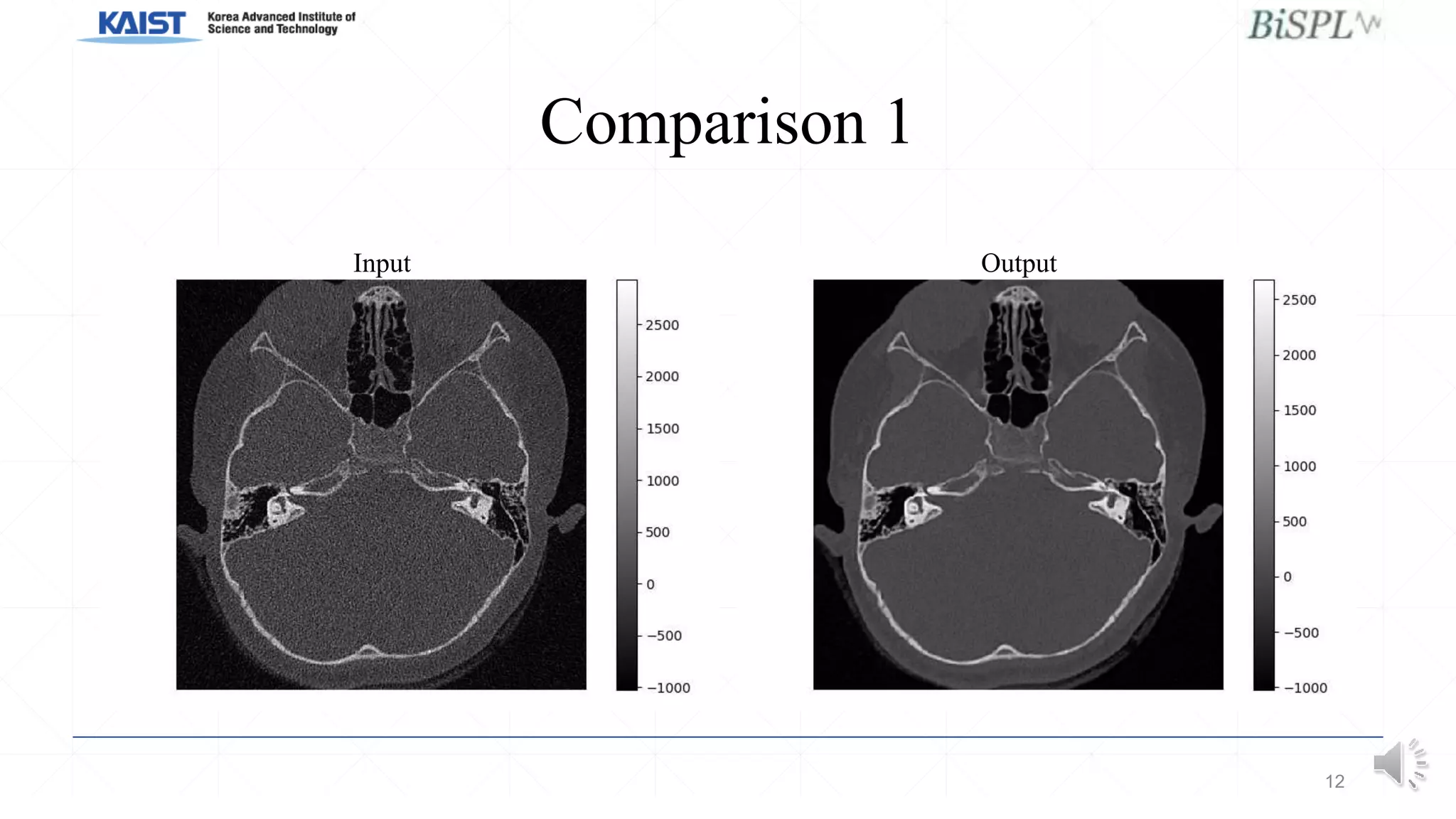
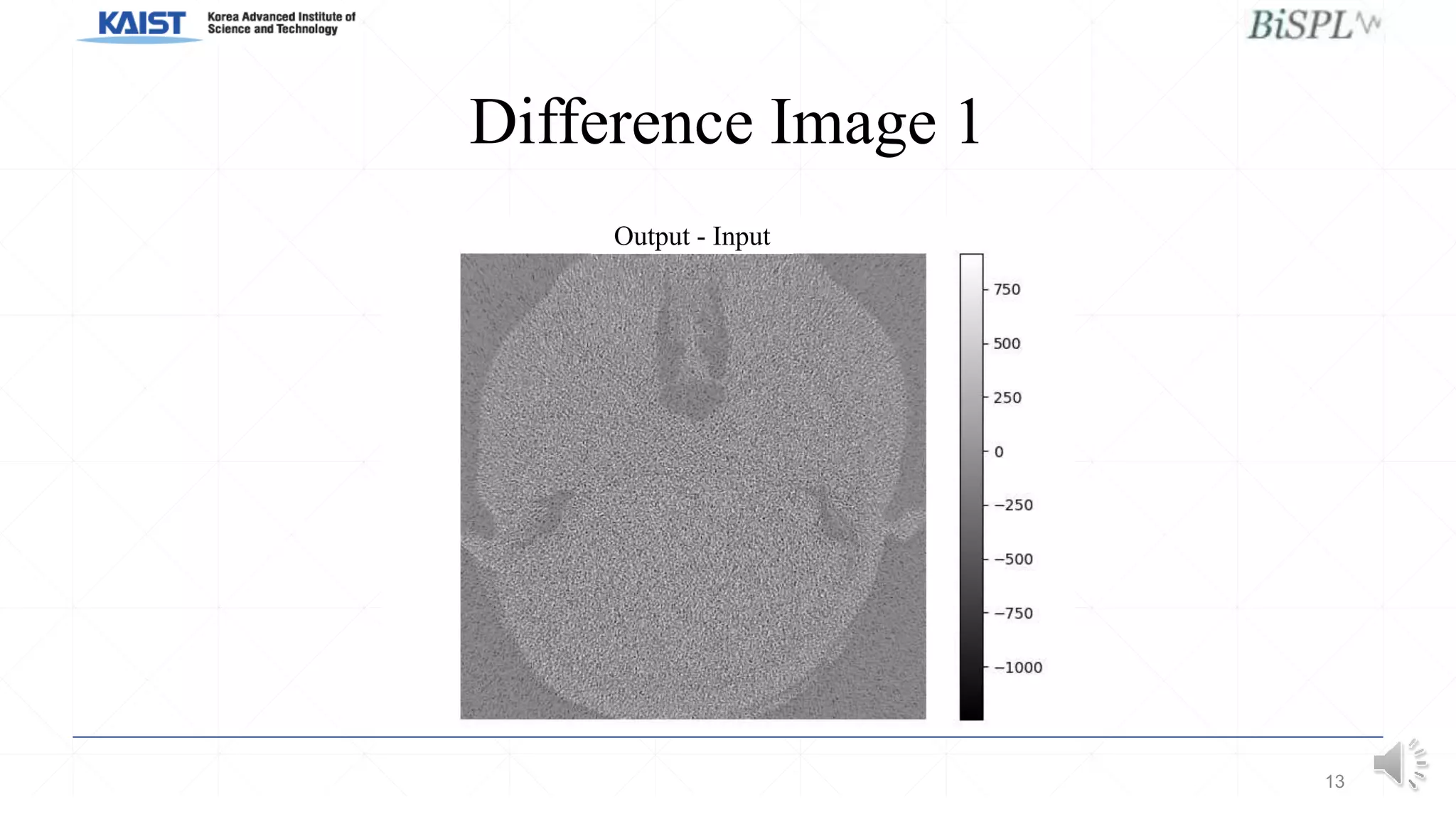
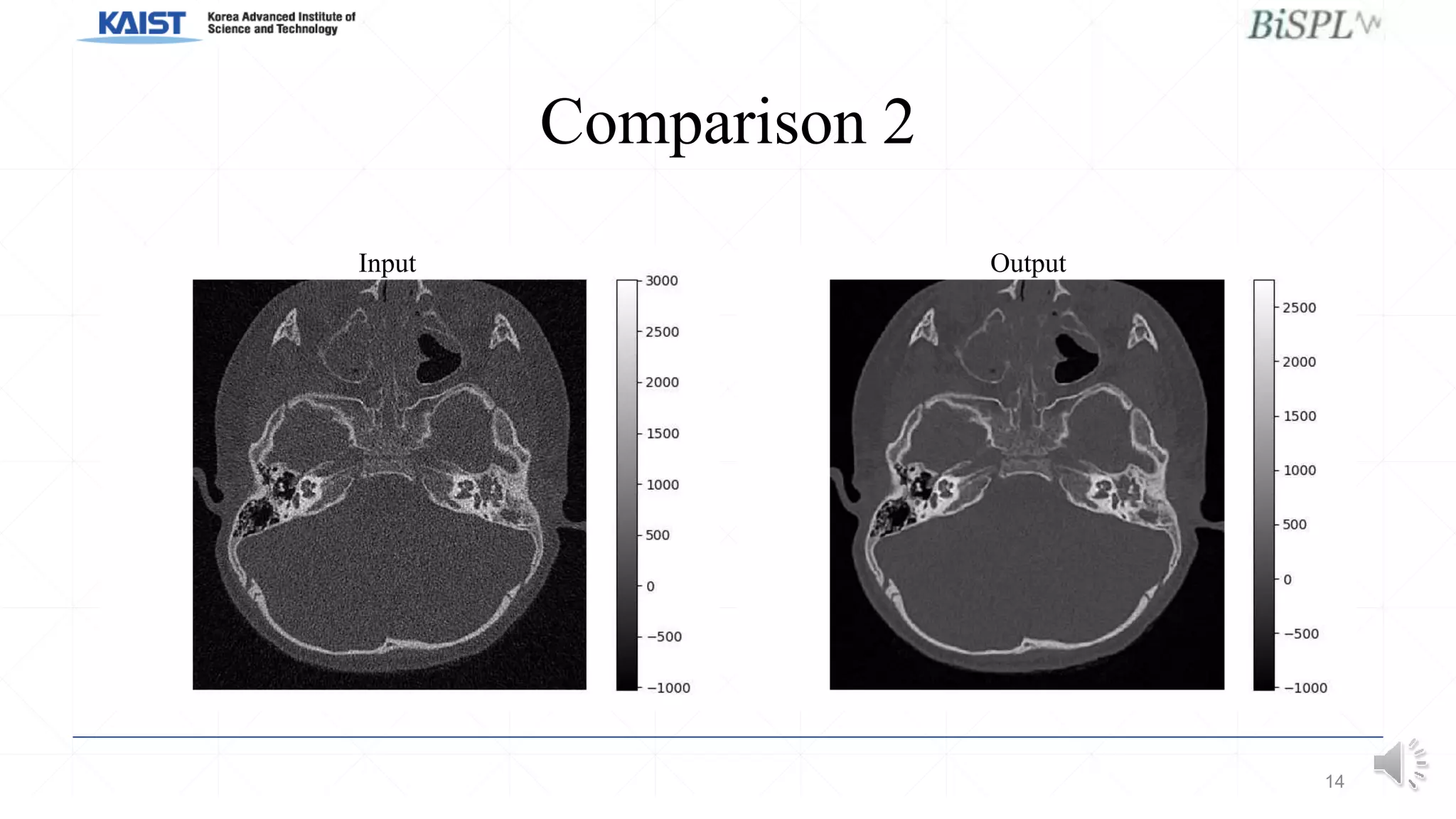
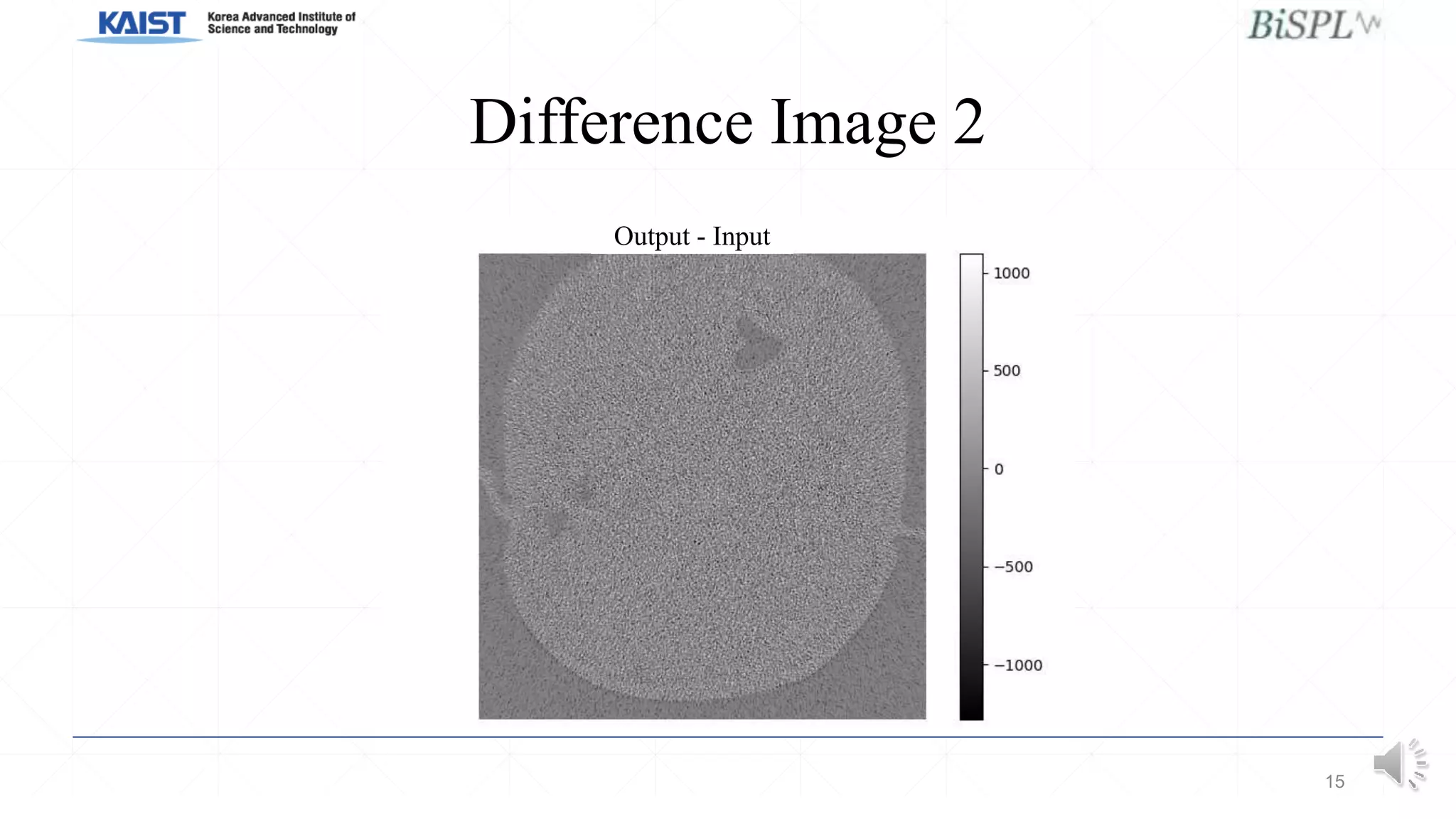
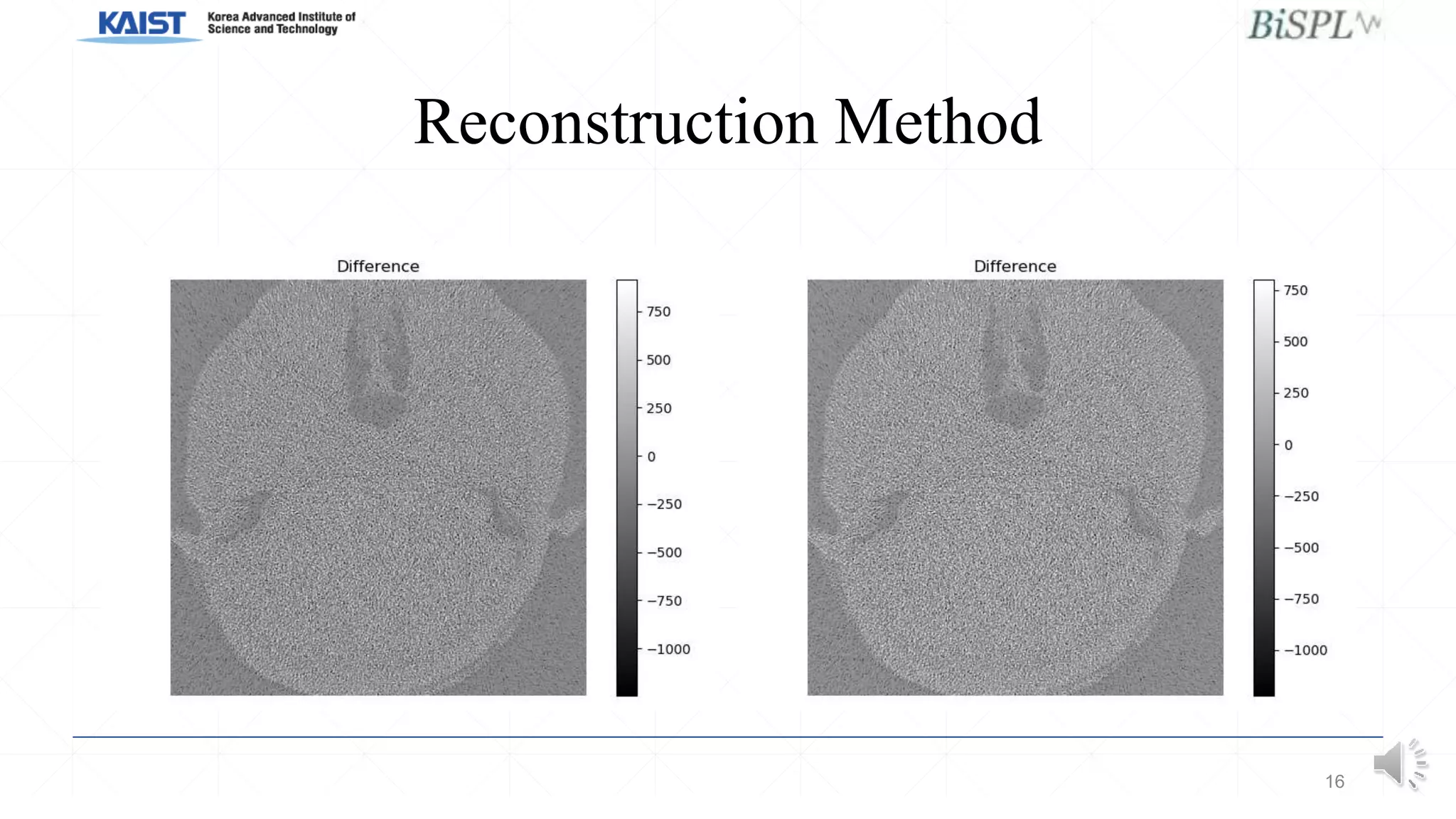
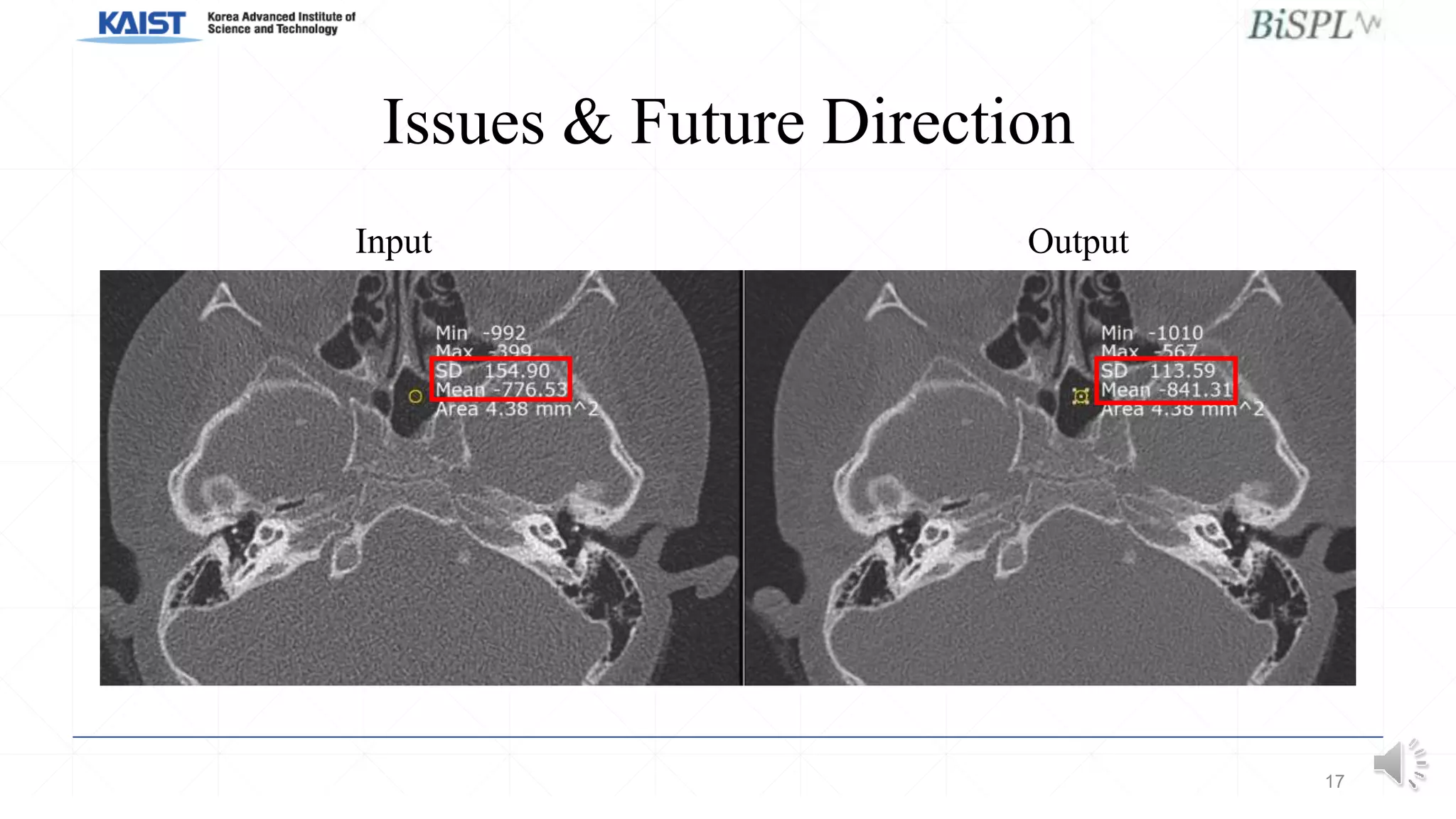

This document presents a poster on denoising unpaired low dose CT images using a self-ensembled CycleGAN, focusing on the comparison between low and high dose images, as well as the architecture and training details. The authors address issues with naive implementations while showcasing results through input-output comparisons. Additionally, the presentation concludes with future directions and invites questions from the audience.

















![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)






![Network Deconvolution review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/networkdeconvolutionreviewcdm-200522173528-thumbnail.jpg?width=640&height=640&fit=bounds)









































