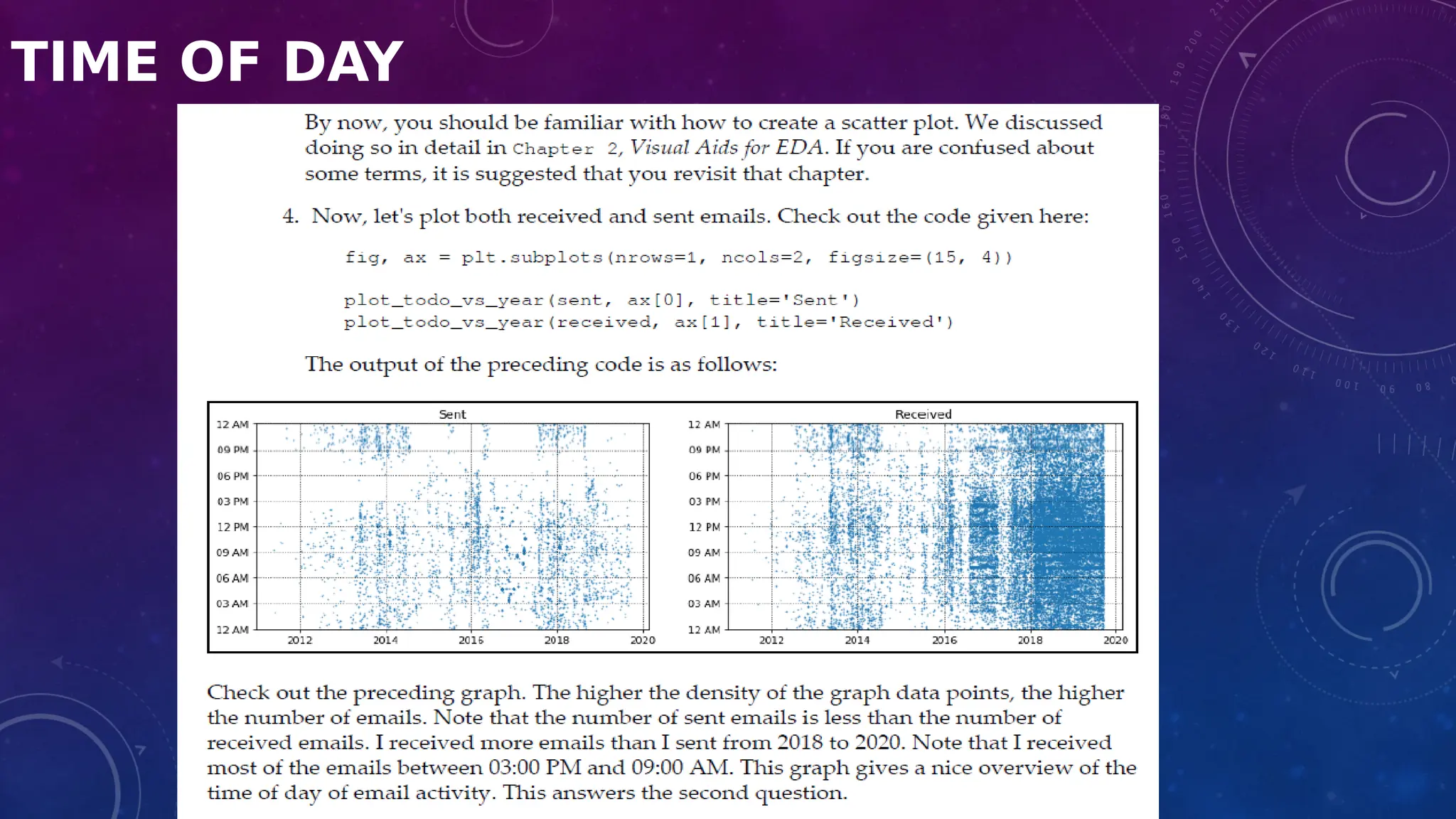
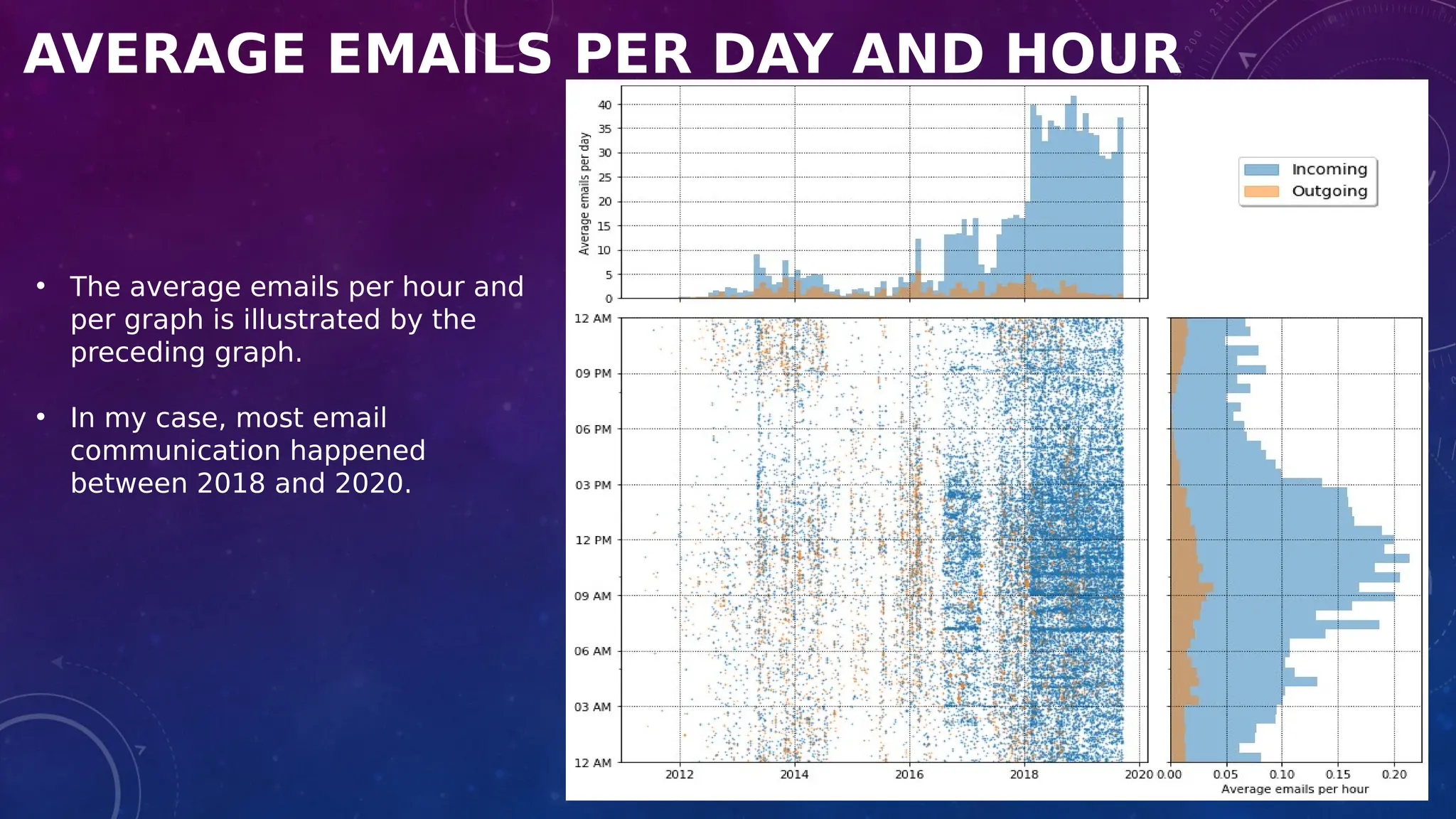
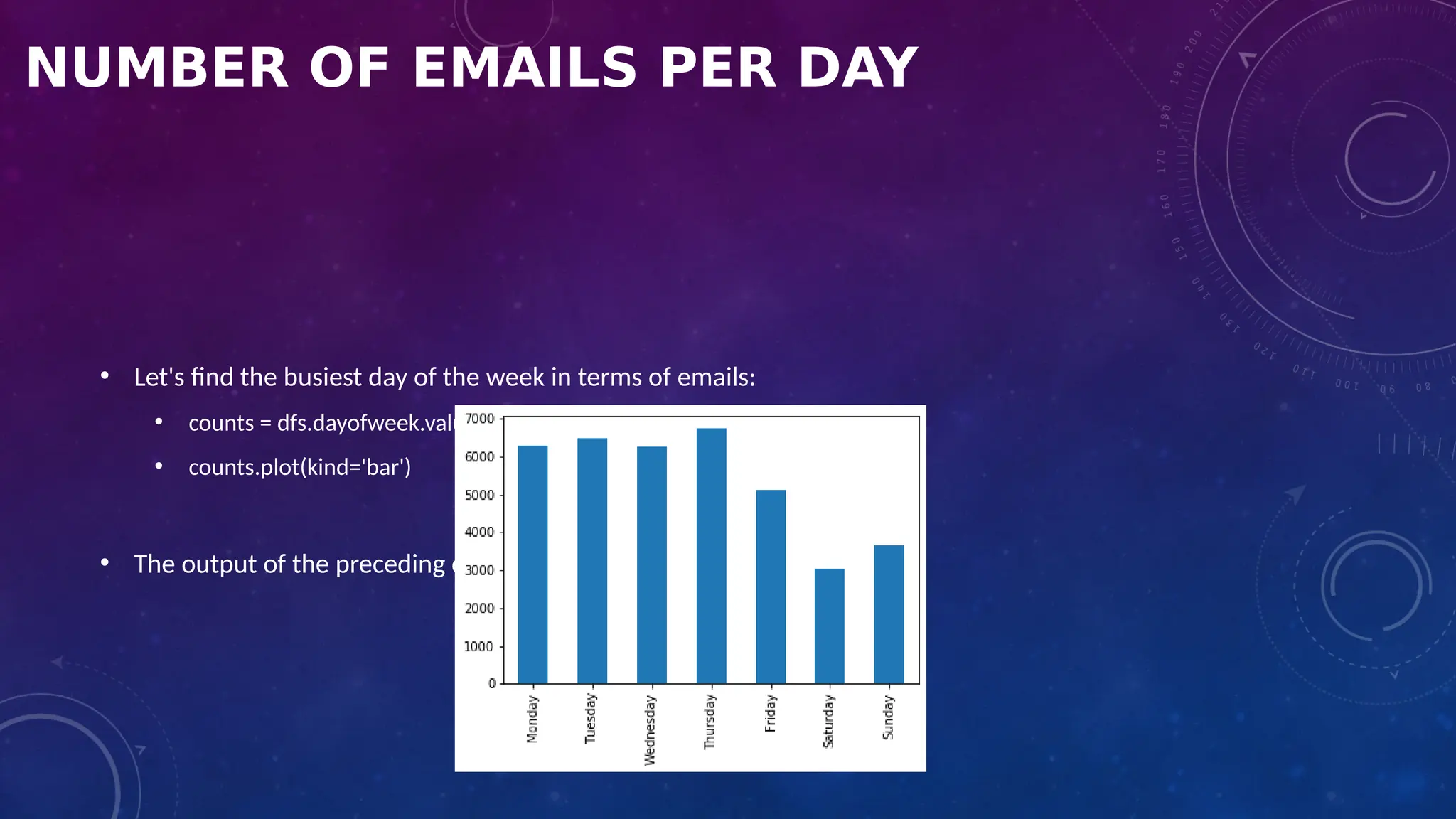
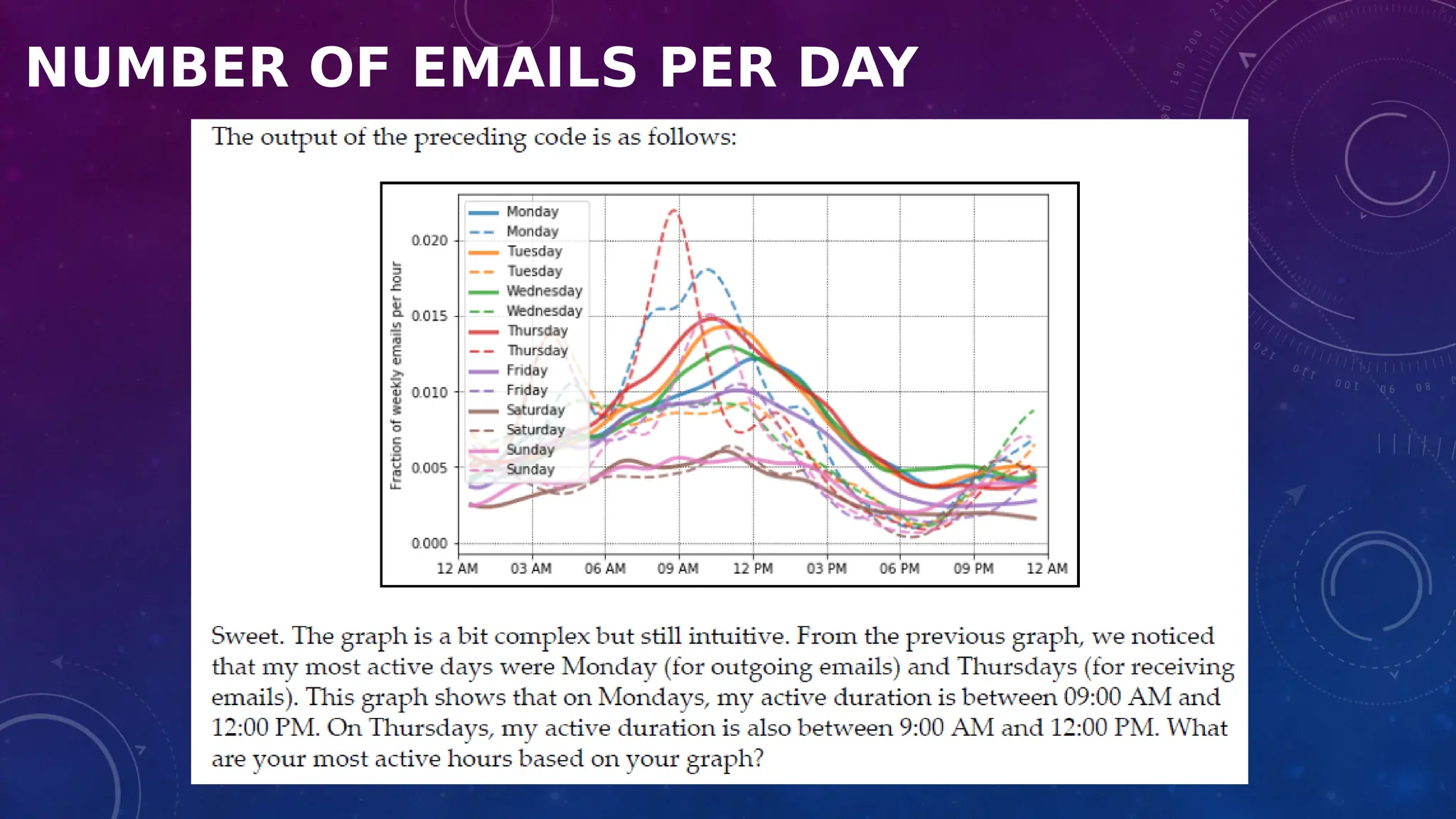
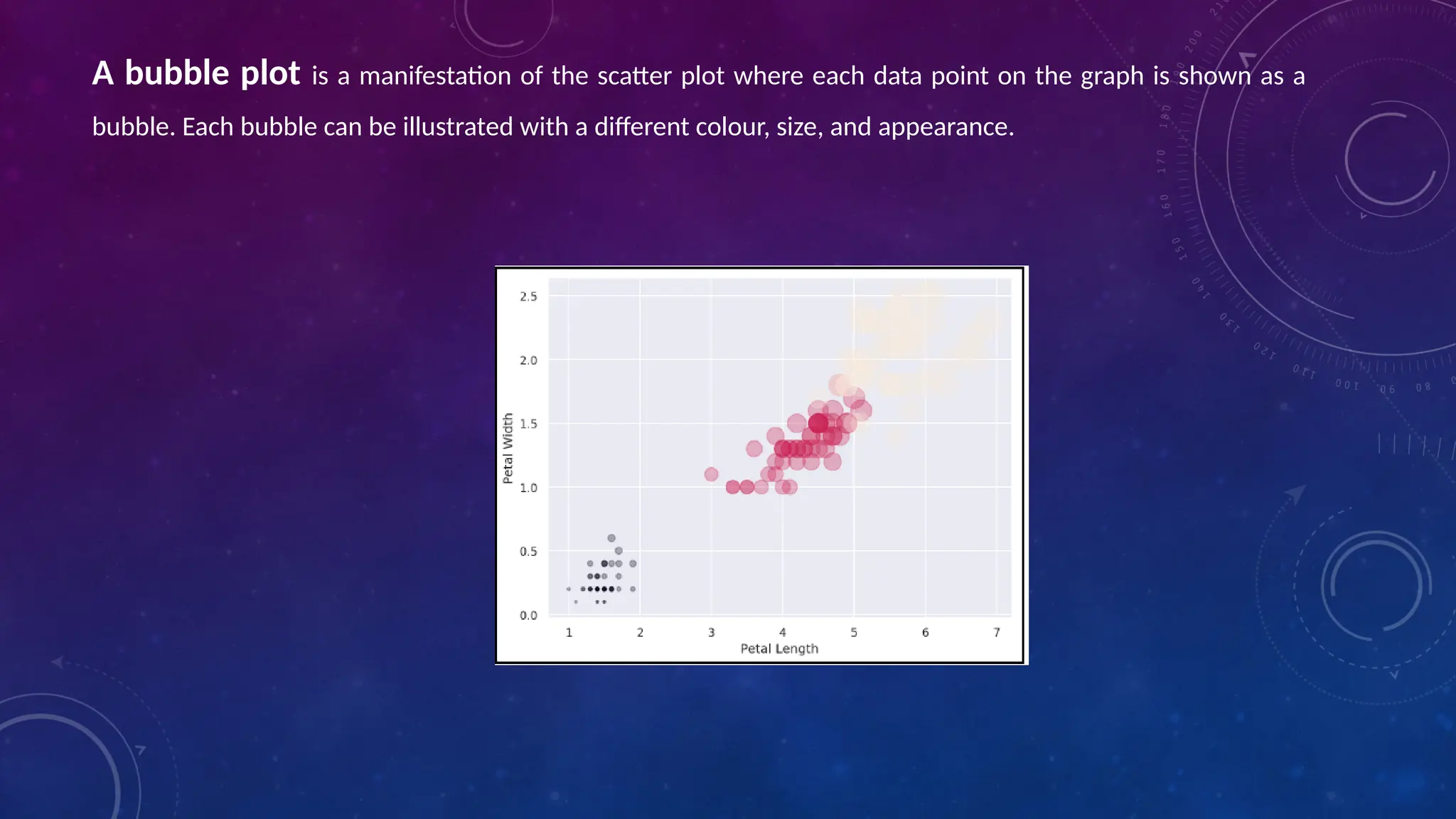
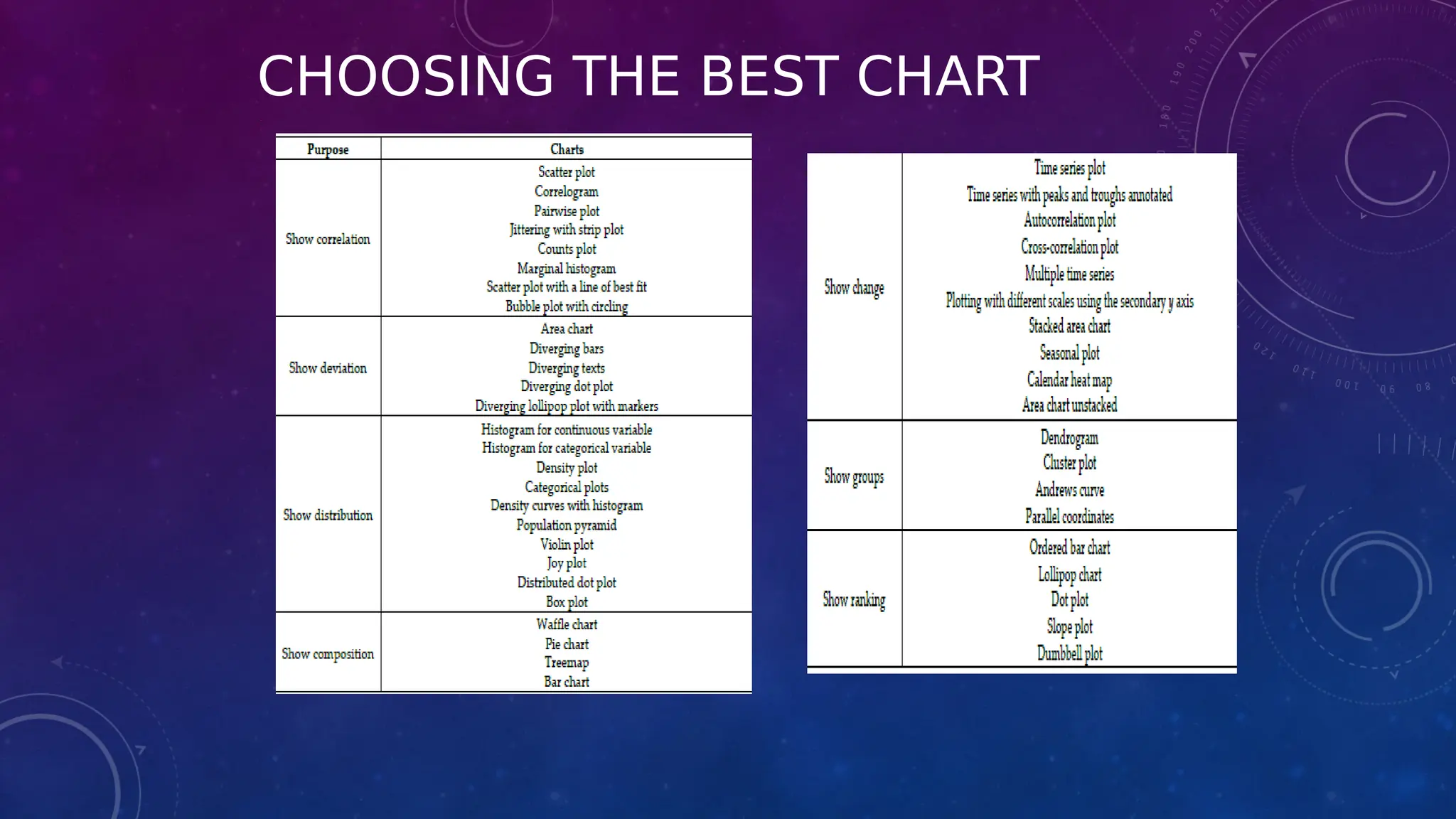
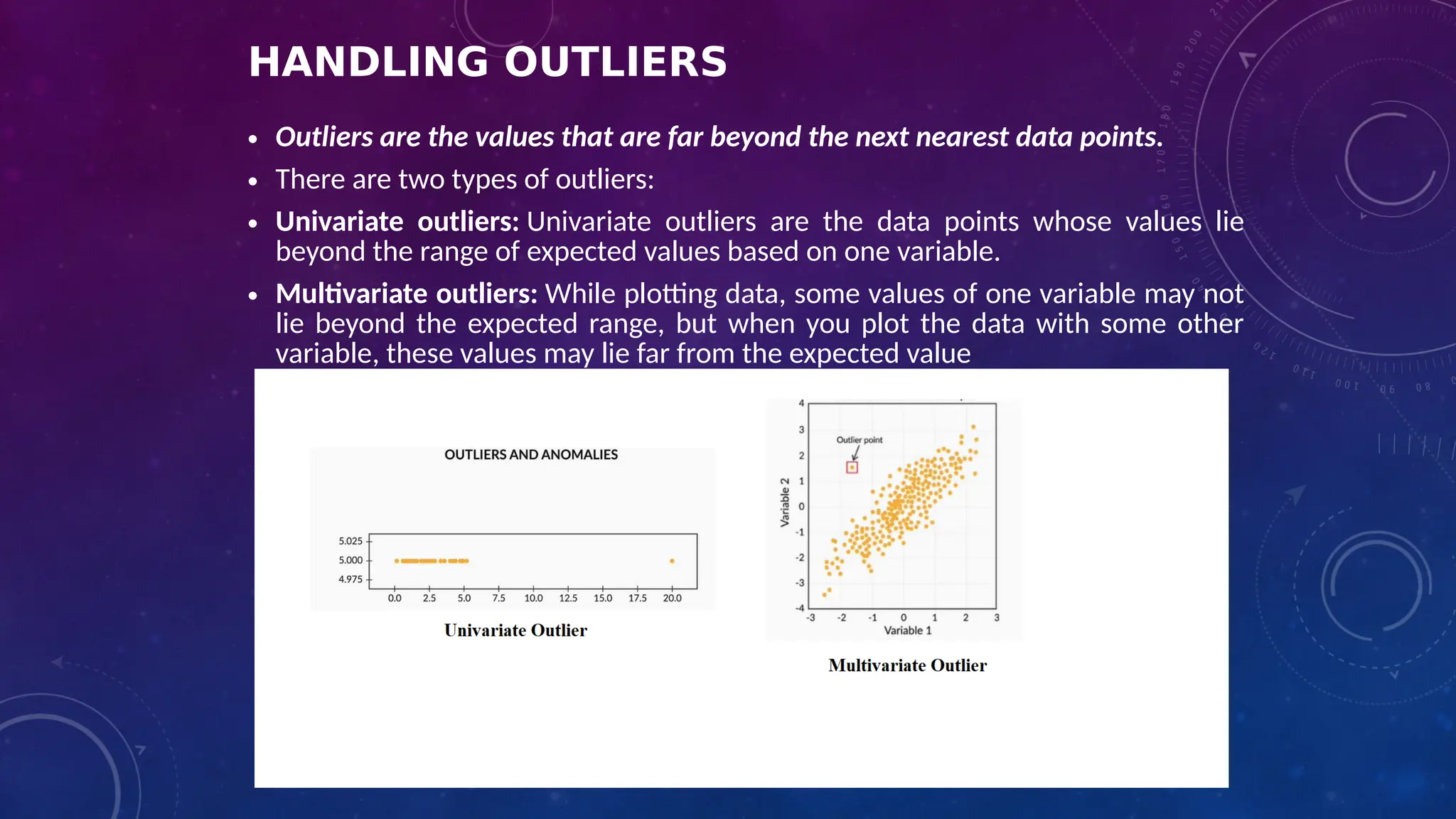
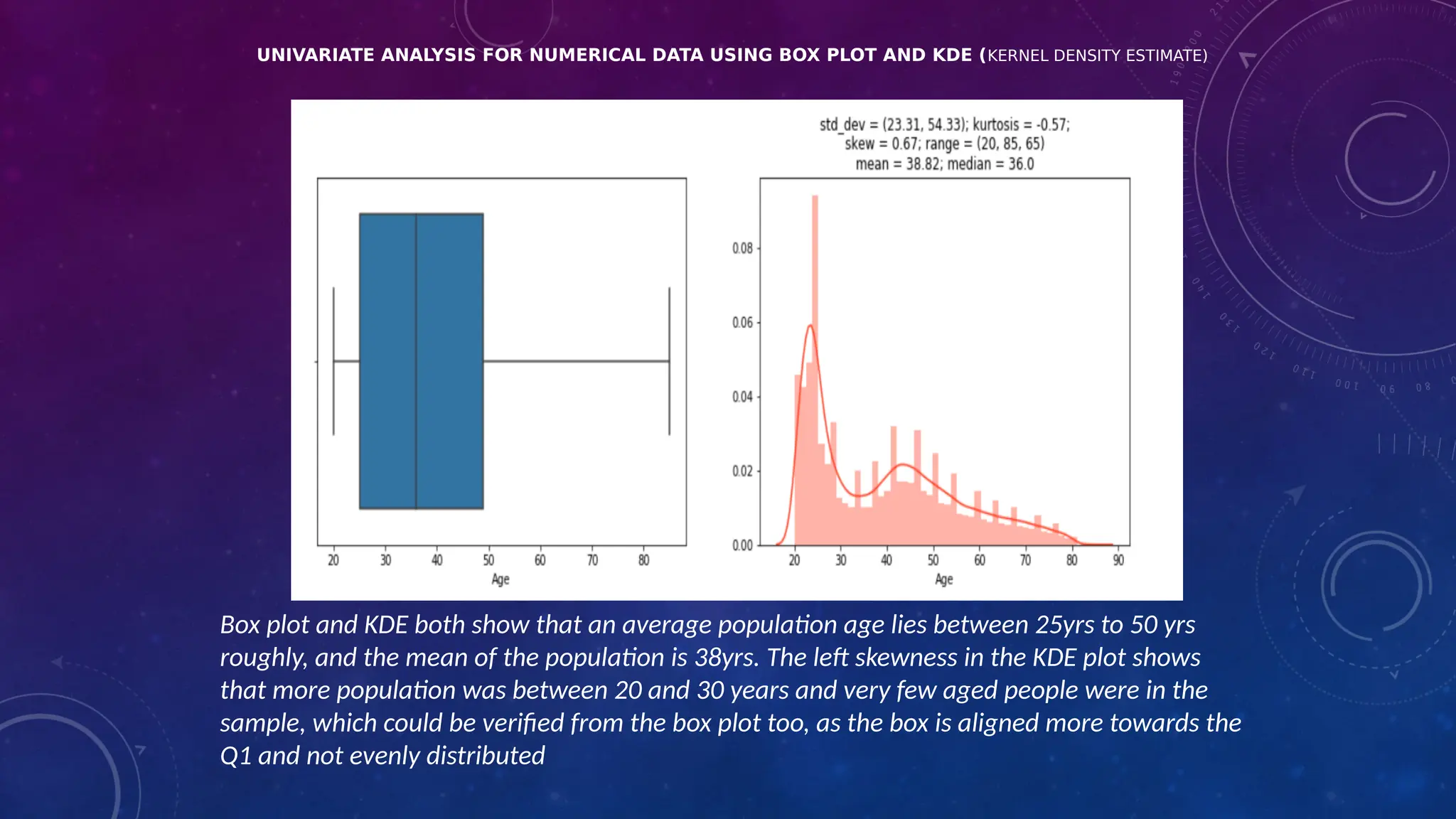
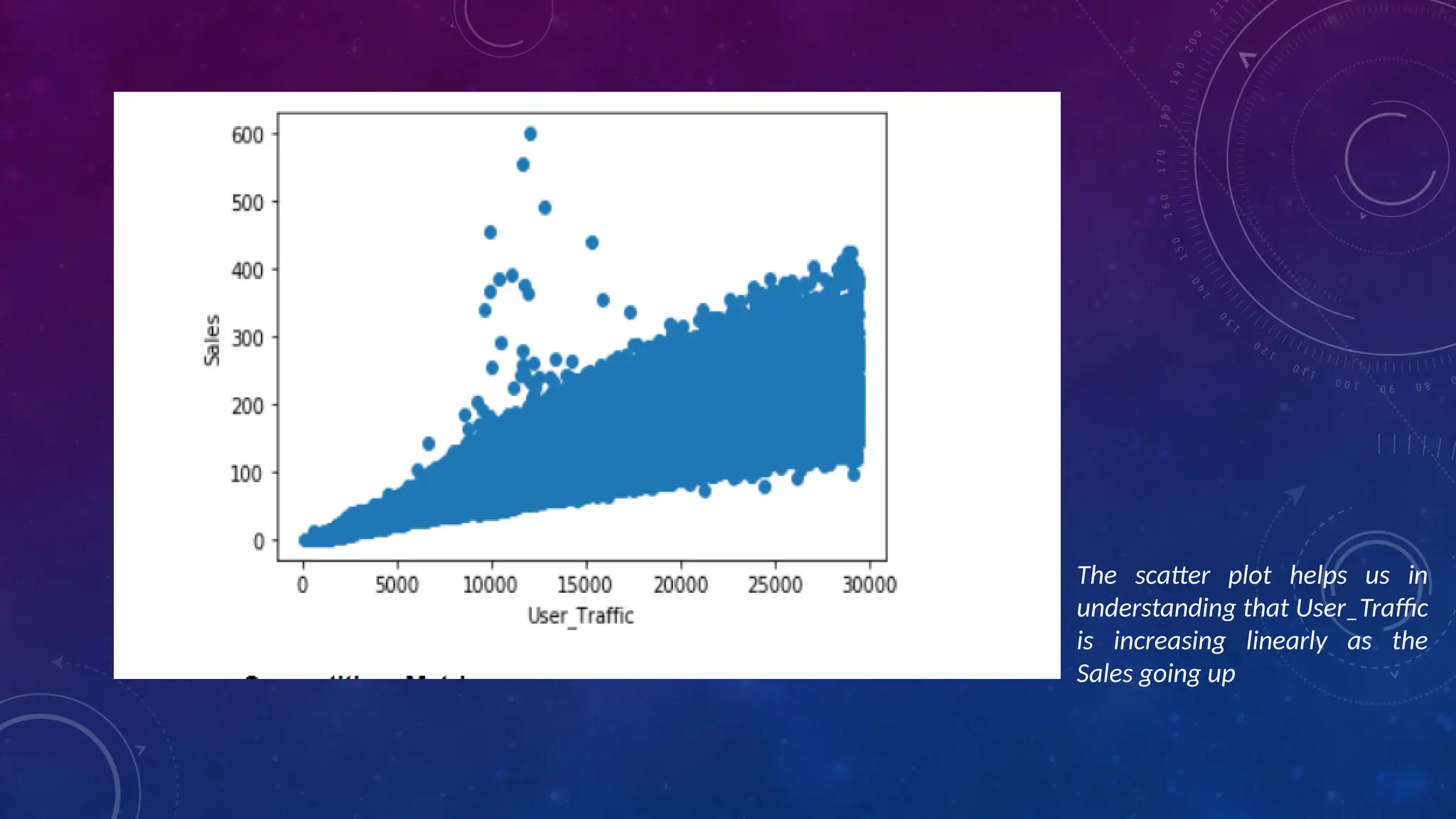
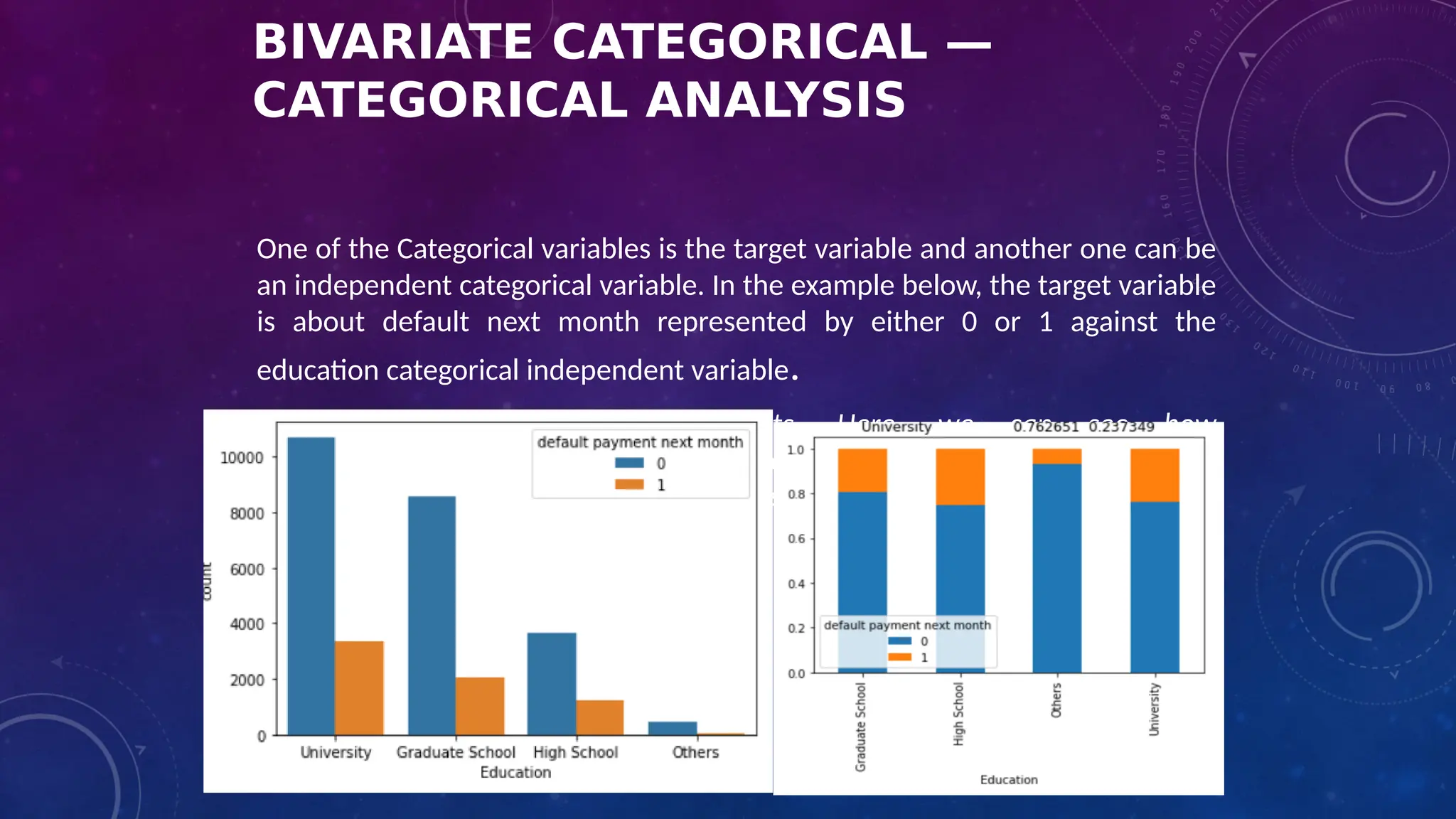
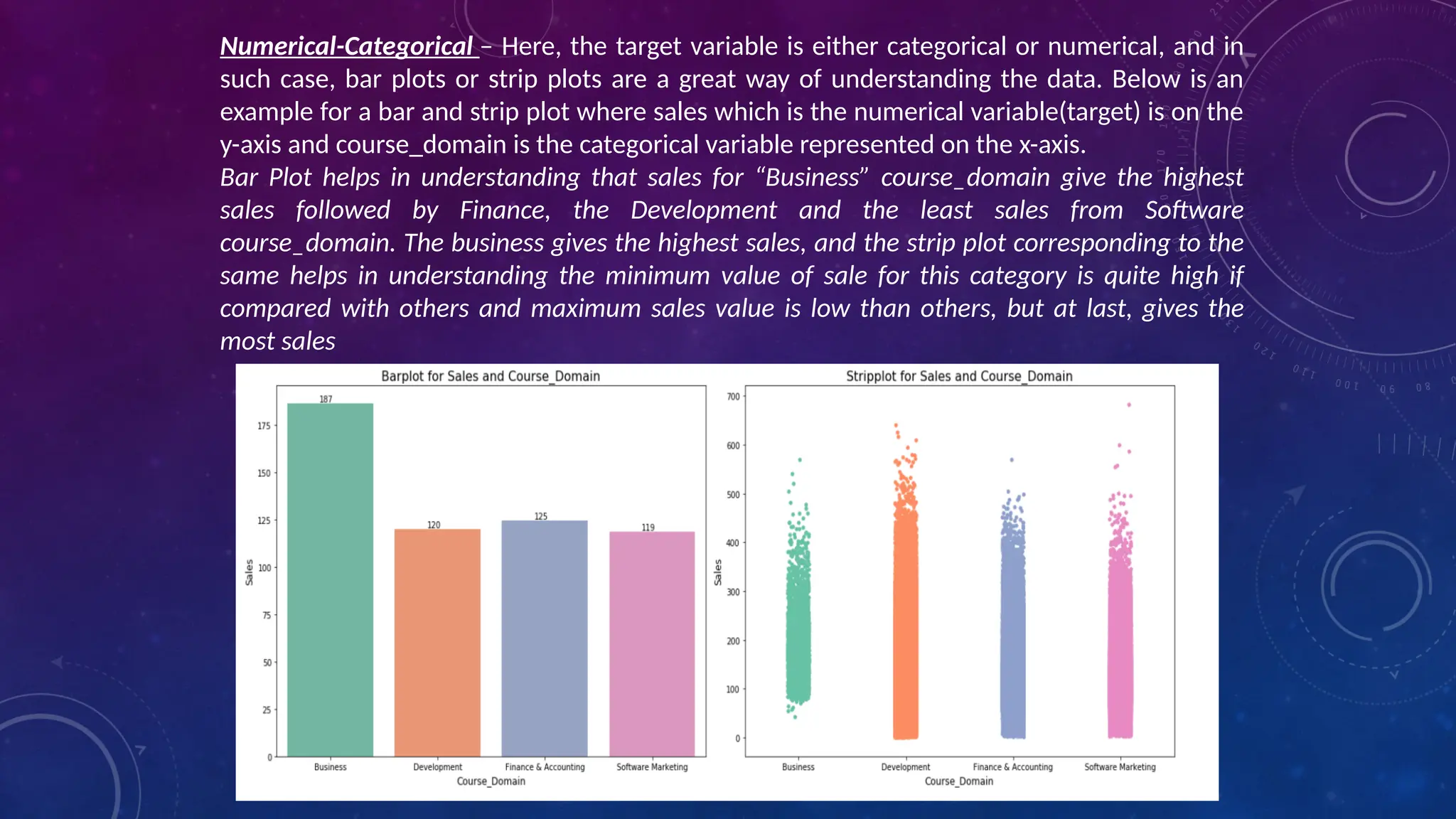
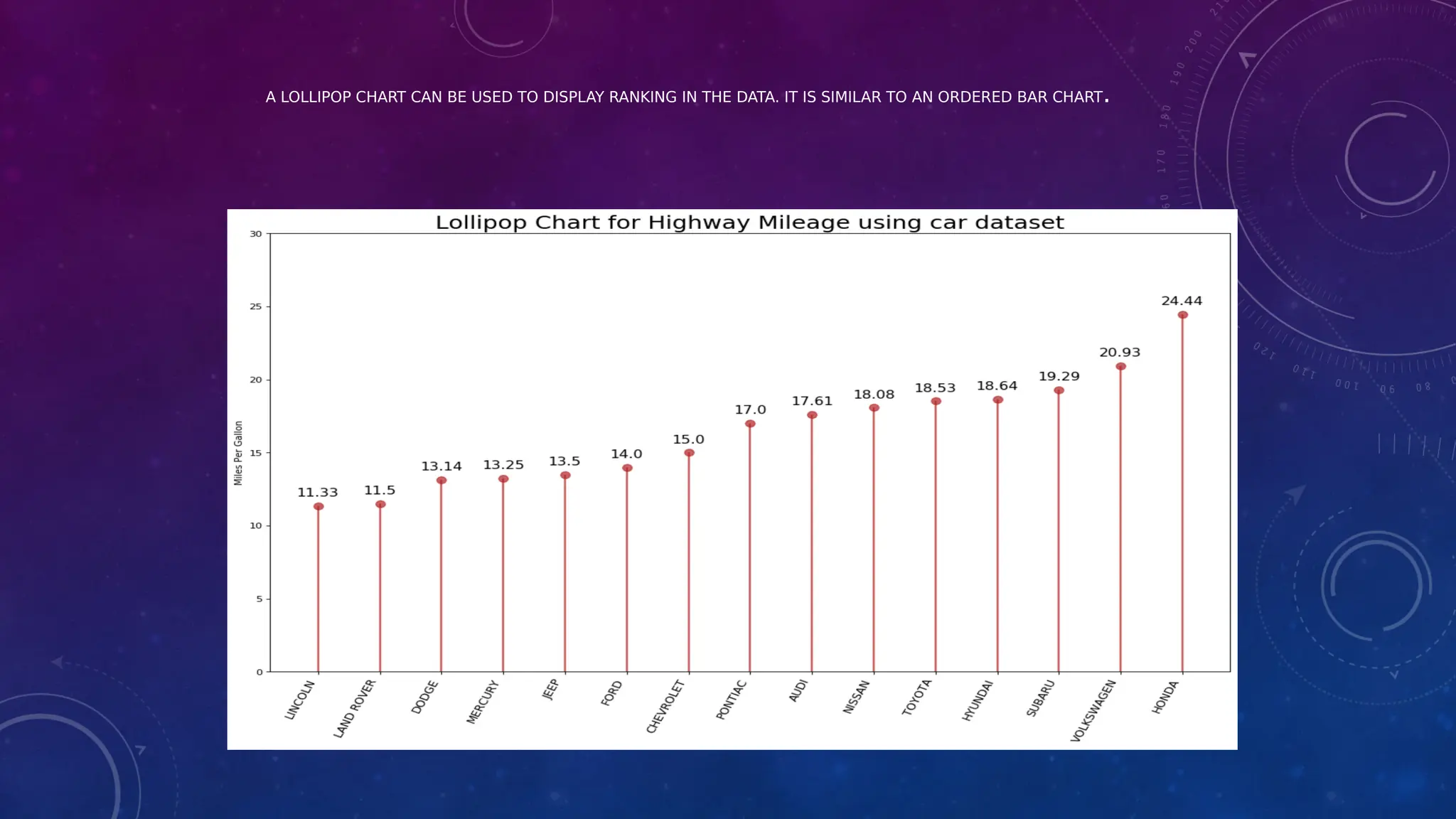
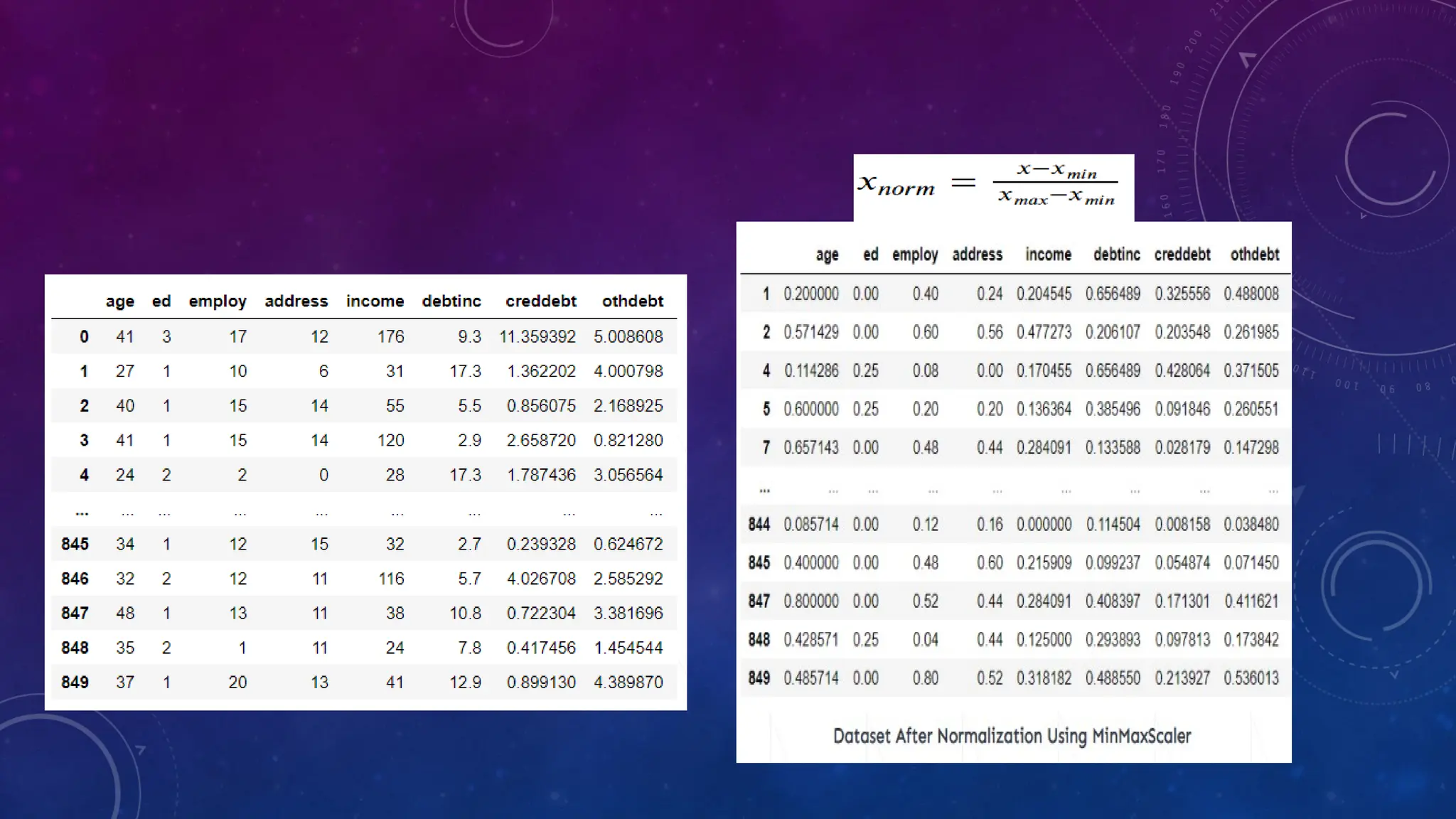
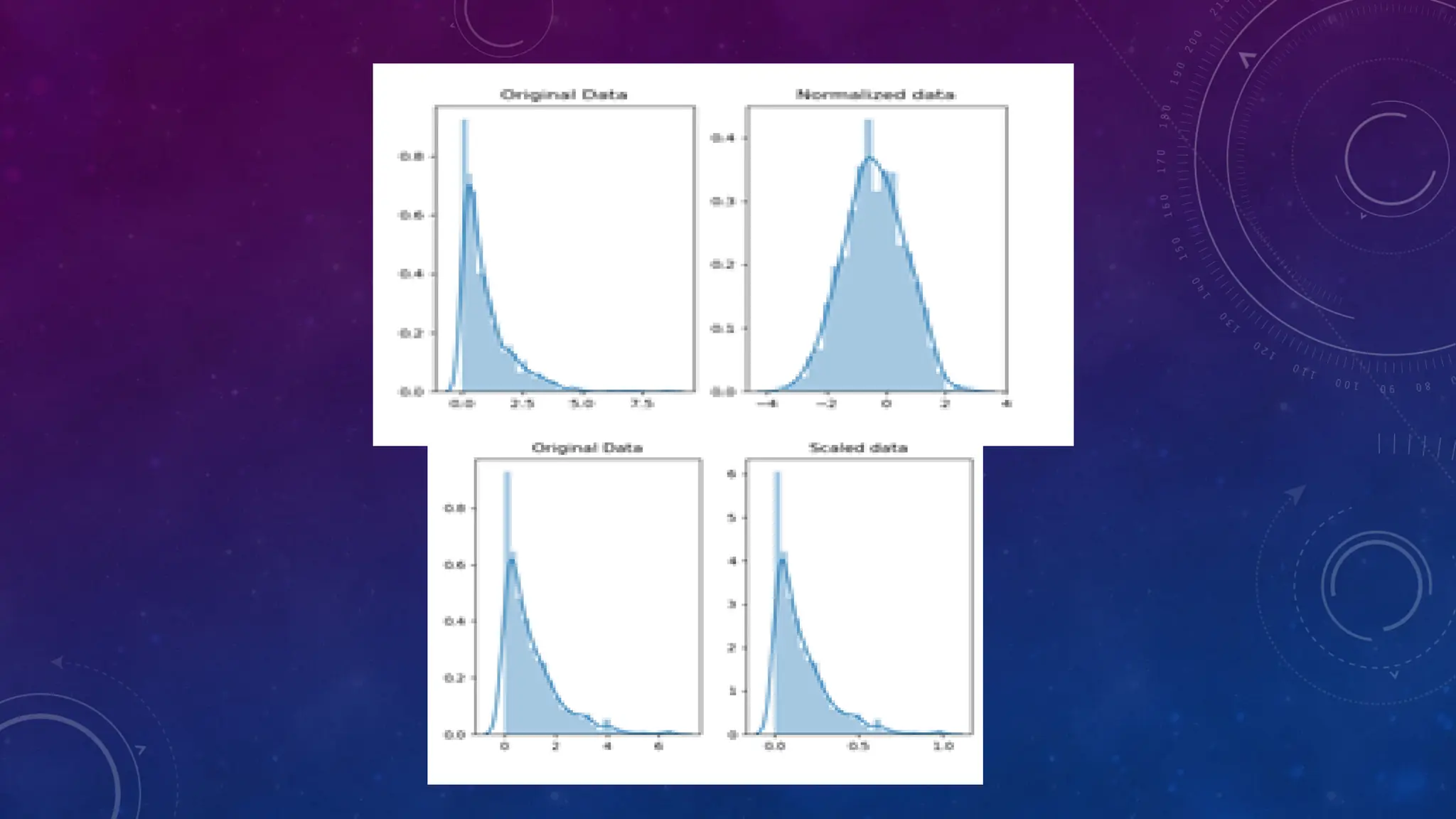
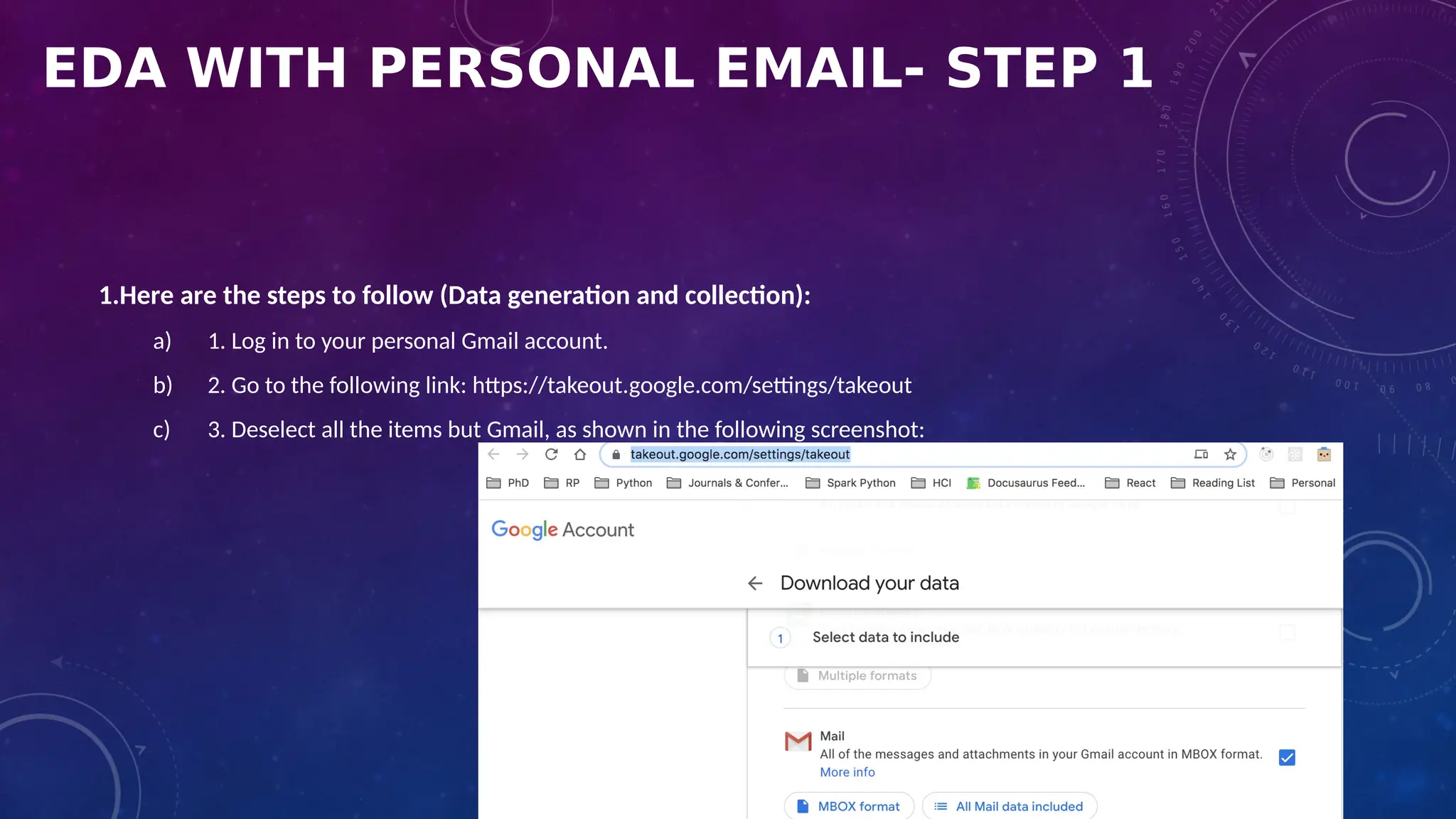
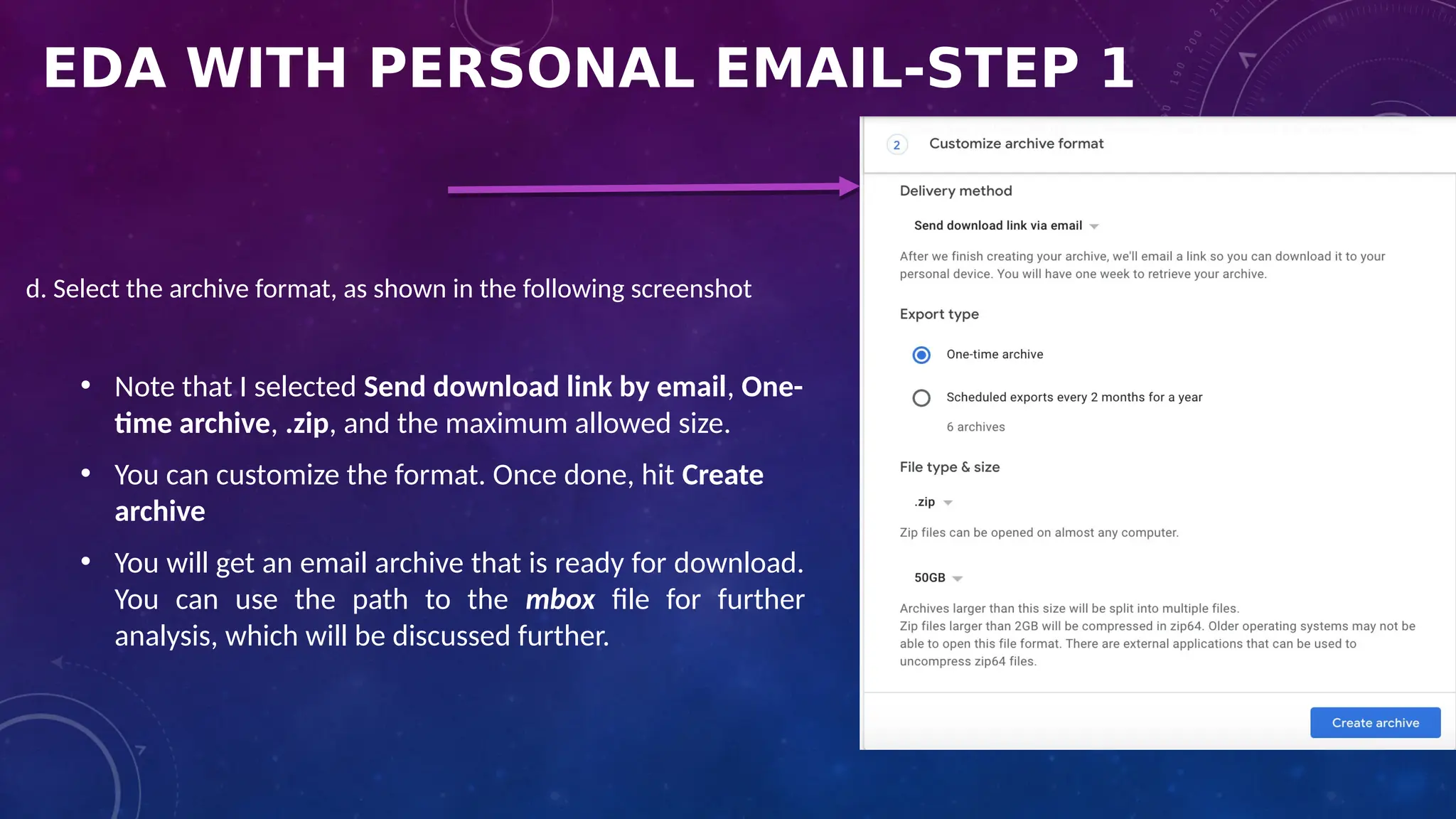
The document covers the fundamentals of exploratory data analysis (EDA) in the context of Internet of Things (IoT) solutions, detailing processes such as data generation, gathering, and pre-processing. It describes various EDA techniques, visualization tools, and the differences between univariate, bivariate, and multivariate analysis, along with the importance of handling outliers and missing values. Additionally, it includes practical steps for conducting EDA using personal email datasets, emphasizing the use of Python libraries for analysis.





























![EDA WITH PERSONAL EMAIL-STEP 2
Loading the dataset
3. Next, let's see the list of available keys::
for key in mbox[0].keys():
print(key)
• The output of the preceding code is as follows:
• The preceding output shows the list of keys that are present in
the extracted dataset.](https://image.slidesharecdn.com/dataanalyticsforiotsolutions-240918144006-52efadcb/75/Data_Analytics_for_IoT_Solutions-pptx-pdf-46-2048.jpg)
![EDA WITH PERSONAL EMAIL-STEP 3
A. Data Transformation
• Although there are a lot of
objects returned by the
extracted data, we do not need
all the items. We will only
extract the required fields.
• Data cleansing is one of the
essential steps in the data
analysis phase.
• For our analysis, all we need is
data for the following: subject,
from, date, to, label, and
thread.
B. Data cleansing
Let's create a CSV file with only the required fields. Let's start with the
following steps
1. Import the csv package:
• import csv
2. Create a CSV file with only the required attributes:
with open('mailbox.csv', 'w') as outputfile:
writer = csv.writer(outputfile)
writer.writerow(['subject','from','date','to','label','thread'])
for message in mbox:
writer.writerow([
message['subject'],
message['from'],
message['date'],
message['to'],
message['X-Gmail-Labels'],
message['X-GM-THRID']
]
)
• The preceding output is a csv file named mailbox.csv. Next, instead of loading the
mbox file, we can use the CSV file for loading, which will be smaller than the
original dataset.](https://image.slidesharecdn.com/dataanalyticsforiotsolutions-240918144006-52efadcb/75/Data_Analytics_for_IoT_Solutions-pptx-pdf-47-2048.jpg)
![EDA WITH PERSONAL EMAIL-STEP 3
C. Loading the CSV file
• We will load the CSV file.
Refer to the following code
block:
dfs=pd.read_csv('mailbox.csv',
names=['subject', 'from', 'date',
'to',
'label', 'thread'])
• The preceding code will
generate a pandas data frame
with only the required fields
stored in the CSV file
D. Converting the date
• Next, we will convert the date.
• Check the datatypes of each column as shown here:
• dfs.dtypes
• The output of the preceding code is as follows:
• Note that a date field is an object. So, we need to convert it into a
DateTime argument.
• In the next step, we are going to convert the date field into an
actual DateTime argument. We can do this by using the pandas
to_datetime() method. See the following code:
dfs['date'] = dfs['date'].apply(lambda x: pd.to_datetime(x,
errors='coerce', utc=True))](https://image.slidesharecdn.com/dataanalyticsforiotsolutions-240918144006-52efadcb/75/Data_Analytics_for_IoT_Solutions-pptx-pdf-48-2048.jpg)
![EDA WITH PERSONAL EMAIL-STEP 3
E. Removing NaN values
• Next, we are going to remove NaN values from the field.
• We can do this as follows:
• dfs = dfs[dfs['date'].notna()]
• Next, it is good to save the preprocessed file into a separate CSV file in case we need it again.
• We can save the data frame into a separate CSV file as follows:
• dfs.to_csv('gmail.csv')](https://image.slidesharecdn.com/dataanalyticsforiotsolutions-240918144006-52efadcb/75/Data_Analytics_for_IoT_Solutions-pptx-pdf-49-2048.jpg)

![EDA WITH PERSONAL EMAIL-STEP 5
• Data refactoring
1. First of all, import the regular
expression package:
import re
2. Next, let's create a function that takes
an entire string from any column and
extracts an email address:
def extract_email_ID(string):
email = re.findall(r'<(.+?)>', string)
if not email:
email = list(filter(lambda y: '@' in y,
string.split()))
return email[0] if email else np.nan
3. Next, let's apply the function to the from column:
dfs['from'] = dfs['from'].apply(lambda x: extract_email_ID(x))
4. Next, we are going to refactor the label field. The logic is
simple. If an email is from your email address, then it is the sent
email. Otherwise, it is a received email, that is, an inbox email:
myemail = 'itsmeskm99@gmail.com'
dfs['label'] = dfs['from'].apply(lambda x: 'sent' if x==myemail
else 'inbox')](https://image.slidesharecdn.com/dataanalyticsforiotsolutions-240918144006-52efadcb/75/Data_Analytics_for_IoT_Solutions-pptx-pdf-51-2048.jpg)