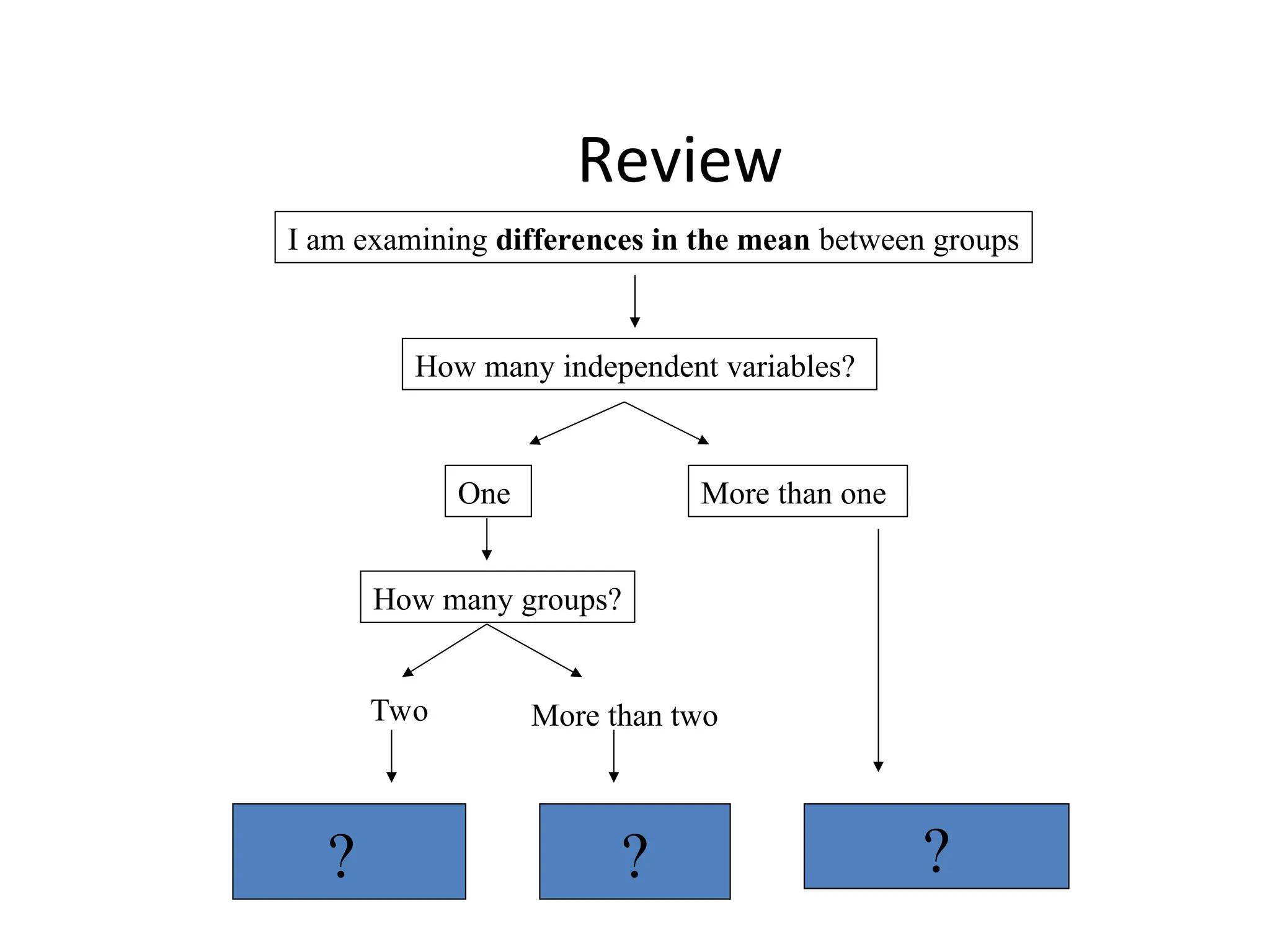
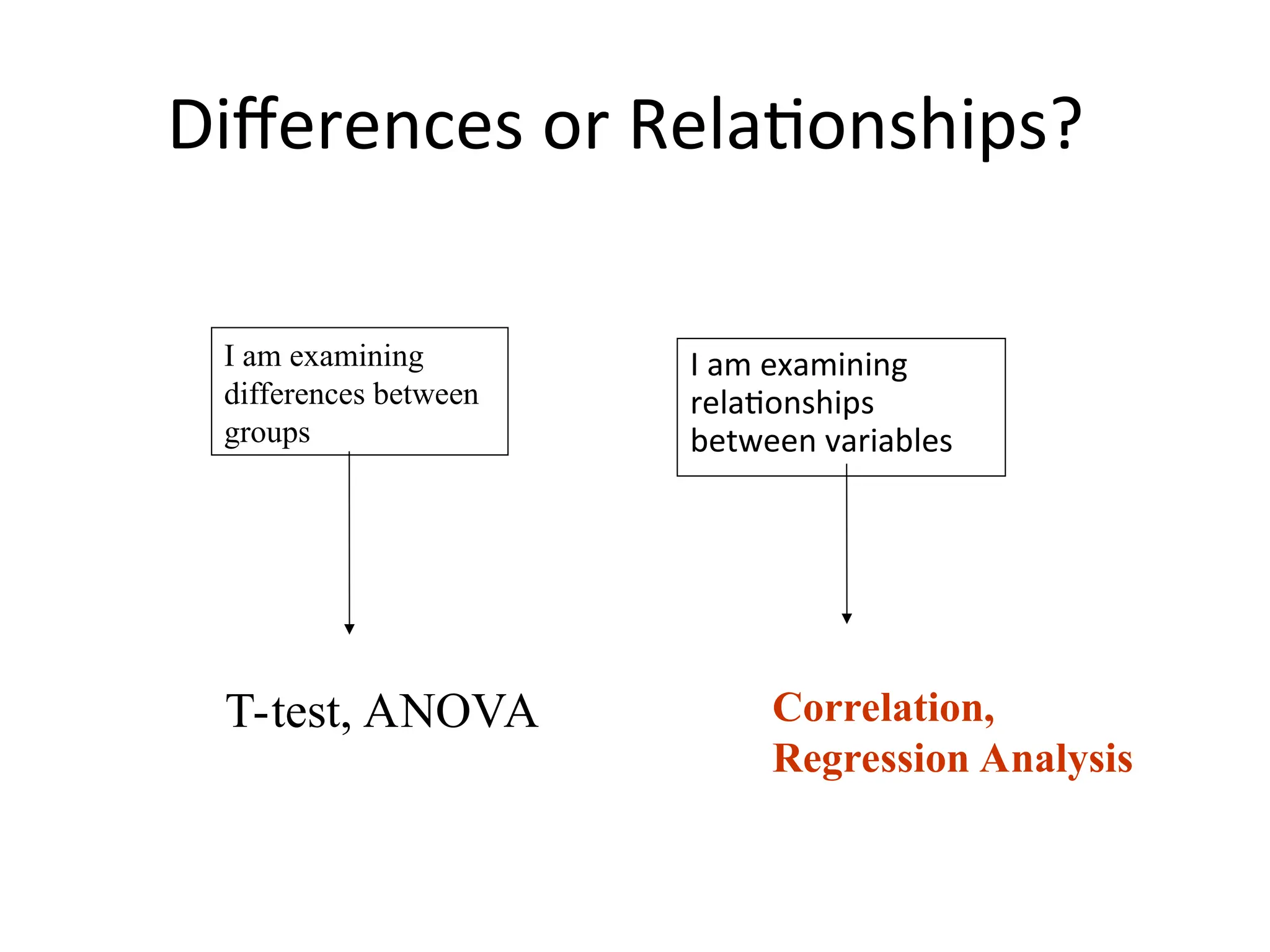
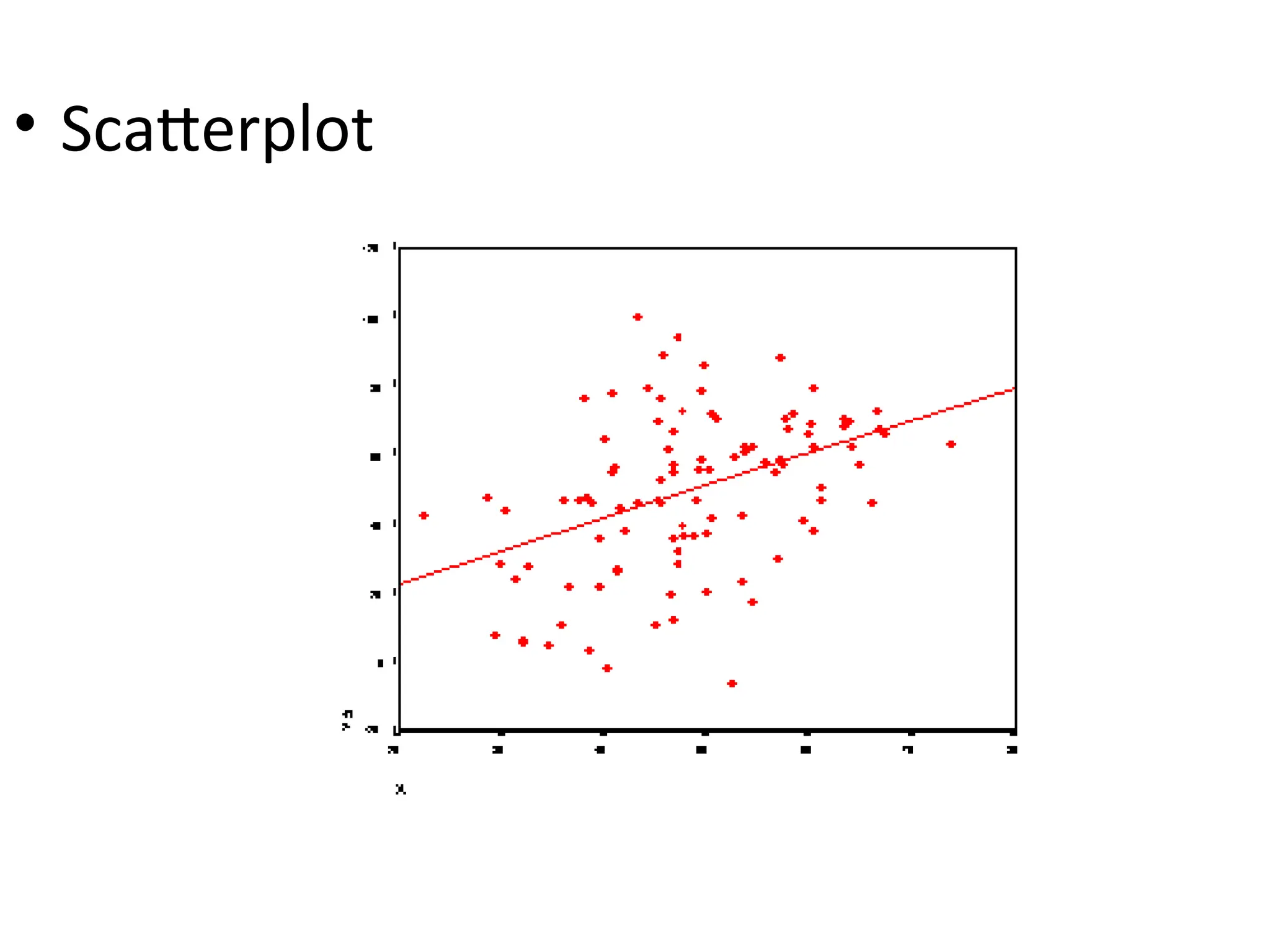
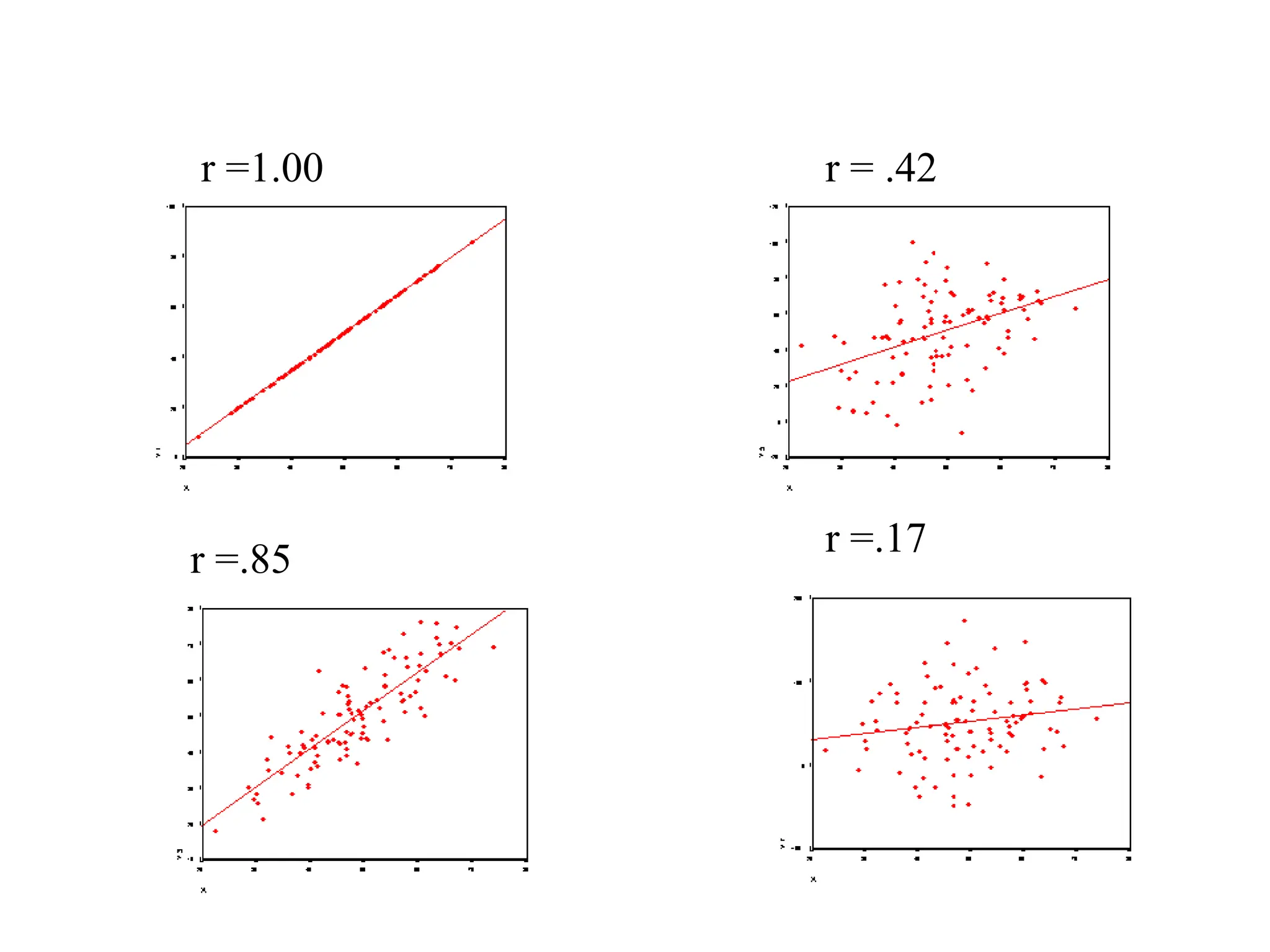
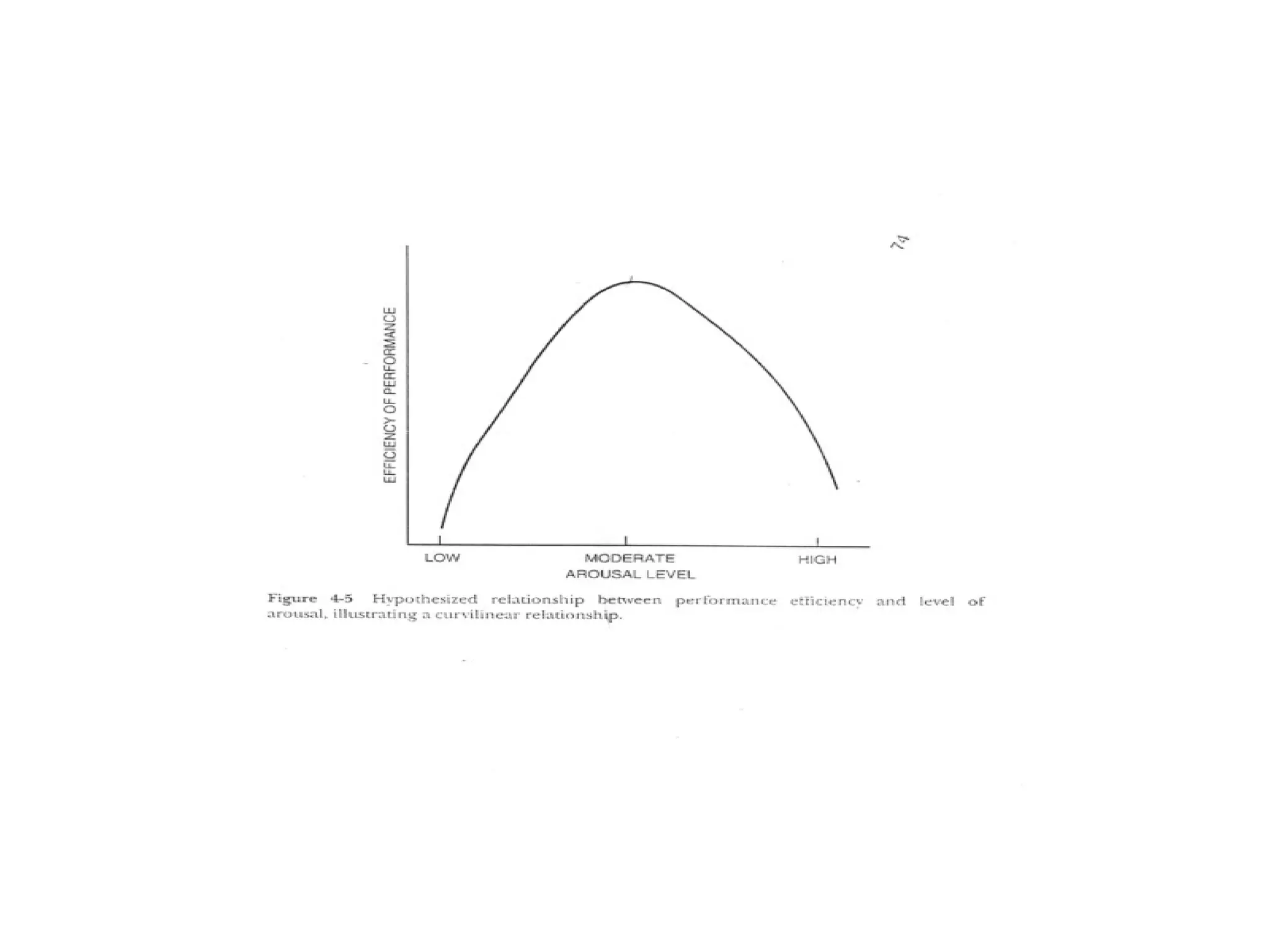
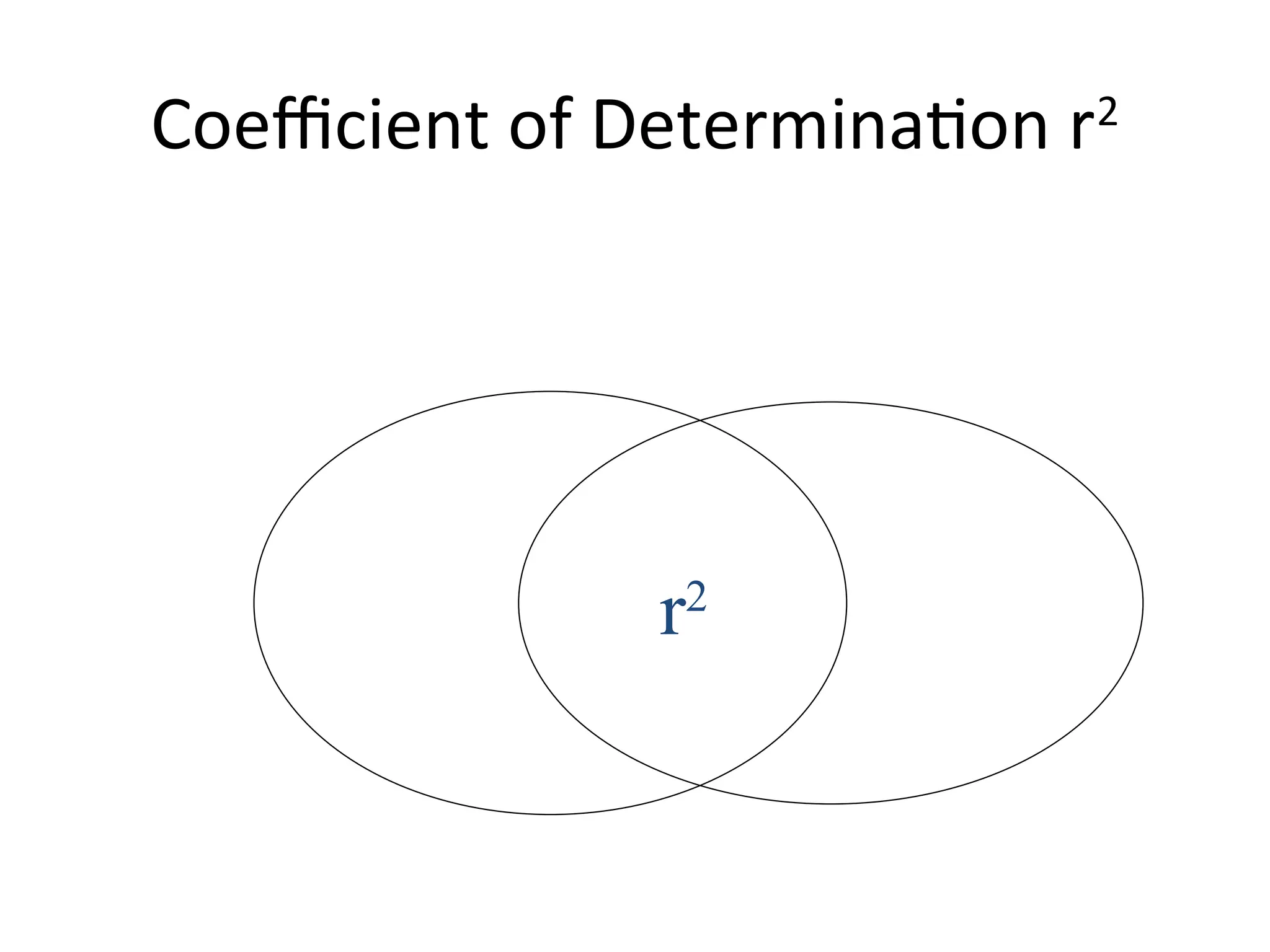
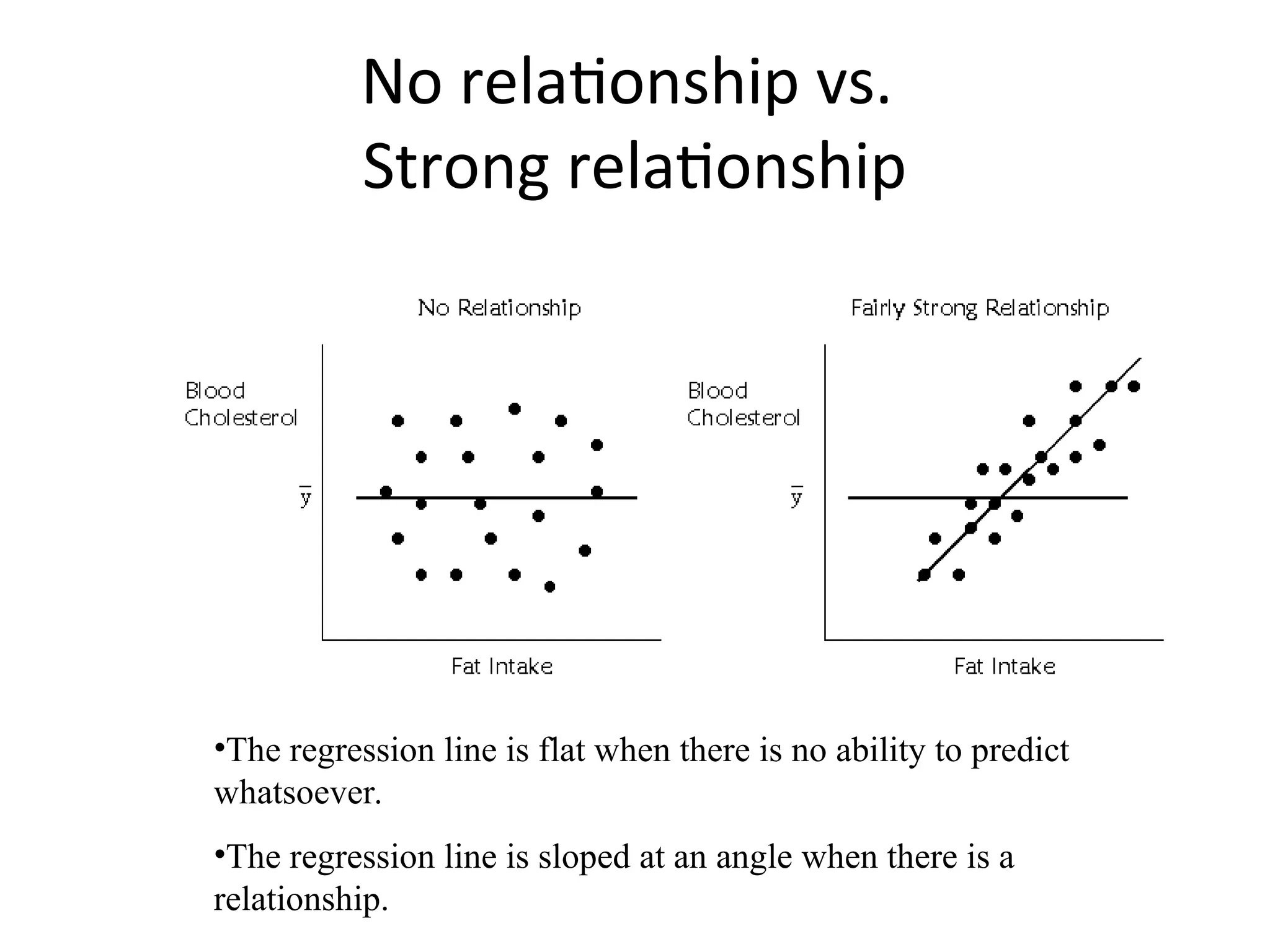
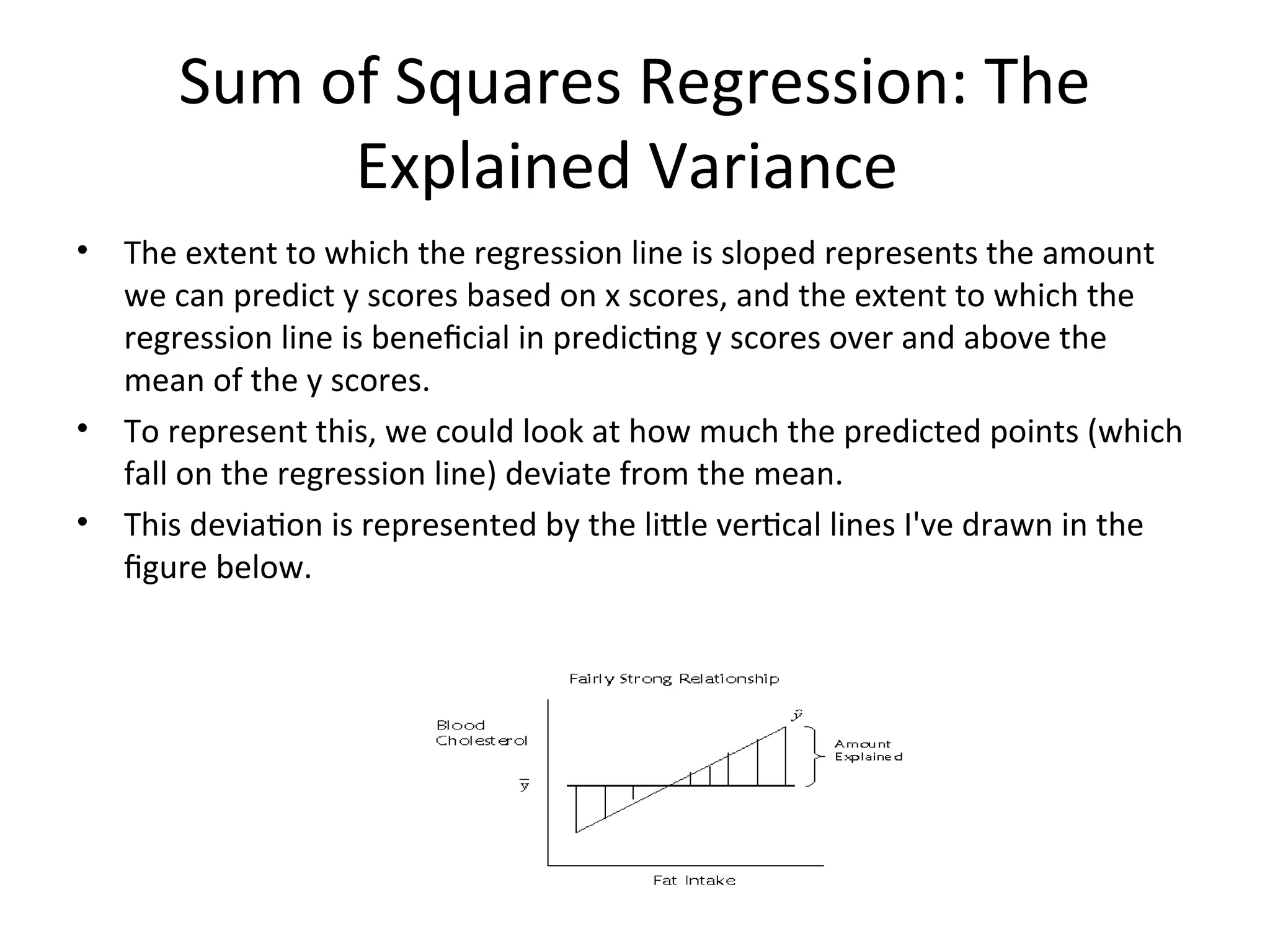
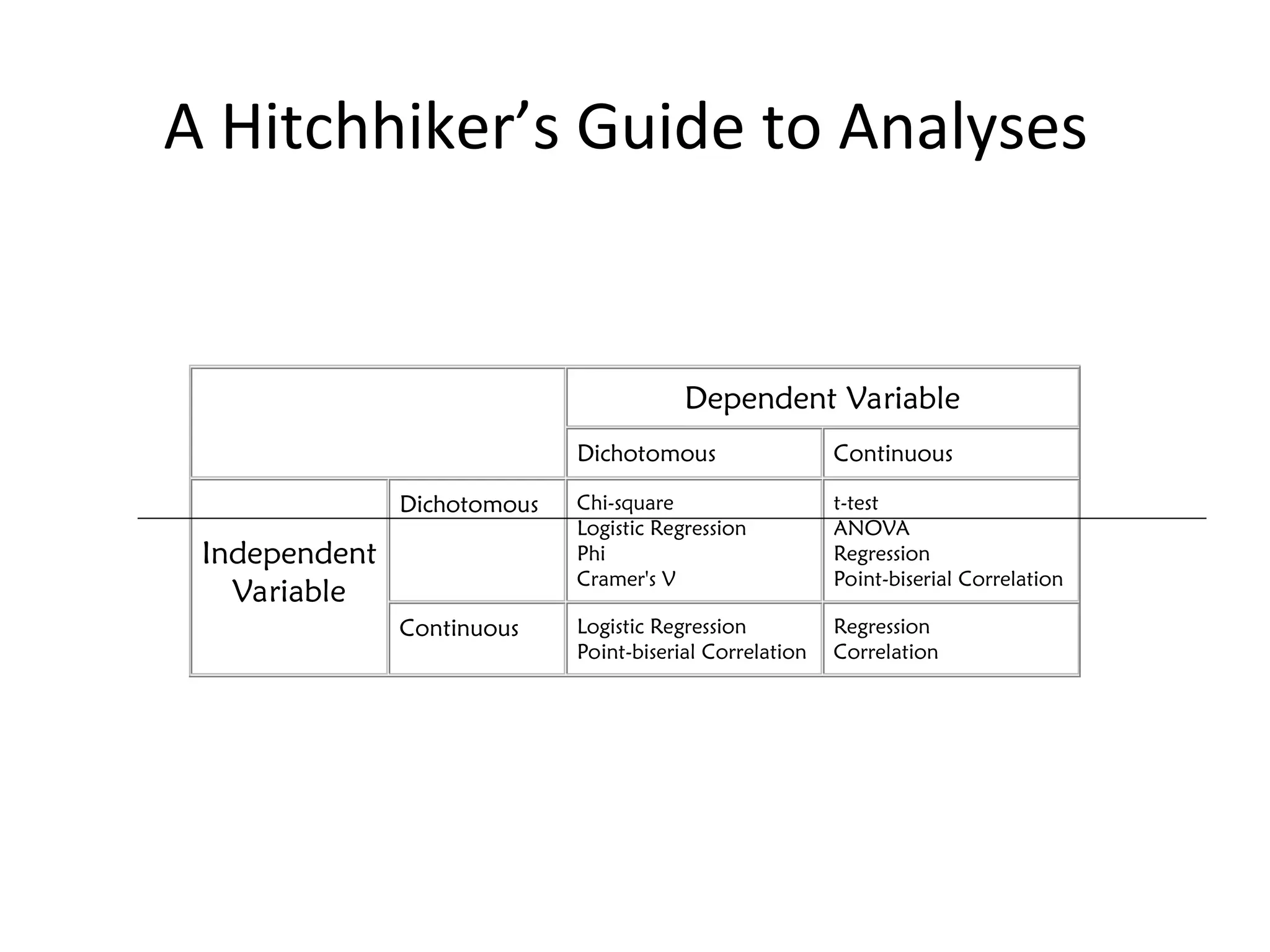
The document discusses statistical analyses focusing on relationships and differences between variables using methods like correlation and regression analysis. It explains the correlation coefficient and its interpretation, including the importance of understanding linearity, outliers, and causation. Additionally, it details regression analysis techniques and their applications, interrelating dependent and independent variables in prediction.