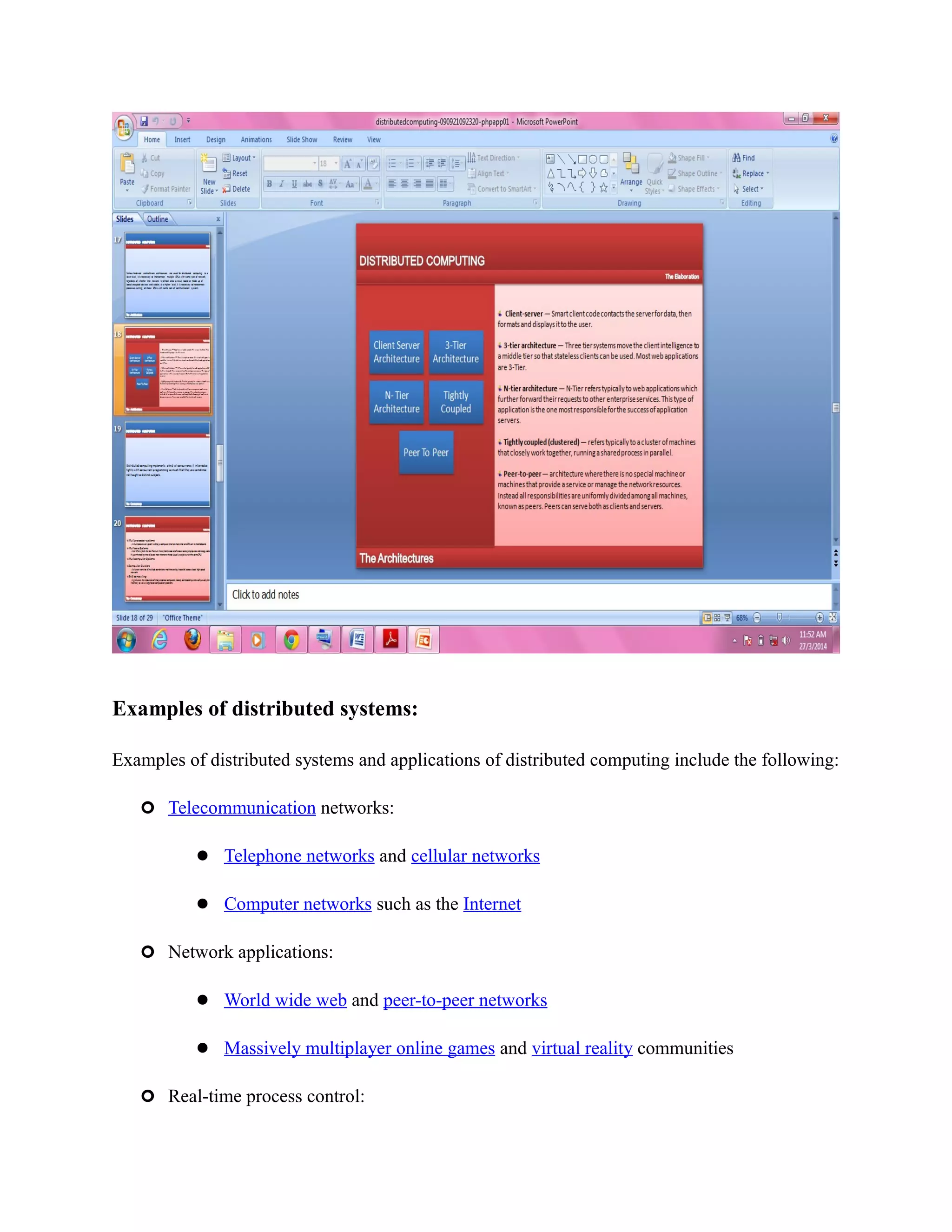
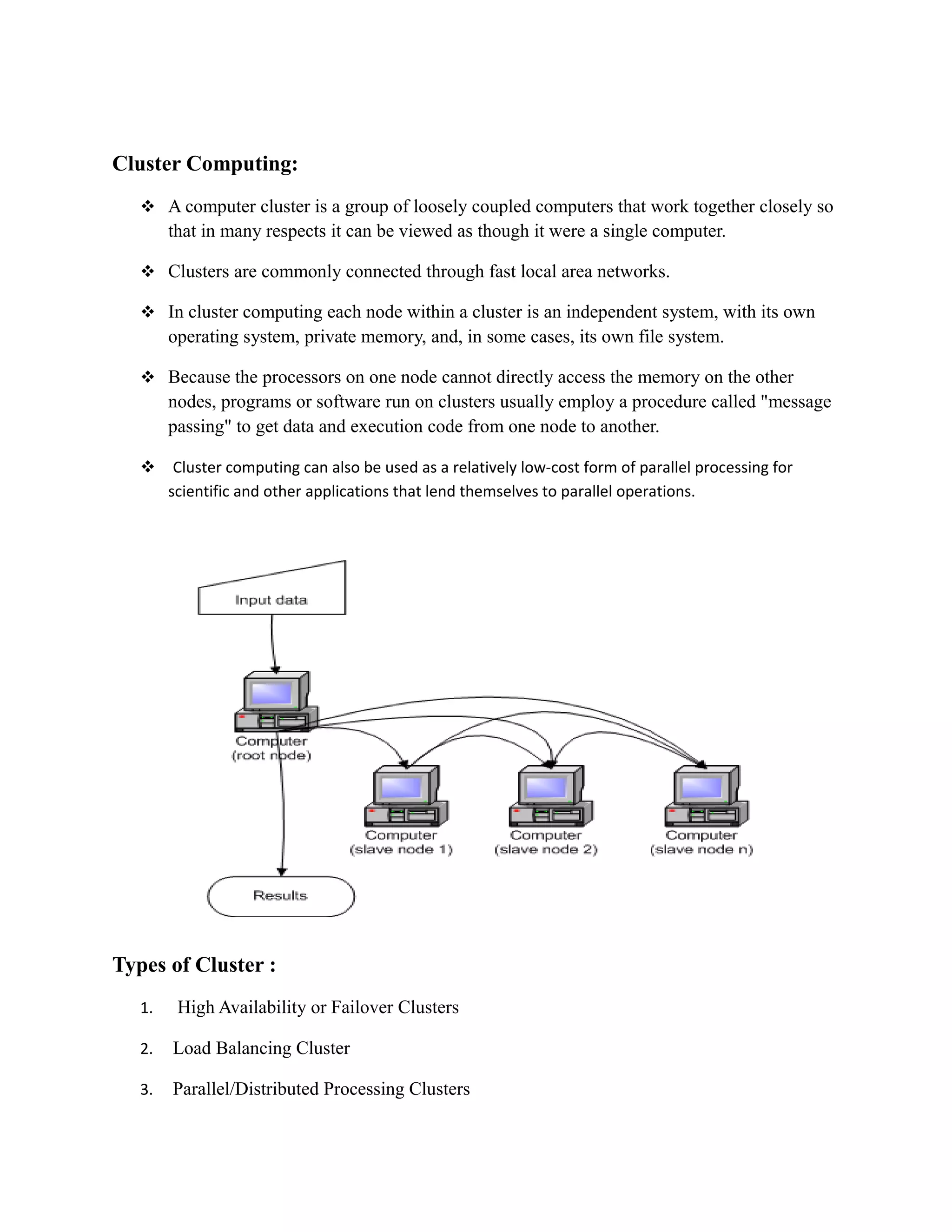
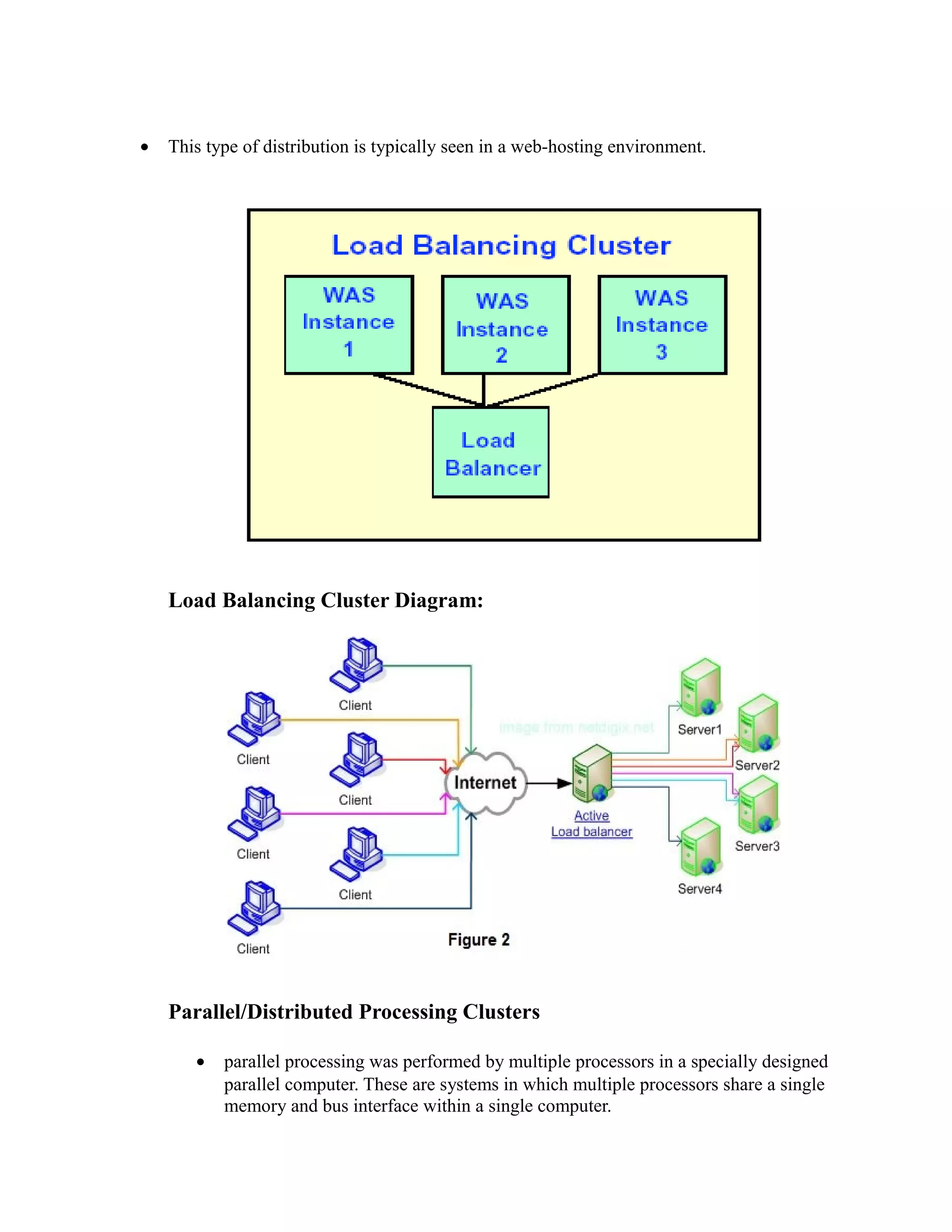
This document provides an overview of distributed computing. It discusses key concepts like distributed systems having computers with separate memories that communicate over a network. Distributed computing involves splitting a program into parts that run simultaneously on multiple computers. The document also covers the history of distributed computing, examples like grid and cloud computing, motivations like performance and fault tolerance, and challenges around complexity and security.