Downloaded 34 times











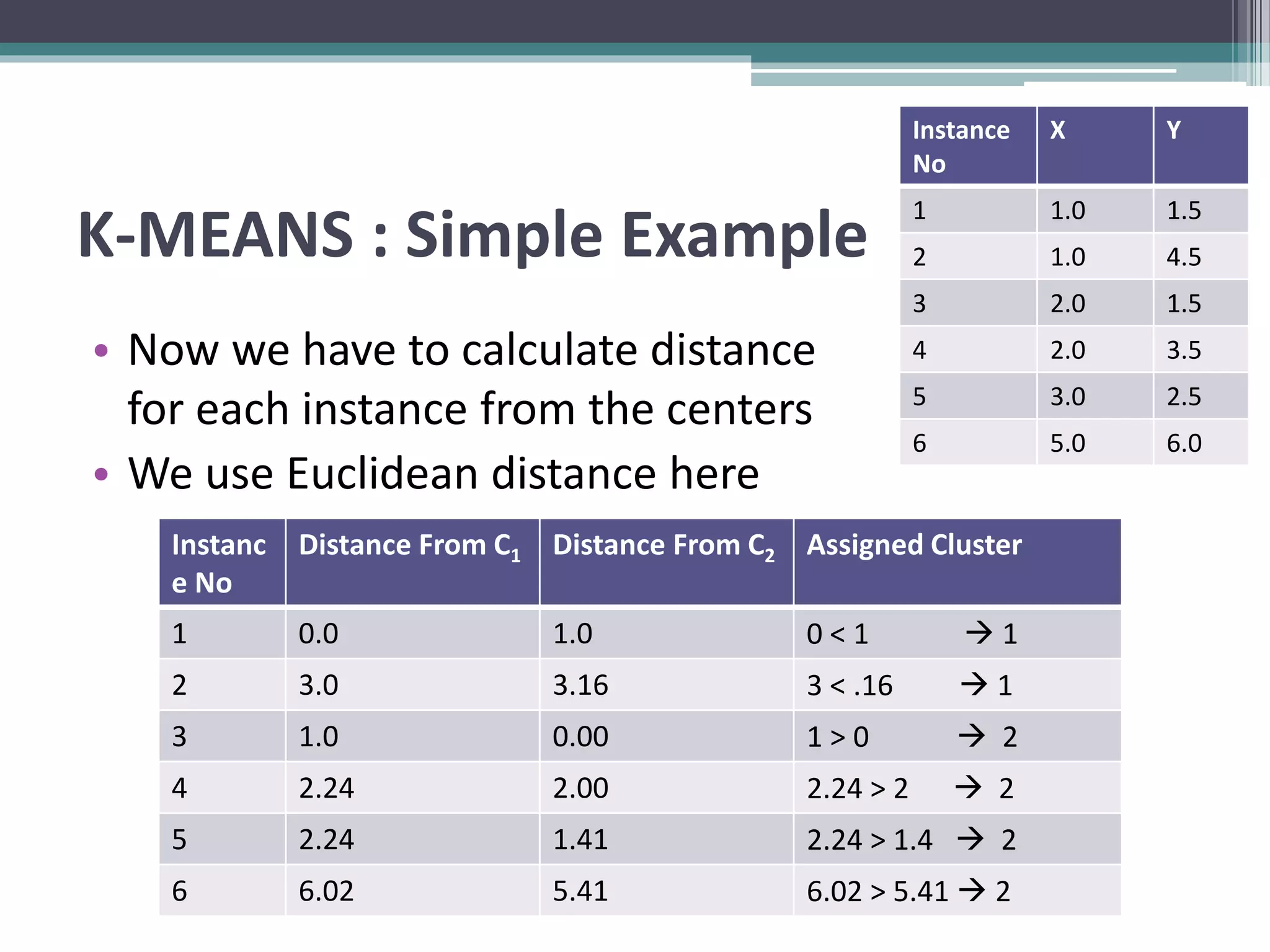

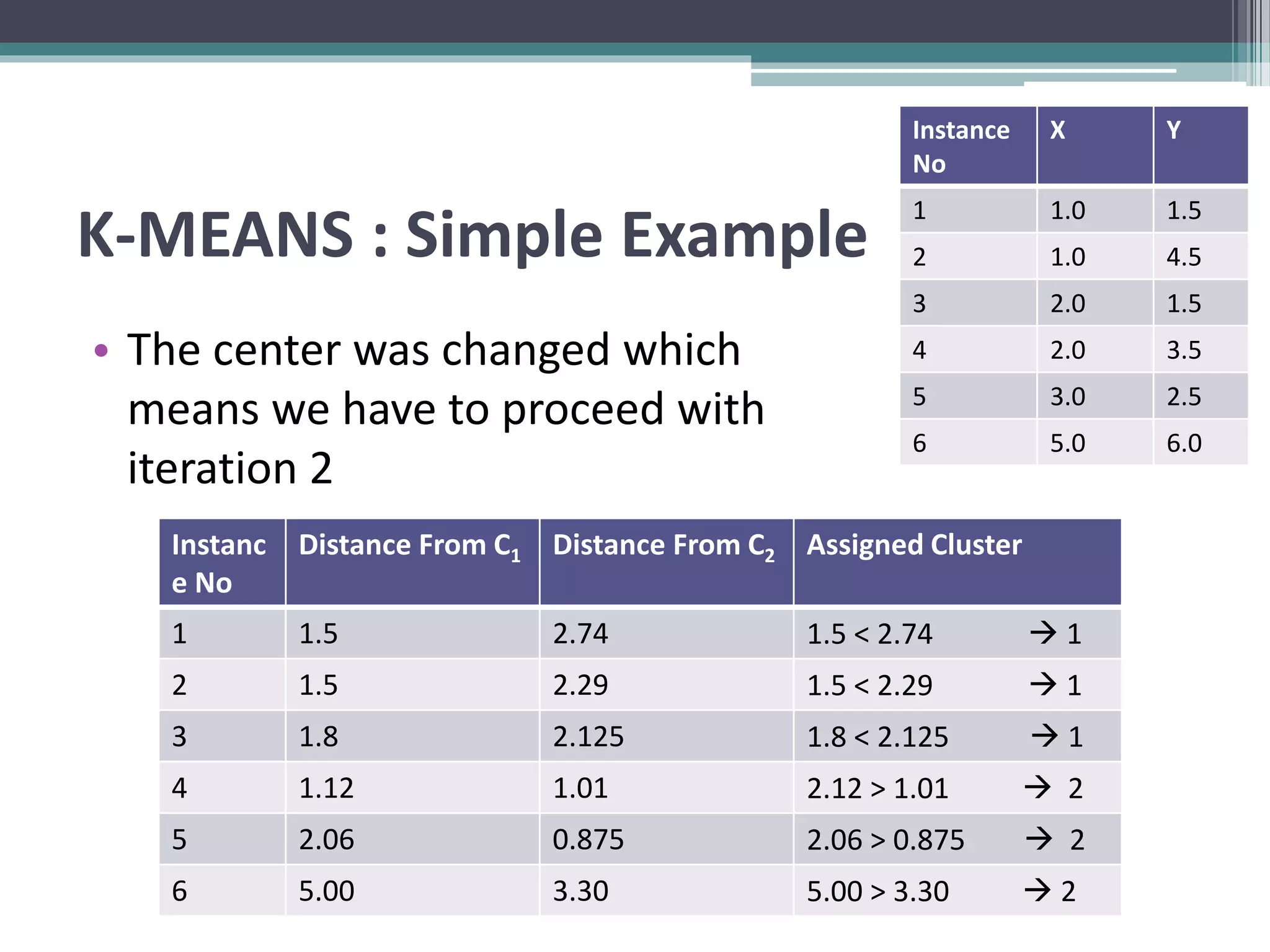



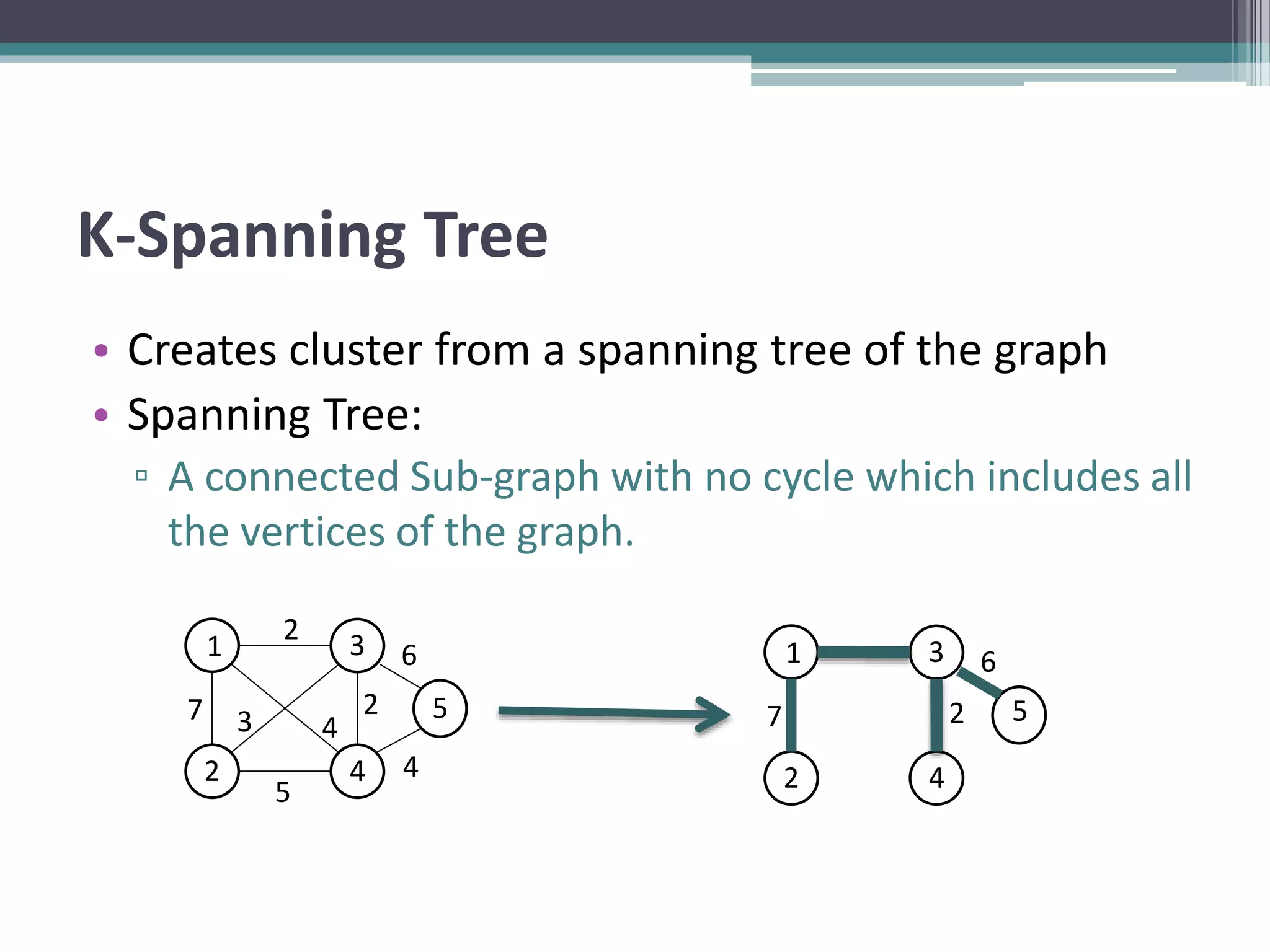
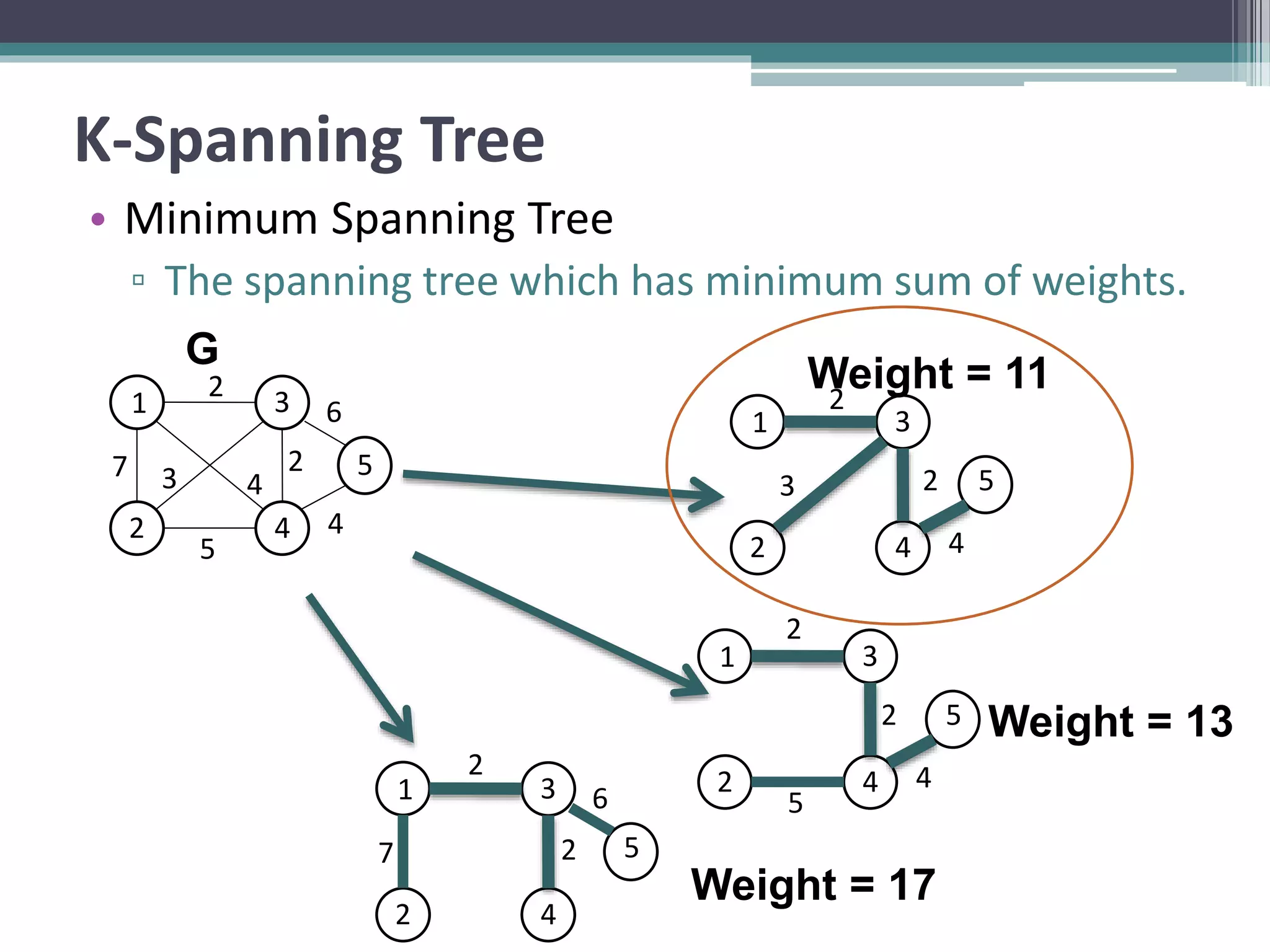

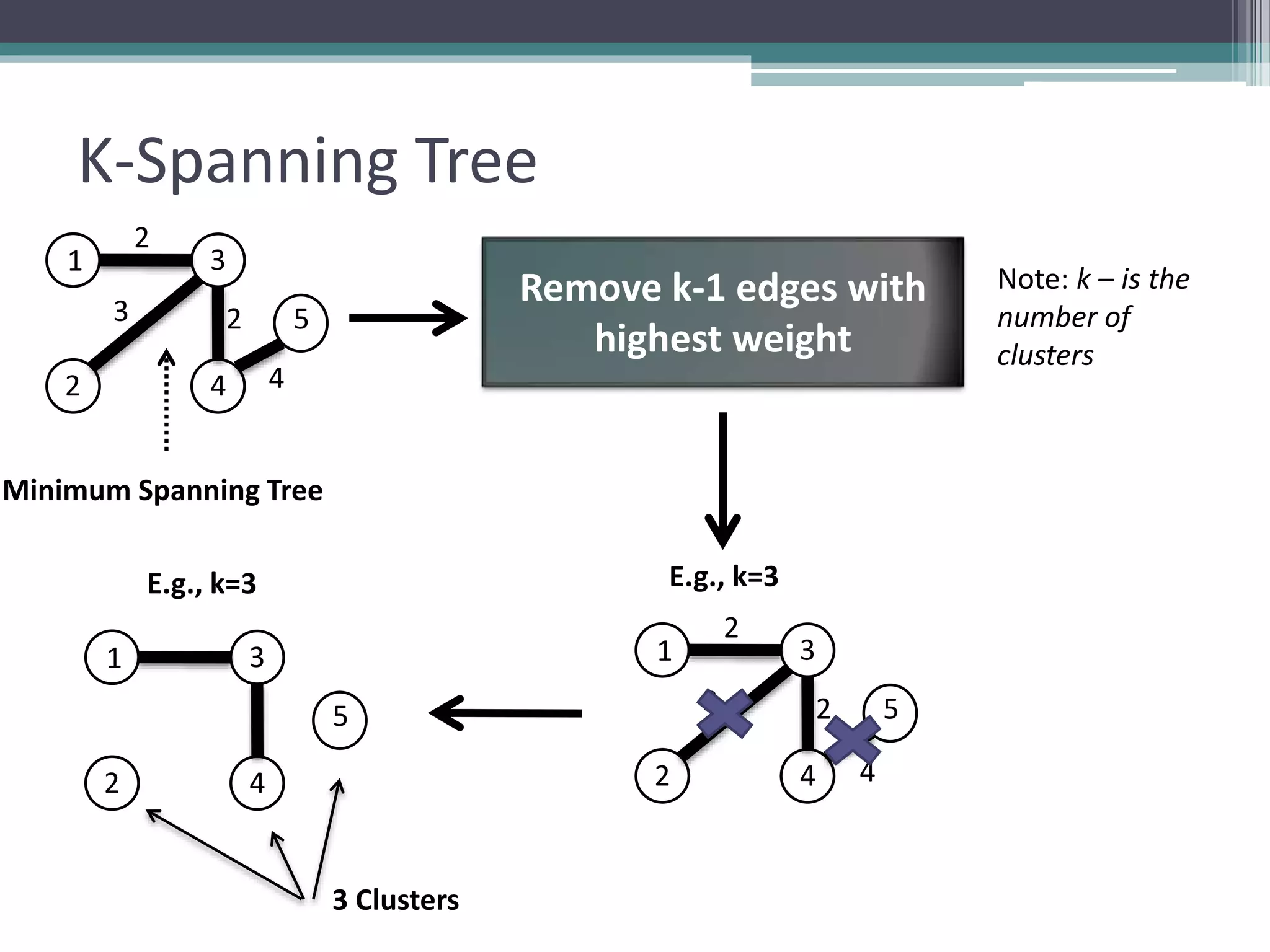
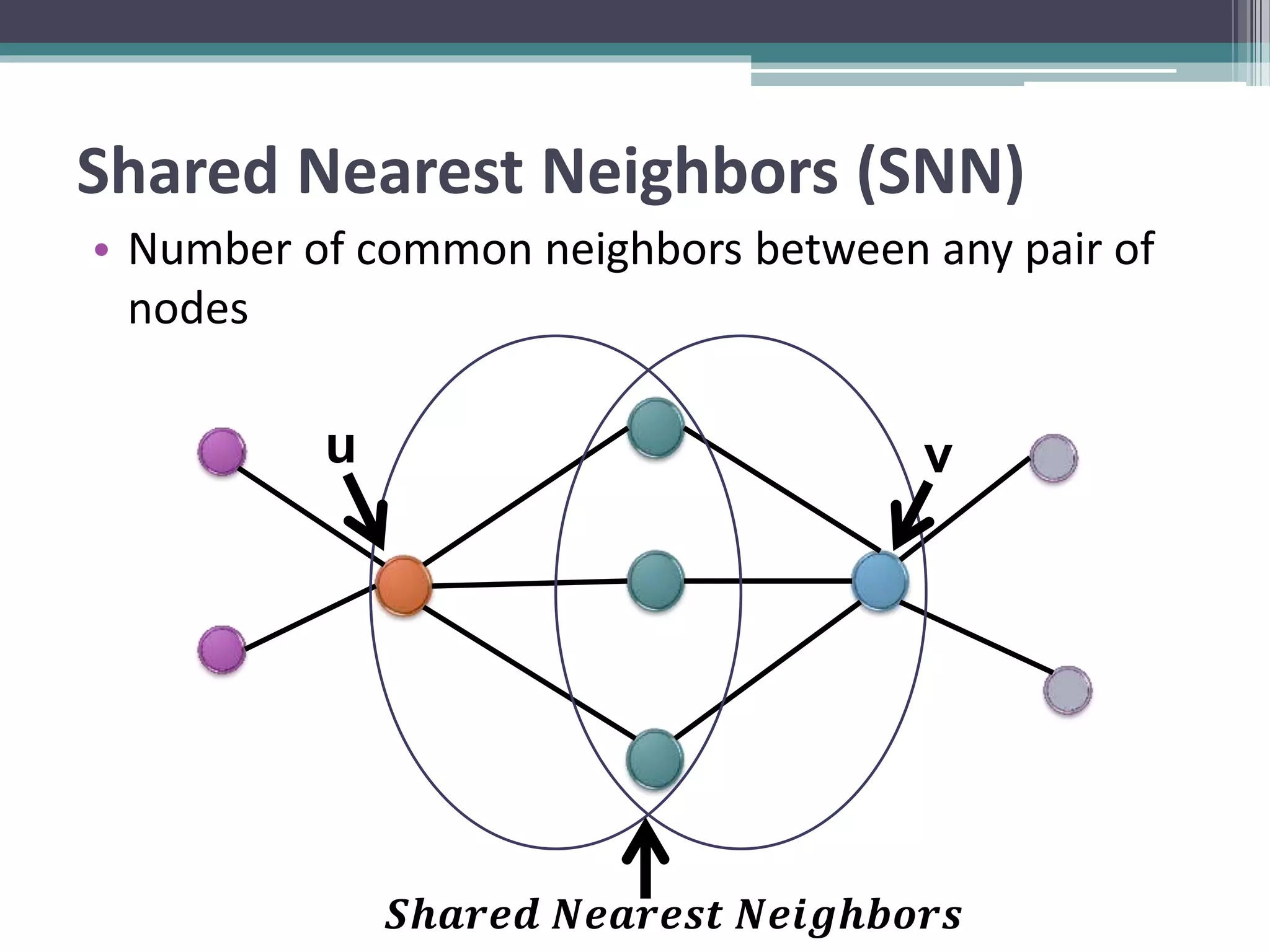
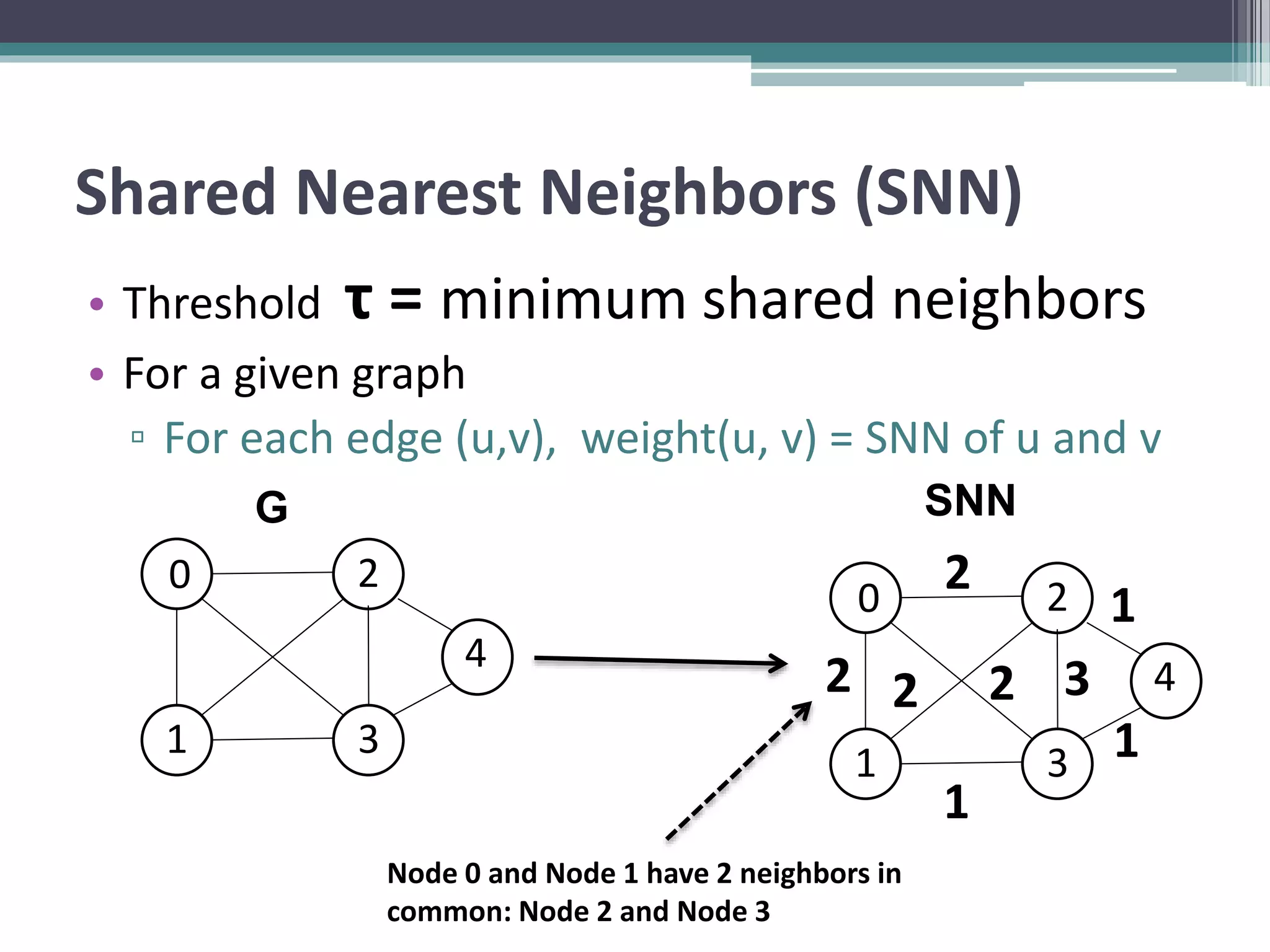
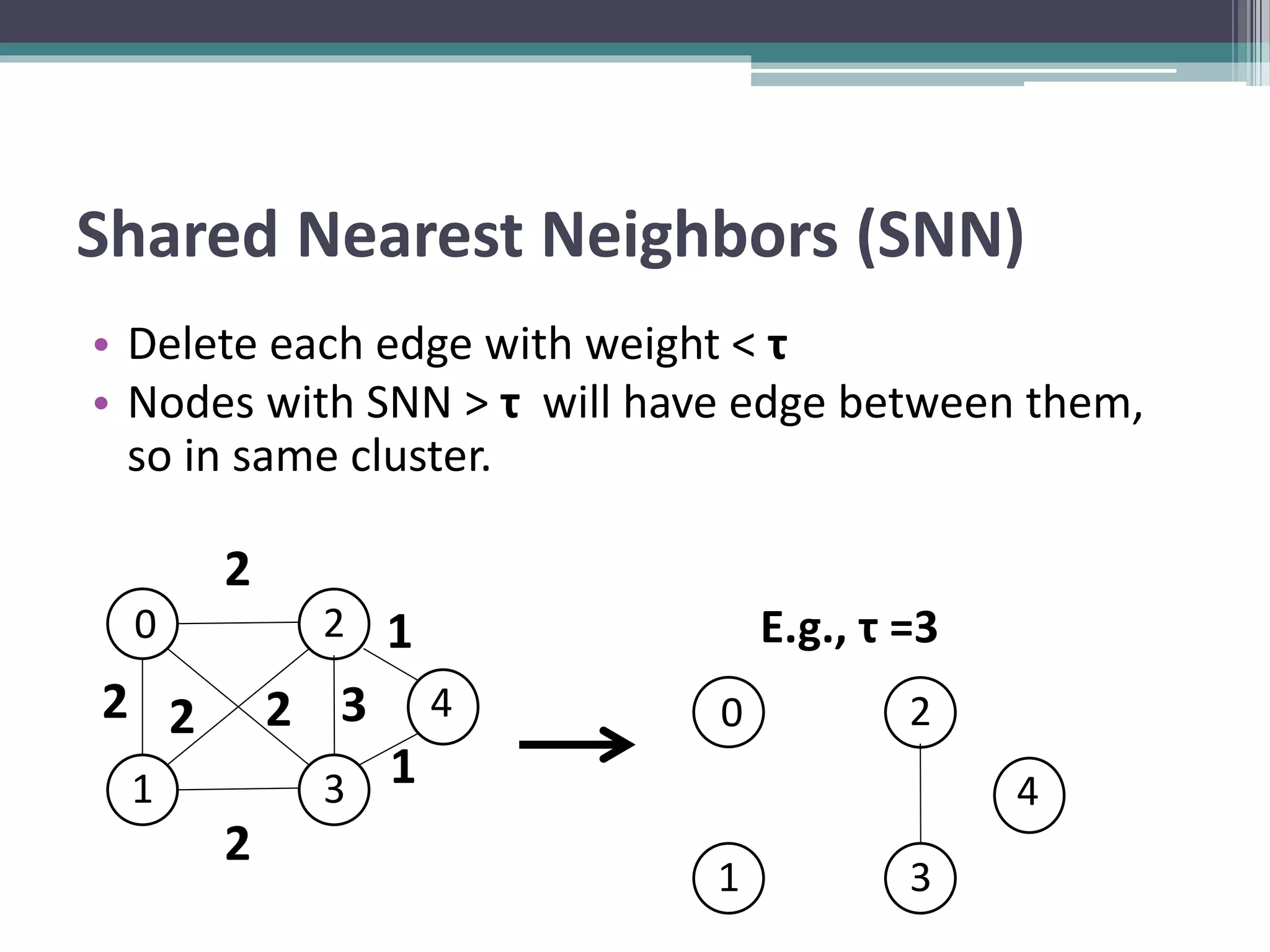

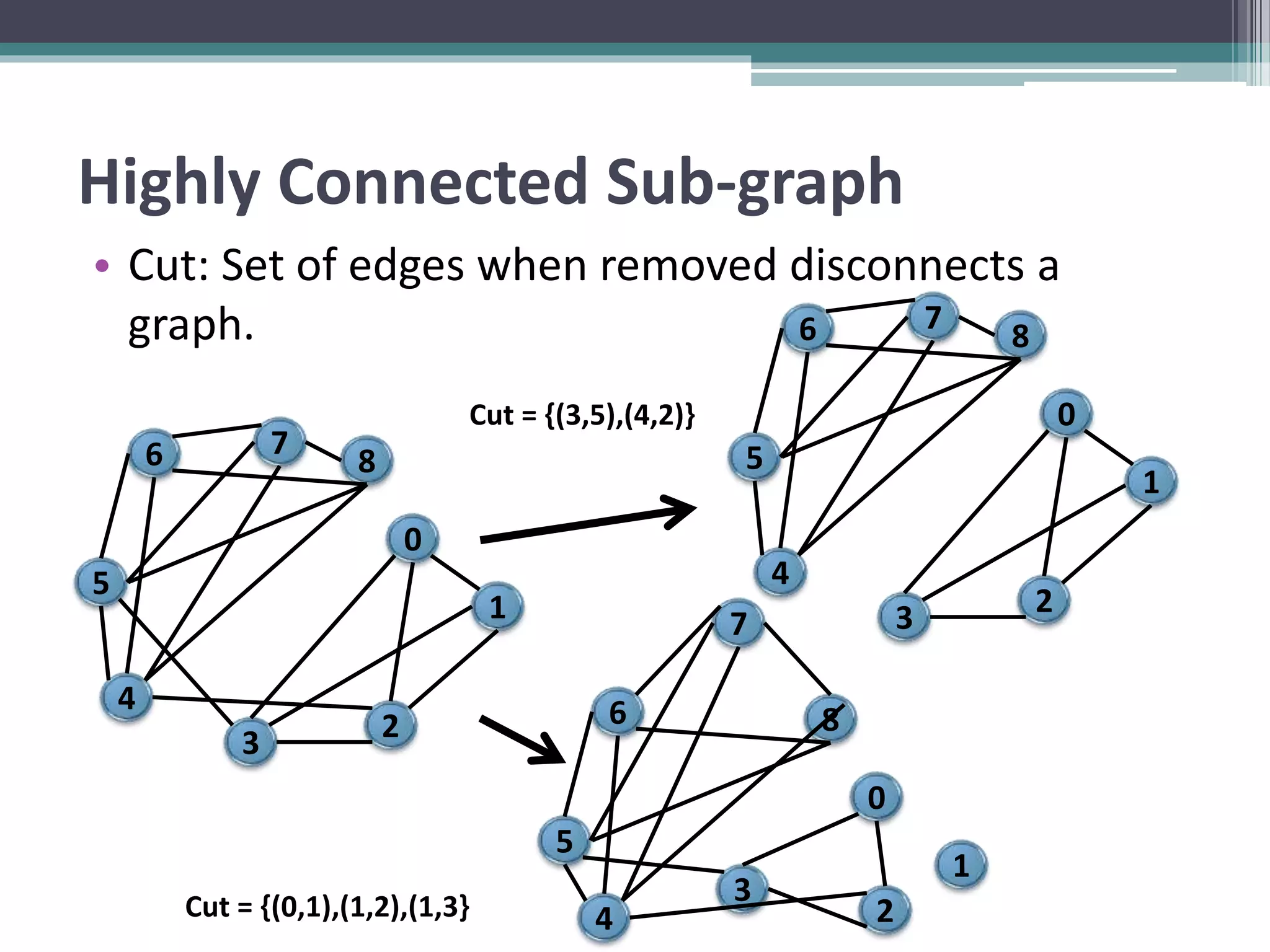

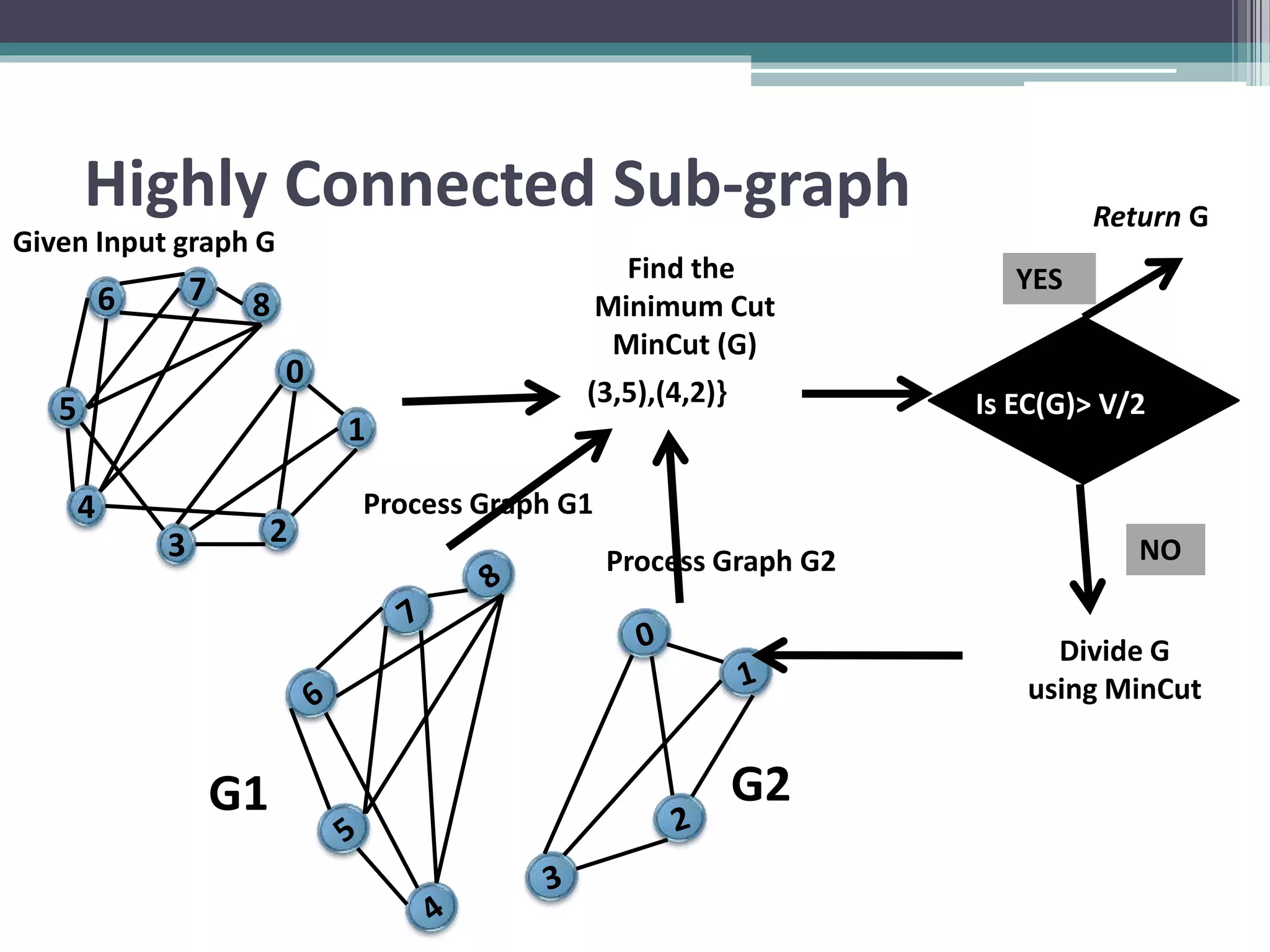


Clustering is an unsupervised machine learning technique used to group similar data points together. There are several common clustering algorithms such as K-means, hierarchical clustering, and density-based clustering. K-means clustering works by assigning data points to clusters based on their distance from initial cluster centers, then recalculating the cluster centers until cluster membership stabilizes. Graph clustering algorithms include approaches based on minimum spanning trees, shared nearest neighbors, and detecting highly connected subgraphs.










































![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)






















