CoSc 6211 JJU4
k-Nearest Neighbor
• KNN is a simple algorithm that stores all
available cases and classifies new cases based
on a similarity measure
• Lazy learning algorithm
• Non-parametric learning algorithm
– because it doesn’t assume anything about the
underlying data.
5.
CoSc 6211 JJU5
KNN-classification
• Lazy approach to classification
• Uses all the training set to perform
classification
• Uses distances between training and test
records
6.
CoSc 6211 JJU6
KNN example
• The test sample (green circle)
should be classified either to
the first class of blue squares
or to the second class of red
triangles.
If k = 3 it is assigned to the
second class because there
are 2 triangles and only 1
square inside the inner circle.
If k = 5 it is assigned to the
first class (3 squares vs. 2
triangles inside the outer
circle).
?
7.
CoSc 6211 JJU7
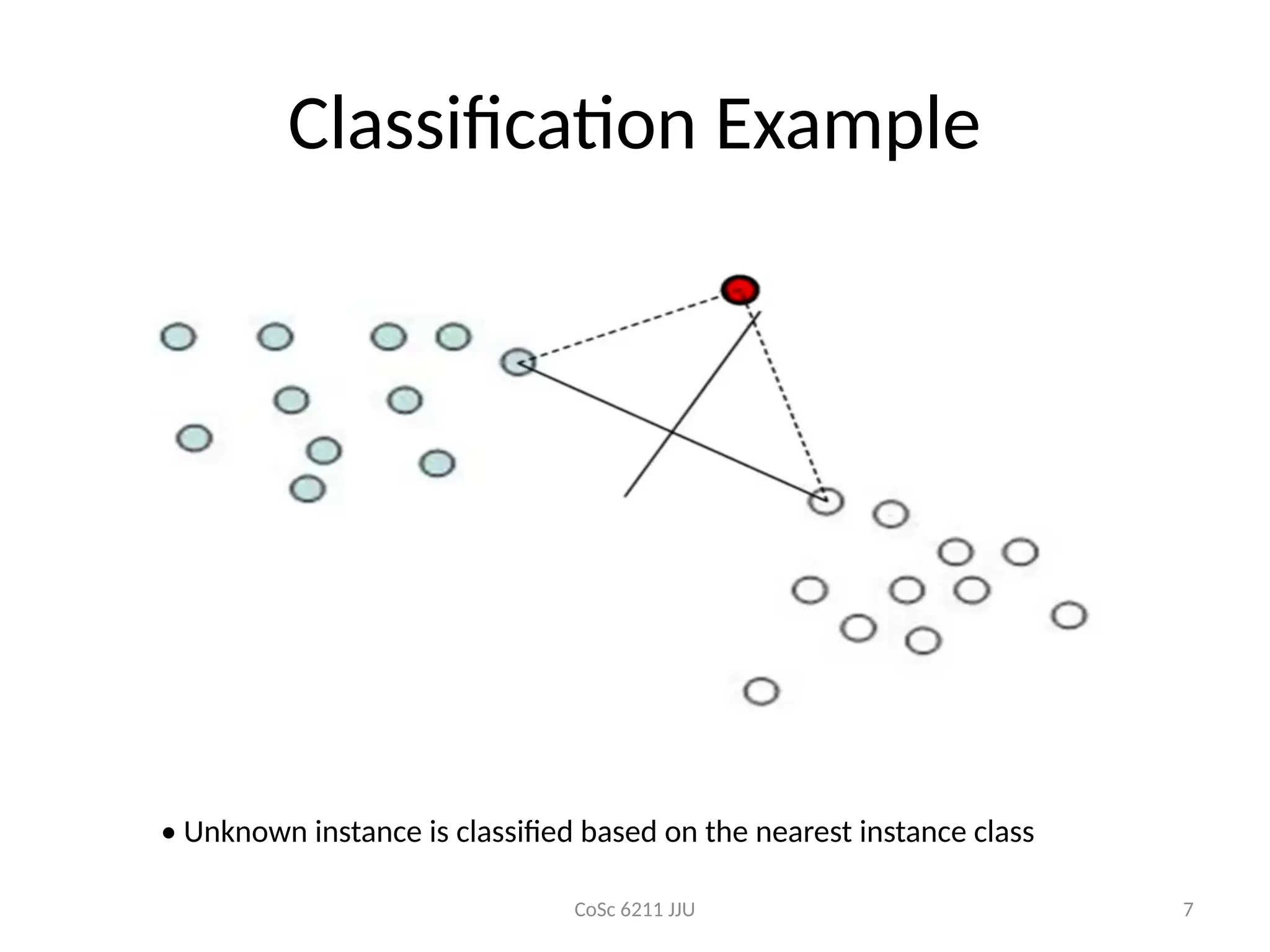
Classification Example
• Unknown instance is classified based on the nearest instance class
8.
CoSc 6211 JJU8
Similarity Measure
• Euclidian distance (sum of squared errors)
• Manhattan distance (sum of absolute errors)
dcityblock(x, y) = i | xi yi |
where x = x1, x2, . . . , xm, and y = y1, y2, . . . , ym represent
the m attribute values of two records.
9.
CoSc 6211 JJU9
KNN
• Scaling issues
– Attributes may have to be scaled to prevent
distance measures from being dominated by one
of the attributes
– Example:
• height of a person may vary from 1.5m to 1.8m
• weight of a person may vary from 90lb to 300lb
• income of a person may vary from $10K to $1M
10.
CoSc 6211 JJU10
Scaling…
• Attribute normalization if scales are different
• For continuous variables, the min–max normalization or Z-score
standardization, may be used:
• Min–max normalization:
X∗
= X − min(X) / Range(X)
= X − min(X) / max(X) − min(X)
• Z-score standardization:
X∗
= X − mean(X) / SD(X)
For categorical variables,
different(xi ,yi ) = 0 if xi = yi , 1 otherwise
Example: x=male and y=female then distance(x, y)=1
11.
CoSc 6211 JJU11
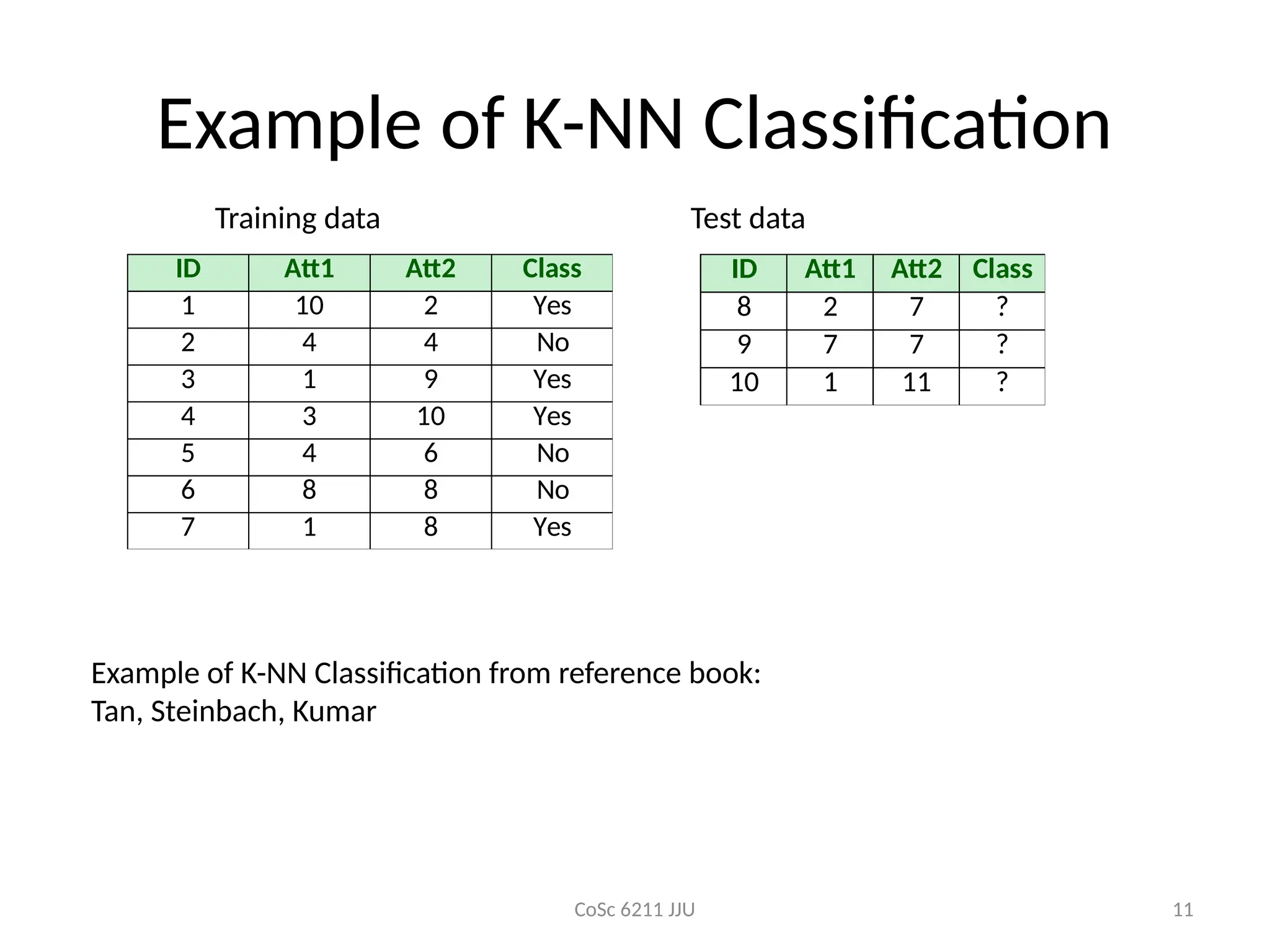
Example of K-NN Classification
ID Att1 Att2 Class
1 10 2 Yes
2 4 4 No
3 1 9 Yes
4 3 10 Yes
5 4 6 No
6 8 8 No
7 1 8 Yes
ID Att1 Att2 Class
8 2 7 ?
9 7 7 ?
10 1 11 ?
Training data Test data
Example of K-NN Classification from reference book:
Tan, Steinbach, Kumar
12.
12
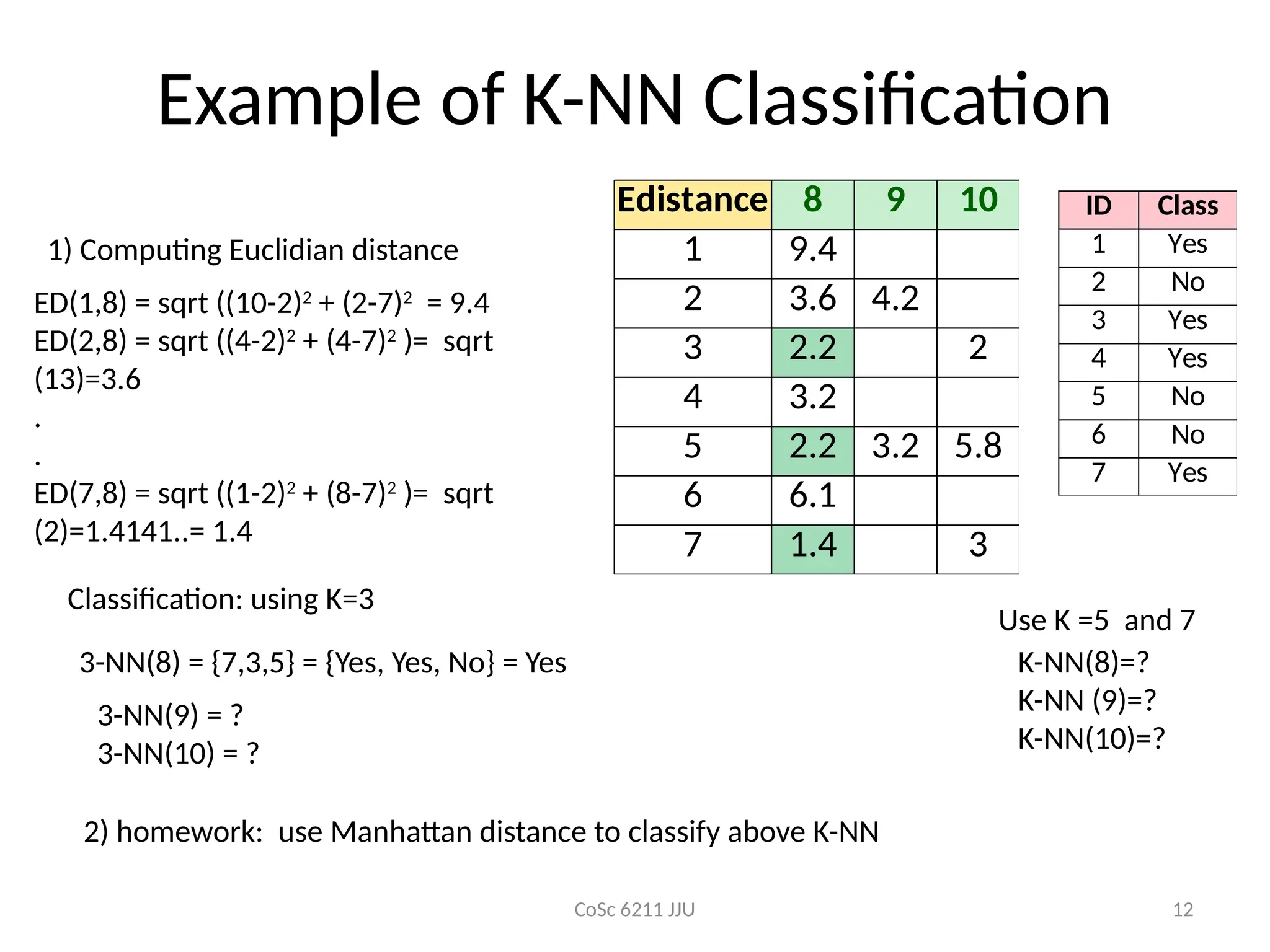
Example of K-NNClassification
Edistance 8 9 10
1 9.4 5.8 13
2 3.6 4.2 7.6
3 2.2 6.3 2
4 3.2 5 2.2
5 2.2 3.2 5.8
6 6.1 1.4 7.6
7 1.4 6.1 3
ID Class
1 Yes
2 No
3 Yes
4 Yes
5 No
6 No
7 Yes
CoSc 6211 JJU
ED(1,8) = sqrt ((10-2)2
+ (2-7)2
= 9.4
ED(2,8) = sqrt ((4-2)2
+ (4-7)2
)= sqrt
(13)=3.6
.
.
ED(7,8) = sqrt ((1-2)2
+ (8-7)2
)= sqrt
(2)=1.4141..= 1.4
1) Computing Euclidian distance
3-NN(8) = {7,3,5} = {Yes, Yes, No} = Yes
3-NN(9) = ?
3-NN(10) = ?
Classification: using K=3
K-NN(8)=?
K-NN (9)=?
K-NN(10)=?
Use K =5 and 7
2) homework: use Manhattan distance to classify above K-NN
13.
CoSc 6211 JJU13
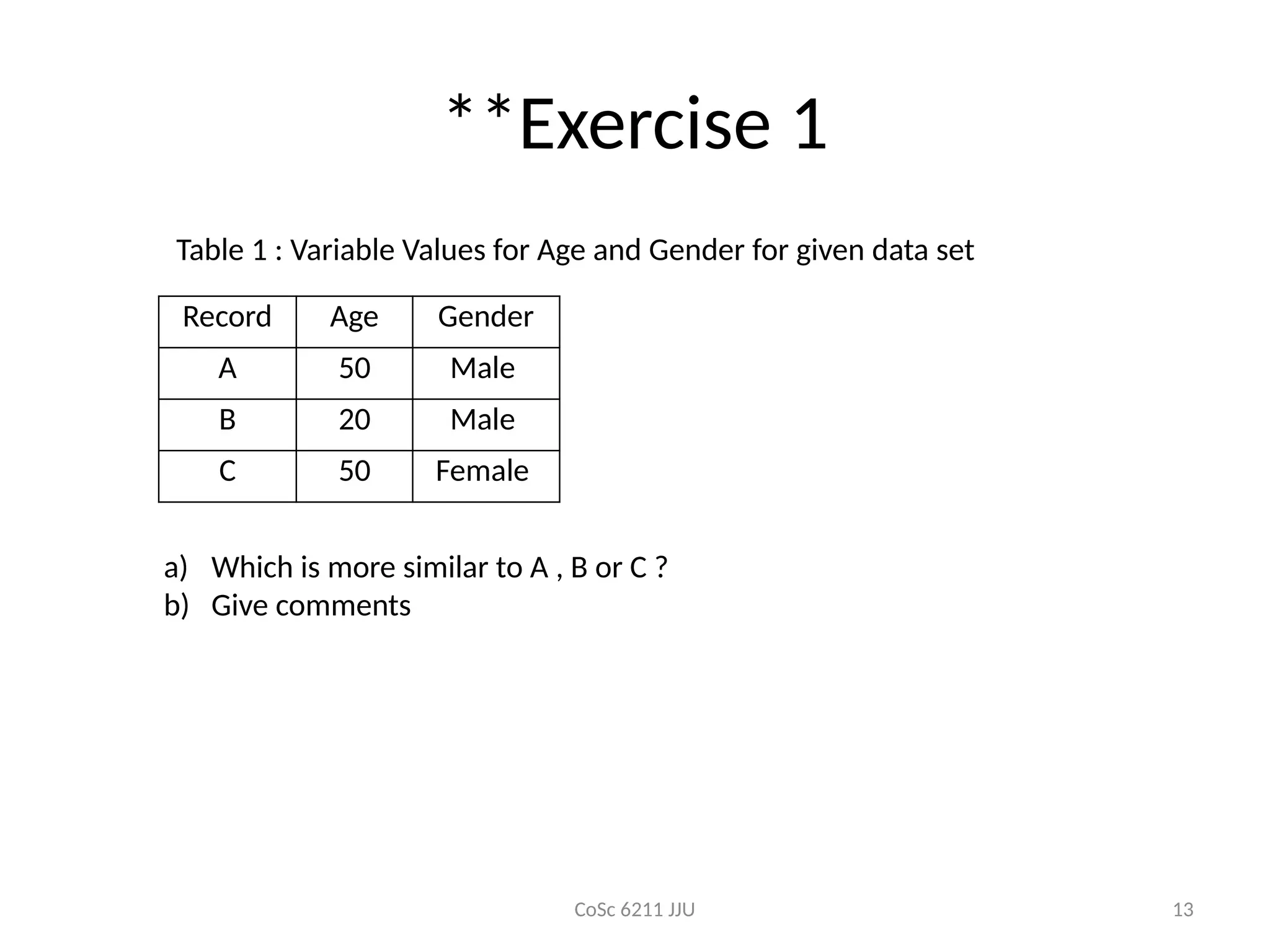
**Exercise 1
Record Age Gender
A 50 Male
B 20 Male
C 50 Female
a) Which is more similar to A , B or C ?
b) Give comments
Table 1 : Variable Values for Age and Gender for given data set
14.
CoSc 6211 JJU14
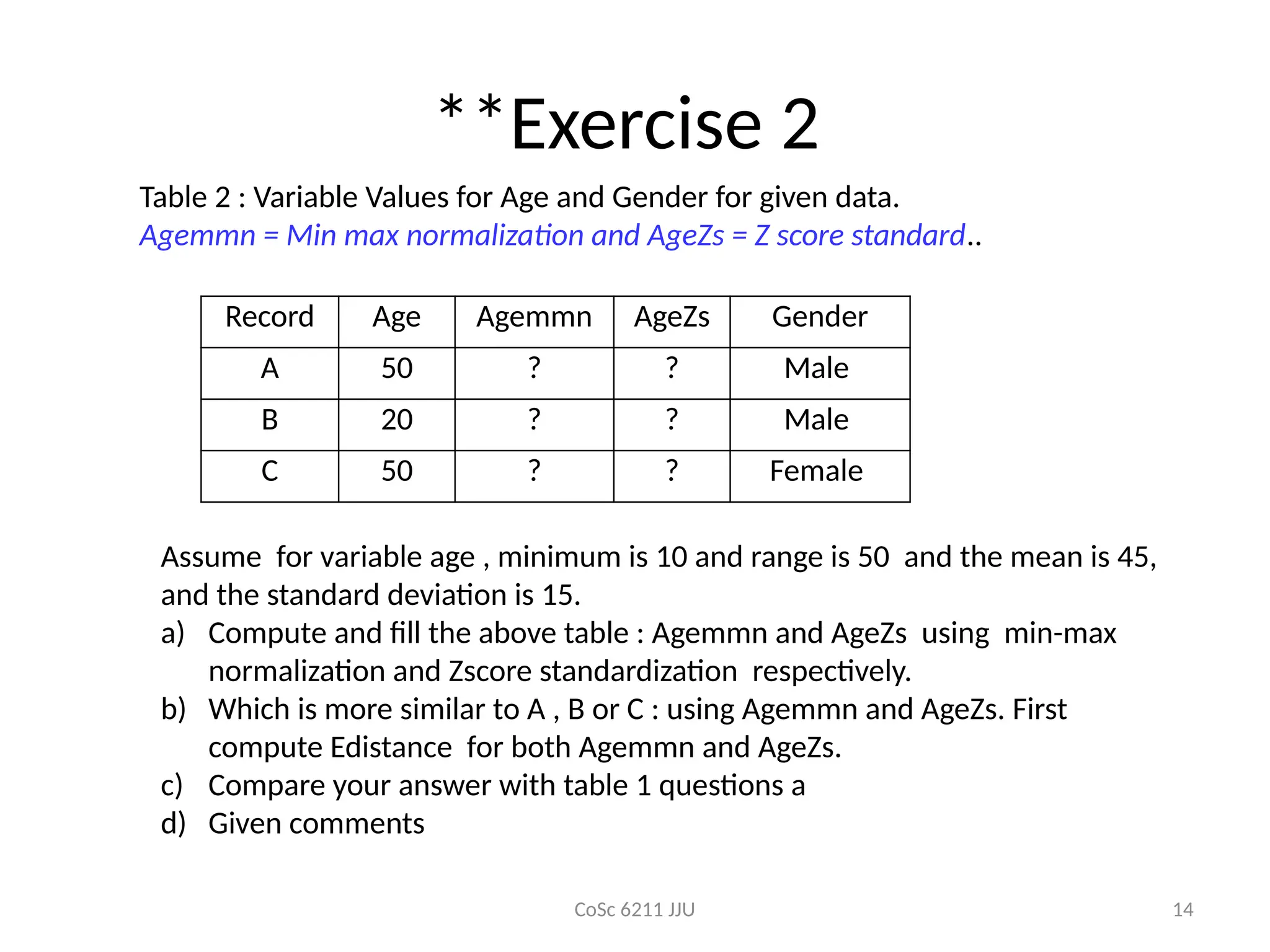
**Exercise 2
Record Age Agemmn AgeZs Gender
A 50 ? ? Male
B 20 ? ? Male
C 50 ? ? Female
Table 2 : Variable Values for Age and Gender for given data.
Agemmn = Min max normalization and AgeZs = Z score standard..
Assume for variable age , minimum is 10 and range is 50 and the mean is 45,
and the standard deviation is 15.
a) Compute and fill the above table : Agemmn and AgeZs using min-max
normalization and Zscore standardization respectively.
b) Which is more similar to A , B or C : using Agemmn and AgeZs. First
compute Edistance for both Agemmn and AgeZs.
c) Compare your answer with table 1 questions a
d) Given comments
CoSc 6211 JJU16
Rule-based classifier
Based on reference book
(Tan, Steinbach, Kumar and some based on text book (J.Han)
17.
CoSc 6211 JJU17
Rule-based classifier
• Classify records by using a collection of “if…then…”
rules
• Rule: (Condition) → y
– where
• Condition is a conjunctions of attributes
• y is the class label
– LHS: rule antecedent or condition
– RHS: rule consequent
– Examples of classification rules:
• (Blood Type=Warm) (Lay Eggs=Yes) → Birds
∧
• (Taxable Income < 50K) (Refund=Yes) → Evade=No
∧
18.
CoSc 6211 JJU18
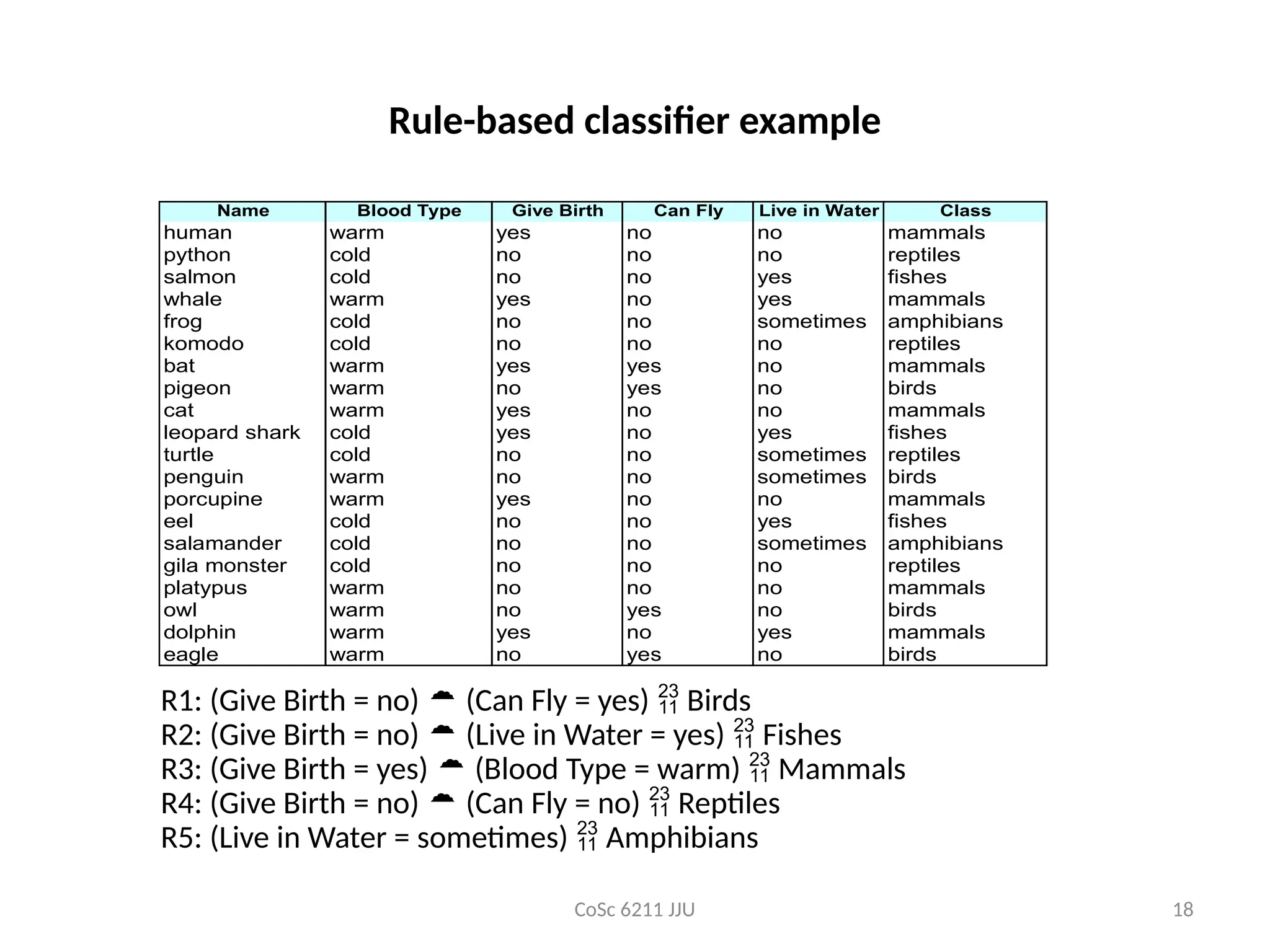
Rule-based classifier example
Name Blood Type Give Birth Can Fly Live in Water Class
human warm yes no no mammals
python cold no no no reptiles
salmon cold no no yes fishes
whale warm yes no yes mammals
frog cold no no sometimes amphibians
komodo cold no no no reptiles
bat warm yes yes no mammals
pigeon warm no yes no birds
cat warm yes no no mammals
leopard shark cold yes no yes fishes
turtle cold no no sometimes reptiles
penguin warm no no sometimes birds
porcupine warm yes no no mammals
eel cold no no yes fishes
salamander cold no no sometimes amphibians
gila monster cold no no no reptiles
platypus warm no no no mammals
owl warm no yes no birds
dolphin warm yes no yes mammals
eagle warm no yes no birds
R1: (Give Birth = no) (Can Fly = yes) Birds
R2: (Give Birth = no) (Live in Water = yes) Fishes
R3: (Give Birth = yes) (Blood Type = warm) Mammals
R4: (Give Birth = no) (Can Fly = no) Reptiles
R5: (Live in Water = sometimes) Amphibians
19.
CoSc 6211 JJU19
Application of Rule-Based Classifier
• A rule r covers an instance x if the attributes of
the instance satisfy the condition of the rule
R1: (Give Birth = no) (Can Fly = yes) Birds
R2: (Give Birth = no) (Live in Water = yes) Fishes
R3: (Give Birth = yes) (Blood Type = warm) Mammals
R4: (Give Birth = no) (Can Fly = no) Reptiles
R5: (Live in Water = sometimes) Amphibians
Name Blood Type Give Birth Can Fly Live in Water Class
hawk warm no yes no ?
grizzly bear warm yes no no ?
The rule R1 covers a hawk => Bird
The rule R3 covers the grizzly bear => Mammal
20.
CoSc 6211 JJU20
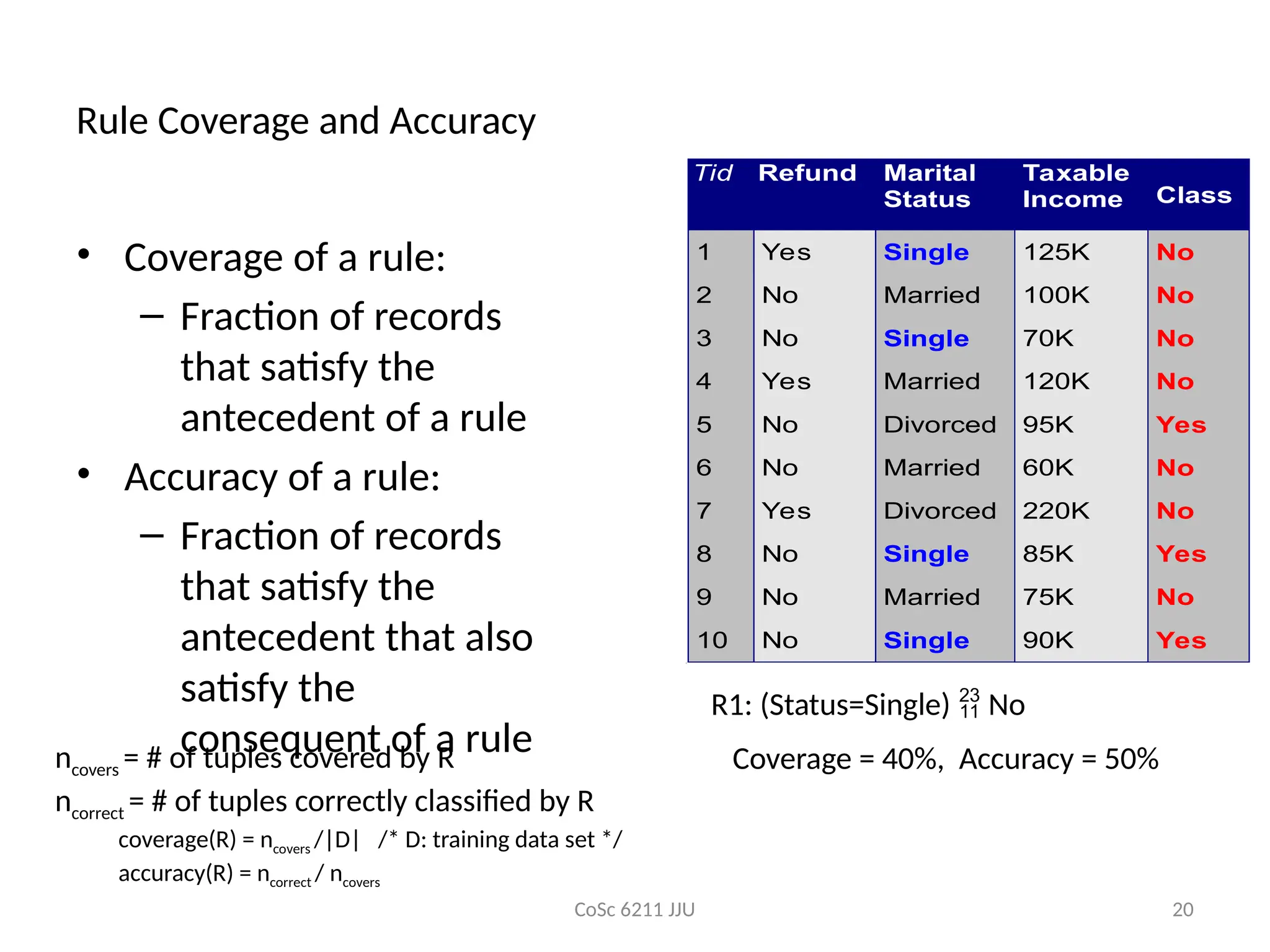
Rule Coverage and Accuracy
• Coverage of a rule:
– Fraction of records
that satisfy the
antecedent of a rule
• Accuracy of a rule:
– Fraction of records
that satisfy the
antecedent that also
satisfy the
consequent of a rule
Tid Refund Marital
Status
Taxable
Income Class
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes
10
ncovers = # of tuples covered by R
ncorrect = # of tuples correctly classified by R
coverage(R) = ncovers /|D| /* D: training data set */
accuracy(R) = ncorrect / ncovers
R1: (Status=Single) No
Coverage = 40%, Accuracy = 50%
21.
CoSc 6211 JJU21
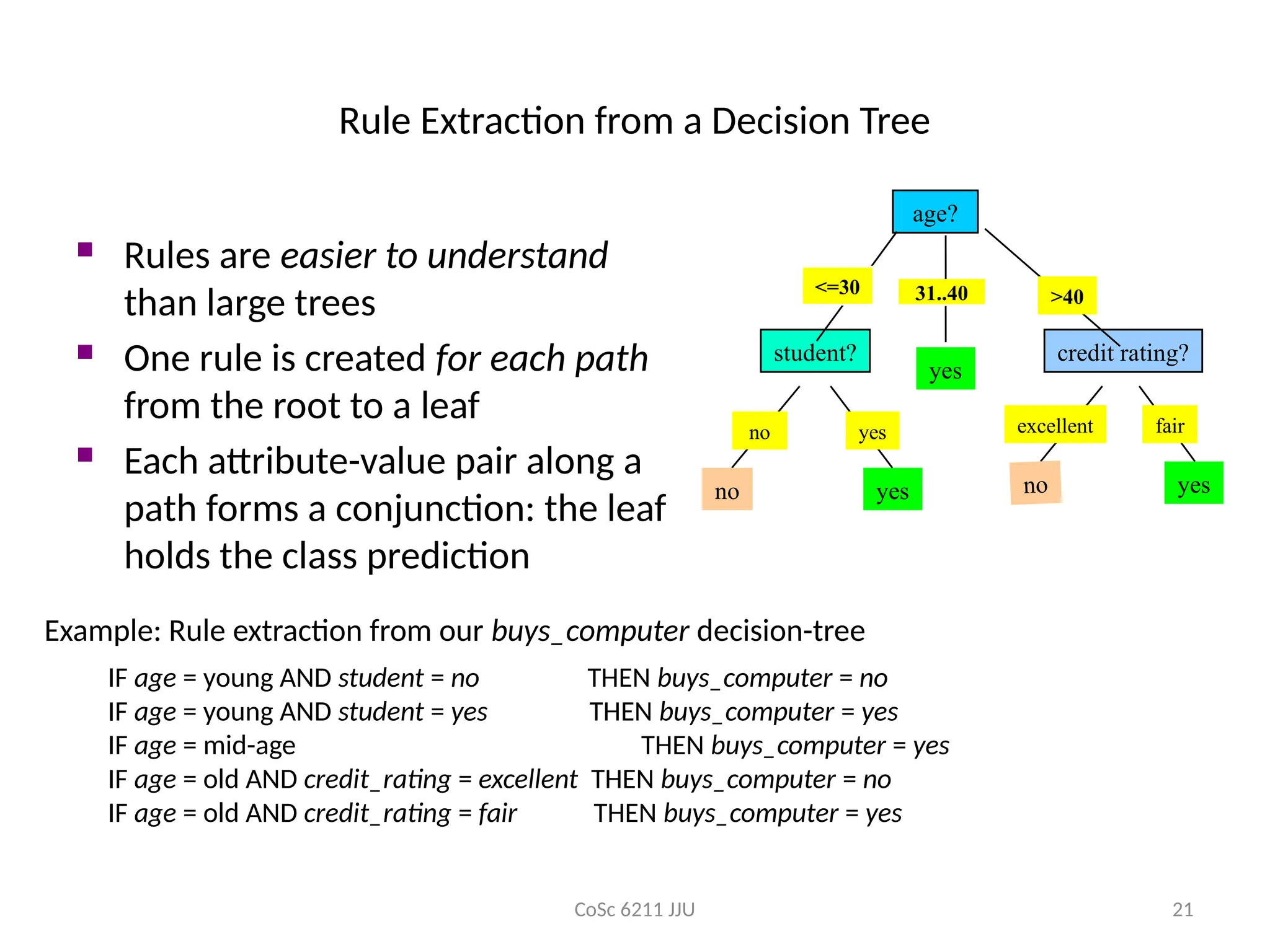
Rule Extraction from a Decision Tree
Rules are easier to understand
than large trees
One rule is created for each path
from the root to a leaf
Each attribute-value pair along a
path forms a conjunction: the leaf
holds the class prediction
age?
student? credit rating?
<=30 >40
no yes yes
yes
31..40
no
fair
excellent
yes
no
Example: Rule extraction from our buys_computer decision-tree
IF age = young AND student = no THEN buys_computer = no
IF age = young AND student = yes THEN buys_computer = yes
IF age = mid-age THEN buys_computer = yes
IF age = old AND credit_rating = excellent THEN buys_computer = no
IF age = old AND credit_rating = fair THEN buys_computer = yes
22.
CoSc 6211 JJU22
• Ensemble Methods: Increasing the Accuracy
23.
CoSc 6211 JJU23
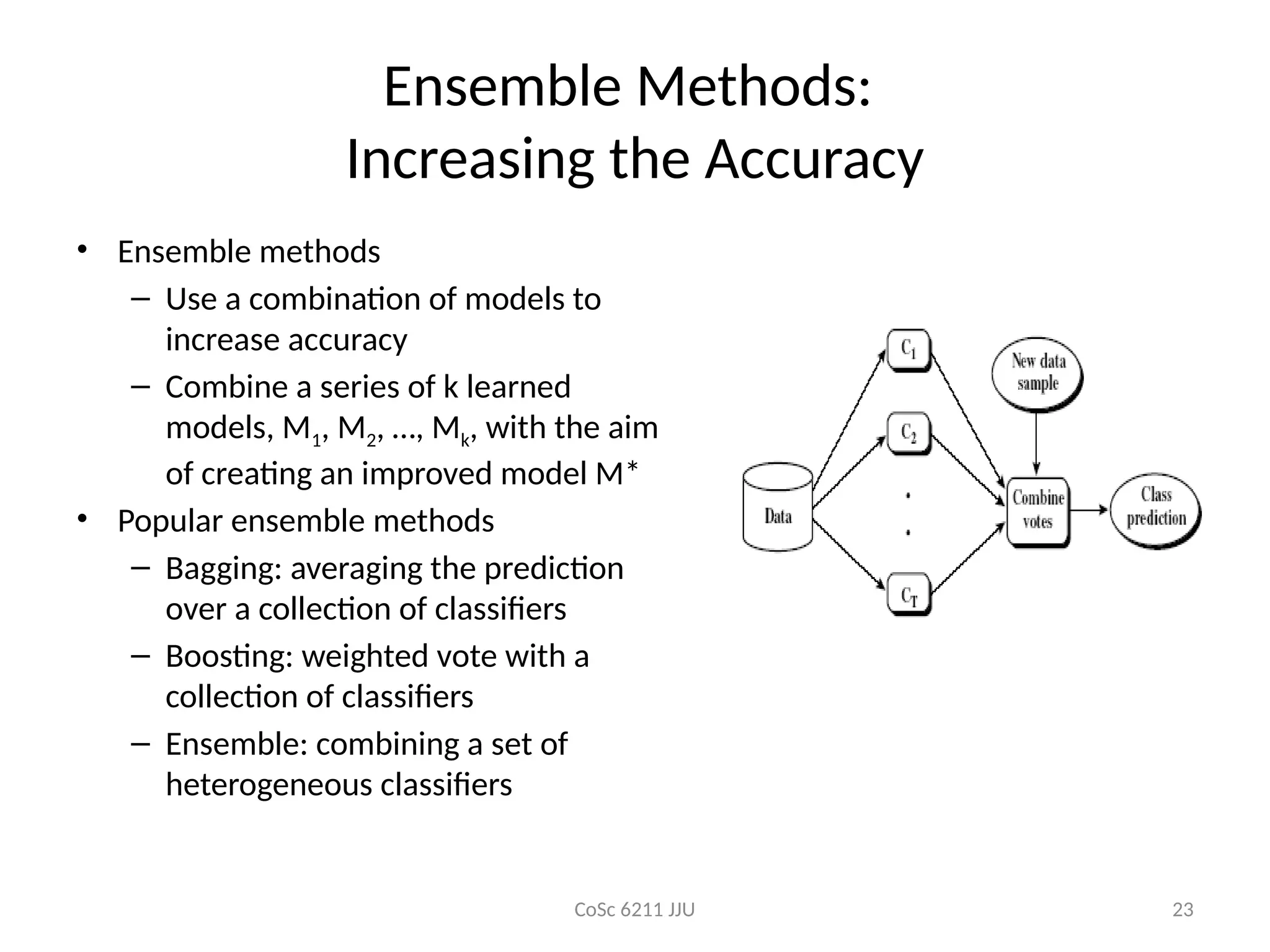
Ensemble Methods:
Increasing the Accuracy
• Ensemble methods
– Use a combination of models to
increase accuracy
– Combine a series of k learned
models, M1, M2, …, Mk, with the aim
of creating an improved model M*
• Popular ensemble methods
– Bagging: averaging the prediction
over a collection of classifiers
– Boosting: weighted vote with a
collection of classifiers
– Ensemble: combining a set of
heterogeneous classifiers
24.
CoSc 6211 JJU24
Bagging: Bootstrap Aggregation
Analogy: Diagnosis based on multiple doctors’ majority vote
• Training
– Given a set D of d tuples, at each iteration i, a training set Di of d tuples is sampled
with replacement from D (i.e., bootstrap)
– A classifier model Mi is learned for each training set Di
• Classification: classify an unknown sample X
– Each classifier Mi returns its class prediction
– The bagged classifier M* counts the votes and assigns the class with the most votes
to X
• Prediction: can be applied to the prediction of continuous values by taking the average
value of each prediction for a given test tuple
• Accuracy
– Often significantly better than a single classifier derived from D
– For noise data: not considerably worse, more robust
– Proved improved accuracy in prediction
25.
CoSc 6211 JJU25
Boosting
• Analogy: Consult several doctors, based on a combination of
weighted diagnoses—weight assigned based on the previous
diagnosis accuracy
• How boosting works?
– Weights are assigned to each training tuple
– A series of k classifiers is iteratively learned
– After a classifier Mi is learned, the weights are updated to allow the
subsequent classifier, Mi+1, to pay more attention to the training tuples
that were misclassified by Mi
– The final M* combines the votes of each individual classifier, where the
weight of each classifier's vote is a function of its accuracy
• Boosting algorithm can be extended for numeric prediction
• Comparing with bagging: Boosting tends to have greater accuracy,
but it also risks overfitting the model to misclassified data
26.
CoSc 6211 JJU26
Adaboost (Freund and Schapire, 1997)
• Given a set of d class-labeled tuples, (X1, y1), …, (Xd, yd)
• Initially, all the weights of tuples are set the same (1/d)
• Generate k classifiers in k rounds. At round i,
– Tuples from D are sampled (with replacement) to form a training set Di of the
same size
– Each tuple’s chance of being selected is based on its weight
– A classification model Mi is derived from Di
– Its error rate is calculated using Di as a test set
– If a tuple is misclassified, its weight is increased, o.w. it is decreased
• Error rate: err(Xj) is the misclassification error of tuple Xj. Classifier Mi error rate is
the sum of the weights of the misclassified tuples:
• The weight of classifier Mi’s vote is
d
j
j
i err
w
M
error )
(
)
( j
X
)
(
)
(
1
log
i
i
M
error
M
error
27.
CoSc 6211 JJU27
Random Forest (Breiman 2001)
• Random Forest:
– Each classifier in the ensemble is a decision tree classifier and is generated
using a random selection of attributes at each node to determine the split
– During classification, each tree votes and the most popular class is returned
• Two Methods to construct Random Forest:
– Forest-RI (random input selection): Randomly select, at each node, F
attributes as candidates for the split at the node. The CART methodology is
used to grow the trees to maximum size
– Forest-RC (random linear combinations): Creates new attributes (or
features) that are a linear combination of the existing attributes (reduces
the correlation between individual classifiers)
• Comparable in accuracy to Adaboost, but more robust to errors and outliers
• Insensitive to the number of attributes selected for consideration at each split,
and faster than bagging or boosting
28.
CoSc 6211 JJU28
Improving Classification Accuracy of Class-
Imbalanced Data Sets
• Class-imbalance problem: Rare positive example but numerous
negative ones, e.g., medical diagnosis, fraud, oil-spill, fault, etc.
• Traditional methods assume a balanced distribution of classes and
equal error costs: not suitable for class-imbalanced data
• Typical methods for imbalance data in 2-class classification:
– Oversampling: re-sampling of data from positive class
– Under-sampling: randomly eliminate tuples from negative class
– Threshold-moving: moves the decision threshold, t, so that the
rare class tuples are easier to classify, and hence, less chance of
costly false negative errors
– Ensemble techniques: Ensemble multiple classifiers introduced
above
• Still difficult for class imbalance problem on multiclass tasks
29.
CoSc 6211 JJU29
• Next :
• Classification: ANN and Evaluation models
4. Clustering
Editor's Notes
#23 So far – learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions.
Ensemble learning select a collection (ensemble) of hypotheses and combine their predictions.
Example 1 - generate 100 different decision trees from the same or different training set and
have them vote on the best classification for a new example.
Key motivation: reduce the error rate. Hope is that it will become much more unlikely that the ensemble of will misclassify an example
#27 Random forest - The random forest is a method of learning sets for classification, regression and
other tasks, where a large number of decision trees are created at the time of the decision and
the class is output, which is the average classification or prediction mode of individual trees.
Random forests rectify the habit of decision trees that go with their training set.
Random forests are a method of calculating the mean of several deep decision trees formed
in different parts of the same training set, with the aim of reducing the variance.
This is to the detriment of a slight increase and a loss of interpretability, but
generally increases significantly the presentation of the final model. (Pham et al., 2017).







































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)






















![Automating ISP Networks Using Ansible and IPAM as a Source of Truth [SoT]](https://cdn.slidesharecdn.com/ss_thumbnails/automatingispnetworksusingansibleandipamasasourceoftruthsot-v25-1-251124105117-d7d4ca24-thumbnail.jpg?width=640&height=640&fit=bounds)





