Download as PDF, PPTX





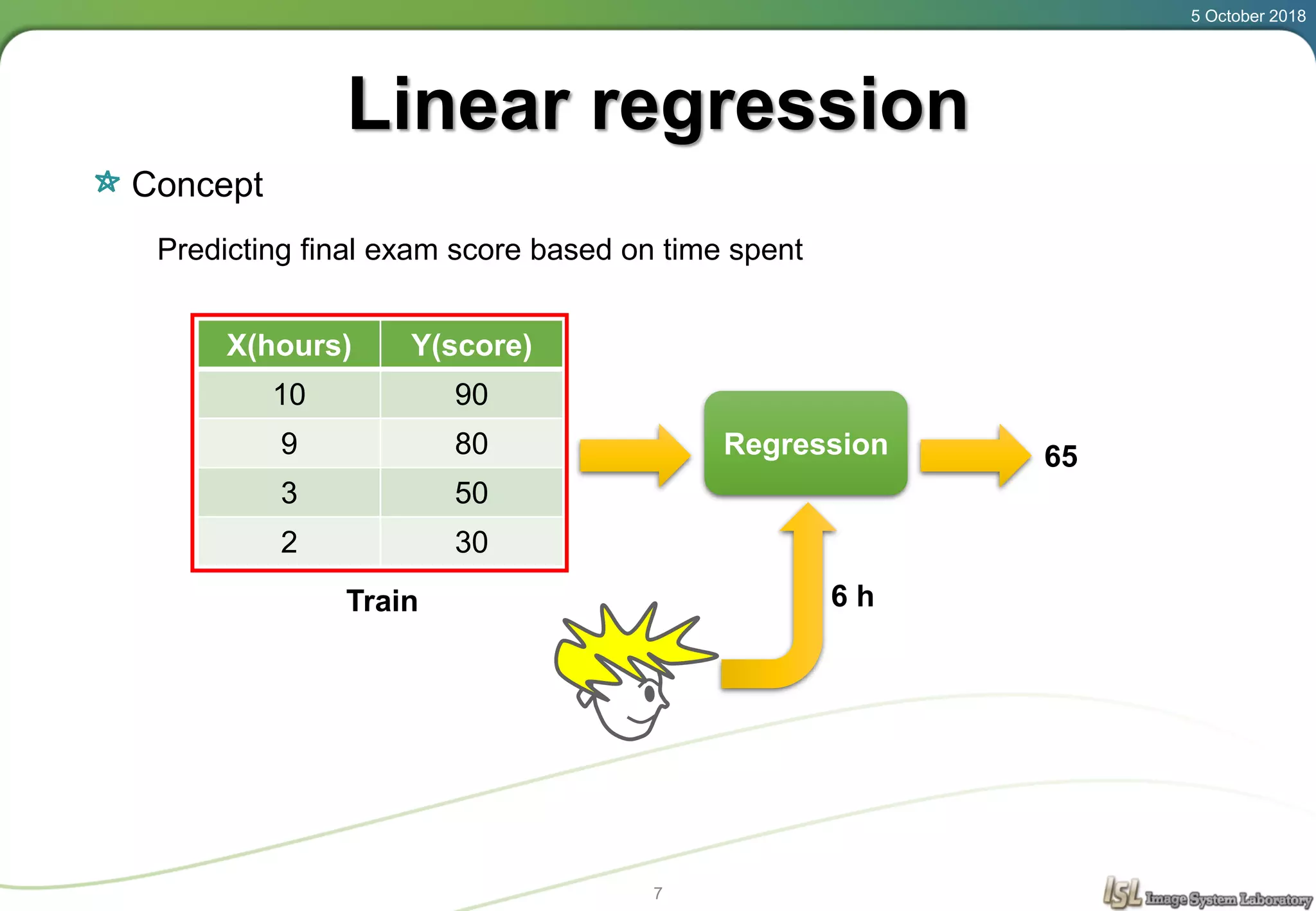
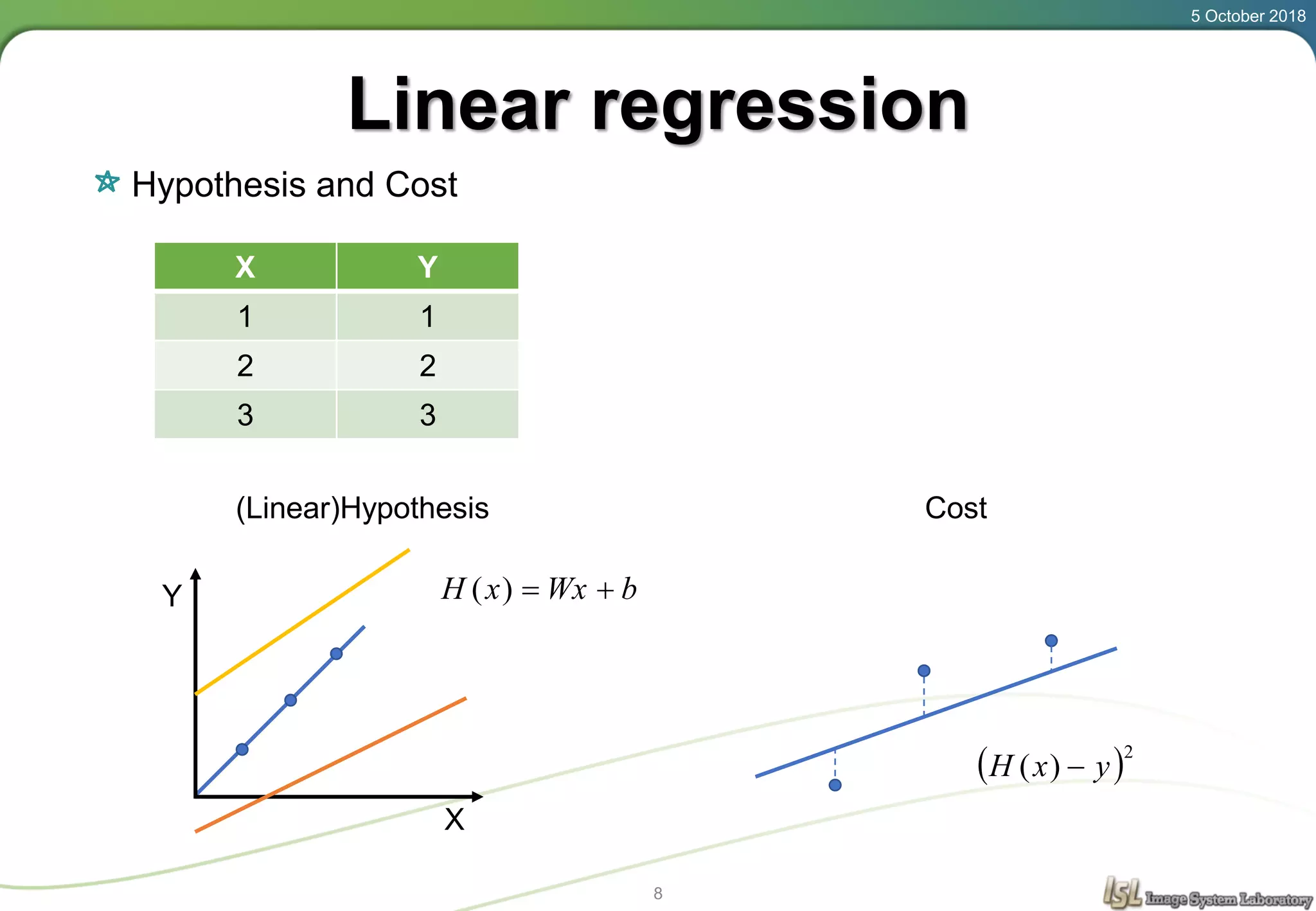

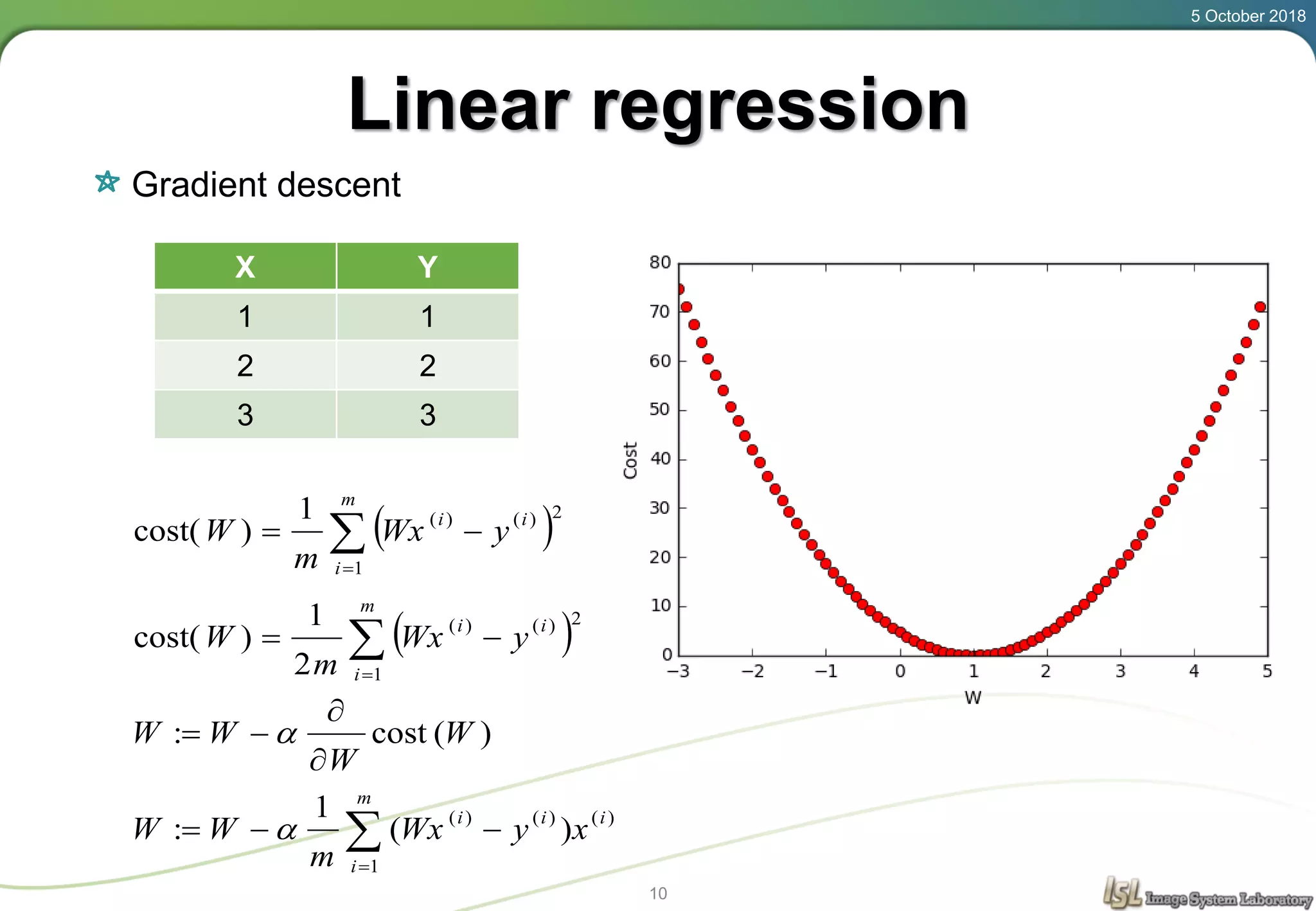
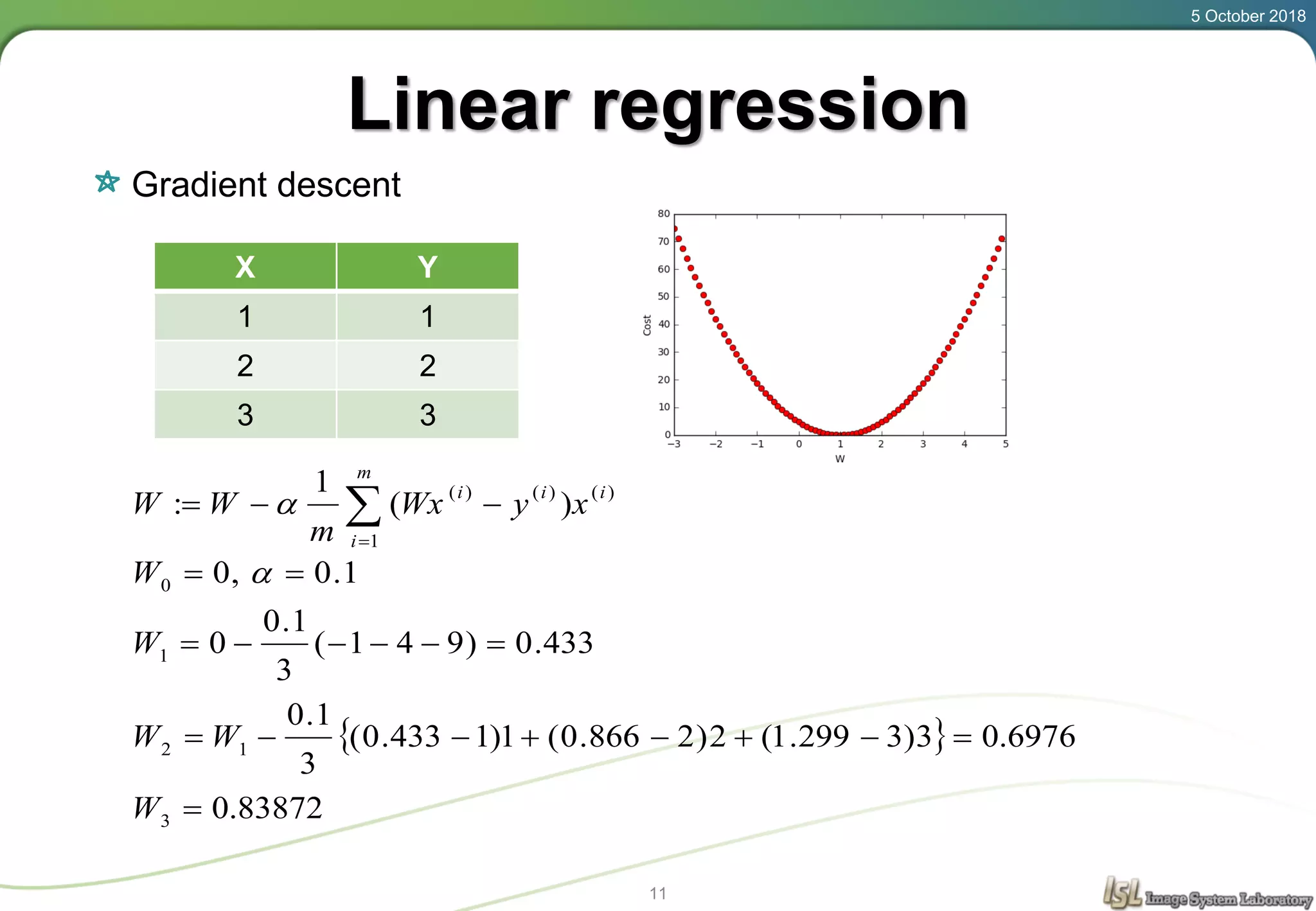
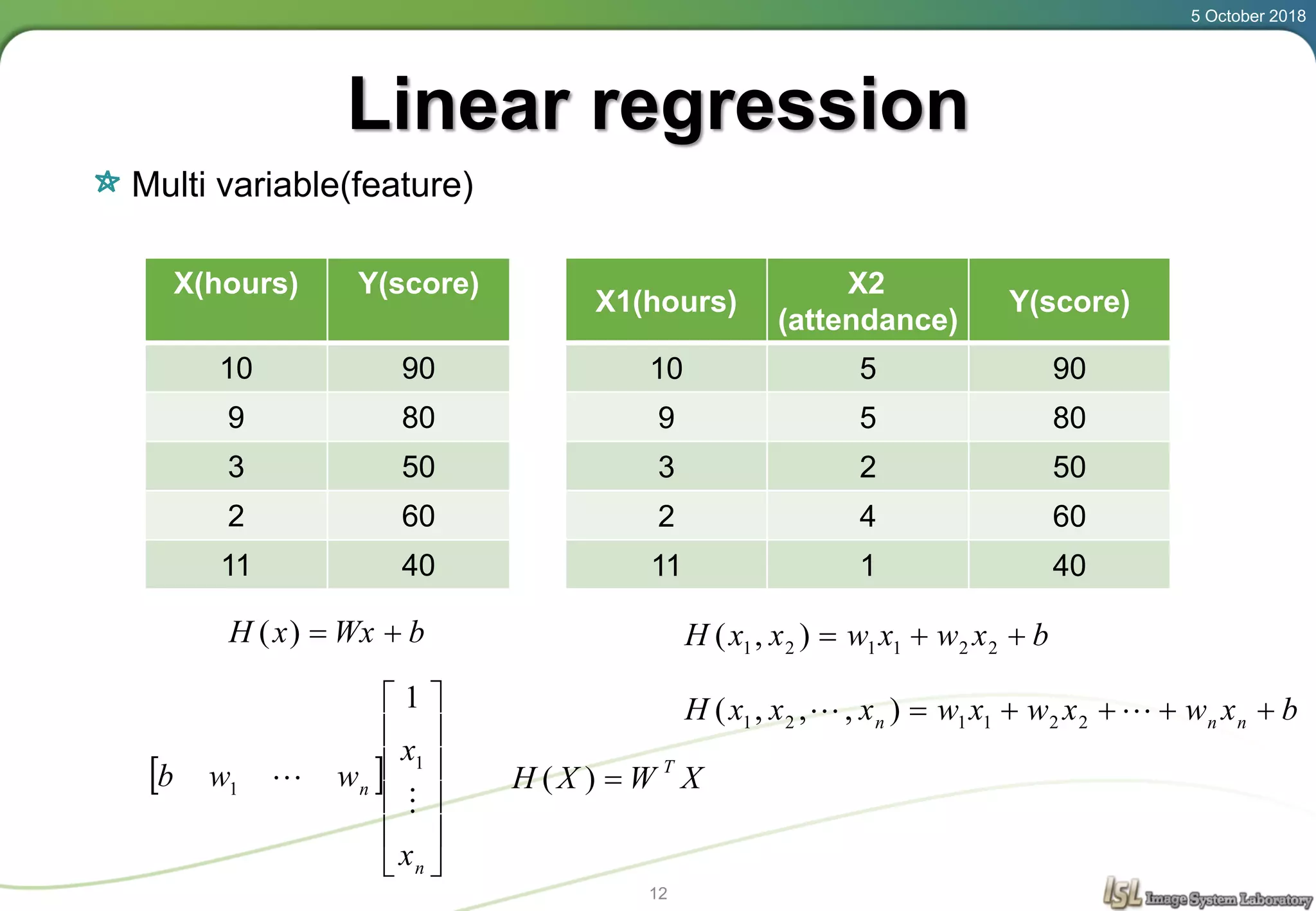
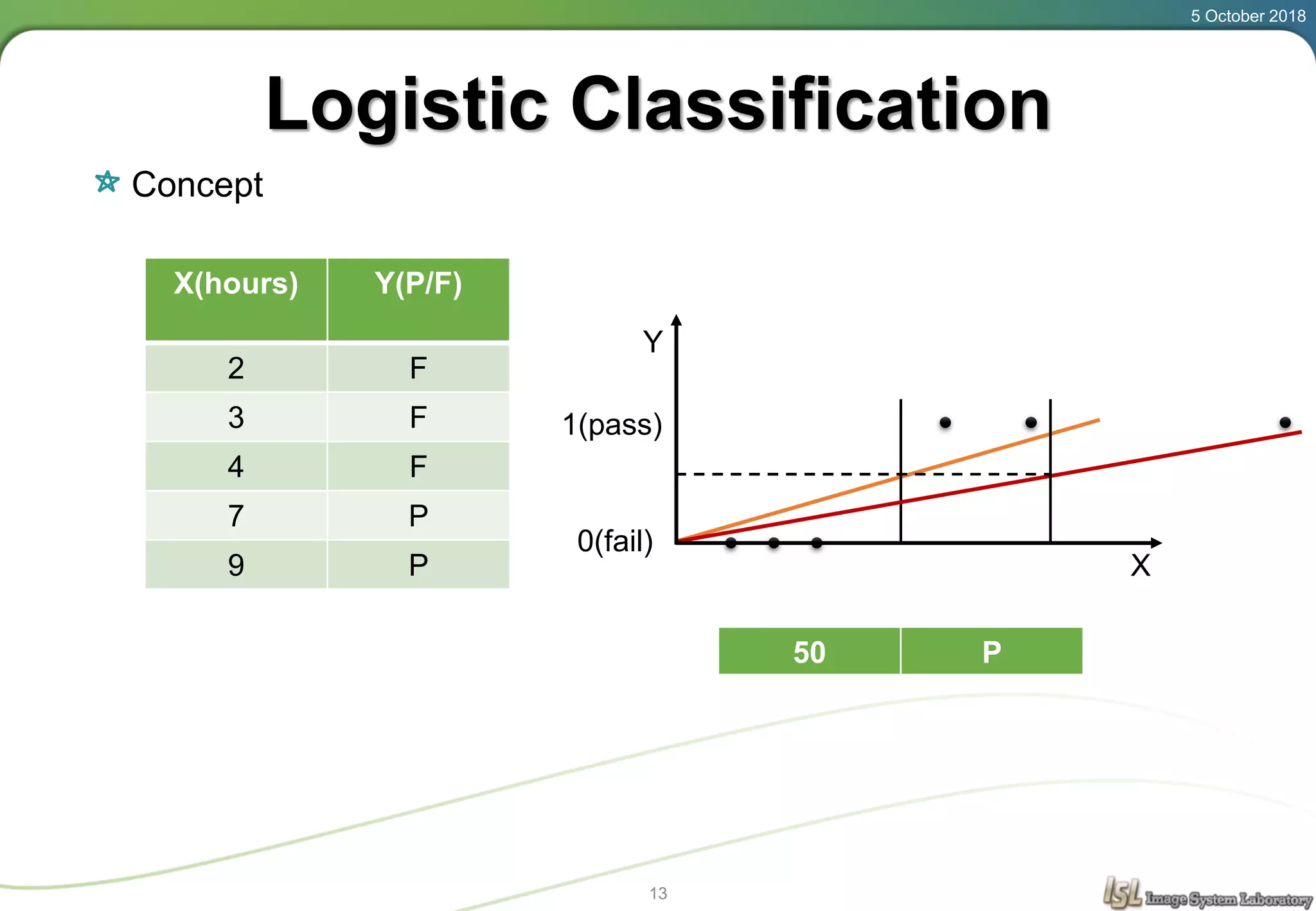
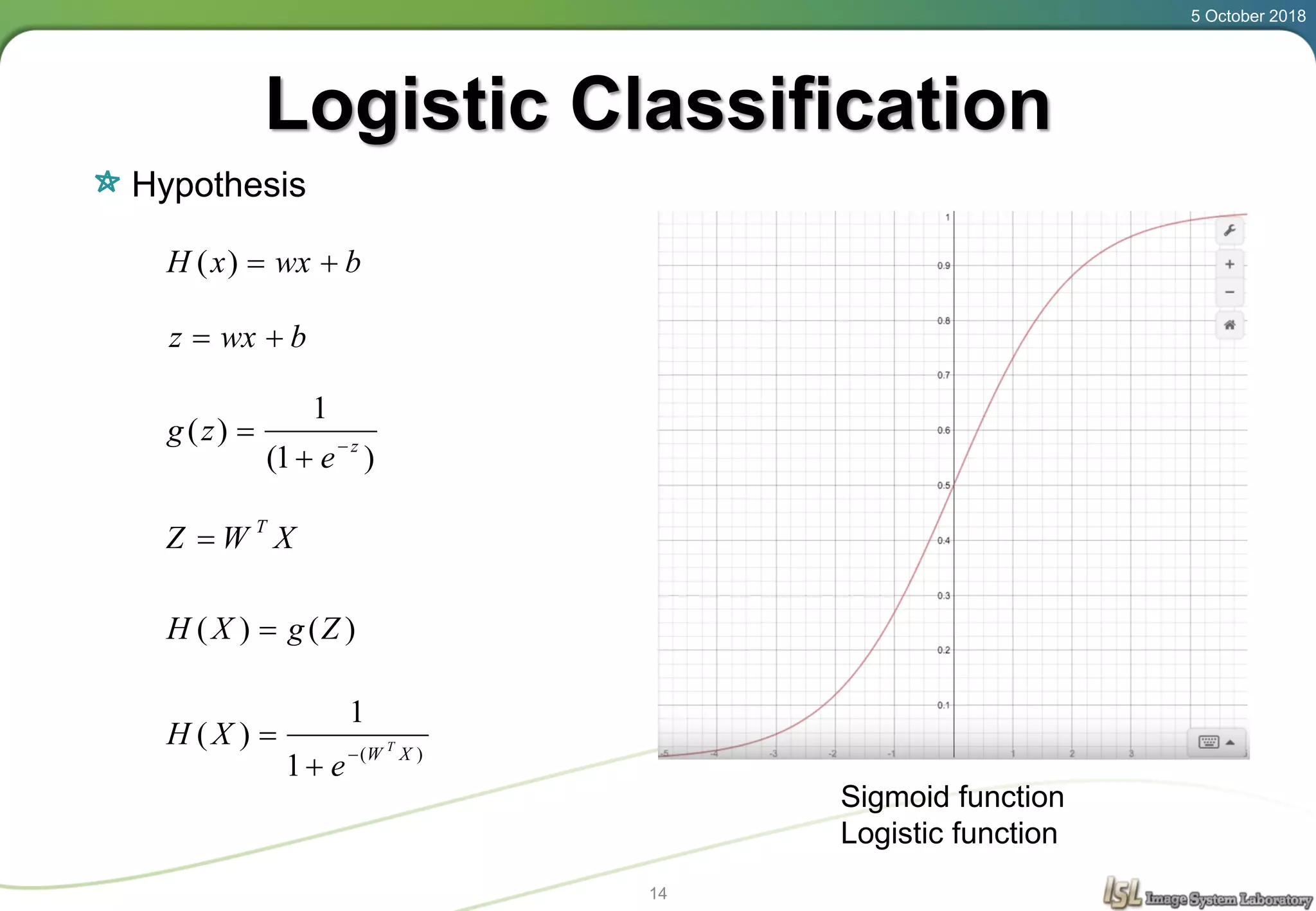
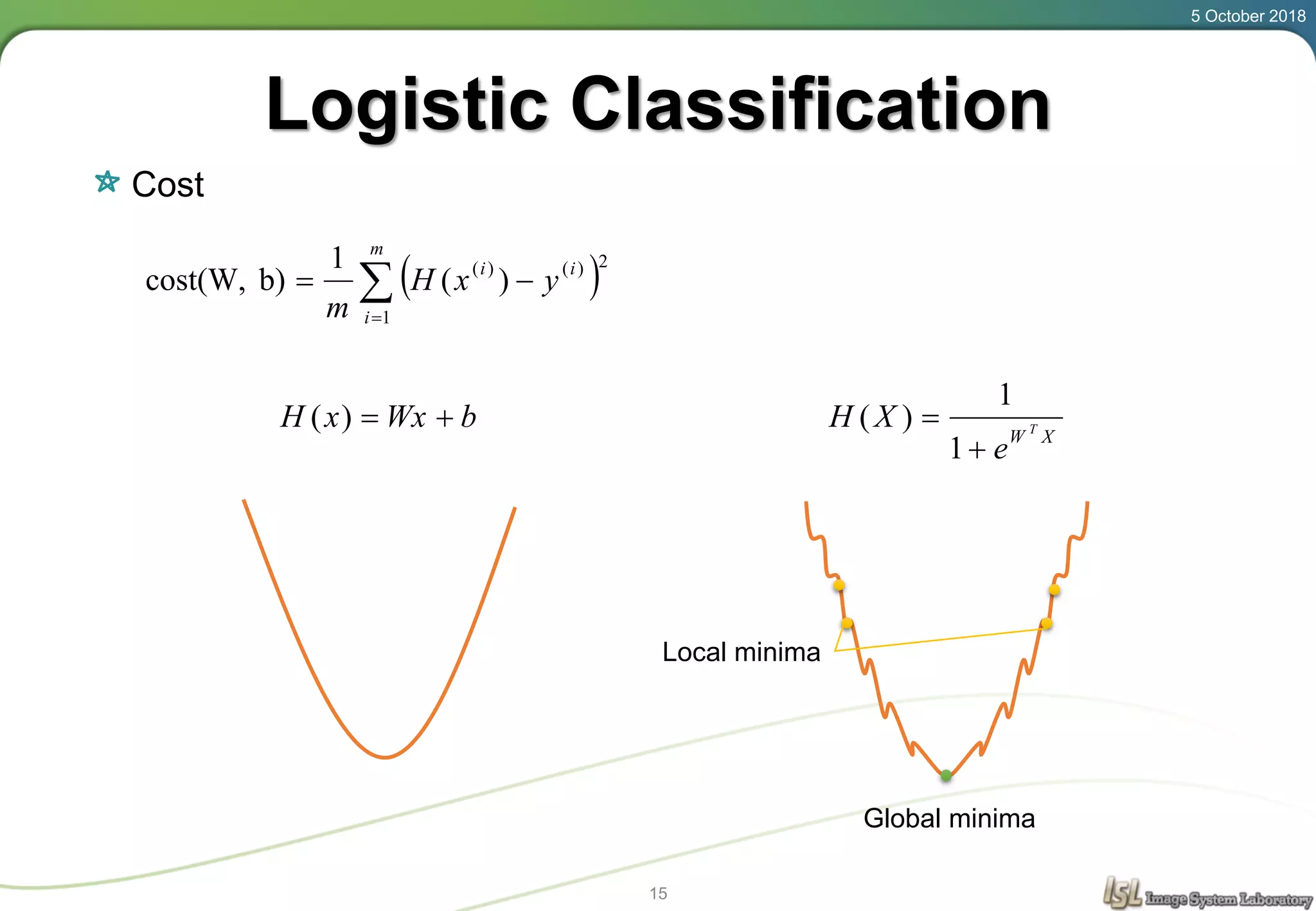
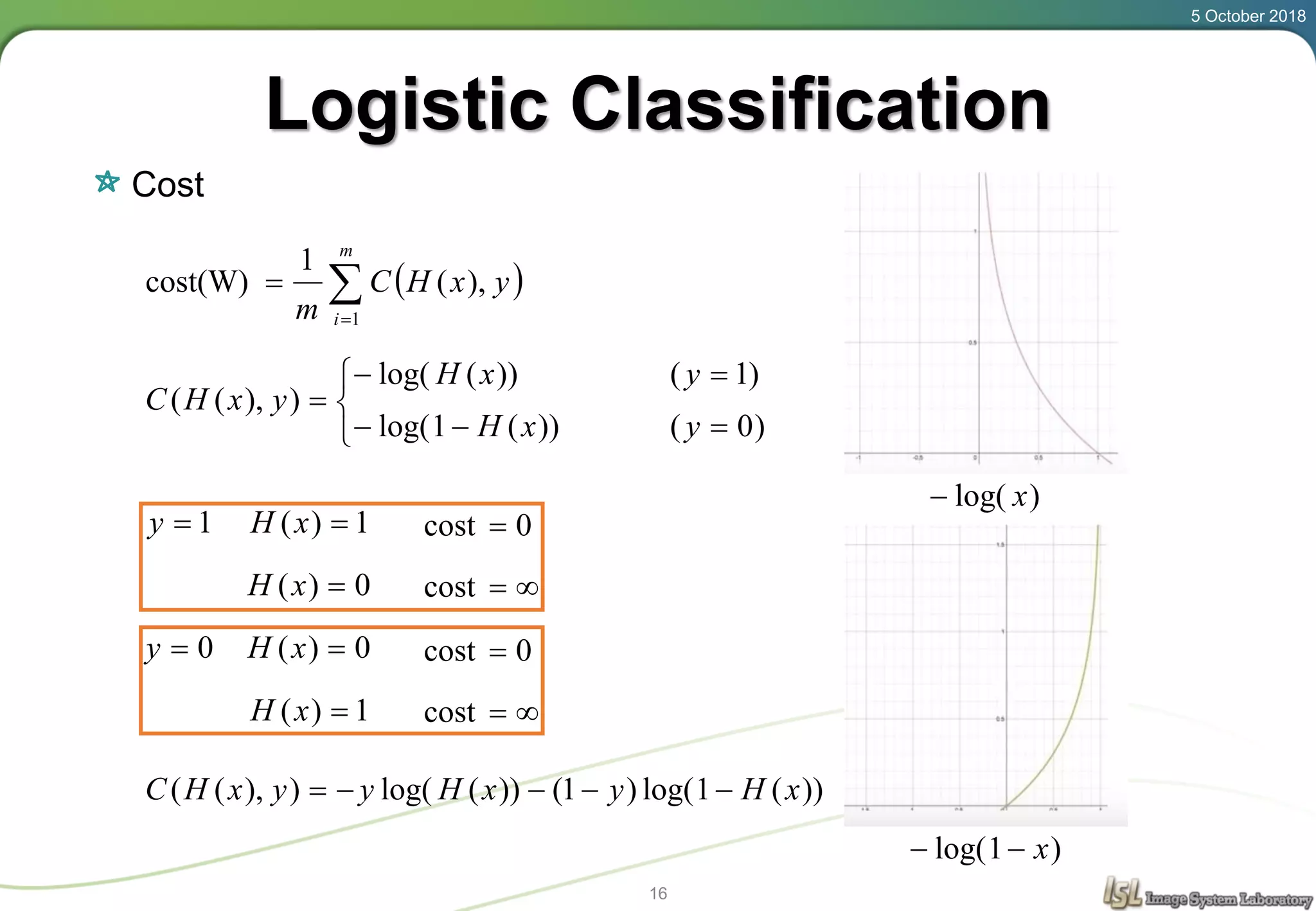



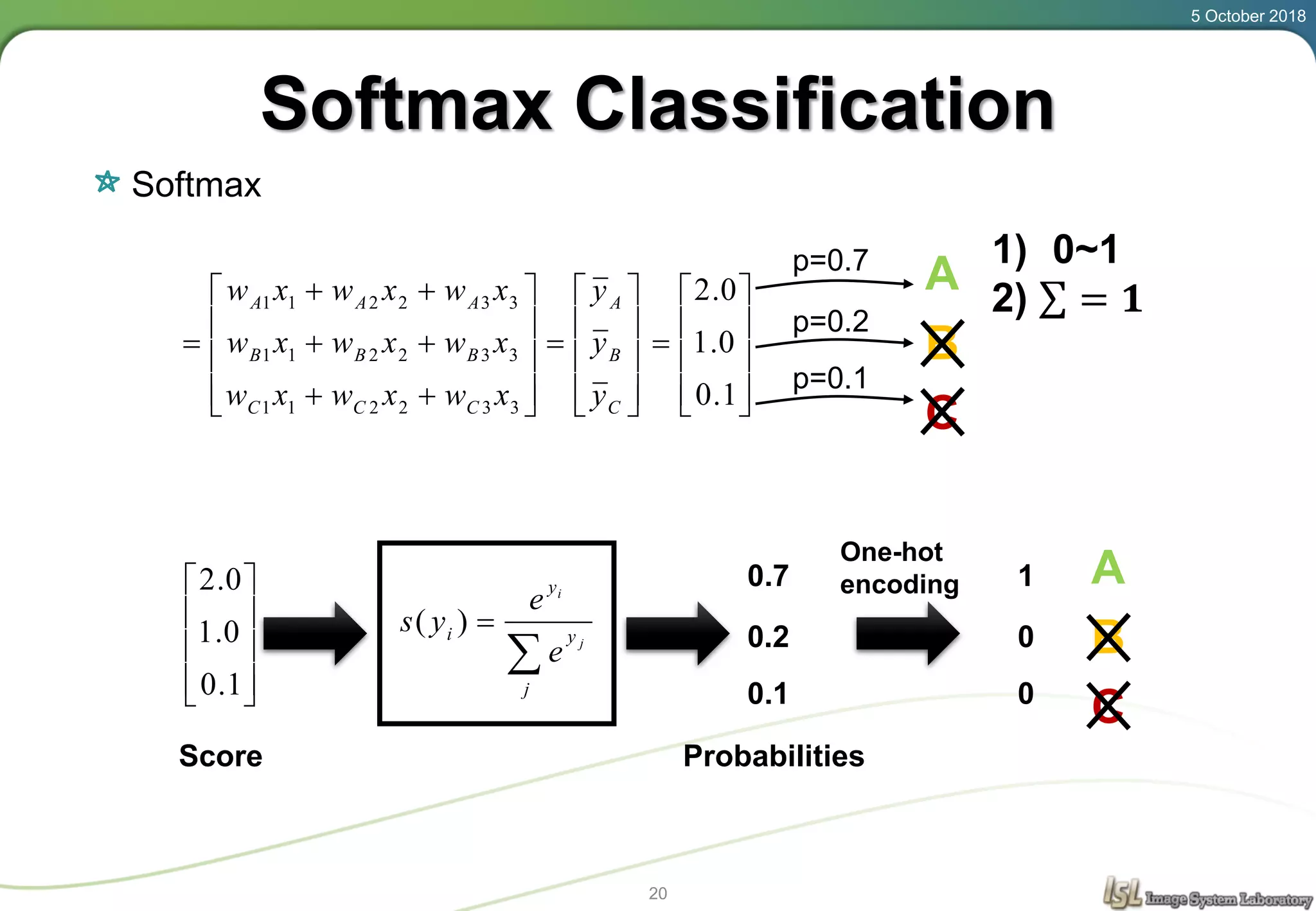
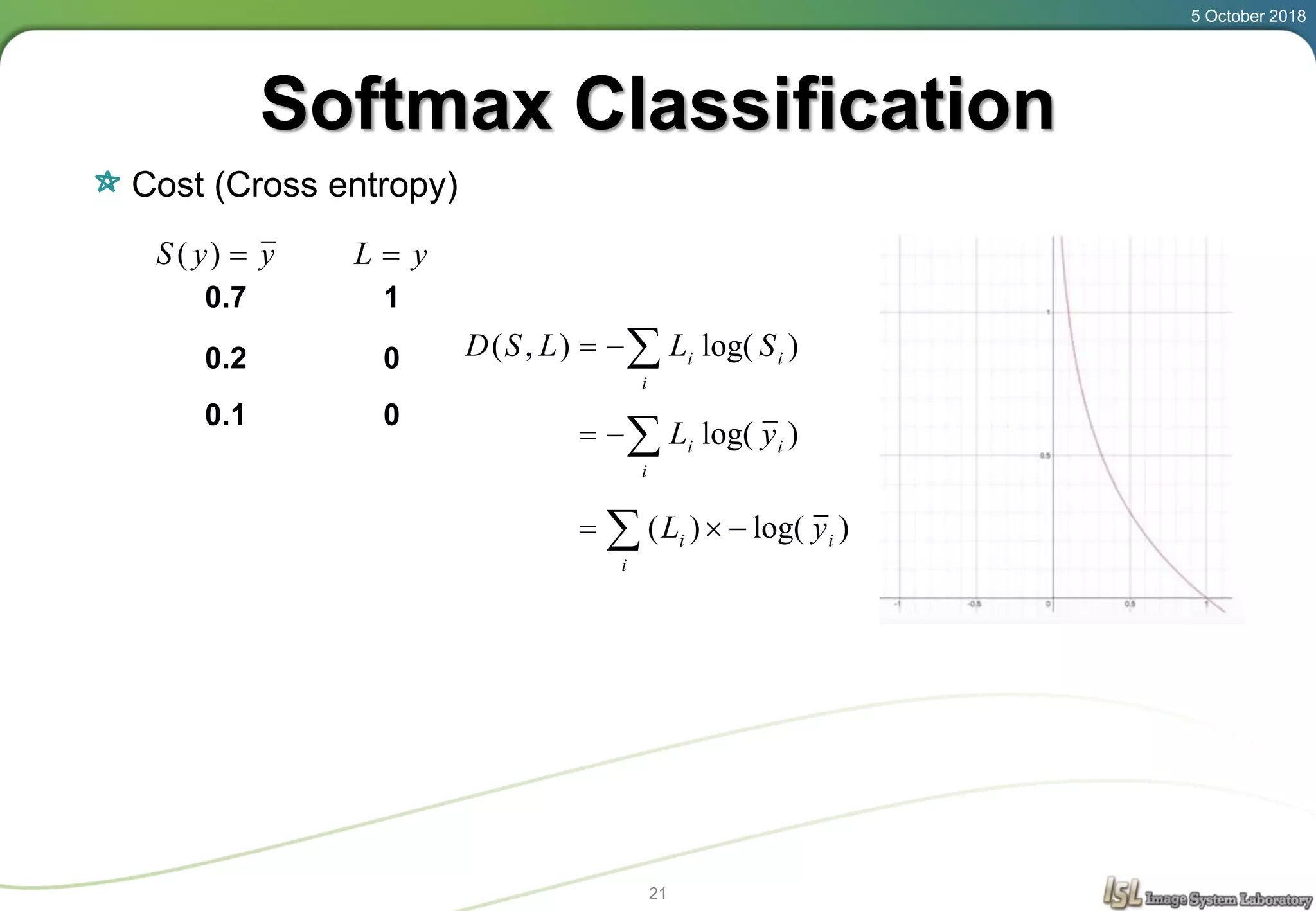


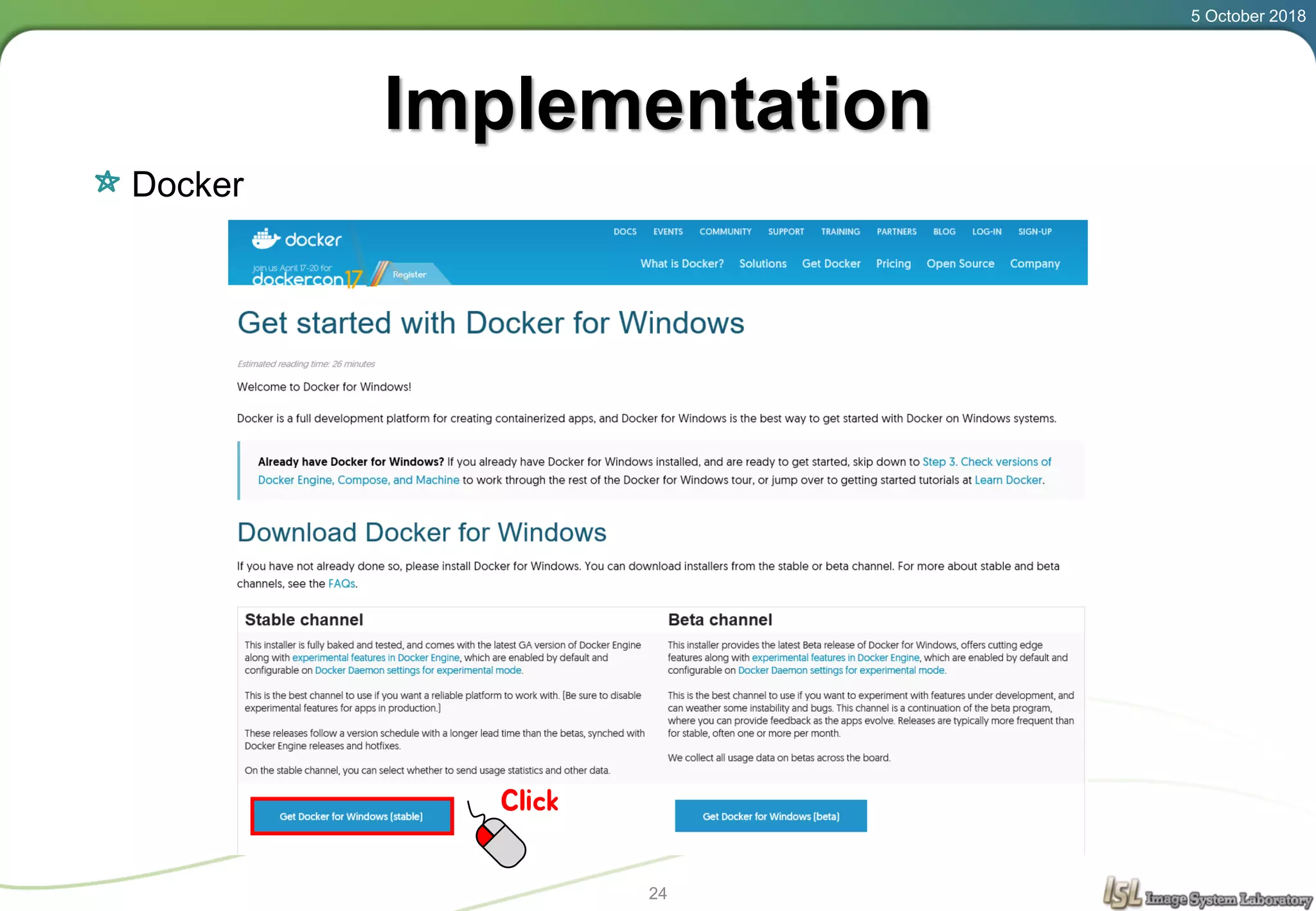
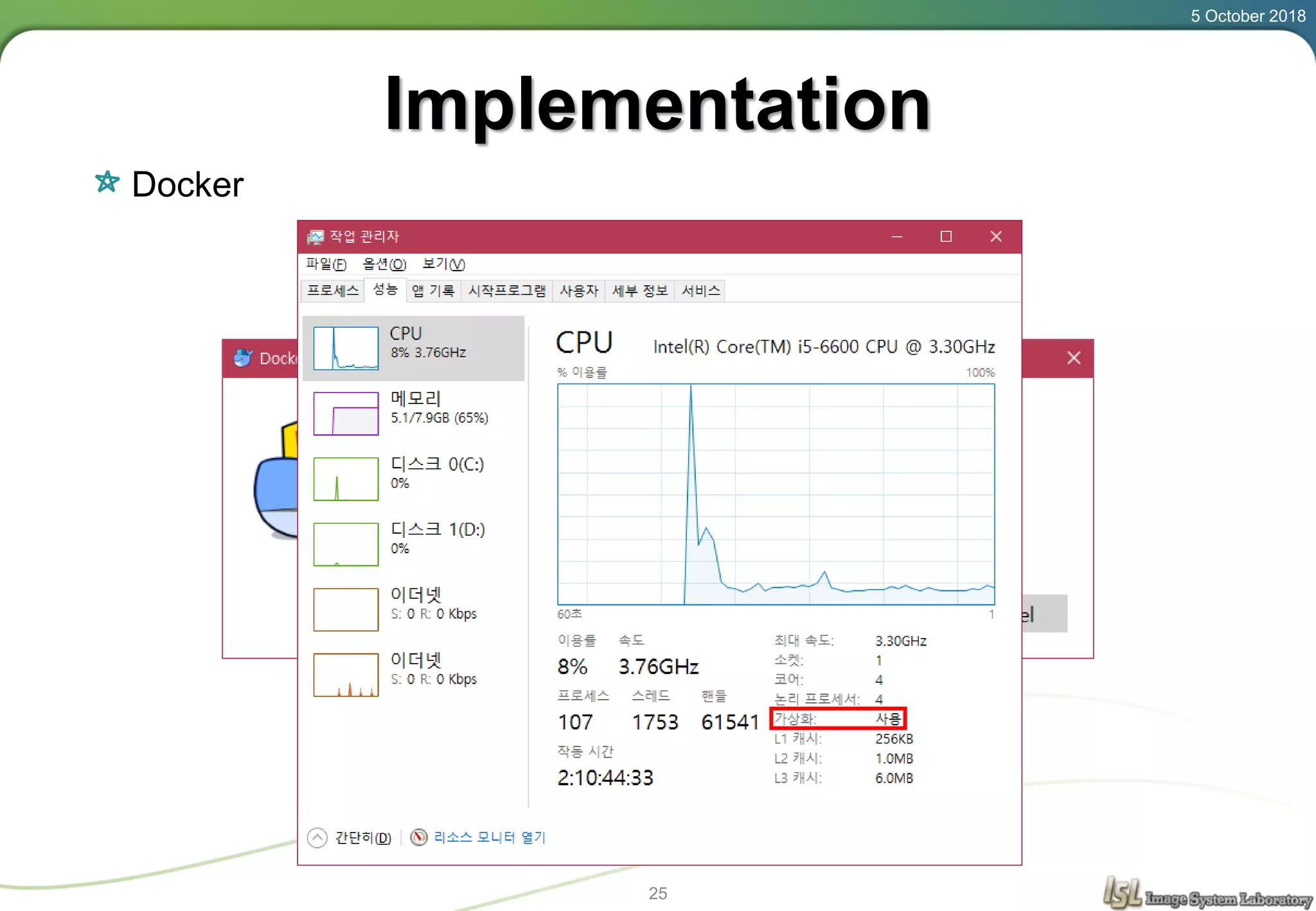
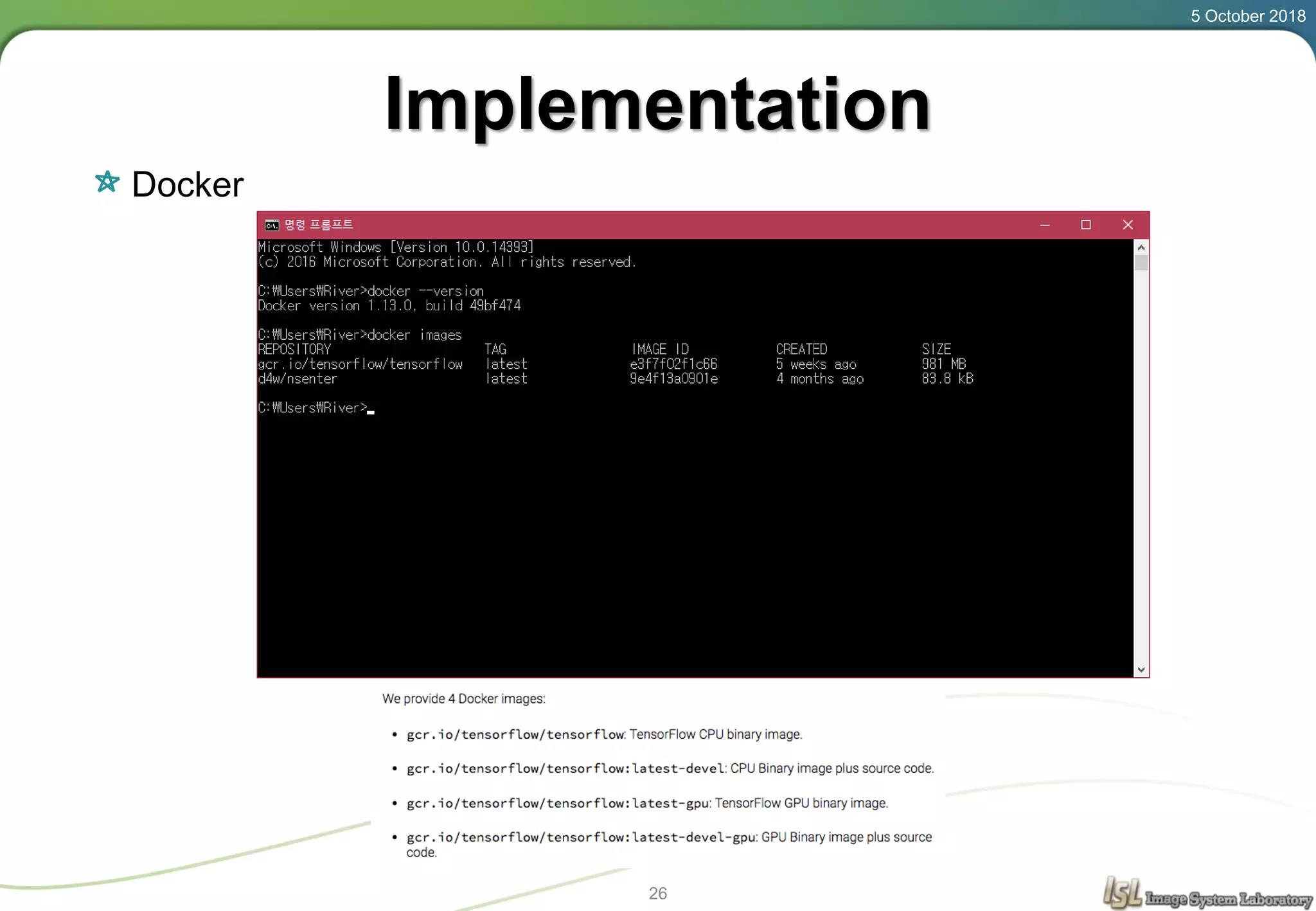
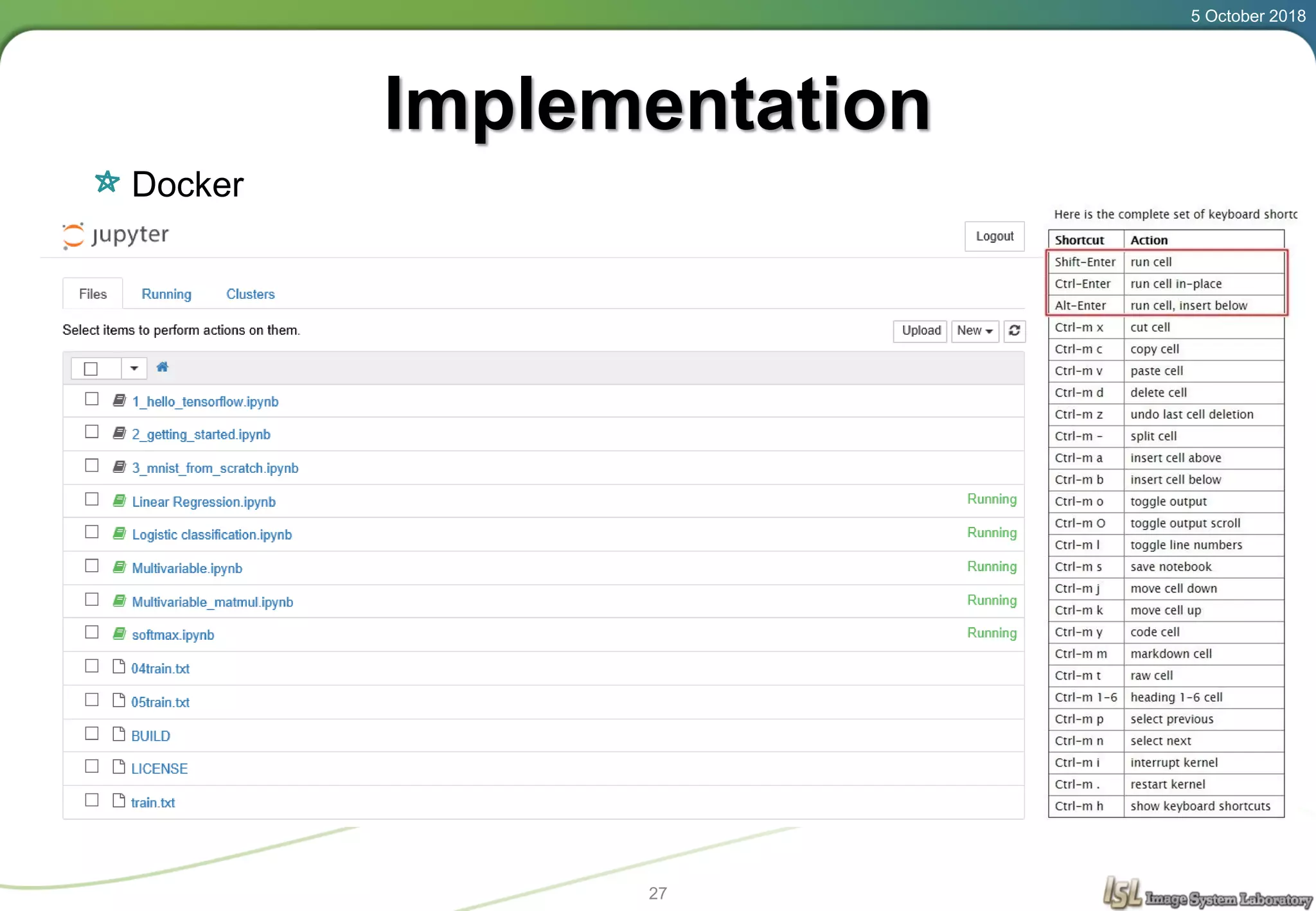




This document provides an overview of basic machine learning concepts including regression, logistic classification, and softmax classification. It introduces linear regression for predicting a continuous output variable, logistic regression for binary classification problems, and softmax classification for multi-class classification problems. Key aspects covered include the hypothesis, cost function, and using gradient descent to minimize the cost function for each of these machine learning algorithms.


![B.Sc.IT: Semester - VI (October - 2016) [IDOL - Revised Course | Question Paper]](https://cdn.slidesharecdn.com/ss_thumbnails/bscit-sem-vi-idol-oct-2016-qp-180803214341-thumbnail.jpg?width=640&height=640&fit=bounds)










![Geographic Information System (May – 2016) [75:25 Pattern | Question Paper]](https://cdn.slidesharecdn.com/ss_thumbnails/gis-75-25-qp-may-2016-180428091913-thumbnail.jpg?width=640&height=640&fit=bounds)





![Internet Technologies (May - 2018) [IDOL - Old Course | Question Paper]](https://cdn.slidesharecdn.com/ss_thumbnails/internettechnologiesmay-2018-180813195906-thumbnail.jpg?width=640&height=640&fit=bounds)














































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)











