
















![Compute Pipeline : Main Algorithm
Strength[Relation(Concept1,Concept2)] =
Function{Confidence(Concept1,Concept2),
Confidence(Concept1),Confidence(Concept2)}](https://image.slidesharecdn.com/approachestotextanalysis-160321115033/75/Approaches-to-text-analysis-21-2048.jpg)
![Compute Pipeline : Main Algorithm
lPhase II will compute relations from concepts formed from Phase I
Strength[Relation(Concept1,Concept2)] =
Function{Confidence(Concept1,Concept2),
Confidence(Concept1),Confidence(Concept2)}](https://image.slidesharecdn.com/approachestotextanalysis-160321115033/75/Approaches-to-text-analysis-22-2048.jpg)
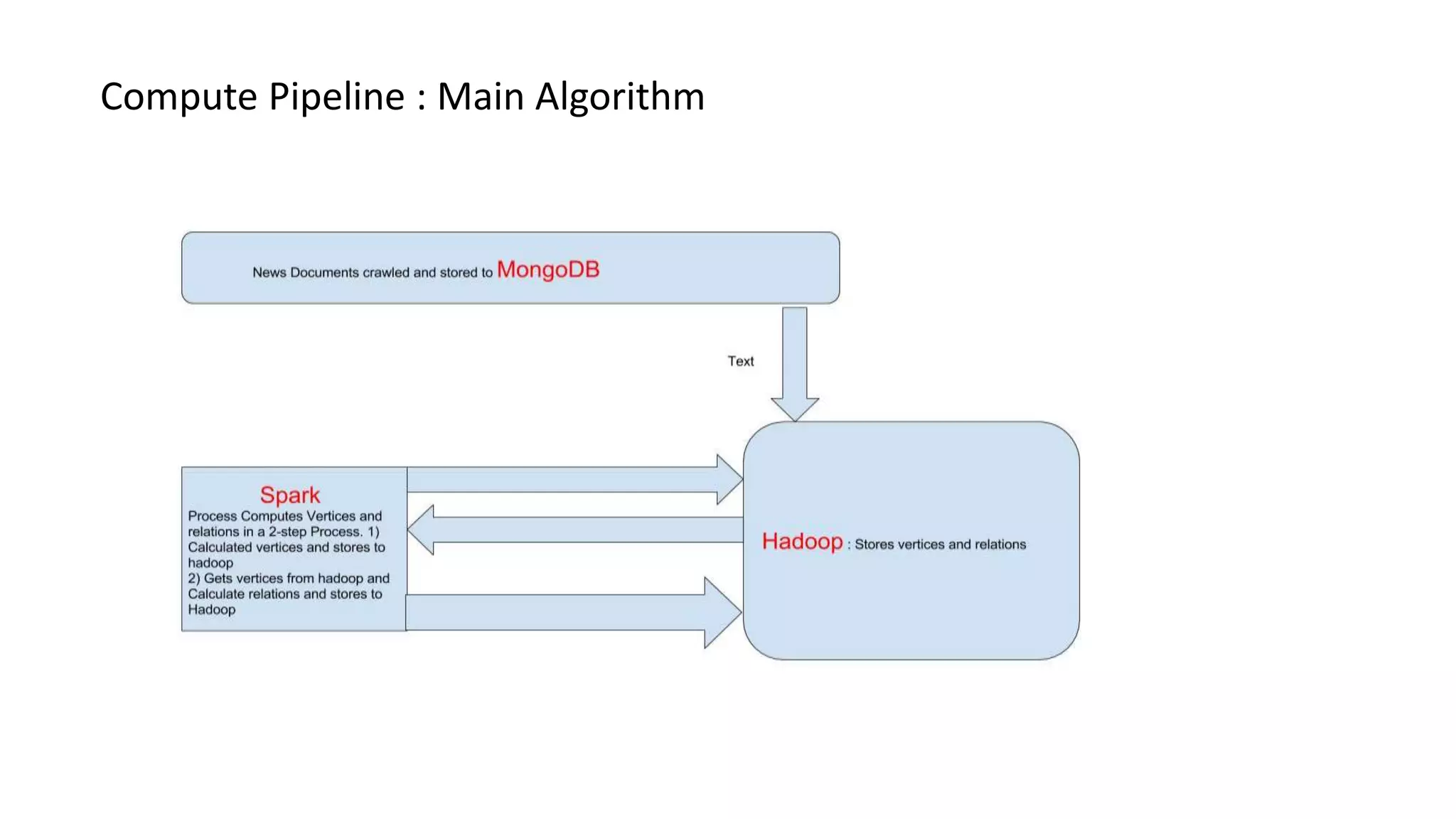


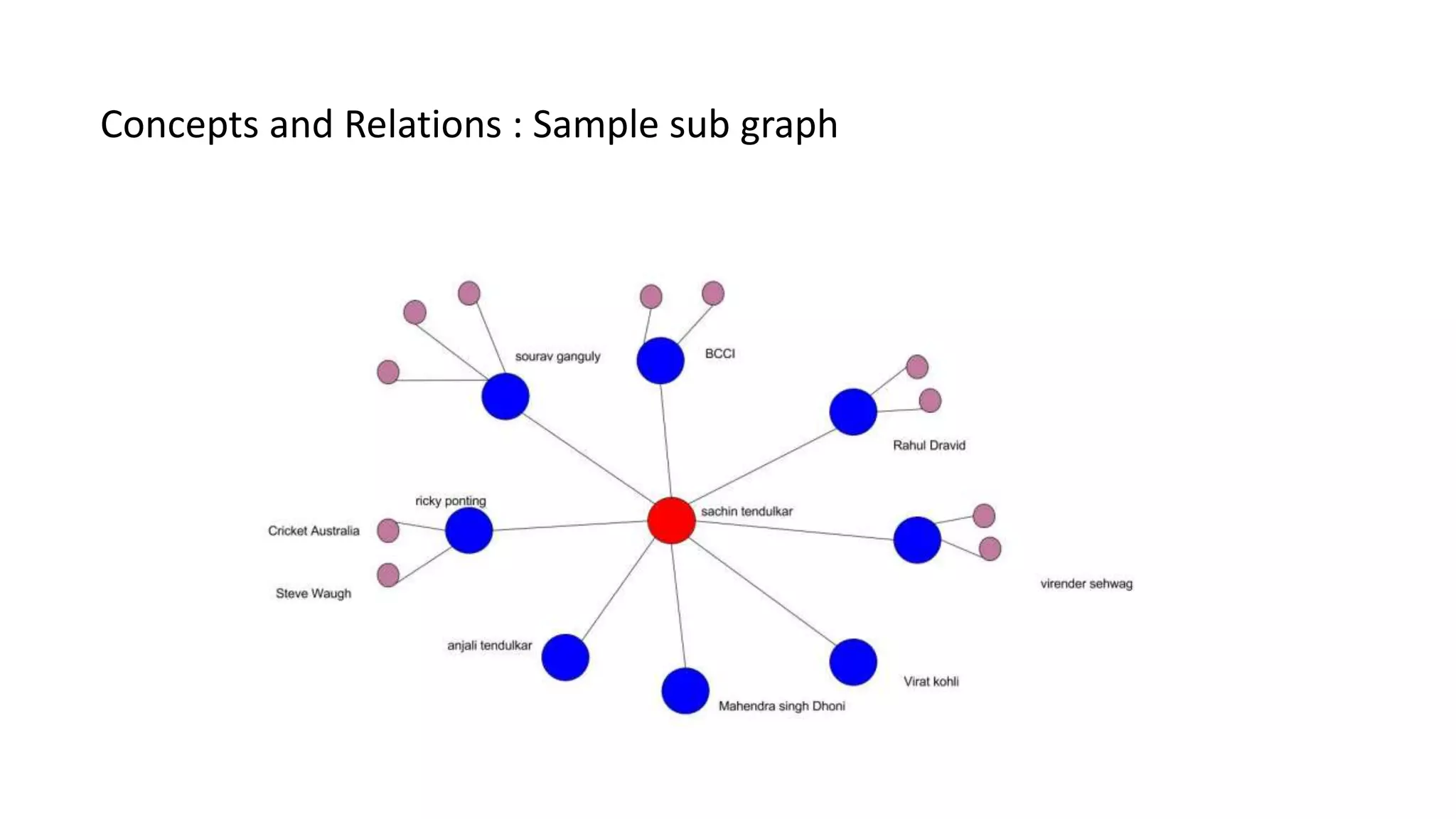




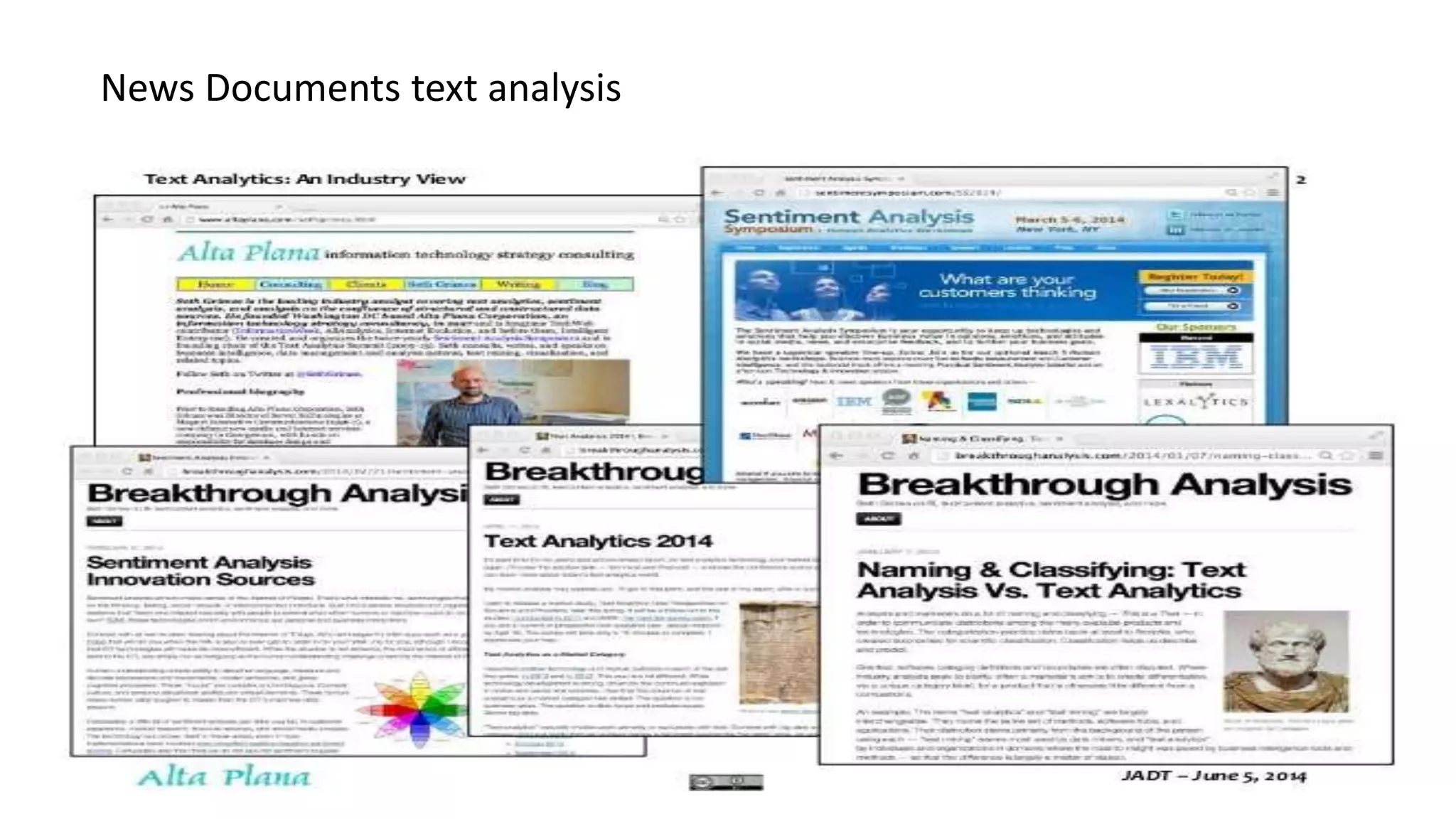
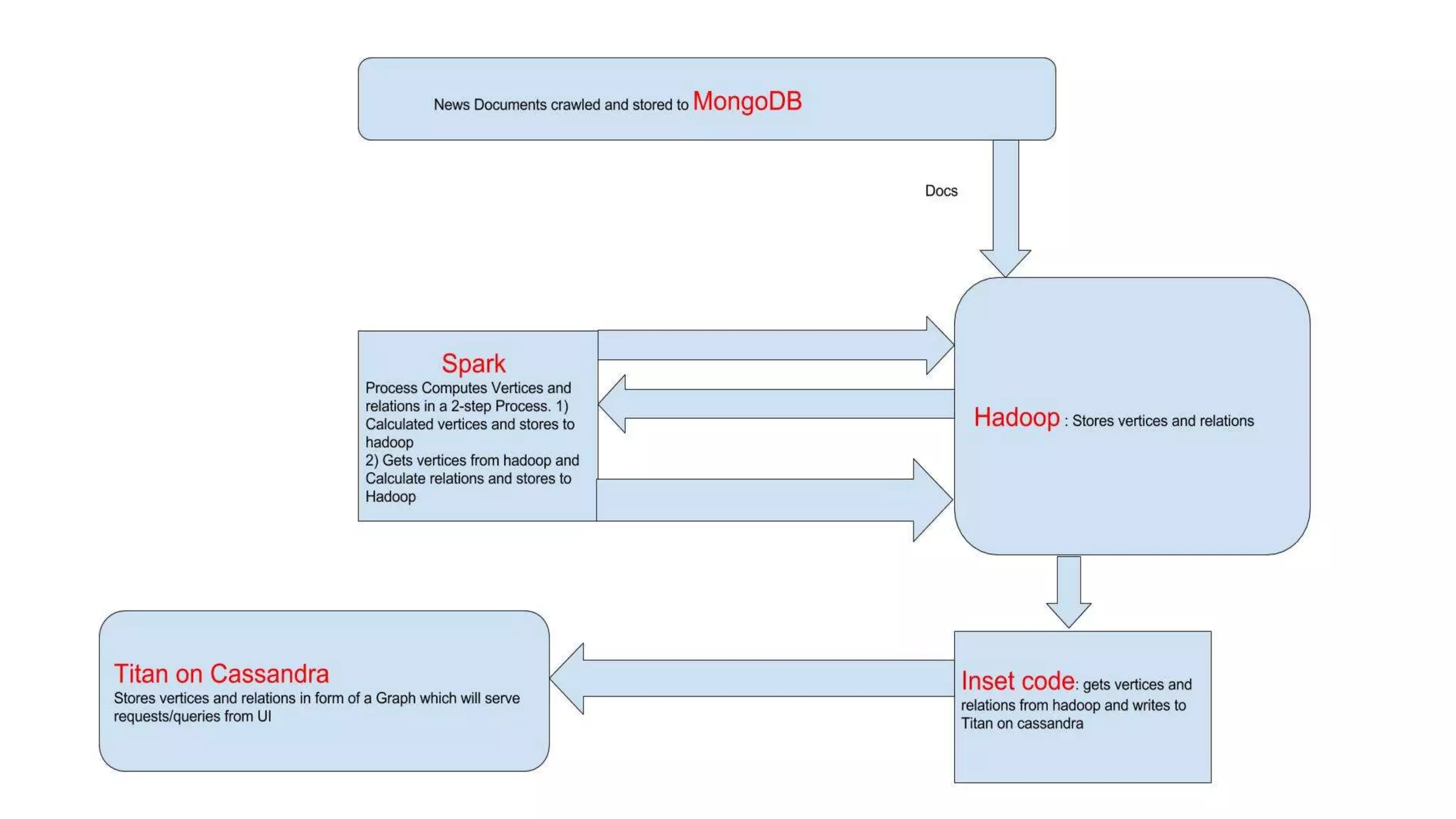
This document discusses text analysis of news documents. It outlines the architecture used, which includes crawling documents, preprocessing the text, identifying concepts and relations to build a knowledge graph. The pipeline involves two phases - identifying concepts in phase I and relations between concepts in phase II. The knowledge graph represents concepts as vertices and relations as edges. This is used to build a news explorer application that allows users to search for and explore topics and related concepts.
































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
