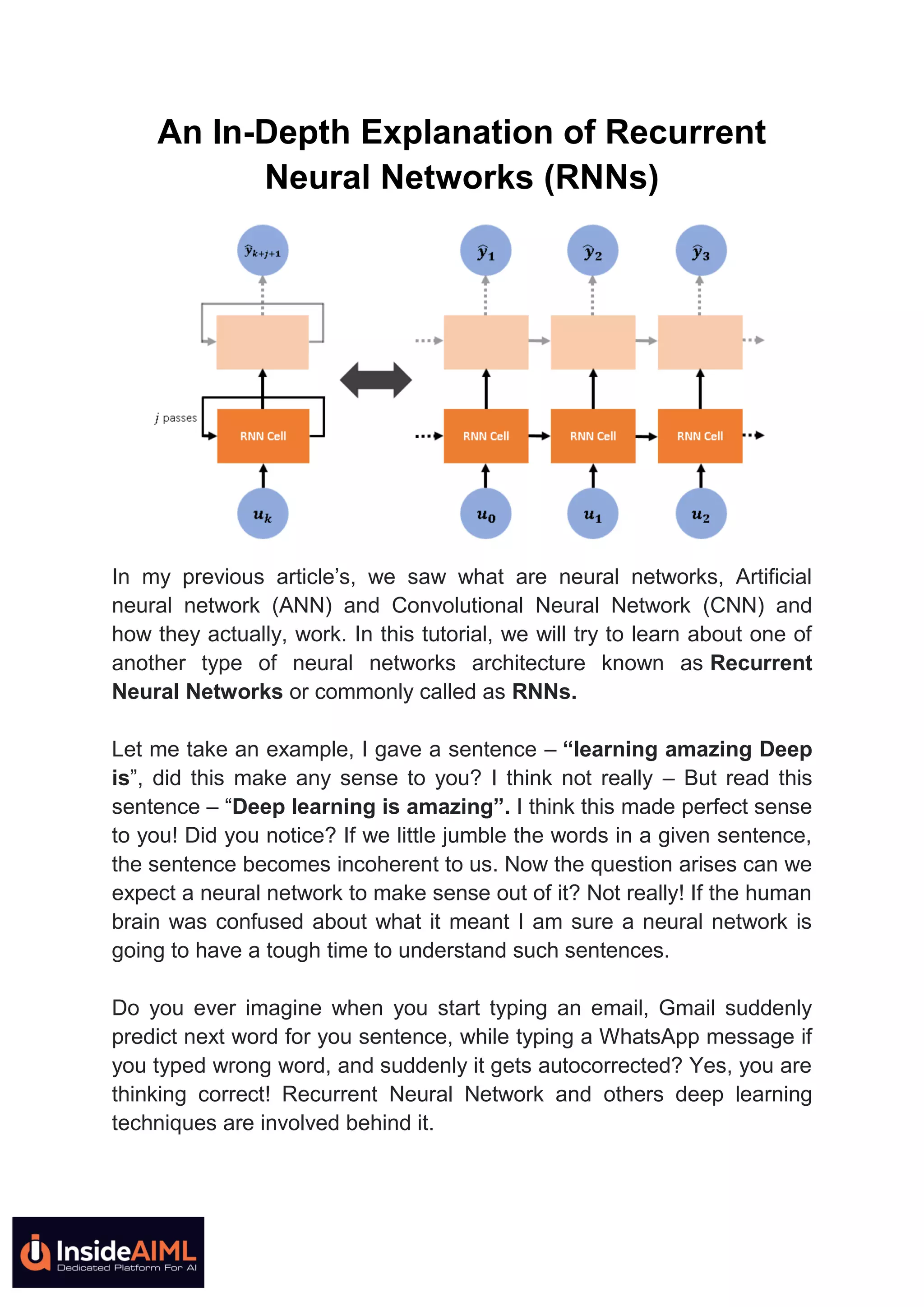
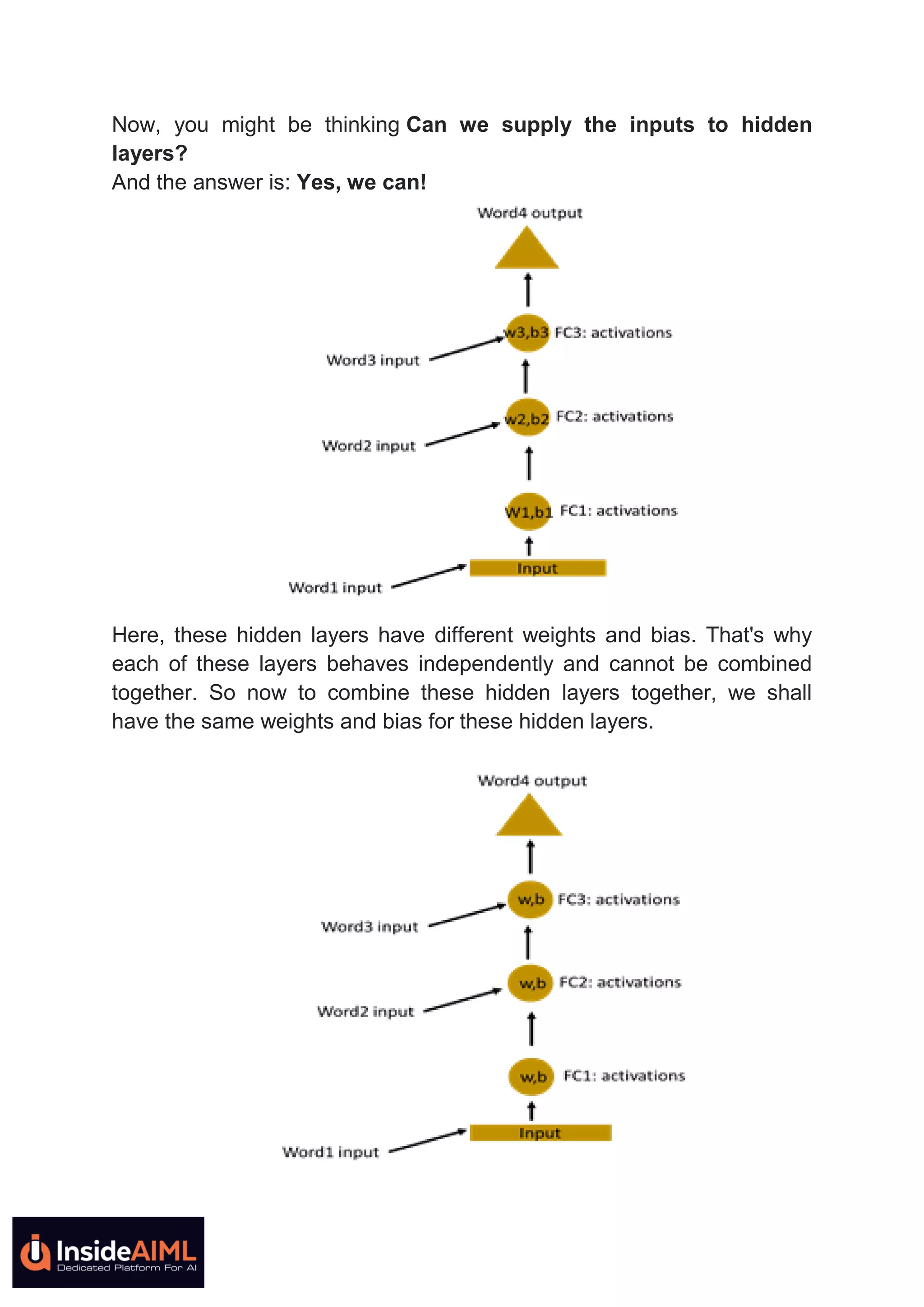
This document provides an in-depth explanation of recurrent neural networks (RNNs). It begins by discussing how RNNs can understand sequential data like text where order matters by having "memory" of previous inputs. It then discusses how standard RNNs have a vanishing gradient problem that prevents them from learning long-term dependencies. More advanced RNN models like LSTMs and GRUs solve this issue by using gates to better control the flow of information. The document concludes by noting how RNNs work by applying the same weights and activation functions at each time step as it processes sequential inputs.