Download as PDF, PPTX





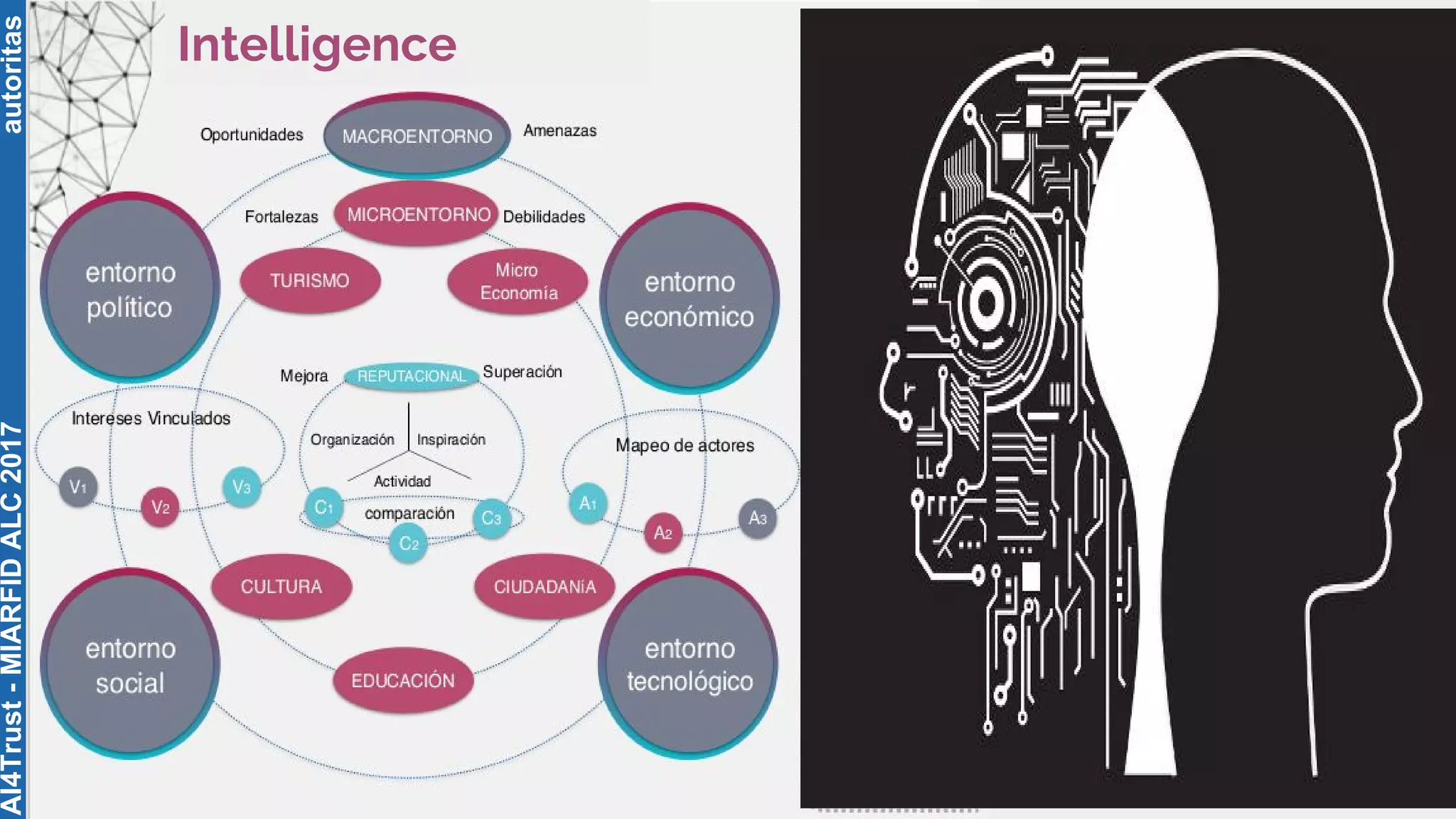


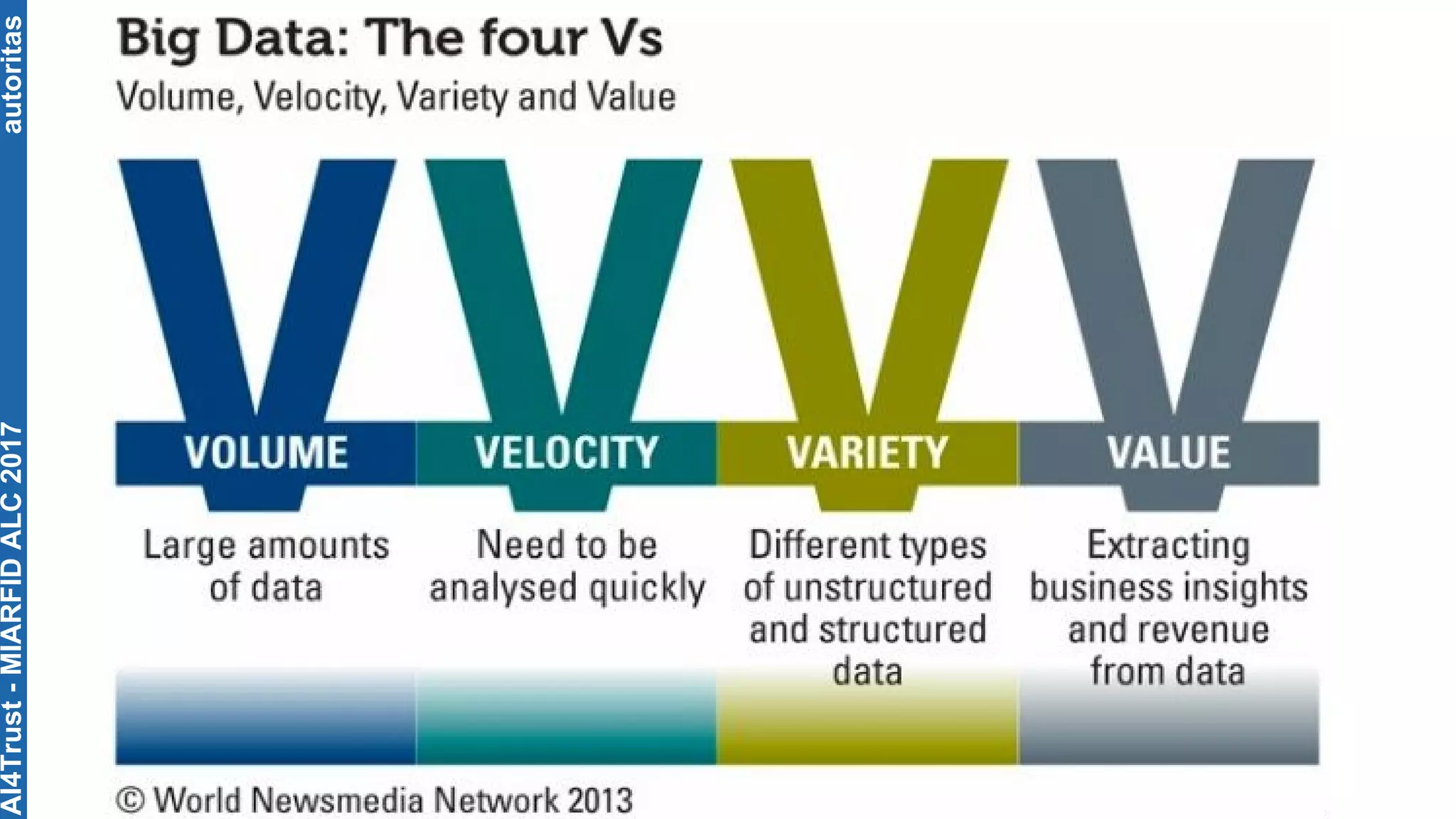

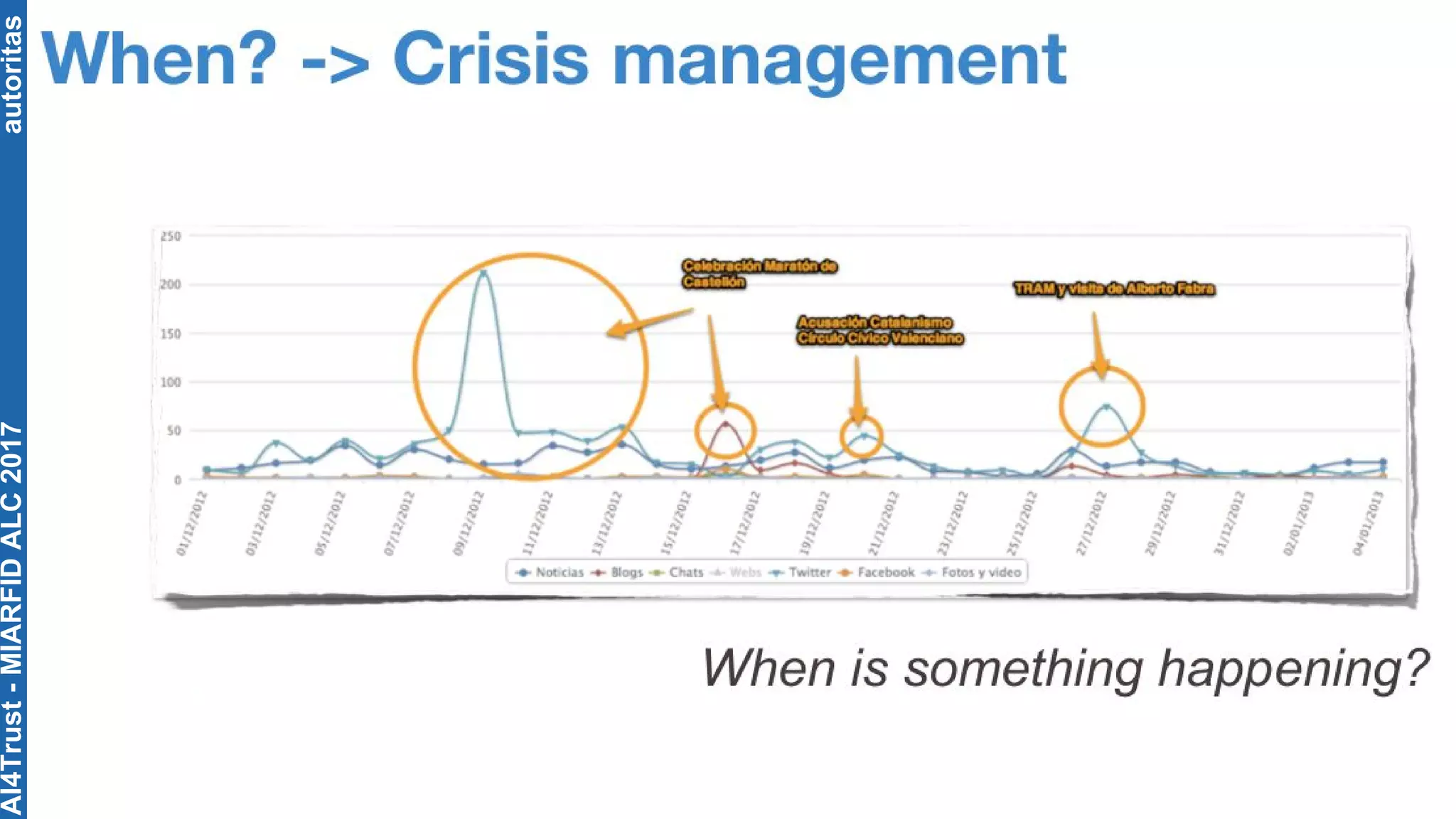

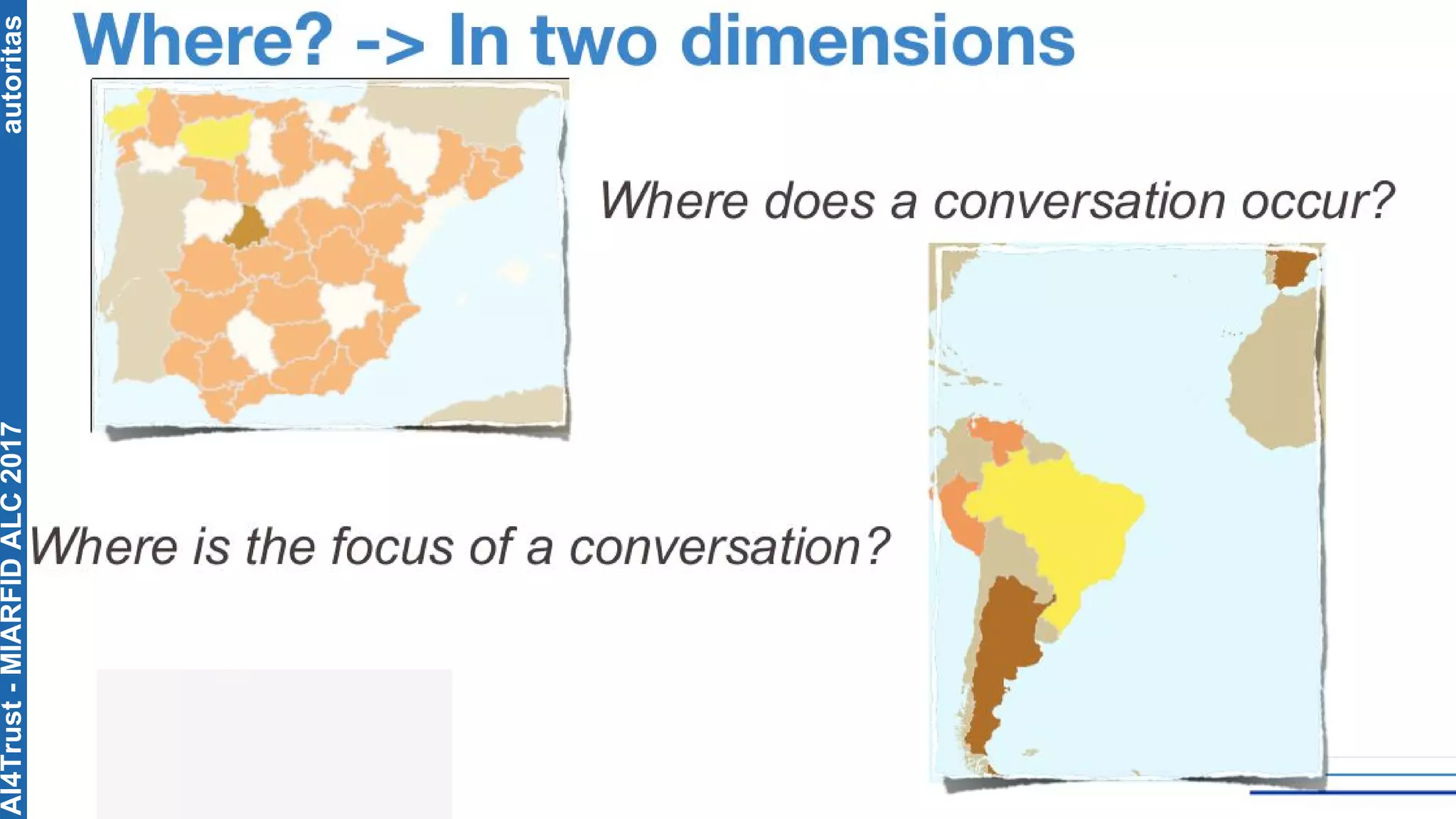


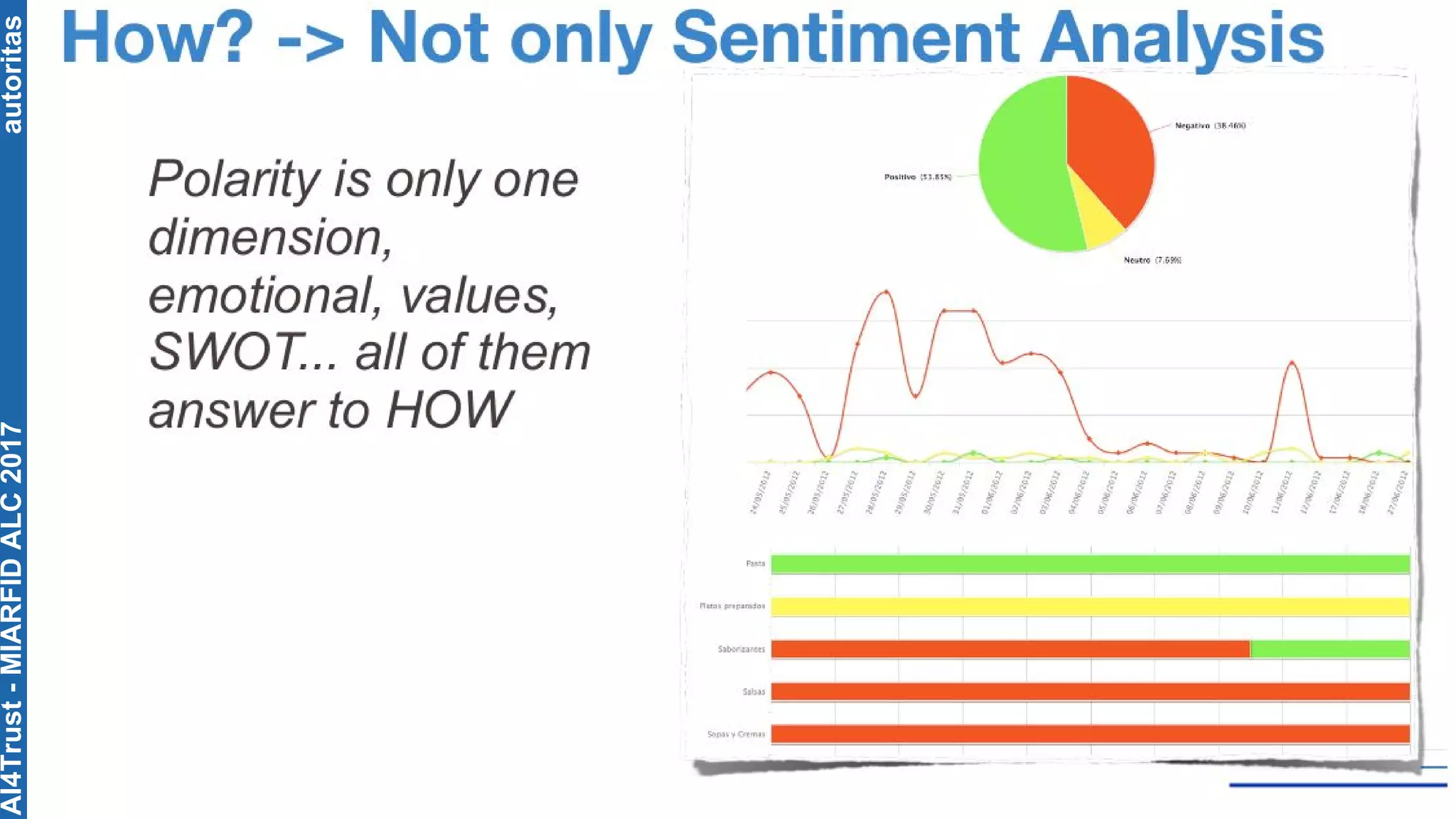




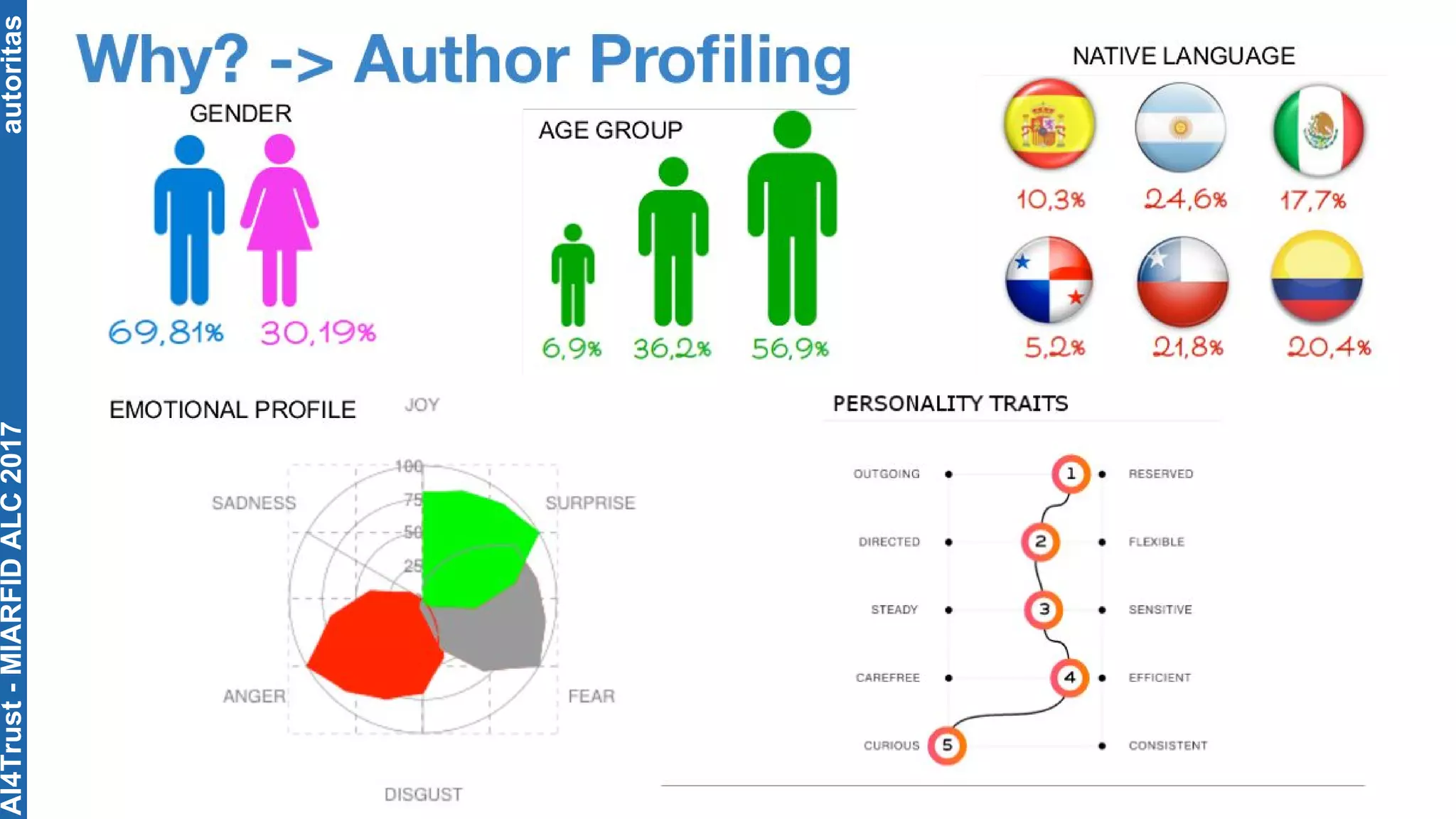

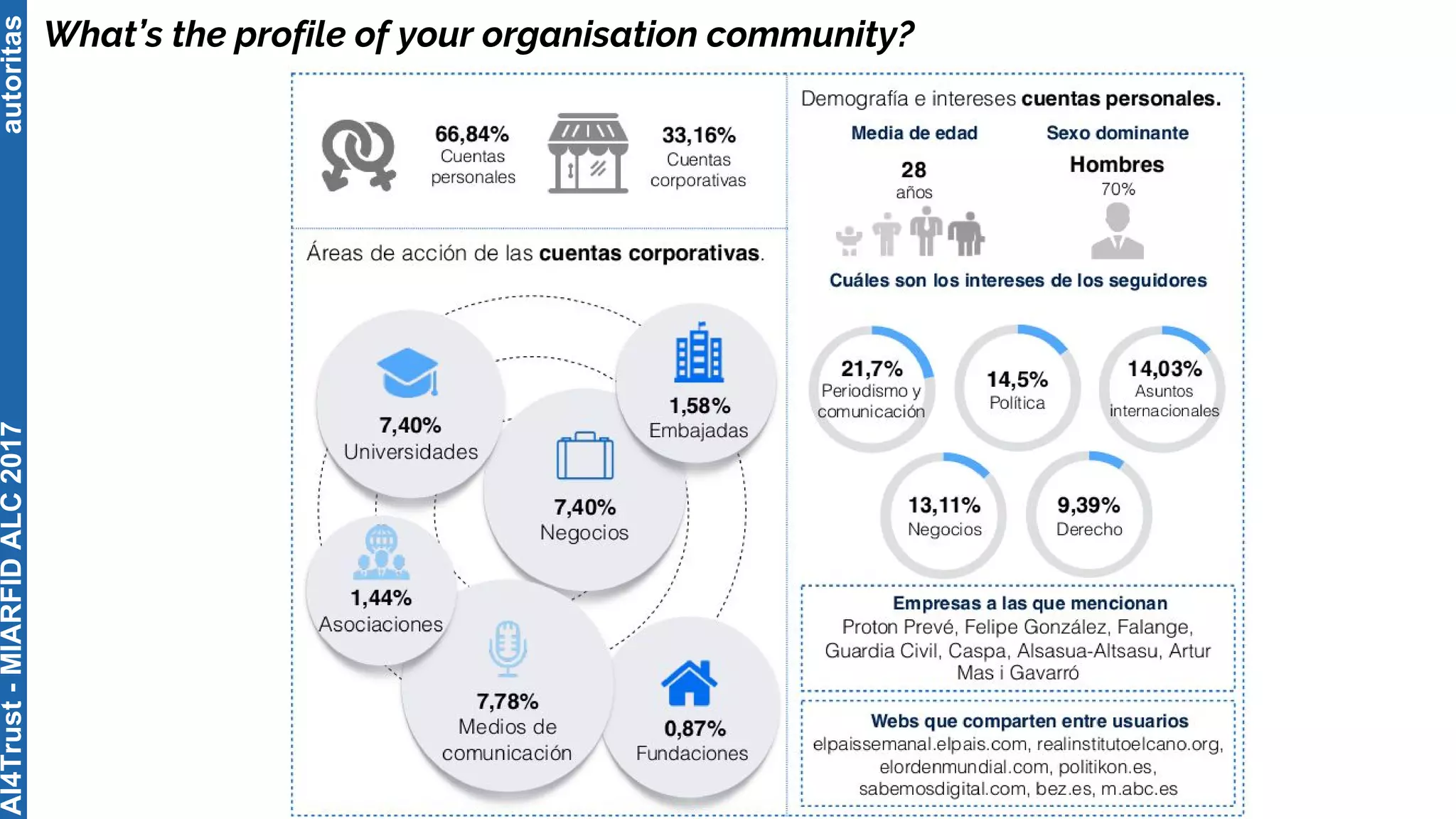
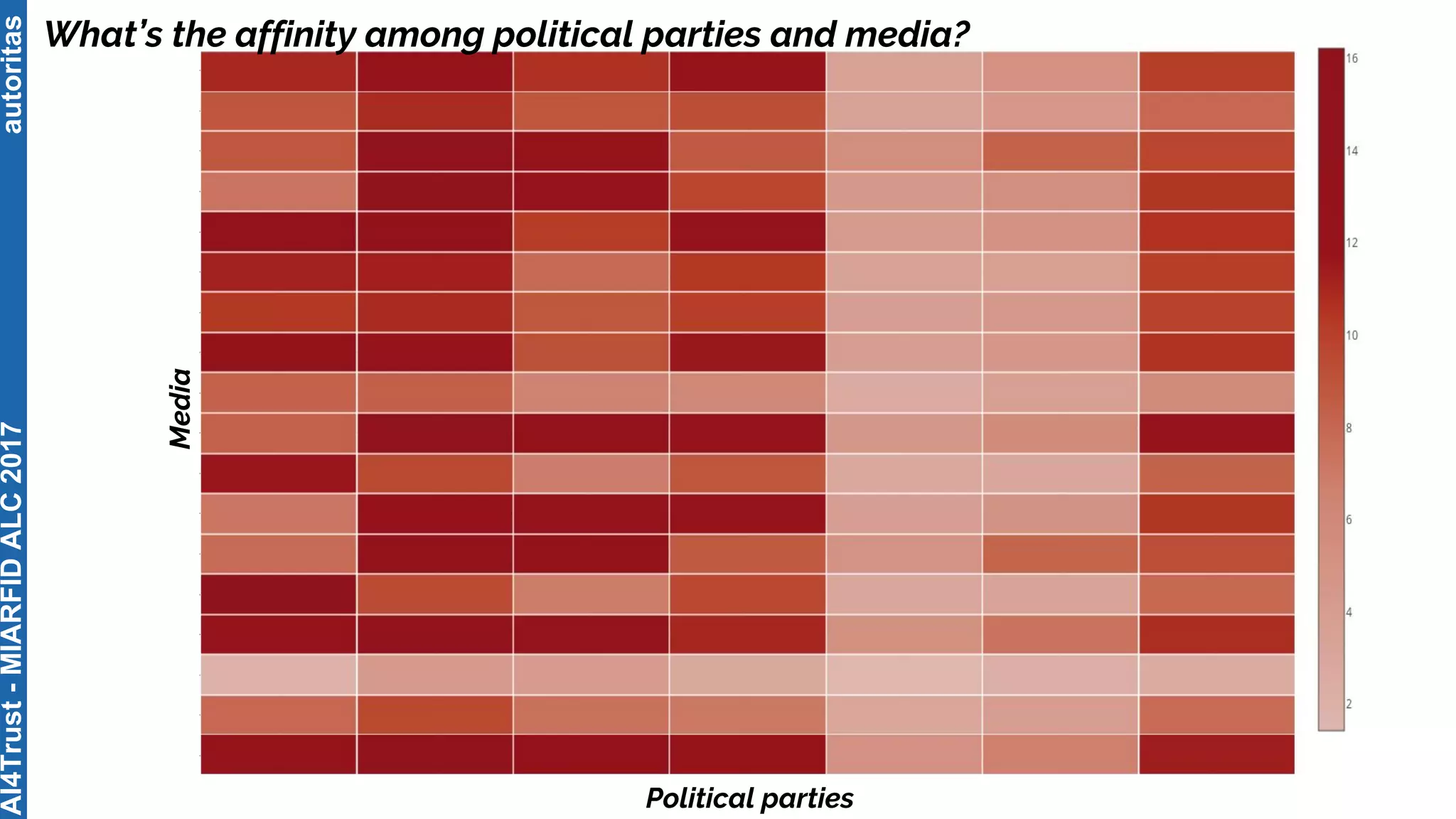






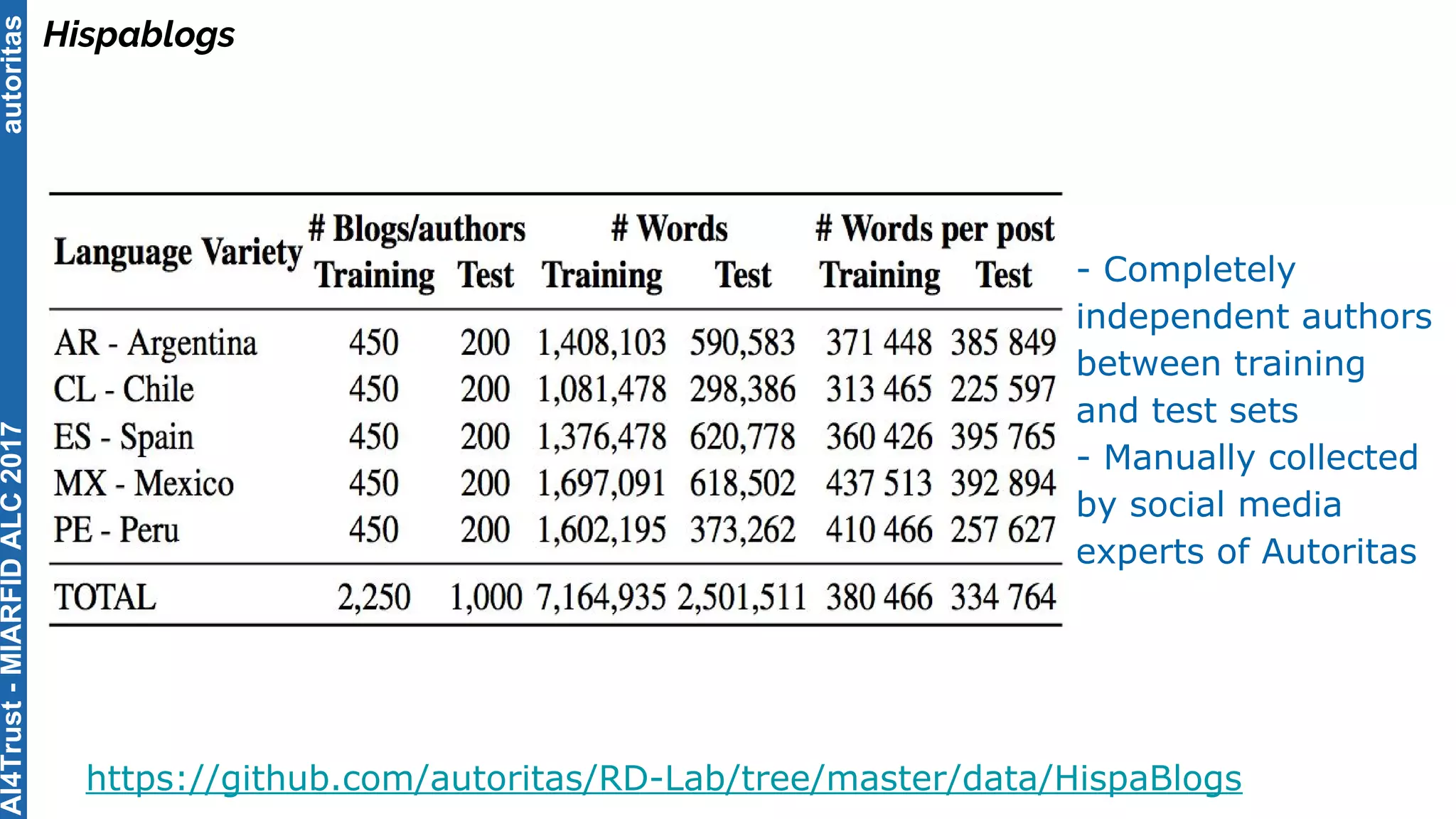
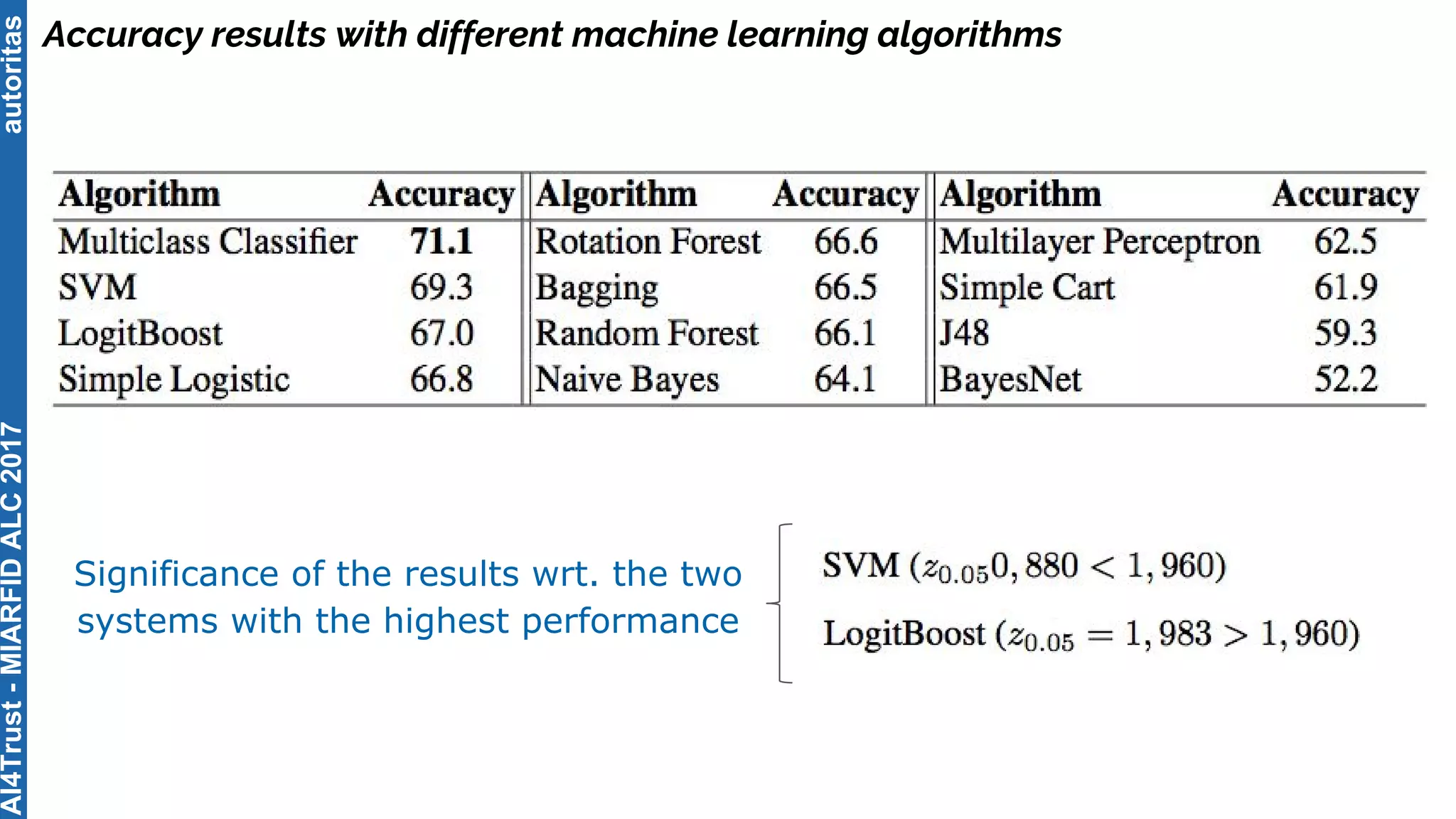
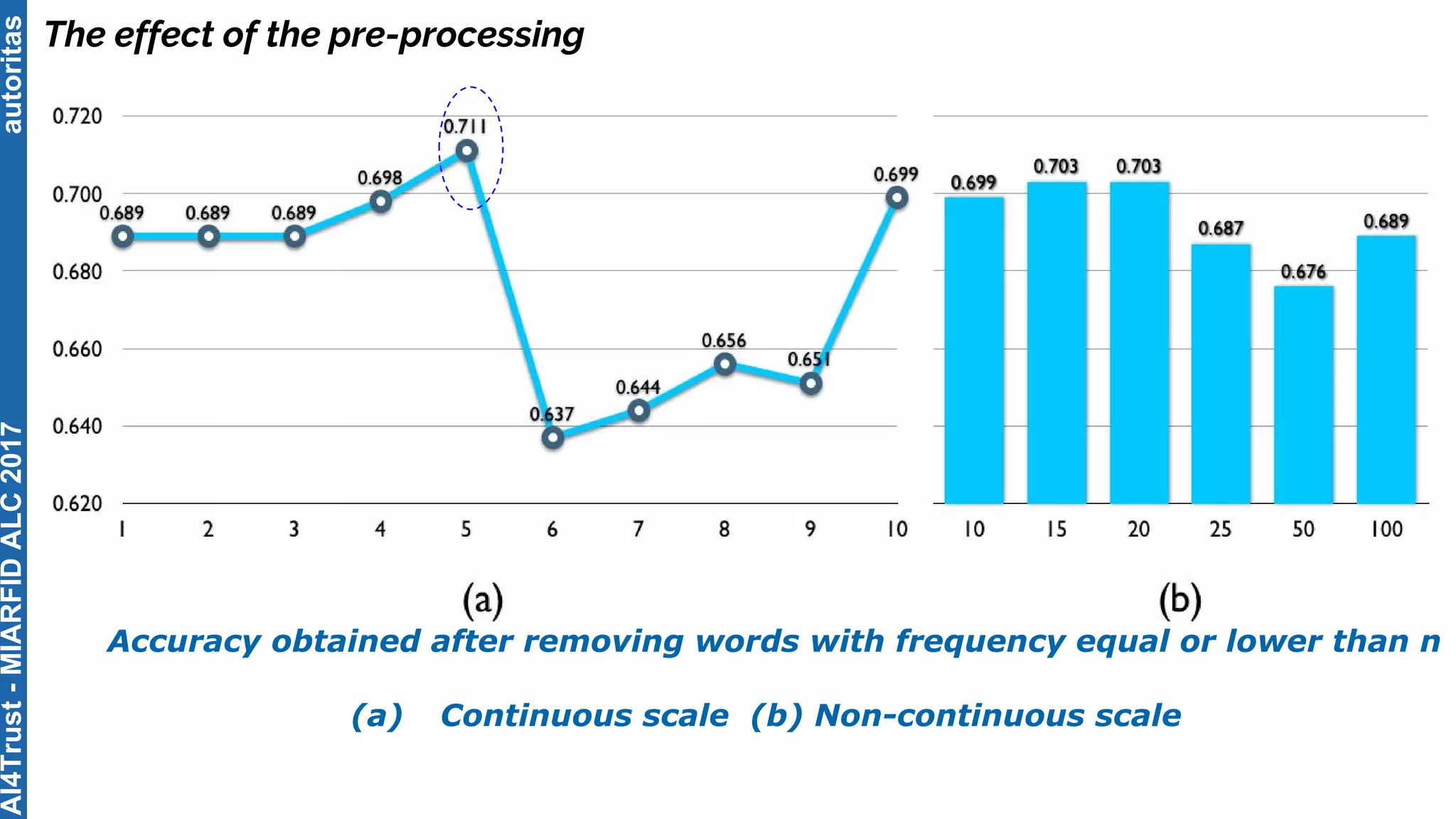
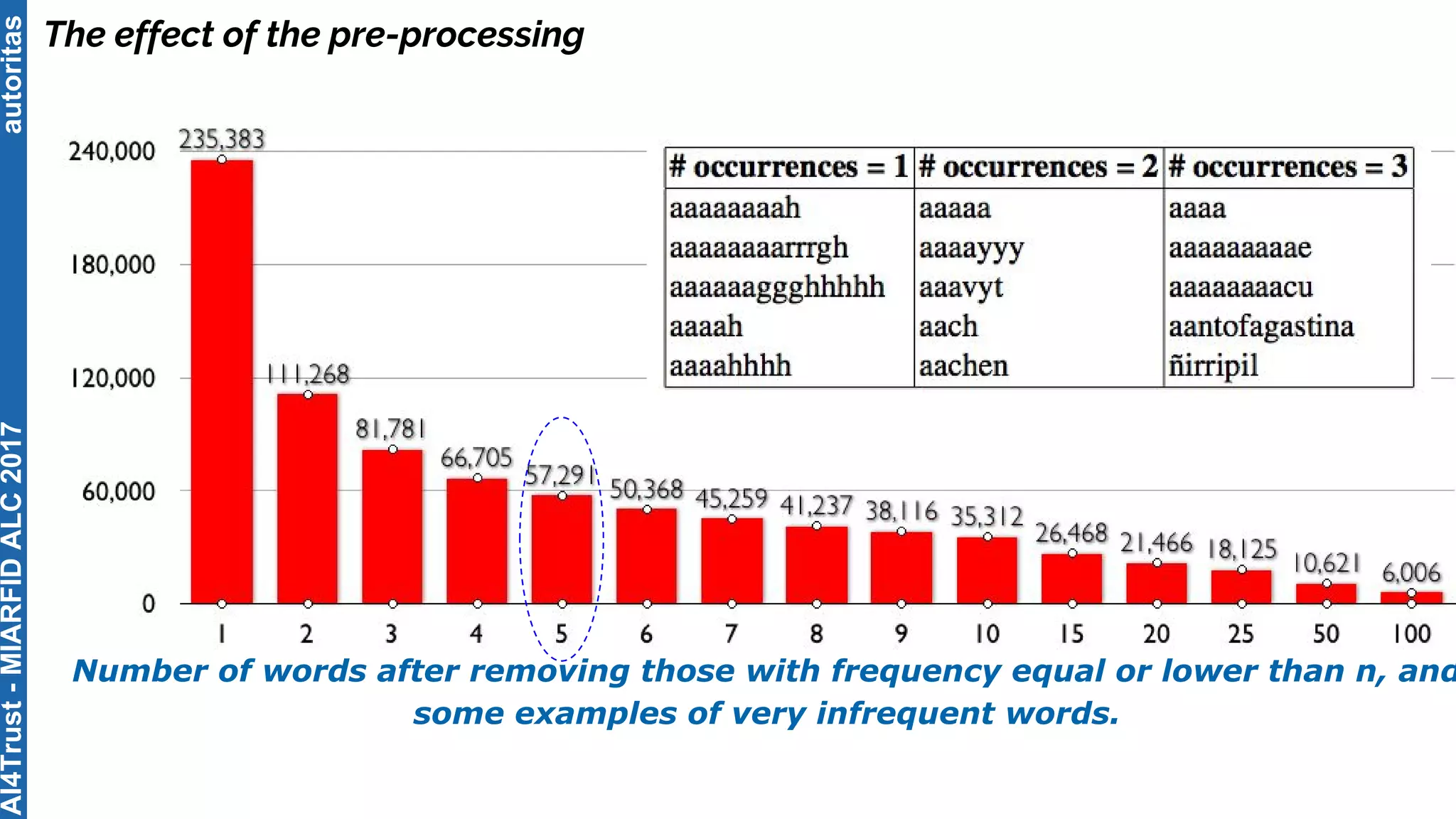
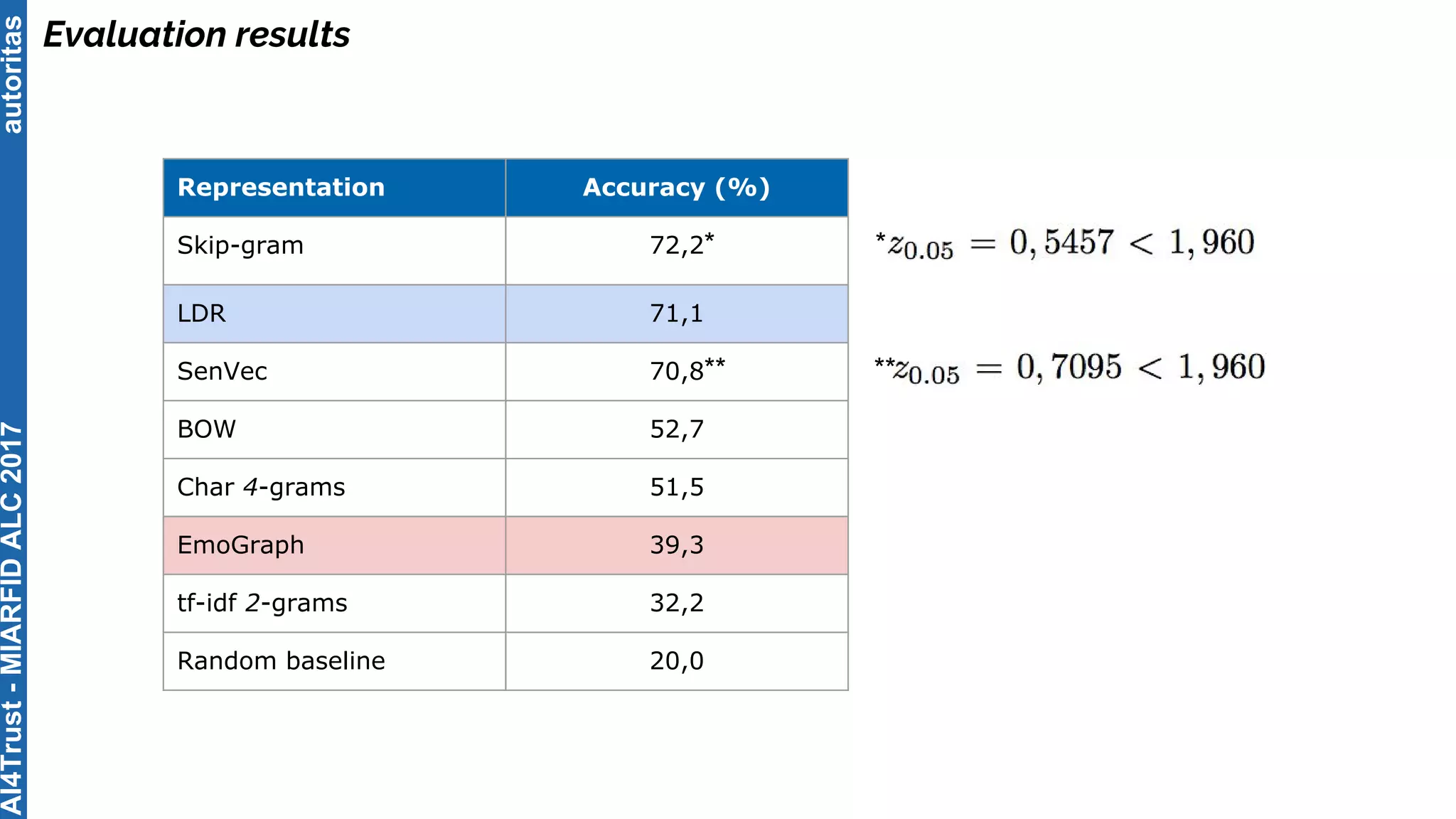
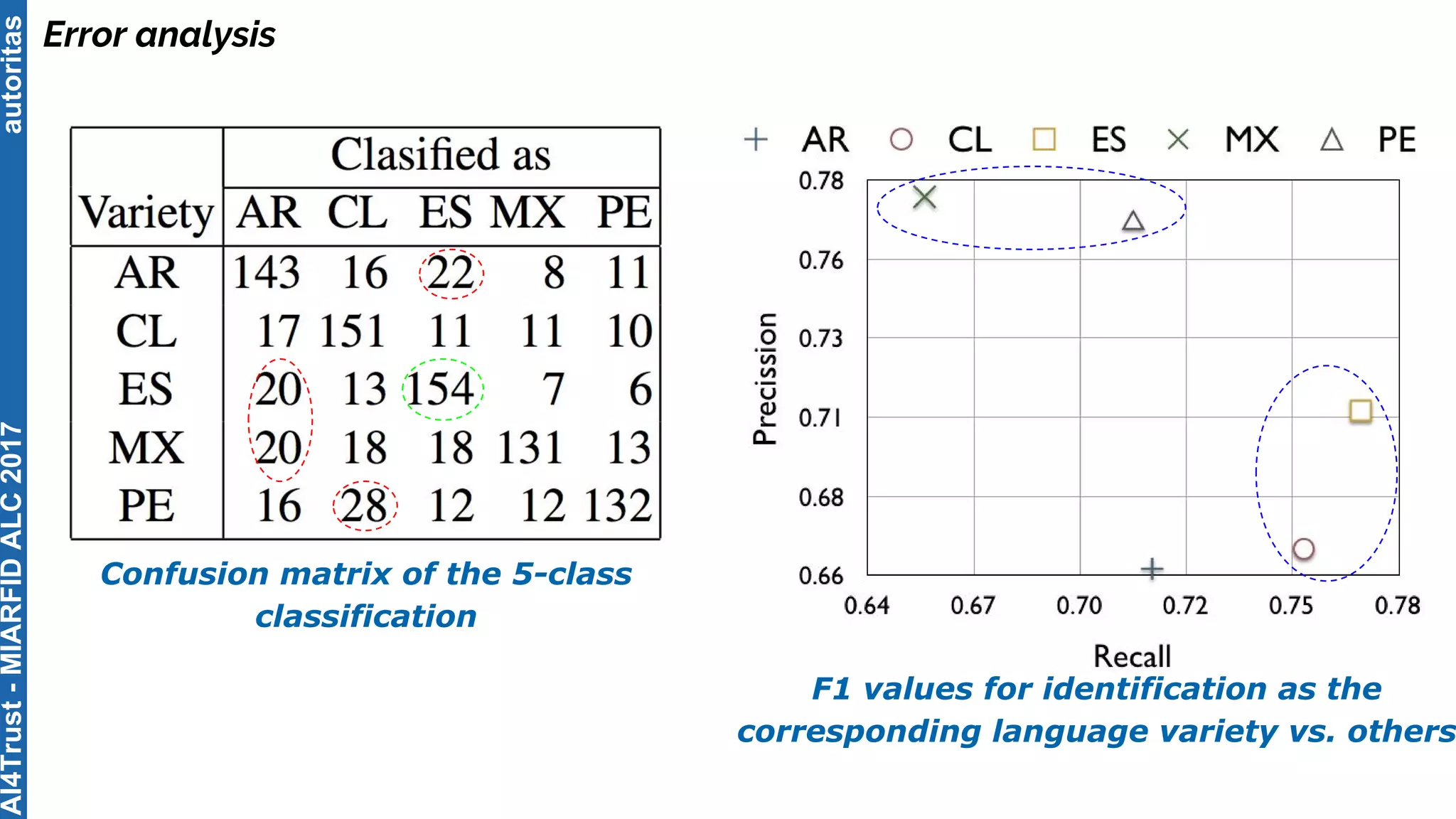
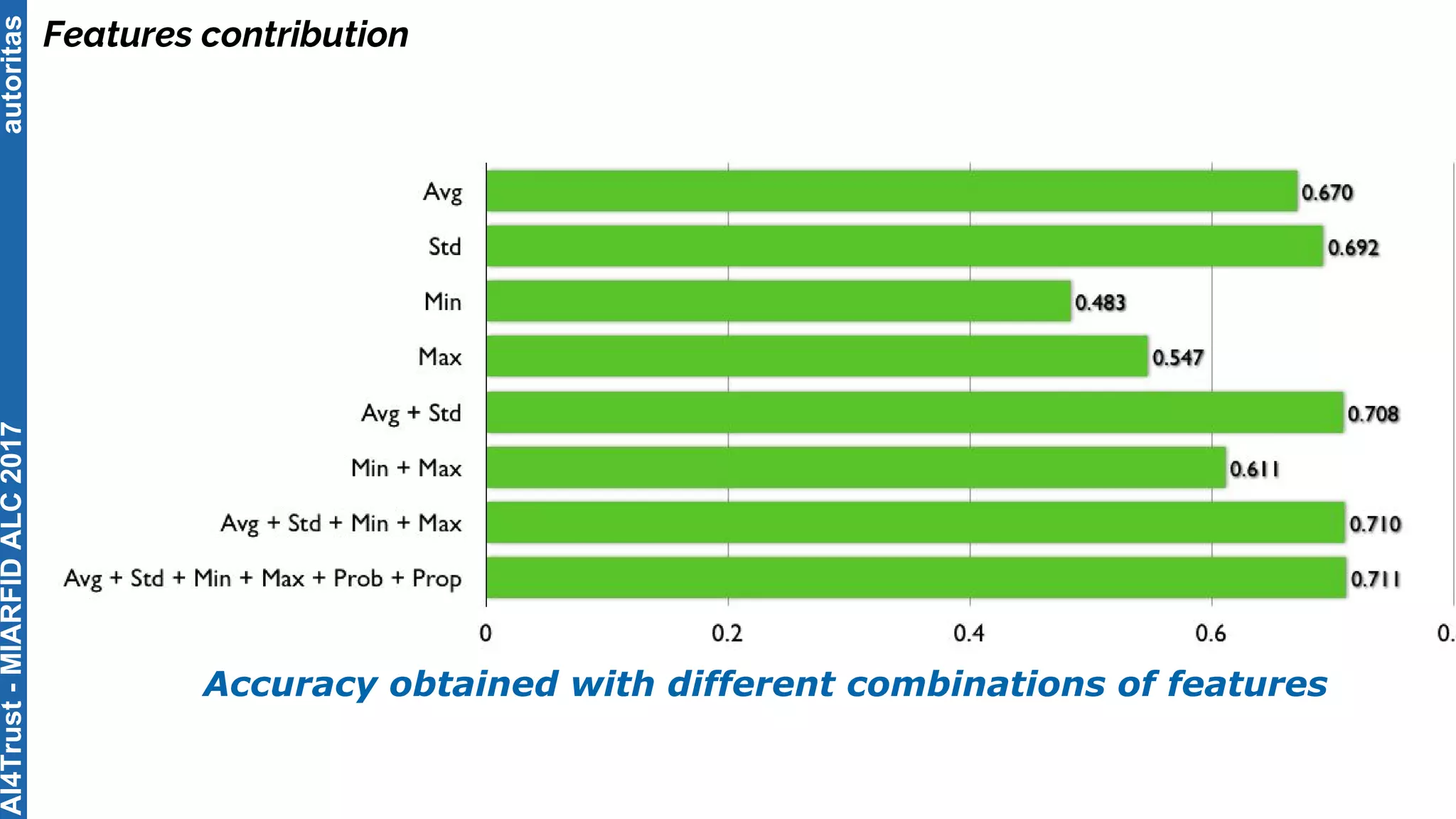
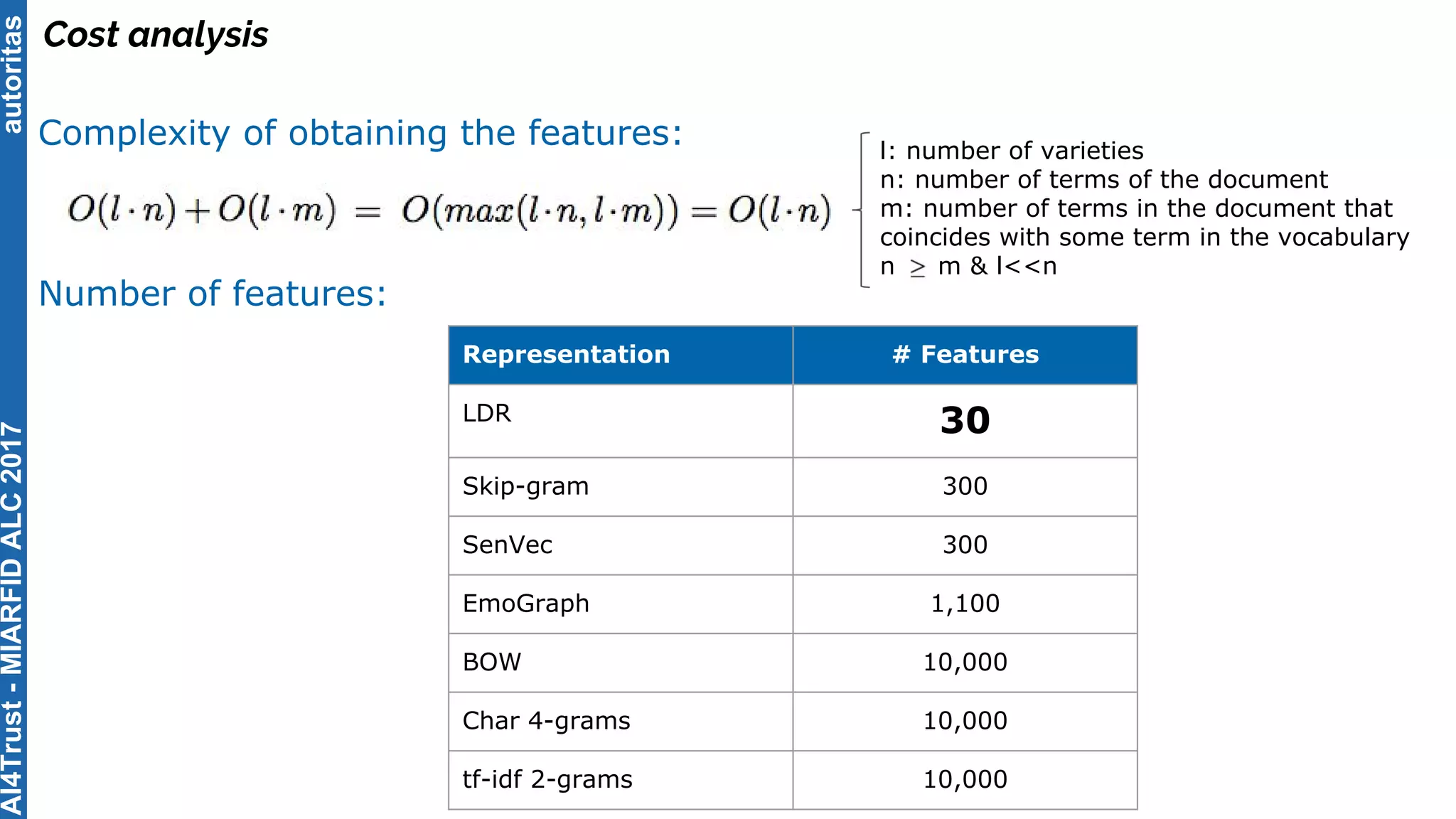
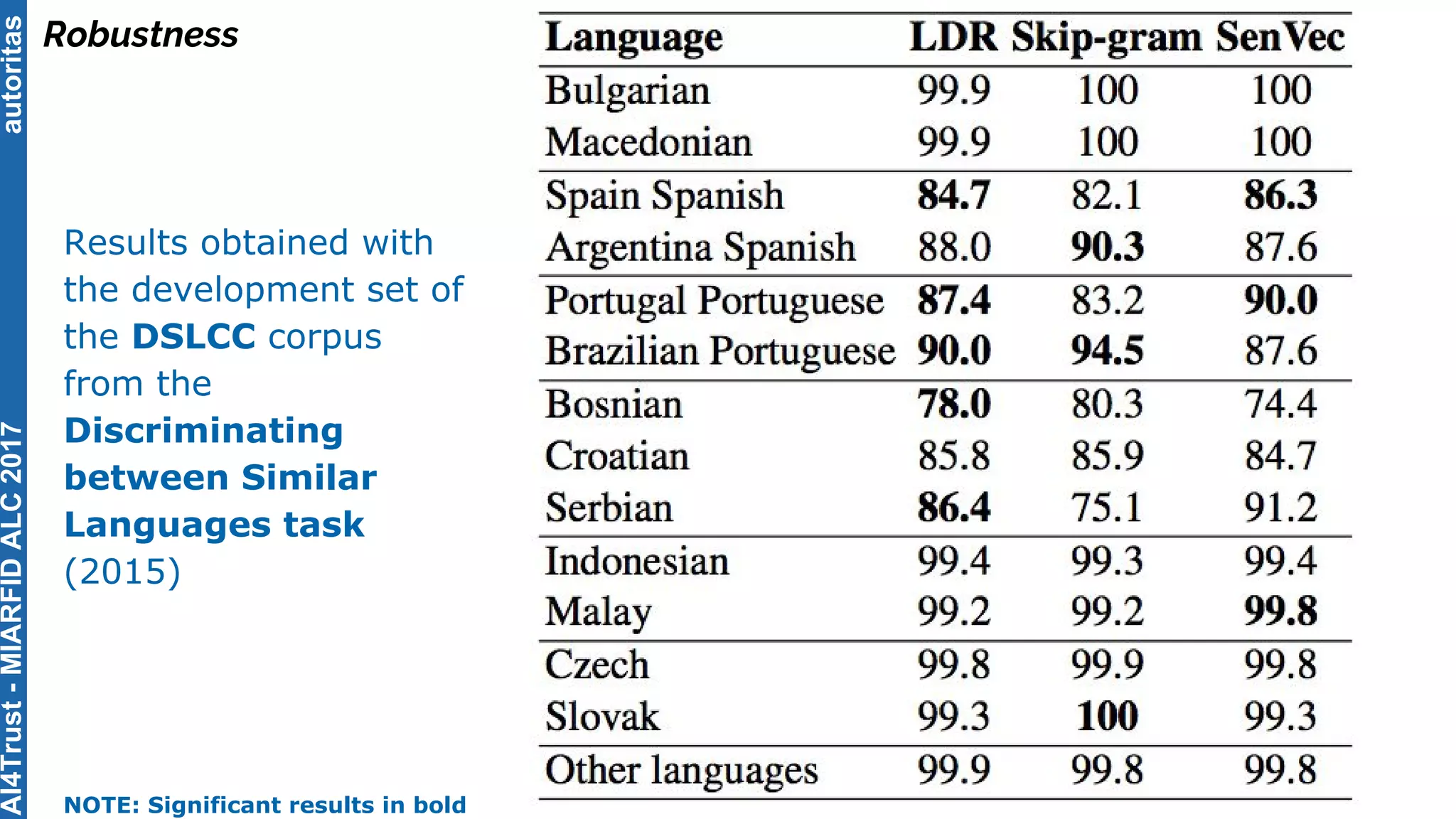
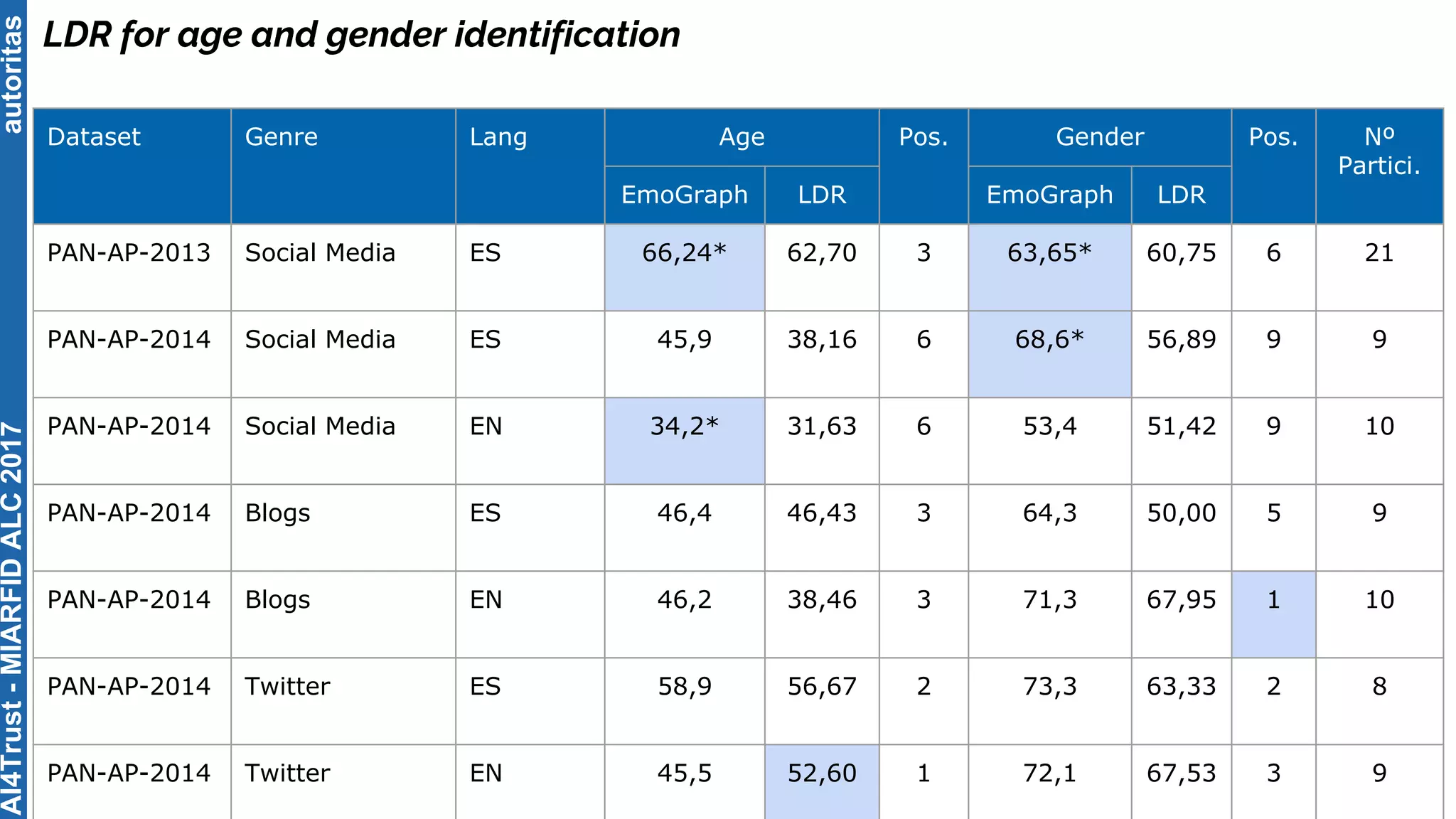






The document outlines the AI4Trust master's program at Universitat Politècnica de València and discusses eight transformative changes in humanity driven by artificial intelligence and big data. It emphasizes the importance of language variety identification for improving geotagging and addresses the effectiveness of different machine learning models for tasks such as age and gender identification. Additionally, it presents the development and contributions of a low dimensionality representation approach, which significantly enhances accuracy in analyzing linguistic variations.























































