Download to read offline


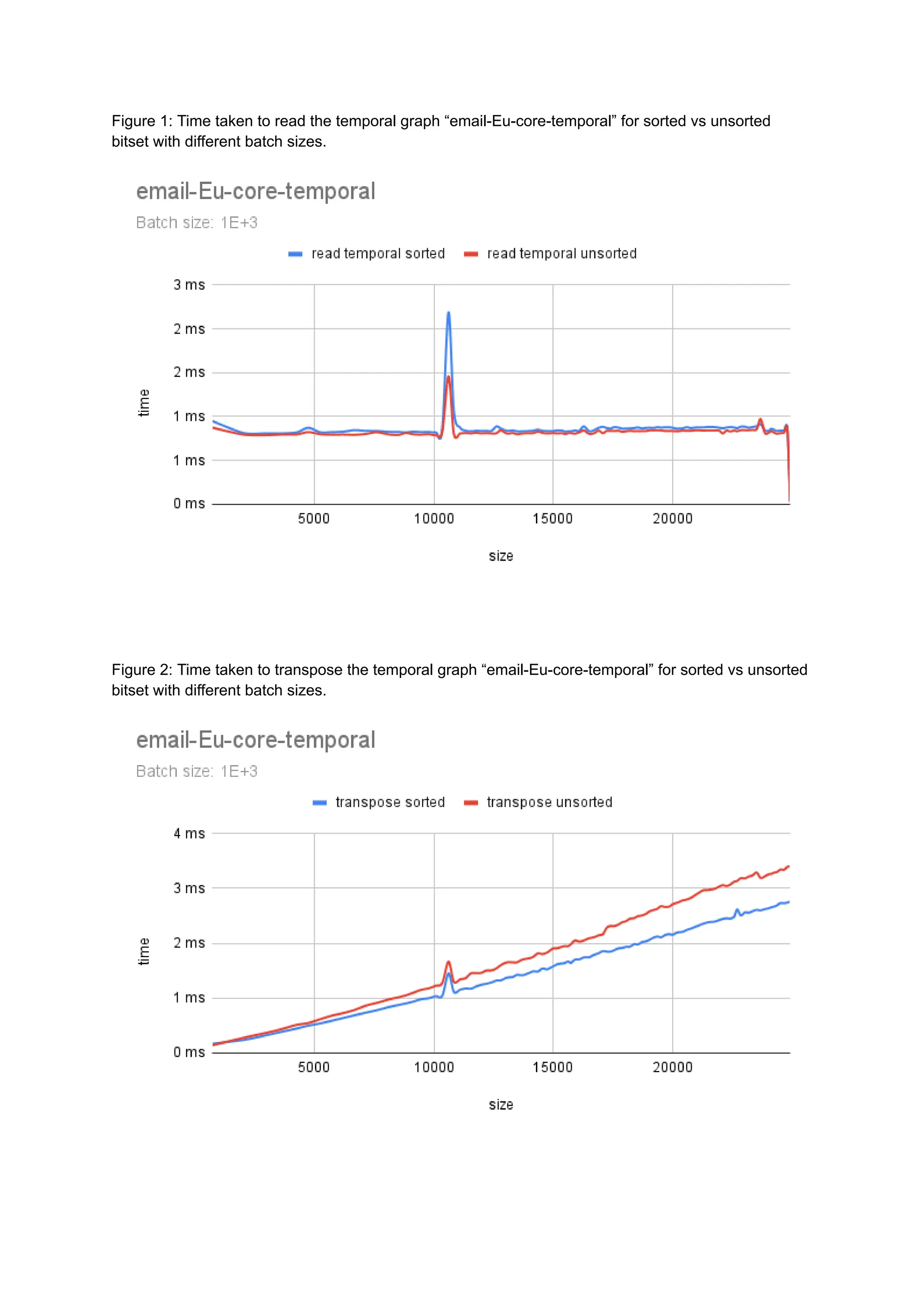
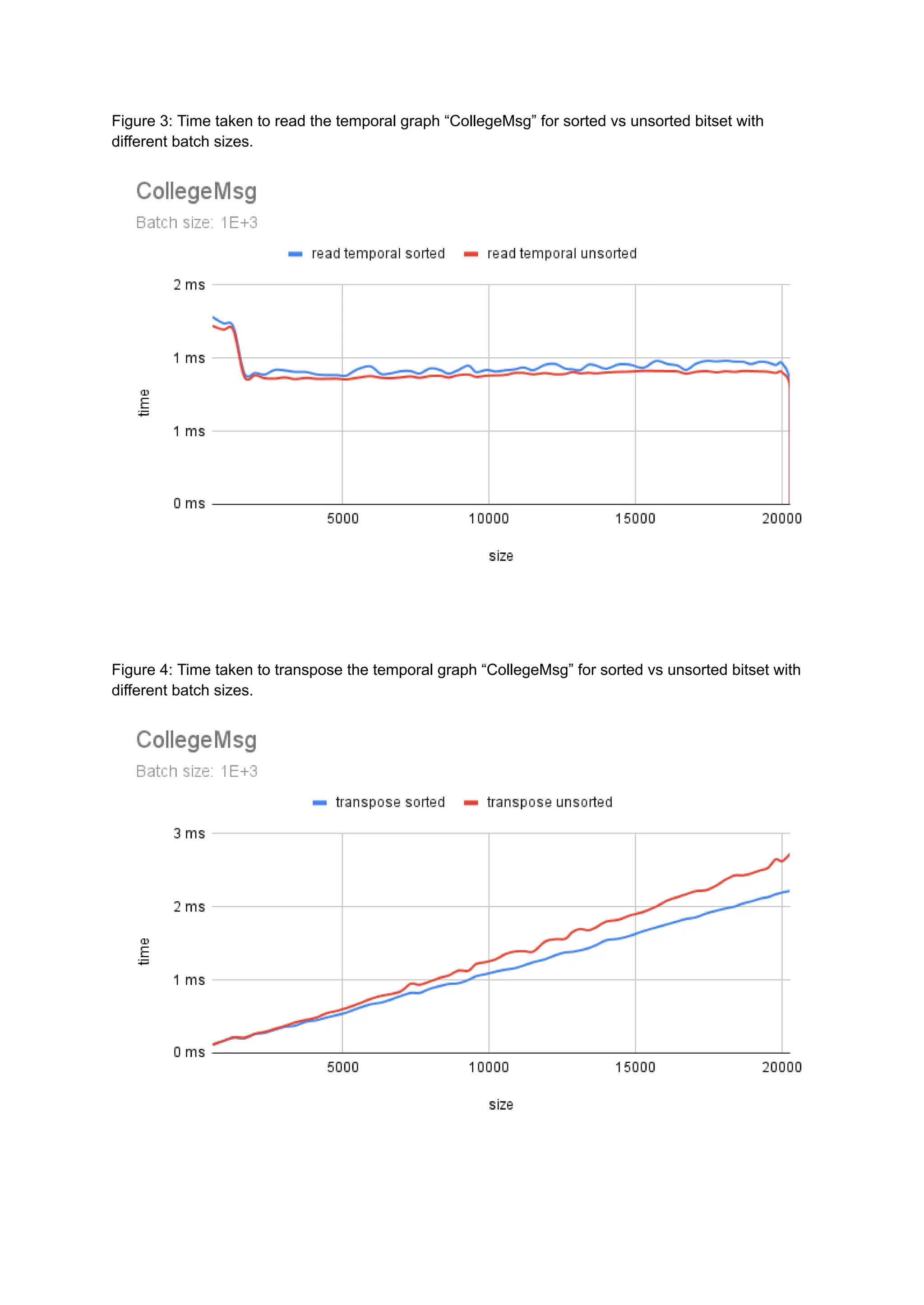
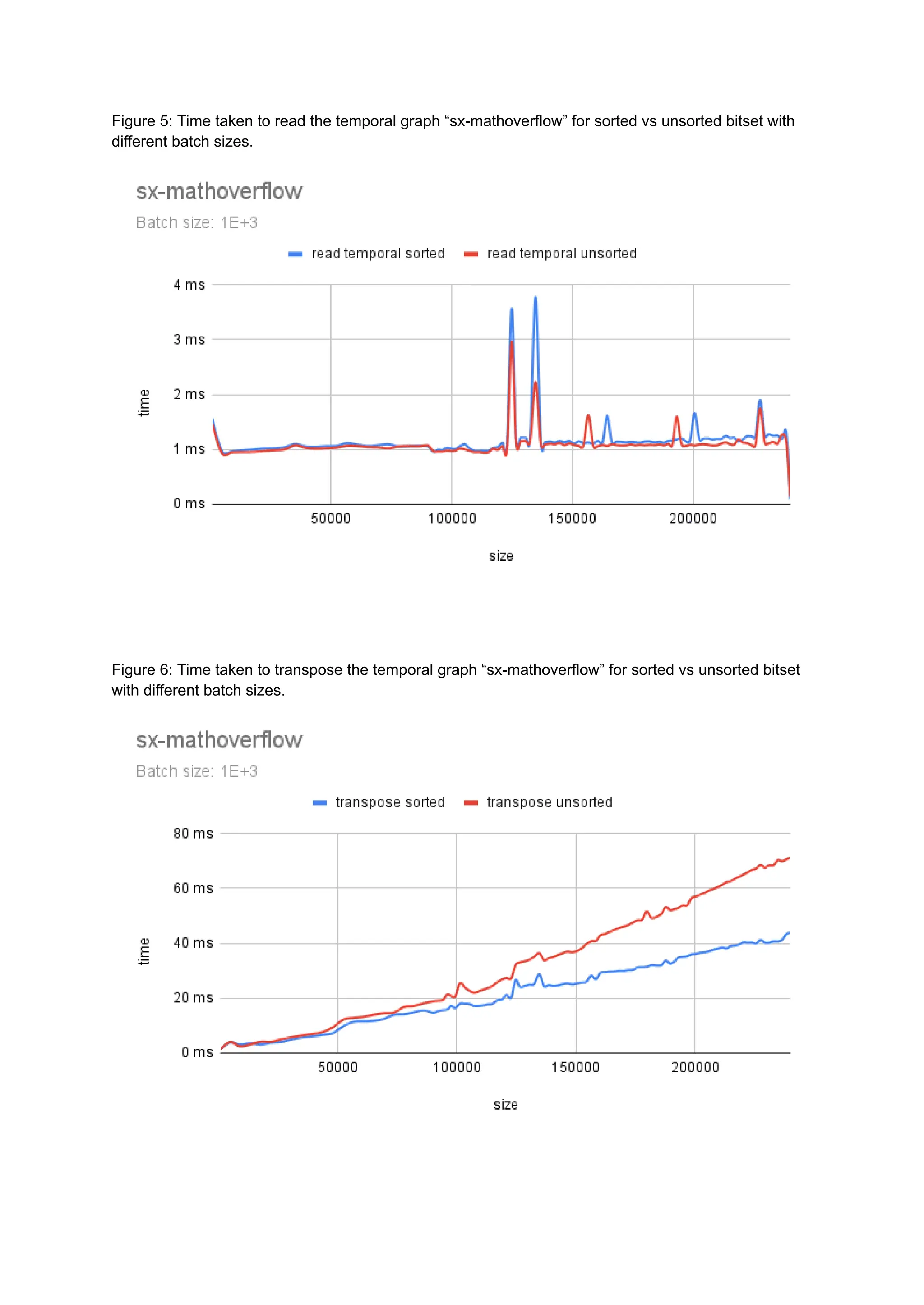
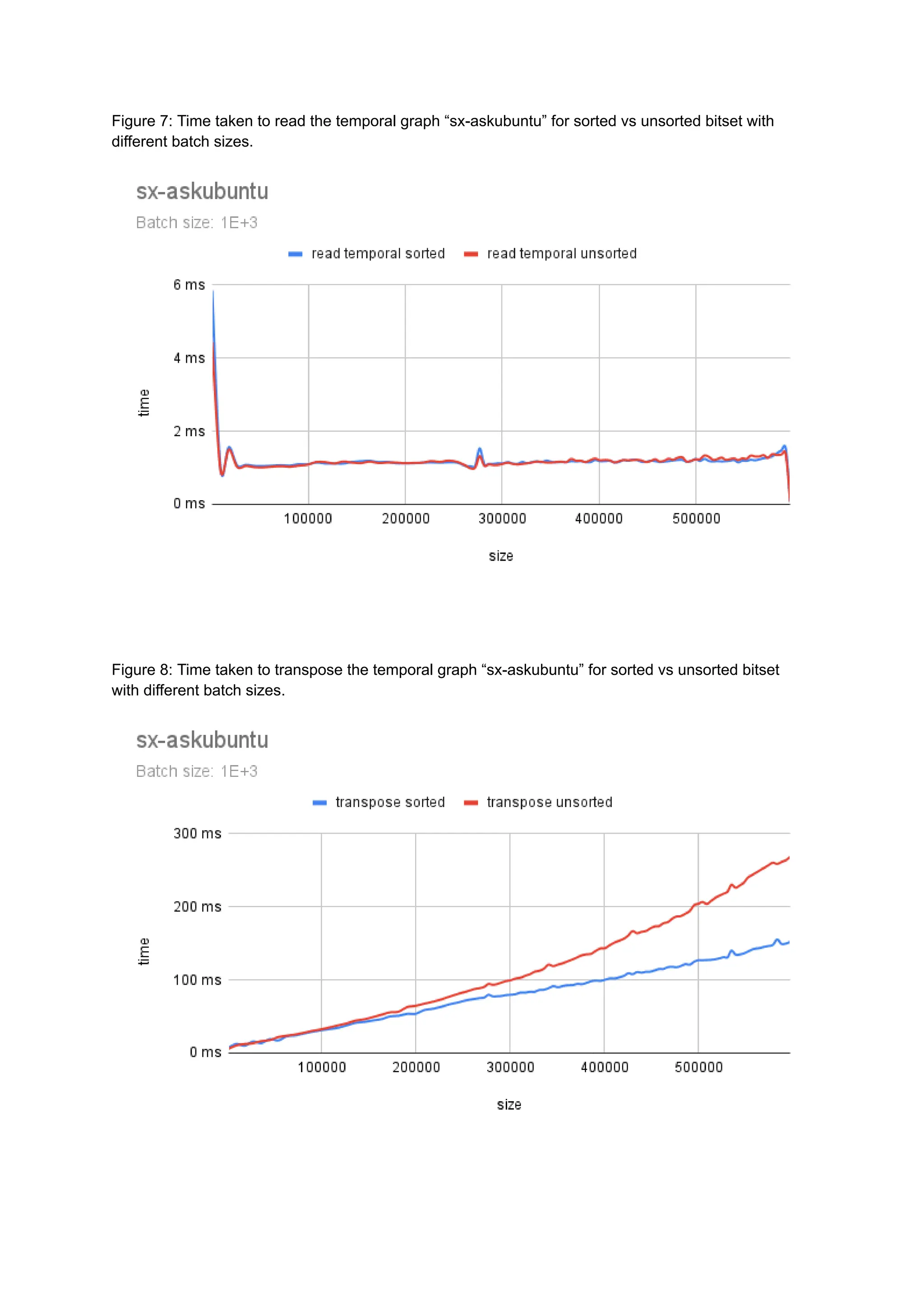
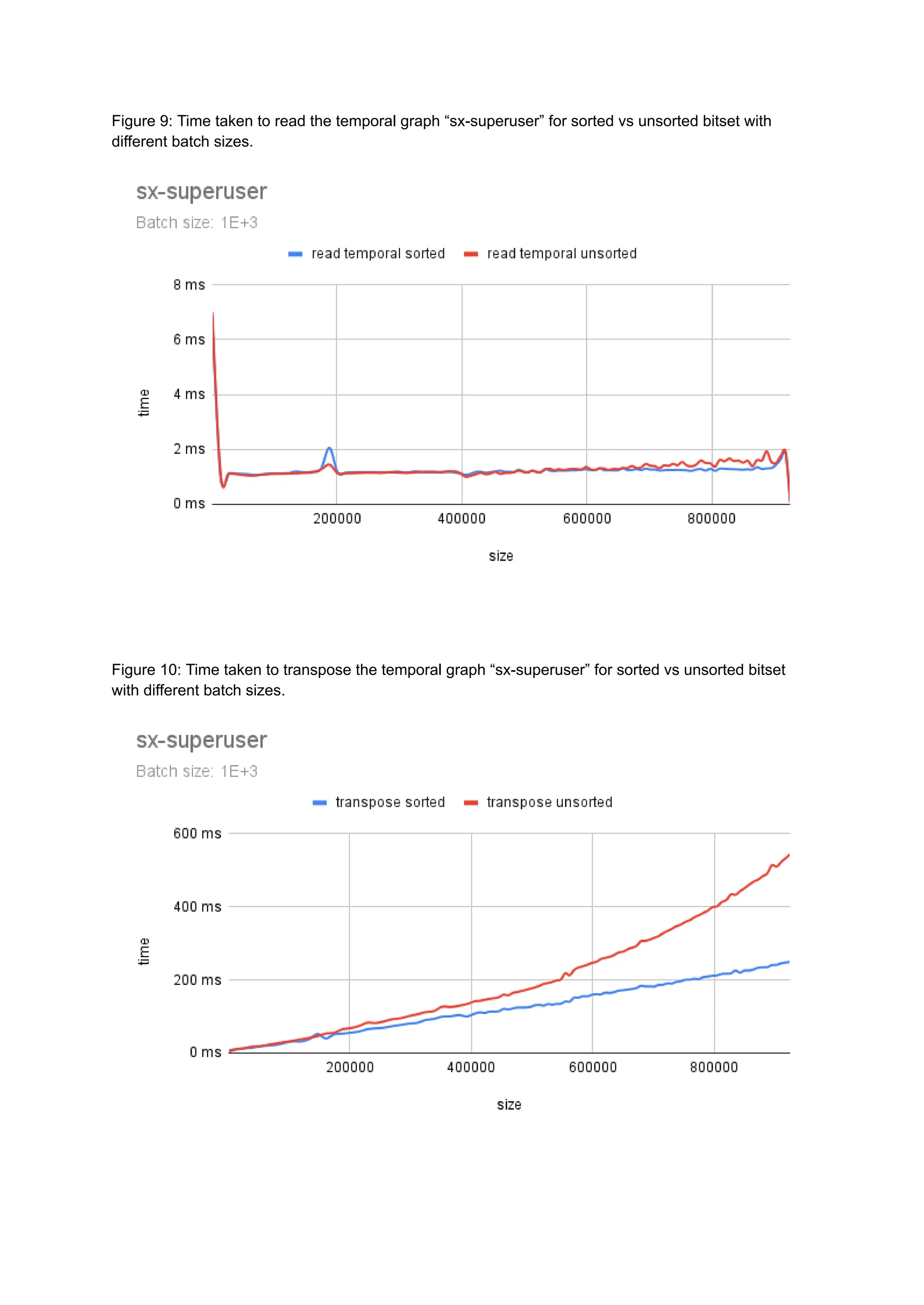
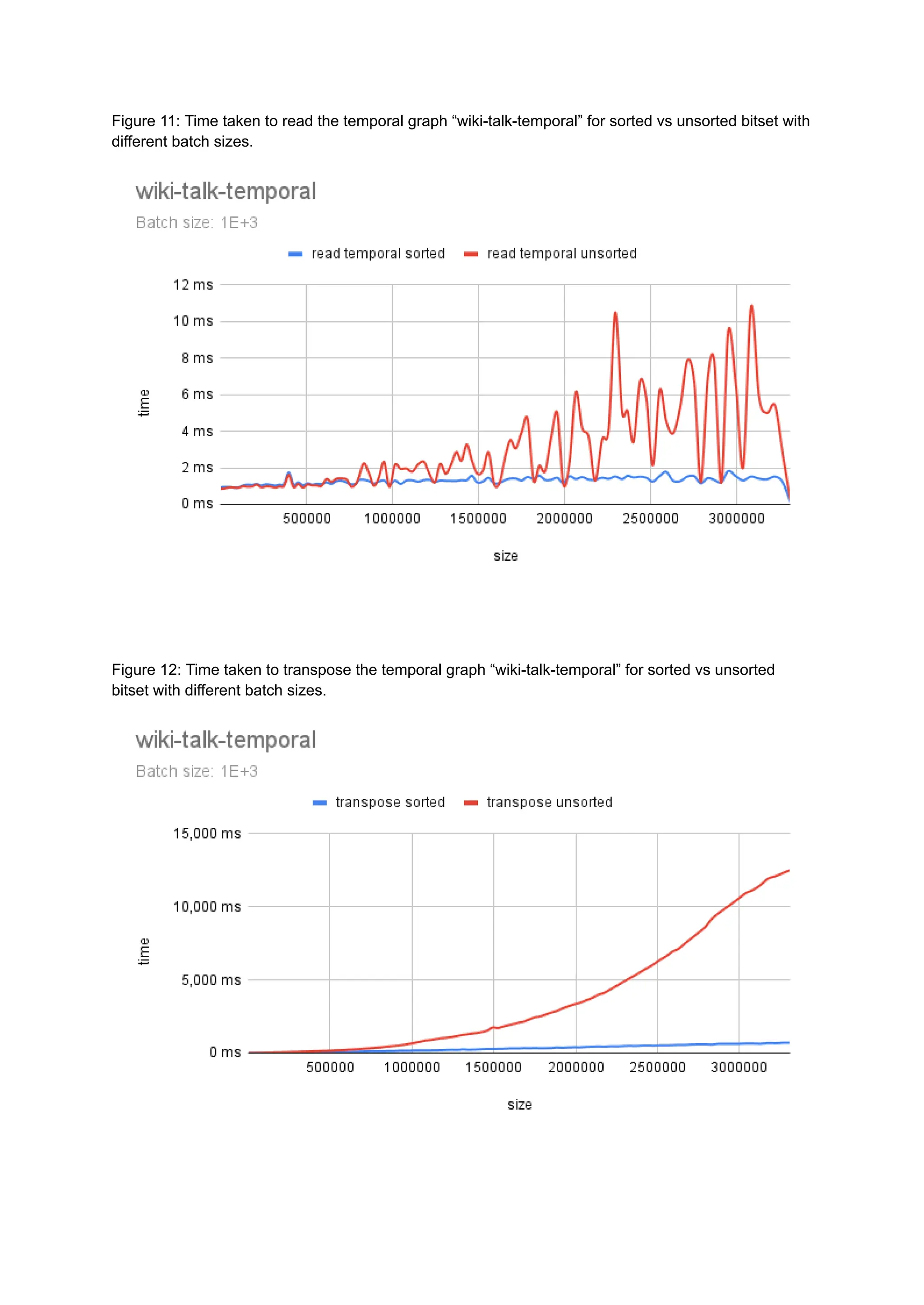
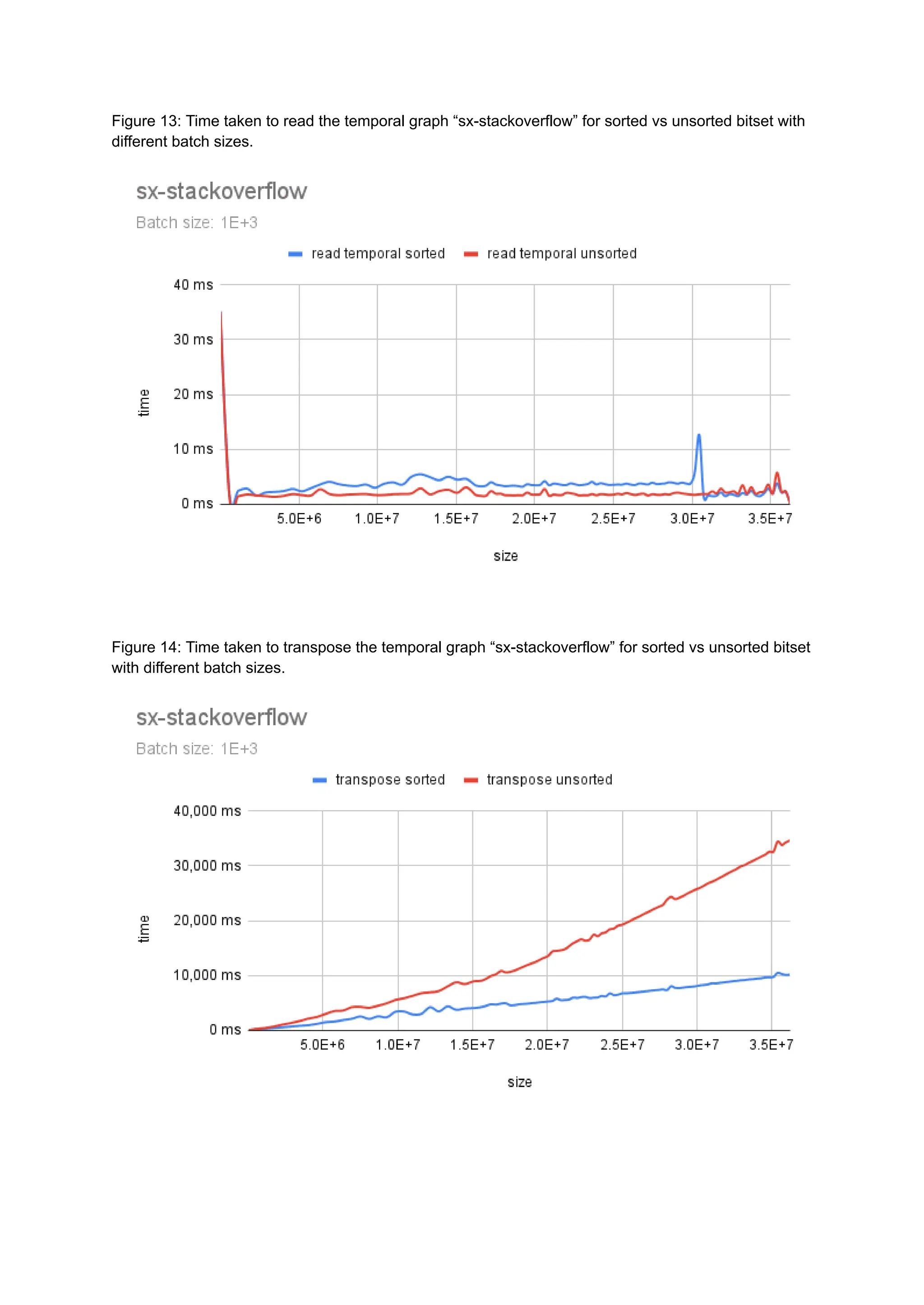
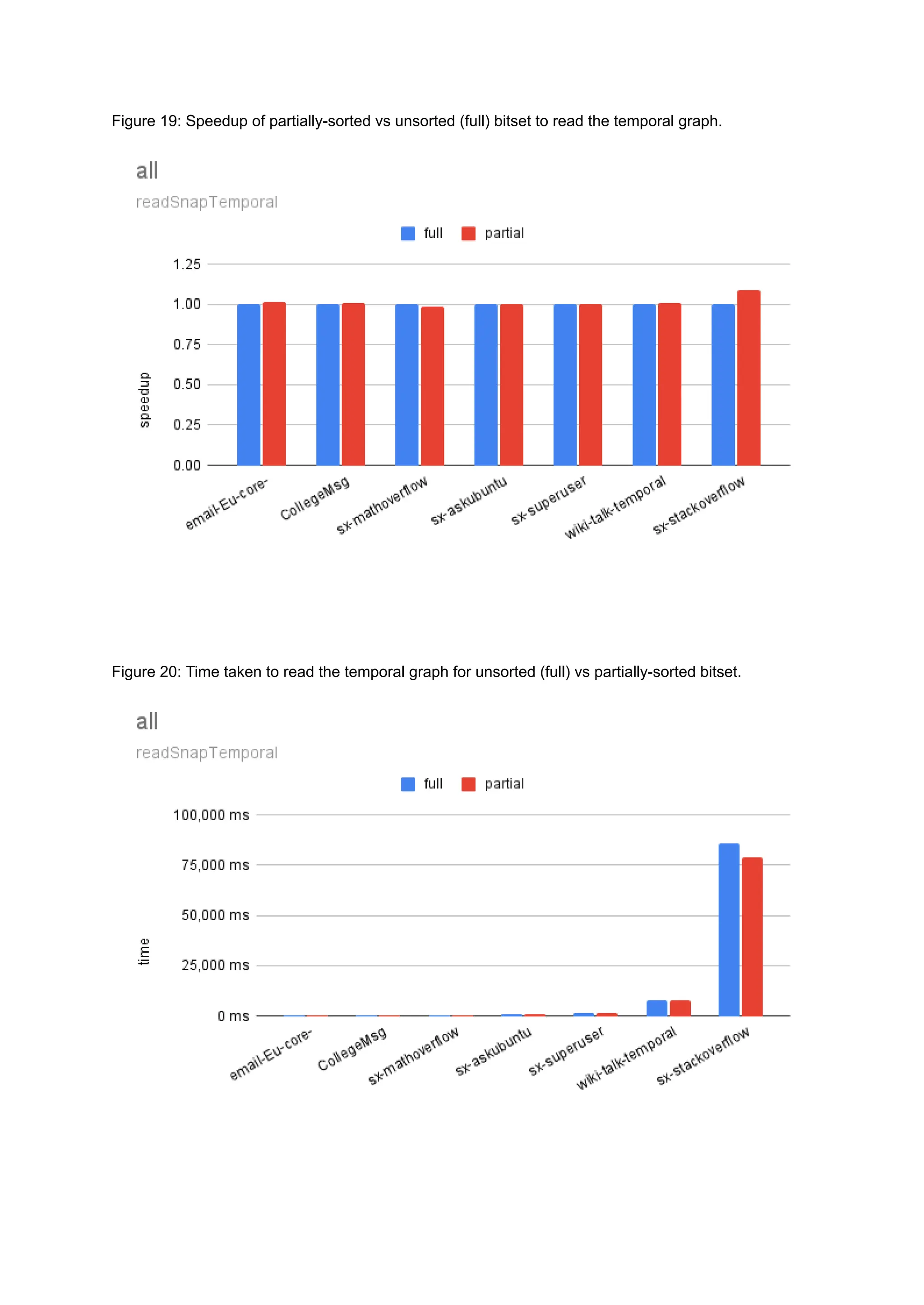
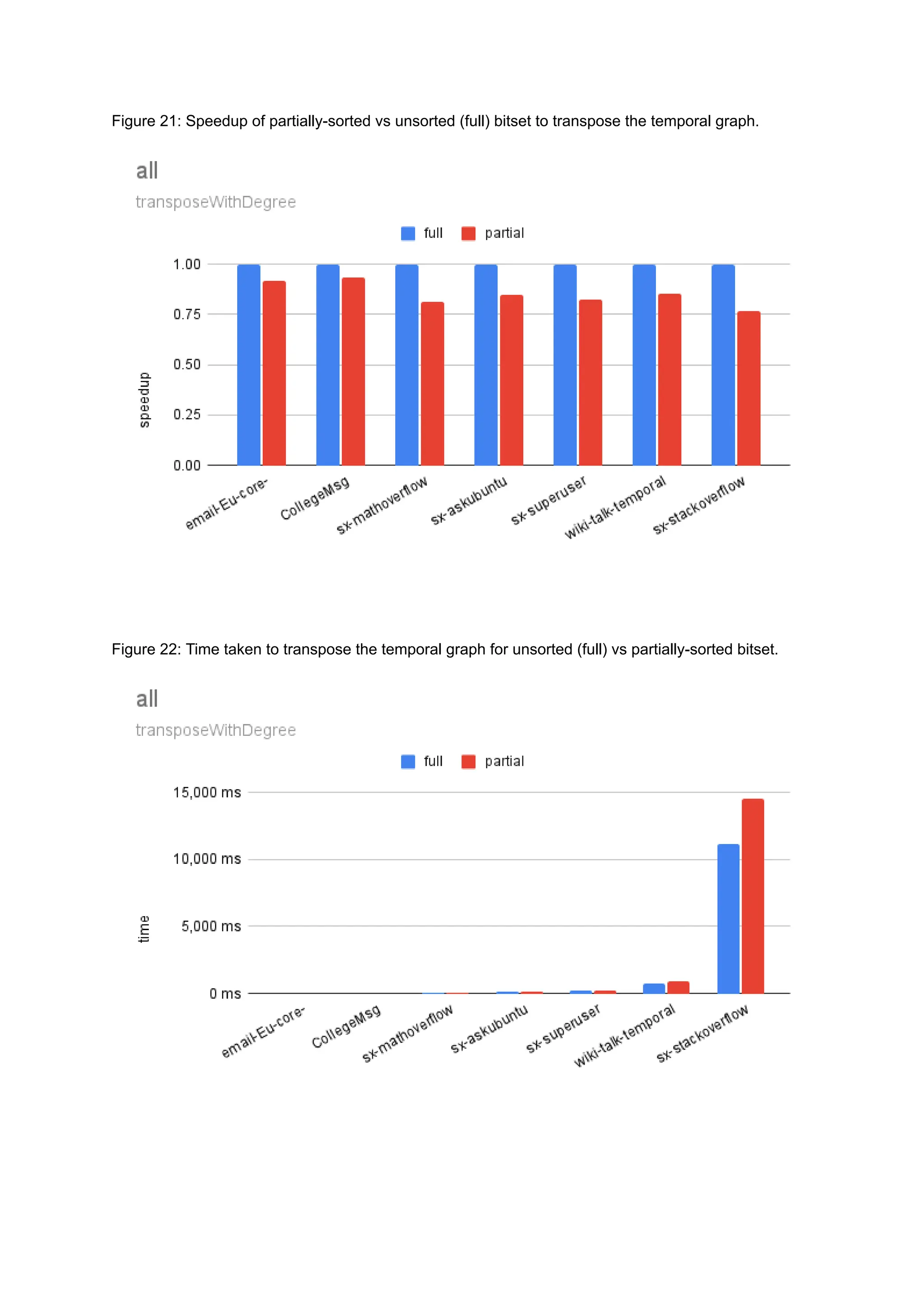
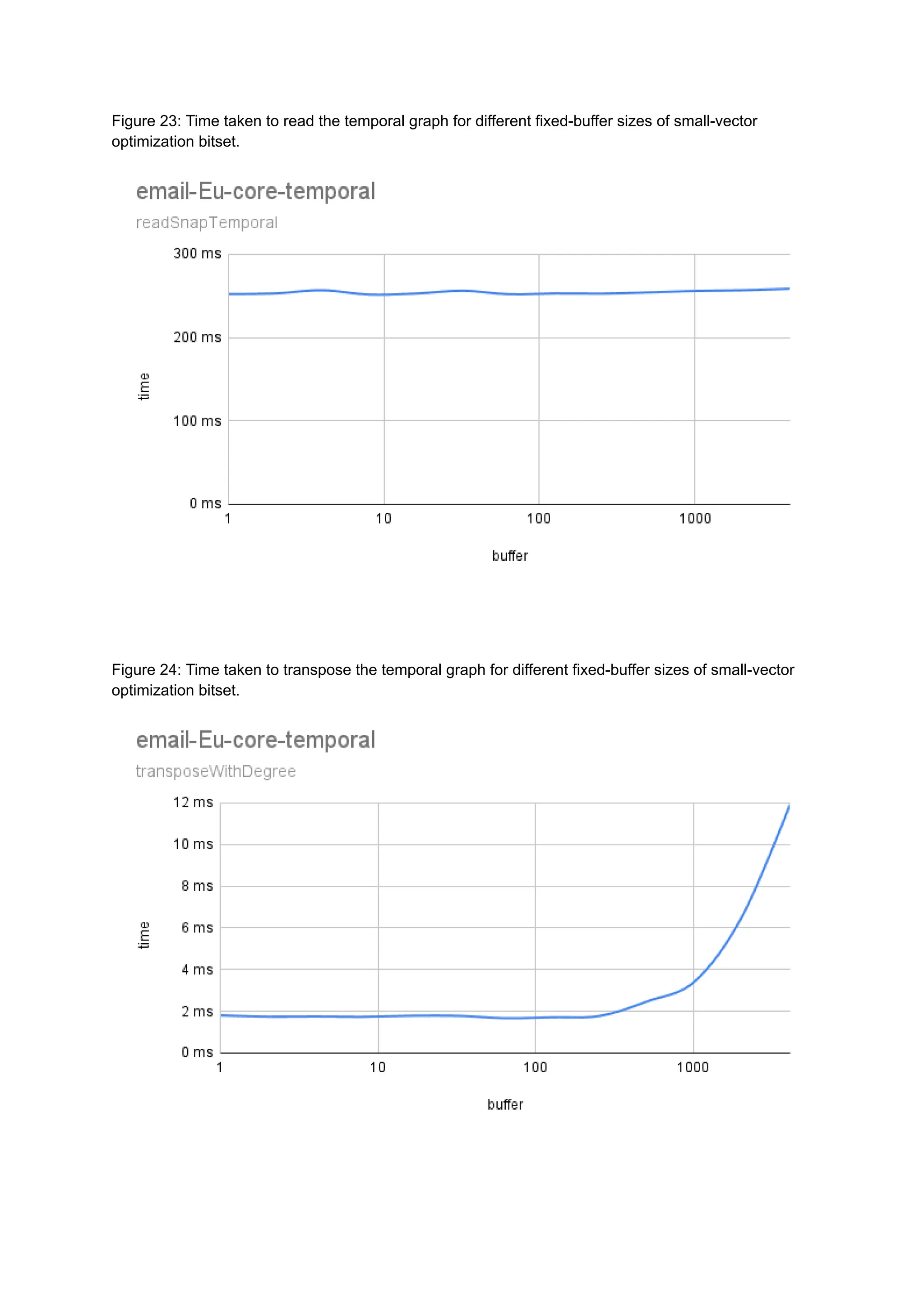

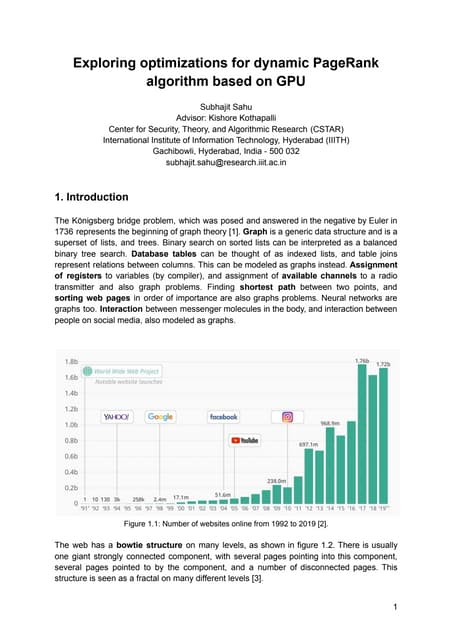
The document discusses the inefficiencies of using Compressed Sparse Row (CSR) representation for dynamic graphs, particularly in terms of memory access during edge addition and deletion. Different data structures for representing edge-lists, such as sorted and unsorted bitsets, were evaluated through experiments conducted on real-world temporal graphs, revealing performance variances depending on the structure and operations performed. The results indicate that sorted bitsets often outperform unsorted ones for specific tasks, while small-vector optimizations were found to provide minimal benefits due to memory allocation issues.